في عام 2025، نشر أندرياس هابي ويورغن سيتو من جامعة TU Wien"حول الفعالية المدهشة لـ LLMs في اختبار الاختراق"، مما يكشف عن حقيقة مذهلة: يمكن للنماذج اللغوية الكبيرة (LLMs) أن تضاهي - وأحياناً تتفوق - على الخبراء البشريين في مهام الاختبار الخماسية الرئيسية مثل التعرف على الأنماط وبناء سلسلة الهجوم، والتغلب على عدم اليقين في البيئات الديناميكية، مع توفير قابلية التوسع الفعالة من حيث التكلفة.
على خلفية تصاعد التهديدات السيبرانية والنقص الحاد في المواهب والبنية التحتية المؤسسية المتزايدة التعقيد، فإن هذا يمثل حقبة جديدة: التحول من "السحر الأسود" الذي يحركه سطر الأوامر إلى اختبار الأمان المدعوم بالذكاء الاصطناعي. ومن خلال دمج الذكاء الاصطناعي في مجموعة أدوات الأمن الهجومية، يمكن للمؤسسات خفض دورات الاختبار من أيام إلى ساعات، وتحويل مهارات الاختبار الخماسي المتقدم إلى بنية تحتية أمنية متاحة للجميع.

كيف يتم تطبيق LLMs في اختبار الاختراق؟
"الأدلة التجريبية من "حول الفعالية المدهشة لـ LLMs لاختبار الاختراق" تشير إلى أن الخصائص التشغيلية لنماذج اللغات الكبيرة تتماشى بشكل غير عادي مع الممارسات الواقعية لمختبري الاختراق. أحد العوامل التي يتم الاستشهاد بها بشكل متكرر هو انتشار الثقافات الأحادية التكنولوجية داخل البنية التحتية للمؤسسات. يسمح هذا التجانس للنماذج اللغوية الكبيرة بالاستفادة من قدراتها الاستثنائية في مطابقة الأنماط لتحديد التهيئة الأمنية المتكررة وتوقيعات الثغرات الأمنية التي تعكس الأمثلة المضمنة في مجموعات التدريب الخاصة بها. ونتيجةً لذلك، يمكن للنماذج صياغة استراتيجيات هجومية تتوافق مباشرةً مع مسارات الاستغلال المعروفة، مما يقلل من العبء الاستكشافي الذي يتطلبه عادةً المختبرون البشريون.
تكمن ميزة أخرى مهمة في قدرة نماذج إدارة مستوى عدم اليقين في البيئات المستهدفة الديناميكية والمتغيرة الحالة. في تمارين الاختراق متعدد الخطوات، يقوم النموذج باستمرار بتجميع الظروف المرصودة - مثل استجابات الخدمة أو سلوكيات المصادقة أو حالات الخطأ الجزئي - في "رؤية عالمية" متطورة. يُوجّه هذا التمثيل عملية اتخاذ القرار اللاحقة، مما يمكّن النموذج من الانتقال بين التكتيكات بسلاسة والتخلص من الافتراضات غير ذات الصلة أو التي عفا عليها الزمن دون قيود إجرائية صارمة تثقل كاهل الأنظمة القائمة على القواعد.
كما توفر النماذج ذات الأغراض العامة مزايا الفعالية من حيث التكلفة وقابلية التوسع. وقد أظهرت النماذج الجاهزة ذات الأغراض العامة بالفعل كفاءة في المهام الأمنية الهجومية المعقدة، مما يقلل من الحاجة إلى التدريب المكثف للموارد للأنظمة الخاصة بمجال محدد. حتى عندما تكون هناك حاجة إلى معرفة سياقية إضافية، يمكن لتقنيات مثل التعلم داخل السياق والتوليد المعزز للاسترجاع (RAG) أن توسع القدرات دون إعادة التدريب من الصفر، مما يسرع من النشر في بيئات تنظيمية متنوعة. والأهم من ذلك، تمتد هذه المرونة إلى ما هو أبعد من مجرد نماذج الاختبار الأكاديمية إلى سيناريوهات على مستوى الإنتاج.
أخيرًا، تعمل الأتمتة المدمجة في تدفقات العمل القائمة على LLM على تعزيز الإنتاجية من خلال سد الفجوة التقليدية بين الكشف والمعالجة. فالنموذج قادر على التحقق من صحة النتائج الأولية، وتصفية النتائج الإيجابية الخاطئة الناجمة عن ظروف الشبكة العابرة أو قيود الأدوات، وتطبيق تحديد الأولويات الواعية بالسياق التي توجه جهود الإصلاح إلى الثغرات الأكثر تأثيراً أولاً. إن مثل هذا التدفق الشامل - من الاستطلاع إلى التحقق من الصحة إلى التقارير القابلة للتنفيذ - يضغط الجداول الزمنية التشغيلية من أيام إلى ساعات، مع الحفاظ على مستوى من الشفافية في الاستدلال والمنهجية التي تساعد على التدقيق والمراجعة التنظيمية.
تحديات الاختبار الخماسي المستند إلى LLM
ومع ذلك، يجب الموازنة بين هذه المزايا والتحديات الملحوظة التي تظهر في السياقات التشغيلية.
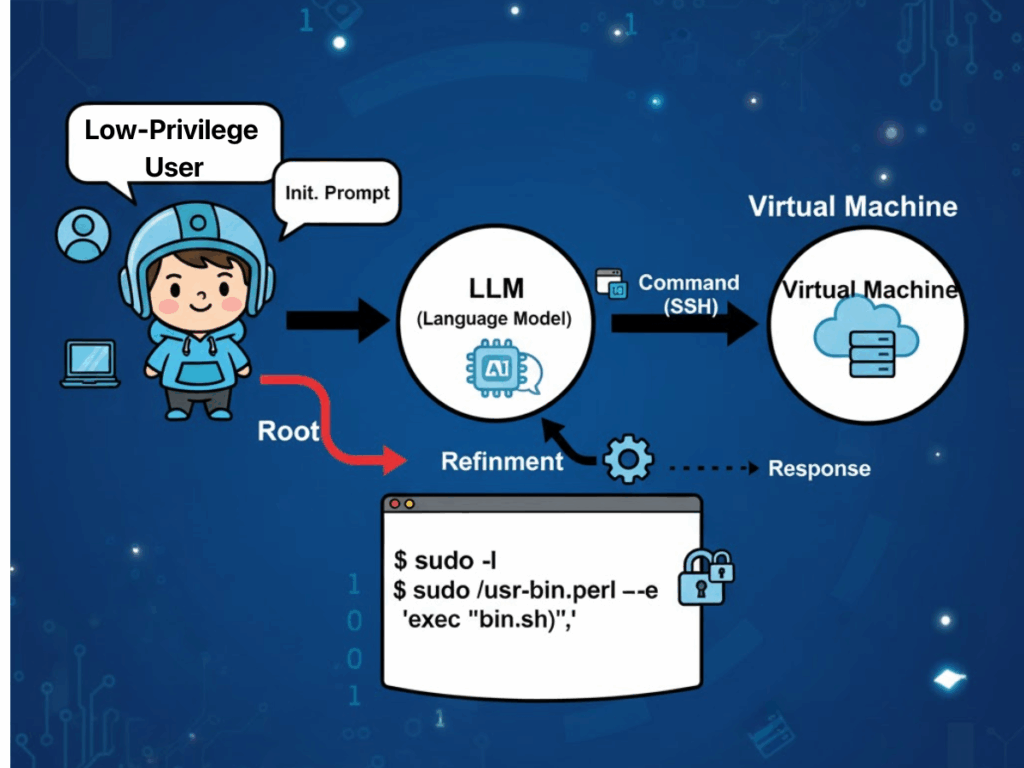
مشكلات الموثوقية والمخاطر الأمنية
يظل الاستقرار وقابلية التكرار إشكالية: يمكن أن تؤدي الاختلافات الطفيفة بين إصدارات النموذج إلى اختلافات في استخدام الأداة أو تسلسل الهجوم. في ظل ظروف متطابقة، قد تؤدي عمليات التشغيل المتعددة إلى إنتاج سلاسل هجمات مختلفة تمامًا، مما يقوض اتساق النتائج ويعقّد عملية التحقق من الصحة. في الاختبارات الديناميكية، في حين أن الاستراتيجية التكيفية هي نقطة قوة، إلا أن النماذج غير المقيدة بشكل كافٍ يمكن أن تنحرف عن نطاق المهمة المقصودة، وتنفذ إجراءات غير ذات صلة أو حتى غير آمنة إذا لم يتم فرض حواجز حماية.
عبء التكلفة والطاقة
يمثل استهلاك الموارد قيدًا آخر. إذ تتطلب نماذج الاستدلال عالية السعة طاقة حاسوبية أكبر بكثير، حيث تم الإبلاغ عن استخدام الطاقة بما يصل إلى سبعين ضعفاً من النماذج الأصغر حجماً والمخصصة للمهام. بالنسبة للمؤسسات التي تخطط لعمليات نشر الاختبار الخماسي المستقل المستدام أو المستقل على نطاق واسع، يُترجم هذا إلى تكاليف تشغيلية وتأثير بيئي كبير. الأتمتة نفسها ذات حدين: قد يتجاهل منطق تحديد الأولويات في النموذج النتائج ذات الأولوية المنخفضة التي تشكل مع ذلك مخاطر كامنة كبيرة، مما يستلزم وجود إشراف بشري ماهر لاكتشاف مثل هذه الإغفالات.
الخصوصية والسيادة الرقمية
تظل المخاوف المتعلقة بالخصوصية والامتثال حادة، لا سيما عند استخدام الاستدلال السحابي. قد يتم نقل البيانات المدخلة مثل ملفات التكوين أو مقاطع التعليمات البرمجية الخاصة أو تفاصيل البيئة إلى مزودي الطرف الثالث عبر واجهة برمجة التطبيقات، مما يثير شبح انتهاكات نقل البيانات عبر الحدود. يجب على الشركات متعددة الجنسيات أن توازن بين الفوائد الإنتاجية لتكامل إدارة السحابة الحاسوبية المحلية وواقع قوانين الامتثال الإقليمية المتباينة.
المساءلة الغامضة
وأخيرًا، لا تزال المساءلة عالقة - إذا أدت الاختبارات التي تعتمد على الذكاء الاصطناعي إلى تعطيل أنظمة الإنتاج عن غير قصد أو تسببت في فقدان البيانات، فإن المشهد القانوني الحالي لا يوفر أي إسناد محدد للمسؤولية، مما يعرض المؤسسات لمخاطر تعاقدية وتنظيمية ومخاطر تتعلق بالسمعة.
Penligent.ai: ثورة الفريق الأحمر للذكاء الاصطناعي
Penligent.ai يظهر كاستجابة متخصصة للعديد من هذه العقبات. يوصف بأنه أول مخترق الذكاء الاصطناعي العميلفهو يتخطى دور الماسحات الضوئية المستقلة أو البرامج النصية الجامدة للتشغيل الآلي من خلال تفسير توجيهات اللغة الطبيعية، وتحليل الأهداف المعقدة إلى مهام فرعية قابلة للتنفيذ، والاختيار من مكتبة متكاملة تضم أكثر من مائتي أداة أمنية قياسية في المجال، وتنسيقها بذكاء لإنتاج قوائم ثغرات أمنية تم التحقق من صحتها وتحديد أولوياتها مصحوبة بإرشادات علاجية.
الشفافية مضمنة في سير العمل: يمكن للمستخدمين مراقبة كل خطوة من خطوات التفكير، ومعرفة الأداة التي تم استدعاؤها بالضبط، وفهم سبب استخلاص استنتاجات معينة والإجراء الذي سيتبع ذلك. يعزز هذا التصميم الثقة ويسهّل عمليات التدقيق، مما يجعل Penligent ليس مجرد أداة بل شريكًا تعاونيًا للفريق الأحمر يتدرج من الاستخدام الفردي إلى النشر المؤسسي. من خلال تضمين المنطق المدرك للامتثال والمتوافق مع أطر العمل مثل NIST TEVV وإرشادات الفريق الأحمر للذكاء الاصطناعي التوليدي الخاص بـ OWASP، فإنه يسد الفجوة بين إمكانات الأتمتة والممارسات المنظمة.
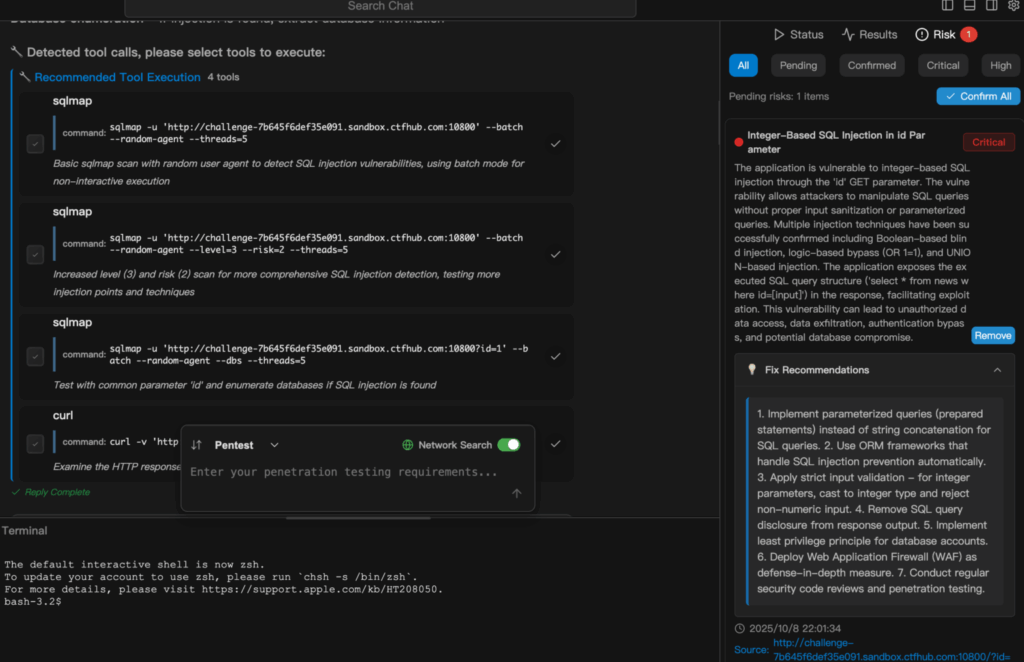
مثال توضيحي
يوضح المقتطف التالي كيف Penligent.ai التحولات من مهمة بسيطة باللغة الطبيعية إلى اختبار أمان تم تنفيذه والإبلاغ عنه بالكامل. إليك مثال على تشغيل فحص حقن SQL في بنليجينت
الخاتمة
من التحقق الأكاديمي للقدرات في "حول الفعالية المدهشة لـ LLMs لاختبار الاختراق" إلى التحسين التشغيلي المتجسد في Penligent.ai، فإن مسار الأمن الهجومي المدعوم بالذكاء الاصطناعي واضح: فالأدوات آخذة في النضج من مرحلة إثبات المفهوم إلى منصات جاهزة للإنتاج. وبالنسبة لمحترفي الأمن السيبراني ومختبري الاختراق والمتحمسين لأمن الذكاء الاصطناعي، فإن هذا الأمر لا يمثل تحسناً تدريجياً بقدر ما هو تحول في النموذج الأساسي. من خلال تقليل وقت الدورة، وخفض حواجز الدخول، وتعزيز الشفافية، ودمج الامتثال منذ البداية, Penligent.ai كيف يمكن أن تساعد الأتمتة الذكية كلاً من الخبراء البشريين وغير المتخصصين في الدفاع عن الأنظمة التي تعتمد عليها الأعمال الحديثة واختبارها.
لا يكمن التحدي الآن في إثبات أن هذه الأنظمة تعمل، ولكن في نشرها بشكل مسؤول: ضمان الاستقرار وقابلية التكرار، والحد من سوء الاستخدام، وحماية الخصوصية، وإرساء المساءلة. إذا تم إجراء الاختبار الخماسي القائم على الذكاء الاصطناعي بشكل صحيح، فقد لا يصبح الاختبار الخماسي القائم على الذكاء الاصطناعي ميزة تنافسية فحسب، بل قد يصبح مكونًا أساسيًا للوضع الأمني في عصر تتطور فيه التهديدات بشكل أسرع من أي وقت مضى.