White box auditing plus black box proof you can ship
Security teams rarely fail because they didn’t run a scanner. They fail because they couldn’t answer three questions fast enough:
- Is this actually exploitable in our environment
- What is the smallest safe fix
- How do we prove it’s fixed and stays fixed
That is why modern security work increasingly looks like a loop rather than a phase gate: white box reasoning to understand root causeund black box validation to prove reachability and impact.
Anthropic’s Claude Code Security is positioned as a capability built into Claude Code that scans codebases for vulnerabilities and suggests targeted patches for human review, designed to catch issues traditional methods often miss. (Anthropisch)
Sträflich positions itself as an AI-powered penetration testing platform focused on running tasks, verifying findings, and producing reports against real targets. (Sträflich)
This article shows how to combine them into one publishable, repeatable workflow:
- Verwenden Sie Claude Code Security für white box auditing and patch direction
- Verwenden Sie Sträflich für black box auditing, vulnerability hunting, and proof of exploitability
- Close the loop with regression tests and re-verification
You are not trying to “replace” engineering judgment. You are trying to make judgment faster, auditable, and evidence-driven.
Why this pairing matches how real breaches happen
A lot of security advice assumes the system in front of you is a clean monolith with a neat boundary. Most modern systems are neither.
They are:
- dependency-heavy and polyglot
- split into services and pipelines
- fronted by identity systems, gateways, WAFs, CDNs
- shaped by environment configuration and feature flags
In that world, white box und black box are not substitutes. They answer different questions:
- White box: Where is the bug in the code, and what fix is correct
- Black box: Is the bug reachable and exploitable through the deployed surface today
OWASP’s testing guidance frames web security testing as a comprehensive practice rather than a single technique, and OWASP’s Code Review Guide exists specifically because code review reveals classes of issues you won’t reliably see from outside. (OWASP-Stiftung)
CISA’s Known Exploited Vulnerabilities Catalog reinforces the operational reality: prioritization should be driven by what is actually exploited in the wild, not just what is theoretically possible. (CISA)
The simplest way to explain the combined model is this:
Claude Code Security tells you what is vulnerable. Penligent tells you what is exposed.
When you combine them, you stop arguing about severity and start shipping fixes with proof.
What Claude Code Security is in practice
Anthropic describes Claude Code Security as a capability built into Claude Code, available in a limited research preview, that scans codebases for vulnerabilities and suggests targeted patches for human review. (Anthropisch)
Their support documentation describes “Automated Security Reviews in Claude Code,” including the /security-review command and a GitHub Actions workflow for pull requests. (Claude Help Center)
Anthropic also publishes a GitHub Action repository, claude-code-security-review, for AI-powered security review of code changes. (GitHub)
Where it shines
Use Claude Code Security when you need to:
- reason about data flow and trust boundaries across modules
- identify injection, XSS, auth flaws, insecure data handling, and dependency risk categories surfaced in their docs (Claude Help Center)
- propose patch direction with context rather than only pattern matching
What it should not be used as
Anthropic’s own documentation explicitly warns that automated security reviews should complement, not replace, existing security practices and manual reviews. (Claude Help Center)
That caveat matters: AI-assisted code auditing is still an accelerator, not a substitute for engineering accountability.
What Penligent is in practice
Penligent positions itself as an AI-powered penetration testing tool that can run end-to-end workflows and produce stakeholder-ready outputs; its public materials emphasize verified results, reproducible steps, and reporting. (Sträflich)
Penligent’s long-form “HackingLabs” content emphasizes “agentic red teaming” and the shift from “LLM writes commands” to “verified findings,” which aligns with the black box job: validate exploitability and evidence. (Sträflich)
Where it shines
Use Penligent when you need to:
- validate exposure against real targets and real gateways
- find vulnerabilities without needing source access
- produce reproducible evidence suitable for remediation workflows and reporting
- re-run verification after fixes ship to prevent regression
The combined workflow you can operationalize
If you want something you can run every sprint without heroics, treat this as a loop with defined artifacts.
Phase 1 White box audit and patch direction
Goal: identify likely vulnerabilities in code and propose safe fixes.
Typical outputs:
- vulnerability hypothesis and affected components
- proposed patch options with tradeoffs
- new tests to prevent regression
- a short risk summary engineers can act on
Practical entry points:
- run on-demand review in the repo via
/security-review(Claude Help Center) - run pull request review via GitHub Actions integration (GitHub)
Example command flow
# From your repository root, in Claude Code
/security-review
# Optional: narrow the scope by focusing on a directory or a set of files
# Then ask for output that includes: root cause, exploit scenario, fix diff, and regression test ideas
The exact UI/UX will vary by how your team integrates Claude Code, but the key is consistent output: you want review artifacts that are readable, traceable, and actionable.
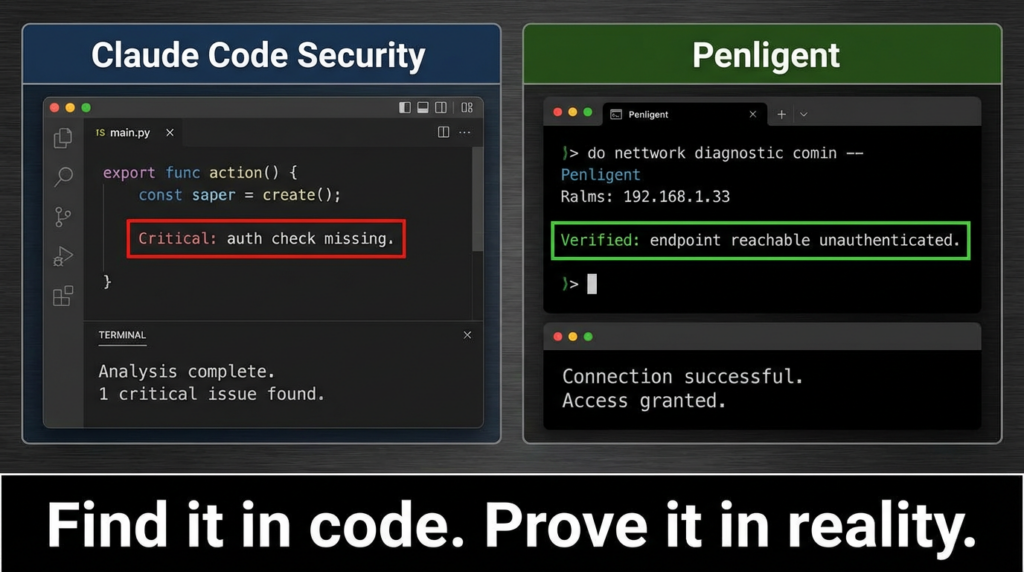
Phase 2 Black box validation and vulnerability hunting
Goal: confirm reachability and impact through the real attack surface.
Typical outputs:
- confirmed vulnerable endpoints and conditions
- proof of exploitability that avoids weaponization
- affected scope and blast radius
- evidence suitable for ticketing and leadership
This is where Penligent fits: black box auditing and vulnerability hunting against what attackers actually see, not what your architecture diagram claims.
Phase 3 Map black box findings back to code and fix
Goal: turn black box evidence into a code-level fix with minimal risk.
This is the handoff point that teams often mishandle.
A black box finding is often a symptom:
- an API returns data it should not
- a privilege boundary is bypassed
- a cookie or token behavior is exploitable
- a gateway route is missing enforcement
Claude Code Security becomes useful again here: map the symptom to the right code path, propose the smallest safe patch, and help generate regression tests that lock the behavior.
Phase 4 Regression proof and repeatable verification
Goal: prove the issue is fixed and stays fixed.
Minimum set of proof artifacts:
- patch diff and code owner approval
- a regression test that fails on the old behavior
- a black box re-run demonstrating closure
Treat this as a product requirement, not a “security nice-to-have.”
A decision table that prevents tool religious wars
| Security need | Beginnen Sie mit | Warum | Follow with | Warum |
|---|---|---|---|---|
| New PR or refactor risk | Claude Code Security | code-context reasoning, patch suggestions (Anthropisch) | Sträflich | validate in staging with real auth and topology |
| Unknown exposure surface | Sträflich | black box sees what attackers see | Claude Code Security | map to source and patch safely |
| Auth and access control correctness | Claude Code Security | locate missing checks in code | Sträflich | prove bypass or prove protection in deployment |
| Edge and gateway vulnerabilities | Sträflich | often outside your repo | Claude Code Security | ensure app side defense-in-depth |
| Proving closure | Both | fix + evidence | Both | stop regressions, build trust |
Why “proof of exploitability” matters more than ever
Many of the worst incidents of the last decade were not about obscure bugs. They were about bugs that were actually exploitable at internet scale, often through surfaces teams underestimated.
CISA’s KEV Catalog exists because not all vulnerabilities deserve equal urgency; “known exploited” should change your priorities. (CISA)
Below are concrete CVE case studies that illustrate why white box alone or black box alone is insufficient.

CVE case studies that show the white box and black box gap
CVE-2021-44228 Log4Shell
NVD describes Log4Shell as an issue in Apache Log4j2 where an attacker who can control log messages or parameters can cause code to be loaded from attacker-controlled LDAP or other JNDI endpoints when message lookup substitution is enabled, with behavior disabled by default starting in Log4j 2.15.0. (NVD)
What white box gives you
- identify where untrusted strings reach logging
- identify dependency versions and lookup behavior
- propose upgrades and safe configuration changes
What black box gives you
- confirm whether vulnerable paths are reachable through deployed routes
- confirm outbound egress constraints that affect exploitation
- confirm whether mitigations are actually applied in production builds
Log4Shell was a dependency vulnerability that became an exposure vulnerability. That distinction is exactly why the loop matters.
CVE-2023-34362 MOVEit Transfer SQL injection
NVD describes CVE-2023-34362 as a SQL injection vulnerability in MOVEit Transfer that could allow an unauthenticated attacker to gain access to the database for affected versions. (NVD)
The CVE record mirrors that characterization. (CVE)
What white box gives you
- identify unsafe query construction and trust boundaries
- patch patterns and test coverage
What black box gives you
- identify whether your instance is exposed, reachable, and exploitable
- identify compensating controls that reduce reachability
- provide evidence for incident response and stakeholder communication
MOVEit is also a reminder that sometimes the vulnerable surface is a product you deploy, not code you wrote. Black box coverage becomes critical.
CVE-2023-4966 Citrix Bleed
CISA released guidance and added Citrix Bleed to its known exploited context, emphasizing active exploitation and mitigation actions for NetScaler ADC and Gateway. (CISA)
NVD also flags CVE-2023-4966 as being in CISA’s Known Exploited Vulnerabilities Catalog. (NVD)
Why this matters to your toolchain discussion
In these cases, code review in your repo may not help you. The vulnerability is at your edge infrastructure, and the “fix” is patching plus session hygiene and configuration. Your defense program must include black box validation and asset visibility.

CVE-2025-5777 CitrixBleed 2
NVD describes CVE-2025-5777 as insufficient input validation leading to memory overread when NetScaler is configured as a Gateway or AAA virtual server. (NVD)
CISA published an alert noting it added CVE-2025-5777 to the KEV Catalog based on evidence of active exploitation. (CISA)
Citrix published a support advisory for CVE-2025-5777, and NetScaler’s blog post discussed security updates for CVE-2025-5777 and CVE-2025-6543. (Citrix Support)
White box relevance
- defense-in-depth in your application, because edge bugs make sessions and tokens more fragile
Black box relevance
- verify whether your gateway and authentication surfaces are exposed and properly patched
- verify post-patch hygiene requirements such as session termination, depending on vendor guidance and incident patterns
For real enterprises, this is not hypothetical. It is a weekly operational concern.
A realistic pipeline design for teams that ship software
The biggest mistake teams make is treating “security review” as a single job. In practice it is four jobs:
- Find likely issues early in code changes
- Validieren Sie exploitability in a realistic environment
- Fix with minimal risk and add regression tests
- Prove closure with repeatable verification
Claude Code Security is most useful in steps 1 and 3. (Claude Help Center)
Penligent is most useful in steps 2 and 4. (Sträflich)
Below is a pipeline architecture you can adopt without rebuilding your org chart.
Implementation blueprint with artifacts and ownership
Security review artifacts that scale
Define these artifacts and require them consistently:
- Finding record: title, risk, affected surface, evidence, reproduction notes
- Fix record: patch summary, tests added, deployment notes
- Verification record: black box re-test summary and evidence of closure
If your artifacts look consistent, your program becomes auditable and measurable.
Ownership model that avoids bottlenecks
- Engineers own fixing
- Security owns validation methodology and severity rubric
- Platform or SRE owns the deployment and regression proof infrastructure
The moment security becomes the only group capable of running verification, you get backlogs and blind spots.
Code examples for engineers who want concrete steps
The goal here is not to “teach exploitation.” It is to show how you can structure secure code and secure tests so that a white box finding can be fixed and then validated in black box.
Example 1 Parameterized queries for SQL injection risk reduction
A huge share of injection risk comes from string concatenation or unsafe interpolation.
Bad pattern
# Do not do this
query = f"SELECT * FROM users WHERE email = '{email}'"
cursor.execute(query)
Better pattern
query = "SELECT * FROM users WHERE email = %s"
cursor.execute(query, (email,))
Claude Code Security reviews explicitly list SQL injection risks as a target class, which aligns with why you want automated review in PRs. (Claude Help Center)

Example 2 A minimal authorization guard with explicit tenancy checks
Many severe issues are not “bugs” in the traditional sense; they are missing enforcement.
def require_tenant_access(user, tenant_id):
if tenant_id not in user.allowed_tenants:
raise PermissionError("Forbidden")
def get_invoice(user, tenant_id, invoice_id):
require_tenant_access(user, tenant_id)
return db.fetch_invoice(tenant_id=tenant_id, invoice_id=invoice_id)
White box auditing helps you find missing checks across call chains. Black box validation proves whether an attacker can hit a route through gateways and role transitions.
Example 3 Regression tests that lock in the fix
def test_invoice_access_blocked_for_other_tenant(client, user_a, tenant_b, invoice_b):
client.login(user_a)
resp = client.get(f"/tenants/{tenant_b}/invoices/{invoice_b}")
assert resp.status_code in (403, 404)
The point is not the framework. The point is: fixes without tests are temporary.
A practical CI workflow sketch with PR gating
Anthropic’s documentation explicitly describes using automated security reviews via /security-review and GitHub Actions. (Claude Help Center)
A safe enterprise pattern is:
- PR review: Claude Code Security comments and summary, human reviewer required for high severity classes
- Merge to staging: Penligent black box validation run
- Release: re-run a focused verification suite, archive evidence
Here is a sketch that illustrates the gating logic. This is intentionally conservative and does not pretend every product has the same public API surface.
name: security-gates
on:
pull_request:
push:
branches: [ "main" ]
jobs:
whitebox_review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Claude Code Security review
run: |
echo "Run Claude Code /security-review for this PR and attach findings."
echo "For GitHub Actions integration, use the Anthropic security review action or official docs."
blackbox_validate:
runs-on: ubuntu-latest
needs: whitebox_review
if: github.ref == 'refs/heads/main'
steps:
- name: Penligent verification run on staging
run: |
echo "Trigger a Penligent black-box verification run for staging."
echo "Fail this job if confirmed critical exposure is detected."
The main idea: white box reduces defect injection, black box reduces false confidence.
How to keep AI-assisted reviews honest
AI-assisted auditing can fail in predictable ways:
- it flags real patterns that are unreachable in practice
- it misses environment-specific exposure
- it proposes patches that look plausible but break semantics
- it overstates severity without proof
Anthropic explicitly frames automated security review as complementary to existing practices and manual review. (Claude Help Center)
So build guardrails that assume fallibility.
Guardrail 1 Make every high severity finding prove one of these
- a clear trust boundary violation in code
- a clear exploit path in black box validation
- a clear dependency exposure with verified deployment footprint
If you cannot prove one of these, treat the finding as “needs investigation” rather than “confirmed.”
Guardrail 2 Separate hypotheses from confirmed exposures
Use two labels:
- suspected: identified via code review heuristics or AI reasoning
- confirmed: validated by reproducible evidence
This prevents your program from becoming a noise generator.
Guardrail 3 Require regression proof for confirmed findings
If the bug mattered enough to fix, it matters enough to prevent reintroduction.
The most common failure modes and how this pairing prevents them
Failure mode A SAST says critical but no one can reproduce
White box tools often over-report. With this workflow:
- Claude Code Security gives contextual reasoning and patch direction (Claude Help Center)
- Penligent provides black box confirmation for reachability and impact (Sträflich)
You converge on reality faster.
Failure mode B Pen test says critical but engineering cannot find root cause
Black box reports without mapping become political documents.
With this workflow:
- Penligent provides evidence and reproduction context
- Claude Code Security helps map the symptom to the right code path and patch design
Engineering stops guessing.
Failure mode C Fix shipped but incident repeats
This is the most expensive failure mode.
With this workflow:
- the fix is paired with tests
- black box verification is re-run
- closure is recorded as evidence
You reduce recurrence rather than just shipping a patch note.
Penligent’s own positioning emphasizes moving from discovery to verified findings and reportable outputs. (Sträflich)
In practical terms, the role is straightforward:
- use it to test what the internet can touch
- use it to validate the severity of suspected issues
- use it to re-test after fixes
Penligent’s long-form content frames the 2026 shift toward agentic red teaming and exploit-chain validation rather than isolated scanner output. (Sträflich)
That worldview aligns with what modern security leaders actually need: proof, not vibes.

A table you can drop into an internal decision doc
| Kategorie | Claude Code Security | Sträflich | Best combined practice |
|---|---|---|---|
| Primary perspective | Quellcode | running target | find in code, prove in reality |
| Best timing | PR and refactor time | staging and continuous validation | run both every sprint |
| Stärke | contextual reasoning over code, patch suggestions (Anthropisch) | exploitability validation, evidence and reporting (Sträflich) | closed-loop remediation |
| Häufiges Scheitern | false positives, missing environment context | hard-to-map symptoms | require mapping and regression proof |
| Metrics | defect prevention | exposure reduction | MTTR, recurrence rate, confirmed-exploitable ratio |
Referenzen
Anthropic announcement: Claude Code Security https://www.anthropic.com/news/claude-code-security Anthropic support docs: Automated Security Reviews in Claude Code https://support.claude.com/en/articles/11932705-automated-security-reviews-in-claude-code Anthropic blog: Automate security reviews with Claude Code https://claude.com/blog/automate-security-reviews-with-claude-code Anthropic GitHub Action: Claude Code Security Reviewer https://github.com/anthropics/claude-code-security-review OWASP-Leitfaden für Web-Sicherheitstests https://owasp.org/www-project-web-security-testing-guide/ OWASP Code Review Guide project https://owasp.org/www-project-code-review-guide/ CISA-Katalog bekannter ausgenutzter Sicherheitslücken https://www.cisa.gov/known-exploited-vulnerabilities-catalog CISA guidance on Citrix Bleed CVE-2023-4966 https://www.cisa.gov/guidance-addressing-citrix-netscaler-adc-and-gateway-vulnerability-cve-2023-4966-citrix-bleed NVD CVE-2021-44228 Log4Shell https://nvd.nist.gov/vuln/detail/CVE-2021-44228 NVD CVE-2023-34362 MOVEit Transfer SQL injection https://nvd.nist.gov/vuln/detail/CVE-2023-34362 NVD CVE-2023-4966 Citrix Bleed https://nvd.nist.gov/vuln/detail/CVE-2023-4966 NVD CVE-2025-5777 CitrixBleed 2 https://nvd.nist.gov/vuln/detail/CVE-2025-5777 CISA alert adding CVE-2025-5777 to KEV https://www.cisa.gov/news-events/alerts/2025/07/10/cisa-adds-one-known-exploited-vulnerability-catalog Citrix advisory CVE-2025-5777 https://support.citrix.com/support-home/kbsearch/article?articleNumber=CTX693420 NetScaler blog security updates for CVE-2025-5777 and CVE-2025-6543 https://www.netscaler.com/blog/news/netscaler-critical-security-updates-for-cve-2025-6543-and-cve-2025-5777/ Penligent main site https://penligent.ai/ Penligent article: The 2026 Ultimate Guide to AI Penetration Testing https://www.penligent.ai/hackinglabs/the-2026-ultimate-guide-to-ai-penetration-testing-the-era-of-agentic-red-teaming/ Penligent article: PentestGPT vs Penligent AI in Real Engagements https://www.penligent.ai/hackinglabs/pentestgpt-vs-penligent-ai-in-real-engagements-from-llm-writes-commands-to-verified-findings/ Penligent article: PentestGPT Alternatives and the Rise of Autonomous AI Red Teaming https://www.penligent.ai/hackinglabs/pentestgpt-alternatives-and-the-rise-of-autonomous-ai-red-teaming-2026/ Penligent article: Clawdbot Shodan technical post-mortem and defense architecture https://www.penligent.ai/hackinglabs/clawdbot-shodan-technical-post-mortem-and-defense-architecture-for-agentic-ai-systems-2026/

