The market for AI pentesting tools is crowded for a simple reason: the label now gets applied to almost anything in security that has an LLM attached to it. In one roundup, you will see a Burp assistant, a source-aware API scanner, an autonomous black-box web testing engine, a continuous attack-path validator, and an AI application red-teaming framework all treated as if they solve the same problem. They do not. That mismatch is why so many “best AI pentesting tools” lists sound useful at first and become less useful the closer you get to an actual engineering decision. (PortSwigger)
The first correction is definitional. NIST’s guidance on technical security testing is still centered on planning tests, conducting them, analyzing findings, and developing mitigation strategies. NIST’s separate definition of AI red teaming is narrower and different: a structured effort to find flaws in an AI system, often in controlled conditions and with developers involved. OWASP’s Web Security Testing Guide still frames application testing around the broad, messy territory that real pentesters know well, including authentication, authorization, session handling, input validation, and business logic. OWASP’s AI Testing Guide and OWASP’s 2026 agentic security work do something else: they address trustworthiness and risk in AI systems themselves. Treating those as the same job creates bad tool evaluations and bad buying decisions. (NIST-Ressourcenzentrum für Computersicherheit)
That distinction matters even more in 2026 because the product categories have pulled farther apart. Burp AI is clearly positioned as an AI-enhanced workflow inside Burp Suite. StackHawk’s AI layer is tied to generating OpenAPI specs from source so teams can test APIs that otherwise stay uncovered. Escape’s multi-agent pentest is built as an autonomous black-box engine with reconnaissance, exploitation, validation, and reporting inside a sandbox. Promptfoo is built for red teaming AI applications and MCP-based systems. NodeZero, Pentera, and Hadrian are all closer to proof-first exposure or attack-path validation than to classic app-only pentesting. PentestGPT remains one of the most important open-source efforts in the space, but its public materials still place it closer to an operator framework and research platform than to a turnkey enterprise engagement substitute. (PortSwigger)
AI Pentesting Tools Need a Stricter Definition
A real pentesting tool does more than summarize scan output in friendlier English. It has to sustain context across a testing workflow, handle authentication correctly, understand when state matters, preserve enough evidence for another engineer to reproduce what happened, and avoid presenting speculative issues as if they were proven. That is not just a philosophical preference. It is built into how authoritative guidance describes the job, and it is visible in the way serious platforms describe their strongest features: proof, impact, validation, retest, or evidence-rich reporting show up again and again. (NIST-Ressourcenzentrum für Computersicherheit)
For web and API work, the fastest way to test whether a vendor is stretching the term is to ask four questions. Can it survive authenticated testing on stateful applications. Can it reason about authorization and business logic instead of only payload-class vulnerabilities. Can it prove impact or at least capture enough artifacts to replay the path. Can it help with retesting after a fix. If the answer is no to most of those, the product may still be valuable, but it is probably better described as a scanner, an assistant, a coverage layer, or an AI testing tool rather than a general AI pentester. OWASP’s web and API material makes that standard hard to evade because broken authorization and workflow abuse are not edge cases anymore. They are central categories. (OWASP-Stiftung)
The same logic applies in the other direction. If the target is an LLM application, an agent, an MCP server, or a RAG system, then a conventional web pentesting workflow is not enough by itself. OWASP’s AI Testing Guide, the OWASP Top 10 for Agentic Applications 2026, and Promptfoo’s own documentation all reflect the same operational shift: prompt injection, tool misuse, indirect instruction following, data exfiltration, and agent authorization failures have to be treated as first-class test objectives, not footnotes. A tool can be excellent for traditional app pentesting and still be the wrong answer for AI application security. (OWASP-Stiftung)
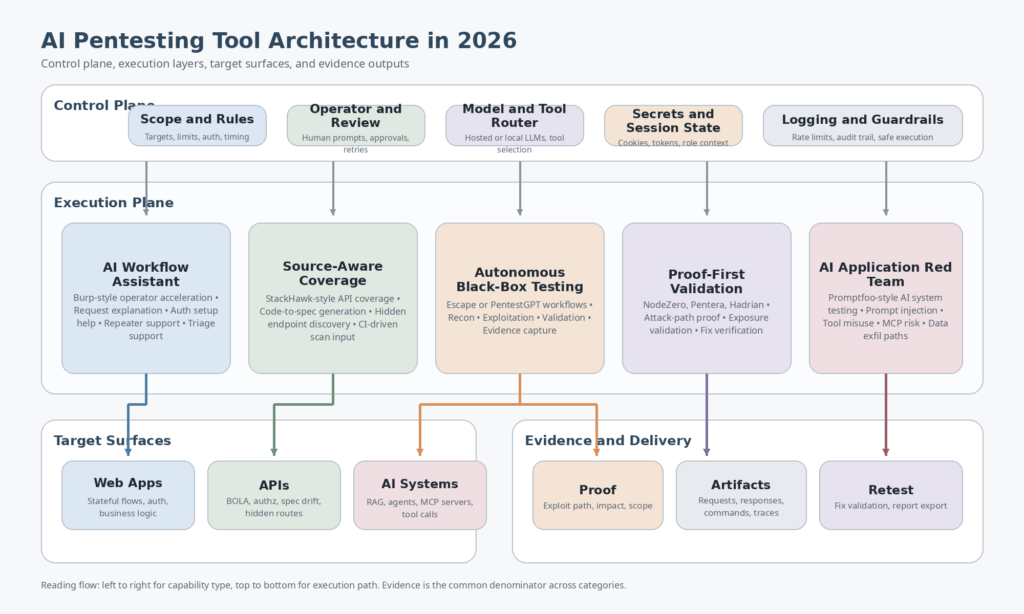
The AI Pentesting Tools Market Is Really Seven Markets
The easiest way to stop comparing unlike things is to sort the field by the question each tool answers.
| Kategorie | Core question answered | Representative examples | Where it is strongest | Where it is weaker |
|---|---|---|---|---|
| AI workflow accelerator | How do I make a human tester faster inside an existing workflow | Rülpsen AI | Manual web testing, auth setup, triage, extension workflows | Not a full autonomous pentest platform (PortSwigger) |
| Source-aware DAST and API coverage | How do I increase API test coverage from code and CI | StackHawk | Code-to-spec generation, CI-driven API security coverage | Less suited to adaptive exploit-path work (StackHawk Documentation) |
| Autonomous black-box web and API pentest | Can coordinated agents find, validate, and report app flaws | Escape | Auth-heavy web and API testing, evidence-rich reporting | Coverage still depends on reachability, auth setup, and time budget (Escape Documentation) |
| Open-source operator framework | How far can an LLM-guided pentest workflow go in a controlled environment | PentestGPT | Labs, CTFs, research, reproducible open workflows | Less turnkey for governed enterprise delivery (GitHub) |
| Proof-first enterprise attack-path validation | What is actually exploitable in the environment | NodeZero, Pentera | Proven paths, impact, remediation verification, continuous validation | Not identical to app-centric business-logic pentesting (Horizon3.ai) |
| Continuous external attack validation | What on my public edge is exposed and exploitable right now | Hadrian | External exposure discovery and 24-7 validation | Narrower than full internal or in-app testing (Hadrian) |
| AI application red teaming | How do I test models, RAG systems, agents, and MCP servers | Promptfoo | Prompt injection, tool misuse, AI app regression testing | Not a substitute for classic network or web pentesting (Promptfoo) |
Once you look at the market that way, the usual “top 10” article starts to break down. A team choosing between Burp AI and Promptfoo is not really comparing two competing pentesting platforms. It is choosing between an AI-augmented web testing workflow and an AI application red-teaming framework. A team choosing between StackHawk and Hadrian is not making a web scanner decision either. It is choosing between code-aware application coverage and continuous external validation. And a team choosing between Escape and Pentera is deciding whether its center of gravity is app-centric black-box testing or broader exploitability validation across the enterprise. (StackHawk Documentation)
How to Evaluate AI Pentesting Tools Without Getting Sold a Demo
The strongest evaluation framework for AI pentesting tools is boring on purpose. It focuses on operational questions that stay useful after the marketing language fades.
The first question is scope. What is the target domain. A web app. A public API. An internal identity and lateral movement surface. An LLM agent with tools. A hybrid of all of the above. Tools optimized for source-derived API coverage are not necessarily good at post-auth workflow manipulation. Tools optimized for attack-path validation are not necessarily good at testing checkout flow logic. AI red-team frameworks for agents are not built to replace internal network exploitation platforms. Scope sounds obvious, but it is where most category errors start. (StackHawk Documentation)
The second question is state handling. Burp AI’s most practical AI feature set includes authentication setup help, recorded login generation, and Repeater-centric assistance because state is where real web testing gets expensive. Escape’s documentation makes the same point from the autonomous side by dedicating configuration to authentication and by explicitly describing authorization, business logic, and access control coverage. StackHawk’s value also improves when it can discover auth flows from code paths that traffic-based tools might miss. If a vendor talks only about payload generation and never about session continuity, role switching, or state transitions, assume the hard part is still yours. (PortSwigger)
The third question is proof. NodeZero is unusually direct here: it emphasizes proven attack paths, proof of exploit, impact, and simplified fix verification. Pentera makes a related claim from the validation angle by framing its value as proving what is exploitable rather than merely generating alerts. Escape emphasizes evidence-rich reporting with requests, responses, commands, and reasoning. Those are not small wording differences. They are the dividing line between tools that create more triage work and tools that shrink uncertainty. (Horizon3.ai)
The fourth question is governance and data boundaries. Burp says its AI features only run when explicitly activated and that request data is not stored by its AI providers. StackHawk says its OpenAPI generation processes code analysis results rather than raw source code and says customer data is not used to train models. PentestGPT makes local LLM routing a first-class option and documents telemetry opt-out. These are not identical privacy models, but they are all signs that buyers should treat model usage, prompt flow, and hosted versus local inference as real architecture questions, not legal fine print. (PortSwigger)
The fifth question is safety of execution. AI pentesting tools do not just analyze attack surfaces. Many of them execute against them. Escape’s multi-agent workflow runs in a sandbox and documents domain and timeout limits. Hadrian narrows its claim to the external attack surface. Pentera positions itself as validation rather than anything-goes exploitation. That boundedness is good. A tool that promises unrestricted autonomous action with no explicit discussion of blast radius, scoping, or operator control should trigger skepticism, not excitement. (Escape Documentation)
Burp AI Is Best Understood as a Skilled Assistant Inside Burp
Burp AI makes the most sense when you stop expecting it to be a robot pentester. PortSwigger’s documentation describes it as a set of AI-powered features inside Burp Suite that help testers uncover vulnerabilities more efficiently, understand unfamiliar technologies, and streamline authentication setup. Burp is explicit that the features only run when the user activates them. That framing is important because it makes Burp AI closer to a workflow multiplier than to an autonomous engagement engine. (PortSwigger)
That workflow multiplier model is stronger than it sounds. Burp AI’s documented feature set includes Repeater-side prompting, an Explainer for understanding headers, cookies, and JavaScript, broken access control false-positive reduction, AI-generated recorded login sequences, and AI-powered extension capabilities through the Montoya API. In practice, that package addresses exactly the places where skilled testers waste time: understanding unfamiliar request structures, setting up authentication correctly, filtering noisy findings, and extending the tooling without building separate AI plumbing from scratch. (PortSwigger)
The limit is equally clear. Burp AI still sits inside a tester-driven workflow. It does not claim to autonomously plan and run a full multistage engagement at web-and-beyond scope, and its strongest features assume that a human is already navigating an application, deciding what matters, and exercising judgment about impact. That is not a weakness. It is an honest product boundary, and for many AppSec teams it is exactly the right one. But it is why Burp AI should not be treated as interchangeable with tools built for autonomous black-box exploration or continuous external validation. (PortSwigger)
StackHawk Matters Because Coverage Still Breaks Before Exploitation Does
A lot of security teams still lose before testing even starts because their API surface is incompletely documented. That is the problem StackHawk’s OpenAPI Spec Generation is aimed at. The feature is documented as generating OpenAPI specs from connected source repositories so teams can test APIs that would otherwise remain untested. StackHawk says the system analyzes code directly, generates OpenAPI 3.0 specs, and reanalyzes repositories weekly and after API discovery processing to keep them current. It also says this source-code approach can surface endpoints traffic-based approaches miss, including error handlers, authentication flows, and endpoints not yet in production. (StackHawk Documentation)
That is a meaningful capability because missing coverage is one of the quietest reasons pentesting programs underperform. If the test harness never sees the endpoint, it never reaches the authorization edge case or the workflow abuse path behind it. StackHawk does not solve every appsec problem with that feature, but it does solve a real and common one: the gap between code reality and scan reality. Teams with fast-moving APIs, partial specs, or shadow endpoints should treat that as more than a convenience feature. It is a way to move the security conversation earlier and closer to the source of truth. (StackHawk Documentation)
StackHawk’s own configuration model makes the point concrete. Generated specs can be used through hawk:// URIs or with usePlatform: true in stackhawk.yaml, which turns the AI-derived API understanding into actual scan input rather than a passive dashboard artifact. StackHawk also states that the AI feature processes code analysis results rather than raw source code and that customer data is not used for model training, which matters for teams evaluating how much application context they are comfortable exposing to hosted services. (StackHawk Documentation)
app:
openApiConf:
filePaths:
- hawk://<oas-id>
That snippet is small, but the architectural implication is bigger. The tool is converting source-aware discovery into testable API coverage. That makes StackHawk highly relevant for CI-oriented API security teams and much less relevant as a replacement for a deep, adaptive, business-logic-heavy pentest. (StackHawk Documentation)
Escape Shows What Autonomous Black-Box AI Pentesting Actually Looks Like
Escape’s Multi-Agent Pentest documentation is one of the clearest public descriptions of what autonomous application pentesting is supposed to look like when it is treated as more than a chatbot wrapper. Escape describes the feature as an autonomous black-box engine that deploys coordinated agents in a sandboxed environment, with a core agent orchestrating specialized agents for reconnaissance, targeted exploitation, validation, and reporting. That wording matters because it names the real components of a pentest workflow instead of collapsing them into a vague “AI scan.” (Escape Documentation)
The capability list is unusually concrete. Escape says the agents run in a sandbox with classic pentesting tools, a browser, and an HTTP proxy; cover categories including XSS, SQL injection, IDOR and BOLA, SSRF, command injection, access control, and business logic flaws; and produce evidence-rich reporting with requests, responses, commands, and step-by-step reasoning. Those are the right things to emphasize if the goal is to close the gap between a raw finding and something another engineer can verify. (Escape Documentation)
Just as useful is what Escape documents as a limitation. The scan timeout is roughly four hours, agents stay on the configured target domain, coverage depends on what agents can discover and reach, and natural-language instructions do not replace scope or authentication setup. That is the kind of constraint disclosure buyers should want to see. Autonomous testing that pretends time budgets, reachability, and authenticated surface discovery do not exist is not being honest about the job. (Escape Documentation)
automated_pentesting:
multi_agent_pentest:
enabled: true
instructions: |
Focus on the checkout and payment flow. The /api/v2/orders and
/api/v2/payments endpoints are the highest-priority targets.
authentication:
presets:
- type: headers
users:
- username: user@example.com
headers:
Authorization: "Bearer eyJhbGciOiJIUzI1NiJ9..."
That example captures an important truth about AI pentesting tools: the better ones do not eliminate setup. They turn setup into controlled input that guides where expensive autonomous effort should go. A tool that lets you focus the model on a workflow and feed it valid auth is usually more valuable than one that boasts about total autonomy but fails on the first logged-in path. (Escape Documentation)
PentestGPT Still Matters Because Open Workflows Matter
PentestGPT remains important for two different reasons. First, it is backed by real research lineage. Its maintainers cite the USENIX Security 2024 paper, and the public project continues to evolve. Second, the current repository makes its design choices visible: Docker-first deployment, benchmark inclusion, local LLM routing, telemetry disclosure, and command-line usage are all documented rather than hidden behind a marketing site. (USENIX)
The current public repository describes an agentic upgrade with session persistence, a Docker-first environment, and a target-driven CLI. It documents installation through git clone --recurse-submodules, make install, make configund make connect, and then exposes a straightforward runtime model such as pentestgpt --target 10.10.11.234. It also documents local model routing through OpenAI-compatible servers such as LM Studio and Ollama, plus telemetry opt-out via a flag or environment variable. That combination makes PentestGPT especially attractive for researchers, lab operators, and teams that want controllable building blocks instead of a managed platform. (GitHub)
git clone --recurse-submodules https://github.com/GreyDGL/PentestGPT.git
cd PentestGPT
make install
make config
make connect
pentestgpt --target 10.10.11.234
The honest limitation is that open workflows are not the same thing as solved enterprise delivery. PentestGPT’s public materials are strong on reproducibility, experimentation, and operator control, but they do not by themselves promise the same governance, scoping, fix verification, or cross-team delivery model that some commercial platforms emphasize. That is not a criticism of the project. It is what makes it useful: you can see more of the system, which also means you inherit more of the system design burden. (GitHub)
There is also a research reality check worth keeping in mind. The USENIX paper introduced PentestGPT as a framework for automated penetration testing, and subsequent benchmark work continues to show progress in subtask completion. At the same time, newer research still describes fully automated, end-to-end pentesting as an unsolved problem and presents improvements as incremental rather than final. That is exactly why open tools like PentestGPT remain so valuable: they let practitioners inspect where the frontier really is instead of trusting slogans about general autonomy. (USENIX)
NodeZero, Pentera, and Hadrian Solve a Different Layer of the Problem
NodeZero is not best understood as “another AI scanner.” Horizon3.ai’s own platform description emphasizes proven attack paths, step-by-step visibility into those paths, proof of exploit, impact, mitigation guidance, and fix verification. Those are the language of operational security validation, not merely issue discovery. For organizations trying to answer which weaknesses really chain into something breach-worthy, that distinction is more useful than another long list of theoretical findings. (Horizon3.ai)
Pentera sits nearby in spirit but not identically in scope. Pentera’s public material frames the platform around continuous validation that proves what is exploitable, prioritizes real risk, and accelerates remediation. Its ASV explanation is explicit about the gap between point-in-time testing and continuously changing environments, and it contrasts its model against vulnerability assessment, BAS, penetration testing, and external attack surface management. In other words, Pentera is selling certainty and operational relevance more than app-by-app exploratory depth. (Pentera)
Hadrian narrows the lens further toward the public edge. Its current positioning centers on “agentic pentesting across your external attack surface,” with autonomous AI that continuously discovers exposures, validates what attackers can exploit, and delivers pentest-level insights around the clock. That is a strong fit when the dominant problem is internet-facing drift, shadow exposure, or external validation cadence. It is not the same buying decision as choosing a web workflow assistant or an AI application red-team framework. (Hadrian)
Those three products illustrate why the phrase AI pentesting tools is both useful and dangerous. Useful, because they all represent genuine moves from alerting toward exploitability and proof. Dangerous, because a buyer can incorrectly assume that proof-first external or enterprise validation is interchangeable with business-logic-heavy application testing. It is not. Mature teams often need both layers, and sometimes a third layer for AI systems themselves. (Horizon3.ai)
Promptfoo Belongs in This Conversation Because AI Systems Are Targets Too
Promptfoo is the clearest example of a tool that belongs in an AI pentesting article while not being a conventional web pentest platform. Its red teaming documentation says the tool can scan 50-plus vulnerability types, generate dynamic attack probes, integrate with CI and CD, and test through HTTP APIs, browsers, or direct model access. Its configuration model is built around generating adversarial tests against LLM applications, not around discovering forgotten admin panels. That difference is exactly why it matters. (Promptfoo)
Promptfoo’s overview is also sharper than many generic AI security pages. It separates model-layer threats from application-layer threats and names application-layer issues that look familiar to any pentester: indirect prompt injection, PII leakage from context, tool-based vulnerabilities, hijacking, and exfiltration techniques. That is the right frame for AI systems because the failure often does not live in the foundation model alone. It lives in how the system routes tool calls, merges retrieved data, exposes functions, and handles identity or authorization across chained actions. (Promptfoo)
The MCP documentation is where that becomes especially practical. Promptfoo’s MCP Security Testing Guide says MCP’s server-based architecture creates a disconnect between what users see and what models process, which opens the door to tool poisoning, side-channel exfiltration, authentication hijacking, tool shadowing, indirect prompt injection, and cross-server attacks. That is not theoretical hand-waving. It is an operational description of a new attack surface that classic web-only thinking will miss. (Promptfoo)
npx promptfoo@latest redteam setup
promptfoo redteam init
promptfoo redteam run
promptfoo redteam report
targets:
- id: https
label: my-chatbot-v1
config:
url: 'https://api.example.com/chat'
method: 'POST'
headers:
'Content-Type': 'application/json'
body:
message: '{{prompt}}'
redteam:
purpose: |
Customer service chatbot for an e-commerce platform.
Users can ask about orders, returns, and product information.
The bot should not reveal customer data or internal system details.
plugins:
- pii
- prompt-extraction
- hijacking
- rbac
- excessive-agency
strategies:
- jailbreak:meta
- prompt-injection
That is why teams building agents, RAG pipelines, or tool-using assistants should stop asking whether Promptfoo is a “real pentesting tool” in the same sense as Burp or Escape. It is solving a different but increasingly essential class of offensive testing. If your production risk lives in tool permissions, model instructions, MCP descriptions, or retrieval boundaries, Promptfoo is often more directly relevant than a general web scanner with AI features. (Promptfoo)
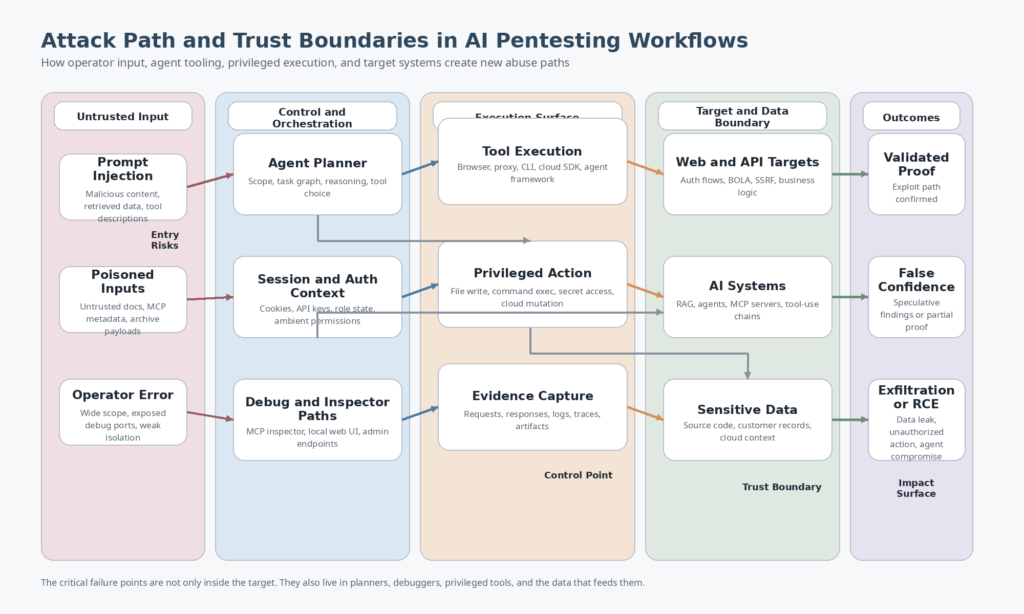
The Toolchain Itself Is Now an Attack Surface
One of the least mature parts of the AI pentesting conversation is how rarely people discuss the security posture of the tools, agents, MCP components, and orchestration frameworks themselves. That blind spot is getting harder to justify because the vulnerability record is no longer hypothetical. Recent CVEs affecting AI development kits, MCP tooling, and multi-agent frameworks show that offensive and agentic security stacks can introduce exactly the kinds of dangerous flaws security teams would condemn anywhere else. (GitHub)
| CVE | Komponente | Warum das hier wichtig ist | Fix or mitigation |
|---|---|---|---|
| CVE-2025-2867 | GitLab Duo with Amazon Q | A crafted issue could manipulate AI-assisted development features and potentially expose sensitive project data, which makes it a concrete example of AI-assisted workflow boundaries failing under adversarial input. (NVD) | Upgrade from affected GitLab 17.8, 17.9, and 17.10 branches to the patched releases listed in the advisory. (NVD) |
| CVE-2026-23744 | MCPJam inspector | The inspector reportedly listened on 0.0.0.0 by default and exposed a route that could lead to remote code execution, which is exactly the kind of “local tooling becomes remote attack surface” failure AI operators should worry about. (NVD) | Upgrade to 1.4.3 and do not expose debugging or inspector interfaces beyond the trusted host boundary. (NVD) |
| CVE-2026-4810 | Google ADK | The advisory describes unauthenticated remote code execution on hosted ADK instances, a reminder that agent frameworks are privileged software, not neutral middleware. (GitHub) | Upgrade to 1.28.1 or 2.0.0a2 and redeploy updated production environments. (GitHub) |
| CVE-2026-39305 | PraisonAI Action Orchestrator | Path traversal in an action orchestrator means a compromised agent or malicious input can break workspace boundaries and write arbitrary files. (GitHub) | GitHub’s advisory lists 4.5.113 as patched, while NVD currently shows 1.5.113, so verify the project’s actual release lineage before automating remediation. (GitHub) |
| CVE-2026-39306 | PraisonAI recipe registry pull flow | Unsafe archive extraction in recipe pull is a supply-chain-shaped failure inside an agent framework, not just a generic bug. (GitHub) | Upgrade to a patched release and treat recipe and template ingestion as hostile input until verified. (GitHub) |
| CVE-2026-5059 | aws-mcp | The advisory describes unauthenticated command injection RCE in aws-mcp, which is especially serious because cloud tooling often runs with powerful ambient permissions. (GitHub) | No patched version was listed in the advisory at publication time, so containment, isolation, and exposure reduction matter immediately. (GitHub) |
Each of those flaws teaches a different lesson. GitLab Duo is about data boundary failure inside AI-assisted developer workflows. MCPJam is about development and debugging interfaces becoming remotely reachable. Google ADK is about unauthenticated execution paths in agent frameworks. PraisonAI is about workspace boundary failure and supply chain ingestion. aws-mcp is about the compounded danger of command execution in cloud-connected tooling. Put differently, the systems used to automate testing now need testing with the same seriousness as the systems they target. (GitHub)
That is also why AI application red teaming and AI-assisted pentesting should not be organizationally isolated from each other. The people evaluating whether an AI workflow can attack a target should also be thinking about whether the AI workflow can be attacked. The hard part is not adding more AI. The hard part is preserving boundaries when the software is allowed to reason, call tools, consume external instructions, and operate with privileged context. OWASP’s agentic work and Promptfoo’s MCP material both point in the same direction on this: the interface between instructions, tools, and identity is where much of the new risk lives. (OWASP Gen AI Sicherheitsprojekt)
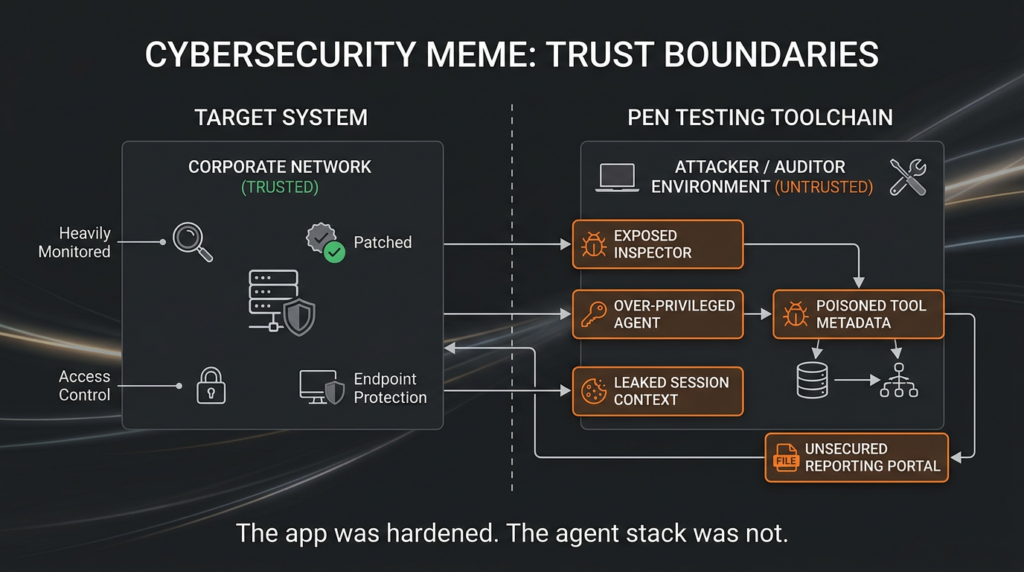
What Current AI Pentesting Tools Still Break On
The field is moving quickly, but some failure modes remain stubborn. Authentication-heavy multistep workflows are still hard. Tools can identify the login page and still fail the real test if the application depends on role transitions, post-login branching, nonces, or sequential business actions. Escape’s documentation is strong precisely because it admits discovery and reachability limits and makes authentication a first-class input. Burp AI is useful precisely because it stays near a human operator who can correct drift when the workflow gets weird. (Escape Documentation)
Business logic remains even harder than payload-class testing. OWASP’s API material makes clear that authorization defects and object-level logic problems are central risks, not edge cases. Tools that mostly shine on reflected XSS, classic SQLi, or parameter mutation can still fall apart when the vulnerability depends on workflow sequence, entitlement mismatch, or abuse of ordinary features rather than obviously malformed inputs. This is why the best product pages now emphasize access control, business logic, path proof, or exploit validation instead of listing only scanner-style categories. (OWASP-Stiftung)
The other persistent failure mode is misplaced confidence. AI can make tools feel articulate long before they become reliable. A beautifully worded explanation of a request is not a validated finding. A long chat transcript is not an audit trail. A suggested exploit path is not proof. That burden of proof still lives in reproducible requests, captured responses, bounded execution, and retest. The strongest public materials in the market increasingly converge on that point, which is a good sign. But users still need to enforce it. (Sträflich)
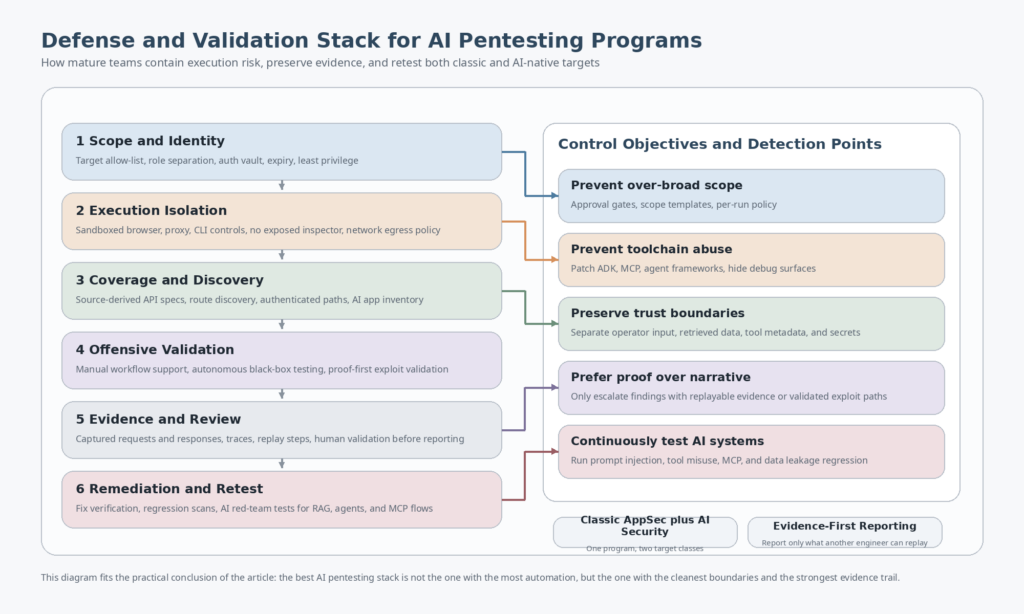
A Practical Way to Combine AI Pentesting Tools Without Buying Into Hype
The most effective operating model today is layered rather than monolithic. Use a workflow assistant when the human still adds the most value per minute. Use source-aware coverage tooling when the biggest problem is API visibility. Use autonomous black-box testing where auth, business logic, and exploit validation can be profitably delegated inside clear bounds. Use proof-first validation to find what truly matters across the broader environment. Use AI red teaming when the target itself is an AI system with tools, retrieval, or agent logic. That layered model sounds less glamorous than “one AI hacker to rule them all,” but it maps better to how real security programs work. (PortSwigger)
This is also the place where orchestration-first platforms make sense. Some teams do not want another point product. They want a system that sits between discovery, verification, tool execution, and report export. Penligent’s public pricing and product pages describe that shape directly: end-to-end AI pentesting from asset discovery to validation, automated asset profiling and attack surface mapping, on-demand access to 200-plus pentest tools, and exportable PDF or Markdown reports with evidence and reproduction steps. Whether that exact product shape is right for a given team depends on trust, workflow fit, and governance requirements, but it is a more meaningful product thesis than generic “AI-powered security” language. (Sträflich)
The same reasoning applies to reporting. Security teams do not need chatty output. They need evidence that survives retest. Penligent’s own reporting-focused writing makes the right point here: the problem is not “make AI write a PDF,” but turning testing evidence into something another engineer can verify and act on. That is consistent with the broader market direction toward proof, impact, and reproducibility. Any platform that cannot narrow the gap between finding and replayable evidence will eventually create more meetings than security value. (Sträflich)
Which AI Pentesting Tools Deserve Attention for Which Job
If your center of gravity is hands-on web application testing and you already live in Burp, Burp AI deserves attention because it improves the places where skilled humans actually lose time: understanding opaque requests, setting up auth, triaging access-control noise, and extending the platform without external glue. It is not pretending to be a full autonomous engagement platform, and that honesty is part of its strength. (PortSwigger)
If your main problem is API coverage in CI and code-to-runtime visibility, StackHawk is one of the more practically differentiated offerings because its AI layer addresses the documentation gap directly. Teams with fast-moving APIs and partial specs should take that seriously. Coverage is boring until you realize how many testing programs never reach the endpoints that matter. (StackHawk Documentation)
If your team wants autonomous black-box web and API testing that still looks recognizably like penetration testing, Escape is one of the clearest public examples of the category done seriously. Its multi-agent architecture, auth-aware configuration, business-logic coverage, and evidence-rich reporting are closer to what practitioners mean when they say they want an AI pentester. (Escape Documentation)
If you want open, inspectable workflows and are comfortable owning more of the stack yourself, PentestGPT still deserves a place on the shortlist. Its research lineage and Docker-first, local-model-capable workflow make it one of the most instructive ways to understand what AI-assisted pentesting can and cannot do today. (GitHub)
If your primary concern is “what is actually exploitable in my environment right now,” the conversation shifts toward NodeZero, Pentera, and Hadrian, depending on whether the center of gravity is broader attack-path proof, continuous validation, or external edge exposure. That is not a downgrade from “real pentesting.” It is a different operational question, and sometimes the more important one. (Horizon3.ai)
If the target is an AI system, especially one with retrieval, agents, or MCP servers, Promptfoo belongs much higher on the shortlist than many generic AI pentest tools. Once the risk surface becomes prompt routing, tool descriptions, authorization drift inside agent actions, or exfiltration through multi-turn interactions, classic web thinking alone is not enough. (Promptfoo)
The strongest conclusion is not that one vendor has already won. It is that proof now matters more than novelty. The tools worth taking seriously in 2026 are the ones that shorten the distance between raw signal and evidence another engineer can trust, whether that evidence comes from a Repeater workflow, source-derived API coverage, an autonomous black-box agent, an attack-path validator, or an AI red-team harness. The hype cycle will keep flattening these categories into one phrase. Your evaluation process should not. (Horizon3.ai)
Related Reading and References
For the baseline definitions and testing scope, start with NIST SP 800-115, the NIST definition of AI red teaming, OWASP’s Web Security Testing Guide, OWASP’s API Security Project, and the OWASP AI Testing Guide. These are still the cleanest way to separate app pentesting from AI system testing. (NIST-Ressourcenzentrum für Computersicherheit)
For product documentation, the most useful primary sources are PortSwigger’s Burp AI documentation, StackHawk’s OpenAPI Spec Generation docs, Escape’s Multi-Agent Pentest docs, Horizon3.ai’s NodeZero platform material, Pentera’s validation model, Hadrian’s public platform positioning, Promptfoo’s red team docs and MCP guide, and the PentestGPT repository plus its USENIX paper. Those documents do a much better job than generic roundups of revealing what each tool actually thinks its job is. (PortSwigger)
For Penligent pages that are genuinely relevant to this topic, the most useful ones are AI Pentester in 2026 How to Test AI Systems Without Confusing the Two, How to Get an AI Pentest Reportund AI Pentest Tool, wie eine echte automatisierte Offensive im Jahr 2026 aussehen wird. The homepage and pricing page are also relevant if you are specifically evaluating orchestration-first offensive workflows rather than a single testing layer. (Sträflich)
