Security teams do not buy vulnerability discovery because a model can write clever payloads or because an agent can run a long list of tools. They buy it because they need real weaknesses found, verified, explained, fixed, and retested before attackers turn them into incidents. The business question is not whether an AI system can produce findings. The business question is how much it costs to produce one finding that a serious security team can trust.
That is the point of cost per validated vulnerability.
The term borrows its logic from industries that already think in unit economics. In autonomous trucking, cost per mile is not a slogan about whether the truck can drive itself. It is a hard operating metric. It includes fuel or energy, maintenance, insurance, vehicle depreciation, remote supervision, routing, downtime, safety interventions, and delivery reliability. A system only becomes economically superior when the real cost of moving freight falls while safety and service quality stay acceptable.
Security needs the same discipline. A vulnerability program does not become better because it creates more tickets. It becomes better when the cost of producing each true, reproducible, useful vulnerability goes down without lowering quality, scope control, evidence standards, or safety. AI can help, but only if it changes the whole workflow: asset understanding, hypothesis generation, tool execution, validation, evidence capture, reporting, and retesting.
A scanner that creates 500 low-confidence findings may increase operating cost. A model that writes plausible but untested exploit narratives may increase review cost. A human tester who spends two days proving one critical business logic flaw may be worth every dollar. The right metric has to reward validated security outcomes, not noise.
What the metric actually means
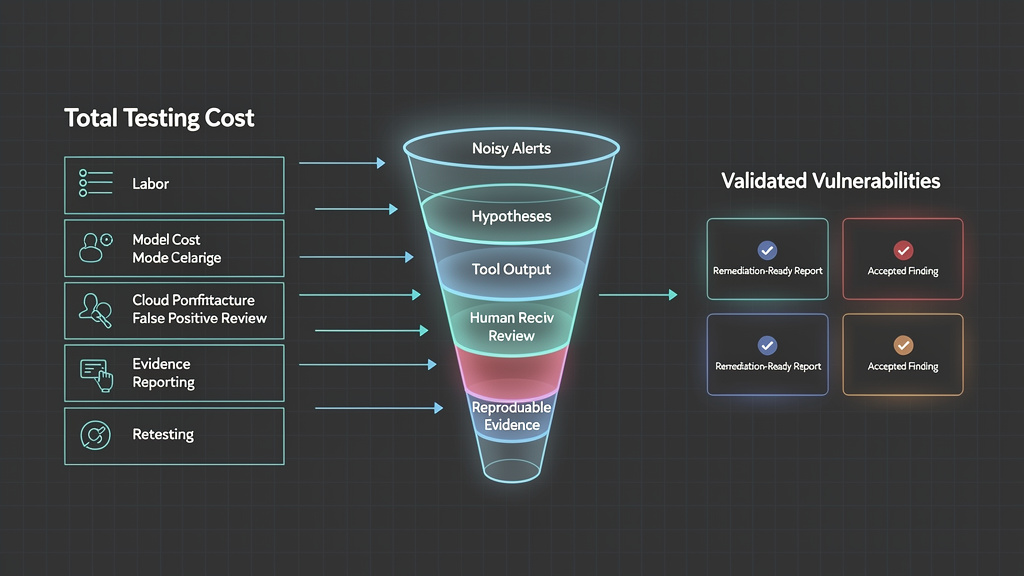
Cost per validated vulnerability is the total cost of an authorized security testing workflow divided by the number of vulnerabilities that survive technical validation and are accepted as useful by the receiving team.
A simple version looks like this:
cost per validated vulnerability = total testing cost / accepted validated vulnerabilities
The numerator should not be limited to tool license fees or model tokens. In a real program, total testing cost includes scope setup, asset discovery, engineer time, tool execution, model calls, cloud infrastructure, proxy capture, test environment preparation, false positive review, evidence collection, report writing, remediation support, retesting, and the cost of failed attempts. The denominator should not be every scanner alert. It should be the number of findings that meet an agreed validation standard.
A validated vulnerability should usually meet these conditions:
| Anforderung | Warum das wichtig ist |
|---|---|
| The issue is reproducible | Another tester or developer can follow the evidence and see the same security behavior. |
| The affected asset is in scope | The finding does not create legal, contractual, or operational risk by crossing boundaries. |
| The vulnerable condition is technically explained | The report identifies the broken control, not just a symptom. |
| The impact is clear | The receiving team understands what an attacker could gain. |
| The evidence is safe and sufficient | Proof does not rely on destructive actions or data exposure beyond the rules of engagement. |
| The fix path is actionable | Developers, infrastructure owners, or security teams can take a concrete next step. |
| Retesting is possible | The same workflow can confirm whether remediation worked. |
That last point is often ignored. If a finding cannot be retested without reinventing the investigation, the true cost is higher than it looks. A cheap bug report with weak evidence becomes expensive when engineers spend hours reconstructing what happened.
A noisy finding is different. It may be a suspicious response, an outdated banner, a generic CVE match, an unconfirmed scanner signature, a model guess, or a theoretical weakness with no demonstrated path. Those signals can still be useful, but they should not count as validated vulnerabilities until they survive controlled verification.
| Signal type | Useful as input | Counts as validated | Typical hidden cost |
|---|---|---|---|
| Scanner alert based only on version match | Ja | Nein | Manual reachability review |
| LLM-generated vulnerability hypothesis | Ja | Nein | False reasoning and test design |
| Crash without root-cause analysis | Ja | Usually no | Triage, minimization, deduplication |
| Reproducible IDOR across two authorized test accounts | Ja | Ja | Evidence packaging and fix mapping |
| Safe proof of SSRF with controlled callback evidence | Ja | Ja | Boundary analysis and mitigation design |
| Confirmed KEV exposure on a public-facing asset | Ja | Yes, if reachable in the environment | Urgent remediation and incident review |
This distinction matters because vulnerability discovery is full of partial truth. A version string can be true while the vulnerable code path is unreachable. A model can correctly describe a class of bug while being wrong about the target. A crash can be real while not being exploitable. A penetration test can find a serious flaw that no commercial scanner would ever flag. Unit economics only become meaningful when the denominator is honest.
Why vulnerability counts are a bad scoreboard
Counting findings is tempting because it is easy. It is also one of the fastest ways to make a security program worse.
A team that rewards total finding count will tend to produce more low-value output: duplicate CVEs, informational issues, best-practice warnings, unverified headers, theoretical risks, and alerts that developers have already accepted or mitigated elsewhere. That looks productive in a dashboard. It feels different when an application team has to triage it.
Severity scores help, but they do not solve the problem by themselves. The Common Vulnerability Scoring System gives the industry a shared way to describe severity characteristics, and CVSS v4.0 includes exploitability metrics intended to reflect the ease and technical means of exploitation. NVD’s own guidance is careful, though: CVSS provides a qualitative severity measure, not a complete measure of risk. A vulnerability’s real priority still depends on exposure, asset value, compensating controls, exploit availability, business context, and whether the vulnerable path exists in your environment. (FIRST)
CISA’s Known Exploited Vulnerabilities catalog adds another useful signal because it focuses on vulnerabilities known to be exploited in the wild. CISA describes the catalog as a resource to help organizations manage vulnerabilities and keep pace with threat activity. That is a better prioritization input than severity alone, especially for internet-facing systems and edge devices. (CISA)
OWASP’s Web Security Testing Guide is also relevant because it frames web testing as a structured discipline rather than a pile of tool output. OWASP describes the WSTG as a comprehensive guide for testing web applications and web services, built by cybersecurity professionals and used by penetration testers and organizations. A cost metric should not replace that kind of methodology. It should measure whether the methodology produces validated outcomes efficiently. (OWASP-Stiftung)
The failure mode is clear: if a program measures only count and severity, it may optimize for volume. If it measures cost per validated vulnerability, it has to optimize for signal.
| Metrisch | What it measures well | Where it fails | Better use |
|---|---|---|---|
| Total findings | Output volume | Rewards noise and duplicates | Early scanner health, backlog size |
| Critical findings | Potential severity | May ignore reachability and exposure | Initial triage and escalation |
| CVSS score | Standardized severity characteristics | Not a complete risk measure | Cross-team communication |
| KEV-Status | Known exploitation signal | Does not prove your asset is affected | Urgent validation priority |
| Time to report | Delivery speed | Can reward shallow testing | Workflow efficiency |
| Cost per validated vulnerability | Economic efficiency of real findings | Requires disciplined validation criteria | Program-level optimization |
Cost per validated vulnerability is not a replacement for severity, exploitability, or threat intelligence. It is the economic layer that sits above them. It asks whether your security process converts time, tools, models, and human expertise into validated risk reduction at a competitive cost.
Why AI changes the economics, but not by magic
AI changes security testing because it compresses several expensive tasks. A good model can read documentation quickly, summarize code paths, explain unfamiliar frameworks, draft test plans, generate safe proof scripts, parse tool output, compare HTTP responses, and help prepare reports. An agentic system can go further by preserving state, selecting tools, executing tests, checking results, and iterating on hypotheses.
The field is moving fast. DARPA’s AI Cyber Challenge brought together AI and cybersecurity experts to build systems intended to safeguard critical software, and DARPA later reported that teams’ AI-driven systems found and patched real-world cyber vulnerabilities, with open-source releases for broader adoption. A 2026 systematization paper describes AIxCC as the largest competition to date for fully autonomous cyber reasoning systems that use AI, especially LLMs, to discover and remediate vulnerabilities in real-world open-source software. (AI Cyber Challenge)
Google’s Project Zero and DeepMind work on Big Sleep is another important marker. In late 2024, Google described a real-world vulnerability discovered by the Big Sleep agent: an exploitable stack buffer underflow in SQLite that was reported and fixed before it appeared in an official release, so users were not affected. Google later described Big Sleep as an AI agent that actively searches for unknown security vulnerabilities in software. (Google Projekt Zero)
Continuous fuzzing shows the non-LLM side of the same economic trend. OSS-Fuzz aims to improve open-source security and stability by combining modern fuzzing techniques with scalable, distributed execution. Research on OSS-Fuzz has studied tens of thousands of bugs across hundreds of projects, and newer work has analyzed more than a million fuzzing sessions to understand how continuous fuzzing contributes to vulnerability detection. (GitHub)
These examples do not prove that every AI pentesting product is economically superior. They prove something narrower and more useful: automation can shift where the cost sits. Manual reading becomes assisted analysis. One-off testing becomes repeatable workflow. A single tester’s attention can be focused on judgment, scope, exploitability, and risk instead of repetitive parsing and formatting.
But AI can also raise costs. Model calls can be wasted on broad exploration. Agents can loop. Tool output can be misread. Hallucinated conclusions can create review debt. Context windows can fill with irrelevant artifacts. Poorly designed systems can run unsafe tests, violate scope, or generate reports that look polished but do not stand up to engineering review.
That is why cost per validated vulnerability is a better metric than “AI used” or “tools called.” It forces the question back to results. Did the system reduce the cost of reaching a verified outcome, or did it only move the cost from execution to review?
A practical cost model for security teams
A useful cost model should be simple enough to run every week and detailed enough to guide decisions. The goal is not accounting perfection. The goal is to expose waste.
A basic model can start with these components:
| Cost component | How to measure it | Common waste source | Optimization path |
|---|---|---|---|
| Scope setup | Hours spent defining targets, accounts, exclusions, rules | Ambiguous authorization | Reusable scope templates |
| Asset discovery | Tool time plus human review | Repeated enumeration without context | Asset inventory integration |
| Hypothesenbildung | Model spend and analyst time | Generic vulnerability guessing | Threat-informed targeting |
| Testing execution | Tool runtime, cloud cost, agent time | Repeated low-signal scans | Prioritized test plans |
| Validierung | Engineer minutes per finding | Weak evidence and unclear reproduction | Standard proof criteria |
| False positive review | Rejected finding count times review minutes | Version-only matches | Reachability and exploitability checks |
| Verpackung von Beweismitteln | Time to prepare screenshots, logs, commands, traces | Unstructured notes | Evidence schema |
| Reporting | Writing and editing time | Rewriting from scratch | Report-ready finding templates |
| Retesting | Time to confirm fixes | Missing reproduction steps | Replayable commands |
| Failed attempts | Time and model spend that produced no accepted finding | Agent loops and broad exploration | Negative evidence tracking |
Here is a small Python model that a security team could adapt for internal reporting. It is deliberately plain. The value is not in the code; the value is in forcing the team to name the cost drivers.
from dataclasses import dataclass
@dataclass
class TestingRun:
engineer_hours: float
blended_hourly_rate: float
model_cost: float
cloud_cost: float
tool_cost: float
false_positive_review_hours: float
reporting_hours: float
retest_hours: float
validated_findings: int
def total_cost(self) -> float:
labor_hours = (
self.engineer_hours
+ self.false_positive_review_hours
+ self.reporting_hours
+ self.retest_hours
)
labor_cost = labor_hours * self.blended_hourly_rate
return labor_cost + self.model_cost + self.cloud_cost + self.tool_cost
def cost_per_validated_vulnerability(self) -> float:
if self.validated_findings <= 0:
return float("inf")
return self.total_cost() / self.validated_findings
run = TestingRun(
engineer_hours=18,
blended_hourly_rate=150,
model_cost=220,
cloud_cost=80,
tool_cost=300,
false_positive_review_hours=5,
reporting_hours=4,
retest_hours=3,
validated_findings=6,
)
print(f"Total cost: ${run.total_cost():,.2f}")
print(
"Cost per validated vulnerability: "
f"${run.cost_per_validated_vulnerability():,.2f}"
)
This calculation is intentionally conservative because it includes the work that many teams hide: false positive review, reporting, and retesting. If those are excluded, the metric becomes a vanity number.
For a more mature program, the denominator can be split:
| Metrisch | Formula | Warum das wichtig ist |
|---|---|---|
| Cost per first validated finding | Total run cost until first accepted finding | Measures time-to-value |
| Cost per high-impact validated finding | Total run cost divided by accepted high-impact findings | Prevents optimization for trivial bugs |
| Cost per report-ready finding | Total run cost divided by findings with complete evidence | Connects testing to delivery |
| Cost per retested fix | Retest cost divided by fixes verified | Measures remediation loop efficiency |
| Human minutes per accepted finding | Human review and validation minutes divided by accepted findings | Shows how much expert attention is still required |
| False positive cost | Rejected findings multiplied by average review cost | Makes noise visible |
| Coverage per dollar | Assets, endpoints, flows, or code paths tested divided by cost | Helps compare workflows |
The best version of the metric is not a single number. It is a dashboard of economic pressure. If cost per validated vulnerability is high because no findings were accepted, the team needs to know whether the cause was hardened assets, weak testing, poor scope, tool failure, or unrealistic acceptance criteria. If cost is low because the team found many low-risk issues, the metric needs severity or impact segmentation. If AI model cost is low but human review cost is high, the workflow is probably generating too much ambiguity.
The validation loop that separates signal from noise
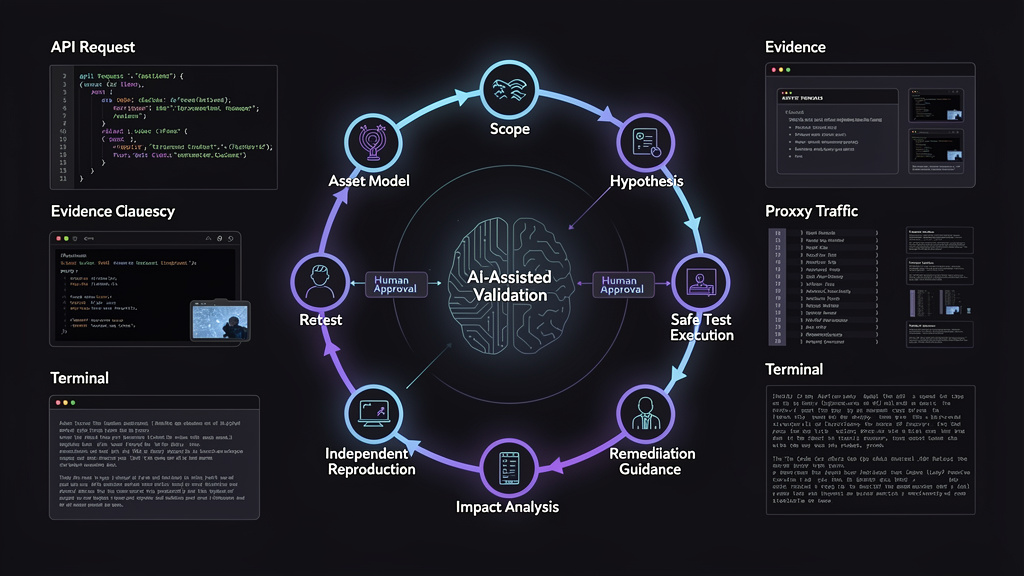
The validation loop is the heart of the metric. Without it, cost per validated vulnerability collapses into cost per alert.
A mature loop looks like this:
- Define authorization and test boundaries.
- Build a target model from assets, roles, endpoints, versions, APIs, identities, and data flows.
- Generate hypotheses tied to specific controls or attack paths.
- Select tests that can confirm or reject each hypothesis safely.
- Execute tools or manual steps with logging enabled.
- Capture positive and negative evidence.
- Reproduce the result independently.
- Explain impact and exploit conditions.
- Map the issue to remediation.
- Retest after a fix.
This loop is especially important when AI is involved. A model can produce an elegant explanation that is wrong. A tool can produce a true signal that is misinterpreted. An agent can run many steps without proving the thing that matters. Validation turns activity into evidence.
Consider server-side request forgery. A weak report says, “The endpoint may be vulnerable to SSRF because a URL parameter is accepted.” A validated report shows that an authorized test endpoint caused a controlled outbound interaction to a callback domain, explains which protocols and destinations were reachable, confirms whether cloud metadata was blocked, states rate limits and scope constraints, and includes safe reproduction steps. That report costs more to produce than a guess, but far less to remediate than a vague ticket.
Consider IDOR. A weak report says, “Changing the ID returns data.” A validated report uses at least two authorized test identities, proves cross-tenant or cross-user access, captures request and response differences, rules out caching artifacts, states the object type, and explains the missing authorization check. That evidence gives developers a direct path to fix.
Consider remote code execution. A safe validation workflow should avoid destructive commands on production systems. It may use a controlled canary, a sandbox, a non-sensitive environment, a harmless command, or a vendor-recommended verification method. The goal is to prove control without causing harm. Lower cost cannot mean reckless proof.
A structured record helps agents and humans preserve context:
finding:
id: "WEB-IDOR-2026-041"
status: "validated"
asset: "https://app.example.com/api/invoices/{invoice_id}"
scope_reference: "ROE-2026-Q2-WebApp"
hypothesis: "User-level authorization is missing on invoice object retrieval."
validation:
tester_accounts:
- "user_a@example.test"
- "user_b@example.test"
positive_evidence:
- "User A can retrieve User B invoice metadata by changing invoice_id."
- "Response includes invoice owner, amount, and billing period."
negative_evidence:
- "Access is blocked when invoice_id is malformed."
- "Admin-only endpoint was not tested because it is out of scope."
reproduction:
safe: true
steps:
- "Authenticate as User A."
- "Request User A invoice endpoint and capture a valid invoice_id."
- "Replace invoice_id with User B invoice_id from authorized test fixture."
- "Confirm HTTP 200 and cross-user invoice data in response."
impact:
summary: "Unauthorized user can read another user's invoice metadata."
affected_data: "Invoice metadata in test tenant"
destructive_actions: "None"
remediation:
owner: "Billing API team"
recommendation: "Enforce object-level authorization before invoice retrieval."
retest:
command: "python tests/retest_idor_invoice.py --env staging"
expected_result: "HTTP 403 for cross-user invoice access"
This format is not just paperwork. It reduces future cost. The next tester can replay the finding. The developer can understand the broken control. The manager can see impact. The retest can be automated. The agent can avoid repeating failed branches.
Evidence standards also make false positives cheaper to eliminate. A team can decide that a finding does not count unless it has reproduction steps, impact, affected asset, proof boundary, and remediation owner. That standard may reduce the number of accepted findings, but it raises trust and lowers the downstream cost of every accepted item.
What real incidents teach about validation cost
Major vulnerabilities show why validation cost is not academic. In real environments, knowing that a CVE exists is only the beginning. The hard work is proving whether your assets are affected, reachable, exploitable, mitigated, monitored, or already compromised.
| CVE | Why it matters to the metric | Validation focus | Cost driver |
|---|---|---|---|
| CVE-2021-44228, Log4Shell | A critical RCE in a widely used logging library forced teams to find vulnerable usage across complex software estates. | Affected Log4j versions, reachable logging paths, mitigations, outbound controls. | Asset inventory gaps and transitive dependencies. |
| CVE-2023-34362, MOVEit Transfer | A public-facing managed file transfer vulnerability was exploited by Cl0p and tied to SQL injection and unauthorized database access. | Internet exposure, affected versions, compromise indicators, data access paths. | Urgency, incident response overlap, third-party exposure. |
| CVE-2023-4966, CitrixBleed | A NetScaler ADC and Gateway vulnerability was actively exploited and tied to session compromise risk. | Appliance exposure, patch status, session invalidation, log review. | Edge device criticality and limited telemetry. |
| CVE-2024-3094, XZ Utils | A supply chain backdoor showed that not every critical issue is found by standard black-box scanning. | Package versions, distribution exposure, build provenance, binary integrity. | Dependency visibility and supply chain investigation. |
Log4Shell is the classic lesson. CISA described CVE-2021-44228 as a critical remote code execution vulnerability in Apache Log4j versions 2.0-beta9 through 2.14.1, and NVD notes that it appears in CISA’s Known Exploited Vulnerabilities catalog. For defenders, the cost was not only patching a library. It was finding where Log4j existed, where vulnerable code paths were reachable, where mitigations were incomplete, and where exploitation might have already happened. (CISA)
MOVEit Transfer showed another pattern. CISA’s advisory states that the Cl0p ransomware group exploited CVE-2023-34362, a zero-day affecting MOVEit Transfer, and NVD describes the issue as a SQL injection vulnerability that could allow an unauthenticated attacker to gain access to the MOVEit Transfer database. In a case like that, validation is not a casual scan. Public exposure, affected version, exploitation evidence, data access, and incident response all collapse into the same urgent workflow. (CISA)
CitrixBleed shows why edge devices deserve special treatment. CISA and partners responded to active, targeted exploitation of CVE-2023-4966 affecting Citrix NetScaler ADC and Gateway. NVD also marks CVE-2023-4966 as present in CISA’s Known Exploited Vulnerabilities catalog. For defenders, the practical work includes patch status, session token exposure risk, session invalidation, and review of authentication anomalies. The cost of validation is high because the affected systems often sit at the boundary between the internet and privileged enterprise access. (CISA)
XZ Utils is different. CISA warned that malicious code was embedded in XZ Utils versions 5.6.0 and 5.6.1, and NVD describes complex obfuscation in upstream tarballs that modified liblzma during the build process. That is not the kind of problem a basic external scanner can fully validate. The verification burden shifts toward software supply chain controls: package inventory, distribution versions, build artifacts, provenance, and dependency review. (CISA)
These cases point to the same conclusion. The highest-value work is not always finding a new bug from scratch. Sometimes it is proving that a known exploited vulnerability is reachable in a specific environment. Sometimes it is proving that a severe CVE is not exploitable because the vulnerable path is absent. Sometimes it is proving that a fix actually removed the risk. A good cost metric should reward all three when they produce useful security decisions.
LLM prompts are not the workflow
A single LLM prompt is not a vulnerability discovery program. It is a reasoning step.
That distinction matters because the market often collapses “AI security” into one blurry category. There are LLM assistants, code review tools, scanners with AI summaries, autonomous cyber reasoning systems, fuzzing systems, browser agents, exploit generation tools, and human-in-the-loop pentest platforms. Their economics are different.
A prompt-only workflow is cheap to start but expensive to trust. It can produce test ideas, explain CVEs, write scripts, and summarize logs. It cannot by itself prove that a target is vulnerable. A scanner-only workflow is repeatable and often fast, but it may lack business context, identity context, and exploitability judgment. A human-only workflow can produce high-quality findings, but senior tester time is scarce and expensive. An agent-assisted workflow can be powerful when it combines state, tools, evidence, and approval gates.
| Arbeitsablauf | Stärke | Schwäche | Cost pattern |
|---|---|---|---|
| LLM-only | Fast reasoning, explanation, script drafting | No native proof, hallucination risk | Low direct cost, high review cost |
| Scanner-only | Repeatable coverage and known checks | Noise, weak context, limited logic testing | Predictable tool cost, variable triage cost |
| Nur für Menschen | Judgment, creativity, business logic insight | Limited scale, expensive expert time | High labor cost, high signal when scoped well |
| Agent-assisted | Iteration, tool use, evidence capture, repeatability | System design complexity, safety requirements | Can reduce cost if validation is disciplined |
The key phrase is “if validation is disciplined.” Without that, an agent can become a faster noise generator. With it, an agent can lower cost by doing the repetitive work around expert judgment: collecting context, executing safe tests, preserving output, comparing responses, drafting reproduction steps, and retesting fixes.
This is where security buyers should be precise. Ask whether the system can preserve state across a test. Ask whether it records negative evidence. Ask whether it can replay a proof. Ask whether it distinguishes suspected, confirmed, accepted, and remediated findings. Ask whether it has approval gates before high-risk actions. Ask how it handles credentials and data. Ask how it reports uncertainty.
A model that “knows security” is not enough. The system around it must turn security reasoning into a controlled workflow.
Lower cost cannot mean lower control
Cost pressure can make security testing dangerous if teams optimize the wrong thing. A cheap unauthorized scan is not a good security outcome. A fast destructive proof is not a mature validation. A model that ignores scope is not efficient; it is a liability.
Authorized testing needs explicit boundaries. The rules of engagement should define target assets, allowed accounts, test windows, rate limits, excluded systems, third-party dependencies, data handling, escalation paths, destructive test limits, and reporting recipients. For AI-assisted testing, those rules should be machine-readable when possible so the agent can use them as execution constraints rather than after-the-fact policy text.
NIST’s Secure Software Development Framework is relevant because it frames vulnerability reduction as part of the software development life cycle, not as a one-time external event. NIST SP 800-218 gives recommendations for mitigating the risk of software vulnerabilities through secure development practices. Cost per validated vulnerability should connect to that lifecycle: the output of testing should feed design, coding, review, deployment, monitoring, and remediation. (NIST-Ressourcenzentrum für Computersicherheit)
A controlled AI testing workflow should include:
| Kontrolle | Practical purpose |
|---|---|
| Durchsetzung des Geltungsbereichs | Prevents testing outside authorized targets. |
| Rate limits | Reduces operational impact and avoids accidental denial of service. |
| Approval gates | Requires human review before sensitive actions. |
| Credential boundaries | Prevents reuse, leakage, or privilege escalation beyond test accounts. |
| Safe payload library | Avoids destructive commands and unsafe proof methods. |
| Data minimization | Keeps evidence sufficient without collecting unnecessary sensitive data. |
| Audit logs | Makes every action reviewable after the test. |
| Retest workflow | Confirms fixes without restarting from zero. |
This is also why evidence-driven AI pentesting is a better frame than fully unsupervised offense. Tools can automate steps, but responsibility remains with the organization running the test. Penligent’s public materials describe an AI-powered penetration testing tool aimed at finding, exploiting, verifying, and reporting issues with human-in-the-loop control, and its own article on using AI for pentesting emphasizes starting with authorization, scope, evidence, and control rather than payload generation. In workflows where teams are already doing authorized AI-assisted validation, that kind of framing is closer to the economics that matter: less time lost to setup and reporting, but not less control over what gets tested. (Sträflich)
The safest way to lower cost is not to let agents do anything they want. It is to make the allowed workflow easier, faster, more repeatable, and better documented than the unsafe one.
Metrics that actually help operators
A serious security team should track cost per validated vulnerability, but not alone. A single number can hide too much. The better approach is to instrument the workflow.
At minimum, each test run should record:
| Feld | Beispiel |
|---|---|
| Run ID | webapp-q2-authz-2026-07 |
| Scope size | 3 domains, 14 APIs, 5 roles |
| Test type | Web, API, CVE validation, business logic |
| Tool calls | 184 |
| Model spend | 67 dollars |
| Human validation time | 9.5 hours |
| False positives rejected | 18 |
| Validated findings | 5 |
| Accepted findings | 4 |
| Zeit bis zum ersten validierten Befund | 3.2 hours |
| Time to report-ready evidence | 21 hours |
| Retest pass rate | 75 percent |
| Findings reopened | 1 |
The difference between validated and accepted matters. A security tester may validate a real issue, but the receiving team may reject it because it is out of scope, already known, mitigated by design, or below the current risk threshold. Those rejected findings should still teach the program something. They may indicate scope mismatch, duplicate testing, or poor prioritization.
A simple SQL schema can support weekly reporting:
CREATE TABLE security_test_runs (
run_id TEXT PRIMARY KEY,
started_at TIMESTAMP NOT NULL,
finished_at TIMESTAMP,
test_type TEXT NOT NULL,
scope_assets INTEGER NOT NULL,
model_cost_usd NUMERIC NOT NULL DEFAULT 0,
tool_cost_usd NUMERIC NOT NULL DEFAULT 0,
cloud_cost_usd NUMERIC NOT NULL DEFAULT 0,
human_hours NUMERIC NOT NULL DEFAULT 0,
blended_hourly_rate_usd NUMERIC NOT NULL DEFAULT 0
);
CREATE TABLE findings (
finding_id TEXT PRIMARY KEY,
run_id TEXT REFERENCES security_test_runs(run_id),
severity TEXT NOT NULL,
status TEXT NOT NULL,
is_validated BOOLEAN NOT NULL DEFAULT FALSE,
is_accepted BOOLEAN NOT NULL DEFAULT FALSE,
is_false_positive BOOLEAN NOT NULL DEFAULT FALSE,
created_at TIMESTAMP NOT NULL,
report_ready_at TIMESTAMP
);
The weekly query can calculate cost per accepted validated finding:
WITH run_costs AS (
SELECT
run_id,
date_trunc('week', started_at) AS week,
model_cost_usd
+ tool_cost_usd
+ cloud_cost_usd
+ human_hours * blended_hourly_rate_usd AS total_cost
FROM security_test_runs
),
finding_counts AS (
SELECT
run_id,
COUNT(*) FILTER (
WHERE is_validated = TRUE AND is_accepted = TRUE
) AS accepted_validated_findings,
COUNT(*) FILTER (
WHERE is_false_positive = TRUE
) AS false_positives
FROM findings
GROUP BY run_id
)
SELECT
rc.week,
SUM(rc.total_cost) AS weekly_cost,
SUM(fc.accepted_validated_findings) AS accepted_validated_findings,
CASE
WHEN SUM(fc.accepted_validated_findings) = 0 THEN NULL
ELSE SUM(rc.total_cost) / SUM(fc.accepted_validated_findings)
END AS cost_per_validated_vulnerability,
SUM(fc.false_positives) AS false_positives
FROM run_costs rc
JOIN finding_counts fc ON rc.run_id = fc.run_id
GROUP BY rc.week
ORDER BY rc.week;
This query is not meant to become a bureaucratic reporting ritual. It is meant to create feedback. If the cost per validated vulnerability rises for API tests, look at false positives, missing test accounts, or unclear object ownership. If cost rises for CVE validation, look at asset inventory quality. If human hours rise while model cost stays flat, the agent may be producing too much ambiguous output. If retest pass rate is low, remediation guidance may be weak.
The most useful metrics are the ones that change behavior.
| Metrisch | Bad signal | Likely action |
|---|---|---|
| High false positive cost | Review time is being consumed by noise | Add validation gates before ticket creation |
| High time to first finding | Setup or discovery is slow | Improve scope templates and asset ingestion |
| High human minutes per finding | Evidence is hard to trust | Standardize proof artifacts |
| Low accepted finding rate | Testing is misaligned with owner expectations | Clarify acceptance criteria |
| High reopen rate | Fixes are incomplete | Improve remediation guidance and retest scripts |
| High model spend with low validation | Agent is exploring too broadly | Add planning constraints and stop conditions |
Good security leaders should not ask, “How many findings did we get?” first. They should ask, “How many findings changed a remediation decision, how much did they cost, and what made the expensive ones expensive?”
How to reduce the cost without chasing shallow bugs
The fastest way to reduce cost per validated vulnerability is also the worst: lower the validation standard. Count weak findings. Accept duplicates. Mark theoretical issues as confirmed. Ignore retesting. That produces a better number and a worse security program.
The real goal is to reduce wasted work while keeping the evidence bar high.
Start with acceptance criteria. Before testing begins, define what counts as validated for the target class. For API authorization testing, require two roles, object ownership proof, request and response evidence, and remediation mapping. For CVE validation, require affected version, reachable code path or compensating control analysis, exposure state, and patch or mitigation status. For SSRF, require controlled callback evidence and boundary analysis. For XSS, require execution context, affected parameter, payload safety, and impact. A clear definition prevents endless debate later.
Prioritize assets by exposure and value. A public-facing identity provider, VPN, file transfer service, admin panel, CI/CD system, or payment workflow deserves different attention than a low-risk marketing endpoint. CISA KEV status, external exposure, privileged access, sensitive data, and business criticality should all influence test order. The point is not to ignore low-risk systems forever. The point is to spend validation effort where the expected value is highest.
Record negative evidence. If an agent or tester proves that a suspected path is not vulnerable, that work should not disappear. Negative evidence prevents repeated testing, helps explain scope coverage, and improves future prompts or agent plans. It also protects the metric from unfair interpretation. A run with no vulnerabilities may still be valuable if it reduced uncertainty on critical assets.
Standardize evidence fields. Every validated finding should have affected asset, vulnerability class, reproduction steps, proof artifact, impact, exploit conditions, limitations, owner, remediation, and retest method. This reduces report writing cost and makes handoff easier.
Use replayable tests where safe. A retest script is often worth more than a screenshot. It lets teams confirm fixes, detect regressions, and prove closure. Replayability is one of the strongest cost reducers because it turns a one-time investigation into reusable verification.
Separate exploration from validation. Exploration can be broad and creative. Validation should be narrow and disciplined. AI agents are useful in both phases, but the controls should differ. Exploration can generate hypotheses and collect context. Validation should use stricter permissions, safer payloads, evidence schemas, and human approval gates.
Keep humans on judgment, not formatting. Senior security engineers should spend time deciding whether a path is exploitable, whether a proof is safe, whether impact is real, and whether remediation is adequate. They should not spend most of their time cleaning messy tool output or rewriting basic reproduction steps. A good AI workflow reduces administrative drag without replacing expert judgment.
Review rejected findings. False positives are expensive training data. Classify why they were rejected: version mismatch, unreachable code path, missing authorization context, duplicate, accepted risk, compensating control, scope issue, model hallucination, or tool signature error. The next workflow should use that classification to avoid the same waste.
The economics of exploitability
A vulnerability is not equally valuable just because it has a name. Exploitability changes the economics.
A remotely exploitable issue on an internet-facing system that handles credentials or sensitive data has a different expected value than a local issue on an isolated system with strong monitoring and rapid patching. A business logic flaw that allows cross-tenant access may be more valuable than a technically severe issue that is unreachable. A known exploited vulnerability on an edge appliance may deserve immediate validation even if the team is not sure whether exploitation has happened.
Mandiant’s 2026 M-Trends reporting is a useful reminder that exploitation timelines are compressing. Google Cloud’s Mandiant blog states that mean time to exploit vulnerabilities dropped to an estimated negative seven days, meaning exploitation is routinely occurring before a patch is released. That does not mean every vulnerability is exploited before patch availability. It does mean defenders cannot rely on slow attacker adoption as a general assumption. (Google Wolke)
Verizon’s 2026 DBIR summary also points to the rising importance of software vulnerabilities as an initial breach path, stating that 31 percent of breaches now start with software vulnerabilities. Even if individual environments vary, the direction is clear: vulnerability validation is becoming a core operating capability, not a periodic compliance exercise. (Verizon)
Exploitability should therefore be part of the denominator quality. A program that finds many low-impact issues cheaply may look efficient, but it may not reduce meaningful risk. A program that finds fewer high-impact validated vulnerabilities may be economically superior if those findings prevent likely compromise paths.
One practical approach is to segment cost by impact tier:
| Segment | Beispiel | Why separate it |
|---|---|---|
| Cost per critical validated vulnerability | Reachable RCE, auth bypass, exposed admin takeover | High remediation urgency |
| Cost per high-impact business logic flaw | IDOR, privilege escalation, tenant isolation failure | Often missed by scanners |
| Cost per known exploited exposure | KEV-listed CVE reachable in environment | Threat-driven priority |
| Cost per report-ready medium finding | Stored XSS, sensitive metadata exposure | Useful but should not dominate economics |
| Cost per retested remediation | Confirmed fix for accepted finding | Measures closure, not just discovery |
This keeps the team from gaming the metric. A cheap pipeline that only finds missing headers is not beating an expensive human-assisted workflow that finds a tenant isolation failure. The unit being measured must reflect value.
AI agents and the cost of failure
Failure is not free. In vulnerability discovery, failure takes many forms: dead-end hypotheses, tool crashes, blocked requests, noisy scans, duplicate findings, weak proofs, overbroad CVE matching, invalid assumptions about architecture, and reports rejected by developers. AI agents can reduce some failures and amplify others.
The most common AI-driven failure modes are predictable.
First, agents overgeneralize from public vulnerability descriptions. If a CVE affects one product version under certain conditions, the model may assume that any similar banner is vulnerable. That creates version-match noise.
Second, agents confuse symptoms with proof. A 500 error, timeout, or reflected string may be interesting, but it is not automatically a vulnerability. The workflow needs follow-up tests.
Third, agents lose track of identity context. Business logic testing often depends on roles, tenants, object ownership, subscription levels, and workflow state. If the agent does not preserve those relationships, it may mislabel normal behavior as a flaw or miss a real authorization break.
Fourth, agents repeat failed branches. Without negative evidence and stop conditions, they may keep trying slight variations of a test that has already been ruled out.
Fifth, agents write reports too early. A polished narrative can hide weak evidence. Report generation should follow validation, not replace it.
A good system design treats failure as measurable. Every failed hypothesis should have a reason code:
{
"hypothesis_id": "ssrf-avatar-fetch-003",
"asset": "https://app.example.com/profile/avatar",
"status": "rejected",
"reason": "no_outbound_interaction",
"evidence": [
"Callback server received no DNS or HTTP request",
"Application returned validation error for external URL scheme"
],
"next_action": "Do not retest unless URL validation behavior changes"
}
This is the difference between activity and learning. If the agent fails and the program learns nothing, the cost is wasted. If the agent fails and records why, future cost goes down.
Cost per validated vulnerability in bug bounty
Bug bounty programs already think in a related way, even if they use different language. A valid report has to meet program scope, severity, proof, impact, and duplication rules. Hunters who submit noisy reports raise triage cost. Programs that provide clear scope, test accounts, API docs, safe harbor language, and known limitations reduce invalid submissions and improve signal.
For independent hackers, the metric becomes personal. The cost is time, tooling, infrastructure, subscriptions, model spend, and opportunity cost. The denominator is accepted reports, paid reports, or high-impact accepted reports. A hunter who spends 40 hours producing one accepted high-severity business logic finding may have better economics than a hunter who submits 30 low-quality reports and receives no acceptance.
For program owners, cost per validated vulnerability should include triage labor. If AI causes a flood of shallow reports, the program’s cost can rise even when hunters’ submission cost falls. That is one reason validation standards matter. AI-assisted bug hunting is only healthy when it improves proof quality, not just report volume.
A bug bounty version of the metric might track:
| Metrisch | Hunter view | Program view |
|---|---|---|
| Hours per accepted report | Personal efficiency | Signal quality |
| Tool and model spend per bounty | Profitability | Submission pressure |
| Duplicate rate | Wasted effort | Triage cost |
| Invalid rate | Skill or scope mismatch | Program clarity problem |
| Time from discovery to acceptance | Cash-flow and feedback | Triage efficiency |
| Retest success | Reputation and quality | Remediation confidence |
This framing avoids the false debate over whether AI makes hacking “too easy.” The better question is whether AI improves accepted, useful vulnerability evidence per unit of effort. If it does, both serious hunters and serious programs benefit. If it only increases low-quality submissions, the economics get worse.
Cost per validated vulnerability in enterprise pentesting
Enterprise teams face a different problem. They do not only need new bugs. They need defensible assurance across assets, releases, cloud environments, APIs, identity systems, and third-party dependencies. They also need reports that can survive internal review, audit, customer security questionnaires, and remediation planning.
In enterprise work, the cost of a vulnerability includes coordination. Scheduling test windows, provisioning accounts, clarifying scope, collecting logs, notifying owners, reviewing evidence, opening tickets, fixing code, validating patches, and documenting closure all consume time. AI can help, but the largest savings may come from reducing coordination friction.
The most expensive finding is sometimes the one that nobody owns. A validated vulnerability with no clear owner can sit unresolved. A report with no retest method can create uncertainty. A fix with no evidence can be challenged later. Unit economics should therefore include the remediation loop.
An enterprise-ready finding should answer:
| Frage | Warum das wichtig ist |
|---|---|
| Who owns the affected asset? | Without ownership, remediation stalls. |
| Which business process is affected? | Impact becomes understandable outside security. |
| What exact condition is broken? | Developers need root cause, not just symptoms. |
| How was proof collected safely? | Legal, compliance, and operations teams need confidence. |
| What is the recommended fix? | Action reduces risk. |
| How can the fix be retested? | Closure requires verification. |
| What detection signals exist? | Blue teams may need monitoring before full remediation. |
This is where agent-assisted workflows can be economically strong. They can help maintain context across a long test, keep evidence structured, generate retest commands, and produce reports that are closer to remediation-ready. The value is not that the agent replaces the pentester. The value is that the pentester spends less time reconstructing context and more time making security decisions.
The hidden cost of reporting
Reporting is often treated as the end of testing. Economically, it is part of validation.
A finding that cannot be understood by the receiving team is not fully delivered. A vague report creates back-and-forth. A missing screenshot forces retesting. A missing request body blocks reproduction. A missing impact statement delays prioritization. A missing remediation path creates developer frustration. Every gap adds cost.
Good reporting should be evidence-dense and concise. A useful report-ready finding normally includes:
| Report field | Good example |
|---|---|
| Title | Cross-tenant invoice metadata access through missing object-level authorization |
| Affected asset | GET /api/invoices/{invoice_id} |
| Severity rationale | Cross-user access to billing metadata in authenticated user context |
| Voraussetzungen | Valid low-privilege account and another invoice ID |
| Reproduction | Four safe steps with two test users |
| Beweise | HTTP requests, responses, timestamps, test account IDs |
| Auswirkungen | Unauthorized reading of another tenant’s invoice metadata |
| Beschränkungen | Test did not access production customer data |
| Sanierung | Enforce object ownership check before retrieval |
| Retest | Script or manual replay steps |
The more standardized this becomes, the lower the marginal cost of each validated vulnerability. This is one of the areas where AI is practically useful today. It can turn structured evidence into readable reports, compare proof against a checklist, identify missing fields, and prepare retest instructions. But it should not invent evidence. The system must keep a hard boundary between observed facts and generated prose.
A good rule is simple: if the report says it happened, the evidence store should prove it happened.
Using known exploited vulnerabilities as a cost reducer
Threat intelligence can reduce cost when it narrows the search space. CISA KEV is especially useful because it identifies vulnerabilities with known exploitation. That does not mean every KEV item is relevant to every organization. It means the validation queue should treat those exposures differently.
A practical KEV-driven workflow looks like this:
- Match KEV entries against the asset inventory.
- Prioritize internet-facing and privileged systems.
- Confirm product, version, and configuration.
- Check whether the vulnerable path is reachable.
- Verify patch or mitigation status.
- Review relevant logs and indicators.
- Record whether the exposure is confirmed, mitigated, not applicable, or unknown.
- Retest after remediation.
The cost advantage comes from focus. Instead of scanning everything equally, the team asks: which known exploited issues could plausibly affect our most exposed assets?
That said, known exploited validation has risks. A KEV match can create urgency, but it can also create panic. Teams should avoid unsafe exploit attempts on production systems. For many CVEs, validation should rely on version checks, vendor-recommended detection, configuration review, non-destructive probes, and log analysis rather than weaponized proof. The goal is to make a remediation decision, not to demonstrate maximum exploit impact.
The role of fuzzing, static analysis, and dynamic testing
Cost per validated vulnerability should not privilege one testing technique. Different methods find different issues at different costs.
Fuzzing is powerful for memory corruption, parser bugs, protocol handling, and crash discovery. It can run continuously and find issues humans would not manually enumerate. But raw crashes require triage, minimization, deduplication, root cause analysis, and exploitability assessment. A fuzzing campaign with many flaky crashes may have a high validation cost even if discovery cost is low.
Static analysis can find code patterns, tainted flows, insecure API use, and dependency issues before deployment. It is valuable because it runs close to development. But static findings can be noisy without reachability, configuration, and runtime context.
Dynamic testing shows real behavior in a running system. It can prove authentication, authorization, SSRF, injection, deserialization, misconfiguration, and business logic issues. But it requires safe scope, test data, accounts, and environment control.
AI can connect these methods. It can help build fuzz harnesses, interpret static analysis output, generate dynamic test hypotheses, and summarize evidence. But the validation burden remains. A finding is not validated because a tool says so. It is validated when the evidence meets the acceptance standard.
| Technik | Low-cost strength | Validation burden |
|---|---|---|
| Fuzzing | Broad automated input exploration | Crash triage and exploitability |
| Statische Analyse | Early code-level detection | False positives and reachability |
| Dynamic testing | Real runtime proof | Safe execution and scope control |
| Manual testing | Creative business logic insight | Expert time and repeatability |
| AI-assisted agents | Context handling and iteration | Evidence quality and control |
The best programs combine methods. They do not ask one tool to do everything.
A scoring model for validated findings
To keep the denominator honest, teams can score each finding before counting it as validated. The score should not replace severity. It should measure proof quality.
A practical validation score can use five dimensions:
| Dimension | 0 points | 1 point | 2 points |
|---|---|---|---|
| Reproducibility | Cannot reproduce | Reproduces once with unclear steps | Reproduces reliably with documented steps |
| Auswirkungen | Theoretical | Limited technical impact | Clear security or business impact |
| Umfang | Unclear or out of scope | In scope but boundary needs review | Clearly in scope |
| Beweise | Weak or incomplete | Some proof but missing context | Complete safe evidence |
| Remediation path | No clear fix | General recommendation | Specific owner and fix guidance |
A team might require at least 8 out of 10 before a finding counts as validated. For high-risk vulnerabilities, it may require human approval regardless of score. For low-risk findings, it may require deduplication and owner acceptance.
This kind of score helps because it separates discovery from delivery. An agent may discover many promising leads. Only a subset should count. The score also helps improve training data: rejected findings can be reviewed for missing evidence, weak impact, or scope ambiguity.
How CISOs should use the metric
For a CISO or security leader, cost per validated vulnerability should answer three questions.
First, is the organization getting more real risk reduction from the same testing budget? If cost per validated vulnerability falls while accepted severity and evidence quality remain stable, the workflow is improving.
Second, where is the waste? The answer may be false positives, unclear scope, poor asset inventory, missing test accounts, weak reporting templates, slow triage, or repeated retesting.
Third, which testing mode produces the best outcome for each risk class? AI-assisted testing may be excellent for CVE validation and API evidence packaging, while senior manual testers may still dominate complex business logic abuse. Fuzzing may be best for parsers and libraries. Static analysis may be best for early secure development feedback. The metric should help route work to the right method.
A CISO dashboard should avoid vanity comparisons. It should not say, “AI found 40 bugs and humans found 8” unless the findings are normalized by severity, validation standard, scope difficulty, and acceptance. A better dashboard says:
| Frage | Useful metric |
|---|---|
| Are we reducing review noise? | False positive cost and rejected finding rate |
| Are we getting value faster? | Zeit bis zum ersten validierten Befund |
| Are reports usable? | Report-ready findings and reopen rate |
| Are fixes working? | Retest pass rate |
| Are high-risk assets covered? | Coverage per dollar by asset tier |
| Are AI workflows helping? | Human minutes per accepted finding before and after adoption |
The goal is not to prove that AI is better in every category. The goal is to learn where it changes the cost curve.
Common mistakes
The first mistake is counting unverified alerts. This makes the metric meaningless. A vulnerability must meet the validation standard before it enters the denominator.
The second mistake is ignoring false positives. False positives consume human time, damage trust, and slow remediation. They belong in the numerator.
The third mistake is ignoring retesting. A vulnerability that is found but never confirmed fixed is an incomplete security outcome.
The fourth mistake is comparing teams without scope context. Testing a mature identity system is not the same as testing a small brochure site. Cost per validated vulnerability should be segmented by asset class, test type, and expected difficulty.
The fifth mistake is optimizing for cheap bugs. A program should not celebrate low cost if it only finds low-impact issues while missing critical paths.
The sixth mistake is treating model cost as the whole cost. Token spend is often visible, but engineer review time is usually larger and more important.
The seventh mistake is letting agents run without control. Unsafe automation can create legal, operational, and reputational cost that dwarfs any testing savings.
FAQ
What is cost per validated vulnerability?
- Cost per validated vulnerability is the total cost of producing accepted, reproducible, useful vulnerability findings divided by the number of those validated findings.
- It includes labor, tools, model usage, infrastructure, false positive review, evidence preparation, reporting, and retesting.
- It should not count raw scanner alerts, untested LLM hypotheses, duplicate findings, or theoretical issues without proof.
- The metric is useful because it connects technical security work to unit economics without reducing quality to a simple bug count.
How is it different from cost per bug?
- Cost per bug can be misleading because “bug” may include crashes, duplicates, low-impact defects, informational alerts, or unconfirmed reports.
- Cost per validated vulnerability requires proof, scope alignment, impact explanation, and remediation value.
- It rewards findings that a security team can act on, not merely issues that a tool can list.
- For AI security workflows, the validated version is much safer because it penalizes hallucinations and false positives.
Should teams optimize for the cheapest vulnerability?
- No. The cheapest vulnerabilities are often low-impact and easy to find.
- Teams should segment the metric by impact, asset class, and test type.
- A higher cost for a critical, reachable authentication bypass may be better than a low cost for dozens of minor hardening issues.
- The goal is lower cost per useful risk decision, not cheaper noise.
Can AI agents really reduce vulnerability discovery cost?
- Yes, in specific parts of the workflow: context gathering, hypothesis generation, tool orchestration, response comparison, evidence structuring, report drafting, and retesting.
- AI does not automatically reduce cost. Poorly controlled agents can increase false positives, review time, model spend, and scope risk.
- The strongest economic gains usually come when AI handles repetitive workflow steps while humans keep control over authorization, validation, impact, and remediation judgment.
- Teams should measure before and after adoption instead of assuming savings.
How do you count a vulnerability as validated?
- Define validation criteria before testing begins.
- Require reproducible steps, affected asset, proof artifact, impact, scope confirmation, and a recommended fix.
- For risky classes such as RCE, use safe proof methods and human approval.
- Count the finding only when the receiving team accepts it as real, in scope, and actionable.
- Record rejected findings separately so false positive cost remains visible.
How should false positives be included?
- False positives should increase the numerator because they consume review time and slow the team.
- Track the reason for each rejection: duplicate, unreachable path, version mismatch, compensating control, model hallucination, out of scope, or insufficient evidence.
- Use rejection data to improve scanners, prompts, agent policies, and validation gates.
- Do not hide false positives outside the metric; that makes AI workflows look cheaper than they are.
What should a CISO track alongside this metric?
- Time to first validated finding.
- Human minutes per accepted finding.
- False positive cost.
- Cost per high-impact validated finding.
- Coverage per dollar by asset tier.
- Report-ready finding rate.
- Retest pass rate.
- Reopened finding rate after remediation.
Does cost per validated vulnerability replace CVSS or KEV?
- No. CVSS helps describe severity characteristics, and KEV helps identify known exploited vulnerabilities.
- Cost per validated vulnerability measures the economics of your workflow.
- A mature program uses all three: CVSS for severity language, KEV for threat prioritization, and validation cost for operating efficiency.
- The strongest decisions come from combining severity, exploitability, exposure, business context, and verified evidence.
Closing judgment
The next phase of AI security will not be won by the system that generates the most findings. It will be won by the system that produces the most trusted, reproducible, remediation-ready vulnerabilities per unit of cost.
Cost per validated vulnerability gives security teams a sharper lens. It exposes false positives. It values evidence. It forces AI tools to prove their usefulness beyond fluent explanations. It connects pentesting, CVE validation, bug bounty, fuzzing, static analysis, reporting, and retesting into one operating question: how efficiently are we turning effort into verified risk reduction?
That question is uncomfortable because it makes waste visible. It is also exactly why the metric is useful.

