Warum sich der Schwerpunkt auf die lokale Ebene verlagert
Cloud-LLMs sind nach wie vor bemerkenswert, doch die Realität in den roten Teams ist unversöhnlich: Ratenbeschränkungen kommen mitten im Engagement, Preisänderungen machen Planungsmodelle zunichte und regionale politische Veränderungen stören die Beweiserhebung. Für Teams, die von Reproduzierbarkeit, Forensik und sauberen Prüfpfaden leben und sterben, sind diese Unsicherheiten keine Nuance - sie sind ein Betriebsrisiko. Parallel dazu bevorzugen regulierte Umgebungen im Gesundheitswesen, im Finanzwesen und im öffentlichen Sektor zunehmend, dass sensible Daten niemals verlässt kontrollierte Netzwerke, was die Modellausführung auf Laptops, Workstations und private Cluster verlagert. Diese Verschiebung ist in der Öffentlichkeit sichtbar: In Berichten wird der Anstieg der "Schatten-KI" verfolgt, wobei ein großer Teil der Mitarbeiter die nicht genehmigte KI-Nutzung einräumt, die ein Risiko für die Offenlegung von Daten darstellt. (Cybernews)
Eine zweite Kraft ist die Transparenz. Kleine Open-Source-Modelle mit 7B bis 13B Parametern, die quantisiert, beschnitten und abgestimmt sind, werden für einen großen Teil der Triage, PoC-Generierung und Skripting-Unterstützung "gut genug", während sie auf der Ebene der Gewichte und Prompt-Templates überprüfbar bleiben. Kombiniert man dies mit Grenzkosten von nahezu Null pro Lauf und einer lokalen Latenz von weniger als einer Sekunde auf handelsüblichen GPUs, erhält man eine Experimentierschleife, die sowohl schneller als auch einfacher zu steuern ist als ein entfernter Blackbox-Endpunkt. Der lokale Weg minimiert auch den Radius von Ausfällen und Richtlinienänderungen, die sonst ein Testfenster zum Stillstand bringen würden. Dennoch ist "lokal" nicht automatisch "sicher": Jüngste Scans haben Hunderte von selbst gehosteten LLM-Endpunkten, darunter auch Ollama, im öffentlichen Internet aufgedeckt - was uns daran erinnert, dass grundlegende Zugangskontrolle und Netzwerkisolierung immer noch wichtig sind. (TechRadar)
Quellen: Cybernews über die Verbreitung und die Risiken von Schatten-KI; TechRadar und Cisco Talos über ungeschützte Ollama-Server. (TechRadar)
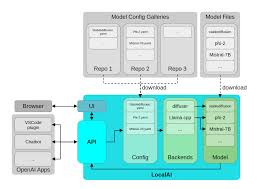
Definition von pentestai in der Praxis
pentestai ist Penligents Arbeitsdefinition für KI-gestützte Penetrationstests: eine Methode und ein Arbeitsablauf, bei dem lokale, quelloffene kleine LLMs Ihre bestehende Toolchain - Burp, SQLMap, Nuclei, GHunt - orchestrieren und dabei Befehle, Parameter, Artefakte und Reproduktionsschritte als permanente Beweisführung erfassen. Das Modell ist nicht der "Akteur"; es ist der Kollaborateur die unter menschlicher Aufsicht Befehle vorschlägt, PoCs synthetisiert und Schlussfolgerungen über Scannerergebnisse zieht. In einer hybriden Haltung können langkettige Schlussfolgerungen oder ultralange Kontextaufgaben zu Cloud-Modellen eskalieren, aber die Überprüfung und anfängliche Beweiserfassung verbleiben auf der von Ihnen kontrollierten Hardware.
Das Plädoyer für "lokale + offene kleine LLMs"
Ein lokaler Ansatz lässt sich problemlos mit Datenschutz- und Compliance-Kontrollen verbinden, da die Daten innerhalb der Gerätegrenzen und des Prüfsystems verbleiben. Der Ansatz entspricht den Kontrollfamilien, die den Sicherheitsverantwortlichen vertraut sind - Zugriffsdurchsetzung, Auditing und Datenminimierung - und die in Frameworks wie NIST SP 800-53. Darüber hinaus ermöglichen offene Gewichte eine externe Überprüfung, eine Verifizierung in der Lieferkette und eine deterministische Reproduktion der Ergebnisse über Teams und Zeit hinweg. Wenn die Cloud gedrosselt wird, ausfällt oder die Bedingungen ändert, geht Ihr rotes Team nicht unter, sondern macht auf der Workstation neben Ihnen weiter. Der Vorbehalt: Behandeln Sie Ihre lokale Modell-Laufzeit als sensiblen Dienst - authentifizieren Sie ihn, segmentieren Sie ihn, und stellen Sie ihn niemals direkt dem Internet zur Verfügung. (NIST-Ressourcenzentrum für Computersicherheit)
Ein Referenzstapel für pentestai
Lokal bedeutet nicht monolithisch. Es bedeutet eine sorgfältig abgestufte Kapazität, bei der jede Sprosse eine spezifische Testfunktion hat und die gesamte Leiter bei Bedarf in die Cloud verlagert werden kann, um die Komplexität, den Umfang oder das Kontextfenster zu erhöhen.
| Ebene | Typische Hardware | Modell/Laufzeit | Hauptrolle | Anmerkungen |
|---|---|---|---|---|
| Leichter Prototyp | MacBook-Klasse | Ollama laufende 7B-13B quantisierte Modelle | Prompt→Befehlssynthese, kleine PoCs, Protokolltriage | Tragbar, privat, niedrige Latenzzeit. (Ollama) |
| Haushaltslabor | GTX 1070 / iGPU | GGUF mit llama.cpp oder LM Studio | Luftgekühlte Bohrer, Offline-Automatisierung | Stabil auch auf älteren GPUs/iGPUs. (umarmungsgesicht.co) |
| High-End-Arbeitsplatz | RTX 4090 (24GB) | Multi-Agenten-Orchestrierung + Fuzz-Schleifen | Große Bestände, parallele Validierung | Hohe Gleichzeitigkeit, kurze Rückkopplungszyklen. (NVIDIA) |
| Rand & Mobil | Apple-Geräte + Kern ML | Inferenz auf dem Gerät | Probenahme vor Ort in regulierten Gebieten | Keine Gefährdung durch die Cloud für PHI/PII. (Apple Entwickler) |
In dieser Architektur, Ollama vereinfacht die lokale Modellverwaltung und den API-Zugang, GGUF bietet ein effizientes, portables Format, das für CPU/GPU-Inferenz optimiert ist, RTX 4090 Klassensysteme schalten aggressives Fuzzing und Multi-Agenten-Flows frei, und Kern ML behält sensible Daten auf dem Gerät und nutzt die Neural Engine von Apple. (Ollama)
Was sich bei der täglichen Prüfung ändert
Für Web/API pentestai beschleunigt die Schleife von der OSINT- und Parameterermittlung bis hin zur Hypothesengenerierung und schablonenhaften Prüfungen. IDOR-Kandidaten, falsch zugewiesene Autorisierungsregeln oder die Umgehung von Ratenbeschränkungen können mit Hilfe von Eingabeaufforderungen und einem kleinen Parsing-Gerüst in überprüfbare Nuclei-Vorlagen umgewandelt werden, während sich Zugriffskontroll- und Injektionsrisiken sauber mit OWASP Top 10 und ASVS Leitlinien, die Sie bereits für die Berichterstattung verwenden. (OWASP-Stiftung)
Unter Beglaubigungen und Föderation arbeiten, helfen Modelle bei der Erstellung und Validierung von Testplänen für OAuth 2.0 und OpenID-Verbindung Abläufe: Status, Nonce, Publikum und Token-Lebensdauer sind kein Stammeswissen mehr, sondern werden zu Checklisten mit angehängten Skripten. Der Vorteil liegt nicht in einem "magischen Exploit", sondern in einer rigorosen, wiederholbaren Methode zur Prüfung von Annahmen, zur Protokollierung jedes Versuchs und zur Aufbewahrung von Artefakten für die Überprüfung. (datatracker.ietf.org)
Für LLM-Sicherheit-Einschleusung, Exfiltration, Jailbreaks und Umgehung von Richtlinien - sind lokale Modelle doppelt nützlich: Sie simulieren die Eingaben von Angreifern und stellen Überlegungen zur Tiefenverteidigung an, ohne Ihre Eingabeaufforderungen, Systemanweisungen oder bereinigten Datenbestände nach außen zu senden. Dies ist sowohl ein Gewinn für die Datenverwaltung als auch für die Geschwindigkeit. In der Zwischenzeit sind die falsch konfigurierten LLM-Endpunkte der Branche ein abschreckendes Beispiel: Wenn Sie sich selbst hosten, schließen Sie es ab. (TechRadar)
Eine minimale lokale Kette: Modellgestützte Überprüfung von Nuklei
# Verwenden Sie ein lokales 7B-13B-Modell über Ollama, um eine Nuklei-Vorlage+Befehl zu synthetisieren.
prompt='Erzeugen Sie eine Nuclei-Vorlage, um nach einem einfachen IDOR unter /api/v1/user?id=... zu suchen.
Geben Sie nur gültige YAML und einen einzeiligen Nuclei-Befehl zur Ausführung zurück.'
curl -s http://localhost:11434/api/generate \
-d '{"model": "llama3.1:8b-instruct-q4", "prompt":"'"$prompt"'", "stream": false}' \
| jq -r '.response' > gen.txt
# YAML extrahieren und ausführen, dann Artefakte in ein Audit-Protokoll hacken.
awk '/^id: /,/^$/' gen.txt > templates/idor.yaml
nuclei -t templates/idor.yaml -u https://target.example.com -o evidence/idor.out
sha256sum templates/idor.yaml evidence/idor.out >> audit.log
Es geht nicht darum, "das Modell hacken zu lassen". Es ist von Menschen gelenkt Automatisierung mit engem Umfang, erfassten Beweisen und deterministischer Reproduktion.
Governance, die bei Prüfungen tatsächlich Bestand hat
Local-first" ist keine Entschuldigung für schwache Prozesse. Behandeln Sie Prompts als versionierte Assets, führen Sie Tests auf Unit-Ebene durch, um Sicherheit und Determinismus zu gewährleisten, und setzen Sie RBAC auf Ihrer Orchestrierungsebene durch. Bilden Sie Ihre Kontrollen auf NIST SP 800-53 Familien, damit Ihre Prüfer sie erkennen: Zugriffskontrolle (AC), Prüfung und Verantwortlichkeit (AU), Konfigurationsmanagement (CM) und System- und Informationsintegrität (SI). Bewahren Sie die Modelllaufzeit in einem privaten Segment auf, verlangen Sie eine Autorisierung und protokollieren Sie alle Aufrufe, einschließlich Prompt-Text, Tool-Aufrufe und Hashes der generierten Artefakte. Und da die meisten Web/API-Ergebnisse schließlich in den Berichten der Geschäftsführung landen, sollten Sie Sprache und Schweregrad an OWASP zur Minimierung von Neuschreibzyklen mit AppSec und Compliance. (NIST-Ressourcenzentrum für Computersicherheit)
Wann sollte man auf die Cloud umsteigen und warum ist Hybrid ehrlich?
Es gibt legitime Gründe, gehostete Modelle zu verwenden: extrem lange Kontexte, mehrstufige Schlussfolgerungen über heterogene Korpora oder strenge Verfügbarkeits-SLAs für Produktionspipelines. Eine vertretbare Strategie ist "lokal für die Überprüfung, in der Cloud für die Skalierung", wobei explizite Regeln für die Datenverarbeitung und die Redigierung eingebaut werden. Damit wird der Tatsache Rechnung getragen, dass einige Probleme die praktischen Grenzen lokaler Hardware überschreiten, während der sensible Kern Ihrer Tests innerhalb Ihrer Prüfungsgrenzen bleibt.
Wo Penligent passt, wenn Sie einen produktbezogenen Pfad benötigen
Penligent operationalisiert pentestai in einen evidenzbasierten Arbeitsablauf: Anweisungen in natürlicher Sprache werden in ausführbare Werkzeugketten umgewandelt, Ergebnisse werden validiert und mit Parametern und Artefakten protokolliert, und die Berichte richten sich nach Frameworks, denen Ihre Stakeholder bereits vertrauen, wie z. B. OWASP Top 10 und NIST SP 800-53. Einsätze unterstützen Ollama für die lokale Verwaltung, GGUF Modelle für eine effiziente Inferenz, und Kern ML für geräteinterne Tests, bei denen die Einhaltung von Vorschriften ohne Cloud-Exposition erforderlich ist. Das Ergebnis ist eine "always-on"-Red-Team-Position, die Ratenbeschränkungen von Anbietern, Richtlinienänderungen und Netzwerkpartitionen übersteht, ohne die Überprüfbarkeit zu verlieren. (Ollama)
Praktische Lektüre und Anker, die Ihr Team bereits verwendet
Wenn sich Ihre Tests auf Authentifizierung und Identität erstrecken, behalten Sie die OAuth 2.0 und OpenID-Verbindung Bei einer Eskalation in die Cloud sollten Sie sicherstellen, dass Ihre Nachweise immer noch demselben Berichtsnetz zugeordnet sind. Weisen Sie die Produktmanager und die technische Leitung auf folgende Punkte hin, wenn es um Web-Risiken geht OWASP Top 10 Primer, so dass die Behebungszyklen kürzer und weniger nachteilig sind. Und wenn Sie die Workstation-Route verfolgen, sollten Sie ein Profil RTX 4090 Klassensystem für paralleles Fuzzing und Agenten-Orchestrierung; wenn Sie mobil oder in der Klinik sind, verwenden Sie Kern ML und seine Toolchain, um regulierte Daten auf dem Gerät zu halten. (datatracker.ietf.org)
Quellen
- Verbreitung von Schatten-KI und Risiken am Arbeitsplatz (Cybernews; TechRadar-Zusammenfassung der gleichen Umfrage). (Cybernews)
- Offengelegte lokale LLM-Endpunkte, einschließlich Ollama (TechRadar; Cisco Talos Blog). (TechRadar)
- OWASP Top 10 (offiziell). (OWASP-Stiftung)
- NIST SP 800-53 Rev. 5 (offizielles HTML und PDF). (NIST-Ressourcenzentrum für Computersicherheit)
- OAuth 2.0 (RFC 6749) und OpenID Connect Core 1.0. (datatracker.ietf.org)
- Ollama und GGUF Referenzen; Core ML Dokumente; NVIDIA RTX 4090 Produktseite. (Ollama)
Autoritative Links, die Sie immer griffbereit haben sollten:
OWASP Top 10 - NIST SP 800-53 Rev. 5 - RFC 6749 OAuth 2.0 - OpenID Connect Kern 1.0 - Ollama - GGUF-Übersicht - ML-Kerndokumente - GeForce RTX 4090

