Wenn man die Schlagzeilen über Sicherheitslücken liest, steht XML-Injection selten im Mittelpunkt des Interesses. Sie hat nicht den gleichen Bekanntheitsgrad wie RCE oder SQLi und ist auch optisch nicht so dramatisch wie ein auffälliger Remote-Exploit. Aber in vielen Unternehmens-Stacks - SOAP-Endpunkte, ältere XML-APIs, Dokumentenverarbeitungs-Pipelines und SAML/SOAP-Integrationen - ist XML-Injection der stille Fehlermodus, der vertrauenswürdige Eingaben in logische Fehler verwandelt.
Im Grunde genommen ist XML-Injection keine einzelne Schwachstelle. Es handelt sich um eine Reihe von Verhaltensweisen, bei denen vom Angreifer kontrolliertes XML die Art und Weise verändert, wie ein Server eine Anfrage interpretiert. Das kann bedeuten, dass eine XPath-Abfrage plötzlich unerwartete Datensätze zurückgibt, ein Parser externe Ressourcen auflöst, die er nicht aufrufen sollte, oder eine Entitätserweiterung CPU und Speicher verbraucht. Aus der Sicht eines Angreifers sind dies praktische Bausteine: Dateien lesen, interne Anfragen auslösen oder nützliches Chaos verursachen. Aus der Sicht eines Verteidigers sind die gleichen Bausteine eine Navigationskarte, um die Lücken in der Logik und der Beobachtbarkeit zu schließen.
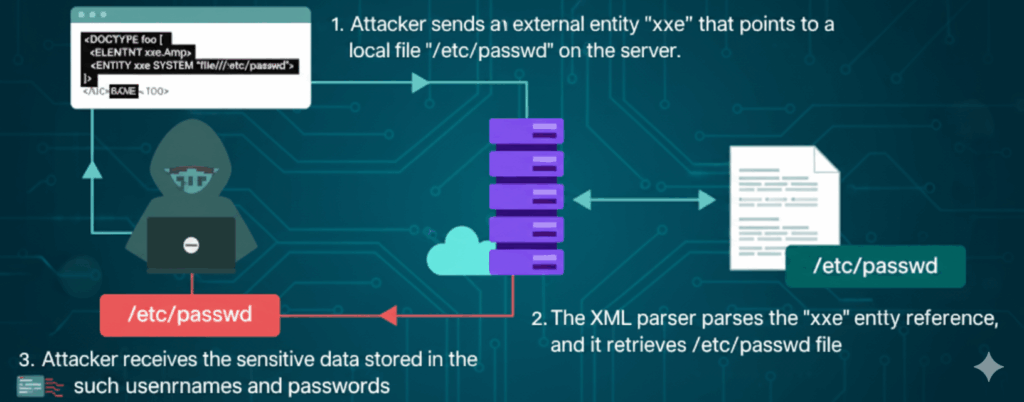
Ein kleiner, konkreter Vorgeschmack - ohne jemandem eine Anleitung zu geben
Sie brauchen keine ausgefeilten Nutzdaten, um das Muster zu erkennen. Stellen Sie sich einen serverseitigen Code vor, der einen XPath aus Anforderungsfeldern durch naive Stringverkettung erstellt:
// anfälliges Muster (Pseudo)
userId = request.xml.user.id
rolle = anfrage.xml.benutzer.rolle
query = "doc('/db/users.xml')/users/user[id = " + userId + " und role = '" + role + "']"
Ergebnis = xmlEngine.evaluate(Abfrage)
Dies sieht harmlos aus, wenn userId und Rolle wohlgeformt sind. Wenn Sie aber die Struktur der Abfrage durch Benutzereingaben steuern lassen, verwischen Sie die Grenze zwischen Daten und Logik. XPath-Injektion ist die natürliche Folge: Eine spröde Abfrage kann so manipuliert werden, dass sie die Wahrheitsbedingungen ändert und Zeilen zurückgibt, die sie nicht zurückgeben sollte.
Eine weitere Achse ist die Behandlung von Entitäten oder DTDs. Viele XML-Engines erlauben Dokumenttyp-Deklarationen, Entitäten und externe Verweise - nützlich für legitime Komposition, aber gefährlich, wenn sie für nicht vertrauenswürdige Eingaben aktiviert sind. Die defensive Regel ist einfach: Wenn Sie die Entitätserweiterung oder DOCTYPE-Verarbeitung nicht benötigen, schalten Sie sie aus.
Warum das Parsen der Konfiguration wichtiger ist als obskure Exploits
Es gibt zwei Ebenen dieses Problems. Die erste ist der Fehler in der Geschäftslogik - die Übergabe von nicht vertrauenswürdigen Werten in die Abfragelogik, das Templating von XML in XPath- oder XPath-ähnliche Evaluatoren und die Annahme, dass "wohlgeformt" "sicher" bedeutet. Das lässt sich durch Design beheben: Validierung, Kanonisierung und Trennung von Daten und Abfragen.
Der zweite Punkt ist das Verhalten des Parsers. XML-Parser sind mächtig; sie können Dateiinhalte abrufen, HTTP-Anfragen stellen oder verschachtelte Entitäten expandieren, die den Speicher auslasten. Diese Fähigkeiten sind in kontrollierten Kontexten gut, aber katastrophal, wenn öffentliche Eingaben akzeptiert werden. Der praktische Schutz besteht also in der Abhärtung des Parsers plus Verhaltenstelemetrie.
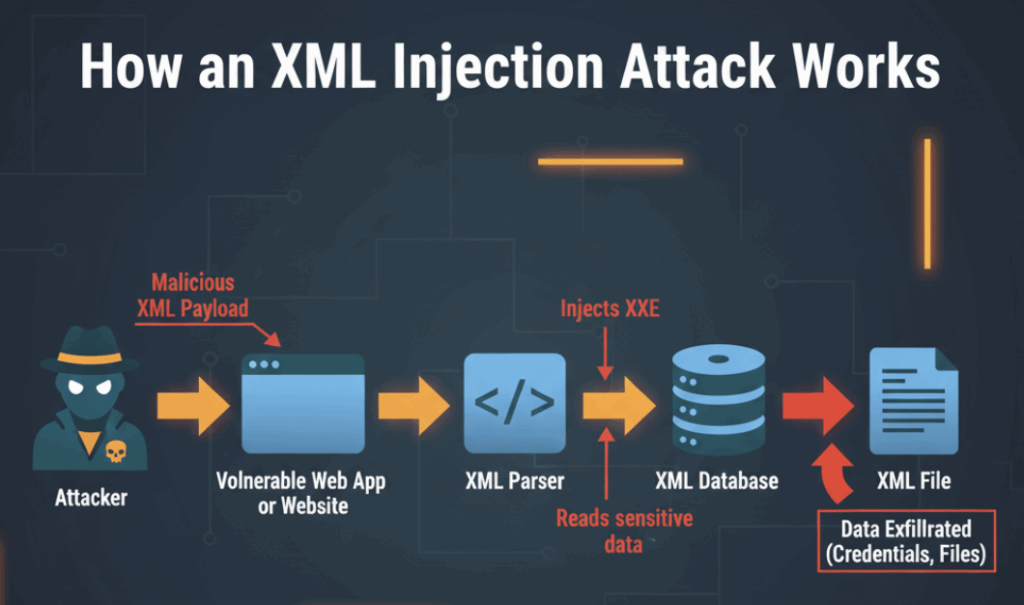
Praktische, ingenieurfreundliche Gegenmaßnahmen (mit Beispiel)
Sie müssen XML nicht verbieten, um sicher zu sein. Sie brauchen drei gewohnheitsmäßige Änderungen:
1) Begrenzung der Parser-Fähigkeit. In den meisten Sprachen können Sie die Verarbeitung von externen Entitäten und DOCTYPE deaktivieren. Zum Beispiel in Java (Pseudo-API):
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setFeature("", true);
dbf.setFeature("", false);
dbf.setFeature("", false);
Oder in Python mit defusedxml (verwenden Sie eine Bibliothek, die standardmäßig ein sicheres Verhalten aufweist):
from defusedxml.ElementTree import fromstring
tree = fromstring(untrusted_xml)
2) Validierung und Kanonisierung. Wenn Ihr Endpunkt nur eine kleine Anzahl von Tags benötigt, validieren Sie anhand einer XSD oder weisen Sie unerwartete DOCTYPEs zurück. Bevorzugen Sie das Parsen in Datenstrukturen und den parametrisierten Zugriff, anstatt Abfragen durch String-Verkettung zu erstellen.
3) Instrument und Alarm. Fügen Sie Hooks hinzu, die auf merkwürdige Signale achten: Parser-Ausnahmen, die auf DOCTYPE/ENTITY verweisen, plötzliche ausgehende DNS/HTTP vom Parsing-Dienst oder während des Parsings eingeleitete Datei-Öffnungsoperationen. Diese Signale sind weitaus aussagekräftiger als jede statische Regelliste.
Erkennbare Signale, die den Verteidigern tatsächlich helfen
Achten Sie bei der Überwachung auf echte Verhaltensweisen und nicht auf schwache Textsignaturen:
- Ausgehende DNS- oder HTTP-Aufrufe, die von Ihrem Parser-Prozess ausgehen.
- Dateizugriffsversuche auf lokale Pfade während der XML-Verarbeitung.
- Parser-Ausnahmespuren, die die Auflösung von DOCTYPE oder externen Entitäten erwähnen.
- Antworten, die plötzlich nur noch interne Felder oder Daten enthalten (was auf XPath- oder Abfragemanipulationen hinweist).
- Ungewöhnliche CPU-/Speicherspitzen beim Parsen von Code unter normaler Last.
Das sind die Dinge, auf die Sie aufmerksam machen und schnell eine Entscheidung treffen können.
Wie man übt, ohne rücksichtslos zu sein
Wenn Sie experimentieren wollen - um Erkennungsregeln zu überprüfen, um zu bestätigen, dass die Parser-Härtung funktioniert, oder um für eine CTF-ähnliche Herausforderung zu trainieren - tun Sie dies nur in kontrollierten Labors. Schieben Sie missgebildetes XML nicht in die Produktion. Verwenden Sie stattdessen isolierte VMs, nachweisbare Laborbereiche oder Werkzeuge, die hygienisch einwandfrei, nicht ausbeuterisch Testfälle.
Workflow in natürlicher Sprache - Penligent in der Schleife
Hier zahlt sich die praktische Automatisierung aus. Sie sollten nicht Dutzende von Tests von Hand programmieren müssen, nur um Parser-Einstellungen oder Erkennungslogik zu validieren. Mit einem natürlichsprachlich gesteuerten Pentest-Tool wie SträflichIn der Alltagssprache sieht der Ablauf folgendermaßen aus:
"Überprüfen Sie unsere Staging-SOAP-Endpunkte auf XML-Injection-Risiken. Verwenden Sie nur sichere Sonden, sammeln Sie Parser-Ausnahmen, Dateizugriffsereignisse und alle ausgehenden DNS/HTTP-Callbacks. Erarbeiten Sie nach Prioritäten geordnete Härtungsschritte."
Penligent wandelt diesen Satz in gezielte, bereinigte Prüfungen gegen Ihre autorisierte Testumgebung um. Es führt gezielte Testfälle aus (keine Live-Exploit-Ketten), sammelt Telemetriedaten (Parser-Fehler, Dateizugriffsprotokolle, DNS-Rückrufe), korreliert die Beweise und liefert eine übersichtliche Checkliste für Abhilfemaßnahmen. Für CTF-Spieler liegt der Vorteil in der Geschwindigkeit: Sie können eine Hypothese validieren und herausfinden, ob Ihre Erkennung funktioniert hätte - und dann iterieren - ohne Shell-Skripte zu schreiben oder Dutzende von Nutzlastdateien zu erstellen.
Abschließender Gedanke
XML-Injection sieht auf einer Schwachstellenliste unspektakulär aus, aber ihre wahre Stärke ist die Heimlichkeit. Sie nutzt Annahmen aus - dass die Datenschicht harmlos ist, dass der Parser sich "wie erwartet" verhält, dass die Überwachung offensichtliche Fehler aufdeckt. Bei der Behebung dieses Problems geht es weniger um einen magischen Patch als vielmehr um Design-Hygiene: Minimierung der Parser-Privilegien, Trennung von Daten und Logik, aggressive Validierung und Instrumentierung für die wichtigen Signale. Tools, die Absichten in natürlicher Sprache in sichere Validierungsläufe umwandeln, nehmen den Teams die lästige Arbeit ab und ermöglichen es ihnen, sich auf Abhilfemaßnahmen und Lernprozesse zu konzentrieren - und genau das ist der Sinn einer modernen defensiven Automatisierung.

