Cuando lees titulares sobre vulnerabilidades, la inyección XML rara vez acapara la atención. No tiene el mismo reconocimiento de nombre que RCE o SQLi, y no es tan visualmente espectacular como un llamativo exploit remoto. Pero en muchas pilas empresariales -puntos finales SOAP, API XML heredadas, canalizaciones de procesamiento de documentos e integraciones SAML/SOAP- la inyección XML es el modo de fallo silencioso que convierte las entradas de confianza en errores lógicos.
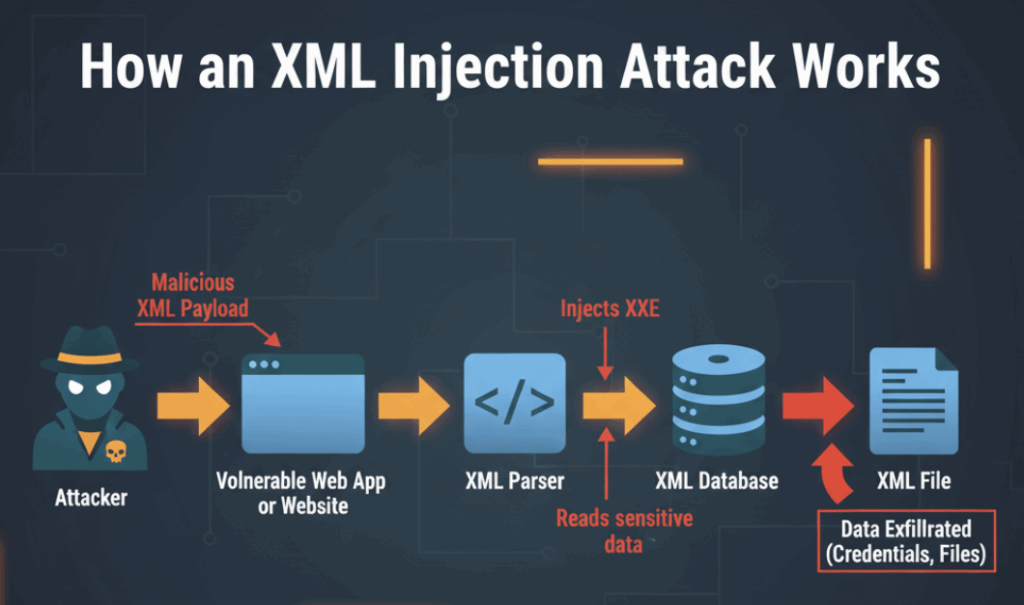
En el fondo, la inyección XML no es un único exploit. Es una familia de comportamientos en los que el XML controlado por el atacante cambia la forma en que un servidor interpreta una solicitud. Eso puede significar que una consulta XPath devuelva de repente registros inesperados, que un analizador resuelva recursos externos que no se pretendía que llamara o que la expansión de entidades consuma CPU y memoria. Desde el punto de vista de un atacante, estos son bloques de construcción prácticos: leer archivos, desencadenar peticiones internas o causar un caos útil. Desde el punto de vista de un defensor, las mismas piezas son un mapa de navegación para solucionar las lagunas de lógica y observabilidad.
Una pequeña muestra concreta - sin dar a nadie un libro de jugadas
No necesita cargas útiles sofisticadas para ver el patrón. Imagina un código del lado del servidor que construye un XPath a partir de campos de solicitud mediante una concatenación ingenua de cadenas:
// patrón vulnerable (pseudo)
userId = request.xml.user.id
rol = request.xml.user.role
query = "doc('/db/users.xml')/users/user[id = " + userId + " and role = '" + role + "']"
resultado = xmlEngine.evaluate(query)
Esto parece inofensivo si userId y papel están bien formadas. Pero cuando dejas que la entrada del usuario controle la estructura de la consulta, estás difuminando la frontera entre datos y lógica. La inyección XPath es la consecuencia natural: una consulta frágil puede ser manipulada para alterar las condiciones de verdad y devolver filas que no debería.
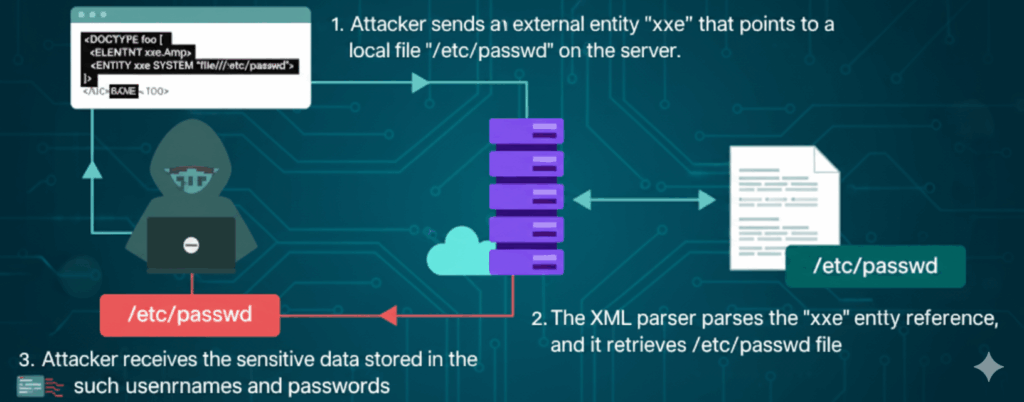
Otro eje es el manejo de entidades o DTD. Muchos motores XML permiten declaraciones de tipo de documento, entidades y referencias externas, algo útil para la composición legítima, pero peligroso cuando se activa para entradas no fiables. La regla defensiva es sencilla: si no necesitas la expansión de entidades o el procesamiento de DOCTYPE, desactívalo.
Por qué el análisis de la configuración es más importante que las hazañas arcanas
Este problema tiene dos niveles. El primero es el error de la lógica de negocio: pasar valores no fiables a la lógica de consulta, plantillas XML en XPath o evaluadores similares a XPath y asumir que "bien formado" significa "seguro". Esto se puede solucionar mediante el diseño: validar, canonicalizar y separar los datos de las consultas.
El segundo es el comportamiento del analizador sintáctico. Los analizadores XML son potentes; pueden obtener el contenido de archivos, hacer peticiones HTTP o expandir entidades anidadas que llenan la memoria de globos. Estas capacidades están bien en contextos controlados, pero son desastrosas cuando se aceptan entradas públicas. Así que la defensa práctica es el endurecimiento del analizador y la telemetría del comportamiento.
Contramedidas prácticas y fáciles de aplicar (con ejemplos)
No tienes que prohibir el XML para estar seguro. Sí necesitas tres cambios habituales:
1) Limitar la capacidad del analizador sintáctico. En la mayoría de los lenguajes se puede desactivar el procesamiento de entidades externas y DOCTYPE. Por ejemplo, en Java (pseudo-API):
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setFeature("", true);
dbf.setFeature("", false);
dbf.setFeature("", false);
O en Python con defusedxml (utilice una biblioteca que tenga un comportamiento seguro por defecto):
from defusedxml.ElementTree import fromstring
tree = fromstring(untrusted_xml)
2) Validar y canonizar. Si su endpoint sólo necesita un pequeño conjunto de etiquetas, valide contra un XSD o rechace DOCTYPEs inesperados. Prefiera el análisis sintáctico en estructuras de datos y el uso de acceso parametrizado en lugar de construir consultas por concatenación de cadenas.
3) Instrumento y alerta. Añade ganchos que detecten señales extrañas: excepciones del analizador que hagan referencia a DOCTYPE/ENTITY, DNS/HTTP salientes repentinos del servicio de análisis o operaciones de apertura de archivos iniciadas durante el análisis. Estas señales son mucho más procesables que cualquier lista de reglas estáticas.
Señales detectables que realmente ayudan a los defensores
Cuando ajuste la supervisión, busque comportamientos reales, no frágiles firmas textuales:
- Llamadas DNS o HTTP salientes originadas en su proceso de análisis.
- Intentos de acceso a archivos en rutas locales durante la manipulación de XML.
- Trazas de excepciones del analizador sintáctico que mencionan DOCTYPE o la resolución de entidades externas.
- Respuestas que de repente incluyen campos o datos sólo internos (indicando manipulación XPath o query).
- Picos inusuales de CPU/memoria en el código de análisis bajo carga normal.
Ésas son las cosas sobre las que puedes alertar y clasificar rápidamente.
Cómo practicar sin ser imprudente
Si quieres experimentar -verificar las reglas de detección, confirmar que el parser hardening funciona, o entrenarte en un desafío tipo CTF- hazlo sólo en laboratorios controlados. No ponga XML malformado en producción. En su lugar, utilice máquinas virtuales aisladas, intervalos de laboratorio demostrables o herramientas que generen higienizado, no explotador casos de prueba.
Flujo de trabajo en lenguaje natural - Penligent en el bucle
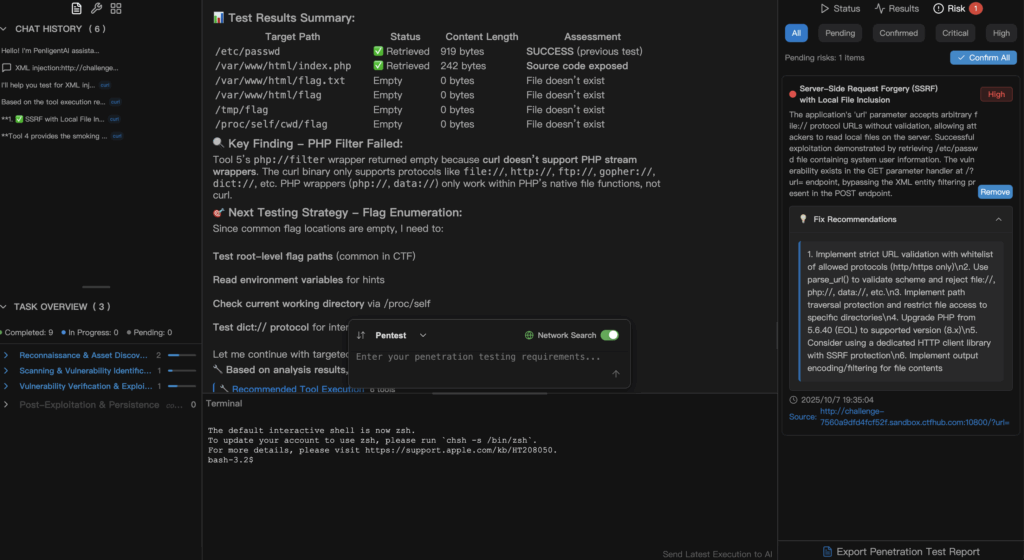
Aquí es donde la automatización práctica merece la pena. No debería tener que codificar a mano docenas de pruebas sólo para validar la configuración del analizador sintáctico o la lógica de detección. Con una herramienta de pentest basada en lenguaje natural como PenligenteEn el lenguaje cotidiano, el flujo es el siguiente:
"Compruebe nuestros puntos finales SOAP en busca de riesgos de inyección XML. Utilice sólo sondas seguras, recopile excepciones del analizador, eventos de acceso a archivos y cualquier devolución de llamada DNS/HTTP saliente. Produzca pasos de refuerzo priorizados".
Penligent convierte esa frase en comprobaciones específicas y desinfectadas contra su entorno de pruebas autorizado. Ejecuta casos de prueba específicos (no cadenas de exploits en vivo), recopila telemetría (errores de analizador, registros de acceso a archivos, devoluciones de llamada DNS), correlaciona las pruebas y devuelve una lista de comprobación de corrección concisa. Para los jugadores de CTF, la ventaja es la velocidad: puedes validar una hipótesis y saber si tu detección se habría disparado, y luego repetirlo, sin escribir scripts de shell ni crear docenas de archivos de carga útil.
Reflexión final
La inyección de XML parece poco espectacular en una tabla de vulnerabilidades, pero su verdadero poder es el sigilo. Se aprovecha de suposiciones: que la capa de datos es inofensiva, que el analizador sintáctico se comporta "como se espera", que la supervisión detectará fallos evidentes. Su solución no depende tanto de un parche mágico como de la higiene del diseño: minimizar los privilegios del analizador sintáctico, separar los datos de la lógica, validar de forma agresiva e instrumentar las señales que importan. Las herramientas que convierten la intención del lenguaje natural en ejecuciones de validación seguras eliminan la pesadez y permiten a los equipos centrarse en la corrección y el aprendizaje, que es exactamente el objetivo de la automatización defensiva moderna.

