Kubernetes orchestration is a privilege distribution system before it is a deployment system. It schedules containers, but it also hands workloads identities, mounts Secrets, opens service paths, applies admission decisions, exposes Ingress behavior, and asks a container runtime to enforce Linux boundaries that were never designed as a perfect wall. A production cluster fails when those decisions drift apart.
A single vulnerable app container is not always a cluster compromise. A single overpowered service account is not always an incident. A single exposed webhook is not always exploitable from the public internet. The danger appears when orchestration joins them: a web bug reaches a Pod, the Pod has a token, the token can read Secrets, an admission controller is reachable from the Pod network, NetworkPolicy does not block egress, and audit logs do not preserve enough evidence to reconstruct the path.
The Kubernetes project describes Kubernetes as an open-source container orchestration engine for automating deployment, scaling, and management of containerized applications. NSA and CISA’s hardening guidance uses the same framing, but immediately adds the security caveat: clusters are complex to secure and are often abused through misconfigurations. (Kubernetes)
That is the right starting point for Kubernetes orchestration security. The question is not whether Kubernetes is secure or insecure. The question is whether the cluster’s control plane, identities, Secrets, network paths, admission rules, runtime constraints, and observability match the blast radius you think you have.
Kubernetes orchestration changed the security boundary
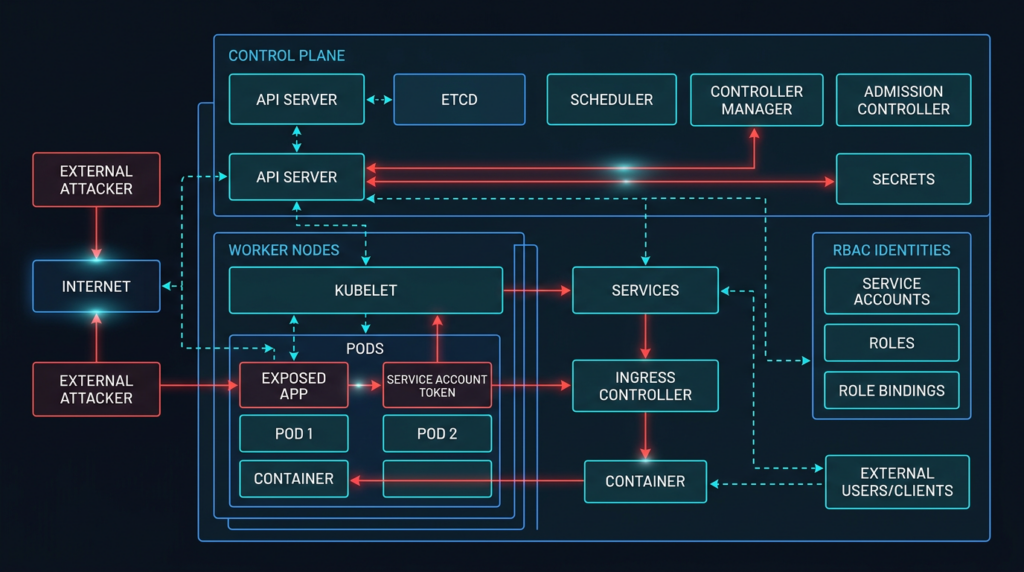
A traditional application stack often has a small number of long-lived servers, explicit network tiers, and a relatively static set of credentials. Kubernetes moves that model into an API-driven control system. The API server becomes the front door for nearly every meaningful cluster action. Controllers continuously reconcile desired state. The scheduler places Pods on nodes. The kubelet starts and monitors containers. Services and Ingress controllers route traffic. Secrets and ConfigMaps inject runtime configuration. RBAC determines who can make API calls. Admission controllers decide whether an object should be persisted. Runtime profiles decide what a process can do after it starts.
NSA and CISA describe the control plane as the part of Kubernetes that makes cluster decisions, including scheduling containers, responding to failures, and starting new Pods when replicas are missing. They identify the API server, etcd, scheduler, controller manager, and optional cloud controller manager as control plane components, while worker nodes run kubelet and kube-proxy to support workload execution and routing.
That architecture means a Kubernetes security review has to ask a different class of questions. Can this identity create a Pod? Can that Pod mount a Secret? Can a compromised workload reach the API server or an admission webhook? Can it talk to the cloud metadata service? Can it run as root, add Linux capabilities, mount hostPath, or join the host network namespace? Can a controller with broad permissions be influenced by a namespace-scoped user? Can logs prove what happened?
| Capa | Qué controla | Common failure | Real risk |
|---|---|---|---|
| API server | Cluster object access and state changes | Public or overly broad access, weak authentication, missing audit policy | Attackers interact directly with cluster state |
| RBAC | Who can do what against Kubernetes resources | Wildcards, cluster-admin bindings, overpowered service accounts | Namespace issue becomes cluster-wide privilege |
| Secretos | Credentials and sensitive runtime data | Unencrypted etcd storage, broad Secret read access, environment variable leakage | Credential theft and cloud pivoting |
| NetworkPolicy | Pod ingress and egress constraints | No default deny, unsupported CNI, missing egress limits | Lateral movement and SSRF-to-internal-service paths |
| Admission control | Object validation before persistence | Missing policy, insecure webhooks, fail-open behavior | Unsafe workloads enter the cluster |
| Runtime | Linux process, filesystem, and kernel boundary | privileged Pods, hostPath, hostNetwork, weak seccomp or AppArmor | Container breakout impact increases |
| Ingress and controllers | External routing and controller automation | Controller has high privileges and is reachable from untrusted paths | Edge flaw turns into cluster Secret exposure |
| Observability | Evidence and response visibility | Audit disabled, logs stored only in cluster, short retention | Slow triage and uncertain scope |
The common theme is not “Kubernetes is hard.” The common theme is that orchestration connects controls. A safe-looking permission can become dangerous when paired with workload creation. A safe-looking network path can become dangerous when it reaches a privileged controller. A safe-looking Secret can become dangerous when mounted into a noisy app that logs its environment.
The production misconfigurations that matter most
Most serious cluster security failures are not exotic. They are boring decisions that looked reasonable at the time.
The Kubernetes API server is reachable from too many places. A CI/CD service account gets cluster-admin because a deployment failed once and nobody had time to design a narrower role. A default service account token is mounted into every Pod even when the workload never calls the Kubernetes API. A namespace is treated as a security boundary even though no NetworkPolicy isolates it. A Pod runs with hostNetwork because DNS broke during an outage. A team uses latest tags because the release pipeline is moving fast. A cluster has audit logs, but only on nodes that an attacker can delete or overwhelm.
NSA and CISA’s high-level recommendations map closely to these failures: run containers as non-root where possible, avoid privileged containers and common breakout-enabling features, scan images, use network policies, encrypt etcd and Secrets, create unique RBAC roles, enable audit logging, persist logs outside fragile runtime locations, and apply patches promptly.
The mistake is treating those recommendations as independent checklist items. In a real attack path, they compound. If Secrets are not encrypted at rest, etcd access is worse. If RBAC allows too many users to read Secrets, encryption at rest does not help against authorized API reads. If a compromised Pod can create new Pods, Secret restrictions may be bypassed indirectly. If egress is open, internal-only services become reachable from an exploited app. If audit logs are missing, the incident response team cannot tell which path was used.
A better model is to think in graph terms. Every identity, object, controller, node, and network path is a node in the graph. Every permission, mount, route, webhook, and token is an edge. Kubernetes orchestration security is the work of removing unnecessary edges and proving the important ones are constrained.
RBAC is additive, so bad grants accumulate
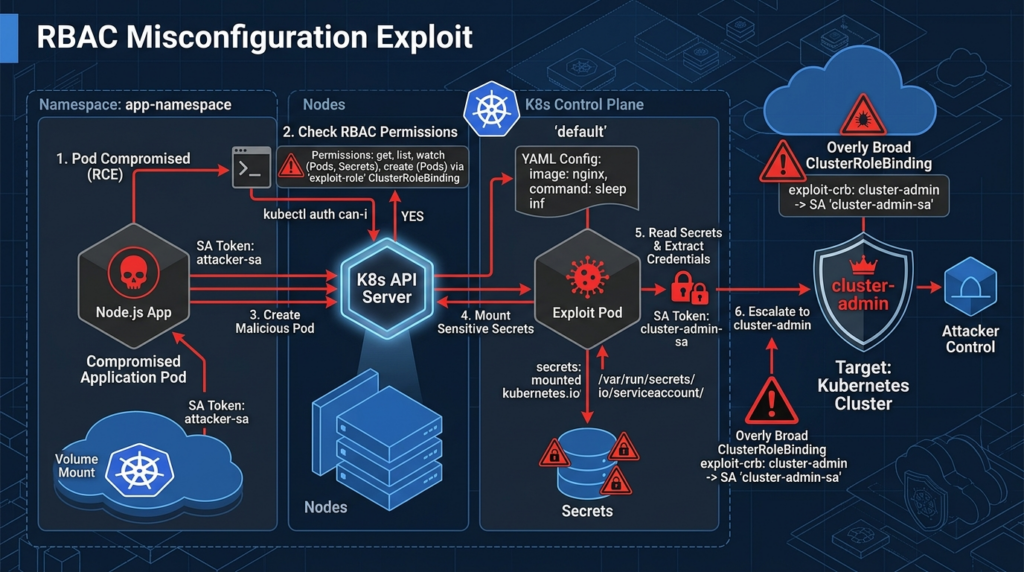
Kubernetes RBAC uses Role, ClusterRole, RoleBinding, and ClusterRoleBinding objects. A Role grants permissions inside a namespace. A ClusterRole is non-namespaced and can define cluster-wide permissions. A RoleBinding attaches a Role or ClusterRole to a subject within a namespace. A ClusterRoleBinding attaches a ClusterRole to a subject across the cluster. Kubernetes RBAC permissions are additive; there are no deny rules. (Kubernetes)
That additive model is easy to underestimate. In systems with deny rules, a dangerous grant might be counterbalanced later. In Kubernetes RBAC, once a subject has permission from any binding, that permission exists. Cleanup requires removing or changing the grant, not adding a denial somewhere else.
Kubernetes’ own RBAC good practices warn operators to assign minimal rights, prefer namespace-level permissions where possible, avoid wildcard permissions, avoid unnecessary cluster-admin usage, avoid adding users to system:masters, limit privileged tokens, and avoid default service account token auto-mounting where workloads do not need Kubernetes API access. (Kubernetes)
A safe starting Role looks narrow:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: payments
name: pod-read-only
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
The binding should also be scoped:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
namespace: payments
name: payments-debug-read-pods
subjects:
- kind: Group
name: payments-debuggers
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-read-only
apiGroup: rbac.authorization.k8s.io
That role lets the group inspect Pods in one namespace. It does not let them create Pods, exec into Pods, read Secrets, change Deployments, approve certificate signing requests, bind themselves to stronger roles, or affect other namespaces.
A dangerous pattern looks like this:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: ci-admin-shortcut
subjects:
- kind: ServiceAccount
name: deployer
namespace: ci
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
This kind of shortcut is common because it fixes deployment friction. It also turns a CI token into a cluster takeover primitive. If the CI system is compromised, if a build step can print environment variables, or if a developer can run arbitrary pipeline code, the attacker may inherit cluster-admin.
The risky RBAC permissions are often not obvious from the name alone.
| Permission pattern | Por qué es importante | Safer design |
|---|---|---|
verbs: ["*"] | Grants future verbs too, not only the ones you remember today | Use exact verbs required by the workflow |
resources: ["*"] | Applies to current and future resource types, including CRDs | Grant specific resources and review when CRDs change |
cluster-admin | Full control over the cluster | Reserve for tightly controlled break-glass identities |
consiga, lista, ver en secrets | Direct credential access | Limit to exact names only when unavoidable |
create en pods o deployments | Can be used to run a workload with mounted credentials available in the namespace | Separate deployment automation from human debugging |
create en pods/exec | Allows command execution inside existing Pods | Treat as privileged operational access |
vincular | Can attach roles to subjects | Restrict to trusted platform admins |
escalate | Can create or update roles with permissions the caller does not already hold | Rarely needed outside admin workflows |
impersonate | Can act as another user, group, or service account | Monitor closely and bind narrowly |
| CSR approval permissions | Can issue client certificates under some configurations | Separate certificate approval from application teams |
NSA and CISA’s guidance also calls out RBAC as an authorization boundary and notes that Roles and ClusterRoles only add permissions. It further states that RoleBindings and ClusterRoleBindings tie those permissions to users, groups, or service accounts, and that privileges should follow least privilege across users, administrators, developers, service accounts, and infrastructure teams.
Useful RBAC checks should be part of normal cluster operations:
kubectl auth can-i list secrets \
--as=system:serviceaccount:payments:web \
-n payments
kubectl auth can-i create pods \
--as=system:serviceaccount:payments:web \
-n payments
kubectl get clusterrolebindings -o wide | grep cluster-admin
kubectl get rolebindings,clusterrolebindings \
--all-namespaces \
-o jsonpath='{range .items[*]}{.metadata.namespace}{" "}{.metadata.name}{" -> "}{.roleRef.kind}/{.roleRef.name}{"\n"}{end}'
The goal is not to prove that every identity has zero permissions. The goal is to prove that every permission has a reason, a scope, an owner, and a review path.
Service accounts are workload identities, not harmless defaults
A Kubernetes service account is not a label. It is a workload identity. When a Pod receives a service account token, the workload can use it to call the Kubernetes API. If that token is mounted into an app that never needed Kubernetes access, the cluster has created an unnecessary credential exposure.
Kubernetes RBAC good practices explicitly recommend avoiding default service account token auto-mounting by setting automountServiceAccountToken: false, while still allowing workloads that need tokens to mount them intentionally. (Kubernetes)
Use service account defaults defensively:
apiVersion: v1
kind: ServiceAccount
metadata:
name: web
namespace: payments
automountServiceAccountToken: false
For workloads that do need API access, make it explicit and narrow:
apiVersion: apps/v1
kind: Deployment
metadata:
name: payments-api
namespace: payments
spec:
replicas: 3
selector:
matchLabels:
app: payments-api
template:
metadata:
labels:
app: payments-api
spec:
serviceAccountName: payments-reader
automountServiceAccountToken: true
containers:
- name: app
image: registry.example.com/payments-api@sha256:REPLACE_WITH_DIGEST
Then test exactly what the workload can do:
kubectl auth can-i get pods \
--as=system:serviceaccount:payments:payments-reader \
-n payments
kubectl auth can-i list secrets \
--as=system:serviceaccount:payments:payments-reader \
-n payments
If the second command returns yes, the service account has a credential path that needs a strong justification.
Kubernetes Secrets reduce accidental exposure, but they are not a vault by default
A Kubernetes Secret is an API object for a small amount of sensitive data such as a password, token, or key. The official documentation says Secrets are intended for confidential data and reduce the need to place sensitive values directly in Pod specifications or container images. That is useful, but the same documentation warns that Kubernetes Secrets are stored unencrypted in the API server’s underlying data store by default, and that anyone with API access or etcd access can retrieve or modify them. It also warns that anyone authorized to create a Pod in a namespace can use that access to read any Secret in that namespace, including indirectly through workload creation. (Kubernetes)
This is one of the most important Kubernetes orchestration security lessons: Secret safety is not only a storage property. It is an authorization, scheduling, mounting, logging, and runtime property.
Kubernetes supports encryption of API resource data at rest. The official task documentation states that Kubernetes APIs supporting persistent resource data support at-rest encryption, including Secrets, and that this encryption is additional to system-level encryption for etcd or host filesystems. It also notes that without an --encryption-provider-config, the API server stores plaintext resource representations in etcd. (Kubernetes)
A Secret threat model should include at least these paths:
| Secret exposure path | Condición desencadenante | Detection signal | Mitigación |
|---|---|---|---|
| etcd plaintext | Encryption at rest not enabled | API server lacks encryption provider config | Enable Secret encryption and protect etcd access |
| Kubernetes API read | Subject can consiga, listao ver Secretos | Audit event for Secret read | Remove broad Secret read permissions |
| Indirect Pod mount | Subject can create Pods in namespace | New Pod mounts unexpected Secret | Restrict workload creation and use admission policy |
| Environment variable leakage | Secret injected into env and app logs env or crashes | Logs contain keys or token-like strings | Prefer file mounts and avoid noisy env dumps |
| Controller access | Controller service account can read many Secrets | Controller token has cluster-wide Secret access | Narrow controller RBAC where supported |
| CSI or driver logs | Storage or driver component logs tokens under specific settings | Verbose component logs include service account tokens | Patch driver and avoid sensitive verbose logging |
| Node compromise | Attacker gets root on node running Pods with mounted Secrets | Node-level access to Pod volumes and kubelet state | Harden nodes, isolate sensitive workloads, rotate Secrets |
CVE-2024-3744 shows why logs belong in the Secret threat model. NVD describes a vulnerability in azure-file-csi-driver where an actor with access to driver logs could observe service account tokens when TokenRequests was configured in the CSIDriver object and the driver ran at log level 2 or greater. Those tokens could potentially be exchanged with external cloud providers to access secrets stored in cloud vault solutions. (NVD)
CVE-2024-3177 shows why admission controls around Secrets should not be treated as a perfect boundary. NVD describes a Kubernetes issue where users could launch containers that bypassed the mountable secrets policy enforced by the ServiceAccount admission plugin when containers, init containers, or ephemeral containers used envFrom. (NVD)
Those CVEs do not mean Kubernetes Secrets are broken as a concept. They mean defenders should layer controls: least-privilege RBAC, encryption at rest, narrow service accounts, admission checks, external secret stores where appropriate, log hygiene, and rotation.
A safer workload pattern avoids default token mounting and uses read-only Secret volumes:
apiVersion: apps/v1
kind: Deployment
metadata:
name: billing-worker
namespace: payments
spec:
replicas: 2
selector:
matchLabels:
app: billing-worker
template:
metadata:
labels:
app: billing-worker
spec:
serviceAccountName: billing-worker
automountServiceAccountToken: false
containers:
- name: worker
image: registry.example.com/billing-worker@sha256:REPLACE_WITH_DIGEST
volumeMounts:
- name: db-credentials
mountPath: /run/secrets/db
readOnly: true
volumes:
- name: db-credentials
secret:
secretName: billing-db
This is not a universal rule. Some applications need environment variables. Some need service account tokens. Some use external secret stores. The important point is intentionality. A Secret should not become available to a workload because a chart default said so.
Namespaces are not network isolation
Namespaces organize resources and support scoped RBAC, quotas, and policy. They do not automatically isolate network traffic. Kubernetes NetworkPolicy is the built-in API for controlling traffic flow at OSI layer 3 or 4 between Pods and between Pods and the outside world, but it requires a network plugin that supports NetworkPolicy enforcement. Creating a NetworkPolicy object without an enforcing controller has no effect. (Kubernetes)
The official documentation also states that Pods are non-isolated for egress by default, meaning all outbound connections are allowed unless an egress NetworkPolicy selects the Pod. Pods are also non-isolated for ingress by default unless an ingress NetworkPolicy selects them. Once isolated, only traffic allowed by applicable policies is permitted. Policies are additive, and order does not determine the result. (Kubernetes)
NSA and CISA make the same operational point from a hardening perspective: by default, no network policies are applied to Pods or namespaces, which results in unrestricted ingress and egress traffic within the Pod network. They recommend using a CNI plugin that supports NetworkPolicy, creating default deny policies for ingress and egress, and then relaxing restrictions only for permitted connections.
A default deny policy should exist early, not after the first incident:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress-egress
namespace: payments
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
Then allow the specific application path:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-api-to-postgres
namespace: payments
spec:
podSelector:
matchLabels:
app: postgres
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
app: payments-api
ports:
- protocol: TCP
port: 5432
Egress deserves the same attention. An exploited application with open egress can often reach internal admin panels, metadata services, webhook endpoints, service meshes, and other Pods. Egress policy will not fix application-layer vulnerabilities, but it can stop a web bug from becoming a cluster discovery tool.
CVE-2024-7598 is a useful reminder that network controls can have lifecycle edge cases. NVD describes a Kubernetes issue where a malicious or compromised Pod could bypass network restrictions enforced by NetworkPolicies during namespace deletion because object deletion order is not defined and NetworkPolicies may be deleted before the Pods they protect. That creates a brief period where Pods are still running but their network policies may no longer apply. (NVD)
That does not make NetworkPolicy optional. It means mature environments should test lifecycle states too: namespace deletion, rollout rollback, CNI upgrades, node drain, policy controller restarts, and emergency remediation workflows.
Admission control is the change gate
Admission control sits after authentication and authorization but before an object is persisted. Kubernetes documentation describes an admission controller as code that intercepts requests to the API server before resource persistence. Admission controllers can validate, mutate, or do both; they apply to create, update, delete, and some custom connect-style requests, but they do not block read requests such as consiga, listao ver. (Kubernetes)
That placement makes admission control a strong prevention layer for unsafe desired state. It is not an investigation layer, not a Secret-read control, and not a runtime detector. It prevents bad objects from entering the cluster.
Pod Security Admission is the built-in mechanism for enforcing Pod Security Standards. Kubernetes marks Pod Security Admission stable as of v1.25. It applies restrictions at namespace level and supports the privileged, línea de basey restricted levels. It also supports enforce, audity warn modes through namespace labels. (Kubernetes)
A practical rollout often starts with warning and audit before enforcement:
kubectl label namespace payments \
pod-security.kubernetes.io/warn=restricted \
pod-security.kubernetes.io/audit=restricted \
pod-security.kubernetes.io/enforce=baseline \
--overwrite
After teams fix violations, enforcement can move toward restricted:
kubectl label namespace payments \
pod-security.kubernetes.io/enforce=restricted \
pod-security.kubernetes.io/enforce-version=latest \
--overwrite
Pod Security Admission is intentionally broad. For organization-specific rules, teams often add ValidatingAdmissionPolicy, OPA Gatekeeper, Kyverno, or a similar policy engine. The key is to prevent high-risk runtime settings before they start.
Example Kyverno policy blocking privileged containers:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: disallow-privileged-containers
spec:
validationFailureAction: Enforce
rules:
- name: privileged-containers
match:
any:
- resources:
kinds:
- Pod
validate:
message: "Privileged containers are not allowed."
pattern:
spec:
containers:
- =(securityContext):
=(privileged): "false"
Example policy blocking latest image tags:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-image-digest
spec:
validationFailureAction: Enforce
rules:
- name: image-must-use-digest
match:
any:
- resources:
kinds:
- Pod
validate:
message: "Images must be pinned by digest."
pattern:
spec:
containers:
- image: "*@sha256:*"
Admission control should also protect RBAC objects. A policy that blocks wildcard verbs or wildcard resources can prevent risky changes from reaching production:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: block-rbac-wildcards
spec:
validationFailureAction: Enforce
rules:
- name: no-wildcard-verbs
match:
any:
- resources:
kinds:
- Role
- ClusterRole
validate:
message: "Wildcard RBAC verbs are not allowed."
deny:
conditions:
any:
- key: "{{ request.object.rules[].verbs[] }}"
operator: AnyIn
value: ["*"]
- name: no-wildcard-resources
match:
any:
- resources:
kinds:
- Role
- ClusterRole
validate:
message: "Wildcard RBAC resources are not allowed."
deny:
conditions:
any:
- key: "{{ request.object.rules[].resources[] }}"
operator: AnyIn
value: ["*"]
The policy language is less important than the operating model. Admission policies should be version-controlled, tested in staging, rolled out with audit or warn mode when possible, and reviewed after incidents. A broken policy engine can block releases. A fail-open policy can admit unsafe workloads. Both are operational risks.
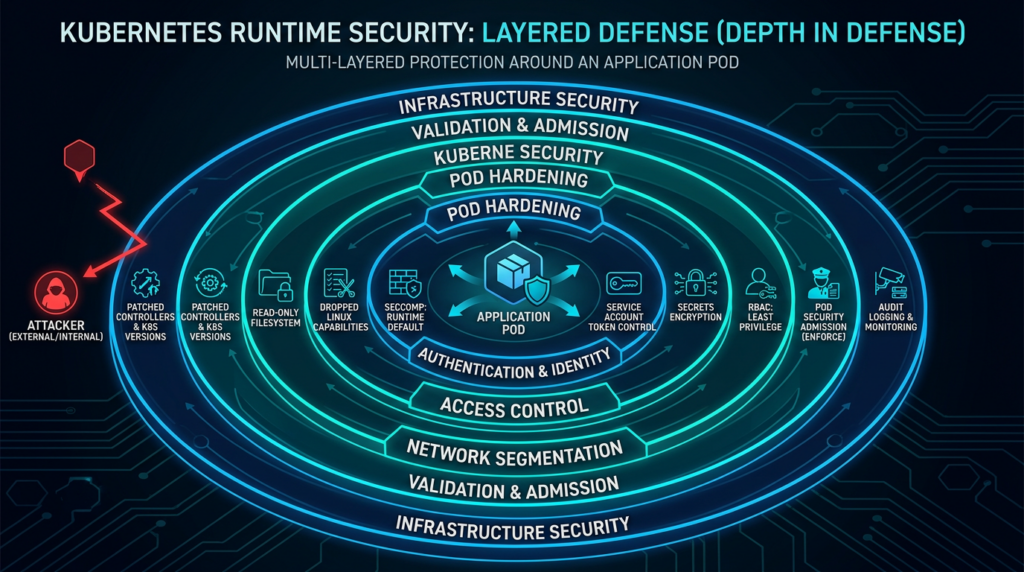
Runtime risk starts after the Pod is admitted
A safe admission decision does not guarantee a safe runtime. Once a Pod starts, the kernel, container runtime, node configuration, Linux capabilities, mounted volumes, and process behavior matter.
Kubernetes security context lets operators control settings such as Linux capabilities, seccomp profiles, AppArmor profiles, SELinux labels, non-root users, privilege escalation, and read-only filesystems. Kubernetes documentation shows that Linux capabilities can be added or dropped in securityContext, and that seccomp can be set to RuntimeDefault, Unconfinedo Localhost. It also documents AppArmor profile settings and notes that AppArmor support depends on node configuration. (Kubernetes)
A hardened Pod spec should look boring:
apiVersion: apps/v1
kind: Deployment
metadata:
name: inventory-api
namespace: inventory
spec:
replicas: 3
selector:
matchLabels:
app: inventory-api
template:
metadata:
labels:
app: inventory-api
spec:
serviceAccountName: inventory-api
automountServiceAccountToken: false
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
containers:
- name: api
image: registry.example.com/inventory-api@sha256:REPLACE_WITH_DIGEST
ports:
- containerPort: 8080
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
capabilities:
drop:
- ALL
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "512Mi"
This spec does several things at once. It avoids unnecessary service account token mounting. It requires non-root execution. It asks for the runtime default seccomp profile. It blocks privilege escalation. It drops Linux capabilities. It uses a read-only root filesystem. It sets resource requests and limits.
No single line makes the workload safe. The value comes from forcing an attacker to defeat multiple boundaries instead of inheriting broad capabilities by default.
Runtime risk checks should be automated:
kubectl get pods --all-namespaces \
-o jsonpath='{range .items[*]}{.metadata.namespace}{" "}{.metadata.name}{" privileged="}{.spec.containers[*].securityContext.privileged}{" hostNetwork="}{.spec.hostNetwork}{"\n"}{end}'
kubectl get pods --all-namespaces \
-o jsonpath='{range .items[*]}{.metadata.namespace}{" "}{.metadata.name}{" hostPath="}{.spec.volumes[*].hostPath.path}{"\n"}{end}'
kubectl get pods --all-namespaces \
-o jsonpath='{range .items[*]}{.metadata.namespace}{" "}{.metadata.name}{" serviceAccount="}{.spec.serviceAccountName}{" automount="}{.spec.automountServiceAccountToken}{"\n"}{end}'
The most important findings are usually Pods that combine multiple risky attributes: privileged plus hostPath, hostNetwork plus broad service account, writable root filesystem plus Secret env vars, or public-facing workload plus mounted Kubernetes token.
Ingress controllers can turn edge bugs into cluster bugs
Ingress controllers sit at a dangerous intersection. They handle external traffic, translate user-defined Kubernetes objects into proxy behavior, and often need enough Kubernetes API access to watch Services, Endpoints, Secrets, and Ingress objects. When their admission or configuration path is vulnerable, the blast radius can reach far beyond HTTP routing.
CVE-2025-1974 is the cleanest recent example. NVD describes it as a Kubernetes security issue where, under certain conditions, an unauthenticated attacker with access to the Pod network can achieve arbitrary code execution in the context of the ingress-nginx controller, leading to disclosure of Secrets accessible to the controller. NVD also notes that in the default installation, the controller can access all Secrets cluster-wide. (NVD)
The Kubernetes project’s own advisory-style blog told users to determine whether clusters were using ingress-nginx with kubectl get pods --all-namespaces --selector app.kubernetes.io/name=ingress-nginx, then remediate immediately. It recommended upgrading to patched ingress-nginx releases, and, if an immediate upgrade was not possible, reducing risk by disabling the ingress-nginx Validating Admission Controller feature temporarily. The same post warned operators to turn that feature back on after upgrading because it catches incorrect Ingress configurations before they take effect. (Kubernetes)
Wiz Research, which discovered the IngressNightmare vulnerability chain, described a set of unauthenticated RCE vulnerabilities in Ingress NGINX Controller for Kubernetes and stated that successful exploitation could lead to unauthorized access to Secrets across namespaces and potential cluster takeover. Wiz also recommended updating, ensuring the admission webhook endpoint was not externally exposed, enforcing strict network policies so only the API server can access the admission controller, and temporarily disabling the admission controller only when immediate patching was not possible. (wiz.io)
The operational lesson is broader than ingress-nginx. Any controller with high privileges deserves a controller-specific threat model:
| Controller question | Por qué es importante |
|---|---|
| What service account does it run as? | Determines API blast radius after controller compromise |
| Which Secrets can it read? | Determines credential exposure |
| Which webhooks or admin ports are reachable from Pods? | Determines whether an internal app compromise can reach controller internals |
| Does it process user-controlled annotations or custom resources? | Determines injection surface |
| Is it pinned to a patched version? | Determines known CVE exposure |
| Are audit logs capturing its API actions? | Determines incident reconstruction quality |
| Is network access restricted to expected callers? | Reduces exploitability of internal-only components |
Check ingress-nginx presence and webhook configuration:
kubectl get pods --all-namespaces \
--selector app.kubernetes.io/name=ingress-nginx
kubectl get validatingwebhookconfigurations \
| grep -i ingress
kubectl get service -A \
| grep -i ingress
Then inspect the controller service account:
kubectl get pods -A \
--selector app.kubernetes.io/name=ingress-nginx \
-o jsonpath='{range .items[*]}{.metadata.namespace}{" "}{.metadata.name}{" sa="}{.spec.serviceAccountName}{"\n"}{end}'
kubectl auth can-i list secrets \
--as=system:serviceaccount:ingress-nginx:ingress-nginx \
--all-namespaces
The precise namespace and service account name vary by installation. The method is what matters: identify the controller identity, test its Secret access, test webhook reachability, verify version, and prove the remediation state.
Kubernetes CVEs worth understanding as design failures
CVE lists can become noise. For Kubernetes orchestration security, the useful CVEs are the ones that teach how boundaries fail.
| CVE | Component or area | Why it matters to Kubernetes orchestration security | Practical defensive takeaway |
|---|---|---|---|
| CVE-2025-1974 | ingress-nginx admission/controller path | Shows how Pod network reachability, controller privileges, and Secret access can combine into cluster-wide impact | Patch ingress-nginx, restrict webhook reachability, review controller RBAC |
| CVE-2024-3177 | ServiceAccount admission and mountable Secrets policy | Shows that Secret boundary assumptions can fail through workload fields like envFrom | Patch, restrict Pod creation, avoid relying on one admission rule |
| CVE-2024-3744 | azure-file-csi-driver logging of service account tokens | Shows that storage drivers and logs can become credential exposure paths | Patch drivers, avoid verbose sensitive logging, protect logs |
| CVE-2024-7598 | NetworkPolicy during namespace termination | Shows that lifecycle operations can temporarily weaken network restrictions | Test deletion and rollback states, do not rely on a single network control |
| CVE-2023-2727 | ImagePolicyWebhook and ephemeral containers | Shows that debug and ephemeral container features can bypass policy if not handled | Patch, include ephemeral containers in policy coverage, audit debug access |
CVE-2023-2727 is especially useful for platform teams because it involves policy bypass through ephemeral containers when ImagePolicyWebhook is used. NVD states that users may be able to launch containers using images restricted by ImagePolicyWebhook when using ephemeral containers, and that clusters are affected only if ImagePolicyWebhook is used together with ephemeral containers. (NVD)
The thread across these issues is not that every cluster is affected by every CVE. Many are conditional. The lesson is that Kubernetes features interact. Debug containers, envFrom, CSI TokenRequests, admission webhooks, namespace deletion, and controller service accounts all sit on orchestration boundaries. Conditional bugs become serious when the environment provides the missing condition.
Audit logs are the difference between suspicion and proof
Kubernetes audit logging records API activity. The official documentation says audit records begin inside the kube-apiserver, each request at each stage can generate an audit event, and the audit policy determines what is recorded and where backends persist those records. Supported stages include RequestReceived, ResponseStarted, ResponseCompletey Panic. (Kubernetes)
NSA and CISA recommend enabling audit logging, persisting logs so they survive node, Pod, or container failure, configuring logs across the environment, aggregating logs outside the cluster, and implementing monitoring and alerting tailored to the cluster.
A useful audit policy does not log everything at maximum verbosity forever. That creates cost, noise, and sensitive data handling problems. It should capture high-risk actions with enough fidelity to answer incident questions.
Example audit policy excerpt:
apiVersion: audit.k8s.io/v1
kind: Policy
rules:
- level: Metadata
verbs: ["get", "list", "watch"]
resources:
- group: ""
resources: ["secrets"]
- level: RequestResponse
verbs: ["create", "update", "patch", "delete"]
resources:
- group: "rbac.authorization.k8s.io"
resources: ["roles", "clusterroles", "rolebindings", "clusterrolebindings"]
- level: RequestResponse
verbs: ["create"]
resources:
- group: ""
resources: ["pods/exec", "pods/attach", "pods/portforward"]
- level: Metadata
verbs: ["create", "update", "patch", "delete"]
resources:
- group: "admissionregistration.k8s.io"
resources: ["validatingwebhookconfigurations", "mutatingwebhookconfigurations"]
- level: Metadata
resources:
- group: ""
resources: ["pods", "services", "configmaps"]
High-value detections include:
| Detection target | Suspicious signal |
|---|---|
| Secret reads | Unusual user, service account, namespace, or bulk list/watch |
| RBAC changes | New ClusterRoleBinding to cluster-admin or wildcard Role update |
| Exec access | pods/exec into sensitive workloads or production namespaces |
| Admission changes | Webhook configuration modified or deleted outside deployment window |
| Service account token use | Token used from unexpected source IP or namespace |
| Namespace deletion | Sensitive namespace termination during active incident |
| Controller behavior | Controller suddenly reading Secrets outside normal pattern |
Logs should leave the cluster quickly. If the attacker can delete Pods, tamper with node files, or exhaust local storage, cluster-local logs may disappear exactly when they are needed most.
Runtime detection needs both Kubernetes and Linux context
Kubernetes audit logs tell you what happened through the API server. They do not tell you everything happening inside a container. Runtime detection fills that gap by watching process execution, file access, network behavior, kernel events, and container metadata.
The Microsoft Threat Matrix for Kubernetes is useful here because it maps cluster-specific techniques to familiar attacker tactics: initial access, execution, persistence, privilege escalation, defense evasion, credential access, discovery, lateral movement, and impact. Examples include exposed dashboards, application exploits, exec into container, privileged containers, writable hostPath mounts, listing Kubernetes Secrets, accessing service account tokens, network mapping, and resource hijacking. (Microsoft)
A runtime alert without Kubernetes context is often too vague. “Shell spawned” matters more if it happened inside a public-facing Pod with a service account that can read Secrets. “Connection to API server” matters more if the workload normally never calls Kubernetes. “Process wrote to /var/run/secrets” matters more if the Pod has a mounted service account token.
Runtime detections that tend to have high value include:
Interactive shell in a non-debug production container
Process reading service account token path
Unexpected kubectl, curl, wget, nc, python, perl, or busybox execution
Connection from app Pod to kube-apiserver
Connection from app Pod to admission webhook service
Outbound connection to cloud metadata endpoint
Write attempt to read-only filesystem path
Mount or access of hostPath-sensitive locations
Cryptomining process names, pool protocols, or sustained abnormal CPU
The 2018 Tesla cryptomining incident remains a useful historical example because it shows how an exposed Kubernetes console can become cloud resource abuse. CyberScoop reported that attackers infiltrated an unprotected Kubernetes console, performed cryptomining, and found exposed AWS S3 credentials tied to Tesla’s environment. (CyberScoop)
The incident is old, but the pattern is current: exposed orchestration admin surface, credential discovery, cloud pivot, resource abuse, and detection difficulty. Modern clusters may use different consoles and managed services, but the attack path still applies.
Supply chain controls belong in admission, not only CI
Image scanning in CI is necessary, but it is not sufficient. Kubernetes admits whatever the API server and admission chain allow. If an attacker can push a new image tag, alter a Helm value, compromise a registry credential, or deploy from a different path, CI scan results may not represent what is actually running.
Kubernetes admission control can enforce image policies at deployment time. The Kubernetes admission controller documentation notes that ImagePolicyWebhook allows a backend webhook to make admission decisions, though it is disabled by default. Kubernetes also supports admission extension points such as MutatingAdmissionWebhook, ValidatingAdmissionWebhook, and ValidatingAdmissionPolicy. (Kubernetes)
A practical supply chain policy should answer:
| Question | Stronger answer |
|---|---|
| Are images pinned? | Use digests, not mutable tags |
| Are images signed? | Verify signature or provenance before admission |
| Are base images minimal? | Reduce package and shell surface |
| Are critical CVEs blocked? | Block deployment or require exception with expiry |
| Are registries restricted? | Only allow trusted registries |
| Are debug images controlled? | Separate debug access from production workloads |
| Are ephemeral containers covered? | Include ephemeral container policy in reviews |
CVE-2023-2727 matters again here because it involved ImagePolicyWebhook and ephemeral containers. If debug paths are excluded from policy, attackers and well-meaning operators may both bypass the controls that protect normal Pods. (NVD)
A practical Kubernetes orchestration security validation workflow
A production validation workflow should produce evidence, not just a pass or fail label. The best results come from combining static inspection, live permission checks, controlled reachability tests, runtime review, and audit evidence.
Start with cluster inventory:
kubectl version
kubectl cluster-info
kubectl get nodes -o wide
kubectl get namespaces
kubectl get apiservices
kubectl get crds
Map controllers and privileged add-ons:
kubectl get deployments,daemonsets,statefulsets -A \
-o wide
kubectl get pods -A \
-o jsonpath='{range .items[*]}{.metadata.namespace}{" "}{.metadata.name}{" sa="}{.spec.serviceAccountName}{" node="}{.spec.nodeName}{"\n"}{end}'
Review RBAC blast radius:
kubectl get clusterrolebindings -o yaml
kubectl get rolebindings -A -o yaml
kubectl auth can-i '*' '*' \
--as=system:serviceaccount:ci:deployer \
--all-namespaces
kubectl auth can-i list secrets \
--as=system:serviceaccount:ci:deployer \
--all-namespaces
Check Pod Security Admission labels:
kubectl get ns \
-o custom-columns=NAME:.metadata.name,ENFORCE:.metadata.labels.pod-security\\.kubernetes\\.io/enforce,WARN:.metadata.labels.pod-security\\.kubernetes\\.io/warn,AUDIT:.metadata.labels.pod-security\\.kubernetes\\.io/audit
Find risky runtime specs:
kubectl get pods -A -o json \
| jq -r '
.items[]
| .metadata.namespace as $ns
| .metadata.name as $pod
| .spec.containers[]
| select(.securityContext.privileged == true
or .securityContext.allowPrivilegeEscalation == true
or (.securityContext.capabilities.add // [] | length > 0))
| "\($ns)/\($pod) container=\(.name)"'
Check NetworkPolicy coverage:
kubectl get networkpolicy -A
kubectl get ns -o name | while read ns; do
name="${ns#namespace/}"
count=$(kubectl get networkpolicy -n "$name" --no-headers 2>/dev/null | wc -l | tr -d ' ')
echo "$name networkpolicies=$count"
done
Check ingress-nginx exposure and version:
kubectl get pods -A \
--selector app.kubernetes.io/name=ingress-nginx \
-o wide
kubectl get validatingwebhookconfigurations \
| grep -i ingress || true
kubectl describe deployment -n ingress-nginx ingress-nginx-controller
Review audit signals after testing:
grep -E '"resource":"secrets"|"resource":"clusterrolebindings"|"resource":"pods/exec"' /var/log/kubernetes/audit.log
In authorized environments, platforms that combine tool execution, scope control, repeated validation, and evidence collection can reduce the gap between “a scanner found something” and “we can prove this path is exploitable or not.” Penligent’s product positioning focuses on AI-assisted pentesting workflows with evidence-first results, and its RBAC-focused Kubernetes article is a relevant companion for teams reviewing how Kubernetes RBAC and cloud IAM interact in real environments. (Penligente) (Penligente)
That kind of workflow is most useful when it stays grounded in cluster facts: the exact service account, exact namespace, exact RBAC verb, exact Secret, exact webhook, exact command output, and exact remediation diff. It should not replace human judgment or official advisories. It should make the evidence easier to reproduce.
Hardening priorities by attack path
Kubernetes hardening is easier when organized around attack paths instead of product categories.
| Attack path | Initial condition | Expansion mechanism | Controls that matter most |
|---|---|---|---|
| App RCE to Secret theft | Public app is exploited | Mounted token or broad service account reads Secrets | Disable unnecessary token mounts, narrow RBAC, Secret audit logs |
| Pod to controller compromise | Compromised Pod reaches internal webhook | Vulnerable controller executes code with high RBAC | NetworkPolicy egress, patch controllers, reduce controller RBAC |
| CI compromise to cluster takeover | CI token has cluster-admin | Pipeline code uses Kubernetes credentials | Dedicated deploy roles, no cluster-admin, short-lived credentials |
| Namespace compromise to lateral movement | Namespace has no default deny | Pod scans and connects to internal services | Default deny ingress and egress, allow-only policies |
| Debug feature abuse | User can create ephemeral containers or exec | Debug shell bypasses image or runtime assumptions | Restrict pods/exec, include ephemeral containers in policy |
| Node compromise to cluster access | Privileged Pod or hostPath exposes host | Attacker reads kubelet data or mounted credentials | Block privileged and hostPath, node hardening, workload isolation |
| Secret leakage through logs | App or driver logs sensitive data | Logs stored broadly or shipped externally | Log redaction, patch drivers, avoid env Secret injection |
The highest return usually comes from five moves:
First, remove cluster-admin from anything that is not a tightly controlled break-glass path.
Second, disable service account token auto-mounting by default and make API access intentional.
Third, enforce Pod Security Admission and a policy engine for organization-specific rules.
Fourth, adopt default deny NetworkPolicy for sensitive namespaces and prove CNI enforcement.
Fifth, preserve audit logs outside the cluster and alert on Secret reads, RBAC changes, exec, and webhook modifications.
Common mistakes that make secure clusters look safe
A cluster can pass a superficial review and still be fragile. Watch for these traps.
A namespace with no NetworkPolicy is not isolated. RBAC may limit Kubernetes API actions across namespaces, but it does not automatically block Pod-to-Pod network traffic.
A Secret encrypted at rest is not protected from authorized API reads. Encryption protects storage exposure, not overbroad RBAC.
A non-root container can still be risky. Capabilities, writable filesystems, hostPath mounts, and service account permissions can matter more than UID alone.
A managed Kubernetes service does not remove your responsibilities. NSA and CISA note that cloud service providers may administer many managed Kubernetes aspects, but organizations still need to understand their responsibilities, including authentication and authorization, because default configurations may not be secure.
An admission policy does not cover reads. Kubernetes admission control does not block consiga, vero lista, so Secret-read prevention belongs in RBAC and audit monitoring. (Kubernetes)
A chart default is not a security decision. Helm charts often optimize for installation success across many environments. Production security requires reviewing service accounts, Pod specs, Secrets, NetworkPolicies, and controller permissions.
A patch is not complete until exposure is proven closed. After upgrading ingress-nginx or any controller, verify running image versions, webhook configuration, service reachability, and RBAC blast radius.
Kubernetes orchestration security checklist for production teams
Use this as an operational baseline, not a one-time audit.
| Control area | Minimum production expectation |
|---|---|
| API server access | Private or tightly restricted endpoint, strong authentication, no broad anonymous access |
| RBAC | Namespace-scoped roles where possible, no unnecessary wildcards, no CI cluster-admin, reviewed bind/escalate/impersonate |
| Service accounts | No default token auto-mounting for workloads that do not need API access |
| Secretos | Encryption at rest, narrow Secret RBAC, external store where appropriate, no Secret logging |
| NetworkPolicy | CNI enforcement confirmed, default deny for sensitive namespaces, explicit egress rules |
| Pod Security | Baseline or restricted enforcement, warn and audit for rollout, exceptions tracked |
| Runtime | Non-root, no privilege escalation, drop capabilities, RuntimeDefault seccomp, read-only root filesystem where feasible |
| Controllers | Patched versions, narrow service account permissions, internal webhook reachability restricted |
| Supply chain | Digest-pinned images, trusted registries, signature or provenance checks where feasible |
| Auditoría | API audit enabled, logs stored outside cluster, alerting for high-risk actions |
| Incident response | Token rotation, Secret rotation, node isolation, namespace quarantine, evidence capture runbooks |
The checklist works only if it is tied to ownership. Every exception should have an owner, reason, expiry date, compensating control, and test proving it still behaves as expected.
PREGUNTAS FRECUENTES
What is Kubernetes orchestration security in practice?
- It is the protection of the full Kubernetes decision chain: API access, RBAC, service accounts, Secrets, network paths, admission control, controllers, runtime settings, nodes, and audit logs.
- It is broader than container image scanning because Kubernetes can turn a safe image into a risky workload through privileges, mounts, tokens, and network access.
- The practical goal is to reduce blast radius when a workload, user, controller, or credential is compromised.
Is Kubernetes RBAC enough to secure a cluster?
- No. RBAC controls Kubernetes API authorization, but it does not automatically isolate Pod network traffic, prevent unsafe runtime settings, encrypt Secrets, or detect process behavior.
- RBAC is still a core control because it determines whether identities can read Secrets, create workloads, exec into Pods, modify roles, or bind stronger privileges.
- Strong clusters combine RBAC with admission policy, NetworkPolicy, runtime hardening, Secret protection, patching, and audit logging.
Are Kubernetes Secrets encrypted by default?
- Kubernetes documentation warns that Secrets are stored unencrypted in etcd by default unless encryption at rest is configured.
- Secret safety also depends on RBAC. A user or service account with API permission to read Secrets can still retrieve them even if etcd encryption is enabled.
- Treat Secrets as sensitive API objects: encrypt them at rest, restrict read access, avoid unnecessary mounts, avoid environment-variable leakage, and rotate them after suspected exposure.
Do Kubernetes namespaces isolate network traffic by default?
- No. Namespaces help organize resources and scope RBAC, but they do not automatically block Pod-to-Pod traffic.
- NetworkPolicy can isolate ingress and egress only if the cluster uses a CNI plugin that enforces NetworkPolicy.
- Sensitive namespaces should start with default deny ingress and egress, then allow only required application paths.
What should I check first after a possible Kubernetes compromise?
- Identify the initial workload, namespace, node, service account, and image digest involved.
- Check whether the service account can read Secrets, create Pods, exec into Pods, or modify RBAC.
- Review audit logs for Secret reads,
pods/exec, RoleBinding or ClusterRoleBinding changes, admission webhook changes, and unusual controller actions. - Rotate exposed Secrets and service account tokens, isolate affected namespaces or nodes, and preserve logs outside the cluster before cleanup.
How do I reduce runtime risk for Pods?
- Run as non-root where possible, set
allowPrivilegeEscalation: false, drop Linux capabilities, useseccompProfile: RuntimeDefault, and use read-only root filesystems when feasible. - Block privileged containers, hostPath mounts, hostNetwork, hostPID, and hostIPC unless a tightly reviewed platform component genuinely requires them.
- Use Pod Security Admission and policy engines to prevent unsafe specs before they enter the cluster.
Which Kubernetes CVEs are useful for understanding cluster misconfiguration risk?
- CVE-2025-1974 shows how ingress-nginx controller exposure and privileges can lead to Secret disclosure under certain network conditions.
- CVE-2024-3177 shows that Secret-related admission assumptions can fail when workload fields are not fully covered.
- CVE-2024-3744 shows how service account tokens can leak through component logs under specific CSI driver conditions.
- CVE-2024-7598 shows that NetworkPolicy enforcement can have lifecycle edge cases during namespace deletion.
- CVE-2023-2727 shows that debug and ephemeral container paths must be included in image policy design.
Closing judgment
Kubernetes orchestration security is not a single control. It is the discipline of making sure the cluster does not hand unnecessary power to users, workloads, controllers, logs, and network paths.
A well-secured cluster assumes that applications will have bugs, credentials may leak, controllers may need urgent patches, and operators will sometimes make mistakes. The defensive posture comes from reducing each mistake’s blast radius: narrow RBAC, intentional service account tokens, encrypted and restricted Secrets, enforced admission policy, default-deny network boundaries, hardened runtime settings, patched controllers, and audit evidence that survives the incident.
The clusters that age well are not the ones with the most YAML. They are the ones where every permission, route, Secret mount, and privileged exception can still be explained six months later.

