Por qué el centro de gravedad se desplaza a escala local
Los LLM en la nube siguen siendo extraordinarios, pero la realidad de los equipos rojos no perdona: los límites de tarifas llegan a mitad de la intervención, los cambios de precios rompen los modelos de planificación y los cambios en las políticas regionales interrumpen la recogida de pruebas. Para los equipos que viven y mueren por la reproducibilidad, el análisis forense y las pistas de auditoría limpias, estas incertidumbres no son un matiz, sino un riesgo operativo. Paralelamente, los entornos regulados de la sanidad, las finanzas y el sector público prefieren cada vez más que los datos sensibles nunca abandona las redes controladas, lo que empuja la ejecución de modelos hacia portátiles, estaciones de trabajo y clústeres privados. Este cambio es visible a la vista de todos: los informes registran el aumento de la "IA en la sombra", con una gran proporción de empleados que reconocen el uso no autorizado de la IA que pone en riesgo la exposición de los datos. (Cibernoticias)
Una segunda fuerza es la transparencia. Los modelos pequeños de código abierto (entre 7.000 y 13.000 parámetros, cuantificados, podados y ajustados) se están convirtiendo en "lo suficientemente buenos" para una gran parte del triaje, la generación de PoC y la asistencia de secuencias de comandos, al tiempo que siguen siendo auditables a nivel de peso y de plantillas de avisos. Si combinamos esto con un coste marginal por ejecución cercano a cero y una latencia local inferior a un segundo en GPU de consumo, obtenemos un bucle de experimentación más rápido y fácil de controlar que un punto final remoto de caja negra. La ruta local también minimiza el radio de acción de las interrupciones y los cambios de política que, de otro modo, paralizarían una ventana de prueba. Sin embargo, "local" no es automáticamente "seguro": análisis recientes han encontrado cientos de puntos finales LLM autoalojados, incluido Ollama, expuestos en la Internet pública, lo que nos recuerda que el control de acceso básico y el aislamiento de la red siguen siendo importantes. (TechRadar)
Fuentes: Cybernews sobre la prevalencia y los riesgos de la shadow-AI; TechRadar y Cisco Talos sobre los servidores Ollama expuestos. (TechRadar)
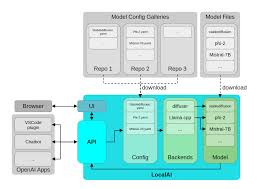
Definición de pentestai en la práctica
pentestai es la definición de trabajo de Penligent para las pruebas de penetración asistidas por IA: un método y flujo de trabajo en el que pequeños LLM locales y de código abierto orquestan su cadena de herramientas existente -Burp, SQLMap, Nuclei, GHunt- mientras capturan comandos, parámetros, artefactos y pasos de reproducción como un rastro de evidencia permanente. El modelo no es el "actor"; es el colaborador que propone comandos, sintetiza PdC y razona sobre la salida del escáner bajo supervisión humana. En una postura híbrida, el razonamiento de cadena larga o las tareas de contexto ultralargo pueden escalar a modelos en la nube, pero la verificación y la recopilación inicial de pruebas permanecen en el hardware que usted controla.
El caso de los "LLM locales + abiertos pequeños"
Una postura de "lo local primero" se corresponde perfectamente con los controles de privacidad y cumplimiento de normativas, ya que los datos permanecen dentro de los límites del dispositivo y de su sistema de registro de auditorías. El enfoque se alinea con las familias de control conocidas por los responsables de seguridad -aplicación del acceso, auditoría y minimización de datos- codificadas en marcos como NIST SP 800-53. Además, los pesos abiertos permiten la revisión externa, la verificación de la cadena de suministro y la reproducción determinista de los hallazgos entre equipos y en el tiempo. Cuando la nube se ralentiza, falla o cambia las condiciones, su equipo rojo no se queda a oscuras, sino que continúa en la estación de trabajo de al lado. La advertencia: trate el tiempo de ejecución de su modelo local como un servicio sensible: autentifíquelo, segméntelo y nunca lo exponga directamente a Internet. (Centro de recursos de seguridad informática del NIST)
Una pila de referencia para pentestai
Local no significa monolítico. Significa una capacidad cuidadosamente escalonada en la que cada peldaño tiene una función de prueba específica, y toda la escalera se puede transferir a la nube por complejidad, escala o ventana de contexto cuando sea necesario.
| Nivel | Hardware típico | Modelo/tiempo de ejecución | Función principal | Notas |
|---|---|---|---|---|
| Prototipo ligero | Clase MacBook | Ollama funcionamiento de los modelos cuantificados 7B-13B | Prompt→síntesis de comandos, pequeños PoCs, triaje de logs. | Portátil, privado, de baja latencia. (Ollama) |
| Laboratorio presupuestario | GTX 1070 / iGPU | GGUF con llama.cpp o LM Studio | Taladradoras neumáticas, automatización offline | Estable incluso en GPUs/iGPUs antiguas. (huggingface.co) |
| Estación de trabajo de gama alta | RTX 4090 (24GB) | Orquestación multiagente + bucles fuzz | Grandes conjuntos de activos, validación paralela | Alta concurrencia, ciclos de retroalimentación cortos. (NVIDIA) |
| Edge y móvil | Dispositivos Apple + Núcleo ML | Inferencia en el dispositivo | Muestreo sobre el terreno en lugares regulados | Exposición cero a la nube para PHI/PII. (Desarrollador de Apple) |
En esta arquitectura, Ollama simplifica la gestión del modelo local y el acceso a la API, GGUF proporciona un formato eficiente y portátil optimizado para la inferencia en CPU/GPU, RTX 4090 los sistemas de clase desbloquean el fuzzing agresivo y los flujos multiagente, y Núcleo ML mantiene los datos confidenciales en el dispositivo al tiempo que aprovecha el motor neuronal de Apple. (Ollama)
Qué cambia en las pruebas cotidianas
Para Web/API pentestai acelera el bucle desde el descubrimiento de OSINT y parámetros hasta la generación de hipótesis y comprobaciones con plantillas. Las IDOR candidatas, las reglas de autorización mal delimitadas o los desvíos de límites de velocidad pueden convertirse en plantillas de núcleos verificables con avisos y un pequeño andamiaje de análisis sintáctico, mientras que los riesgos de control de acceso e inyección se alinean limpiamente con las plantillas. Top 10 de OWASP y ASVS orientación que ya utiliza para informar. (Fundación OWASP)
En credenciales y federación trabajo, los modelos ayudan a componer y validar planes de pruebas para OAuth 2.0 y OpenID Connect estado, nonce, audiencia y duración de los tokens dejan de ser conocimiento tribal y se convierten en elementos de listas de comprobación con scripts adjuntos. El beneficio no es un "exploit mágico", sino una forma rigurosa y repetible de auditar los supuestos, registrar cada intento y preservar los artefactos para su revisión. (datatracker.ietf.org)
Para LLM seguridad-Los modelos locales son doblemente útiles: simulan las entradas de los adversarios y razonan sobre la defensa en profundidad sin enviar sus mensajes, instrucciones del sistema o corpus desinfectados fuera de su perímetro. Es una ventaja tanto para el control de los datos como para la velocidad. Mientras tanto, los puntos finales LLM mal configurados del sector son un ejemplo de advertencia: si te autoalojas, bloquéalo. (TechRadar)
Una cadena local mínima: verificación de Núcleos asistida por modelos
# Utilizar un modelo local 7B-13B a través de Ollama para sintetizar una plantilla Nuclei+command.
prompt='Generar una plantilla Nuclei para sondear un IDOR básico en /api/v1/user?id=... .
Devuelve sólo YAML válido y un comando nuclei de una línea para ejecutarlo.'
curl -s http://localhost:11434/api/generate \
-d '{"model": "llama3.1:8b-instruct-q4", "prompt":"'"$prompt"'", "stream": false}' \ | jq -r '.yAML.
| jq -r '.respuesta' > gen.txt
# Extraer YAML y ejecutarlo, a continuación, hash artefactos en un registro de auditoría.
awk '/^id: /,/^$/' gen.txt > templates/idor.yaml
nuclei -t plantillas/idor.yaml -u https://target.example.com -o evidencias/idor.out
sha256sum templates/idor.yaml evidence/idor.out >> audit.log
Esto no es "dejar que la modelo piratee". Es dirigido por el hombre automatización con alcance ajustado, pruebas capturadas y reproducción determinista.
Una gobernanza que se sostiene en las auditorías
La primacía local no justifica un proceso deficiente. Trate los avisos como activos versionados, ejecute pruebas a nivel de unidad para garantizar la seguridad y el determinismo, y aplique RBAC en su capa de orquestación. Asigne sus controles a NIST SP 800-53 para que los revisores las reconozcan: control de acceso (AC), auditoría y responsabilidad (AU), gestión de la configuración (CM) e integridad del sistema y de la información (SI). Mantenga el tiempo de ejecución del modelo en un segmento privado, exija autenticación y registre todas las invocaciones, incluido el texto de solicitud, las llamadas a herramientas y los hashes de los artefactos generados. Y como la mayoría de los hallazgos de la Web/API acaban apareciendo en informes ejecutivos, vincule su lenguaje y gravedad a OWASP para minimizar los ciclos de reescritura con AppSec y cumplimiento. (Centro de recursos de seguridad informática del NIST)
Cuándo escalar a la nube y por qué lo híbrido es honesto
Hay razones legítimas para utilizar modelos alojados: contextos extremadamente largos, razonamiento multietapa a través de corpus heterogéneos o estrictos acuerdos de nivel de servicio de disponibilidad para procesos de producción. Una política defendible es "local para la verificación, en la nube para la escala", con reglas explícitas de tratamiento de datos y redacción incorporadas. Reconoce la realidad de que algunos problemas superan los límites prácticos del hardware local, al tiempo que mantiene el núcleo sensible de sus pruebas dentro de sus límites de auditoría.
Dónde encaja Penligent si necesita una ruta productizada
Penligent operativiza pentestai en un flujo de trabajo que da prioridad a las pruebas: las instrucciones en lenguaje natural se transforman en cadenas de herramientas ejecutables; las conclusiones se validan y registran con parámetros y artefactos; y los informes se ajustan a los marcos en los que ya confían las partes interesadas, tales como Top 10 de OWASP y NIST SP 800-53. Apoyo a las implantaciones Ollama para la gestión local, GGUF modelos para una inferencia eficaz, y Núcleo ML para pruebas en dispositivos en los que la exposición cero a la nube es un requisito de cumplimiento. El resultado es una postura de equipo rojo "siempre activo" que sobrevive a los límites de velocidad de los proveedores, los cambios de políticas y las particiones de red sin perder auditabilidad. (Ollama)
Lectura práctica y anclajes que su equipo ya utiliza
Si sus pruebas abarcan la autenticación y la identidad, mantenga el campo OAuth 2.0 y OpenID Connect Si escalas a la nube, asegúrate de que tus pruebas siguen correspondiendo a la misma columna vertebral de informes. Para enmarcar los riesgos de la web, indique a los jefes de producto y a los responsables de ingeniería lo siguiente Top 10 de OWASP para que los ciclos de reparación sean más cortos y menos adversos. Y si sigue la ruta de la estación de trabajo, perfile un RTX 4090 para el fuzzing paralelo y la orquestación de agentes; si se mantiene en movimiento o en la clínica, utilice Núcleo ML y su cadena de herramientas para mantener los datos regulados en el dispositivo. (datatracker.ietf.org)
Fuentes
- Shadow-AI prevalence and workplace risk (Cybernews; resumen de TechRadar de la misma encuesta). (Cibernoticias)
- Puntos finales LLM locales expuestos, incluido Ollama (TechRadar; Cisco Talos blog). (TechRadar)
- OWASP Top 10 (oficial). (Fundación OWASP)
- NIST SP 800-53 Rev. 5 (HTML y PDF oficiales). (Centro de recursos de seguridad informática del NIST)
- OAuth 2.0 (RFC 6749) y OpenID Connect Core 1.0. (datatracker.ietf.org)
- Referencias de Ollama y GGUF; documentación de Core ML; página del producto NVIDIA RTX 4090. (Ollama)
Enlaces fiables para tener a mano:
Top 10 de OWASP - NIST SP 800-53 Rev. 5 - RFC 6749 OAuth 2.0 - OpenID Connect Core 1.0 - Ollama - Visión general del GGUF - Documentación básica sobre ML - GeForce RTX 4090

