Lorsque vous lisez les titres sur les vulnérabilités, l'injection XML attire rarement l'attention. Son nom n'est pas aussi percutant que celui de RCE ou SQLi, et elle n'est pas aussi spectaculaire qu'un exploit à distance tape-à-l'œil. Mais dans de nombreuses piles d'entreprise - points d'extrémité SOAP, API XML héritées, pipelines de traitement de documents et intégrations SAML/SOAP - l'injection XML est le mode d'échec silencieux qui transforme les entrées de confiance en erreurs de logique.
Au fond, l'injection XML n'est pas un exploit unique. Il s'agit d'une famille de comportements où le XML contrôlé par l'attaquant modifie la façon dont un serveur interprète une requête. Cela peut signifier qu'une requête XPath renvoie soudainement des enregistrements inattendus, qu'un analyseur syntaxique résout des ressources externes que vous n'aviez pas l'intention d'appeler, ou que l'expansion d'une entité consomme de l'unité centrale et de la mémoire. Du point de vue d'un attaquant, il s'agit de blocs de construction pratiques : lire des fichiers, déclencher des requêtes internes ou provoquer un chaos utile. Du point de vue du défenseur, ces mêmes éléments constituent une carte de navigation permettant de combler les lacunes en matière de logique et d'observabilité.
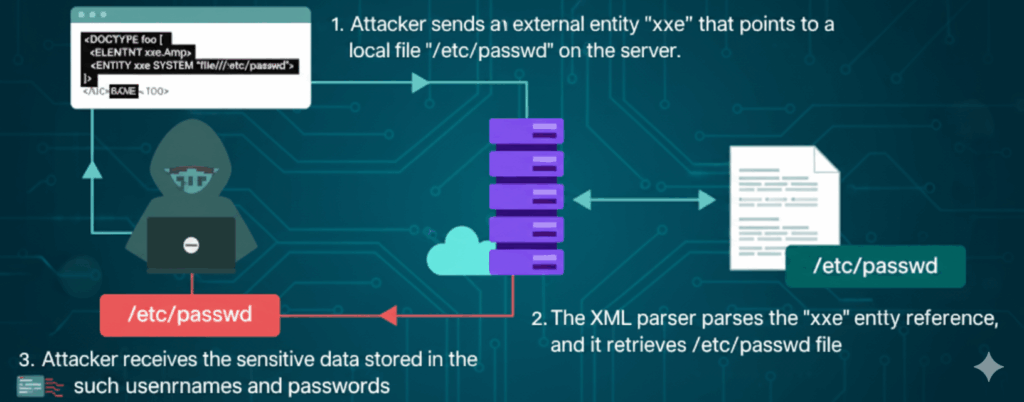
Un petit goût concret - sans donner à quiconque un manuel de jeu
Il n'est pas nécessaire d'avoir des charges utiles sophistiquées pour voir le modèle. Imaginez un code côté serveur qui construit un XPath à partir des champs de la requête par concaténation naïve de chaînes de caractères :
// modèle vulnérable (pseudo)
userId = request.xml.user.id
role = request.xml.user.role
query = "doc('/db/users.xml')/users/user[id = " + userId + " and role = '" + role + "']"
result = xmlEngine.evaluate(query)
Cela semble inoffensif si ID utilisateur et rôle sont bien formées. Mais lorsque vous laissez l'utilisateur contrôler la structure de la requête, vous brouillez la frontière entre données et logique. L'injection XPath en est la conséquence naturelle : une requête fragile peut être manipulée pour modifier les conditions de vérité et renvoyer des lignes qu'elle ne devrait pas.
Un autre axe est la gestion des entités ou des DTD. De nombreux moteurs XML autorisent les déclarations de type de document, les entités et les références externes - utiles pour la composition légitime, mais dangereuses lorsqu'elles sont activées pour des entrées non fiables. La règle défensive est simple : si vous n'avez pas besoin de l'expansion des entités ou du traitement des DOCTYPE, désactivez-les.
Pourquoi l'analyse de la configuration est plus importante que les exploits obscurs
Ce problème se pose à deux niveaux. Le premier est le bogue de la logique d'entreprise - le passage de valeurs non fiables dans la logique de requête, le modelage du XML dans XPath ou des évaluateurs de type XPath, et le fait de supposer que "bien formé" signifie "sûr". Ce problème peut être résolu dès la conception : validation, canonisation et séparation des données et des requêtes.
Le second est le comportement de l'analyseur. Les analyseurs XML sont puissants ; ils peuvent récupérer le contenu de fichiers, effectuer des requêtes HTTP ou développer des entités imbriquées qui gonflent la mémoire. Ces capacités conviennent dans des contextes contrôlés, mais sont désastreuses lorsque des entrées publiques sont acceptées. La défense pratique consiste donc à renforcer l'analyseur et à effectuer une télémétrie comportementale.
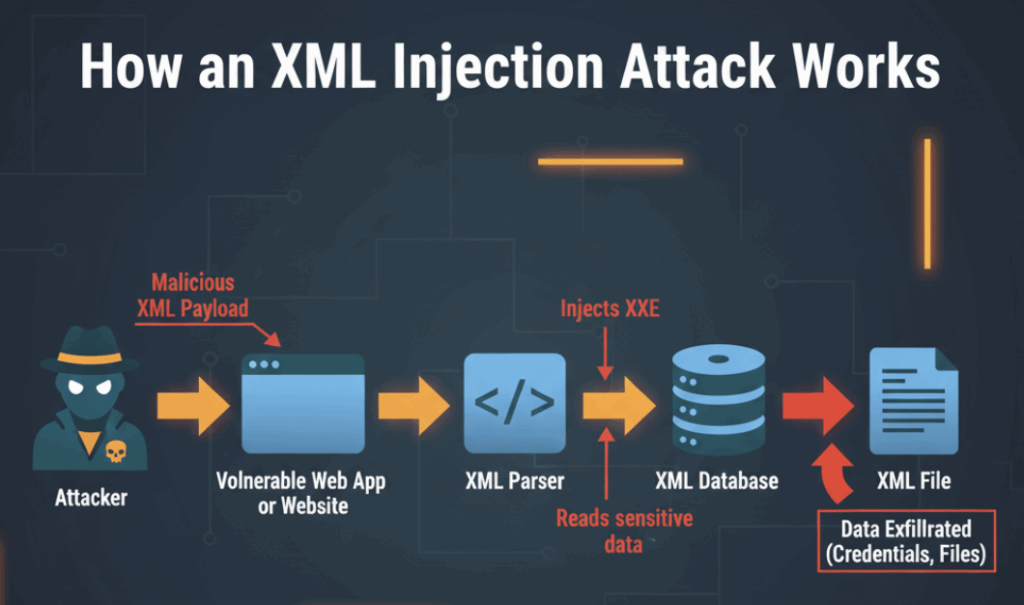
Contre-mesures pratiques et faciles à mettre en œuvre (avec exemple)
Il n'est pas nécessaire d'interdire le XML pour être en sécurité. Trois changements d'habitudes s'imposent :
1) Limiter la capacité de l'analyseur. Dans la plupart des langages, vous pouvez désactiver les entités externes et le traitement DOCTYPE. Par exemple, en Java (pseudo-API) :
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance() ;
dbf.setFeature("", true) ;
dbf.setFeature("", false) ;
dbf.setFeature("", false) ;
Ou en Python avec defusedxml (utilisez une bibliothèque qui adopte par défaut un comportement sûr) :
from defusedxml.ElementTree import fromstring
tree = fromstring(untrusted_xml)
2) Valider et canoniser. Si votre point d'accès n'a besoin que d'un petit ensemble de balises, validez par rapport à un XSD ou rejetez les DOCTYPEs inattendus. Préférez l'analyse en structures de données et l'utilisation d'accès paramétrés plutôt que la construction de requêtes par concaténation de chaînes.
3) Instrument et alerte. Ajoutez des crochets qui surveillent les signaux étranges : exceptions de l'analyseur faisant référence à DOCTYPE/ENTITY, DNS/HTTP sortant soudainement du service d'analyse, ou opérations d'ouverture de fichiers lancées pendant l'analyse. Ces signaux sont bien plus utiles que n'importe quelle liste de règles statiques.
Des signaux détectables qui aident réellement les défenseurs
Lorsque vous mettez en place une surveillance, recherchez des comportements réels, et non des signatures textuelles fragiles :
- Appels DNS ou HTTP sortants provenant de votre processus d'analyseur.
- Tentatives d'accès à des chemins d'accès locaux lors de la gestion de XML.
- Traces d'exceptions de l'analyseur mentionnant le DOCTYPE ou la résolution d'entités externes.
- Les réponses qui incluent soudainement des champs ou des données internes (indiquant une manipulation XPath ou une requête).
- Pics inhabituels d'utilisation du processeur et de la mémoire dans le code d'analyse sous une charge normale.
Ce sont les éléments sur lesquels vous pouvez donner l'alerte et effectuer un triage rapide.
Comment pratiquer sans être imprudent
Si vous souhaitez expérimenter - vérifier les règles de détection, confirmer que le durcissement de l'analyseur fonctionne, ou vous entraîner sur un défi de type CTF - ne le faites que dans des laboratoires contrôlés. N'introduisez pas de XML malformé dans la production. Utilisez plutôt des machines virtuelles isolées, des gammes de laboratoires prouvables ou des outils qui génèrent des aseptisé, non exploité les cas de test.
Flux de travail en langage naturel - Penligent dans la boucle
C'est là que l'automatisation pratique porte ses fruits. Vous ne devriez pas avoir à coder à la main des dizaines de tests simplement pour valider les paramètres de l'analyseur ou la logique de détection. Avec un outil de pentest basé sur le langage naturel comme PenligentDans la langue de tous les jours, le flux se présente de la manière suivante :
"Vérifiez nos points d'extrémité SOAP pour les risques d'injection XML. Utiliser uniquement des sondes sûres, collecter les exceptions de l'analyseur, les événements d'accès aux fichiers et tous les rappels DNS/HTTP sortants. Produire des étapes de renforcement prioritaires."
Penligent transforme cette phrase en vérifications ciblées et aseptisées par rapport à votre environnement de test autorisé. Il exécute des cas de test ciblés (pas des chaînes d'exploitation en direct), recueille des données télémétriques (erreurs d'analyseur, journaux d'accès aux fichiers, rappels DNS), met en corrélation les preuves et renvoie une liste de contrôle concise pour la remédiation. Pour les joueurs de CTF, l'avantage est la rapidité : vous pouvez valider une hypothèse et savoir si votre détection aurait fonctionné - puis itérer - sans écrire de scripts shell ou créer des dizaines de fichiers de charge utile.
Réflexion finale
L'injection XML semble peu spectaculaire sur un tableau de classement des vulnérabilités, mais son véritable pouvoir est furtif. Elle exploite des hypothèses - que la couche de données est inoffensive, que l'analyseur syntaxique se comporte "comme prévu", que la surveillance détectera les défaillances évidentes. Pour y remédier, il ne s'agit pas tant d'une rustine magique que d'une hygiène de conception : minimiser les privilèges de l'analyseur, séparer les données de la logique, valider agressivement et instrumenter les signaux qui comptent. Les outils qui convertissent les intentions en langage naturel en validations sûres éliminent la corvée et permettent aux équipes de se concentrer sur la remédiation et l'apprentissage - ce qui est exactement l'objectif de l'automatisation défensive moderne.

