There is a reason projects like AutoClaw attract serious attention from engineers. They promise something many teams actually want: not another flashy desktop demo, but a lean, headless, tool-driven runtime that can sit inside containers, run in CI, and execute repetitive work without a GUI. AutoClaw’s own repository describes it as a high-stability, command-driven, Docker-native automation framework for headless systems, with support for shell actions, file I/O, email, notifications, web search, and screenshot-based website interaction. That positioning is not marketing fluff. It reflects a real architectural shift in agent systems away from “watch the screen and guess” and toward “call tools and act deterministically.” (GitHub)
But that shift cuts both ways. In a plain chatbot, a mistake is usually a bad answer. In an agent runtime, a mistake can become a file write, a command execution, an email with attachments, a webhook to an external system, or a browser request to an internal endpoint. That is why the center of gravity in AI security has moved away from purely model-centric discussions and toward execution boundaries, delegated authority, and tool governance. NIST describes many current agents as vulnerable to “agent hijacking,” a form of indirect prompt injection in which malicious instructions hidden in consumed data push the system toward unintended actions. OWASP still ranks prompt injection as the leading LLM risk area, and OpenAI’s recent public guidance makes the same point in plainer language: once AI tools can browse, retrieve information, and act on a user’s behalf, prompt injection stops being a quirky prompt-engineering problem and becomes a real security challenge. (NIST)
That framing matters for AutoClaw because this project is not best understood as “a CLI wrapper around a model.” It is better understood as a compact action engine. The central question is not whether the model is smart. The central question is whether the surrounding system constrains what happens when the model is wrong, manipulated, or simply over-authorized. IBM’s current guidance for AI agent security lands on the same operational conclusion: agent risk rises sharply when tools, APIs, memory, and automation pipelines are added, and the important controls are least privilege, sandboxing, input validation, logging, approvals, and continuous monitoring. Microsoft has been equally direct in recent runtime-security guidance, warning that even sophisticated agent orchestrations can be exploited when tool invocations are not carefully controlled. (IBM)
So the right verdict on AutoClaw is neither “unsafe hype” nor “safe because Docker.” The more honest verdict is this: AutoClaw is an engineering-first agent runtime with a meaningful productivity upside, but it is not secure by default. It can be operated responsibly, but only if the environment, permissions, and tool surface are hardened around it. The code and documentation show enough structure to take seriously, and enough exposed capability to justify a hard security review. (GitHub)
AutoClaw, what the architecture actually is
AutoClaw’s repository states its design philosophy clearly. It is built for headless execution, not GUI automation; it emphasizes command-driven execution over visual interpretation; it advertises compatibility with local servers, CI/CD pipelines, and large fleets of containerized nodes; and it explicitly supports a non-interactive mode with a -y flag that automatically approves tool executions. The repo also calls out “universal control,” from file I/O to more general system administration, and surfaces integrations for Tavily web search, SMTP mail, and chat webhook notifications. Those are not incidental add-ons. Together they define the effective authority of the agent. (GitHub)
That authority becomes clearer in the tool registry. AutoClaw registers shell execution, file read, file write, date and time, prompt optimization, email, search, notifications, website reading, screenshots, and image generation as available tools. The important security implication is not simply that these tools exist. It is that they are exposed through one common registry and handed to the model as callable capabilities in the same planning loop. In practice, that means the model does not just “answer questions.” It can decide to read, write, navigate, notify, and execute. (GitHub)
The architecture in agent.ts is straightforward and powerful. AutoClaw creates an OpenAI-compatible client, builds a system prompt that includes runtime context such as OS, architecture, Node version, working directory, username, home directory, and current date, then sends the full message history plus the full tool definition set into the chat completion call with tool_choice: "auto". If the model emits tool calls, AutoClaw executes them and pushes the tool result back into the conversation as a tool message. That is an elegant loop from an engineering perspective. It is also exactly the kind of loop security engineers worry about, because it closes the gap between “language output” and “state-changing action.” (GitHub)
Even the system prompt language is revealing. The runtime tells the model it is container-optimized and non-interactive, and instructs it to suppress prompts with flags such as apt-get -y et rm -rf. It also tells the model to use execute_shell_command for actions and write_file for code generation. That is useful for automation success. It is also a strong signal that this project is optimized to remove friction between intent and execution, not to insert defensive review checkpoints at every boundary. (GitHub)
The simplest way to think about AutoClaw is to stop calling it “just a headless agent” and start calling it a language-driven operator bound to local and remote execution surfaces. Once you see it that way, the security review becomes clearer.
The table below summarizes the architectural tradeoff visible in the public code and documentation. It is not a moral judgment. It is the runtime’s risk geometry. (GitHub)
| Design choice | Engineering upside | Security cost |
|---|---|---|
| Headless, command-driven execution | More deterministic than vision-driven agents | Lower friction from model output to real action |
| Unified tool registry | Broad capability from one runtime | Large default action surface |
| Auto tool selection | Flexible planning | Harder to reason about least privilege |
| Tool results fed back to model | Better multi-step execution | Greater risk of sensitive context recirculation |
Non-interactive mode and -y | Good for CI and unattended workflows | Weaker human review at the exact moment of risk |
| Browser and screenshot tools | Useful for retrieval and validation | Expands SSRF, internal browsing, and prompt injection exposure |
| SMTP and webhook integrations | Real workflow utility | Adds exfiltration channels |
Why headless agent security is different from ordinary application security
A normal application usually has a clear boundary between input parsing and privileged operations. The user clicks a button, a handler validates the request, and a downstream function executes a tightly scoped action. Agent systems blur that boundary because natural-language planning, retrieved content, model inference, tool selection, and action execution are part of one continuous chain. OpenAI’s current public writing on prompt injection makes this point explicitly: attacks increasingly resemble social engineering, not just naive instruction overrides, and the right defense is not only filtering malicious strings but constraining the impact of manipulation even when some attacks succeed. (OpenAI)
That view lines up closely with NIST’s discussion of agent hijacking. The important issue is not simply “bad prompts.” The issue is that agents consume data that looks benign, interpret it as task-relevant context, and may then convert it into actions if no architectural boundary interrupts the flow. Hidden instructions in a webpage, email, document, log line, or issue body can shift planning. If the system also has tools, credentials, or local execution rights, that influence can cross from cognition to consequence. (NIST)
OWASP’s current agentic guidance and prompt-injection material point in the same direction. Prompt injection remains the leading problem not because it is the only risk, but because it is the easiest way to bridge untrusted input and privileged behavior when the runtime is not carefully segmented. That is especially true in systems that ingest web content, parse arbitrary files, or attach models directly to shells and APIs. Google’s own 2025 mitigation write-up emphasizes a layered defense model, with content classifiers, system safeguards, suspicious URL handling, and user confirmation frameworks distributed across the prompt lifecycle rather than attached as a single brittle filter at the front door. (Projet de sécurité Gen AI de l'OWASP)
The best summary is simple. In agent systems, the question is no longer “Can hostile input influence reasoning?” The answer is yes. The real question is “What can influenced reasoning do?” AutoClaw matters because, by design, the answer can include shell execution, filesystem access, network navigation, email, and notifications. (GitHub)
Trust boundary one, shell execution and filesystem authority
The sharpest risk in AutoClaw is still the oldest one in systems security: command execution. In core.ts, the shell tool is implemented with Node’s processus_enfant.exec, taking a model-supplied command string and, after a confirmation step unless autoConfirm is enabled, executing it on the host environment. The same file exposes an unrestricted read_file and an unrestricted write_file that will create parent directories recursively and overwrite existing files. On paper, this looks practical and minimal. In a hostile or simply sloppy context, it means the model can ask to run arbitrary shell commands, read arbitrary paths, and write arbitrary paths unless the operator has wrapped the process in stronger external controls. (GitHub)
The project does deserve credit for not silently executing shell commands by default. The tool will ask for confirmation unless autoConfirm is set, and the README explicitly warns that -y is dangerous and should be used with caution or inside sandboxes. That is a meaningful safeguard for a human operator sitting at a terminal. It becomes much weaker when the runtime is used the way the project advertises it for CI, one-shot automation, or unattended containerized work. The more “industrial” the deployment becomes, the more likely that manual confirmation disappears. (GitHub)
This is where adjacent industry CVEs stop being abstract cautionary tales and start looking uncomfortably familiar. NVD’s description of CVE-2025-53818 in a GitHub Kanban MCP server says the vulnerable tool relied on Node’s exécuter to run the gh command and became vulnerable to command injection when untrusted input was concatenated into that execution path. The relevance to AutoClaw is not that the two projects are identical. The relevance is architectural: once an agent tool’s user-influenced input hits exécuter, the exploit class is already defined. (NVD)
The same lesson appears again in CVE-2025-6514, where mcp-remote was exposed to OS command injection when connecting to untrusted MCP servers due to crafted input in an authorization endpoint response URL. Different component, same pattern: string-based, high-authority execution paths become brittle when they accept influence from external systems that were not meant to control the final command context. That pattern should make any security reviewer nervous when they see a general-purpose agent runtime advertising shell access as a first-class tool. (GitHub)
AutoClaw does not, in the public code we reviewed, appear to constrain shell commands to a fixed allowlist, a structured argument schema, or a dedicated working directory jail. It also does not appear to scope read_file et write_file to a safe project subtree. That absence matters more than people sometimes admit. Least privilege is not just about whether the container is rootless. It is also about whether the language model ever gets a generic “do anything with this string” primitive in the first place. IBM’s current agent-security guidance explicitly calls out least privilege, sandboxing, and approvals as core controls, and it warns developers not to give an agent or tool root access. That advice is directly relevant here. (IBM)
A safer pattern looks more like this, where the model is allowed to select from a constrained action set and pass validated arguments, rather than synthesize one shell string with broad ambient authority:
# Illustrative example, not copied from AutoClaw
ALLOWED_ACTIONS = {
"list_src": ["find", "src", "-maxdepth", "3", "-type", "f"],
"npm_test": ["npm", "test", "--", "--runInBand"],
"git_status": ["git", "status", "--short"],
}
def run_safe_action(action_name: str):
if action_name not in ALLOWED_ACTIONS:
raise PermissionError("Action not allowed")
return subprocess.run(
ALLOWED_ACTIONS[action_name],
cwd="/workspace",
capture_output=True,
text=True,
check=False,
timeout=30,
env={"PATH": "/usr/bin:/bin"},
)
This kind of design does not solve prompt injection by itself. It solves something just as important: blast radius. OpenAI’s current builder guidance is explicit that tool approvals should remain on and that untrusted data should never directly drive agent behavior. That recommendation is easier to follow when the runtime offers narrow, typed actions instead of one big command channel. (Développeurs OpenAI)

Trust boundary two, secrets, context leakage, and the problem of recirculating tool output
The next major issue is less flashy than shell access and often more damaging in practice: context leakage. AutoClaw’s agent.ts injects system information directly into the system prompt, including operating system, working directory, user, home directory, and current date. On their own, those fields are not catastrophic. But they tell you the design philosophy: rich runtime context is considered useful fuel for the model. Once a project embraces that pattern, there is a high risk that more sensitive information starts flowing through the same channel over time. (GitHub)
The more consequential detail is that tool results are pushed back into the model conversation as tool messages. That means anything read from the filesystem, pulled from a website, returned by a search result, or emitted by another tool can become part of future model-visible context. In a local-only model environment that still matters. In a remote API-backed model environment it matters much more, because sensitive local information may leave the machine as part of subsequent inference calls. OpenAI’s own public prompt-injection writing frames the dangerous sink exactly this way: an attacker succeeds when untrusted influence combines with an action such as transmitting information to a third party or interacting with a tool. (GitHub)
AutoClaw’s email tool expands that concern. The tool allows sending plain-text email with optional local file attachments using configured SMTP credentials. That is highly practical for legitimate automation. It is also a ready-made exfiltration primitive if the agent has already been induced to read sensitive material and the environment permits outbound mail. The webhook notification tool has a similar property: if Feishu, DingTalk, or WeCom webhooks are configured, the runtime can push arbitrary text content to an external collaboration surface. Again, nothing here is “malicious by design.” The risk is that the runtime bundles retrieval, local access, and outbound communication into one planning loop. (GitHub)
The repository’s handling of local configuration reveals another important security footgun. The README warns users that if they store apiKey or other secrets in .autoclaw/setting.json, they should add .autoclaw/ à .gitignore to avoid leaking secrets. But the repository’s current .gitignore contient .env, node_modules, distet .vscode, and does not include .autoclaw. That mismatch matters. It means the project documents a leakage risk but does not eliminate the most obvious path to making that mistake by default. In security reviews, these “known footgun, not removed” patterns matter because they are exactly how operational leaks happen. (GitHub)
There is also a broader design lesson here. The safest agent runtimes treat secrets as narrowly scoped inputs delivered through a dedicated mechanism, not as generic data the model might accidentally observe, recite, or attach to downstream requests. OWASP’s Docker security guidance recommends dedicated secret-handling mechanisms rather than casual exposure in images or runtime commands, and IBM’s current agent guide repeatedly returns to memory bounds, approvals, and access controls for exactly this reason. A runtime with shell, email, and local file access should be stricter than average about secrets, not looser. (Série d'aide-mémoire de l'OWASP)
Trust boundary three, arbitrary URL handling, SSRF, and browser-mediated prompt injection
AutoClaw’s browser and screenshot tools deserve more attention than they usually get in casual reviews. The browser tool takes an arbitrary URL, launches Playwright, navigates to the page, pulls the HTML, runs it through Readability, and returns article content or raw text. The screenshot tool also accepts an arbitrary URL, launches Playwright, and captures the target into an image file. That means the agent can be induced to fetch and process arbitrary web content as part of normal operation. (GitHub)
The security issue is not only browser automation. It is the combination of browser automation with agent semantics. Palo Alto’s March 2026 research on web-based indirect prompt injection argues that the web itself is becoming an LLM prompt delivery mechanism: hostile instructions can be hidden in HTML, metadata, comments, or benign-looking content that a model later consumes during summarization, analysis, or automated decision-making. Their telemetry suggests this is no longer just a lab problem; they observed real-world attacker behavior aimed at ad review evasion, SEO manipulation, data destruction, unauthorized transactions, and sensitive information leakage. That threat model maps unusually well onto a runtime that can browse, summarize, and then act. (Unité 42)
This is also where OpenAI’s recent “social engineering” framing becomes useful. Not every successful attack on an agent will look like a crude “ignore previous instructions” payload. The more realistic attacks are often persuasive, contextual, or embedded in task-relevant prose. If the system treats retrieved content as ordinary task input and then allows the same model to choose actions, the browser becomes both a data plane and an influence plane. AutoClaw’s website-reading design makes that concern concrete rather than theoretical. (OpenAI)
There is a second risk here: SSRF and internal reachability. The public code for the browser and screenshot tools does not show a URL allowlist, RFC1918 blocklist, or metadata-service restriction. If AutoClaw is running in an enterprise VPC, a CI runner, or a container with access to internal admin panels or cloud metadata, “read this website” can become “probe this internal endpoint” surprisingly quickly. Docker docs are blunt that container setups must be treated carefully because shared mounts, privileged daemon access, and insufficient parameter validation can collapse the host-guest security boundary. The same lesson applies to agent-driven browsing: the runtime inherits the network reality of wherever it runs. (GitHub)
The screenshot tool adds one more complication. If it detects missing CJK or emoji fonts on Linux, it may attempt to modify the environment by running apk add --no-cache ou apt-get update && apt-get install -y before continuing. That behavior may be convenient in disposable development containers. In hardened production environments, it is a red flag. A screenshot feature should not quietly turn into package management with elevated implications. From a supply-chain and drift perspective, that changes a runtime from “read and render” into “read, render, and mutate the base environment when dependencies are missing.” (GitHub)

Trust boundary four, why “it runs in Docker” is not a security answer
One of AutoClaw’s strongest public claims is that it is Docker-native and built to run safely inside containers. That claim is directionally reasonable: containerization is better than handing a shell-capable agent direct access to a developer laptop with broad ambient privileges. But Docker by itself is not a security proof. Docker’s own documentation stresses that the daemon typically requires root privileges unless rootless mode is enabled, and it warns that bind mounts can give a container unrestricted access to the host filesystem if operators are careless. The same docs explicitly warn that only trusted users should control the daemon because of how powerful container parameters are. (GitHub)
That warning matters enormously for agent runtimes. If AutoClaw runs in a container with /var/run/docker.sock mounted, broad host binds, writable root filesystem, unnecessary Linux capabilities, outbound access to the whole internet, and long-lived secrets in environment variables, then the container is not meaningfully acting as a security boundary. It is merely a packaging format around a high-authority process. In that scenario, the productivity benefit of a headless agent remains real, but the safety argument collapses. (Docker Documentation)
Rootless mode is one of the few container hardening decisions that directly changes the consequences of compromise. Docker documents rootless mode as running both the daemon and containers without root privileges, and OWASP’s Docker Security Cheat Sheet recommends it because even a container breakout does not hand the attacker root on the host. That does not eliminate risk. It does make the difference between a bad runtime decision and an immediate host-level disaster much more meaningful. (Docker Documentation)
For agent systems, I would go further. A serious production deployment should assume that prompt injection, tool misuse, or logic mistakes will occasionally happen. The environment therefore needs to be designed so that those events degrade into contained failures. That means rootless execution, read-only root filesystem when practical, no Docker socket, no host / bind, no extra capabilities, no-new-privileges, tight CPU and memory limits, bounded PID count, minimal outbound egress, and a workspace volume that is both isolated and disposable. Those controls are not optional embellishments. They are the real answer to the question “What happens when the agent is wrong?” (Docker Documentation)
An illustrative deployment pattern might look like this:
services:
autoclaw:
image: your-hardened-autoclaw:latest
user: "10001:10001"
read_only: true
tmpfs:
- /tmp:size=128m,noexec,nosuid,nodev
security_opt:
- no-new-privileges:true
cap_drop:
- ALL
pids_limit: 256
mem_limit: 1g
cpus: "1.0"
volumes:
- ./workspace:/workspace:rw
working_dir: /workspace
environment:
- OPENAI_API_KEY_FILE=/run/secrets/openai_key
secrets:
- openai_key
# Prefer rootless Docker and controlled egress outside this file
secrets:
openai_key:
file: ./secrets/openai_key.txt
That kind of setup is still not “secure because container.” It is simply the minimum shape of a runtime that deserves to be called defensible. The agent code and the container posture have to be judged together, not separately. (Docker Documentation)
The CVEs that matter here are not random, they map to the same architectural mistakes
Security teams sometimes make a mistake when reviewing agent runtimes. They treat prompt injection as one bucket and software CVEs as another, as if they belong to different worlds. In reality, the two categories increasingly meet in the same execution chain. The model is manipulated through text, but the final impact still depends on classic engineering errors such as missing authentication, command injection, overbroad authority, and unsafe trust in remote services. The most relevant CVEs for AutoClaw are therefore the ones that illuminate those joins. (NIST)
CVE-2025-49596 is a good first example. NVD says versions of MCP Inspector below 0.14.1 were vulnerable to remote code execution because of a lack of authentication between the Inspector client and proxy, allowing unauthenticated requests to launch MCP commands over stdio. The lesson is not “AutoClaw is MCP Inspector.” The lesson is that developer tooling around agent execution surfaces can become an RCE boundary very quickly if authentication and command channels are treated casually. (NVD)
CVE-2025-53818 is even more directly instructive. NVD describes a command injection vulnerability in a GitHub Kanban MCP server where the add_comment tool used Node’s exécuter to run the gh CLI in an unsafe way. That is the clearest reminder in this entire cluster of issues that “tool implementation quality” is not a secondary concern in agent systems. The moment a tool takes user- or model-influenced input and forwards it into an unsafe shell primitive, the runtime has imported one of the oldest exploit classes in application security. (NVD)
CVE-2025-6514 adds a third lesson. GitHub’s advisory says mcp-remote was exposed to OS command injection when connecting to untrusted MCP servers due to crafted input from the authorization_endpoint response URL. Here the danger is not merely local tool misuse. It is the trust the client extends to a remote component during connection and authorization. That matters because modern agent systems increasingly compose multiple tools, services, and connectors. The more components an agent trusts, the more dangerous “untrusted but syntactically valid” remote input becomes. (GitHub)
If you want one recent signal from outside the MCP ecosystem, CVE-2026-26144 in Microsoft Excel is also worth noting as an adjacent warning. The public CVE record describes an information disclosure issue caused by improper neutralization of input during web page generation, and March 2026 patch analyses highlighted it as a critical Excel issue. Security reporting around the patch tied it to the broader problem of agent-enabled data exfiltration and Copilot-style workflow abuse. Whether you focus on the Office details or not, the pattern is familiar: untrusted document content plus agentic processing plus a path to external disclosure is now a recurring industry theme, not a speculative future risk. (CVE)
The table below summarizes the practical lesson of these cases for an AutoClaw review.
| CVE | Ce qui s'est passé | Why it matters for AutoClaw |
|---|---|---|
| CVE-2025-49596 | Missing authentication enabled command launch over stdio in MCP Inspector | Agent-adjacent tooling becomes RCE-capable when command paths are not protected |
| CVE-2025-53818 | Command injection through Node exécuter in an MCP tool | General-purpose shell primitives are dangerous when model or user input can shape arguments |
| CVE-2025-6514 | Untrusted remote component influenced OS command execution | Agent ecosystems fail at trust boundaries, not just at code syntax |
| CVE-2026-26144 | Untrusted content processing created an information-disclosure path | Document or content ingestion can become an exfiltration chain in agent workflows |

What AutoClaw gets right
A fair review has to acknowledge that AutoClaw makes several technically sound choices. First, it is right to reject the fantasy that all useful agent automation must look like a desktop robot. Headless, command-driven execution is often more stable, more reproducible, and more auditable than screen-scraping or multimodal pixel guessing. The repository is open about that engineering tradeoff, and for many DevOps-style automations it is the correct instinct. Deterministic interfaces are usually easier to test and reason about than visual heuristics. (GitHub)
Second, the project does not completely hide the danger of powerful modes. The README labels automatic approval as dangerous and explicitly advises caution or sandboxing. The shell tool itself does request confirmation when auto-confirm is not enabled. Those are meaningful signs that the project is not pretending ambient command execution is harmless. In a space where some agent demos still blur the line between “plan” and “permission,” even that baseline honesty is useful. (GitHub)
Third, the README’s warning about secrets in .autoclaw/setting.json shows that the maintainers understand operational leakage risk. The weakness is not absence of awareness. The weakness is failure to convert awareness into stronger defaults, such as ignoring .autoclaw out of the box or nudging users toward dedicated secret delivery. That distinction matters because it points to a path for improvement. AutoClaw does not need a different identity. It needs stricter guardrails around the identity it already has. (GitHub)
What keeps AutoClaw from being secure by default
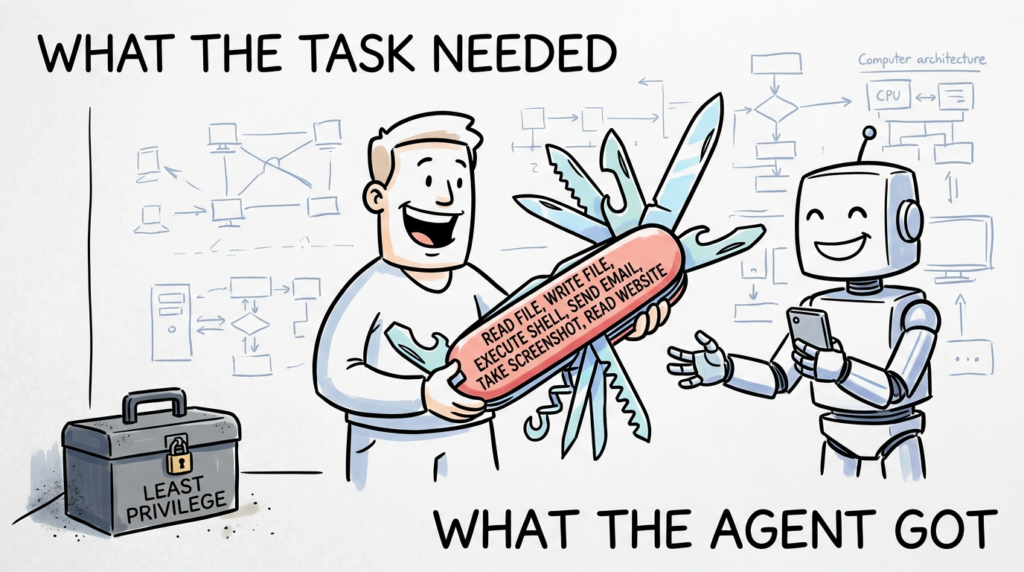
The most important weakness is the lack of a visible policy layer between model intent and tool execution. The model sees a broad tool set, chooses tools automatically, and the runtime executes the matching handler. There is no public sign, in the materials reviewed, of a separate authorization engine that reasons about path scope, URL scope, data sensitivity, or action criticality before the handler runs. OpenAI’s current guidance recommends approvals for reads and writes when using MCP tools and warns that untrusted data should not directly drive behavior. AutoClaw’s loop is powerful precisely because it compresses that distance. (GitHub)
The second weakness is capability bundling. Shell, file access, email, notifications, browsing, screenshots, search, and other tools are registered together. This makes life easier for the runtime and harder for defenders. In a safer architecture, the capabilities used for one task profile are different from the capabilities used for another. A summarization worker should not silently inherit the same authority surface as a refactoring worker or an incident-response worker. IBM’s agent-security guide repeatedly emphasizes that each added tool expands the attack surface and should be investigated, permissioned, and monitored independently. (GitHub)
The third weakness is unrestricted path and URL handling. read_file accepts a path string. write_file accepts a path string. The browser and screenshot tools accept arbitrary URLs. Those are exactly the surfaces where a serious security design usually introduces allowlists, scoping, or routing guards. Without them, least privilege is left to the surrounding deployment environment rather than encoded into the application’s own logic. That is workable for experts. It is dangerous as a default assumption for broader adoption. (GitHub)
The fourth weakness is operational maturity. package.json still shows a placeholder test script that exits with “Error: no test specified.” For a high-authority agent runtime, that matters. It does not prove the project is bad. It does suggest that the public artifact does not yet present the kind of security regression harness or behavior-verification discipline you would want before trusting it in a sensitive workflow. OWASP’s current guidance for securing agentic applications is practical rather than theoretical for a reason: once agents gain authority, evaluation and hardening have to become continuous, not optional. (GitHub)
A hardening blueprint that would materially improve AutoClaw
The first change I would make is architectural, not cosmetic. Replace free-form shell execution as the default high-power primitive with structured actions and typed arguments. When true shell access is still needed, gate it behind a dedicated policy object that evaluates command class, working directory, expected side effects, and whether the target task is allowed to invoke that class of operation at all. This is the difference between “the model can do operations” and “the model can synthesize arbitrary command strings.” The second model is much harder to secure. The first is at least governable. (NVD)
The second change is to scope the filesystem explicitly. The runtime should define a workspace root and deny reads and writes outside that root by default, with exceptions granted only for narrowly defined cases. Paths such as ~/.ssh, cloud metadata locations, OS credential stores, package manager config, shell history, and CI secret directories should never be normal model-visible terrain. If a workflow genuinely requires them, that should be an exceptional, separately approved mode with its own audit trail. (GitHub)
The third change is URL policy. Browser and screenshot tools should reject localhost, RFC1918 ranges, link-local ranges, cloud metadata addresses, and enterprise internal domains unless an operator has explicitly whitelisted them. This is where many teams underestimate their risk. An agent with “read this website” capability running inside a trusted network is not reading the public web. It is reading whatever the network path permits. Microsoft’s recent runtime-security guidance focuses on monitoring and blocking suspicious tool invocations for exactly this reason: the dangerous step is often not the initial prompt, but the later use of a tool against a sensitive system. (GitHub)
The fourth change is to separate read, write, and outward-transmission privileges. Email and webhook notifications should not be normal peers of file reading and browsing inside the same unconstrained planning loop. The runtime should treat “send data out” as a different risk class, with stronger approvals, destination restrictions, and redaction checks. OpenAI’s current public discussion of Safe URL and sensitive-data transmission is built around this same principle: potentially dangerous transmissions should not happen silently. (GitHub)
The fifth change is to stop tools from mutating the runtime environment without an explicit maintenance boundary. The screenshot tool’s package-install behavior may feel ergonomic in ephemeral containers, but in hardened systems it should either fail safely or require an operator-approved setup step. Runtime mutation complicates supply-chain review, image reproducibility, and incident response. A capture tool should not double as an on-demand package bootstrapper in production. (GitHub)
The sixth change is to harden the container posture as a first-class design requirement rather than a README suggestion. Rootless mode, read-only root filesystem, capability drops, no-new-privileges, minimal mounts, secret injection through dedicated facilities, and outbound network policy should be documented as the standard deployment model. Docker’s own security guidance and OWASP’s cheat sheet already give the baseline here. The runtime should meet that posture halfway instead of assuming “containerized” implies “contained.” (Docker Documentation)
The seventh change is continuous security evaluation. Agent systems need adversarial testing that reflects their real execution chain, not just one-time source review. OpenAI recommends evals and trace grading. Google emphasizes layered mitigation and ongoing adversarial improvement. OWASP’s agentic-app guidance is explicitly practical and deployment-focused. For AutoClaw, that means building red-team cases around prompt injection, command shaping, unsafe path requests, SSRF attempts, silent exfiltration, and long multi-step workflows where the dangerous decision emerges only after several benign-looking actions. (Développeurs OpenAI)
A compact policy wrapper might look like this:
// Illustrative pattern, not copied from the project
type ActionClass = "read" | "write" | "exec" | "network" | "egress";
function authorize(action: ActionClass, target: string, ctx: RequestContext) {
if (action === "exec" && !ctx.policy.allowExec) throw new Error("Denied");
if (action === "write" && !target.startsWith("/workspace/")) throw new Error("Denied");
if (action === "network" && isPrivateAddress(target)) throw new Error("Denied");
if (action === "egress" && !ctx.policy.approvedDestinations.has(target)) throw new Error("Denied");
}
async function guardedRead(path: string, ctx: RequestContext) {
authorize("read", path, ctx);
return fs.promises.readFile(path, "utf8");
}
The point of patterns like this is not elegance. It is enforceability. Security improves when the runtime becomes opinionated about what it refuses to do, not when the operator is expected to remember every sharp edge by hand. (Développeurs OpenAI)
What a real security review of AutoClaw should test
A professional review of AutoClaw should not stop at reading the code and assigning a vibe-based score. It should test the runtime as an execution system. The first layer is hostile-input testing: can a malicious webpage, document, or pasted instruction influence the model’s tool plan? Can that influence cross into command execution, sensitive file reads, or outbound notifications? Palo Alto’s recent field research shows that indirect prompt injection is already being weaponized in the wild, which means any agent that reads untrusted content should be assumed reachable by this class of attack. (Unité 42)
The second layer is privilege-boundary testing. If the model requests to read /etc/passwd, .env, SSH keys, package-manager config, or CI secrets, what stops it? If it tries to write into shell startup files, cron-like persistence locations, or arbitrary repository paths, what stops it? If it synthesizes boucler, nc, or package-manager commands, which controls notice and deny them? These are not exotic red-team moves. They are the first things an attacker will try once a language model can drive host actions. (GitHub)
The third layer is network-boundary testing. The review should explicitly try localhost, RFC1918 targets, metadata addresses, and fake internal hostnames through read_website et take_screenshot. It should also test how the runtime behaves when hostile HTML or prompt-like content appears in a fetched page. OpenAI’s latest public writing is useful here because it reminds defenders that not all successful prompt injection looks syntactically obvious. A page can be manipulative without looking like a toy jailbreak. (GitHub)
The fourth layer is exfiltration testing. If SMTP or webhook integrations are configured, can the runtime be induced to attach files or send summaries containing secrets? Can it be tricked into transmitting model-visible context learned during earlier steps? Microsoft’s runtime-security guidance frames this precisely as a tool-invocation control problem, not merely an input-sanitization problem. That is the right lens. Defenders should test the sink, not just the source. (GitHub)
The fifth layer is regression discipline. Once mitigations are added, the same adversarial cases should run in CI so the runtime does not drift back into dangerous behavior after feature changes. That is where many agent projects still lag behind mature application security programs. The code can look simple and still be difficult to keep safe because small ergonomic changes often reopen large authority boundaries. (Développeurs OpenAI)
AutoClaw is a good example of why agent security cannot be reduced to prompt filtering or a one-time code audit. The harder problem is continuous verification of a live execution boundary: can untrusted content gain influence, can that influence acquire authority, and can the resulting action escape the environment? That is why continuous AI red teaming is starting to matter more than static “AI safety” checklists in real deployments. Penligent’s recent writing on AI agent hacking, OpenClaw security audit, and Promptfoo all land in that same operational space: the real risk is the chain from hostile input to privileged action, and the real defense is repeated, adversarial validation of that chain over time. (penligent.ai)
Used that way, a platform like Penligent is not a marketing add-on to an AutoClaw review. It is a way to turn design concerns into testable security claims. If a team wants to say its headless agent is safe to run in a CI runner, on a build box, or inside a production-adjacent container, the important question is no longer “Did we read the code?” The question is “Did we repeatedly try to make it misbehave under realistic hostile conditions, and did the controls actually hold?” That is a much better standard for any runtime that can read files, touch tools, and act in the world. (penligent.ai)
Final verdict
AutoClaw is interesting for the right reasons. It is small, concrete, headless, and unapologetically useful. It is much closer to the way serious teams actually want to automate work than many glossy agent demos. That is also exactly why it deserves a stricter security standard than “looks container-friendly.” The repository shows a runtime that can execute commands, read and write files, browse arbitrary URLs, send mail, and push notifications, all under model-directed orchestration. That is not an ordinary application surface. It is a delegated execution surface. (GitHub)
My practical assessment is this: AutoClaw is architecturally promising, operationally sharp, and defensible only when wrapped in stronger controls than the project currently enforces by default. If you run it casually on a developer workstation or in a permissive container, the risk is high. If you run it in a hardened, rootless, least-privilege, audited, egress-controlled environment with strict tool approvals and scoped actions, the design becomes much more reasonable. But that safer version is the result of deployment discipline and additional policy engineering, not the default state of the repository. (Docker Documentation)
That is the most important takeaway for security engineers. AutoClaw should not be dismissed. It should be treated seriously enough to harden. The right question is not whether headless Docker-native agents are inherently bad. The right question is whether your implementation ensures that when the model is manipulated, wrong, or unlucky, the system fails small instead of failing as an operator. That is the standard AutoClaw has not fully met yet, and it is also the standard worth building toward. (OpenAI)
Related reading
For official grounding on the threat model, the strongest starting points are OWASP’s prompt injection material, NIST’s agent hijacking guidance, OpenAI’s recent writing on prompt injection and social-engineering-resistant agent design, Google’s layered mitigation strategy, Docker’s own security documentation, and IBM’s current guide to AI agent security. (Projet de sécurité Gen AI de l'OWASP)
For adjacent vulnerability context, the most relevant public references are NVD’s entries for CVE-2025-49596 and CVE-2025-53818, along with GitHub’s advisory for CVE-2025-6514. (NVD)
For Penligent material that fits this topic naturally, the most relevant published pieces are AI Agents Hacking in 2026: Defending the New Execution Boundary, The Future of AI Agent Security — Openclaw Security Audit, OpenClaw Security Audit, What Actually Breaks When an AI Agent Can Touch Your Files, Tools, and Accountset Promptfoo, the Engineering Reality of AI Red Teaming. (penligent.ai)