Le choix entre Gemma 4 et Qwen pour le pentesting de l'IA n'est pas vraiment un problème de benchmark. C'est un problème de flux de travail. Un système de test de pénétration ne réussit pas parce qu'un modèle semble plus précis dans le chat. Il réussit parce qu'il peut conserver l'état d'une preuve désordonnée, proposer des actions utiles, rester dans le champ d'application et éviter de transformer l'utilisation d'un outil en une nouvelle surface d'attaque. C'est exactement la raison pour laquelle l'article de PentestGPT est toujours d'actualité : sa principale conclusion n'était pas que les LLM pouvaient remplacer complètement un testeur, mais qu'ils pouvaient aider de manière significative sur des sous-tâches spécifiques, tandis que le flux de travail global avait encore besoin d'une conception modulaire pour réduire la perte de contexte et préserver la forme d'un engagement. (USENIX)
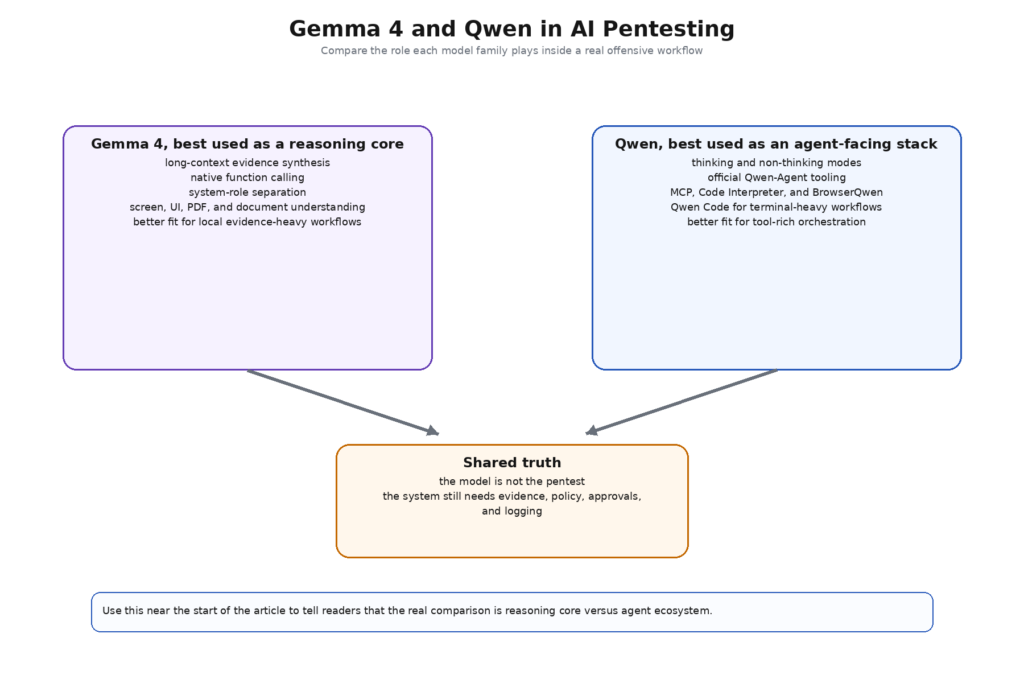
Ce cadrage change immédiatement la façon dont Gemma 4 et Qwen devraient être comparés. Les documents officiels de Gemma 4 mettent l'accent sur le contexte long, l'appel de fonctions en natif, la prise en charge en natif de la norme système Le document officiel de Qwen, quant à lui, présente l'histoire de la famille de modèles et de la pile d'agents. Les documents officiels de Qwen, en revanche, présentent l'histoire de la famille de modèles et de la pile d'agents : Qwen3 propose des variantes denses et MoE, des modes de pensée et de non-pensée, un contexte long et une force revendiquée par l'éditeur en matière d'utilisation d'outils ; Qwen-Agent ajoute les couches Function Calling, MCP, Code Interpreter, BrowserQwen et un analyseur d'appels d'outils intégré ; Qwen Code va plus loin en proposant un agent terminal-first avec des outils et des sous-agents intégrés. Il ne s'agit pas du même type de forces, et prétendre qu'elles sont identiques conduit à des conclusions superficielles. (Google AI pour les développeurs)
La question utile est donc plus étroite et plus honnête. Si vous construisez un flux de travail de pentesting d'IA qui traite le modèle comme un noyau de raisonnement local gouverné, quelle famille correspond le mieux à ce rôle ? Et si vous construisez une couche d'exécution agentique lourde en outils et conviviale en termes de terminaux, quelle famille vous donne plus de surface disponible sans cacher le nouveau risque que vous introduisez ? Une fois la question formulée de cette manière, Gemma 4 et Qwen cessent d'être des substituts directs et commencent à ressembler à deux façons différentes d'assembler le milieu d'un système de sécurité offensif. Cette distinction est importante pour les acheteurs, les constructeurs et les chercheurs. (Penligent)
Gemma 4 vs Qwen pour l'IA Pentesting commence par une comparaison équitable
La première erreur dans ce domaine est de comparer le modèle de base d'un fournisseur à l'ensemble de l'écosystème d'un autre fournisseur. Pour une discussion équitable, la comparaison modèle à modèle la plus claire est la suivante Gemma 4 31B contre Qwen3 32B, avec Qwen3 30B-A3B comme l'alternative ouverte de style MoE la plus orientée vers l'agent dans la même famille. La carte de modèle Gemma 4 de Google mentionne un modèle 31B dense et un modèle MoE A4B 26B, tous deux avec un contexte de 256K. Le référentiel officiel Qwen3 répertorie le modèle dense 32B ainsi que les variantes MoE 30B-A3B et 235B-A22B, et décrit la famille comme prenant en charge la commutation transparente entre les modes de pensée et de non-réflexion. (Google AI pour les développeurs)
La deuxième erreur consiste à dissimuler la multimodalité dans une comparaison entre un modèle de langage et un autre. Gemma 4 31B prend nativement en charge la saisie de texte et d'images dans le cadre de la même famille de modèles, et la carte de modèle de Google mentionne explicitement l'analyse de documents et de PDF, la compréhension d'écrans et d'interfaces utilisateur, l'OCR et la compréhension de graphiques parmi les capacités essentielles. Qwen peut tout à fait être compétitif dans le domaine du travail multimodal, mais la manière officielle de le faire n'est généralement pas Qwen3. Il s'agit de Qwen3-VL ou de modèles multimodaux de classe Qwen3.5. Le dépôt de Qwen3-VL le décrit comme le modèle vision-langage le plus puissant de la série Qwen à ce jour, avec une orientation visuelle-agent, un contexte natif de 256K et une extension de contexte de 1M via YaRN. Cela signifie que la réponse "Gemma 4 vs Qwen" change selon que l'on parle des modèles de langage Qwen3 ou de la pile multimodale et d'agents Qwen plus large. (Google AI pour les développeurs)
La troisième erreur consiste à supposer que le pentesting doit se préoccuper avant tout des tableaux de référence des fournisseurs. Ce n'est pas le cas. Les tableaux de référence des fournisseurs permettent de savoir comment un fournisseur souhaite que sa famille de modèles soit comprise. Ils ne permettent pas de savoir comment le modèle se comportera si on lui donne des captures d'écran d'un portail d'administration, une trace de navigateur partiellement authentifiée, des itinéraires extraits en JavaScript, une matrice de différences de rôles et l'obligation de ne pas dépasser le champ d'application ou de ne pas déclencher d'actions destructrices. Le pentesting est un problème de système. Le modèle est important, mais seulement à l'intérieur du plan de contrôle qui l'entoure. C'est la même leçon à laquelle reviennent sans cesse les écrits publics sur le pentest et l'IA : la question durable n'est pas "quel modèle explique...", mais "quel modèle explique...". nmap mais "quel système peut passer d'un signal brut à un résultat vérifié sans perdre le contrôle". (Penligent)
Une comparaison équitable comporte donc quatre niveaux. La première est le modèle lui-même : longueur du contexte, mode de raisonnement, types d'entrée et comportement d'inférence de base. Deuxièmement, la surface de l'outil : appel de fonction, support de l'analyseur, cadres d'agents et intégration des terminaux. Le troisième est la surface du garde-fou : la facilité avec laquelle la politique, le champ d'application et l'exécution sont séparés du modèle. Quatrièmement, la surface opérationnelle : la facilité avec laquelle le modèle et son outillage peuvent être déployés localement, gouvernés, audités et tenus à l'écart du mauvais chemin du réseau. Une fois que l'on compare Gemma 4 et Qwen à ces quatre niveaux, le choix devient beaucoup moins idéologique et beaucoup plus pratique. (Google AI pour les développeurs)
La surface de capacité officielle qui compte dans le pentesting de l'IA
Avant de parler du meilleur modèle, il convient d'examiner ce que Google et Qwen documentent publiquement, car les conclusions les plus sûres proviennent généralement des parties ennuyeuses des documents, et non du battage médiatique du jour du lancement. Les documents Gemma 4 de Google indiquent que les modèles 31B dense et 26B A4B medium supportent 256K de contexte, la pensée configurable, l'entrée multimodale, l'appel de fonction, et le support natif de la technologie système rôle. Google documente également les besoins approximatifs en mémoire d'inférence du modèle 31B à 58,3 Go en BF16, 30,4 Go en 8 bits et 17,4 Go en Q4_0, tout en avertissant que le contexte et la surcharge logicielle sont supplémentaires. Le dépôt officiel de Qwen3 documente les modèles denses et MoE de 0,6B à 32B, 30B-A3B et 235B-A22B, ainsi que la commutation entre les modes pensant et non pensant et la gestion des contextes longs que le dépôt décrit comme 256K, extensible à 1 million de tokens. (Google AI pour les développeurs)
Ce qui importe pour le pentesting, ce n'est pas seulement l'existence de ces caractéristiques, mais le type de travail qu'elles facilitent. Un contexte long est utile lorsqu'un modèle doit raisonner sur des paquets de preuves. L'appel de fonctions natives est utile lorsque le modèle doit demander des actions délimitées au lieu d'imprimer des chaînes de commande arbitraires. La prise en charge native de la fonction système Le rôle est important car le plan de contrôle d'un pentest bénéficie d'une séparation nette entre les instructions de politique et les preuves cibles. L'entrée multimodale est importante si votre flux de travail comprend des captures d'écran, des PDF internes et des applications à forte interface utilisateur. Les modes de réflexion et de non-réflexion sont importants car les flux de travail offensifs contiennent à la fois des phases de raisonnement et des phases de répétition rapide. Le danger est que les différentes familles de modèles exposent ces forces sous des formes très différentes. Gemma 4 les intègre davantage dans l'interface de la même famille. Qwen les pousse davantage dans un écosystème plus large de famille de modèles et de pile d'agents officiels. (Google AI pour les développeurs)
| Domaine de compétence | Surface officielle de Gemma 4 | Surface officielle de Qwen | L'importance du pentesting de l'IA | Source |
|---|---|---|---|---|
| Fenêtre contextuelle principale | Jusqu'à 256K sur 31B et 26B A4B | Compréhension du contexte long 256K, extensible à 1M dans le langage Qwen3 repo | Les enquêtes plus longues nécessitent plus d'espace pour les reconnaissances, les traces, les notes et les changements de rôle. | (Google AI pour les développeurs) |
| Mode de raisonnement | Mode de réflexion configurable sur l'ensemble de Gemma 4 | Modes de réflexion et de non-réflexion, avec commandes de commutation explicites | Les flux de pentest alternent entre des analyses approfondies et des tournants opérationnels plus légers | (Google AI pour les développeurs) |
| Fonction et utilisation des outils | Appel de fonctions natives, et avertissement explicite de Google que l'exécution doit être validée de manière externe | Qwen3 met l'accent sur l'utilisation d'outils, et Qwen-Agent ajoute l'appel et l'analyse natifs d'outils en plusieurs étapes. | L'utilisation des outils n'est utile que lorsqu'elle est structurée et contrôlée | (Google AI pour les développeurs) |
| Chemin multimodal | Gemma 4 31B prend en charge la saisie de texte et d'images dans la même famille, y compris l'interface utilisateur et la compréhension des PDF. | L'histoire multimodale de Qwen vit principalement dans Qwen3-VL et les familles apparentées. | Les tests d'applications basés sur des captures d'écran modifient la signification de l'expression "meilleur modèle". | (Google AI pour les développeurs) |
| Cadre pour les agents | Pas de cadre officiel unique pour l'agent Gemma-first comparable à Qwen-Agent | Qwen-Agent prend officiellement en charge MCP, Code Interpreter, BrowserQwen et les outils personnalisés. | Un outillage officiel plus solide peut accélérer les prototypes agentiques | (Qwen) |
| L'histoire d'un agent de terminal | Les appels de fonction existent, mais l'outillage terminal n'est pas le principal sujet d'intérêt public. | Qwen Code est un agent open-source pour les modèles Qwen. | L'examen des opérations de pension, la rédaction de scripts et les flux de travail nécessitant beaucoup d'outils se déroulent souvent dans le terminal. | (GitHub) |
Même ce tableau peut induire en erreur s'il est lu avec trop de désinvolture. Le fait que Qwen dispose d'une plus grande surface d'outils officiels ne le rend pas automatiquement meilleur pour le pentesting de l'IA. Cela signifie que Qwen est plus facile à positionner en tant que famille de modèles au sein d'une pile d'agents. Le fait que Gemma 4 intègre la multimodalité, la prise en charge des rôles système, l'appel de fonction et la possibilité de déploiement local dans une seule famille documentée ne la rend pas automatiquement plus forte dans l'ensemble. Cela signifie que Gemma est plus facile à positionner en tant que couche de raisonnement local contrôlé. Il s'agit là de choix différents en matière de conception de système, et une équipe de pentesting peut raisonnablement préférer l'un ou l'autre en fonction de l'endroit où se trouve la partie la plus coûteuse de son flux de travail. (Google AI pour les développeurs)
Gemma 4 s'adapte naturellement au raisonnement local du pentest
L'argument le plus fort de Gemma 4 en matière de sécurité offensive n'est pas qu'il s'agit du modèle ouvert le plus agentique sur le papier. C'est que la documentation de Google elle-même rend exceptionnellement facile son utilisation en tant que noyau de raisonnement local sans prétendre que le modèle lui-même devrait posséder l'exécution. Les documents de Google traitent longuement du contexte, de la prise en charge des rôles du système, de l'appel de fonctions et d'un ensemble de capacités multimodales qui s'alignent de manière presque suspecte sur les preuves réelles du pentest : analyse de documents et de PDF, compréhension de l'interface utilisateur et de l'écran, reconnaissance optique de caractères et compréhension des graphiques. Le guide d'appel de fonctions de Google énonce aussi clairement le garde-fou le plus important : un modèle Gemma ne peut pas exécuter de code par lui-même, et tout code généré doit être exécuté et validé par l'application avec des garde-fous en place. C'est exactement le bon modèle mental pour une sécurité offensive. (Google AI pour les développeurs)
Pourquoi cela est-il important ? Parce que la partie centrale la plus difficile du pentesting n'est généralement pas la syntaxe d'exploitation. C'est l'interprétation des preuves. C'est la lecture d'un paquet client et la décision de savoir si /api/v1/admin/export est probablement accessible uniquement à partir d'un rôle privilégié ou si le client masque une limite plus faible du côté du serveur. Il s'agit de comparer les captures d'écran de deux rôles d'utilisateur et de décider si un contrôle caché mérite une étape de validation en lecture seule. Il s'agit de prendre un replay diff authentifié et de reconnaître que le même objet commercial expose différents jeux de champs sous différents rôles d'une manière qui suggère une autorisation non respectée au niveau de l'objet. Un modèle capable de conserver davantage de preuves dans un contexte actif et de raisonner sur des indices d'interface utilisateur, des traces de texte et des itinéraires extraits au sein d'une interface est véritablement utile. (Google AI pour les développeurs)
Gemma 4 bénéficie également d'une histoire plus claire sur le contrôle local. La documentation de Google place les modèles 31B et 26B A4B sur le territoire des GPU grand public et des stations de travail, tandis que les modèles plus petits sont explicitement décrits comme compatibles avec les appareils. Le tableau de mémoire publié indique clairement que le modèle 31B n'est pas un jouet portable occasionnel, mais il s'agit toujours d'une famille de modèles sur laquelle vous pouvez raisonner dans le cadre d'un plan de déploiement privé plutôt qu'en tant que dépendance à l'API hébergée. C'est important lorsque les preuves comprennent des captures d'écran internes, des traces brutes, des rapports partiellement expurgés ou des artefacts de conception que les équipes ne veulent pas voir circuler dans plus de systèmes que nécessaire. Dans un programme de pentest, l'inférence locale est rarement une question d'idéologie. Il s'agit généralement de contrôler les preuves. (Google AI pour les développeurs)
La structure des invites et des rôles de Gemma 4 présente un autre avantage subtil. La documentation de Google sur le formatage de l'invite montre des jetons de contrôle explicites pour système, utilisateuret modèle plus des jetons de contrôle distincts pour l'agent et le raisonnement. Cela est important dans une architecture de pentest surveillée, car les règles de politique, de portée et d'approbation ne doivent pas se trouver dans la même soupe textuelle que les preuves cibles. Les équipes de sécurité parlent souvent de ce problème comme d'une hygiène rapide, mais la question plus profonde est celle de la séparation des autorités. Un modèle qu'il est plus facile de maintenir à l'intérieur d'une frontière de conversation structurée est plus facile à envelopper dans un plan de contrôle plus sûr. Gemma 4 n'est pas le seul à soutenir les rôles, mais la documentation de Google place cette capacité juste à côté du raisonnement et du contrôle des outils au lieu de la traiter comme une note de bas de page de l'implémentation. (Google AI pour les développeurs)
Le résultat pratique est que Gemma 4 ressemble à une famille de modèles qui veut s'asseoir derrière une couche de normalisation. Les preuves proviennent des collecteurs, sont transformées en enregistrements structurés, atterrissent dans une invite de contexte long ou un cadre d'extraction, et le modèle renvoie des hypothèses, des classements et des demandes d'action plutôt que des commandes. C'est exactement comme cela que devrait se comporter un flux de travail de pentesting IA sérieux. Les écrits de Public Penligent sur les pentesters IA utilisent presque le même cadre lorsqu'ils définissent un pentester IA comme un système gouverné qui réduit la distance entre le signal brut et la découverte vérifiée plutôt que comme un chatbot jouet ou un bot d'exploitation autonome. C'est l'endroit le plus utile pour placer Gemma 4 dans la pile. (Penligent)
Cela ne signifie pas que Gemma 4 est manifestement meilleur dans toutes les tâches de pentesting. Cela signifie que la forme documentée de la famille s'aligne très bien sur une architecture de sécurité dans laquelle le modèle est puissant mais pas souverain. Il s'agit là d'une distinction importante. Dans de nombreux programmes offensifs, le problème le plus difficile n'est pas "comment faire en sorte que le modèle soit plus performant". Il s'agit plutôt de savoir comment faire en sorte que le modèle ne fasse que ce qu'il faut, tout en restant utile. La conception et la documentation publiques de Gemma 4 rendent cette discipline plus facile à défendre. (Google AI pour les développeurs)
Qwen s'adapte naturellement à une pile d'agents riche en outils.
Le cas le plus solide de Qwen dans le pentesting de l'IA se trouve ailleurs. Si Gemma 4 ressemble à un noyau de raisonnement local propre, Qwen ressemble à un écosystème qui a déjà décidé que l'utilisation d'outils fait partie de l'histoire du produit. Le référentiel Qwen3 décrit la famille comme prenant en charge la commutation transparente entre les modes de réflexion et de non-réflexion, les modèles denses et MoE, la compréhension du contexte long de 256K extensible à 1 million de tokens, et l'expertise dans les capacités d'agent avec l'intégration d'outils externes dans les modes de réflexion et de non-réflexion. Il s'agit déjà d'une position plus ouvertement orientée vers les agents que ce que Google dit à propos de Gemma 4 (GitHub)
L'écosystème officiel prend ensuite le relais. La documentation de Qwen-Agent mentionne la prise en charge native de l'appel d'outils en parallèle et en plusieurs étapes, l'intégration MCP, l'interpréteur de code, la recherche et l'extraction sur le web, les outils personnalisés, la gestion du contexte et un assistant orienté navigateur appelé BrowserQwen. Le référentiel Qwen Code étend cette prise en charge à un agent open-source terminal-first optimisé pour les modèles Qwen, avec des outils intégrés, des sous-agents, une intégration IDE et un flux de travail conçu pour les personnes qui vivent dans des lignes de commande et des bases de code. Il ne s'agit pas d'une différence mineure. Pour les équipes dont le flux de travail de pentest dépend déjà de l'écriture de scripts, de la révision de repo, de l'automatisation de laboratoire, de contrôleurs de terminal ou de registres d'outils personnalisés, la pile officielle de Qwen réduit la quantité de colle qu'ils doivent écrire avant que le système ne ressemble à un agent plutôt qu'à une enveloppe de chat. (Qwen)
C'est important parce qu'une part surprenante du travail de pentesting de l'IA n'est pas un raisonnement à partir d'une page web. Il s'agit d'un raisonnement de type "workbench". Il s'agit de lire du code, d'extraire des itinéraires, de trier des artefacts volumineux, de transformer des preuves, d'écrire des scripts d'aide ou d'orchestrer des étapes de validation répétées. Qwen Code n'est pas un cadre de pentesting, et il serait irresponsable de le commercialiser de cette manière. Mais c'est un bon exemple de la raison pour laquelle Qwen semble plus naturel lorsqu'un flux de travail devient lourd en terminaux. Il est officiellement décrit comme un agent IA open-source pour le terminal, optimisé pour les modèles de la série Qwen, avec de riches outils intégrés, des sous-agents et une expérience de type "Claude Code". C'est exactement le type de surface que les équipes de sécurité finissent souvent par réaffecter à des tâches offensives lourdes en termes d'ingénierie. (GitHub)
La séparation entre réflexion et non-réflexion a également une véritable valeur opérationnelle. Les flux de travail offensifs sont hétérogènes. Certaines étapes nécessitent un raisonnement approfondi : classement des chemins d'attaque, interprétation du flux d'authentification, explication de la cause première. D'autres étapes veulent de la rapidité et de la structure : classer ce point final, réécrire ce modèle de demande, résumer cette trace, générer ce squelette de rapport ou reformater ces artefacts. Le repo officiel de Qwen3 documente deux façons de contrôler ce comportement : au niveau du tokenizer enable_thinking=False et /penser ou /no_think instructions dans le système ou dans le message de l'utilisateur. Cela rend Qwen intéressant pour les équipes qui souhaitent qu'une seule famille couvre à la fois les tournants "réfléchir sérieusement" et "agir rapidement" au sein d'une seule couche d'orchestration. (GitHub)
Il existe cependant un problème qui est plus important dans le domaine de la sécurité que dans celui de l'outillage de développement ordinaire. Plus la surface de l'outil est riche, plus le problème des limites devient difficile. Qwen-Agent fournit explicitement un code_interprétation qui exécute du code Python. Il prend explicitement en charge l'intégration MCP. Il prend explicitement en charge les outils externes et les outils personnalisés. Cette puissance est utile. Elle rappelle également qu'une pile de pentesting d'IA centrée sur Qwen est susceptible d'accumuler une surface d'exécution plus large plus rapidement qu'une pile de raisonnement centrée sur Gemma. En d'autres termes, la chose qui rend Qwen plus facile à adopter pour l'automatisation agentique est également la chose qui rend la gouvernance plus urgente. (Qwen)
La documentation de Qwen fait même apparaître une note de bas de page technique, petite mais révélatrice. Dans son dépôt Qwen3, les notes de service pour SGLang avertissent que le prétraitement des requêtes peut faire chuter le nombre d'utilisateurs. contenu du raisonnementLe projet recommande une solution de contournement pendant que les corrections sont en cours. Ce n'est pas un scandale. C'est quelque chose de mieux : un rappel réaliste que la qualité agentique en production dépend de l'ensemble du chemin de service, et pas seulement du point de contrôle du modèle. Les équipes de sécurité devraient lire ce genre de note aussi attentivement qu'elles lisent les tableaux de référence, car dans l'automatisation offensive, la qualité de la plomberie décide souvent si une capacité survit au contact avec la pile réelle. (GitHub)
Qwen n'est donc pas "meilleur pour le pentesting de l'IA" dans un sens universel. Il est meilleur si votre définition du problème inclut déjà un cadre d'agent réel, une intégration de terminal, des capacités de type interprète de code, une connectivité MCP et une orchestration multi-outils. Si c'est la pile que vous avez l'intention de construire, Qwen vous donne des blocs de construction plus officiels. Le prix à payer est que vous possédez maintenant une surface de contrôle plus large et plus dangereuse. Dans le pentesting, ce n'est jamais une note de bas de page. C'est l'histoire. (Qwen)
Les preuves multimodales modifient la comparaison plus que ne l'admettent la plupart des revues de modèles.
De nombreuses comparaisons de modèles considèrent encore la multimodalité comme une caractéristique du consommateur. Dans le pentesting de l'IA, ce n'est pas le cas. Les flux de travail riches en captures d'écran et en documents sont courants, et c'est souvent là que l'assistance LLM devient utile. Pensez aux preuves réelles qu'une équipe offensive traite : captures d'écran de portails d'administration, consoles de facturation, tableaux de bord internes, files d'attente de modération, écrans d'exportation, interfaces utilisateur avec drapeaux, flux spécifiques à un rôle, PDF d'architecture et longs documents d'assistance ou de mise en œuvre. Un modèle capable de raisonner sur ces données modifie directement le sens de l'expression "AI pentesting". (Google AI pour les développeurs)
C'est là que Gemma 4 devient exceptionnellement attrayant. La carte modèle de Google mentionne explicitement l'analyse de documents et de PDF, la compréhension d'écrans et d'interfaces utilisateur, l'OCR et le traitement d'images à résolution variable comme étant des capacités essentielles de compréhension d'images. Cela signifie que la même famille qui gère le raisonnement sur les textes longs et l'appel de fonctions peut également consommer des captures d'écran et des documents dans la même voie de modélisation. Pour les équipes qui construisent un flux de travail local centré sur les preuves, il s'agit d'une grande simplification. Vous n'avez pas besoin d'une famille multimodale distincte pour déterminer si une capture d'écran ressemble à une console d'exportation interne, à une vue de modération réservée au personnel ou à un tableau de bord d'utilisateur normal avec des différences esthétiques. (Google AI pour les développeurs)
Qwen peut tout à fait répondre à ce défi, mais la réponse passe généralement par une ligne de modèle différente. Le référentiel de Qwen3-VL décrit une histoire complète d'agent visuel, y compris le fonctionnement de l'interface graphique, des capacités d'interaction d'agent plus fortes, un contexte natif de 256K et des fonctions d'analyse de documents. Si une équipe est prête à étendre le côté "Qwen" de la comparaison des modèles linguistiques Qwen3 à Qwen3-VL plus Qwen-Agent, alors l'écart multimodal se réduit considérablement et peut disparaître pour certains flux de travail. Mais il s'agit alors d'une décision différente que "Gemma 4 31B vs Qwen3 32B". Cela devient "une famille où la multimodalité fait déjà partie de la comparaison" par rapport à "une famille plus large où la multimodalité vit dans une branche adjacente dédiée". Il s'agit là d'une différence architecturale significative. (GitHub)
En termes de pentesting, la distinction se manifeste dans la façon dont le pipeline de preuves devient désordonné. Si le modèle doit inspecter en permanence des captures d'écran, des PDF et l'état de l'interface utilisateur, il est plus facile, d'un point de vue opérationnel, que le modèle de raisonnement et le chemin de raisonnement visuel soient de la même famille et de la même histoire de garde-fou. Si l'équipe utilise déjà une pile d'agents plus modulaire, la séparation du raisonnement linguistique et du raisonnement visuel peut être acceptable, voire souhaitable. Mais la décision doit être prise en toute connaissance de cause. Trop de discussions sur le "meilleur modèle pour le pentesting" cachent cette complexité en faisant l'éloge des captures d'écran ou des performances de l'interface utilisateur d'un modèle sans dire si cela a nécessité une famille de modèles différente ou un échafaudage d'agents supplémentaire. (Google AI pour les développeurs)
C'est important dans le travail offensif réel car les preuves multimodales sont souvent le chemin le plus court vers une étape suivante correcte. Un bouton d'exportation du backend visible uniquement par un rôle peut avoir plus d'importance que dix résumés génériques de vulnérabilités. Un simple PDF décrivant les approbations du flux de travail interne peut avoir plus d'importance qu'une semaine de vagues discussions sur le modèle de menace. Une capture d'écran côte à côte d'un utilisateur de base et d'un administrateur de facturation peut révéler un gradient de privilèges qui mérite d'être testé avant qu'un rejeu HTTP ne se produise. Si le modèle n'est pas en mesure d'intégrer naturellement ces éléments de preuve, l'effort humain augmente. S'il peut l'ingérer, mais uniquement par l'intermédiaire d'un sous-système distinct dont les garde-fous sont moins stricts, le risque système augmente. Le "meilleur" choix dépend de celui de ces deux coûts qui est le plus préjudiciable dans votre environnement. (Penligent)
Il s'agit d'un cas où le cadrage public de Penligent est utile, même si l'on ignore le produit lui-même. Ses écrits récents sur les pentesters de l'IA et les outils de pentest de l'IA reviennent toujours au même point opérationnel : le problème difficile n'est pas un résumé impeccable. Il s'agit de transformer des éléments de preuve diversifiés et contenant des états en résultats validés dans le cadre d'un flux de travail contrôlé. Les preuves multimodales font partie intégrante de ce problème. Les équipes qui les considèrent comme une caractéristique secondaire concevront des comparaisons et des systèmes moins performants. (Penligent)
L'utilisation d'outils et de garde-fous modifie le modèle de menace avant d'améliorer le flux de travail.
Dès qu'un modèle cesse d'être un lecteur et commence à devenir un demandeur d'actions, le modèle de menace change. Le Top 10 de l'OWASP pour les applications LLM conserve l'injection rapide, la gestion non sécurisée des sorties, la conception non sécurisée des plugins et l'agence excessive en tant que catégories distinctes parce que les systèmes d'IA modernes échouent exactement de cette manière. Le GenAI Red Teaming Guide aborde le même point sous un autre angle : une évaluation sérieuse doit examiner le modèle, l'implémentation, l'infrastructure et le comportement en cours d'exécution ensemble. Dans le pentesting, cet avertissement est encore plus difficile à obtenir parce que le système est intentionnellement dirigé vers une entrée hostile ou semi-hostile, et parce que ses outils sont souvent plus privilégiés que les aides d'application ordinaires. (OWASP)
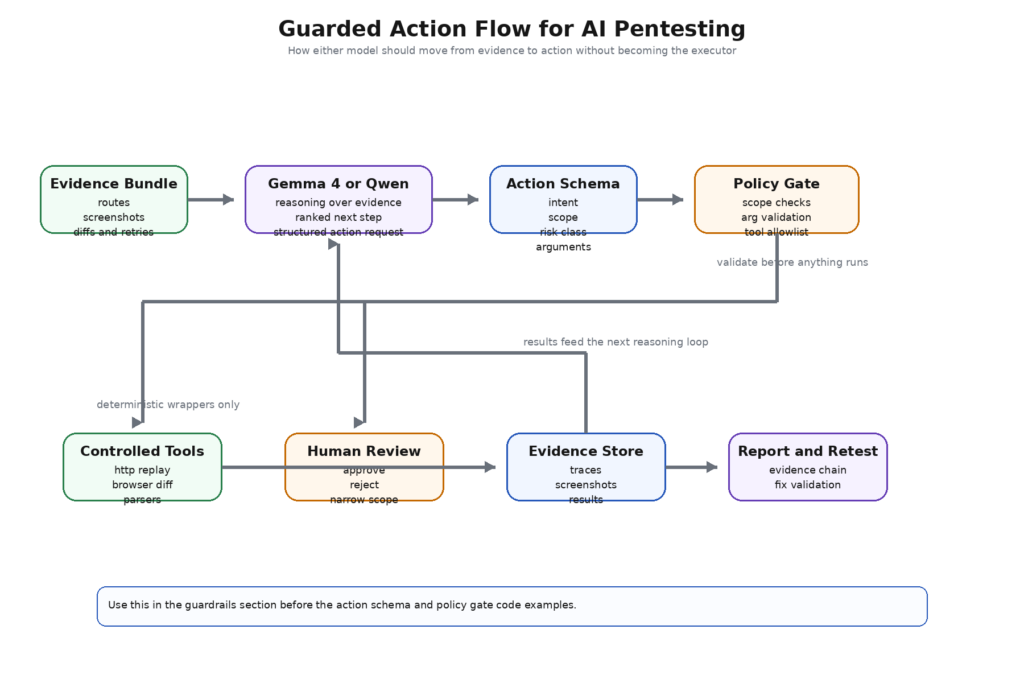
C'est pourquoi la bonne architecture pour Gemma 4 ou Qwen n'est pas "le modèle écrit des commandes et les outils les exécutent". La bonne architecture est la suivante : "le modèle émet des demandes d'action structurées, la politique les évalue, l'opérateur les approuve le cas échéant, et ce n'est qu'ensuite que les enveloppes déterministes s'exécutent". Le guide d'appel de fonctions Gemma de Google indique explicitement que le modèle ne peut pas exécuter de code seul et que le code généré doit être validé avant d'être exécuté. Cette phrase doit être considérée comme un principe architectural, et non comme une note d'utilisation. La surface d'outils plus riche de Qwen-Agent rend le même principe encore plus important, précisément parce qu'il inclut des éléments tels que l'interpréteur de code et la connectivité MCP dès le départ. (Google AI pour les développeurs)
Dans la pratique, un contrat d'action sûre semble ennuyeux. C'est une bonne chose. Le modèle doit renvoyer des champs typés comme intention, champ d'application cible, classe_de_risque, outil_nécessaire, arguments, base_de_la_preuveet besoins_approbation. Il ne doit pas renvoyer de données brutes Bash ou PowerShell pour une exécution directe. Il ne doit pas interpoler des arguments non contrôlés dans les chaînes de caractères de l'interpréteur de commandes. Il ne doit pas décider silencieusement qu'une opération de changement d'état compte comme "lecture seule". Un plan de contrôle de pentest veut que le modèle se comporte comme un planificateur et un classificateur, pas comme un shell racine avec un meilleur anglais. Cela est vrai que le modèle soit Gemma 4, Qwen, ou n'importe quoi d'autre. (Google AI pour les développeurs)
Voici le type d'objet d'action qui permet à un modèle d'être utile sans être souverain :
{
"intent" : "verify_object_level_authorization",
"target_scope" : {
"project_id" : "acme-b2b-portal",
"asset" : "app.target.example",
"route_group" : "/api/v1/invoices"
},
"risk_class" : "credentialed_read_only_replay",
"outil_nécessaire" : "http_replay_runner",
"arguments" : {
"method" : "GET",
"candidate_object_ids" : ["inv_1042", "inv_1043", "inv_1044"],
"profils_de_rôle" : ["basic_user", "billing_admin"].
},
"evidence_basis" : [
"bundle_extract:/api/v1/invoices/{invoice_id}",
"ui_screenshot:billing_export_screen",
"response_diff:role_matrix_02"
],
"needs_approval" : true
}
Ce schéma est utile parce qu'il limite la responsabilité du modèle. Le modèle est chargé de décrire quel type de contrôle est justifié, dans quel champ d'application et sur quelle base de preuve. Le plan de contrôle est chargé de décider si l'outil demandé est autorisé, si les arguments sont sûrs, si l'action correspond à la classe de risque déclarée et si un opérateur doit l'approuver. Les équipes de sécurité qui omettent cette séparation redécouvrent généralement le même problème sous un autre nom : le modèle a dit quelque chose de plausible, un autre système lui a fait trop confiance et un outil dangereux est devenu la véritable vulnérabilité. Il ne s'agit pas d'un "bug d'IA". Il s'agit d'un problème d'architecture. (OWASP)
Un simple portail politique rend la distinction concrète :
ALLOWED_TOOLS = {
"passive_recon_runner",
"http_replay_runner",
"screenshot_diff_runner",
"js_endpoint_mapper",
"report_writer",
}
RISK_CLASSES = {
"passive" : {"approval" : False, "state_change" : False},
"credentialed_read_only_replay" : {"approval" : True, "state_change" : False True, "state_change" : False},
"ui_navigation_only" : {"approval" : True, "state_change" : False} : True, "state_change" : False},
"state_modifying" : {"approval" : True, "state_change" : False} : True, "state_change" : True},
"interdit" : {"approval" : True, "state_change" : True}, "interdit" : {"approval" : True, "state_change" : True}, "prohibited" : {"approval" : True True, "state_change" : True},
}
def validate_action(action, allowed_assets) :
asset = action["target_scope"]["asset"]
si l'actif n'est pas dans allowed_assets :
return False, "asset outside scope"
tool = action["required_tool"]
si l'outil n'est pas dans ALLOWED_TOOLS :
return False, "outil non autorisé"
risk_class = action["risk_class"]
si risk_class ne figure pas dans RISK_CLASSES :
return False, "classe de risque inconnue"
si classe_de_risque == "interdit" :
return False, "bloqué par la politique"
return True, "autorisé"
def dispatch(action) :
# Enveloppe déterministe, pas d'interpolation brute du shell
return f "queued:{action['required_tool']}"
Ce type d'enveloppe n'est pas très glamour, mais c'est ce qui rend le pentesting de l'IA défendable. Les documents de Public Penligent sur la sécurité agentique et les pentesters de l'IA ont la même thèse sous-jacente, même s'ils ne parlent pas d'une famille de modèles spécifique : le chemin qui mène du signal brut à l'action doit être régi, contrôlable et étayé par des preuves. C'est la bonne optique pour comparer Gemma 4 et Qwen. La question n'est pas de savoir qui peut appeler le plus d'outils. Il s'agit de savoir qui s'inscrit le plus clairement dans le modèle de contrôle que vous pouvez réellement défendre. (Penligent)
Des CVE récents expliquent la différence réelle mieux que ne le font les références des fournisseurs.
Les équipes chargées de la sécurité devraient prêter une attention particulière aux récents CVE dans les cadres d'agents et les couches d'exécution d'outils, car ils révèlent où le choix du modèle cesse d'avoir de l'importance et où la conception du système commence à en avoir beaucoup. Il ne s'agit pas de débats abstraits sur la sécurité. Il s'agit d'échecs de production qui montrent ce qui se passe lorsque des systèmes en langage naturel se rapprochent trop de l'exécution privilégiée.
L'exemple le plus direct est CVE-2026-27966 dans Langflow. NVD décrit une faille d'exécution de code à distance dans le nœud de l'agent CSV avant la version 1.8.0. Le problème était que le nœud codait en dur allow_dangerous_code=Truequi exposait automatiquement l'outil Python REPL de LangChain. Cela a transformé l'injection d'invite en exécution arbitraire de commandes Python et du système d'exploitation. Il est difficile d'imaginer une meilleure démonstration de la raison pour laquelle "l'utilisation d'outils plus puissants" n'est pas une victoire gratuite dans le pentesting de l'IA. Si votre pile permet à un modèle d'atteindre facilement une primitive générale d'exécution de code, un problème de manipulation au niveau du contenu peut rapidement devenir un problème de compromission du serveur. (NVD)
La leçon à tirer de la comparaison entre Gemma 4 et Qwen n'est pas "Qwen est risqué" ou "Gemma est sûr". La leçon est qu'une pile centrée sur Qwen, parce qu'elle vous donne plus d'outils officiels pour les agents et des chemins plus immédiats vers l'exécution de code et l'intégration MCP, vous permettra généralement de construire un agent plus capable plus rapidement. Elle vous permettra également de créer plus rapidement un agent plus dangereux. Une pile centrée sur Gemma, parce qu'elle vous pousse plus naturellement vers la validation externe et les modèles d'appel de fonction contrôlés, facilite souvent le maintien du modèle du côté du raisonnement. La question de savoir si c'est un avantage dépend de vos besoins, mais il s'agit absolument d'un compromis de conception, et non d'une question de goût. (Google AI pour les développeurs)
Le deuxième cas instructif est le suivant CVE-2025-53355 en mcp-server-kubernetes. La NVD affirme que le serveur MCP a utilisé des paramètres d'entrée non nettoyés à l'intérieur d'un fichier de type processus_enfant.execSync permettant l'injection de commande et l'exécution potentielle de code à distance, avec un correctif dans la version 2.5.0. C'est exactement le type de bogue qui importe aux architectes de pentesting d'IA, car il ne concerne pas vraiment Kubernetes. Il s'agit de la frontière de l'agent. À partir du moment où un modèle peut passer des arguments dans un wrapper d'outil qui atteint un shell ou une API à haut privilège, chaque paramètre devient une partie de la surface d'attaque. Si vous choisissez un écosystème d'utilisation d'outils plus riche, c'est la classe d'erreur contre laquelle vous devez être prêt à concevoir. (NVD)
Le troisième cas, CVE-2025-66414NVD, qui a été mis en place par le ministère de l'Agriculture, déplace l'avertissement dans les flux de travail des développeurs locaux. NVD indique que le SDK TypeScript officiel pour MCP n'activait pas la protection contre le rebinding DNS par défaut pour les serveurs basés sur HTTP avant la version 1.24.0. Si un serveur HTTP MCP non authentifié fonctionnait sur localhost sans protection contre le rebinding, un site web malveillant pourrait exploiter le rebinding DNS pour contourner les restrictions d'origine identique du navigateur et envoyer des requêtes à ce serveur MCP local. Ce cas est important car "local" est souvent utilisé comme synonyme de "sûr" dans les outils d'IA. Ce n'est pas le cas. L'inférence locale et l'outillage local sont précieux, mais une fois qu'ils sont exposés au réseau de la mauvaise manière, ils deviennent juste un autre service accessible avec des pouvoirs inhabituellement intéressants. (NVD)
Le quatrième cas, CVE-2025-67511L'article de NVD est encore plus proche du cas d'utilisation de la sécurité offensive. La NVD décrit une faille d'injection de commande dans le cadre de Cybersecurity AI. run_ssh_command_with_credentials() disponible pour les agents d'intelligence artificielle dans les versions 0.5.9 et inférieures. Seuls les mots de passe et les entrées de commande ont été échappés, tandis que le nom d'utilisateur, l'hôte et le port sont restés injectables, et le problème n'a pas été résolu au moment de la publication. C'est exactement ce qui se passe lorsqu'un outil de sécurité orienté IA expose des actions puissantes à travers des interfaces mal délimitées. Le modèle n'est pas le seul problème de sécurité. L'outil "utile" qui l'entoure devient la vulnérabilité. (NVD)
| CVE | Zone affectée | Ce qui a cassé | L'importance de Gemma 4 contre Qwen dans le pentesting de l'IA | Source |
|---|---|---|---|---|
| CVE-2026-27966 | Langflow CSV Agent | L'injection d'une invite a atteint la REPL de Python parce que l'exécution de code dangereux était activée. | Des outils d'agent plus riches peuvent réduire la manipulation au niveau du contenu en RCE si les limites d'exécution sont lâches. | (NVD) |
| CVE-2025-53355 | mcp-server-kubernetes | Paramètres non assainis en execSync injection de commande activée | Les écosystèmes d'outils solides exigent une validation stricte des arguments et aucune interpolation de l'interpréteur de commandes. | (NVD) |
| CVE-2025-66414 | MCP TypeScript SDK | La protection contre le rebond du DNS est désactivée par défaut pour les serveurs MCP à hôte local basés sur HTTP. | L'outil de l'agent local n'est pas intrinsèquement sûr lorsqu'il est exposé à des hypothèses de réseau local faibles. | (NVD) |
| CVE-2025-67511 | Cadre de cybersécurité pour l'IA | L'aide SSH a exposé des champs injectables à l'exécution de l'agent d'IA | L'outil d'agent spécifique à la sécurité peut devenir un puits d'injection de privilèges si les wrappers sont négligents. | (NVD) |
Ces CVE permettent également d'expliquer une conclusion subtile mais importante. Si vous choisissez une famille de modèles pour le pentesting de l'IA, vous ne devez pas seulement vous demander "lequel raisonne mieux". Vous devriez plutôt vous demander "lequel permet à mon équipe de mieux séparer le raisonnement et l'exécution". Dans de nombreux environnements, cette question orientera vers Gemma 4 en tant que noyau de raisonnement local plus propre. Dans d'autres environnements, l'équipe peut encore choisir Qwen parce que les gains de productivité de son écosystème d'agents officiels valent le coût de gouvernance supplémentaire. La bonne réponse est contextuelle, mais l'aspect coût du compromis n'est plus théorique. Les enregistrements CVE ont déjà commencé à l'écrire pour nous. (NVD)
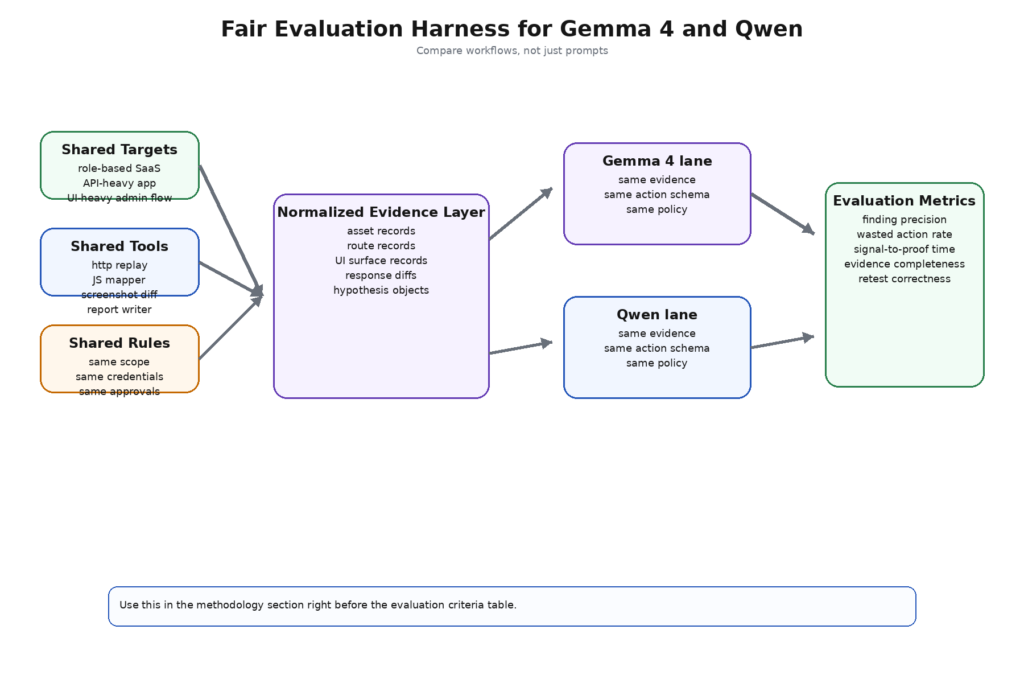
Un système de test d'IA équitable est plus important qu'une capture d'écran de référence.
Pour comparer Gemma 4 et Qwen dans la pratique, il ne suffit pas de leur demander à tous deux une charge utile intelligente et de déclarer un vainqueur. Une évaluation sérieuse a besoin d'une charge de travail qui ressemble à un travail offensif plutôt qu'à une démonstration rapide. Les catégories de référence qui comptent ne sont pas la "conversation générale", le "codage" ou le "raisonnement" dans l'abstrait. Il s'agit des sous-problèmes récurrents à l'intérieur d'un flux de travail de pentest.
La première catégorie est recon synthèse. Le modèle peut-il prendre les résultats de l'analyse passive, l'extraction des itinéraires, les métadonnées de l'en-tête, les captures d'écran, les notes et les tentatives antérieures, puis identifier le petit nombre de chemins les plus susceptibles d'avoir de l'importance ? C'est ici que le contexte long et la normalisation des preuves sont plus importants que l'éloquence brute du modèle. Un bon résultat n'est pas une longue liste d'idées. C'est une liste plus courte et plus défendable. La conception modulaire de PentestGPT a été construite précisément parce que l'état libre de bout en bout est difficile à préserver pour les LLM. Cela reste le modèle mental correct pour comparer ces systèmes. (USENIX)
La deuxième catégorie est raisonnement par flux authentifié. Le modèle peut-il comparer le comportement des rôles entre les navigateurs et les API et déduire les différences qui s'apparentent à une conception de produit ou à une défaillance d'autorisation ? Cela est important car de nombreuses découvertes précieuses dans des applications réelles ne sont pas des bogues de syntaxe. Il s'agit de bogues liés aux limites de la confiance. Ce type de raisonnement ne se limite pas à la génération de code. Il nécessite la conservation de l'état et l'interprétation de l'objet commercial.
La troisième catégorie est sélection des outils et proposition d'action. Une fois que le modèle a formulé une hypothèse, demande-t-il la bonne action suivante ? Un bon modèle doit proposer une étape de validation précise, étayée par des preuves. Un modèle faible dira quelque chose de générique comme "essayez l'injection SQL", "testez IDOR" ou "inspectez davantage l'API". L'objectif n'est pas de maximiser la créativité. Il s'agit d'obtenir un signal fort pour la prochaine étape de l'enquête.
La quatrième catégorie est rétention du contexte long. Le modèle peut-il se souvenir de ce qui a déjà été essayé, de ce qui a échoué, de l'état d'authentification qui importait et des preuves qui soutenaient réellement l'hypothèse actuelle ? C'est là que l'avertissement de PentestGPT concernant la perte de contexte est toujours d'actualité, et que le contexte long ne devient précieux que si le système de preuves environnant est discipliné. (USENIX)
La cinquième catégorie est traitement multimodal des preuves. Si des captures d'écran, des PDF ou des produits à forte interface utilisateur font partie du flux de travail, le modèle peut-il classer les surfaces privilégiées et les différences de rôle sans s'effondrer dans une description vague ? Ici, le soutien multimodal de Gemma 4 au sein de la famille est un avantage structurel. Qwen peut combler l'écart si la comparaison s'étend à Qwen3-VL, mais cela modifie la forme du système et la portée du modèle, de sorte que le harnais de test doit le dire explicitement. (Google AI pour les développeurs)
La sixième catégorie est la qualité des rapports et des nouveaux tests. Le modèle peut-il préserver la différence entre l'observation, l'hypothèse, l'action et la conclusion ? Une conclusion polie mais trop sûre d'elle est pire qu'une conclusion brutale mais reproductible. Les systèmes de pentest gagnent en valeur lorsqu'ils facilitent la réutilisation des preuves dans les nouveaux tests, et non lorsqu'ils rendent la prose plus facile à admirer.
Une exploitation raisonnable évalue donc non seulement les résultats du modèle, mais aussi la qualité du flux de travail :
| Métrique | Ce qu'il mesure | Pourquoi cela importe plus que les critères génériques du LLM |
|---|---|---|
| Trouver la précision | Combien de fois un chemin proposé devient-il un problème vérifié ? | Le pentesting est une question de preuve, pas d'imagination |
| Taux d'actions perdues | Combien d'actions suggérées par le modèle sont rejetées, redondantes ou bloquées ? | Un bon modèle doit réduire la résistance de l'opérateur, et non l'augmenter. |
| Durée du signal à l'épreuve | Temps écoulé entre le premier indice faible et l'hypothèse vérifiée ou rejetée | L'objectif est d'obtenir des boucles d'investigation plus rapides et plus propres |
| Complétude des preuves | Si un autre ingénieur peut reproduire le résultat à partir des artefacts stockés | Le travail de sécurité doit survivre au transfert et au nouveau test |
| Charge d'approbation | Combien d'examens humains sont nécessaires pour chaque action utile ? | Les garde-corps doivent être fonctionnels et non cérémoniels |
| Efficacité contextuelle | Le modèle utilise-t-il bien le contexte actif sans se noyer dans le bruit ? | Un contexte long n'est utile que si l'invite reste significative |
| Retester l'exactitude | Le modèle permet-il de distinguer une question fixe d'une question déplacée ou partielle ? | Le retest est l'une des utilisations les plus utiles de l'assistance de l'IA. |
Un outil d'évaluation utile nécessite également une couche de configuration stricte. Même classe cible, mêmes enveloppes d'outils, même schéma de preuves, mêmes règles d'approbation, même politique d'opérateur, mêmes limites de taux, mêmes limites d'accréditation. Si Gemma 4 obtient des captures d'écran et pas Qwen, le résultat n'a pas de sens. Si Qwen obtient Qwen-Agent et que Gemma n'obtient que des invites de chat brutes, le résultat n'a pas de sens. Si un modèle est autorisé à émettre des chaînes d'exécution directe et que l'autre doit émettre des actions typées, le résultat est pire qu'insignifiant parce qu'il enseigne la mauvaise leçon. (Projet de sécurité Gen AI de l'OWASP)
Une configuration minimale du harnais peut ressembler à ceci :
projet : ai-pentest-model-comparison
cibles :
- class : role-based-saas-webapp
- classe : api-heavy-b2b-portal
tools :
- passif_recon_runner
- js_endpoint_mapper
- http_replay_runner
- lecteur_diff_capture_d'écran
- rédacteur de rapports
evidence_schema :
- enregistrement_actif
- route_record
- ui_surface_record
- enregistrement_réponse_diff
- enregistrement_hypothèse
approval_rules :
passif : auto
credentialed_read_only_replay : human_review
modification d'état : bloqué
métriques :
- précision_de_la_recherche
- taux_d'action_gâchée
- temps_du_signal_à_l'épreuve
- complétude_des_preuves
- exactitude du retest
Ce type d'instrument n'est pas aussi amusant qu'un tableau de référence, mais il répond à la bonne question. Il vous indique si la famille de modèles correspond au flux de travail offensif que vous exécutez réellement. Pour les équipes de sécurité, il s'agit là d'un résultat bien plus important que de savoir quel fournisseur a obtenu le meilleur score sur un critère de raisonnement choisi par le fournisseur. (USENIX)
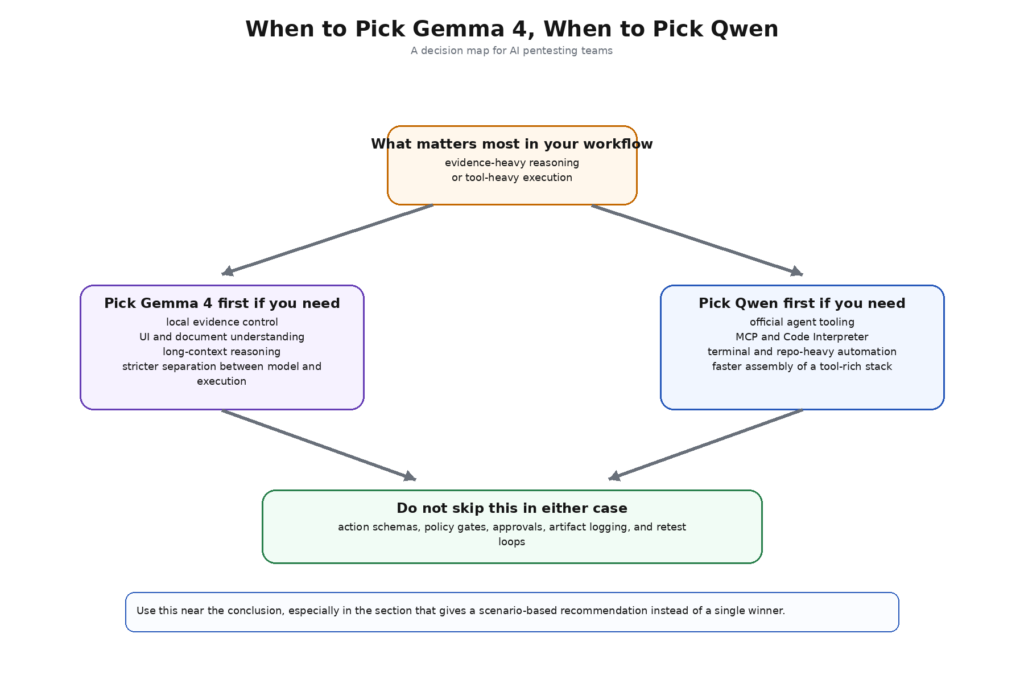
Gemma 4 contre Qwen, c'est vraiment le raisonnement local contre la surface d'un agent plus large.
Une fois la comparaison fondée sur le flux de travail, le compromis devient plus clair. Gemma 4 est plus facile à recommander lorsque l'équipe souhaite qu'une famille locale raisonne sur du texte, des captures d'écran, des PDF et des demandes d'outils structurés dans le cadre d'un flux de travail protégé. La documentation de Google permet de décrire facilement le modèle de cette manière : contexte 256K sur les modèles plus grands, réflexion intégrée, appel de fonction natif, prise en charge explicite de la fonction système et la compréhension de l'image qui comprend l'interface utilisateur et l'analyse du document. Si le principal goulot d'étranglement de l'équipe est l'effort humain nécessaire pour lire les preuves et décider ce qui mérite d'être validé, Gemma 4 s'impose naturellement. (Google AI pour les développeurs)
Qwen est plus facile à recommander lorsque le plus grand goulot d'étranglement de l'équipe n'est pas l'interprétation des preuves mais la plomberie de l'agent. Si la pile souhaitée comprend le MCP, l'exécution du code, les assistants orientés navigateur, les agents terminaux, les services locaux compatibles avec OpenAI et la possibilité de passer d'un tour de pensée à un tour de non-pensée au sein d'une même famille et d'un même cadre, Qwen vous offre plus de pièces officielles avec lesquelles travailler. Cela fait de Qwen un choix convaincant pour les équipes qui ont déjà une forte gouvernance d'exécution et qui veulent aller plus vite dans l'orchestration. Cela fait également de Qwen le choix par défaut le plus dangereux pour les équipes qui n'ont pas encore cette gouvernance. (Qwen)
Il existe également un troisième scénario, moins évident. Certaines équipes ne veulent pas vraiment construire le plan de contrôle elles-mêmes. Elles veulent un pentesting par l'IA, mais sous la forme d'un flux de travail avec la capture de preuves, des tests authentifiés, la génération de rapports, des retests et des limites révisables déjà en place. Le matériel Public Penligent décrit exactement ce type de flux de travail offensif gouverné plutôt qu'un assistant de chat générique. Que l'équipe achète ou construise, l'exigence est la même : le modèle ne doit être qu'une couche du système. Si cette idée semble décevante et peu glorieuse, c'est probablement le signe que la conception est en train de mûrir. (Penligent)
La plus grande erreur pratique consiste à imposer une seule réponse pour les trois scénarios. Un flux de travail local à forte intensité de preuves, un flux de travail agentique à forte intensité de terminaux et un flux de travail multimodal à forte intensité d'interface graphique ne sont pas la même chose. Gemma 4 a tendance à gagner le premier scénario de manière plus nette. Qwen a tendance à gagner le deuxième plus proprement. Le troisième dépend de la possibilité pour Qwen de s'étendre à Qwen3-VL. Une fois que vous avez dit cela à haute voix, la plupart des fausses certitudes concernant le "meilleur modèle pour le pentesting de l'IA" disparaissent. (Google AI pour les développeurs)
Erreurs courantes lorsque les équipes comparent Gemma 4 et Qwen pour le travail de sécurité
La première erreur consiste à comparer un modèle à un écosystème. Gemma 4 31B est un choix de famille de modèles. "Qwen" devient souvent un raccourci pour Qwen3, Qwen-Agent, Qwen Code, et parfois Qwen3-VL en même temps. Qwen semble donc plus ou moins fort selon ce qui est discrètement intégré dans la comparaison. Un article juste doit préciser à chaque fois quelle couche est testée. (Google AI pour les développeurs)
La deuxième erreur consiste à considérer les captures d'écran comme une fonctionnalité secondaire. Dans de nombreux processus de pentest, les captures d'écran ne sont pas des preuves cosmétiques. Elles constituent le chemin le plus court pour trouver des différences de privilèges, des chemins d'exportation dangereux, des actions cachées et des flux de travail administratifs. Une comparaison qui ignore les preuves multimodales ne fait souvent que comparer deux modèles de prise de notes. (Google AI pour les développeurs)
La troisième erreur consiste à récompenser l'utilisation agressive des outils au lieu de l'utilisation sûre des outils. Un modèle qui demande plus d'actions n'est pas nécessairement un meilleur modèle de pentest. Il peut simplement s'agir d'un modèle moins bien géré. La question pertinente est de savoir si ces actions sont délimitées, justifiées et reproductibles.
La quatrième erreur consiste à confondre déploiement local et faible risque. Les récents CVE de MCP et d'outils d'agent suffisent à prouver le contraire. Un service local accessible, sous-authentifié ou mal enveloppé constitue toujours une surface d'attaque, qu'il fonctionne sur localhost ou non. (NVD)
La cinquième erreur consiste à laisser le modèle rédiger le rapport comme si la confiance était une preuve. La meilleure rédaction en matière de sécurité reste la rédaction de preuves. L'IA est utile lorsqu'elle préserve la chaîne qui va de l'observation à l'action et à la conclusion. Elle nuit lorsqu'elle comprime cette chaîne dans un texte persuasif qui dissimule l'incertitude.
La réponse finale n'est pas un vainqueur unique
Si la question est de savoir quelle famille est la plus facile à utiliser en tant que noyau de raisonnement local protégé pour le pentesting de l'IA, la meilleure réponse est Gemma 4, en particulier Gemma 4 31B. L'ensemble des fonctionnalités officielles s'aligne exceptionnellement bien sur ce dont les flux de travail offensifs à forte intensité de preuves ont réellement besoin : contexte long, appel de fonction natif, système-La prise en charge des rôles, la compréhension de l'interface utilisateur et des PDF, et l'avertissement explicite du fournisseur que l'exécution doit rester en dehors du modèle et à l'intérieur de la logique d'application validée. C'est une forme saine pour le travail de sécurité. (Google AI pour les développeurs)
Si la question est de savoir quelle famille est la plus facile à utiliser en tant que une pile d'agents ouverte plus large avec des outils officiels pour l'appel de fonctions, le MCP, l'exécution de code, les flux de travail du terminal et l'assistance au navigateur, la meilleure réponse est la suivante Qwen. La combinaison de Qwen3, Qwen-Agent et Qwen Code offre aux constructeurs plus de composants officiels pour l'exécution agentive que ne le fait actuellement Gemma. Il s'agit là d'une véritable force, et non d'une force cosmétique. Cela signifie également que l'équipe doit traiter l'utilisation abusive des outils, la conception des limites d'exécution et le durcissement des services locaux comme des éléments de travail de première classe plutôt que comme un polissage ultérieur. (Qwen)
Si la question est de savoir quel camp est le meilleur pour le pentesting multimodal avec des captures d'écran et des preuves documentaires abondantesla réponse est plus conditionnelle. Gemma 4 simplifie l'histoire si vous voulez une famille qui inclut déjà ces capacités dans la même ligne de modèles. Qwen peut absolument rivaliser si la comparaison s'étend à Qwen3-VL, mais il s'agit d'un choix de système différent de celui de Qwen3 simple plus l'outillage d'agent. La réponse honnête n'est pas "Gemma gagne" ou "Qwen gagne". La réponse honnête est "décidez d'abord si vous choisissez un modèle, un écosystème d'agents ou un atelier de sécurité multimodal". (Google AI pour les développeurs)
Tel est le véritable verdict. Gemma 4 est le choix le plus propre pour les équipes qui veulent un modèle local gouverné pour réfléchir, comparer, classer et expliquer. Qwen est le choix le plus propre pour les équipes qui veulent une surface d'agent officiel plus large et qui sont prêtes à assumer les bords de sécurité plus tranchants qui en découlent. Dans le pentesting de l'IA, c'est souvent le type de gagnant le plus honnête que l'on puisse nommer. (Penligent)
Pour en savoir plus
Google AI pour les développeurs, Carte modèle Gemma 4 et Aperçu du modèle Gemma 4Le système de gestion de l'information de l'Union européenne (UE) a été mis au point pour la longueur du contexte, les capacités multimodales, la prise en charge du rôle du système et les besoins en mémoire. (Google AI pour les développeurs)
Google AI pour les développeurs, Appel de fonction avec Gemma 4 et Gemma 4 Formatage des questionspour l'avertissement d'exécution et la conception du rôle et du jeton de contrôle. (Google AI pour les développeurs)
Google AI for Developers et Google Open Source Blog, Gemma libère et Gemma 4 sous Apache 2.0pour connaître la date de sortie et le contexte de l'octroi des licences. (Google AI pour les développeurs)
Dépôts et documentation officiels de Qwen, Qwen3, Qwen-Agentet Code QwenLe système de gestion de l'information de l'Agence européenne pour la sécurité et la santé au travail (ESA) est un système de gestion de l'information de l'Agence européenne pour la sécurité et la santé au travail (ESA). (GitHub)
Matériaux officiels multimodaux Qwen, Qwen3-VLSi votre flux de travail de pentesting dépend fortement de la compréhension des captures d'écran, de l'interface graphique ou des documents, il est possible d'utiliser l'outil "AI pentesting". (GitHub)
USENIX Security 2024, PentestGPTLe site Web de la Commission européenne est une source d'informations utiles sur la recherche publique concernant l'utilité des masters en droit pour les tests d'intrusion et l'importance de la conception modulaire. (USENIX)
OWASP, Top 10 des applications de modèles linguistiques à grande échelle et Guide de l'équipe rouge de GenAILe système de gestion de l'information de l'Union européenne (UE) est un système de gestion de l'information de l'Union européenne (UE). (OWASP)
NIST et MITRE, AI 100-2 Apprentissage automatique adversarial et MITRE ATLASpour la modélisation des menaces de l'IA et le langage de sécurité au niveau du système. (Centre de ressources en sécurité informatique du NIST)
Fiches NVD pour CVE-2026-27966, CVE-2025-53355, CVE-2025-66414et CVE-2025-67511car les limites des agents et des outils ne sont déjà pas respectées dans la nature. (NVD)
Laboratoire de piratage de Penligent, Le pentester de l'IA en 2026, Sécurité de l'IA agentique en production, Les outils d'IA de Pentest en 2026, AI Pentest Tool, ce à quoi ressemble une véritable attaque automatisée en 2026et Meilleur modèle d'IA pour le pentestingpour des perspectives centrées sur le flux de travail et étroitement liées à ce sujet. (Penligent)

