Résumé
Au fur et à mesure que l'infrastructure des grands modèles de langage (LLM) évolue, la surface d'attaque passe des interfaces de gestion traditionnelles ("plan de contrôle") au flux réel des données d'inférence ("plan de données").
CVE-2025-62164 représente un changement de paradigme dans la vulnérabilité de la vLLMle moteur standard de l'industrie pour le service LLM à haut débit. Cette faille permet aux attaquants d'utiliser le moteur /v1/complétions en injectant des données malveillantes les encastrements rapides. En exploitant des mécanismes de désérialisation non sécurisés au sein de la logique de chargement de PyTorch, un attaquant peut déclencher une corruption de la mémoire, conduisant à un déni de service (DoS) et à une potentielle exécution de code à distance (RCE) - le tout sans avoir besoin de clés API valides (en fonction de la configuration du déploiement).
Cette analyse décompose la cause technique fondamentale, fournit une preuve de concept (PoC) et décrit les étapes de remédiation immédiates pour les ingénieurs de la plateforme d'IA.

Le vecteur d'attaque : Pourquoi les emboîtements sont dangereux
Dans les interactions LLM standard, les utilisateurs envoient du texte. Cependant, les moteurs d'inférence avancés tels que vLLM prennent en charge le intégration des données d'entrée (données tensorielles) directement via l'API. Cette méthode est conçue pour optimiser les performances et les flux de travail multimodaux, mais elle ouvre une porte dangereuse : Désérialisation d'objets directs.
La vulnérabilité réside dans la manière dont vLLM traite ces tenseurs entrants. Plus précisément, le moteur fait implicitement confiance à la structure des données sérialisées fournies par l'utilisateur, en supposant qu'il s'agit d'une représentation mathématique inoffensive.
Le chemin du code vulnérable
La faille critique se situe au niveau de la vllm/entrypoints/renderer.py à l'intérieur du Télécharger et valider l'extrait fonction.
Python
# Représentation simplifiée de la logique vulnérable
import torch
import io
import pybase64
def _load_and_validate_embed(embed : bytes) :
# DANGER : Désérialisation de flux binaires non fiables
tenseur = torch.load(
io.BytesIO(pybase64.b64decode(embed, validate=True)),
weights_only=True, # Le faux sentiment de sécurité
map_location=torch.device("cpu"),
)
retour tenseur
Tandis que weights_only=True est destiné à empêcher l'exécution d'un code Python arbitraire (une vulnérabilité courante de Pickle). insuffisant pour éviter la corruption de la mémoire lors de l'utilisation de types de tenseurs spécifiques à PyTorch.
Plongée technique : Exploiter les tenseurs épars
Le cœur de CVE-2025-62164 exploite une déconnexion entre les drapeaux de sécurité de PyTorch et sa gestion de Tenseurs épars.
- Le changement PyTorch 2.8+ : Les nouvelles versions de PyTorch ignorent par défaut les vérifications d'intégrité coûteuses pour les tenseurs peu denses afin d'améliorer les performances.
- Le contournement : Un pirate peut construire un tenseur "Sparse COO" (Coordinate Format) malformé. Même avec un
weights_only=True,torch.loaddésérialisera cette structure. - Corruption de la mémoire : Étant donné que les indices du tenseur clair ne sont pas validés par rapport à la taille déclarée lors du chargement, les opérations ultérieures (telles que la conversion du tenseur au format dense ou son déplacement vers la mémoire du GPU) donnent lieu à une erreur de type Écriture hors limites (OOB).
Cette écriture OOB provoque un plantage immédiat de l'interpréteur Python (DoS). Avec une pulvérisation sophistiquée du tas et une manipulation de la disposition de la mémoire, cette primitive peut être escaladée pour prendre le contrôle du pointeur d'instruction, réalisant ainsi un RCE.
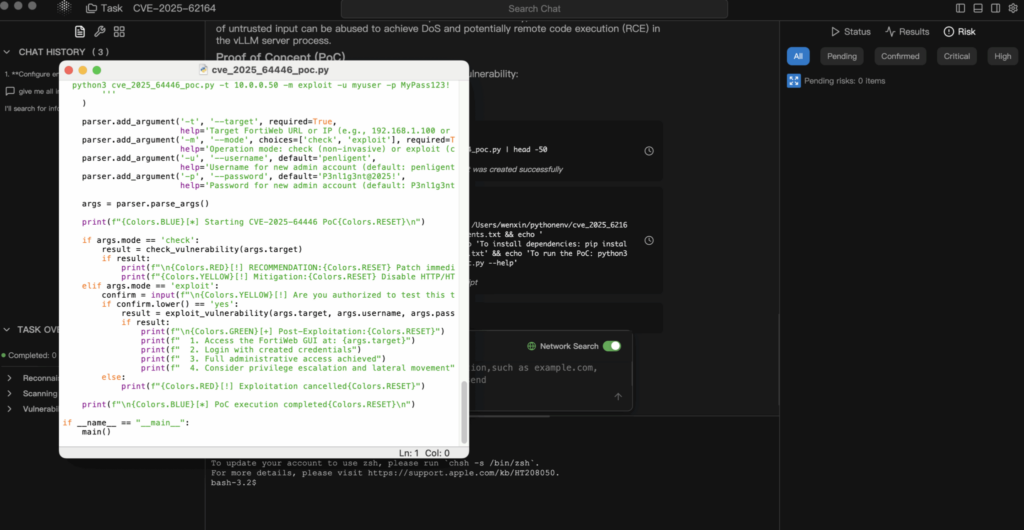
Analyse de la preuve de concept (PoC)
Avertissement : ce PoC est uniquement destiné à des fins éducatives et défensives.
1. Construction de la charge utile
L'attaquant crée un tenseur PyTorch sérialisé qui viole les contraintes de cohérence internes.
Python
import torch
import io
import base64
def generate_exploit_payload() :
buffer = io.BytesIO()
# Créer un Tenseur Sparse conçu pour déclencher une écriture OOB lors de l'accès
# Les indices spécifiques seraient fabriqués pour pointer en dehors de la mémoire allouée
# malformed_tensor = torch.sparse_coo_tensor(indices=..., values=..., size=...)
# Pour la démonstration, nous simulons la sérialisation
# Dans une attaque réelle, ce tampon contient le flux binaire pickle
torch.save(malformed_tensor, buffer)
# Encodage pour le transport JSON
return base64.b64encode(buffer.getvalue()).decode('utf-8')
2. La demande d'exploitation
L'attaquant envoie cette charge utile au point de terminaison standard.
POST http://target-vllm-instance:8000/v1/completions
JSON
{
"model" : "meta-llama/Llama-2-7b-hf",
"prompt" : {
"embedding" : ""
},
"max_tokens" : 10
}
3. Le résultat
- Meilleur cas : Le processus de travailleur vLLM rencontre une erreur de segmentation et s'arrête. Si l'orchestrateur (par exemple, Kubernetes) le redémarre, l'attaquant peut simplement renvoyer la demande, créant ainsi un déni de service persistant.
- Le pire des cas : La corruption de la mémoire écrase les pointeurs de fonction, ce qui permet à l'attaquant d'exécuter un shellcode dans le contexte du conteneur.
Analyse d'impact
- Disponibilité (élevée) : Il s'agit d'un DoS trivial à exécuter. Une seule requête peut mettre hors service un nœud d'inférence. Dans les environnements en grappe, un attaquant peut itérer à travers les nœuds pour dégrader l'ensemble de la grappe.
- Confidentialité et intégrité (critiques) : Si le RCE est réalisé, l'attaquant accède aux variables d'environnement (qui contiennent souvent des jetons Hugging Face, des clés S3 ou des clés WandB) et les poids du modèle propriétaire chargés dans la mémoire.
Remédiation et atténuation
1. Mise à niveau immédiate
La vulnérabilité est corrigée dans vLLM v0.11.1.
- Action : Mettez immédiatement à jour vos images Docker ou vos paquets PyPI vers la dernière version.
- Fixer la logique : Le correctif met en œuvre une logique de validation stricte qui rejette les formats de tenseurs non sûrs avant qu'ils n'interagissent avec l'allocateur de mémoire.
2. Assainissement des entrées (niveau WAF/passerelle)
Si vous ne pouvez pas procéder à une mise à niveau immédiate, vous devez bloquer le vecteur d'attaque au niveau de la passerelle.
- Action : Configurez votre passerelle API (Nginx, Kong, Traefik) pour inspecter les corps JSON entrants.
- Règle : Bloquer toute demande de
/v1/complétionsoù lesrapidecontient un objet avec unintégrationclé.
3. Segmentation du réseau
Veillez à ce que votre serveur d'inférence ne soit pas directement exposé à l'internet public. L'accès doit être médiatisé par un service dorsal qui assainit les entrées et gère l'authentification.
Conclusion
CVE-2025-62164 est un signal d'alarme pour la sécurité de l'IA. Nous ne pouvons plus traiter les "modèles" et les "embeddings" comme des données inertes. À l'ère de l'IA, les données sont des codesL'exécution d'un fichier de données, et sa désérialisation nécessitent le même niveau d'examen que l'exécution d'un exécutable binaire.
Pour les équipes qui effectuent des tests de pénétration sur l'infrastructure de l'IA (comme Penligent.ai), la vérification des points de terminaison de sérialisation exposés dans les moteurs d'inférence devrait désormais faire partie intégrante du champ d'application de l'engagement.
Note de l'auteur : Veillez à la sécurité de votre infrastructure d'IA. Validez toujours les entrées, ne faites jamais confiance aux données sérialisées et veillez à ce que vos versions de vLLM correspondent à la dernière version stable.