Anthropic introduced the Model Context Protocol as an open standard for connecting AI systems to external data sources and tools. The MCP specification is explicit about the trust and safety implications of that design. It says MCP enables arbitrary data access and code execution paths, requires explicit user consent, and warns implementors that tools must be treated with special caution. In April 2026, OX Security argued that one specific design choice around MCP STDIO handling turned those abstract warnings into a concrete ecosystem problem, estimating exposure across more than 150 million downstream package downloads, more than 7,000 publicly reachable servers, and as many as 200,000 total instances. Anthropic did not accept the root-cause framing and, according to OX, treated the behavior as a secure default for developers to use responsibly. That disagreement is the heart of the story. This is not only a patching problem. It is a control-plane problem. (Anthropique)
The easiest way to misunderstand this issue is to frame it as “another prompt injection article.” Prompt injection is present, but it is not the center of gravity. The real issue is whether untrusted input can cross too many boundaries without a hard stop: from a browser page into a tool configuration, from a UI field into a subprocess launch, from a model-edited JSON file into a local server registration, from a browser-generated cross-site request into an MCP tool call, or from a shared transport object into another client’s data. Once you see the problem that way, the OX disclosure stops looking like an isolated research headline and starts looking like a warning about how agent systems fail in production. (OX Security)
That is also why this conversation should not end with a single pentest or a single hotfix. MCP risk is not static. It changes when a team adds one more server, loosens one more scope, changes one more trust dialog, widens one more allowlist, or upgrades one more SDK. In systems where models can reach tools, data, shells, repos, browsers, and internal APIs, the security question is never just “is this vulnerable today?” The better question is “what can become reachable tomorrow after an otherwise normal product change?” That is the case for continuous red teaming. (Modèle Contexte Protocole)
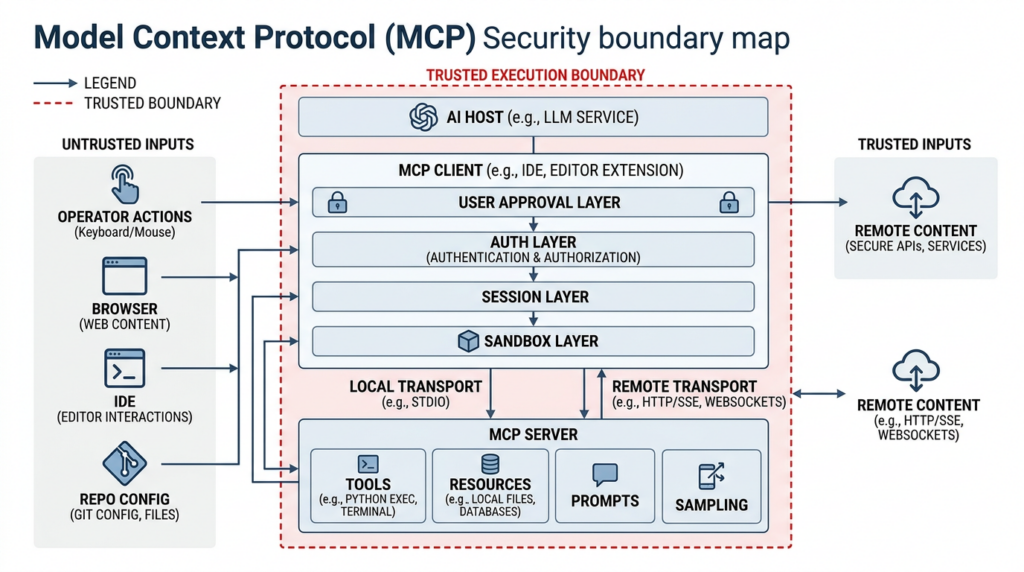
Anthropic MCP vulnerability and the execution boundary that actually failed
MCP is easy to describe in product language and much harder to model correctly in security language. At the highest level, hosts or clients connect to MCP servers. Those servers can expose resources, prompts, and tools. The server side may offer tools that ultimately perform file operations, database queries, browser actions, network access, Git interactions, or local command execution. The client side may support sampling and other advanced behaviors. None of that is inherently broken. In fact, it is why MCP became attractive in the first place. Anthropic described it as a universal, open standard for connecting AI systems to tools and data, meant to replace fragmented one-off integrations with a single protocol. (Anthropique)
The problem is that MCP’s trust model lives at multiple layers at once. There is the protocol layer, where clients and servers exchange structured messages. There is the transport layer, where HTTP and STDIO behave very differently. There is the host layer, where the application decides what to render, what to approve, and what to execute. There is the tool layer, where apparently simple “helpers” may actually expose arbitrary shell commands or privileged filesystem access. And there is the human layer, where consent prompts, trust dialogs, and approval UIs can be clear, ambiguous, too broad, or simply too late. If you focus on only one layer, the system can still fail through another. (Modèle Contexte Protocole)
The distinction between HTTP and STDIO matters more than many teams realize. MCP’s authorization specification is written for HTTP-based transports. It explicitly says that implementations using HTTP should conform to that authorization flow, while implementations using STDIO should not and should instead retrieve credentials from the environment. That is an understandable design choice for local-process communication. It is also a warning sign. The moment a local STDIO pattern is abstracted into a remote UI, a shared service, a browser-managed application, or a multi-user platform, a transport that was supposed to be private may inherit exposure it was never designed to carry. (Modèle Contexte Protocole)
The MCP specification itself does not hide the danger. Under Security and Trust and Safety, it says users must explicitly consent to data access and operations, hosts must obtain explicit consent before invoking tools, and tools represent arbitrary code execution that must be treated with appropriate caution. That language is unusually direct for a protocol spec, and it should be read less as marketing reassurance and more as an architectural warning label. If your application allows untrusted content to influence tool configuration, tool selection, or transport behavior, you are already operating near the sharp edge of the protocol. (Modèle Contexte Protocole)
OX Security’s deep dive makes exactly that argument from the opposite direction. It does not start from policy. It starts from implementation. Their claim is that Anthropic’s modelcontextprotocol SDKs expose a direct configuration-to-command execution path via STDIO, across multiple language implementations. In OX’s description, code intended to launch a local STDIO server can also execute arbitrary operating system commands, because the command runs even when it does not produce a valid server handle. Whether one accepts OX’s framing in full or not, that detail is what turned this from a theoretical trust-model concern into a practical supply-chain argument. (OX Security)
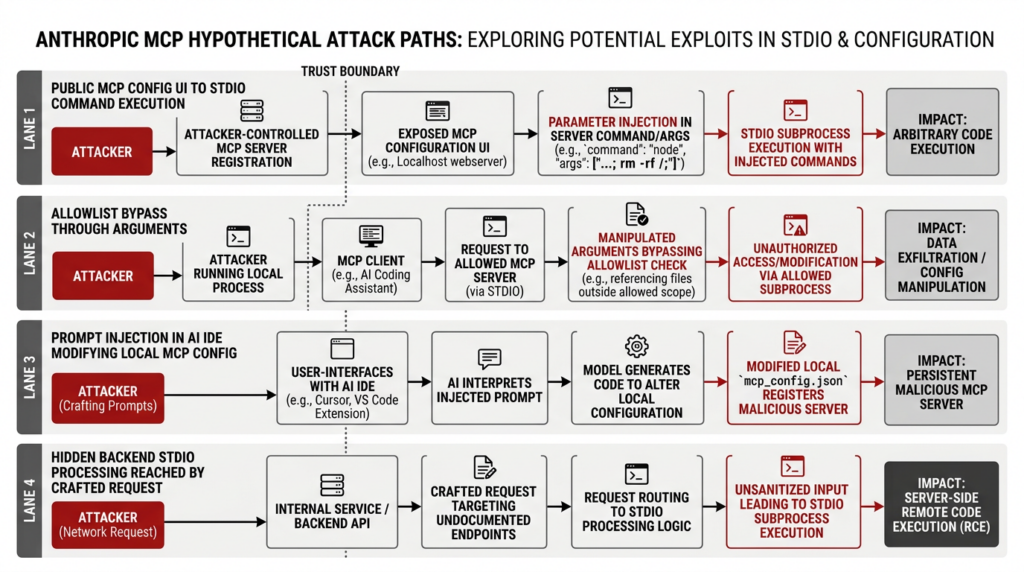
Anthropic MCP vulnerability and the four exploit families OX described
OX did something useful in its advisory that many vulnerability writeups do not. Instead of presenting a single exploit chain and implying universality, it organized the problem into four vulnerability families. That structure matters because it shows how the same underlying trust failure can appear through very different product surfaces. (OX Security)
The first family is the most intuitive. A public or semi-public application exposes an MCP configuration UI, often for adding a new MCP server. If the application accepts a JSON configuration that includes an arbitrary command et args field and passes those values into STDIO server parameters without a strict allowlist or a fixed template system, then the UI has effectively become a remote command launcher. In OX’s advisory, GPT Researcher, LiteLLM, Fay, Bisheng, Jaaz, and Langchain-Chatchat are examples of products where this general pattern translated into critical or high-severity findings, including remote command execution. (OX Security)
The second family is more subtle and more important for defenders, because it targets the kind of mitigation teams often deploy first. Several products attempted to reduce risk by restricting the command field to a small set of allowed executables such as python, npmou npx. On paper, that looks like meaningful hardening. In practice, OX says they were able to bypass those controls by shifting the dangerous behavior into argument space, for example by invoking an allowed executable with arguments that themselves permit arbitrary command execution. Flowise and Upsonic are OX’s main examples here. The lesson is that a string allowlist is not the same thing as a trusted execution model. If the allowed executable is itself a generic launcher or script runner, you may only have moved the problem one field to the right. (OX Security)
The third family moves from server-side platforms into developer workstations and AI coding tools. OX says IDEs and assistants such as Windsurf, Cursor, Claude Code, Gemini CLI, and GitHub Copilot can become vulnerable when attacker-controlled content leads the application to modify local MCP configuration. In OX’s account, Windsurf was the clearest zero-user-interaction case and received CVE-2026-30615. Their description says malicious HTML content could lead to unauthorized modification of local MCP configuration, automatic registration of a malicious STDIO server, and arbitrary command execution on the victim system. Even where other IDEs required some user interaction, OX’s broader point stands: if the UI presents a file modification or tool registration request without making the execution consequence legible, the fact that a user clicked a button is not much comfort. (OX Security)
The fourth family is the kind that tends to survive shallow remediation. In these cases, a web-facing GUI may not show an obviously dangerous STDIO path at all, but the backend still contains logic that processes STDIO configuration. According to OX, a crafted network request can reach that hidden path and trigger command execution. DocsGPT appears in this section of the advisory. From a program perspective, these are often the most painful bugs because product teams believe they have removed the dangerous feature from the UI, but the privileged code path still exists in the service. (OX Security)
What ties all four families together is not the literal field name or the literal product. It is the fact that multiple sources of untrusted influence can reach the same execution boundary. Sometimes the source is a browser form. Sometimes it is HTML interpreted by an IDE. Sometimes it is a backend request. Sometimes it is a model-directed config file edit. But the dangerous transition is the same: a system that was designed to wire tools into an agent ends up wiring attacker-controlled input into a process launch path. (OX Security)
Anthropic MCP vulnerability and the disagreement over responsibility
It is possible to read the MCP specification and conclude that the protocol designers saw the danger coming. The spec emphasizes explicit user consent and explicit approval for tool invocation. The security best-practices documentation expands that concern into concrete categories such as confused deputy attacks, token passthrough, SSRF, session hijacking, and scope inflation. Read on its own, that guidance sounds responsible. It tells implementors that the protocol does not magically make powerful systems safe. (Modèle Contexte Protocole)
It is also possible to read OX’s criticism and conclude that the guidance is not enough. OX says Anthropic confirmed that the relevant STDIO behavior is by design and declined to modify the protocol, arguing that the execution model is a secure default and sanitization is the developer’s responsibility. OX’s criticism is that this answer is unsatisfactory at ecosystem scale, because large numbers of downstream developers will not design perfect isolation around a dangerous primitive, especially when building fast-moving AI products under feature pressure. Both positions are intellectually coherent. They simply optimize for different failure assumptions. One assumes developers will treat the primitive with enough caution. The other assumes many will not, and therefore the primitive itself should offer less rope. (OX Security)
The reason this matters for defenders is not philosophical. It changes the remediation model. If you think the root issue is misuse, then your response is documentation, safer defaults, better prompts, stronger UIs, and more careful app design. If you think the root issue is design, then you look for more fundamental changes: fixed server templates instead of raw command input, stronger separation between configuration and execution, impossible-to-ignore approval checkpoints, and runtime isolation that assumes eventually some unsafe input will still arrive. Most real teams will need both. The disagreement mainly tells you not to wait for a single authoritative upstream fix that may never arrive in the form you want. (Modèle Contexte Protocole)
Anthropic’s own public materials are useful here for a different reason. In its Transparency Hub, Anthropic says Claude Sonnet 4.5 prevented 94 percent of MCP-related prompt injection attacks in one evaluation setup, with mitigations enabled. That is a meaningful result. It suggests model-side defenses and detection systems can materially reduce abuse. But it is not a guarantee, and Anthropic’s own discussion of realism and evaluation awareness makes an adjacent point that security teams should take seriously: realistic testing conditions matter. A model that blocks many attacks in controlled scenarios can still sit inside an application whose trust boundaries are too permissive. That is why “better model defenses” and “better system engineering” are complements, not substitutes. (Anthropique)
Anthropic MCP vulnerability is only part of a wider MCP security picture
One mistake security teams make after a headline disclosure is to treat every related issue as proof of the same root cause. Another mistake is the opposite: to isolate each CVE so aggressively that they miss the system-level pattern. The right approach is to distinguish related classes while still noticing where they rhyme. With MCP, they rhyme a lot. (OX Security)
The OX advisory is centered on command injection and unintended execution paths around STDIO configuration. But the MCP ecosystem has already seen other serious problems that do not rely on the same exact entry point. The TypeScript SDK had a high-severity cross-client data leak issue when a single transport or server instance was reused across multiple requests or transports, allowing JSON-RPC message collisions and response routing errors between clients. That is not a “command injection” bug, but it is still an execution-boundary and trust-boundary bug. It shows what happens when agent infrastructure is treated as stateless glue while retaining hidden per-session assumptions. (GitHub)
The Go SDK had a different but equally revealing problem. GitHub’s advisory for CVE-2026-33252 says its Streamable HTTP transport accepted browser-generated cross-site POST requests without validating the Origine header and without requiring Content-Type : application/json. In deployments without authorization, that meant an arbitrary website could send MCP requests to a local server and potentially trigger tool execution. That issue is especially important because it crosses from “agent security” into classic browser-origin security. It reminds defenders that MCP servers are not somehow outside normal web threat models. If they are reachable over HTTP and trust the browser too easily, you can get tool execution through web primitives teams have known how to defend for years. (GitHub)
The Java SDK’s DNS rebinding issue, tracked as CVE-2026-35568, tells a similar story from another angle. According to the analyzed CVE record, an attacker could access a locally or network-private Java SDK MCP server through the victim’s browser and make tool calls as if they were a locally running MCP-connected AI agent. Again, that is not the same exploit family as OX’s STDIO findings. But it is very much the same category of operational blind spot: a component assumed to be effectively local ends up reachable through a path the system did not model correctly. (GitHub)
The official reference ecosystem around MCP servers also matters because defenders often treat reference implementations as “safe enough” starting points. GitHub advisories and NVD records show that the official mcp-server-git component had multiple moderate-severity vulnerabilities in late 2025 and early 2026. CVE-2025-68143 described unrestricted git_init behavior that could create repositories at arbitrary filesystem locations. CVE-2025-68144 described argument injection in git_diff et git_checkout, allowing file overwrites. CVE-2025-68145 described missing path validation when the server was configured with a repository restriction. None of these alone proves that MCP as a protocol is doomed. They do prove that “official,” “reference,” and “widely used” are not the same thing as “safe to deploy without hardening.” (GitHub)
Claude Code provides another useful case study because it sits right at the developer trust boundary. GitHub’s advisory for CVE-2025-59536 says Claude Code could execute commands contained in a project before the user accepted the startup trust dialog. A later advisory, CVE-2026-21852, says a malicious repository could exfiltrate data, including Anthropic API keys, before the user confirmed trust by controlling ANTHROPIC_BASE_URL. Check Point’s February 2026 research adds more context by showing how repository-controlled configuration and MCP project settings could become execution and exfiltration paths. The point is not to single out Claude Code. It is to show how quickly agentic workflows become dangerous when configuration files, trust prompts, and execution startup order do not align cleanly. (GitHub)
Anthropic MCP vulnerability and the CVEs that matter most
The best way to keep the discussion grounded is to look at the concrete vulnerability records and ask what they say about the system, not just about the individual product.
| CVE or advisory | Composant | Why it matters for the Anthropic MCP vulnerability discussion | Fix or mitigation direction |
|---|---|---|---|
| CVE-2025-65720 | GPT Researcher | OX describes this as command execution reachable through MCP configuration in the UI, showing how a product-level feature can inherit dangerous execution semantics from the MCP path. (OX Security) | Remove or constrain raw STDIO configuration, add strict validation, and isolate execution. (OX Security) |
| CVE-2026-30623 | LiteLLM | OX says LiteLLM allowed authenticated users to add MCP servers through arbitrary JSON and execute operating system commands on the host. That makes the issue relevant even when there is some notion of login or tenancy. (OX Security) | Eliminate arbitrary command fields and use pre-approved server definitions. (OX Security) |
| CVE-2026-40933 | Flowise | Flowise tried to reduce risk with an allowlist, but OX says it could be bypassed through argument-level abuse. This is a strong reminder that superficial command allowlists do not equal safe tool mediation. (OX Security) | Harden argument validation, reduce executor flexibility, and move risky tools behind stronger policy. (OX Security) |
| CVE-2026-30615 | Windsurf | OX says malicious HTML could modify local MCP config and auto-register a malicious STDIO server without further interaction. This is the clearest prompt-to-config-to-execution story in the advisory. (OX Security) | Strengthen config-edit approval, require explicit user review of actual changes, and prevent silent server registration. (OX Security) |
| CVE-2026-26015 | DocsGPT | OX places DocsGPT in the family where hidden backend STDIO logic can still be triggered by crafted requests. That matters because many teams “remove the button” but leave the backend path. (OX Security) | Delete dead dangerous code paths, not just their UI affordances. (OX Security) |
That table is useful for one reason above all: each row is a different application, but the design lesson is the same. If arbitrary or weakly constrained configuration can reach an execution primitive, the exact shape of the surrounding product matters less than teams hope. The route to exploitation may differ, but the control failure is familiar. (OX Security)
A second table helps show that the broader MCP and agent ecosystem has additional fault lines defenders should watch, even when they are not the same as OX’s STDIO thesis.
| CVE or advisory | Composant | Why it matters beyond the OX disclosure | Patch or version guidance |
|---|---|---|---|
| CVE-2026-25536 | @modelcontextprotocol/sdk TypeScript SDK | Cross-client data leakage through transport or server reuse shows that MCP deployments can fail through session and concurrency assumptions, not just command execution. (GitHub) | Upgrade to 1.26.0 and avoid unsafe object reuse patterns. (GitHub) |
| CVE-2026-33252 | modelcontextprotocol/go-sdk | Cross-site tool execution through missing Origin validation shows that browser threat models apply directly to HTTP-exposed MCP servers. (GitHub) | Upgrade to 1.4.1 and enforce Origin plus Content-Type checks. (GitHub) |
| CVE-2026-35568 | Java SDK | DNS rebinding risk shows that “local” or private MCP services can still become reachable through browser-mediated paths. (GitHub) | Upgrade to 1.0.0 and harden network assumptions. (GitHub) |
| CVE-2025-68143, 68144, 68145 | mcp-server-git | Official or reference server implementations can still expose filesystem and repository boundary failures. Reference status does not remove the need for hardening. (GitHub) | Upgrade to patched releases and review repo-path isolation and argument handling. (GitHub) |
| CVE-2025-59536 and CVE-2026-21852 | Claude Code | Trust dialogs and project-controlled configuration are not cosmetic. If startup order is wrong, attacker-controlled repos can execute or exfiltrate before the user meaningfully approves anything. (GitHub) | Update to patched Claude Code versions and treat repository-scoped config as code with execution consequences. (GitHub) |
Together, these records make a larger point. The risk is not just “MCP command injection.” The risk is that teams are building execution-capable AI systems faster than they are building durable security boundaries around configuration, sessions, transports, trust dialogs, and tool authority. That is exactly the kind of environment where continuous red teaming pays off. (Modèle Contexte Protocole)
Anthropic MCP vulnerability and why one-time pentests are not enough
A traditional pentest is a snapshot. It answers a useful question: what could an attacker do against this system, in this state, at this moment? That is still valuable. The problem is that MCP-heavy systems do not stay in one state for very long. They evolve every time a team adds a connector, changes an approval flow, expands a scope, modifies a tool schema, swaps a runtime image, or upgrades an SDK. In ordinary web applications, many of those changes are low drama. In agent systems, they can reopen an execution boundary. (Modèle Contexte Protocole)
This is where the recent public evidence is especially instructive. Anthropic’s own evaluation summary says Claude prevented 94 percent of MCP-related prompt injection attacks in one tested setting with mitigations enabled, and it also says realistic safety evaluation remains a live challenge. OX’s disclosure, by contrast, is about how real deployments and downstream integrations behave when dangerous execution patterns are exposed through actual product surfaces. Those are not contradictory observations. They are evidence that model-level resilience and system-level resilience must be tested separately and continuously. A model can reject many malicious instructions while the application around it still gives untrusted input too much influence over execution. (Anthropique)
The same lesson shows up in the Claude Code advisories. A trust dialog can exist and still fail as a control if command execution or API traffic happens before meaningful confirmation. A server can advertise repository restrictions and still fail as a control if path validation is incomplete. A server can expose HTTP endpoints and still fail as a control if Origin checks are absent. In other words, modern AI security failures often emerge in the gap between the intended control and the actual execution order. One-off pentests find some of these. Continuous red teaming is what catches them again after the next refactor, the next dependency update, or the next feature launch. (GitHub)
That is why the continuous-red-team lens is not optional busywork here. It is the only testing model that matches the rate at which these systems change. If your environment includes MCP servers, model-controlled tool use, repository-scoped configuration, or AI IDEs that can modify local files, your threat surface now has software supply-chain properties and operator-console properties at the same time. The boundary is too dynamic to validate only every six months. (OX Security)
Continuous red teaming for Anthropic MCP environments
Continuous red teaming is often misunderstood as “running more scanners more often.” That is not what matters here. A useful continuous program for MCP environments is hypothesis-driven and boundary-driven. It starts by asking which trust transitions would cause meaningful damage if they reopened, then turns those transitions into replayable tests. (Modèle Contexte Protocole)
The first class of tests should focus on configuration reachability. Can anonymous users, low-privilege users, uploaded content, prompt-controlled file edits, or cross-site requests influence MCP server definitions, tool registrations, transport options, environment variables, or startup commands? This is where many teams stop too early after confirming that direct access is blocked. They need to test indirect influence as well. Does HTML rendered in an assistant end up editing config? Does a Git pull update a trusted settings file? Does a “safe” UI template still allow argument injection? Does a hidden backend parser still accept a legacy format? Those are the tests that keep finding real flaws in the current ecosystem. (OX Security)
The second class should focus on transport and session boundaries. For HTTP-based MCP servers, can a browser send cross-site POST requests that reach the message handler? Are Origine et Content-Type enforced? Is authorization required and correctly scoped? Are sessions bound to actual user identity instead of treated as authentication on their own? The MCP security best-practices documentation is explicit that session hijacking and event injection are real risks, that inbound requests must be verified, and that sessions must not be used as authentication. Continuous testing should prove those controls work in the real deployment, not just in the design doc. (Modèle Contexte Protocole)
The third class should focus on tool authority. The question is not only whether a tool is reachable. It is whether the tool is too broad. The MCP security guidance warns against token passthrough and scope inflation because broad tokens enlarge blast radius and weaken accountability. In practical terms, continuous red teaming here means regularly verifying that a stolen or misplaced token cannot jump across boundaries, that one tool’s authorization is not silently valid for another, and that disabling one risky capability actually removes it instead of only hiding it from the UI. (Modèle Contexte Protocole)
The fourth class should focus on runtime isolation. If unsafe input reaches a subprocess or high-risk tool, how much damage can it still do? Can it read host secrets from environment variables? Can it access the network freely? Can it reach cloud metadata endpoints? Can it write outside a working directory? Can it register persistence through startup scripts or repo configuration? Teams should continuously validate not only prevention controls but blast-radius controls, because the history of MCP and adjacent agent tooling shows that eventually some prevention layer will be bypassed. (GitHub)
A simple operating model is helpful:
| Continuous red teaming trigger | What to test in the MCP environment | Evidence you should require before calling it safe |
|---|---|---|
| New MCP server added | Can users or content influence its config, command, arguments, or scope | Recorded request path, config diff, approval event, and a blocked exploit attempt |
| SDK upgrade | Can prior exploit paths still reach transport, session, or execution boundaries | Regression results for known test cases and version-pinned build artifacts |
| Trust dialog or approval UI change | Does execution happen before or without meaningful user approval | Timeline showing approval, process spawn, and outbound traffic order |
| Allowlist or template change | Can arguments or alternate fields bypass the intended restriction | Negative tests proving non-template values and unsafe argument forms fail |
| HTTP exposure change | Are Origin, authorization, and Content-Type enforced under browser conditions | Request logs showing rejection of cross-site or malformed requests |
| Container or sandbox change | Can a launched tool still reach secrets, metadata, filesystem, or unrestricted egress | Trace of denied file paths, denied sockets, and limited environment exposure |
That table is not a product checklist. It is a way to convert a vague security concern into a living validation program. Teams that skip this step tend to oscillate between panic and complacency. Teams that keep replayable tests build institutional memory instead. That matters more than any single scanner result.
In practice, this is also where ad hoc scripts start to break down. Repeatedly validating MCP surfaces means combining web traffic replay, browser-aware testing, configuration diffing, tool-invocation observation, evidence collection, and retest after remediation. Penligent’s public material is relevant here because it positions the product as an AI-driven penetration testing workflow with continuous red-team testing, evidence-backed findings, and repeated validation around MCP and agent attack surfaces. That is a reasonable fit for this problem space, not because a platform replaces engineering controls, but because MCP security is now an operational verification problem as much as a code problem. (penligent.ai)
Hardening Anthropic MCP deployments without pretending allowlists are enough
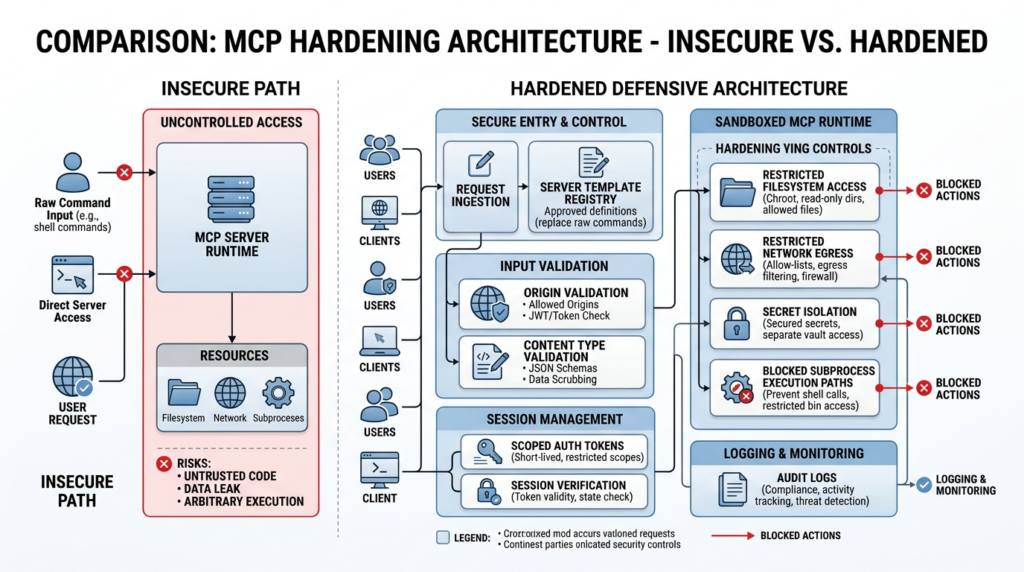
Defenders often want a short list of “fixes.” The problem is that no single fix is honest here. The safe answer is a stack of controls, ordered by how close they are to the dangerous boundary. The most important rule is also the least glamorous: do not expose raw process-launch configuration to end users if you can avoid it. If the application lets a user provide a free-form command et args pair for STDIO, or lets model-edited files register arbitrary MCP servers, you are relying on every downstream safeguard to perform perfectly. The better pattern is to expose a server catalog or template registry and make process-launch details internal-only. (OX Security)
An intentionally unsafe configuration pattern looks like this:
{
"transport": "stdio",
"command": "python",
"args": ["-m", "my_mcp_server"],
"env": {
"API_TOKEN": "${API_TOKEN}"
}
}
On its face, that example looks harmless. The problem is structural. Once an untrusted user, prompt-driven editor, or remote request can alter command, args, or the environment block, the application has handed process-launch authority to an attacker-shaped input. The exact payload does not matter. Even a benign test command proves the boundary is in the wrong place.
A safer pattern is to make server selection indirect and policy-backed:
{
"server_id": "github_readonly",
"workspace_scope": "project",
"requested_permissions": ["repo.read", "issues.read"]
}
Under that pattern, the application never accepts arbitrary executables from the outside. It selects from an internal registry of pre-approved MCP server templates, each with fixed executables, fixed container profiles, fixed environment handling, and predeclared scopes. That does not make the system automatically safe, but it removes an entire exploit family by design.
A minimal policy layer for template-backed registration can be as simple as this:
ALLOWED_SERVERS = {
"github_readonly": {
"command": ["/usr/local/bin/github-mcp"],
"allowed_scopes": {"repo.read", "issues.read"},
"network_profile": "github_only",
"filesystem_profile": "none",
},
"postgres_readonly": {
"command": ["/usr/local/bin/postgres-mcp"],
"allowed_scopes": {"db.read"},
"network_profile": "db_only",
"filesystem_profile": "none",
},
}
def register_mcp_server(user, request):
server = ALLOWED_SERVERS.get(request["server_id"])
if not server:
raise ValueError("unknown server template")
requested = set(request.get("requested_permissions", []))
if not requested.issubset(server["allowed_scopes"]):
raise PermissionError("scope escalation rejected")
return {
"exec": server["command"],
"scopes": sorted(requested),
"network_profile": server["network_profile"],
"filesystem_profile": server["filesystem_profile"],
"approval_required": True,
}
The real value of a pattern like this is not the code itself. It is the change in trust geometry. Users are no longer supplying process-launch instructions. They are selecting from a constrained capability set. That is how you move risk out of string sanitization and into policy.
For HTTP-based MCP deployments, transport hardening has to be equally literal. The Go SDK advisory is useful here because it shows exactly how browser reachability can become tool reachability when servers do not validate Origine and accept text/plain POSTs that avoid preflight. A middleware guard should therefore fail closed on content type, origin, and authorization before the message ever reaches MCP handling logic. (GitHub)
A simple guard pattern looks like this:
func mcpGuard(next http.Handler) http.Handler {
allowedOrigins := map[string]bool{
"https://app.example.com": true,
}
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if r.Method == http.MethodPost && r.Header.Get("Content-Type") != "application/json" {
http.Error(w, "invalid content type", http.StatusUnsupportedMediaType)
return
}
origin := r.Header.Get("Origin")
if origin != "" && !allowedOrigins[origin] {
http.Error(w, "invalid origin", http.StatusForbidden)
return
}
authz := r.Header.Get("Authorization")
if authz == "" {
http.Error(w, "missing authorization", http.StatusUnauthorized)
return
}
next.ServeHTTP(w, r)
})
}
That still is not enough on its own. You also need to ensure session identifiers are not treated as authentication, because MCP’s security guidance explicitly warns against session hijacking and says servers must verify all inbound requests and must not use sessions for authentication. The correct model is that a session helps route state, not prove identity. Identity must come from an authorization control you validate on every request. (Modèle Contexte Protocole)
The same goes for token handling. MCP’s security best practices call token passthrough an anti-pattern and say servers must not accept tokens not explicitly issued for the MCP server. This matters because broad, reusable, or mis-scoped tokens turn a single misstep into lateral movement. In production, you want audience-bound tokens, narrow scopes, distinct credentials per MCP service, and strong auditing around which tool used which credential for which action. (Modèle Contexte Protocole)
Runtime isolation is where many teams become impatient, because containers and sandboxes feel operationally expensive compared with quick feature shipping. But if tools represent arbitrary code execution, and if OX’s advisory is even directionally correct about how often configuration can influence execution in the ecosystem, then containment is not optional. Your MCP subprocesses should launch with the minimum filesystem view they need, minimal environment variables, outbound network restrictions, and no ambient host privileges. A flawed approval flow is much less catastrophic when the process cannot reach secrets, write to arbitrary paths, or phone home freely. (Modèle Contexte Protocole)
A container policy sketch might look like this:
apiVersion: v1
kind: Pod
metadata:
name: mcp-server-github-readonly
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
containers:
- name: mcp
image: registry.example.com/github-mcp:1.2.3
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
capabilities:
drop: ["ALL"]
env:
- name: GITHUB_TOKEN
valueFrom:
secretKeyRef:
name: github-readonly-token
key: token
volumeMounts:
- name: workspace
mountPath: /workspace
readOnly: true
volumes:
- name: workspace
persistentVolumeClaim:
claimName: readonly-workspace
This example is intentionally boring. That is the point. Good hardening makes dangerous systems feel boring in the logs. If the only thing your MCP server can see is the directory it needs, the token it needs, and the network it needs, then a missed approval or unexpected tool invocation is still bad, but it is much less likely to become full compromise.
Detection and verification for Anthropic MCP abuse paths
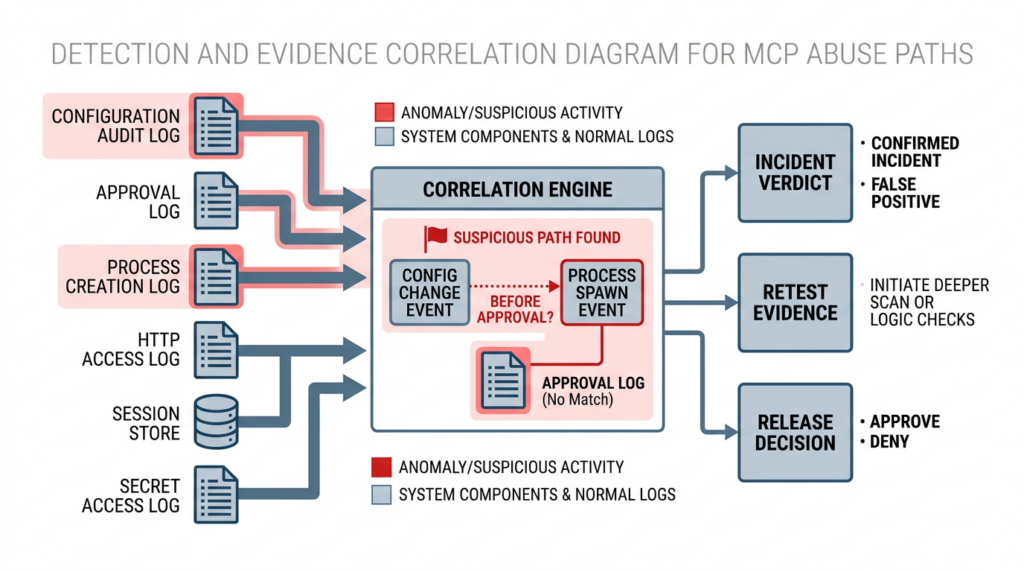
Security guidance that cannot be verified quickly turns into ceremony. For MCP environments, detection has to focus on transitions that should be rare or impossible. You are not trying to log “everything the model did” in prose. You are trying to log the exact moments where configuration changed, approval occurred, a process spawned, an outbound connection was made, a tool executed, or a transport/session condition was violated. (Modèle Contexte Protocole)
A useful way to think about telemetry is to track five timelines at once: configuration timeline, approval timeline, process timeline, network timeline, and session timeline. When a suspicious event happens, you want to answer a sequence of questions in order. Did the config change? Who or what changed it? Was there an approval event? Did a process launch before approval? Did the process use credentials or make network calls it should not have? Was the session or request origin what the system expected? Many of the highest-value MCP and agent security findings become obvious once these timelines are visible in one place. (GitHub)
The following table is a practical starting point.
| Log source | Suspicious signal | Pourquoi c'est important | Likely next step |
|---|---|---|---|
| Config audit log | New MCP server registration from a user, prompt-driven edit, or repo-controlled file | Indicates the boundary between content and execution may have moved | Review the diff, actor, source content, and whether server launch followed |
| Approval log | No approval event, or approval logged after process start | Signals trust dialog or confirmation control may be ineffective | Correlate with process events and block rollout if reproducible |
| Process creation log | Spawn of interpreter, shell, package runner, or MCP server binary from unexpected parent | Often the clearest sign that unsafe config reached execution | Capture arguments, environment, file reads, and egress |
| HTTP access log | Cross-site requests, invalid Origin, or non-JSON content reaching MCP endpoints | Suggests browser-driven request abuse or missing transport enforcement | Verify middleware behavior and close public reachability if needed |
| Session store or queue log | Session identifiers reused across unexpected contexts or nodes | Points to hijacking, response confusion, or cross-client leakage risk | Rotate session state and validate identity binding |
| Secret access or egress log | Tool process reading broad secrets or making unusual outbound calls | Indicates blast-radius controls failed after execution | Isolate runtime, rotate secrets, and rebuild with least privilege |
One reason continuous red teaming is effective here is that it can generate the very telemetry patterns defenders need to trust their own controls. A blocked exploit attempt that leaves clean, correlated evidence is not just a failed attack. It is proof that your approval order, process guardrails, logging, and containment behaved correctly under pressure.
A lightweight detection rule for “unsafe config to process spawn” might look like this:
title: Suspicious MCP STDIO Launch After Config Change
logsource:
product: linux
category: process_creation
detection:
selection_parent:
ParentImage|contains:
- "assistant"
- "ide"
- "mcp"
selection_child:
Image|endswith:
- "/bash"
- "/sh"
- "/python"
- "/node"
- "/npx"
- "/npm"
condition: selection_parent and selection_child
fields:
- ParentImage
- Image
- CommandLine
- User
level: high
That rule is deliberately generic. In a production deployment you would tune it to your real template catalog and known parent processes. The important thing is not the exact syntax. It is that your monitoring is aligned to the trust boundary, not just to generic malware behavior.
The reporting side matters too. Penligent’s public writing repeatedly emphasizes evidence-backed findings, verified results, and reporting that supports replay and retest rather than just AI-generated prose. That emphasis is relevant here because MCP issues are often disputed until someone can show the exact triggering path, the resulting execution, and the state after remediation. In this corner of security, screenshots and narratives are useful, but timeline-grade evidence is what changes engineering behavior. (penligent.ai)
Building a continuous red team loop for Anthropic MCP deployments
A workable continuous red team program for MCP does not need to be massive on day one. It needs to be disciplined. The first step is to define the boundary objects that can change: server templates, raw config files, trust dialogs, transport middleware, sandbox profiles, tokens and scopes, workspace-mounted paths, repository-controlled settings, and MCP-related IDE behavior. If you do not inventory those objects, your test coverage will drift before the product does. (Modèle Contexte Protocole)
The second step is to maintain a library of replayable attack hypotheses. For example: “untrusted content modifies local MCP registration,” “cross-site request triggers a tool call on a local HTTP server,” “session identifier reused across nodes causes event injection,” “broad token allows unrelated tool execution,” “repo-scoped config executes before trust confirmation,” and “a template allowlist still permits dangerous behavior through arguments.” Each hypothesis should map to an actual environment, a safe test payload, a clear pass-fail condition, and a required evidence artifact. That turns security from a memory exercise into an engineering discipline. (OX Security)
The third step is to tie testing to change, not just to the calendar. Weekly validation is better than quarterly validation, but event-driven validation is better still. A new MCP server template should trigger config-boundary tests. A UI or trust-dialog change should trigger approval-order tests. An SDK upgrade should trigger transport, session, and regression tests. A container image change should trigger containment and secret-access tests. This is the operational meaning of continuous red teaming: it follows the system’s pace of change. (OX Security)
The fourth step is to formalize exit criteria. Too many teams stop at “we didn’t reproduce the old bug.” That is not enough. A release should only pass if the dangerous path is blocked, the block is logged, the log correlates cleanly to the triggering action, and the blast-radius controls still hold if a related path is exercised. In other words, a pass condition for MCP security is not absence of proof. It is presence of evidence. That mindset matters because agent systems are unusually good at producing ambiguous behavior if you do not instrument them precisely.
A compact program blueprint looks like this:
| Program element | Minimum viable practice | Better practice |
|---|---|---|
| Inventory | Track MCP servers, transports, scopes, approval paths, and config files | Track them as versioned assets with owners and deployment history |
| Test library | Maintain a small set of replayable exploit hypotheses | Expand to role-based, browser-based, repo-based, and sandbox-escape variations |
| Triggering | Run tests weekly | Run on every high-risk change plus scheduled regression suites |
| Preuves | Save console output and screenshots | Save request traces, process logs, approval events, diffs, and retest artifacts |
| Closure | Patch and move on | Patch, retest automatically, document blast radius, and watch for regression |
This is also the right place to talk about tool support without letting the article turn into a sales page. Public Penligent material on MCP attack surfaces, continuous red teaming, and AI red team assistants describes a workflow that combines offensive validation, evidence capture, retest, and reporting across AI-enabled systems. That is a natural fit for MCP programs because the hard part is rarely generating a single exploit idea. The hard part is re-running the idea safely, proving the control failed, proving the fix works, and keeping that result available for the next release cycle. (penligent.ai)
Anthropic MCP vulnerability and the practical bottom line
The practical lesson from the Anthropic MCP vulnerability story is not that open protocols are bad, nor that agent systems are uniquely doomed. The lesson is simpler and more uncomfortable. When an AI system gains structured access to tools, data, files, browsers, and operating-system actions, the real security problem shifts from model output quality to execution governance. MCP makes that shift explicit. The OX disclosure made it visible. The surrounding CVEs made it impossible to dismiss as a one-off. (OX Security)
If you are responsible for an MCP-enabled product, the wrong question is whether you agree completely with OX’s thesis or Anthropic’s framing. The better question is what your system would do if untrusted input, a prompt-edited config, a browser request, or a shared session path reached the wrong layer tomorrow. If the honest answer is “we are not sure,” then the work is clear. Constrain configuration. Treat tool invocation as code execution. Bind authorization to real identities. Validate origins and content types. Sandboxing is not optional. Reference servers are not automatically safe. Trust dialogs must be tested as controls, not admired as UI. And above all, do not treat one successful pentest as lasting proof that the surface is under control. (Modèle Contexte Protocole)
The teams that will handle MCP safely are not the ones with the most optimistic policy language. They are the ones that keep retesting the execution boundary every time it changes.
Autres lectures et références
OX Security, The Architectural Flaw at the Core of Anthropic’s MCP
OX Security, The Mother of All AI Supply Chains, Technical Deep Dive
OX Security, MCP STDIO Command Injection, Full Vulnerability Advisory
Model Context Protocol Specification
Model Context Protocol Security Best Practices
Model Context Protocol Authorization Specification
Anthropic, Introducing the Model Context Protocol
Anthropic Transparency Hub
GitHub Advisory for CVE-2026-25536, TypeScript SDK cross-client data leak
GitHub Advisory for CVE-2026-33252, Go SDK cross-site tool execution
NVD entry for CVE-2025-68145, mcp-server-git path validation issue
GitHub Advisory for CVE-2025-68143, mcp-server-git unrestricted git_init
GitHub Advisory for CVE-2025-68144, mcp-server-git argument injection
GitHub Advisory for CVE-2025-68145, mcp-server-git repository path validation
GitHub Advisory for CVE-2025-59536, Claude Code startup trust flaw
GitHub Advisory for CVE-2026-21852, Claude Code pre-trust data exfiltration
Check Point Research, RCE and API Token Exfiltration Through Claude Code Project Files
Penligent Home Page
Penligent, MCP and AI Agents, Could They Be Enterprise Security Weak Spots?
Penligent, Agentic AI Security in Production
Penligent, AI Red Team Assistant, What Holds Up in a Real Engagement
Penligent, Continuous Red Teaming With AI, Why the Six Month Pentest Fails

