Anthropic n'a pas présenté Claude Mythos Preview comme une autre version incrémentale du modèle. Elle a présenté le modèle comme un événement de cybersécurité suffisamment grave pour ne pas le mettre à disposition du grand public, le limiter à un programme défensif sur invitation et l'associer à une nouvelle politique de divulgation axée sur la découverte de vulnérabilités à l'échelle de la machine. La documentation d'Anthropic indique que Mythos Preview est un modèle frontière à usage général qui n'a pas été publié et qui n'est disponible qu'en tant qu'aperçu de recherche protégé pour les travaux de cybersécurité défensive dans le cadre du projet Glasswing, sans possibilité d'inscription en libre-service. (Anthropique)
Ce cadrage est important car il modifie la question par défaut. La question n'est plus de savoir si les modèles de frontières peuvent contribuer au travail de sécurité. Le dossier public d'Anthropic répond déjà à cette question. La vraie question est de savoir quel type de travail de sécurité a franchi la ligne qui sépare la "démo de laboratoire intéressante" de la "capacité de perturbation opérationnelle", et quelles parties de la conversation publique ont pris de l'avance par rapport à ce que les personnes extérieures peuvent vérifier de manière indépendante. Anthropic affirme que Mythos Preview a trouvé et exploité des failles dans tous les principaux systèmes d'exploitation et tous les principaux navigateurs web, tout en signalant que plus de 99 % de ses découvertes n'ont pas été divulguées parce qu'elles n'ont pas encore été corrigées. Cette combinaison est exactement la raison pour laquelle ce moment est différent : les capacités revendiquées sont importantes, mais l'ensemble des preuves publiques est intentionnellement réduit. (rouge.anthropic.com)
La bonne lecture n'est ni complaisante, ni essoufflée. L'avant-première de Claude Mythos ne prouve pas publiquement que l'IA a résolu toutes les formes de tests de pénétration par boîte noire sur Internet. Il fournit toutefois la preuve publique la plus solide à ce jour que la recherche de vulnérabilités par l'IA, le développement d'exploits et l'armement du jour zéro évoluent suffisamment rapidement pour imposer des changements dans les fenêtres de correctifs, les processus de divulgation et les flux de travail de validation. La "nouvelle ère du jour zéro" n'est pas un slogan. Il s'agit d'un changement de rythme. (rouge.anthropic.com)
Claude Mythos Preview modifie la charge de la preuve dans la recherche sur les vulnérabilités de l'IA
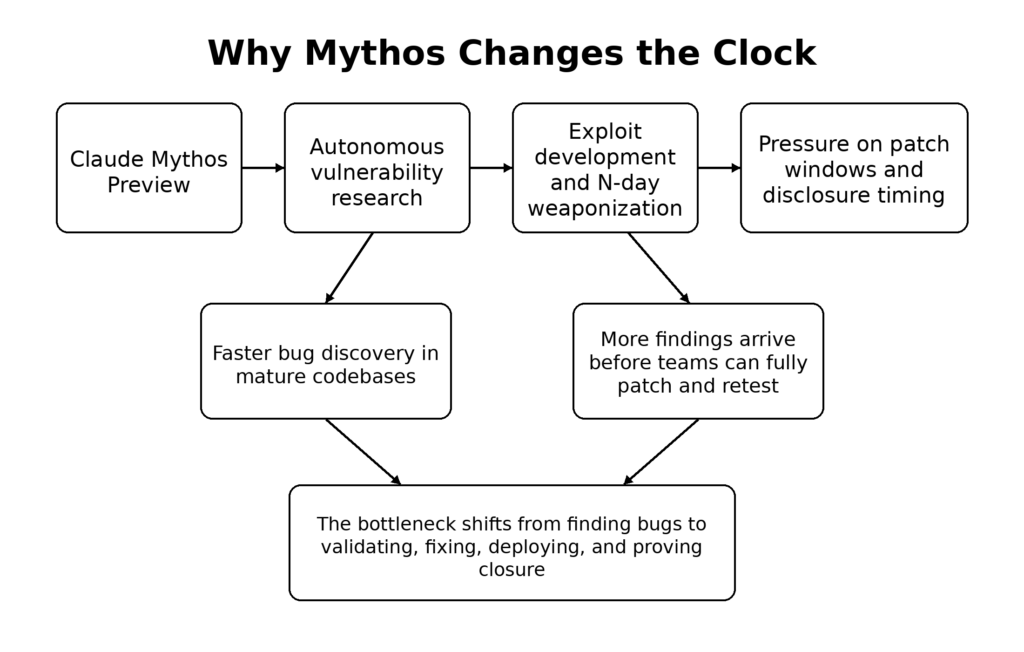
L'article technique principal d'Anthropic contient quatre affirmations que les ingénieurs en sécurité devraient considérer comme le centre de gravité. Premièrement, Mythos Preview est un modèle polyvalent dont les capacités de cybersécurité sont issues de gains plus larges en matière de code, de raisonnement et d'autonomie des agents, plutôt que d'une formation spécifique aux exploits. Deuxièmement, Anthropic affirme que ces capacités comprennent désormais la découverte de zero-day visibles à la source, la construction d'exploits, la rétro-ingénierie de binaires dépouillés et la conversion de vulnérabilités connues en exploits fonctionnels. Troisièmement, Anthropic est explicite sur le fait que ces capacités créent une période de transition au cours de laquelle les attaquants peuvent gagner plus que les défenseurs si les pratiques de diffusion ne changent pas. Quatrièmement, l'entreprise donne suite à cette conclusion en restreignant l'accès et en mettant en place le projet Glasswing autour des principaux opérateurs de logiciels critiques. (rouge.anthropic.com)
Cette combinaison est nouvelle dans les écrits publics sur la sécurité de l'IA. Des documents antérieurs d'Anthropic sur Mozilla et Firefox avaient déjà montré que Claude Opus 4.6 pouvait identifier de nouveaux bogues dans le code d'un grand navigateur, soumettre 112 rapports uniques et contribuer à l'élaboration de correctifs dans Firefox 148. Anthropic a également publié un résultat d'exploitation soigneusement limité pour Opus 4.6 : sur plusieurs centaines de tentatives et environ $4 000 en crédits API, le modèle n'a réussi à transformer les bogues de Firefox en exploits fonctionnels que deux fois, et même ceux-là n'ont fonctionné que dans un environnement de test intentionnellement affaibli. Ce dossier public a révélé aux défenseurs quelque chose d'important, mais qui reste assez limité : La recherche de bogues par l'IA devenait de classe mondiale plus rapidement que le développement d'exploits par l'IA. (Anthropique)
Mythos Preview modifie cet équilibre. Anthropic indique que lorsqu'il a refait le benchmark des exploits Firefox avec Mythos Preview, le modèle a produit des exploits fonctionnels 181 fois et a atteint le contrôle du registre dans 29 cas supplémentaires. Sur son benchmark interne de type OSS-Fuzz, Anthropic indique que Sonnet 4.6 et Opus 4.6 ont principalement atteint des niveaux de crash de faible gravité, tandis que Mythos Preview a atteint un détournement complet du flux de contrôle sur dix cibles entièrement corrigées. Il ne s'agit pas simplement de chiffres plus importants. Ils impliquent que le développement d'exploits n'est plus la moitié la plus en retard du pipeline. (rouge.anthropic.com)
Le rapport d'Anthropic sur les risques ajoute une couche supplémentaire qu'il est facile de ne pas voir dans les gros titres. Le rapport public caviardé indique que Mythos Preview semble être le modèle le mieux aligné qu'Anthropic ait publié, mais il précise également qu'il est nettement plus capable, plus autonome et particulièrement performant dans les tâches d'ingénierie logicielle et de cybersécurité. Le même rapport indique qu'Anthropic a identifié des erreurs dans ses processus de formation, de contrôle, d'évaluation et de sécurité au cours du développement de Mythos et conclut que le risque global est "très faible, mais plus élevé que pour les modèles précédents". Il s'agit là d'un signal de gouvernance autant que de sécurité. Des systèmes plus performants peuvent mieux se comporter en moyenne et néanmoins créer plus de risques opérationnels parce qu'on leur confie des tâches plus difficiles, qu'on leur donne des moyens plus importants et qu'ils sont mieux à même de contourner les obstacles. (Anthropique)
Le projet Glasswing et les raisons pour lesquelles Anthropic n'a pas généralisé l'accès à Mythos Preview
Le projet Glasswing n'est pas une note secondaire. Il s'agit de la réponse politique à l'évaluation des capacités d'Anthropic. L'annonce officielle d'Anthropic indique que le projet rassemble Amazon Web Services, Anthropic, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, la Fondation Linux, Microsoft, NVIDIA et Palo Alto Networks pour sécuriser les logiciels critiques. Anthropic déclare avoir créé le projet parce que Mythos Preview a révélé un fait brutal : les modèles d'IA ont atteint un niveau de capacité de codage tel qu'ils peuvent surpasser tous les humains, à l'exception des plus compétents, pour trouver et exploiter les vulnérabilités des logiciels. (Anthropique)
Cette déclaration est plus forte que l'affirmation habituelle selon laquelle "l'IA peut contribuer à la sécurité des applications". Elle indique que le modèle n'est pas simplement un assistant pour l'examen du code, le triage ou l'élaboration de correctifs. Elle dit que le modèle a sa place dans la même conversation que les chercheurs de vulnérabilités haut de gamme. La documentation officielle de la plateforme renforce le fait qu'Anthropic traite cela comme un aperçu de recherche étroitement contrôlé pour les flux de travail de cybersécurité défensifs uniquement, sans accès en libre-service. C'est assez inhabituel en soi, mais ce qui importe vraiment, c'est la logique opérationnelle qui le sous-tend : si un modèle peut comprimer la recherche d'exploits, alors la gestion de la diffusion et la gestion de la divulgation deviennent des fonctions de sécurité, et pas seulement des fonctions de produit. (Anthropique)
La politique de divulgation coordonnée des vulnérabilités d'Anthropic rend cette logique explicite. L'entreprise indique qu'elle vise à respecter un délai de divulgation de 90 jours, à faire appel à un coordinateur externe lorsque les responsables ne répondent pas dans les 30 jours, à cibler un correctif ou une fenêtre d'atténuation de sept jours pour les vulnérabilités critiques activement exploitées, et à attendre généralement 45 jours après la mise à disposition d'un correctif avant de publier l'ensemble des détails techniques. Ces délais sont reconnaissables pour quiconque a vécu une divulgation coordonnée normale, mais la différence ici est le volume et la cadence supposés. Anthropic affirme que les rapports sont évalués par des humains, que les découvertes provenant de l'IA sont étiquetées comme telles et que le volume de soumissions à un projet devrait être adapté à ce que les responsables peuvent absorber. Il ne s'agit pas d'une simple hygiène de processus. Il s'agit d'admettre que l'IA peut produire des résultats plus vulnérables que les flux de travail traditionnels des mainteneurs n'ont été conçus pour absorber. (Anthropique)
C'est là que l'expression "ère du jour zéro" devient plus pratique que rhétorique. Si la découverte assistée par machine s'étend plus rapidement que le triage des fournisseurs et le déploiement des correctifs en aval, alors le facteur contraignant en matière de sécurité cesse d'être le talent brut de découverte et devient le débit organisationnel. Les équipes qui s'adaptent le plus rapidement ne seront pas celles qui ont la démo la plus flashy. Elles seront celles qui pourront décider, valider, patcher, retester et redéployer plus rapidement que les nouvelles découvertes ne s'accumulent. (rouge.anthropic.com)
Ce que les archives publiques prouvent aujourd'hui, et ce qu'elles ne prouvent pas

La manière la plus propre de penser à Mythos Preview est de séparer le dossier public en trois catégories : les cas vérifiables de manière indépendante, les cas techniquement détaillés mais rédigés par les fournisseurs, et les affirmations générales dont les preuves détaillées restent privées parce que les correctifs ne sont pas prêts. L'article d'Anthropic lui-même indique que plus de 99 % des vulnérabilités qu'il a trouvées n'ont pas encore été corrigées et ne peuvent donc pas être divulguées de manière responsable. Ce simple fait explique la majeure partie de la confusion entourant le lancement. La conversation publique traite toutes les réclamations comme étant également visibles, mais ce n'est pas le cas. (rouge.anthropic.com)
| Domaine de compétence | Preuves publiques | Ce que les personnes extérieures peuvent vérifier aujourd'hui | Ce qui reste essentiellement privé |
|---|---|---|---|
| Découverte d'un zero-day en source ouverte | Anthropic a publié des exemples détaillés de correctifs pour OpenBSD, FFmpeg et FreeBSD, ainsi que d'autres découvertes non nommées. (rouge.anthropic.com) | OpenBSD errata 025 et FreeBSD SA-26:08 sont publics ; FFmpeg 8.1 est public ; des correctifs et des avis spécifiques existent. (openbsd.org) | La plupart des autres découvertes ne sont pas divulguées parce qu'elles n'ont pas été corrigées. (rouge.anthropic.com) |
| Développement d'exploits autonomes | Anthropic a publié des détails sur l'exploitation de FreeBSD, des articles sur l'exploitation de N-day Linux, et des gains de benchmark par rapport à Opus 4.6. (rouge.anthropic.com) | Les chiffres de référence et les récits d'exploits sont publics, mais la reproduction nécessite les mêmes bogues, les mêmes harnais et les mêmes environnements. (rouge.anthropic.com) | De nombreuses chaînes d'exploitation de navigateurs et de systèmes d'exploitation restent sous embargo. (rouge.anthropic.com) |
| Rétro-ingénierie des binaires dépouillés | Anthropic dit que Mythos reconstruit une source plausible à partir de binaires dépouillés, puis analyse la source reconstruite ainsi que le binaire d'origine. (rouge.anthropic.com) | La méthodologie est publique. Les objectifs et les résultats sous-jacents, qui sont des sources fermées, ne le sont généralement pas. (rouge.anthropic.com) | La plupart des dossiers restent confidentiels. (rouge.anthropic.com) |
| Vulnérabilités logiques des applications web | Anthropic énumère publiquement des catégories telles que le contournement de l'authentification, le contournement de la connexion et le déni de service destructeur. (rouge.anthropic.com) | Les preuves au niveau de la catégorie sont publiques. Les études de cas détaillées ne le sont pas. (rouge.anthropic.com) | La preuve publique du pentesting web en boîte noire face à l'internet reste limitée. (penligent.ai) |
| Contrôles des rejets et gouvernance | Le projet Glasswing, l'accès sur invitation seulement et une politique dédiée aux maladies cardiovasculaires sont publics. (Anthropique) | La posture de libération est entièrement visible. | Les seuils internes exacts qui ont motivé cette position ne sont que partiellement visibles dans le rapport sur les risques expurgé. (Anthropique) |
L'exagération la plus courante dans les discussions autour de Mythos est de réduire ces catégories en une seule. Anthropic a publié des preuves exceptionnellement solides de la découverte de vulnérabilités visibles à la source et des preuves de plus en plus solides de l'élaboration d'exploits. Elle n'a pas publié de cas public reproductible montrant que Mythos exécute de manière autonome la boucle complète de test d'une application web en boîte noire contre une cible Internet en direct avec le type d'état désordonné, l'identité, les limites de taux, les contrôles compensatoires et les bizarreries de l'environnement qui définissent le pentesting d'une application réelle. La description de l'échafaudage d'Anthropic indique que le projet sous test et son code source sont placés dans un conteneur isolé. La section relative à la rétro-ingénierie indique que le code source reconstruit et le binaire original sont fournis hors ligne. Il s'agit là d'une capacité réelle et importante, mais ce n'est pas la même chose qu'une preuve publique de l'automatisation universelle du pentest en boîte noire. (rouge.anthropic.com)
Cette distinction est importante car les acheteurs, les équipes rouges et les responsables de la sécurité ont besoin d'un vocabulaire stable. La recherche sur les exploits de l'IA en boîte blanche est déjà importante d'un point de vue stratégique. La validation boîte noire à l'échelle de l'internet est une question différente. Confondre les deux crée de mauvaises acquisitions, de mauvaises attentes et de mauvaises priorités en matière d'ingénierie. La bonne conclusion n'est pas que Mythos est surestimé. La bonne conclusion est que l'accélération de la recherche sur les exploits est bien réelle, tandis que certaines des interprétations les plus larges de la sécurité des applications restent en avance sur les preuves publiques. (rouge.anthropic.com)
La méthodologie d'Anthropic importe autant que les résultats
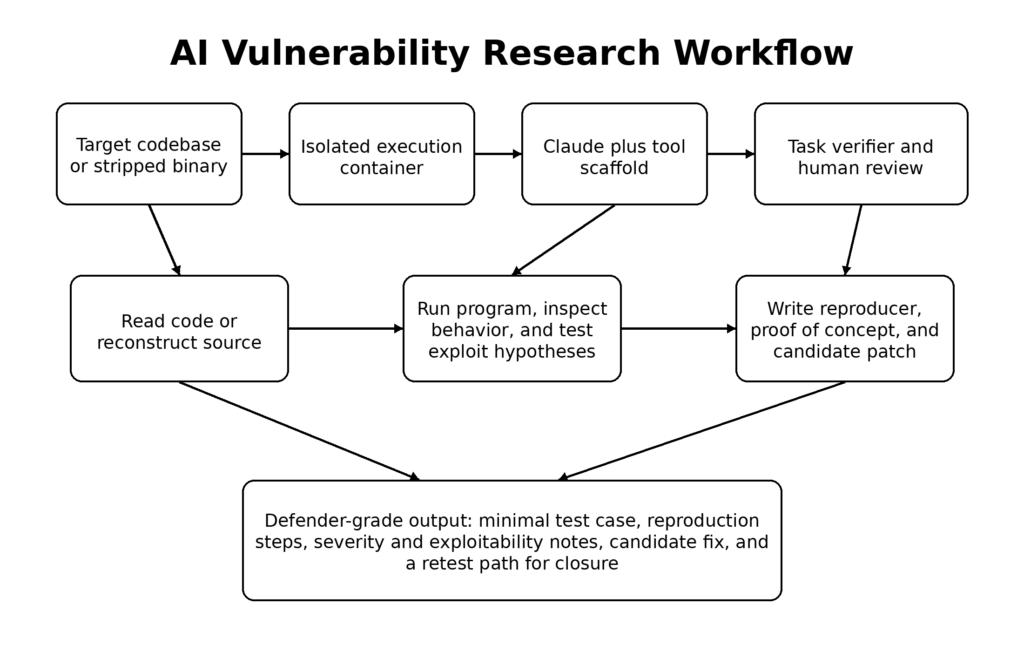
L'une des raisons pour lesquelles Mythos mérite une attention particulière est qu'Anthropic n'a pas présenté ses résultats comme un mystère magique. L'entreprise a consacré une part importante de son article à la méthodologie, et c'est précisément à ces détails méthodologiques que les défenseurs devraient prêter attention. Anthropic explique qu'elle a choisi de se concentrer en premier lieu sur les vulnérabilités liées à la sécurité de la mémoire pour des raisons pragmatiques : elles sont courantes, graves et relativement faciles à vérifier avec des outils comme AddressSanitizer. Le document indique également que l'équipe de recherche avait suffisamment d'expérience en matière d'exploitation pour valider les résultats de manière efficace. Il s'agit là d'un point plus discret mais crucial. La recherche de vulnérabilités par l'IA ne supprime pas le besoin de validation par des experts. Elle change la place de l'expertise dans la boucle. (rouge.anthropic.com)
L'échafaudage décrit par Anthropic est également révélateur. L'entreprise explique qu'elle lance un conteneur isolé qui inclut le projet sous test et son code source, invoque Claude Code avec Mythos Preview, et l'invite à un niveau élevé à trouver une vulnérabilité de sécurité. Claude lit alors le code, formule des hypothèses, exécute le programme, confirme ou rejette les soupçons, ajoute une logique de débogage ou utilise des débogueurs, et émet finalement soit "pas de bogue", soit un rapport de bogue avec une preuve de concept et des étapes de reproduction. Ce flux de travail ressemble moins à un chatbot qu'à un chercheur en vulnérabilités débutant ou moyen, doté d'une patience infinie, d'un changement de contexte rapide et d'une volonté de continuer à essayer. (rouge.anthropic.com)
La collaboration avec Mozilla fournit un modèle antérieur utile sur la façon dont ce type de système devient utile plutôt que bruyant. Anthropic dit que Claude Opus 4.6 a trouvé un Use After Free dans le moteur JavaScript de Firefox après environ vingt minutes d'exploration, après quoi les chercheurs ont indépendamment validé le bogue et l'ont soumis avec une proposition de correctif. Mozilla a ensuite contribué à façonner le processus de signalement et a encouragé la soumission en masse de cas de test de plantage. L'article d'Anthropic sur ce travail met l'accent sur trois artefacts de confiance dans les soumissions : des cas de test minimaux, des preuves de concept détaillées et des correctifs candidats. Ces éléments ne sont pas cosmétiques. Ce sont les ingrédients exacts qui permettent aux mainteneurs de convertir les résultats du modèle en actions techniques. (Anthropique)
Anthropic accorde également une grande importance à ce qu'il appelle les vérificateurs de tâches. Dans l'article sur Mozilla, il affirme que les modèles sont plus performants lorsqu'ils peuvent vérifier leur propre travail par rapport à des signaux de confiance, à la fois pour confirmer le bogue original et pour valider les correctifs proposés par rapport aux régressions. Cette leçon s'applique bien au-delà de Firefox. Une équipe de sécurité qui insère un modèle dans un référentiel sans couche de vérification solide construit un pipeline d'hallucinations coûteux. Une équipe qui donne à un modèle un oracle de confiance, un harnais de test, une suite de régression et un environnement d'exécution contrôlé construit quelque chose de beaucoup plus proche d'un instrument d'ingénierie. (Anthropique)
OpenBSD et la valeur de la découverte d'un vieux bogue dans une cible difficile
Le cas OpenBSD d'Anthropic est le genre d'exemple auquel les professionnels de la sécurité s'accrochent parce qu'il est à la fois concret et chargé de symboles. Anthropic affirme que Mythos Preview a trouvé ce qui est devenu un bogue de 27 ans, aujourd'hui corrigé, dans la gestion du TCP Selective Acknowledgment d'OpenBSD. L'errata officiel de la version 7.8 d'OpenBSD confirme que le patch 025, daté du 25 mars 2026, corrigeait une condition dans laquelle les paquets TCP avec des options SACK invalides pouvaient faire planter le noyau. L'artefact du correctif correspondant montre que le correctif a ajouté une vérification de la limite inférieure sur le paramètre sack.start par rapport à snd_una et a également gardé un chemin d'accès à l'appendice avec p != NULL. (openbsd.org)
L'explication technique d'Anthropic explique pourquoi ce bogue est intéressant. L'article dit qu'OpenBSD a suivi l'état SACK comme une liste chaînée de trous. La fin d'une plage reconnue était vérifiée par rapport à la fenêtre d'envoi, mais le début ne l'était pas. Cela a mis en place un chemin logique où un seul bloc SACK pouvait supprimer le seul trou de la liste et également tenter d'ajouter un nouveau trou, en écrivant finalement à travers un pointeur nul. Anthropic explique en outre que l'enroulement du numéro de séquence TCP et les comparaisons signées ont permis d'atteindre une condition apparemment impossible. Que le lecteur soit ou non d'accord avec chaque détail d'interprétation de l'explication d'Anthropic, le correctif public et l'errata officiel indiquent clairement que la classe de bogues était réelle et que la correction n'était pas cosmétique. (rouge.anthropic.com)
L'exemple d'OpenBSD est important pour trois raisons. Premièrement, il montre que la preuve publique ne doit pas nécessairement se présenter sous la forme d'un RCE prestigieux ou d'un CVE qui fait la une des journaux. OpenBSD a qualifié ce problème de correctif de fiabilité, mais un crash du noyau déclenché à distance reste un problème de sécurité ayant un impact opérationnel réel. Deuxièmement, il démontre le type de raisonnement sur les conditions limites que les modèles commencent à bien maîtriser : machines à états, cas limites arithmétiques, hypothèses sentinelles et branches "ceci devrait être inaccessible". Troisièmement, il met en évidence la manière dont l'IA modifie l'économie de la recherche. Anthropic affirme avoir trouvé le bogue OpenBSD après environ un millier d'exécutions de l'échafaudage, pour un coût total inférieur à $20 000, tout en trouvant des dizaines de problèmes supplémentaires, et affirme que l'exécution réussie spécifique a coûté moins de $50 uniquement a posteriori. Cela ne prouve pas que la chasse aux zero-day soit soudainement bon marché d'une manière générale, mais c'est une preuve solide que certaines parties du processus de recherche sont de plus en plus parallélisables. (rouge.anthropic.com)
Voici une esquisse de pseudocode défensif dépouillé du type de logique limite qui importe dans le traitement SACK :
if (sack.end > snd_max)
ignore() ;
if (sack.start < snd_una)
ignore() ; // Le patch OpenBSD a ajouté une vérification de ce type
walk_hole_list() ;
delete_or_shrink_holes() ;
if (last_hole != NULL && rcv_lastsack < sack.start)
append_new_hole() ;
L'idée n'est pas que les défenseurs devraient mémoriser un bogue d'OpenBSD. L'idée est que les systèmes d'intelligence artificielle sont désormais suffisamment performants pour continuer à s'inquiéter de la logique des limites de l'état que les fuzzers ne peuvent pas facilement atteindre et que les humains peuvent ne pas revisiter pendant des années. Cela change la confiance que les équipes peuvent accorder à l'idée qu'une base de code mature a déjà été "suffisamment examinée". (ftp.openbsd.org)
FFmpeg et pourquoi les cas limites sémantiques sont plus importants que le nombre de crashs
Le cas de FFmpeg est un autre type d'avertissement. Anthropic affirme que Mythos Preview a trouvé une vulnérabilité vieille de 16 ans dans le codec H.264 de FFmpeg. L'explication de la société se concentre sur la façon dont FFmpeg suit la tranche qui possède chaque macrobloc dans une image. Anthropic indique que les entrées de la table sont des entiers de 16 bits, que le compteur de tranches est un entier de 32 bits sans limite supérieure et que la table est initialisée avec la valeur memset(..., -1, ...), laissant 65535 comme sentinelle pour "unowned". Si un attaquant produit une trame avec 65 536 tranches, le numéro de tranche 65535 entre en collision avec la sentinelle et le décodeur peut conclure qu'un voisin inexistant appartient à la même tranche, ce qui entraîne une écriture hors limites et un plantage. Anthropic explique que l'hypothèse sous-jacente de la sentinelle remonte à l'introduction de la norme H.264 en 2003 et qu'elle est devenue exploitable après un remaniement de 2010, que l'historique du projet reflète toujours. (rouge.anthropic.com)
Cet exemple est utile précisément parce qu'Anthropic ne l'exagère pas. L'entreprise indique explicitement que le bogue n'est pas d'une gravité critique et qu'il serait probablement difficile de le transformer en un exploit fonctionnel. Cette retenue est importante. Trop de discussions sur la sécurité de l'IA traitent chaque bogue de mémoire découvert comme s'il s'agissait d'un gadget à la limite de la compromission totale. La meilleure leçon est plus subtile : les modèles commencent à raisonner efficacement sur les invariants sémantiques, les valeurs sentinelles, les largeurs de type et les structures d'entrée rares mais valides que le fuzzing traditionnel peut sous-échantillonner. Ce type de raisonnement élargit l'espace de recherche pour la découverte de vulnérabilités, même lorsque le bogue résultant n'est pas trivialement armé. (rouge.anthropic.com)
FFmpeg fournit également aux défenseurs un point d'ancrage opérationnel. Anthropic affirme que trois vulnérabilités de FFmpeg identifiées par Mythos ont été corrigées dans FFmpeg 8.1, et le site officiel de FFmpeg confirme que la version 8.1 "Hoare" a été livrée le 16 mars 2026. C'est le genre de tissu conjonctif dont les équipes de sécurité doivent se préoccuper aujourd'hui : il ne s'agit pas seulement de savoir si un modèle a trouvé un bogue, mais aussi si la découverte peut être suivie dans un train de publication, si les consommateurs en aval savent qu'ils doivent mettre à jour, et si les mainteneurs de paquets et les équipes de produits sont prêts à absorber le volume de divulgation assistée par l'intelligence artificielle. (rouge.anthropic.com)
| Mallette Mythos publique | Pourquoi c'est important d'un point de vue technique | Ce que les défenseurs devraient apprendre |
|---|---|---|
| OpenBSD SACK | Logique de protocole avec état, arithmétique des bords, maintenance des listes chaînées dans des conditions d'enveloppement. (rouge.anthropic.com) | Les piles de réseaux matures cachent encore des hypothèses fragiles. "L'absence d'accidents récents n'est pas une preuve de sécurité. |
| FFmpeg H.264 | Collisions de sentinelles, inadéquation de la largeur des entiers, structures rares mais conformes à la spécification, et mauvaise utilisation sémantique des schémas d'initialisation. (rouge.anthropic.com) | Le Fuzzing reste nécessaire mais pas suffisant ; le raisonnement symbolique et sémantique s'améliore. |
| FreeBSD RPCSEC_GSS | Débordement de pile classique et construction d'un exploit dans un véritable chemin de service orienté vers le noyau. (Le projet FreeBSD) | L'IA n'est plus confinée à la découverte des accidents ; elle est de plus en plus pertinente pour l'ingénierie d'exploitation. |
| Linux ipset N-day | Les primitives d'écriture d'un bit peuvent toujours être promues en racine avec un chaînage d'exploitation patient. (rouge.anthropic.com) | La latence des correctifs est plus dangereuse lorsque les modèles peuvent accélérer le développement des exploits. |
FreeBSD CVE-2026-4747 et ce à quoi ressemble un désaccord sur les sources publiques
Le cas de FreeBSD est probablement l'exemple public le plus important de Mythos, car c'est là que se rencontrent la découverte de vulnérabilités par l'IA, l'élaboration d'exploits et le désaccord sur les sources. Anthropic affirme que Mythos Preview a identifié et exploité de manière totalement autonome une vulnérabilité d'exécution de code à distance vieille de 17 ans dans le serveur NFS de FreeBSD, classée CVE-2026-4747, et la décrit comme permettant un contrôle complet du serveur à partir d'un utilisateur non authentifié situé n'importe où sur Internet. L'article technique d'Anthropic attribue le bogue à un chemin RPCSEC_GSS qui copie les données contrôlées par l'attaquant dans un tampon de pile de 128 octets avec une vérification insuffisante de la longueur, permettant une attaque ROP conventionnelle dans des conditions inhabituellement favorables. (rouge.anthropic.com)
L'avis officiel de FreeBSD confirme l'essentiel de cette description mais est plus conservateur dans la façon dont il parle de l'impact. L'avis indique que chaque paquet de données RPCSEC_GSS est validé par une routine qui copie une partie du paquet dans un tampon de pile sans s'assurer que le tampon est suffisamment grand, et qu'un client malveillant peut déclencher un débordement de pile sans s'authentifier au préalable. Mais lorsqu'il décrit l'impact, le même avis indique que l'exécution de code à distance en espace noyau est possible par un utilisateur authentifié capable d'envoyer des paquets au serveur NFS du noyau alors que kgssapi.ko est chargé, et indique que les serveurs RPC de l'espace utilisateur liés à la bibliothèque vulnérable sont exploitables à distance à partir de n'importe quel client capable de leur envoyer des paquets. NVD reflète ce langage d'impact plus prudent et, à la date indiquée sur la page publique, affiche un score ADP de 8.8 High alors que le propre score de NVD n'était pas encore renseigné. (Le projet FreeBSD)
Cet écart est exactement le genre de choses auxquelles les défenseurs doivent s'habituer à l'ère de l'IA. Il existe au moins trois interprétations plausibles de la différence. La première est que le déclenchement du débordement de pile n'est pas authentifié, alors que l'éditeur est resté prudent sur les conditions d'un RCE fiable du noyau. Une autre est que la chaîne d'exploitation réussie d'Anthropic a démontré un état final plus fort que ce que l'avis était prêt à généraliser au moment de la divulgation. Enfin, la différence reflète simplement l'écart habituel entre un rapport de recherche axé sur le plafond technique et un avis du fournisseur axé sur des déclarations délimitées et justifiables. L'important n'est pas de choisir son camp de manière théâtrale. Ce qui importe, c'est de lire attentivement les deux sources et de résister à l'envie de les réduire à une seule phrase simplifiée à l'extrême. (rouge.anthropic.com)
L'histoire de la remédiation mérite également d'être soulignée. L'avis de FreeBSD indique que toutes les versions supportées sont affectées et liste les branches corrigées incluant 15.0-RELEASE-p5, 14.4-RELEASE-p1, 14.3-RELEASE-p10, et 13.5-RELEASE-p11, ainsi que les corrections de la branche stable. Elle indique également qu'aucune solution de contournement n'est disponible, si ce n'est que les systèmes sans kgssapi.ko ne sont pas vulnérables dans le chemin du noyau. C'est un exemple classique de la raison pour laquelle les opérations de correction, et pas seulement les abonnements à des services de conseil, décideront qui reste en sécurité dans un monde où l'IA peut aider à créer des exploits plus rapidement. (Le projet FreeBSD)
Un flux de travail pratique de première réponse pour les domaines FreeBSD ressemble à ceci :
# Identifier les versions du noyau et du userland en cours d'exécution
freebsd-version -ku
# Vérifier si le module RPCSEC_GSS du noyau est présent
kldstat | grep kgssapi
# Si vous utilisez des paquets de base
sudo pkg upgrade -r FreeBSD-base
# Si vous utilisez des ensembles de distribution binaires
sudo freebsd-update fetch
sudo freebsd-update install
sudo shutdown -r now
Ces commandes ne remplacent pas la discipline de maintenance, mais elles illustrent la véritable question de la sécurité. À l'ère de Mythos, la question de savoir s'il existe un correctif devient la partie facile. "La question de savoir si j'ai inventorié, hiérarchisé, déployé et vérifié le correctif assez rapidement est la partie la plus difficile. (Le projet FreeBSD)
Linux kernel CVE-2024-53141 et pourquoi N-day est désormais un modèle de menace de premier ordre
Si le cas de FreeBSD montre un potentiel d'exploitation de jour zéro, le cas de Linux ipset montre pourquoi les défenseurs doivent accorder une plus grande priorité à l'exploitation du jour N. La NVD décrit la CVE-2024-53141 comme un problème du noyau Linux en bitmap_ip_uadt où une vérification de plage manquante peut conduire à une vulnérabilité locale de haute gravité. La page NVD indique un score CVSS 3.1 de 7.8 High et des gammes de versions affectées sur plusieurs lignes du noyau. La description de l'avis d'Ubuntu reflète la même cause première, expliquant que lorsque IPSET_ATTR_IP_TO est absente mais IPSET_ATTR_CIDR existe, les valeurs sont traitées d'une manière qui laisse un contrôle de plage manquant et permet à la vulnérabilité de se produire. (nvd.nist.gov)
La contribution d'Anthropic dans le post Mythos n'est pas de revendiquer la découverte de ce bug. Il est explicitement dit que cette section concerne un jour N que Mythos Preview a reçu. Le point était l'exploitation. L'article d'Anthropic explique comment un index hors limites dans ipset peut être transformée en une primitive d'écriture limitée à un bit, puis patiemment amplifiée par l'adjacence de pages physiques, la manipulation de l'ETP et l'altération éventuelle de l'entrée de la mémoire cache de la page pour /usr/bin/passwd pour atteindre la racine. Que le lecteur veuille ou non suivre cette chaîne dans son intégralité, la signification en termes de sécurité est évidente : les vulnérabilités locales corrigées qui se trouvaient auparavant dans le seau "nous nous en occuperons bientôt" deviennent plus dangereuses si les modèles peuvent comprimer le travail d'ingénierie d'exploitation nécessaire pour en faire une arme. (rouge.anthropic.com)
C'est là que le catalogue CISA des vulnérabilités connues et exploitées devient plus pertinent, et non moins. La CISA décrit le catalogue KEV comme une ressource destinée à aider la communauté de la cybersécurité et les défenseurs des réseaux à gérer les mesures correctives sur la base de preuves d'exploitation dans la nature. L'idée de KEV a toujours été que tous les CVE ne méritent pas la même urgence. Les capacités de type mythique n'invalident pas cette logique. Elles l'intensifient. Si l'assistance d'une machine réduit le temps qui s'écoule entre la diffusion du correctif et l'exploitation, alors les défenseurs doivent considérer "publiquement patché et accessible dans mon environnement" comme une condition d'escalade beaucoup plus agressive qu'ils ne le faisaient il y a quelques années. (CISA)
L'erreur opérationnelle que commettent encore de nombreuses organisations est de trier les files d'attente de correctifs en fonction des seules étiquettes de gravité publiques. Cela n'a jamais été idéal, et la situation empire à mesure que le développement d'exploits s'accélère. À court terme, les équipes devraient orienter le triage vers une combinaison de facteurs : surface d'attaque exposée, franchissement des limites de privilèges, primitives de corruption de la mémoire, récence des correctifs récents, clarté du commit pertinent pour l'exploit et disponibilité des vérificateurs qui rendent bon marché la reproduction assistée par l'IA. Une note de correctif claire et un chemin de déploiement accessible sont désormais plus dangereux qu'un CVSS au son effrayant dans un composant que personne ne peut atteindre. (rouge.anthropic.com)
Ingénierie inversée, chaînes de navigation et limites publiques de l'histoire de Mythos
Les affirmations les plus audacieuses d'Anthropic vont au-delà des cas que les personnes extérieures peuvent inspecter pleinement aujourd'hui. Le document indique que Mythos Preview peut prendre une source fermée, un binaire dépouillé, reconstruire un code source plausible, puis analyser la source reconstruite avec le binaire original pour trouver des vulnérabilités. Il indique également que le modèle a trouvé de manière autonome des primitives de lecture et d'écriture dans plusieurs navigateurs, les a enchaînées dans des pulvérisations de tas JIT et, dans un cas, a combiné un exploit de navigateur avec une évasion de bac à sable et une élévation locale des privilèges de sorte qu'une page web malveillante puisse finalement écrire directement dans le noyau du système d'exploitation. Il s'agit là de déclarations extraordinaires. Anthropic prend soin de couvrir certaines d'entre elles en s'engageant à révéler les détails après l'application des correctifs. (rouge.anthropic.com)
Les lecteurs spécialisés dans la sécurité devraient tirer deux leçons de cette section. La première est que la rétro-ingénierie hors ligne et la recherche d'exploits sont elles-mêmes des capacités majeures. La reconstruction d'une source plausible à partir de binaires dépouillés est précieuse, même si elle ne constitue pas encore une preuve publique d'une recherche de vulnérabilités universellement fiable à l'échelle des binaires uniquement. Deuxièmement, la limite de la preuve publique est toujours importante. Anthropic dit à ses lecteurs que ces choses se sont produites, mais les artefacts détaillés nécessaires à une réplication externe indépendante ne sont en grande partie pas encore publics. Cela ne signifie pas que les affirmations sont fausses. Cela signifie que le niveau de confiance doit être formulé correctement. Une "preuve solide rédigée par un fournisseur avec une reproductibilité publique limitée" est différente d'un "fait établi publiquement". (rouge.anthropic.com)
Cette distinction devient encore plus importante lorsque la conversation passe de la recherche d'exploits visibles à la source aux tests d'applications web orientées vers l'internet. Anthropic énumère publiquement d'importantes catégories de bogues logiques, notamment les contournements d'authentification complète, les contournements de connexion de compte et les conditions de déni de service destructeur. Ces catégories de bogues sont très importantes dans les environnements SaaS réels. Mais l'article public d'Anthropic ne donne pas d'études de cas publiques détaillées pour ces résultats, et ses preuves méthodologiques les plus solides restent concentrées dans des contextes visibles à la source ou hors ligne. Une façon utile de présenter la situation est la suivante : Mythos Preview a clairement fait progresser l'état de la recherche sur les exploits de l'IA, mais le dossier public n'a pas encore comblé le fossé entre la recherche d'exploits à haute teneur en information et le pentesting web de bout en bout en boîte noire contre des systèmes réels. (rouge.anthropic.com)
C'est également la raison pour laquelle les équipes matures devraient cesser de considérer le raisonnement en boîte blanche et la validation en boîte noire comme des catégories de produits concurrentes. Il s'agit d'étapes différentes dans une boucle de sécurité plus fiable. L'écriture technique publique de Penligent sur cette séparation est utile à cet égard : elle soutient que l'IA consciente de la source peut réduire la recherche et cartographier les causes profondes probables, tandis que la validation orientée vers la cible est toujours nécessaire pour prouver l'accessibilité et l'impact dans l'environnement déployé. Il s'agit là d'une interprétation sensée du moment Mythos. Le travail qui se comprime clairement en premier est la première moitié coûteuse de la recherche d'exploits. Le travail qui nécessite encore une interaction prudente avec le système est la preuve contre la surface réelle de la cible. (penligent.ai)
La sécurité de la mémoire reste centrale, mais les bogues logiques ne disparaissent pas.
Il est tentant de considérer le lancement de Mythos comme une grande publicité pour les langages à mémoire sécurisée, et il y a une part de vérité là-dedans. Les arguments les plus solides qu'Anthropic a publiés jusqu'à présent sont fortement concentrés dans des domaines où la mémoire n'est pas sûre : Le traitement TCP d'OpenBSD, RPCSEC_GSS du noyau FreeBSD, le décodeur H.264 de FFmpeg et les chaînes d'exploitation du noyau Linux. Les orientations du gouvernement américain vont dans le même sens depuis des années. En décembre 2023, la NSA, la CISA et leurs partenaires ont publié un document intitulé "The Case for Memory Safe Roadmaps", dans lequel ils affirment que l'adoption de langages sans risque pour la mémoire peut éliminer de vastes catégories de vulnérabilités liées à la sécurité de la mémoire. En juin 2025, la NSA et la CISA ont de nouveau souligné que la réduction des vulnérabilités liées à la mémoire est essentielle et que les conséquences d'un manquement à cette règle peuvent inclure des violations, des pannes et des perturbations opérationnelles. (Département de la guerre des États-Unis)
Mais l'article de Mythos montre aussi clairement pourquoi la sécurité de la mémoire ne peut pas être la seule solution. Anthropic indique que Mythos Preview a trouvé de multiples contournements d'authentification complète, des contournements de connexion de compte et des conditions de déni de service qui pourraient supprimer des données à distance ou faire planter un service. Il décrit également un contournement KASLR du noyau Linux qui ne provient pas d'une lecture hors limites classique, mais d'un pointeur du noyau délibérément exposé. Il s'agit là d'erreurs de logique et de conception, et pas seulement d'erreurs de gestion de la mémoire. Une migration vers Rust ou un autre langage à mémoire sécurisée réduirait une surface de risque très importante, mais ne neutraliserait pas les lacunes en matière d'autorisation, les inadéquations entre les modèles de sécurité ou les fuites d'informations qui "fonctionnent comme codées" et restent dangereuses. (rouge.anthropic.com)
| Famille vulnérable dans la discussion Mythos | Ce que la sécurité linguistique peut apporter | Ce qu'il ne résout pas |
|---|---|---|
| Corruption de la mémoire dans les analyseurs, les noyaux et les piles de réseau | Élimine ou réduit un grand nombre de lectures et d'écritures hors limites, d'UAF et de doubles libérations lorsque le sous-ensemble sûr est effectivement utilisé. (Département de la guerre des États-Unis) | Les trappes d'évacuation non sûres, les limites de la FFI et les erreurs de conception ont encore de l'importance. L'exemple de la VMM à mémoire sécurisée d'Anthropic dépendait d'une opération non sécurisée. (rouge.anthropic.com) |
| Erreurs de contournement de l'authentification et de la logique de connexion | Peu d'aide directe en dehors d'une hygiène de mise en œuvre plus sûre. | La logique d'autorisation non respectée, les erreurs de limites de confiance et les failles dans le flux de travail subsistent encore. (rouge.anthropic.com) |
| Fuites d'informations et contournement du KASLR | Peut réduire certaines fuites de mémoire. | L'exposition délibérée de pointeurs ou de métadonnées peut rester exploitable même dans un code à mémoire sécurisée. (rouge.anthropic.com) |
En pratique, les responsables de la sécurité doivent résister aux faux binaires. Ils n'ont pas à choisir entre la sécurité de la mémoire et la rapidité de réponse aux exploits. Ils ont besoin des deux. Les feuilles de route relatives à la sécurité de la mémoire permettent de réduire les risques structurels à long terme. Des vérifications, des correctifs et des tests plus rapides sont des nécessités opérationnelles à court terme dans un monde où le développement d'exploits s'accélère avant que la base installée ne puisse être réécrite. (Département de la guerre des États-Unis)
Le manuel du défenseur pour l'ère Mythos
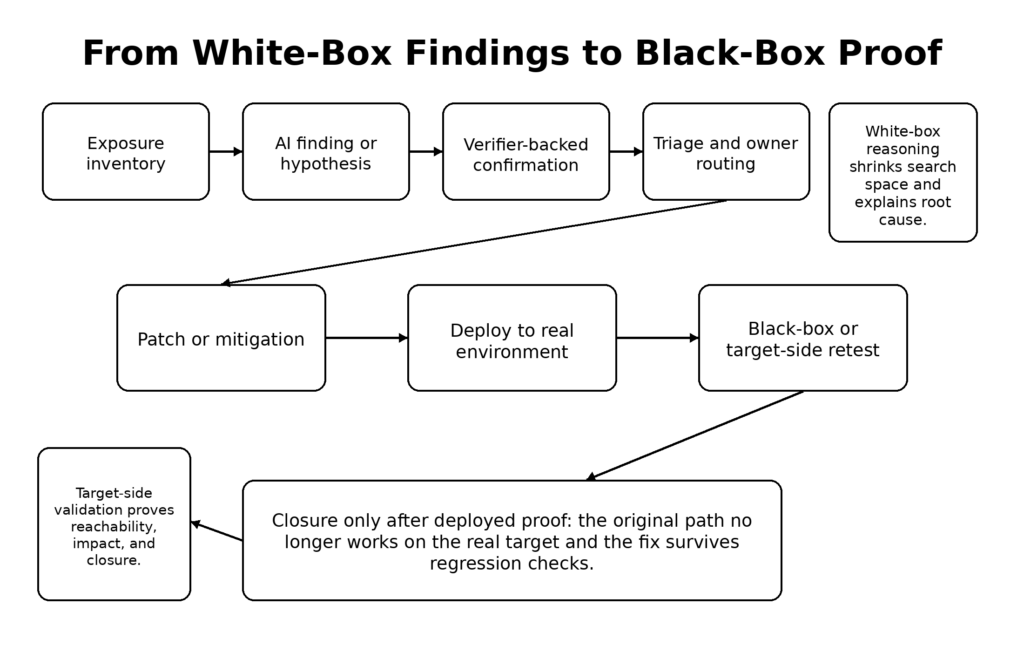
Le conseil public d'Anthropic aux défenseurs est direct, et c'est l'une des parties les plus utiles du communiqué. L'entreprise affirme que les organisations devraient aller au-delà de la recherche de vulnérabilités et s'intéresser au triage, à la déduplication, aux étapes de reproduction, aux correctifs candidats, à l'examen de la mauvaise configuration du nuage, à l'examen des relations publiques et au travail de migration. Elle affirme explicitement que les équipes devraient raccourcir les cycles de correctifs, revoir l'application des correctifs, activer la mise à jour automatique dans la mesure du possible, traiter de manière urgente les bosses de dépendance portant des correctifs CVE, revoir le traitement des divulgations et automatiser la réponse aux incidents, car une découverte plus rapide entraînera davantage de tentatives contre la fenêtre entre la divulgation et le correctif. (penligent.ai)
Ces conseils sont corrects, mais il est utile de les traduire en un modèle opérationnel concret. Les changements immédiats dont les équipes de sécurité ont besoin ne sont pas mystiques. Ils sont procéduraux et mesurables.
Premièrement, il faut séparer les hypothèses des modèles des résultats vérifiés. Un modèle peut être très bon pour générer des candidats à la vulnérabilité, mais l'organisation ne devrait laisser une découverte passer à la remédiation de haute priorité que lorsqu'elle a passé une couche de vérification. En fonction de la cible, ce vérificateur peut être ASan, un harnais de régression, un reproducteur, un test d'intégration défaillant, une preuve de concept minimisée par un crash, ou une validation face à la cible dans un environnement autorisé. C'est la leçon qu'Anthropic a tirée de Firefox, et c'est l'exigence minimale pour maintenir la qualité du signal à un niveau élevé à mesure que le volume de sortie du modèle augmente. (Anthropique)
Deuxièmement, il faut passer d'un travail de sécurité basé sur le calendrier à un travail de sécurité basé sur la file d'attente. Un cycle d'examen trimestriel avait un certain sens lorsque le goulot d'étranglement était la découverte humaine. Il a moins de sens si la découverte assistée par modèle produit des résultats validés tous les jours. La bonne unité de gestion est désormais une file d'attente continuellement actualisée avec des règles de vieillissement claires, des indices d'exploitabilité, la criticité des actifs et l'état des retests. Les organisations qui considèrent encore les tests de sécurité comme un événement de livraison de rapports vont se sentir lentes, même si elles achètent les outils les plus récents. (rouge.anthropic.com)
Troisièmement, traiter les correctifs candidats comme des artefacts de première classe. L'expérience d'Anthropic avec Mozilla nous rappelle que les rapports de bogues sont beaucoup plus utiles lorsqu'ils incluent des cas de test minimaux, des PoC et des correctifs candidats. Le correctif candidat n'a pas besoin d'être fusionné à l'aveugle. Il doit exister suffisamment tôt pour que les ingénieurs puissent raisonner sur le rayon d'action et la fermeture dans la même conversation. Dans un flux de vulnérabilités à la vitesse d'une machine, le passage de "j'ai trouvé un bogue" à "j'ai un correctif plausible" doit se faire en quelques heures ou quelques jours, et non pas dans des silos organisationnels distincts sur plusieurs semaines. (Anthropique)
Quatrièmement, il faut imposer la clôture par de nouveaux tests, et non par l'optimisme. L'une des façons les plus faciles de perdre du terrain à l'ère Mythos est de livrer un correctif, de marquer un ticket comme terminé et de ne jamais réexécuter le chemin de recherche original depuis l'extérieur. Les systèmes réels ont des proxys, des passerelles, des drapeaux de fonctionnalité, des instances périmées, des pools de canaris, des travailleurs en arrière-plan et des dérives de configuration. Une différence de code n'est pas la même chose qu'une fermeture déployée. C'est à ce stade que la validation boîte noire ou boîte grise a encore de l'importance, et c'est également à ce stade que les équipes qui utilisent déjà des plateformes de validation orientées vers la cible ont un avantage. Les documents publics de Penligent, par exemple, décrivent un flux de travail agentique centré sur l'exécution contrôlée des tâches, le contrôle du champ d'application et la collecte de preuves contre des cibles réelles. Qu'une équipe utilise ou non cette plateforme exacte, l'instinct architectural est le bon : le raisonnement du modèle doit se terminer par des preuves vérifiables, et non par une prose persuasive. (penligent.ai)
Voici un exemple compact de fiche de vulnérabilité prête à l'emploi :
{
"report_id" : "AI-2026-0410-0017",
"component" : "rpcsec_gss",
"asset_class" : "kernel_nfs",
"claim_type" : "stack_overflow",
"evidence_source" : "reproducer_plus_human_validation",
"internet_exposed" : vrai,
"exploitability_state" : "publicly_described_vendor_claim",
"patch_status" : "vendor_patch_available",
"owner_team" : "platform_kernel",
"retest_required" : true,
"notes" : "Ne pas passer au niveau critique tant que les artefacts de vérification ne sont pas joints et que la fermeture du déploiement n'est pas confirmée."
}
Ce type de structure est plus important que le modèle qui a généré le texte initial. Une fois que le modèle produit des résultats significatifs, la qualité de votre schéma, de votre routage et de votre processus de validation commence à compter plus que l'élégance de l'invite. (Anthropique)
Voici un exemple simple en Python pour prioriser les découvertes générées par l'IA dans une file d'attente de correctifs. Il est intentionnellement ennuyeux, ce qui est le but. La partie la plus difficile n'est pas la mathématique de classement sophistiquée. Il s'agit de construire un processus reproductible qui reflète la pression réelle des exploits.
from dataclasses import dataclass
@dataclass
classe Finding :
component : str
internet_exposed : bool
verifier_passed : bool
patch_available : bool
privilege_boundary : bool
memory_corruption : bool
days_open : int
def priority_score(f : Finding) -> int :
score = 0
si f.internet_exposé :
score += 30
if f.verifier_passed :
score += 25
si f.patch_available :
score += 15
si f.privilege_boundary :
score += 15
if f.memory_corruption :
score += 10
si f.jours_ouverts > 7 :
score += 10
si f.days_open > 30 :
score += 10
Retourner le score
queue = [
Recherche("rpcsec_gss", Vrai, Vrai, Vrai, Vrai, Vrai, 2),
Recherche("ffmpeg_h264", Faux, Vrai, Vrai, Vrai, Vrai, 10),
Recherche("internal_auth_flow", True, False, False, True, False, 5),
]
for item in sorted(queue, key=priority_score, reverse=True) :
print(item.component, priority_score(item))
Les équipes peuvent étendre cela à la propriété de l'environnement, à la criticité de l'entreprise, aux fenêtres de gel des changements ou à la lignée des dépendances. L'idée importante est que les découvertes soutenues par des vérificateurs, exposées à l'internet et franchissant des privilèges devraient augmenter rapidement, en particulier lorsqu'un correctif existe déjà et qu'un système d'IA peut aider les autres à le transformer en arme plus rapidement qu'auparavant. (CISA)

Actions de trente, quatre-vingt-dix et cent quatre-vingts jours pour les équipes de sécurité
| Horizon temporel | Ce qu'il faut changer maintenant | Pourquoi c'est important à l'ère des "zero-day" ? |
|---|---|---|
| 30 premiers jours | Inventorier les services accessibles de l'extérieur, les services orientés vers le noyau et les analyseurs critiques ; identifier l'endroit où les résultats générés par l'IA se retrouveraient sur le plan opérationnel ; définir les exigences des vérificateurs pour les rapports hautement prioritaires. (Le projet FreeBSD) | La plupart des équipes disposent déjà d'outils. Elles ne disposent pas encore d'une boucle de routage et de validation suffisamment rapide. |
| 90 premiers jours | Ajout de champs de triage structurés, d'attentes en matière de correctifs pour les candidats et de nouveaux tests obligatoires ; renforcement des accords de niveau de service pour les correctifs concernant les problèmes de corruption de la mémoire et de chemin d'accès à l'authentification ; prédéfinition des voies d'escalade de la divulgation. (Anthropique) | La découverte assistée par l'IA augmente le volume des rapports et réduit le délai de sécurité entre la disponibilité des correctifs et l'exploitabilité. |
| 180 premiers jours | Mettre en place une revalidation continue face à la cible pour les surfaces à haut risque ; aligner les équipes AppSec, SRE et plate-forme autour d'une définition commune de la fermeture ; étendre les feuilles de route de sécurité de la mémoire là où c'est possible. (Département de la guerre des États-Unis) | La réponse durable est une boucle opérationnelle plus rapide et une réduction structurelle du code sujet aux bogues. |
La plus grande erreur que commettront les équipes est d'essayer de répondre à l'instant Mythos par du théâtre d'acquisition. L'achat d'un plan d'accès modèle ou d'un module complémentaire "IA de sécurité" ne sauvera pas une organisation dont la gouvernance des correctifs est lente, dont les propriétaires sont ambigus, dont les validateurs sont faibles et dont les preuves de déploiement sont manquantes. La deuxième plus grande erreur sera de rejeter tout cela parce que les affirmations les plus larges ne sont pas encore reproductibles de manière indépendante. C'est une norme trop stricte pour la planification opérationnelle. Lorsqu'un fournisseur a déjà publié des correctifs pour OpenBSD, FreeBSD et FFmpeg, qu'il a documenté les principaux sauts de benchmark et qu'il a modifié sa politique de publication et de divulgation autour du modèle, les défenseurs n'ont pas besoin d'une réplication publique parfaite pour justifier la modification de leurs flux de travail. (openbsd.org)
Ce que les acheteurs de produits de sécurité devraient demander après l'aperçu de Mythos
Les acheteurs techniques qui évalueront les produits de sécurité IA en 2026 devraient être beaucoup plus exigeants que la norme actuelle du marché. La première question est de savoir si la preuve la plus solide du produit provient de l'analyse visible à la source ou de la validation face à la cible. Il ne s'agit pas d'une question piège. Les deux sont précieux, mais ils répondent à des problèmes différents. Si les meilleurs exemples d'un fournisseur reposent tous sur l'accès au code local, la reconstruction de binaires dépouillés ou des harnais hors ligne, les acheteurs ne doivent pas en déduire que le produit a déjà fait ses preuves lors de tests en boîte noire dans des environnements de type production. Le dossier public d'Anthropic est une étude de cas utile qui montre à quel point il est facile de brouiller ces catégories dans les conversations marketing. (rouge.anthropic.com)
La deuxième question est de savoir quelle couche de vérificateurs existe. Les travaux d'Anthropic renvoient sans cesse aux vérificateurs : ASan, tests de régression, artefacts minimaux de reproduction, et preuve de fermeture. Un système qui peut produire de belles explications sans vérificateur fiable est au mieux un assistant de triage, et non un flux de travail de sécurité digne de confiance. Les acheteurs doivent demander à voir la piste des artefacts, et pas seulement l'écran de synthèse. (rouge.anthropic.com)
La troisième question porte sur la manière dont la plateforme gère les nouveaux tests et la clôture. La recherche de vulnérabilités sans revalidation du côté de la cible crée une dette de tickets. Sur le marché actuel, certains documents publics de Penligent sont utiles précisément parce qu'ils insistent sur la séparation entre les résultats de la boîte blanche et la preuve de la boîte noire et qu'ils font de la preuve un résultat de première classe. Les acheteurs devraient récompenser cette distinction partout où ils la trouvent. La question n'est pas de savoir si un outil "utilise l'IA". La question est de savoir s'il peut aider à faire passer une conclusion de l'hypothèse à l'exposition vérifiée et à la fermeture vérifiée. (penligent.ai)
La quatrième question est de savoir quelles sont les hypothèses du fournisseur en matière de divulgation et de charge d'exploitation. Anthropic a dû publier une politique d'exploitation coordonnée en matière de divulgation, car les découvertes générées par l'IA peuvent submerger les mainteneurs si elles sont traitées de manière irresponsable. Toute plateforme sérieuse qui prétend produire des résultats de sécurité à grande échelle devrait être en mesure d'expliquer comment elle empêche les inondations de rapports, comment elle étiquette le matériel généré par l'IA, comment les humains le valident et comment elle évite de transformer les mainteneurs en une infrastructure de triage non rémunérée. (Anthropique)
L'avant-première de Claude Mythos est une étape importante, mais pas la fin de l'histoire
La conclusion la plus nette est aussi la moins à la mode. L'avant-première de Claude Mythos est le signal public le plus fort à ce jour que la recherche sur les exploits de l'IA est entrée dans une nouvelle phase. Anthropic a publié des cas concrets de correctifs, des deltas de référence significatifs, une posture de publication à accès restreint et un cadre de divulgation conçu autour de la découverte assistée par machine. Cela suffit à justifier des changements défensifs majeurs. (rouge.anthropic.com)
Dans le même temps, le dossier public comporte encore des aspects qu'il convient de nommer honnêtement. La plupart des découvertes restent privées parce qu'elles ne sont pas corrigées. Les affirmations les plus larges concernant les navigateurs, les bogues de logique web et les cibles à source fermée ne peuvent pas encore être reproduites de manière indépendante à partir d'artefacts publics. Le cas de FreeBSD montre que même parmi les sources de haute qualité, le langage de l'impact peut diverger entre le laboratoire de découverte et l'avis du fournisseur. Ce ne sont pas des raisons pour rejeter ce moment. Ce sont des raisons de le lire attentivement. (rouge.anthropic.com)
Ce que Mythos change en premier n'est pas la question philosophique de savoir si l'IA peut pirater. Cette question est déjà obsolète. Ce qu'il change, c'est l'horloge. Il raccourcit l'intervalle entre la découverte et l'information utilisable. Elle menace de raccourcir l'intervalle entre la disponibilité des correctifs et l'exploitabilité. Elle augmente la valeur des vérificateurs, des correctifs candidats et des nouveaux tests. Le débit de divulgation et la gouvernance des correctifs font partie du périmètre de sécurité. Les équipes qui comprennent cela s'adapteront à temps. Les équipes qui attendent une preuve publique parfaite de chaque revendication y parviendront probablement encore, mais plus tard que prévu. (rouge.anthropic.com)
Lectures complémentaires et liens de référence
- Anthropique, Évaluation des capacités de cybersécurité de Claude Mythos Preview. (rouge.anthropic.com)
- Anthropique, Projet Glasswing. (Anthropique)
- Anthropique, Divulgation coordonnée des vulnérabilités découvertes par Claude. (Anthropique)
- Anthropique, Claude Mythos Aperçu du rapport sur les risquesversion publique expurgée. (Anthropique)
- Anthropique, Partenariat avec Mozilla pour améliorer la sécurité de Firefox. (Anthropique)
- OpenBSD 7.8 errata et patch 025 pour les options SACK invalides. (openbsd.org)
- Avis de sécurité FreeBSD SA-26:08.rpcsec_gss et entrée NVD pour CVE-2026-4747. (Le projet FreeBSD)
- NVD et enregistrements des fournisseurs pour le noyau Linux CVE-2024-53141. (nvd.nist.gov)
- La page de publication de FFmpeg 8.1 et l'historique 2010 H.264 refactor commit Anthropic cite. (ffmpeg.org)
- Orientations de la NSA et de la CISA sur les feuilles de route et les langages à sécurité mémoire. (Département de la guerre des États-Unis)
- Penligent, L'aperçu de Claude Mythos n'est pas un pentesting en boîte noire. (penligent.ai)
- Penligent, Sécurité du code Claude et négligence : Des conclusions de la boîte blanche à la preuve de la boîte noire. (penligent.ai)
- Page d'accueil négligente. (penligent.ai)

