Most arguments about AI security tooling fail before they start. They collapse several different jobs into one vague category called “security testing,” then compare tools that were built to answer different questions. A repository-aware code reviewer, a SAST engine, and an external penetration testing workflow do not produce the same kind of truth. They look at different evidence, run at different stages of the lifecycle, and fail in different ways. That matters even more now that OpenAI is pushing Codex beyond code generation and into code review, GitHub review workflows, and an application security mode that builds a project-specific threat model, validates findings, and proposes patches. (OpenAI)
The most useful way to evaluate Codex in security work is not to ask whether it is “good at pentesting.” That framing is too blunt to be useful. A better question is this: what part of the security workflow becomes stronger when an AI system can see the repository, the pull request, the surrounding code, the expected system behavior, and the change history? The answer is white-box review. When the problem starts inside the repo, Codex has real leverage. When the question is whether an external attacker can reach, chain, and prove impact against the deployed system, the answer still lives in black-box validation. NIST SP 800-115 makes almost exactly that distinction: white-box techniques tend to be more efficient and cost-effective for finding security defects in custom applications, while black-box techniques are best used to assess compiled components, interactions between components, and interactions with the external environment. (nvlpubs.nist.gov)
That distinction is not academic. It shapes which findings you trust, how you prioritize remediation, and whether your security team spends its time fixing theoretical issues or closing verified risk. Codex, especially in its current security positioning, is increasingly a tool for context-rich internal review. Black-box pentesting remains the discipline that settles exploit reality. Mature teams need both, but they should not expect them to do the same work. (OpenAI)
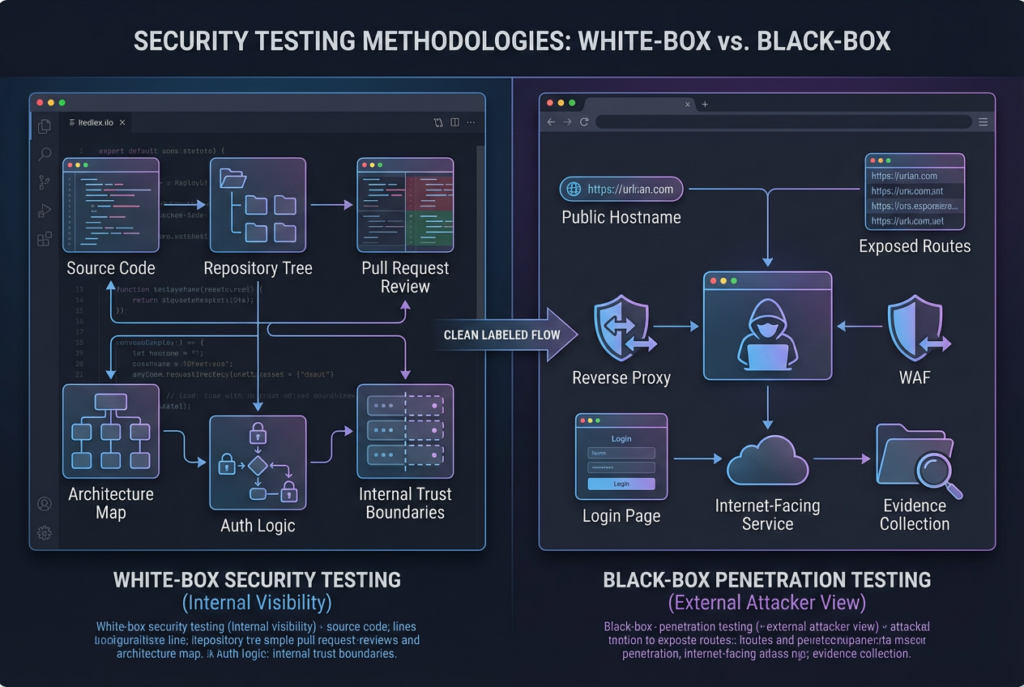
White-Box Security Testing and Black-Box Penetration Testing Answer Different Questions
White-box testing starts from internal knowledge. NIST’s glossary defines white-box testing as a methodology that assumes explicit and substantial knowledge of the internal structure and implementation details of the assessment object. OWASP’s testing guidance makes the same practical point from the application side: source code analysis removes much of the guesswork that black-box testing has to live with, and many significant security problems are difficult to discover through penetration testing alone. In other words, white-box testing is not simply “more detailed testing.” It is testing that begins with visibility into how the system is supposed to work. (csrc.nist.gov)
Black-box testing starts from the opposite premise. The tester does not begin with the source tree, the internal trust model, or the exact control flow. The tester begins with a reachable system, a boundary, an attack surface, and a limited view of what the target exposes. OWASP’s Web Security Testing Guide positions testing as a practical framework for web applications and services, while NIST frames black-box work as especially useful for assessing high-risk compiled components, interactions between components, and interactions with the external environment. That is why black-box testing feels closer to real adversary pressure. It answers whether the system, as deployed, can actually be reached, prodded, misused, and broken under realistic conditions. (Fondation OWASP)
These two testing styles overlap, but they are not interchangeable. White-box review is unusually good at spotting logic flaws, authorization gaps, dangerous defaults, insecure trust assumptions, dead code paths that bypass protections, and fix regressions that are visible in a diff but not yet externally reachable. Black-box testing is unusually good at spotting exposure drift, reverse-proxy mistakes, routing errors, forgotten endpoints, bad TLS termination, authentication breakage at the boundary, and exploitation conditions created by deployment rather than source alone. That is why the most practical enterprise model is almost never “pick one.” It is sequence them. Use internal visibility to find deeper defects earlier, then use external validation to learn which of those defects can be turned into real-world impact. (nvlpubs.nist.gov)
The table below is a better starting point than a generic “tool comparison,” because it focuses on what each method is meant to answer.
| Question | White-box security review | Black-box penetration testing |
|---|---|---|
| What evidence do you start with | Source code, PR diffs, repository history, architecture context, trusted-service assumptions | Reachable assets, exposed interfaces, observed responses, deployment behavior |
| Best at finding | Logic flaws, authorization mistakes, insecure defaults, trust boundary mistakes, risky code changes | Internet exposure, deploy drift, proxy and routing errors, boundary auth failures, exploitability |
| Main strength | Precision about how the system works | Realism about how the system behaves from outside |
| Main weakness | May not prove external reachability or real exploitability in the deployed environment | May miss deep internal logic flaws or hidden unsafe paths without source visibility |
| Best stage in lifecycle | Before merge, during refactors, during secure design review, during remediation | Pre-release validation, internet-facing assessment, retest after fixes, production exposure checks |
The point is not that white-box is “better” or black-box is “more realistic.” The point is that each one produces a different kind of security evidence. Teams that confuse those evidence types usually end up with the wrong workflow, the wrong success criteria, and the wrong expectations for AI tools. (nvlpubs.nist.gov)
Why Codex Fits the White-Box Side So Well
Codex is not just a code generator anymore. OpenAI’s recent product and developer documentation show a much broader workspace: Codex can review pull requests inside GitHub, respond to @codex review, automatically surface regressions and missing tests on pull requests, and use repository-specific guidance from AGENTS.md. The desktop app now also supports reviewing PRs, multiple terminal tabs, multiple files, remote devboxes over SSH, and an in-app browser for local or public pages that do not require sign-in. On top of that, OpenAI launched Codex Security in research preview as an application security agent that builds a project-specific threat model, validates findings, and proposes patches with system intent in mind. Taken together, that is a white-box stack. It is built around repository context, review context, and system context. (Développeurs OpenAI)
That matters because security review quality depends heavily on context. A traditional scanner may know that a particular call is dangerous. A human reviewer may know that the code change is touching an authentication path. A repository-aware AI reviewer can often combine both levels of information. It can read the diff, look at surrounding files, inspect the helper functions that the diff did not touch, compare the route protection pattern in other modules, and reason about whether the new change violates the project’s own design intent. OpenAI’s description of Codex Security is explicit on this point: it builds system context, creates an editable threat model, uses that threat model to prioritize and validate issues, and proposes fixes that align with system intent and surrounding behavior. That is not the language of a generic scanner. It is the language of context-aware review. (OpenAI)
Codex also benefits from living inside real development surfaces. GitHub review support means teams can ask for security-focused review directly in a pull request, and OpenAI’s own examples emphasize security regressions, missing tests, and risky behavior changes. AGENTS.md guidance lets teams steer reviews toward their own security invariants, such as “verify that authentication middleware wraps every route” or “treat PII logging as a priority failure.” That is a practical bridge between AI review and organization-specific security policy. It also means Codex can become more useful as the codebase gets larger and the implicit rules get harder for humans to keep in short-term memory. (Développeurs OpenAI)
The desktop and app features reinforce the same pattern. The in-app browser can preview and comment on local development servers and unsigned public pages, which is useful for front-end review and local validation, but it explicitly does not support authentication flows, signed-in pages, regular browser profiles, cookies, extensions, or existing tabs. Computer use can operate macOS apps by seeing, clicking, and typing, which is useful for reproducing GUI-only bugs and checking app flows, but that is still different from continuous, external, environment-driven attack-surface validation. Those are useful features, but they do not erase the fact that Codex remains strongest where it can anchor itself to code and controlled project context. (Développeurs OpenAI)
Codex Security’s own public positioning makes the white-box case even stronger. OpenAI says it is designed to operate at scale, surface higher-confidence findings, and reduce triage noise by grounding discovery, validation, and patching in system-specific context. OpenAI also says it reported critical vulnerabilities to widely used open-source projects including OpenSSH, GnuTLS, GOGS, Thorium, libssh, PHP, and Chromium, with fourteen CVEs assigned at the time of announcement. Whether or not one views those numbers as a reason for adoption, they show how OpenAI wants the market to understand Codex Security: as a repo-aware application security reviewer that can find subtle issues in real code, not as a black-box external attack platform. (OpenAI)
That positioning is why Codex makes sense in white-box code auditing. Its ideal input is not “a target hostname on the public internet.” Its ideal input is a repository, a diff, a buildable project, a set of review criteria, and a security question. The more of the system it can see, the more useful it becomes. That is exactly the opposite of black-box pentesting, where the interesting part is what the tester cannot see and has to prove anyway. (OpenAI)
What White-Box AI Can See That External Testing Often Misses
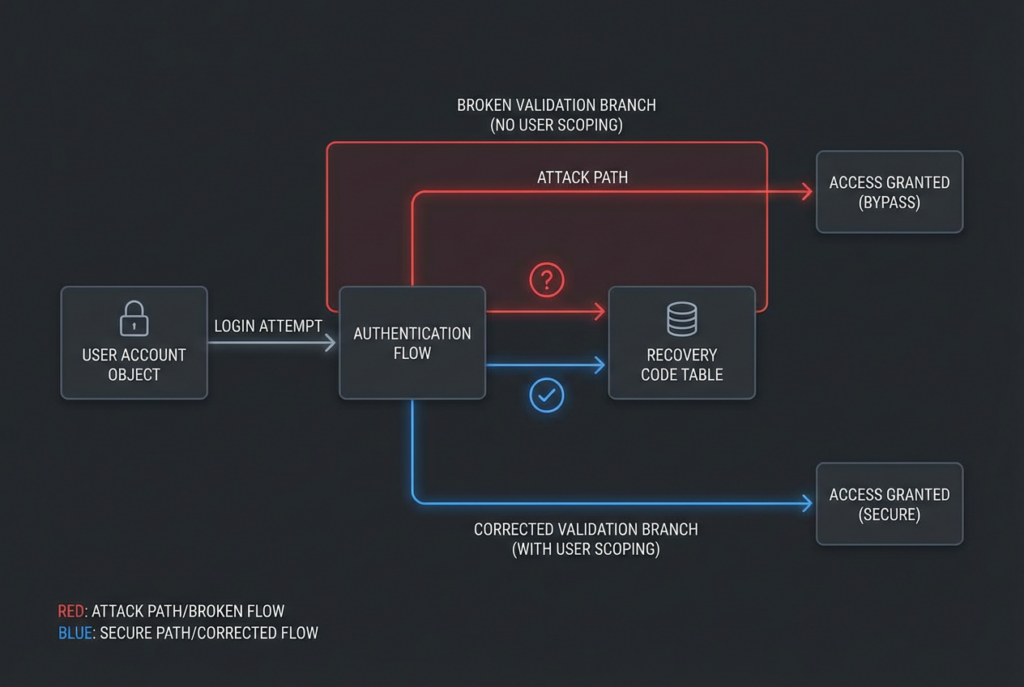
The strongest case for Codex in security is not that it magically finds every vulnerability. It is that certain categories of defects become much easier to reason about when the reviewer can see the repository, the surrounding code, and the intended workflow. The most obvious category is authorization and identity logic. External testing can sometimes detect broken access control, but it often needs a very specific reproduction path, a reachable workflow, and enough observability to tell what happened. In source, the shape of the bug can be plain: a recovery code lookup that is not scoped to the current user, a session token that is not rotated after password change, a route that depends on middleware that is missing in one subrouter, or a fallback path that silently skips a permission check. Those are exactly the kinds of issues where “read the code like a suspicious teammate” is more productive than “scan the perimeter and hope the symptom leaks out.” (GitHub)
A clean real-world example is CVE-2025-64175 in Gogs. NVD describes the issue as a 2FA recovery code validation flaw: in affected versions, recovery codes were not scoped by user, so an attacker who already knew a victim’s username and password could use any unused recovery code, including one from another account, to bypass the victim’s two-factor authentication. That is a genuine account takeover path and it makes 2FA ineffective, but it is also the kind of bug that becomes much easier to spot when you can inspect the recovery-code validation logic directly. The issue is not merely “2FA failed in practice.” The issue is that the code modeled recovery codes as valid without binding them tightly to the right principal. (NVD)
A simplified version of that class of mistake looks like this:
def verify_recovery_code(input_code: str) -> bool:
# flawed example
return db.exists(
"SELECT 1 FROM recovery_codes WHERE code = ? AND used = false",
[input_code],
)
def login_with_recovery_code(username: str, password: str, input_code: str) -> bool:
if not verify_password(username, password):
return False
if not verify_recovery_code(input_code):
return False
mark_code_used(input_code)
create_session(username)
return True
The bug is not hidden in a fancy exploit chain. It is hidden in a missing relationship. The recovery code is treated as globally valid rather than valid for one specific user. An external tester may eventually prove the bypass if the flow is reachable and the app leaks enough behavior to support careful testing. A white-box reviewer can often spot the broken trust boundary immediately, because the logic contradicts the intended security model. The code is asserting “a valid code is enough” where the system needs “a valid code for this user is enough.” (NVD)
A fix has to encode the security relationship explicitly:
def verify_recovery_code(user_id: int, input_code: str) -> bool:
return db.exists(
"""
SELECT 1
FROM recovery_codes
WHERE user_id = ?
AND code = ?
AND used = false
""",
[user_id, input_code],
)
def login_with_recovery_code(username: str, password: str, input_code: str) -> bool:
user = get_user_by_username(username)
if not user or not verify_password(username, password):
return False
if not verify_recovery_code(user.id, input_code):
return False
mark_code_used_for_user(user.id, input_code)
rotate_session(user.id)
create_session(user.username)
return True
That pattern is exactly where Codex-style review can add value. A repository-aware reviewer can compare how other scoped secrets are handled, check whether sessions rotate on sensitive state changes, and flag the mismatch between the intended identity model and the actual query shape. It is a better fit for this class of problem than external-only testing because the bug is fundamentally semantic. (NVD)
Another class of issue where white-box review shines is trust and transport validation. OpenAI’s appendix for Codex Security includes CVE-2025-35434, where CISA Thorium did not validate TLS certificates when connecting to Elasticsearch. NVD says an unauthenticated attacker with access to a Thorium cluster could impersonate the Elasticsearch service, and the issue was fixed in version 1.1.2. This is the kind of flaw that often looks boring in source but catastrophic in context. A single verify=False, a disabled certificate check, or an insecure client constructor can quietly destroy the authenticity guarantee that the whole connection depends on. The code usually tells the story faster than the perimeter does. (NVD)
A minimal form of the same mistake looks like this:
from elasticsearch import Elasticsearch
es = Elasticsearch(
["https://es-internal.example"],
verify_certs=False,
)
An external tester may not be able to prove this kind of defect at all unless they already have foothold conditions close to the cluster or a way to impersonate the service. A white-box reviewer, by contrast, can flag it the moment it appears in a diff, because the logic of the failure is self-contained. This is one reason white-box review is so valuable before merge and during remediation. It catches security debt when it is still one line of code rather than an incident response problem. (NVD)
A third category is unsafe defaults and dangerous public endpoints. OpenAI’s Codex Security appendix also references CVE-2026-25242 in Gogs. NVD describes the issue as unauthenticated file upload exposure: affected versions exposed upload endpoints by default when RequireSigninView was disabled, allowing remote users to upload arbitrary files to the server through release and issue attachment routes. The practical risk was not only disk exhaustion. The instance could also be abused as a public file host or for malware delivery. This is a perfect example of a defect class that spans both white-box and black-box thinking. In source, you can see the missing authorization assumption. In deployment, you need to know whether the instance is reachable and whether the default is actually in place. (NVD)
A code-aware AI reviewer is useful here because it can reason about the relationship between configuration defaults and route exposure. A black-box tester is useful because the route may still be blocked upstream, hidden behind auth, or only reachable on internal networks. This is why a serious workflow should resist false binaries. White-box review can tell you the repo contains a dangerous exposure pattern. Black-box testing can tell you whether the dangerous pattern has become a reachable issue in your environment. (NVD)
The broader pattern is that white-box AI is strongest on bugs whose exploitability depends on system semantics rather than on raw edge exposure alone. Authorization boundaries, cross-account state mixups, trust assumptions between services, logic around recovery paths, dangerous feature defaults, and remediation regressions all benefit from a reviewer that can read code and reason across multiple files. That does not make Codex omniscient. It makes it useful where code understanding is the limiting factor. (OpenAI)
Codex Is Not a Replacement for Deterministic SAST
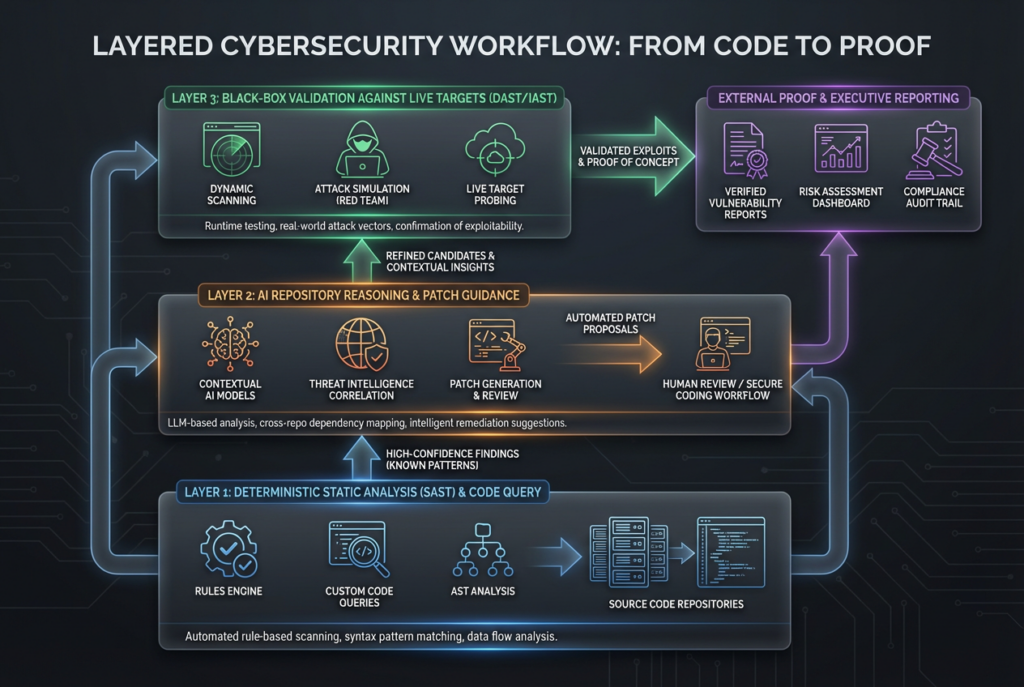
One of the easiest mistakes in 2026 is to look at a powerful AI reviewer and conclude that the old tooling stack no longer matters. That is the wrong lesson. GitHub’s CodeQL documentation is explicit about how CodeQL works: it represents the codebase as a CodeQL database, runs queries against that database, and surfaces results as code scanning alerts. Semgrep’s documentation is equally explicit that Semgrep Code uses rules that encapsulate pattern matching logic and data-flow analysis to scan code for security issues, and its dataflow documentation emphasizes traceability of tainted input through sources and sinks. Those properties matter because they make the system repeatable. They let you encode a baseline, run it in CI, and know that next week’s execution will be governed by the same rules. (Docs GitHub)
Codex does something different. It reads, reasons, prioritizes, explains, and proposes fixes. That is powerful, especially for issues that sit above simple pattern matching. But it is not the same as a rules engine. If a team replaces its deterministic layer with a pure AI review layer, it usually gives up exactly the properties that make a security program operational at scale: reproducibility, policy encoding, gateable checks, and explicit ownership of what the system is supposed to flag every time. The smarter move is to treat Codex as a reasoning and remediation layer that sits above a deterministic baseline, not in place of it. (Docs GitHub)
That layered model is easy to understand in practice. Let CodeQL or Semgrep do the jobs they are designed for: enforce repeatable guardrails around dangerous APIs, route protection patterns, obvious secret leaks, query construction, insecure crypto use, and framework-specific anti-patterns. Then let Codex do the jobs that rules alone struggle with: explaining whether a code change meaningfully weakens an authorization model, inspecting the neighboring code that the diff did not touch, reasoning about whether a patch matches system intent, or proposing a safer remediation that will not create a regression somewhere else. (Docs GitHub)
A tiny Semgrep rule illustrates what the deterministic layer is good at:
rules:
- id: python-requests-no-tls-verify
message: Do not disable TLS certificate verification in requests
languages: [python]
severity: ERROR
patterns:
- pattern: requests.$METHOD(..., verify=False, ...)
That rule cannot understand all the surrounding security intent in your system. It does not know whether the code is in a test helper, a one-off local fixture, or a critical production path. But it does one thing extremely well: it gives you a repeatable signal about a known-dangerous pattern. A Codex reviewer can then decide whether the hit matters, whether the surrounding context changes the severity, whether a better remediation exists, and whether similar patterns appear elsewhere in the same codebase. That combination is stronger than either layer alone. (semgrep.dev)
The comparison below is more useful than vendor-versus-vendor comparisons because it maps tools to jobs.
| Couche | Best use | Main advantage | Main limit |
|---|---|---|---|
| CodeQL | Query-driven code scanning over a structured database of the codebase | Highly repeatable, good for enforceable policy and CI gating | Less flexible on system-specific reasoning without tailored queries |
| Semgrep | Rule-driven SAST with pattern matching and data-flow analysis | Fast to operationalize, strong for framework-specific and policy rules | Still bounded by the quality of rules and analysis scope |
| Codex and Codex Security | Repo-aware review, threat-model-informed reasoning, patch suggestions | Strong on context, semantics, remediation, and review conversations | Not a substitute for deterministic baseline or external validation |
| Black-box validation | Exposure testing, attack-surface verification, exploit reality | Strong on real reachability and deployed behavior | Cannot reliably see deep internal logic without source or context |
This is also where security buyers often get tripped up. They look for one “best AI security tool” when the right architecture is layered by design. Use rules for what should always be checked. Use AI reasoning for what needs context and judgment. Use black-box validation for what must be proven from outside. That is not indecision. It is how you keep signal high without fooling yourself about what has and has not been verified. (Docs GitHub)
What Codex Still Cannot Settle by Itself
Even the strongest white-box reviewer cannot answer every question that matters in a deployed system. That is not a flaw in Codex specifically. It is a structural limit of white-box review. Source visibility tells you what the code intends to do and what paths exist in principle. It does not, by itself, prove that those paths are externally reachable through the deployed boundary stack, reachable in the current environment, or reachable after the messiness of proxies, caches, feature flags, service mesh policies, browser quirks, and identity provider behavior gets involved. NIST’s guidance is useful here again: black-box methods should be used to assess interactions between components and the interaction of the application with its external environment. (nvlpubs.nist.gov)
Codex’s own public feature boundaries reinforce the same point. The in-app browser is useful for previewing local development servers and unsigned public pages, but it does not support authentication flows, signed-in pages, your regular browser profile, cookies, extensions, or existing tabs. That means it is useful for local web iteration and some UI review, not for faithfully reproducing the full browser state that many externally reachable bugs depend on. Computer use on macOS is useful for GUI-only bugs and app flows, but that is still a local control surface, not a distributed external validation system. These are good features. They are just not the same thing as an evidence-first black-box workflow against a live target surface. (Développeurs OpenAI)
Codex Security is also, by OpenAI’s own description, still in research preview. That does not mean it lacks value. It means a serious reader should treat it as promising infrastructure that is still maturing rather than as a completed replacement for the rest of the AppSec stack. OpenAI’s write-up emphasizes high-confidence findings, validated findings, and easy-to-accept patches, which is exactly the right focus. But it is still an application security agent grounded in project context. It is not marketed as a public attack-surface validation platform, and that distinction should stay intact in any technical comparison. (OpenAI)
There is also a human factor that matters. White-box AI can review what you give it. If the sensitive path lives in a forgotten private repository, in a deployment template never committed to the same tree, in an environment variable set by an operator six months ago, or in a gateway rule applied outside the application repo, then the AI reviewer’s worldview is incomplete. Sometimes incomplete review is still enough to catch the defect. Often it is not enough to prove that the defect matters in your actual environment. That is exactly where black-box work becomes the final judge rather than a nice-to-have second opinion. (nvlpubs.nist.gov)
Why Black-Box Pentesting Still Decides Real Risk
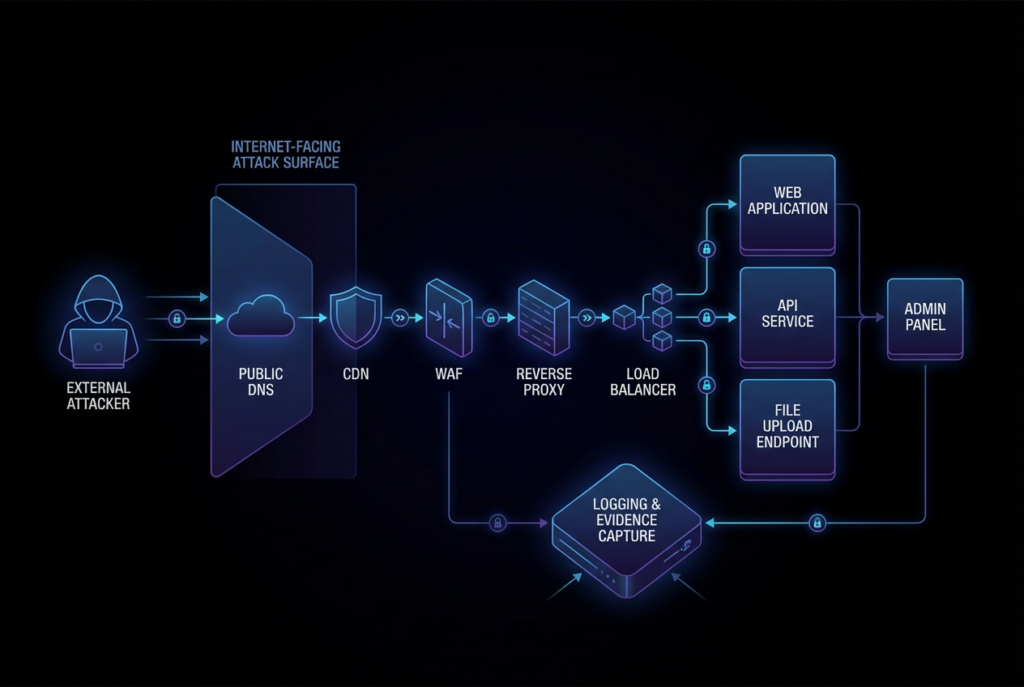
External verification remains the moment of truth because risk is not just a property of source code. It is also a property of exposure, routing, configuration, asset sprawl, protocol handling, and the way a system behaves once it is assembled. A codebase can look secure and still be exploitable because a dangerous feature is enabled in one forgotten edge service. A repository can contain a known-bad path that is not reachable anywhere meaningful in production. White-box review tells you what the internal machinery can do. Black-box testing tells you what an attacker can make it do from where they actually stand. (nvlpubs.nist.gov)
A strong example is CVE-2024-3400 in Palo Alto Networks PAN-OS GlobalProtect. NVD describes it as a command injection vulnerability arising from arbitrary file creation in the GlobalProtect feature, allowing an unauthenticated attacker to execute arbitrary code with root privileges on affected firewalls. Palo Alto’s advisory says Cloud NGFW, Panorama appliances, and Prisma Access were not impacted, which immediately shows why deployment context matters. The bug was not simply “a PAN-OS issue.” It was a bug in particular versions with particular feature configurations and an externally reachable role. CISA later tracked the vulnerability in the Known Exploited Vulnerabilities catalog, and public government advisories noted observed exploitation. That is black-box reality: the critical question is not just that the code path exists, but whether the right exposed service is live in your environment under exploitable conditions. (NVD)
Another strong example is CVE-2024-4577 in PHP-CGI on Windows. NVD says affected PHP versions on Apache and PHP-CGI on Windows, under certain code pages, could misinterpret characters as PHP options due to Windows “Best-Fit” behavior, allowing arbitrary PHP code execution and even source disclosure. PHP’s own changelog shows the fix landed in versions 8.1.29, 8.2.20, and 8.3.8, but the issue later saw a bypass tracked as CVE-2024-8926 in later PHP releases, which is a useful reminder that patch state, deployment mode, and edge conditions matter as much as the original root cause. The actual risk lived at the intersection of platform, SAPI mode, locale behavior, and reachable web exposure. That is not a question source review alone can settle. (NVD)
These examples explain why external validation remains indispensable even for teams with excellent source access. It is the only place you see the full shape of the running system: the domains that resolve today, the ports that are actually open, the routes that the gateway exposes, the headers the reverse proxy injects, the authentication flows the browser really executes, the WAF behaviors that break or fail open, and the shadow assets that never made it into the architecture diagram. None of that is reliably inferable from application code alone. (Fondation OWASP)
This is also why the “just ask the AI to pentest it” pitch so often disappoints practitioners. Pentesting is not simply a reasoning problem. It is a stateful, environment-dependent, evidence-driven process. The useful question is not whether an AI system can describe attack ideas. The useful question is whether it can move from reconnaissance to validation to reproducible proof without losing context. Penligent’s public product and pricing pages are relevant here because they describe exactly that type of workflow: end-to-end AI pentesting from asset discovery to validation, automated asset profiling and attack-surface mapping, baseline probing, one-click exploit reproduction, on-demand access to 200-plus pentest tools, and exportable reports with evidence and reproduction steps. Those claims are directly aligned with the operational gap that white-box review does not close on its own. (Penligent)
The important part is not the brand name. The important part is the workflow shape. A useful black-box platform has to do more than summarize scanner output. It has to help teams understand what is exposed, what is reachable, what changed, what was reproducible, and what evidence exists after retesting. Penligent’s own technical writing on AI pentest tooling and evidence-backed reporting makes the same distinction: the hard part is not writing a PDF, but turning raw signal into attack paths, reproducible validation, and evidence another engineer can verify. That is a much better way to think about black-box value than “AI did the pentest for me.” (Penligent)
There is a practical workflow consequence here. If Codex flags a likely auth regression in a pull request, that is valuable and often urgent. But until someone tests the reachable login flow in the deployed environment, validates whether the edge behavior preserves the vulnerable path, and records reproducible evidence, the team still lacks one kind of truth. The white-box truth is “this design or diff is dangerous.” The black-box truth is “this dangerous design is externally reachable and reproducible in this environment.” Real security decisions usually need both. (OpenAI)
Building a Workflow That Uses Both Without Confusing Them
The most mature workflow is not Codex versus black-box pentesting. It is Codex before deployment, deterministic checks throughout delivery, and black-box proof before and after release. That gives you three different evidence layers instead of one brittle source of confidence. The first layer is repository-aware review. The second is repeatable policy enforcement. The third is external validation. Most teams that think they need “better AI security” actually need this sequencing more than they need a smarter model. (Docs GitHub)
A practical starting point is to define review guidance that makes Codex useful for your real risk profile rather than for generic code hygiene. OpenAI’s GitHub integration explicitly supports review guidance through AGENTS.md. That makes it easy to turn organizational security expectations into persistent prompts that travel with the repo. A minimal version might look like this:
## Review guidelines
- Treat authentication, authorization, session, and recovery-flow changes as high priority.
- Flag any route change that weakens middleware coverage or moves checks from server to client.
- Flag any use of disabled TLS verification, insecure redirect handling, or trust of unsigned callbacks.
- Escalate dangerous defaults, anonymous upload paths, or changes that broaden unauthenticated access.
- For security findings, explain exploit preconditions and suggest the smallest safe remediation.
This kind of repository-local policy does not replace security engineering judgment. It makes that judgment more repeatable across pull requests. It also pushes Codex toward the exact surfaces where white-box review is most valuable: auth, trust, defaults, and boundary assumptions. (Développeurs OpenAI)
The next layer is deterministic policy. Keep CodeQL or Semgrep in CI for invariant checks that should never depend on a model’s interpretation of prose. Good candidates include unsafe redirect construction, known-bad crypto usage, dangerous framework settings, raw SQL patterns, deserialization hotspots, and prohibited APIs. This is not because rules are smarter than AI. It is because a rule that runs every time is better than a reminder that depends on whoever happened to ask for a review. (Docs GitHub)
Then comes pre-release black-box verification. This is the stage where you test whether the risks identified from the inside survive contact with the actual deployment boundary. On a staging or pre-production target that you are authorized to test, the questions are concrete. Is the route externally reachable? Does the reverse proxy preserve the risky header behavior? Is the auth flow really bypassable end to end? Did the fix change the external behavior or only the code path that looked suspicious? Those are black-box questions, and they should be answered with reproducible steps and retained evidence rather than with intuition. (nvlpubs.nist.gov)
A safe, authorization-bound verification scaffold might look like this:
#!/usr/bin/env bash
set -euo pipefail
TARGET="${1:?usage: ./verify.sh https://staging.example.com}"
echo "[*] Baseline headers"
curl -skI "$TARGET" | tee headers.txt
echo "[*] Reachability checks for documented routes"
while read -r path; do
code=$(curl -sk -o /dev/null -w "%{http_code}" "${TARGET}${path}")
printf "%-40s %s\n" "$path" "$code"
done <<'EOF' | tee route-status.txt
/login
/logout
/account/recovery
/issues/attachments
/releases/attachments
EOF
echo "[*] TLS certificate and protocol summary"
openssl s_client -connect "$(echo "$TARGET" | sed 's#https://##; s#/.*##')":443 -brief </dev/null 2>/dev/null | tee tls.txt
echo "[*] Save artifacts for retest diffing"
tar czf verification-artifacts.tgz headers.txt route-status.txt tls.txt
This is not an exploit script. It is a disciplined way to collect evidence about boundary behavior, route reachability, and protocol state before and after a fix. That distinction matters. Good black-box work is not only about breaking things. It is also about proving what changed, what remained exposed, and what a teammate can reproduce tomorrow. (Penligent)
Once teams begin to work this way, the roles become clearer. Codex is the strongest reviewer when the signal lives in the code. A black-box workflow is the strongest validator when the signal has to be proven against the running system. The engineering outcome is better too. Developers get a concrete explanation of why the code was dangerous. Security engineers get externally verifiable proof of what was reachable. Managers get fewer arguments about whether a finding was “just theoretical.” (OpenAI)
Common Failure Modes in AI Security Workflows
The first common mistake is treating AI code review as if it were penetration testing. It is not. If the AI is looking at the diff, the repository, and a local project context, you are doing white-box work even if the interface feels interactive and dynamic. That is fine. White-box work is valuable. It only becomes a problem when teams mistake it for external validation and start reporting code-level suspicion as if it were verified exploitability. (OpenAI)
The second mistake is discarding deterministic tools too early. A team gets excited about a strong AI reviewer, sees a few good catches, and then concludes that query-based or rule-based tooling is obsolete. Usually the result is a weaker program, not a stronger one. The team loses repeatable gates, explicit policy, and reliable regression coverage, then discovers that the AI review process depends too much on who asked the right question at the right time. Codex becomes much more valuable when it sits on top of CodeQL or Semgrep than when it is forced to pretend it is both reviewer and baseline. (Docs GitHub)
The third mistake is shipping fixes without external retesting. This happens constantly. A code review catches the bug, an engineer patches the line, everyone feels good, and nobody checks whether the vulnerable behavior still exists through a different path, a stale instance, a legacy subdomain, or a proxy layer that preserves the old behavior. That is how organizations end up with “fixed in code, still reachable in production.” It is also why evidence-preserving black-box retests are more important than security teams often admit. (nvlpubs.nist.gov)
The fourth mistake is trusting narrow success metrics. If the metric is “did the AI flag a bug,” teams will optimize for volume and novelty. If the metric is “did the external test prove impact,” teams will often underinvest in the internal work that would have caught the bug earlier and made the fix cleaner. A mature program needs both measurements. How many meaningful issues were caught before merge? How many externally reachable issues survived to deployment? How many fixes held up under retest? Those are healthier metrics than “which model found the coolest bug.” (OpenAI)
The fifth mistake is confusing explanation with evidence. AI systems are very good at explanation. They can produce elegant summaries, plausible exploit narratives, and patch suggestions that sound authoritative. None of that is the same thing as evidence. Evidence is a verified code path, a validated finding, a reproducible test, a retained artifact, or an externally observable effect. Codex Security’s public language is actually instructive here because it emphasizes validated findings and, where possible, sandboxed validation environments. The right move is not to trust the explanation more. It is to insist that explanation and evidence stay connected. (OpenAI)
The Right Way to Compare Codex, SAST, and Black-Box Platforms
A better comparison framework starts with the question each tool answers. CodeQL asks, in effect, “does the codebase match a query that represents a security problem?” Semgrep asks, “does the code match a risky pattern, and in some cases a data-flow path, described by a rule?” Codex asks, “given this repo, diff, and system context, what looks dangerous, why, and how should it be fixed?” A black-box platform asks, “what can an attacker reach from here, what can be validated, and what proof exists?” Once you see those as separate questions, the tooling story stops feeling confusing. (Docs GitHub)
Codex’s comparative advantage is strongest when the repo itself is the bottleneck. Large codebases, subtle authorization logic, changing security invariants across teams, risky PRs touching auth or transport behavior, and patches that need review context are all good candidates. It is also strong when security teams need help turning raw findings into reviewable patches rather than simply generating more alerts. OpenAI’s own positioning around threat models, validation, and fix suggestions supports exactly that interpretation. (OpenAI)
Traditional SAST’s comparative advantage is strongest when you need a repeatable safety rail that does not depend on conversational steering. If your program wants to enforce “never disable TLS verification in production code,” “never merge known-dangerous framework settings,” or “always flag raw query construction in this service,” rules and queries are the right substrate. That is not because they are more sophisticated. It is because they are explicit. Explicit detection logic is easier to test, govern, and run continuously. (Docs GitHub)
A black-box platform’s comparative advantage is strongest when the main uncertainty is not what the code says, but what the boundary exposes today. Internet-facing estates, fast-moving cloud environments, shadow assets, authenticated web applications, routing drift, real exploit reproduction, and evidence-first retesting all fall here. Penligent’s own product pages and related technical articles are useful internal links for this topic because they are built around that operational reality: asset discovery, validation, attack-surface mapping, tool orchestration, exploit reproduction, and evidence-backed reports. That is the right shape for black-box AI if the goal is proof rather than polished narration. (Penligent)
The result is not a winner-take-all ranking. It is a workflow map. Codex belongs where security starts in the repository. Rules engines belong where policy must run every time. Black-box validation belongs where risk has to be proven from outside. Teams that align tools to those jobs will get more signal, less noise, and less internal debate about what has actually been confirmed. (Docs GitHub)
Conclusion
Codex is increasingly well positioned for white-box security work. The public GitHub review features, repository guidance model, desktop workflow support, and Codex Security threat-model-and-patching flow all point in the same direction: it is most powerful when it can see the code, the change, and the system context. That makes it valuable for code auditing, especially where the hard bugs live in authorization logic, trust assumptions, unsafe defaults, and remediation quality rather than in simple pattern matches. (Développeurs OpenAI)
Black-box penetration testing still settles the question that organizations ultimately care about: what is reachable, what is exploitable, and what proof can another engineer reproduce against the deployed system. CVE-2024-3400 and CVE-2024-4577 are good reminders that deployment conditions and edge exposure can turn a code-level problem into an operational crisis. That is why external validation remains the final court of appeal. (NVD)
The best workflow is not to force one tool to impersonate all the others. Use Codex where repository context creates leverage. Keep deterministic SAST where repeatable policy matters. Use black-box validation where the system has to prove itself from the outside. When those layers work together, the security story gets much stronger: fewer speculative findings, better fixes, cleaner retests, and evidence that survives contact with real engineering teams. (Docs GitHub)
Further Reading and Reference Links
- OpenAI, Codex Security: now in research preview. (OpenAI)
- OpenAI, Codex for almost everything. (OpenAI)
- OpenAI Developers, Use Codex in GitHub. (Développeurs OpenAI)
- OpenAI Developers, Review pull requests faster. (Développeurs OpenAI)
- NIST SP 800-115, Guide technique pour les tests et l'évaluation de la sécurité de l'information. (nvlpubs.nist.gov)
- OWASP, Web Security Testing Guide. (Fondation OWASP)
- GitHub Docs, About code scanning with CodeQL. (Docs GitHub)
- Semgrep Docs, Semgrep Code overview. (semgrep.dev)
- NVD, CVE-2024-3400. (NVD)
- Palo Alto Networks, CVE-2024-3400 advisory. (security.paloaltonetworks.com)
- CISA, Known Exploited Vulnerabilities Catalog. (cisa.gov)
- NVD, CVE-2024-4577. (NVD)
- PHP, PHP 8 changelog. (php.net)
- NVD, CVE-2025-64175. (NVD)
- NVD, CVE-2025-35434. (NVD)
- NVD, CVE-2026-25242. (NVD)
- Page d'accueil négligente. (Penligent)
- Penligent pricing, with end-to-end AI pentesting, attack-surface mapping, tool access, and evidence export details. (Penligent)
- Penligent, Présentation de l'outil de test de pénétration automatisé de Penligent.ai. (Penligent)
- Penligent, AI Pentest Tool, ce à quoi ressemble une véritable attaque automatisée en 2026. (Penligent)
- Penligent, Comment obtenir un rapport de pentest sur l'IA. (Penligent)
