CVE-2026-43284 is the xfrm ESP half of Dirty Frag, a Linux kernel local privilege escalation chain that turns low-privileged local code execution into root by abusing page-cache-backed packet fragments. It is not a remote code execution bug by itself. It becomes dangerous after an attacker already has a shell, a web-shell execution path, a compromised service account, a container workload, or some other way to run code as a non-root user on a Linux host.
That distinction matters. Many teams still triage “local” vulnerabilities as secondary problems. Dirty Frag is a reminder that local privilege escalation is often the step that turns an intrusion from “one weak account” into “full host control.” Microsoft’s Dirty Frag research describes the vulnerability as a post-compromise escalation path involving esp4, esp6, and rxrpc, and says public proof-of-concept activity indicates a more reliable path than many race-condition-driven Linux LPEs. Microsoft also reported limited in-the-wild activity where privilege escalation involving su was observed, potentially related to Dirty Frag or Copy Fail behavior. (Microsoft)
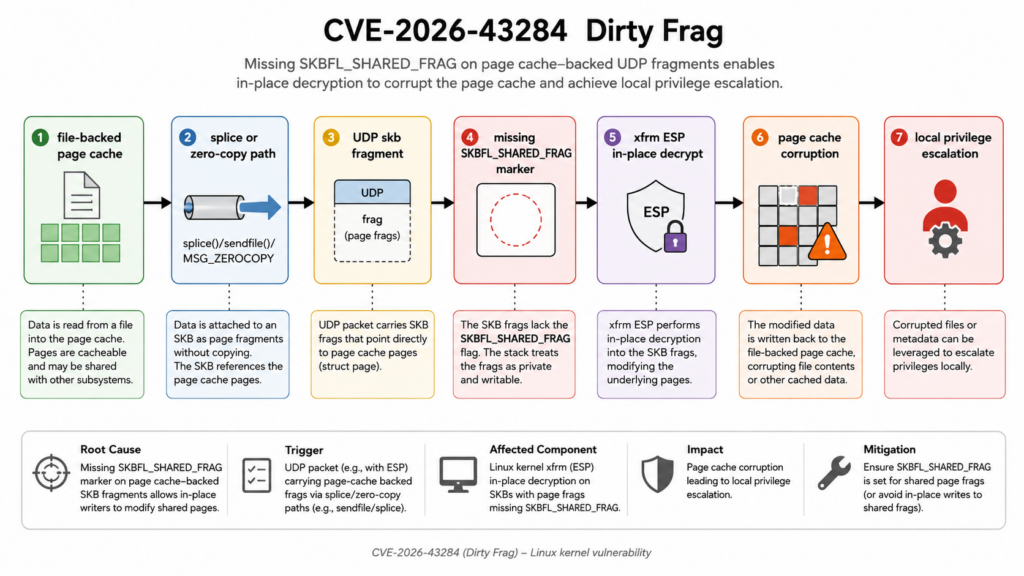
The fastest accurate summary is this: CVE-2026-43284 lives in the Linux kernel xfrm ESP receive path. It concerns shared socket buffer fragments, MSG_SPLICE_PAGES, and an unsafe in-place decrypt path. The kernel can be tricked into decrypting data directly over memory that should not be privately writable by that packet path. Ubuntu’s CVE page describes the resolved issue as xfrm: esp: avoid in-place decrypt on shared skb frags, and explains that IPv4 and IPv6 datagram append paths did not mark spliced UDP skb fragments with SKBFL_SHARED_FRAG, leaving ESP input to take a no-COW fast path over externally backed fragments. (Ubuntu)
Dirty Frag is usually discussed as two CVEs: CVE-2026-43284 for the xfrm ESP path and CVE-2026-43500 for the RxRPC path. Ubuntu’s mitigation post says the two local privilege escalation vulnerabilities were publicly disclosed on May 7, 2026, affect Linux kernel modules tied to ESP and RxRPC, and affect multiple Linux distributions, including Ubuntu releases. The same Ubuntu post says kernel updates are available and that module-disabling mitigations are no longer needed once the fixed kernel updates are installed. (Ubuntu)
The facts that matter first
| Champ d'application | Practical meaning |
|---|---|
| CVE | CVE-2026-43284 |
| Common name | Dirty Frag, xfrm ESP page-cache write path |
| Main affected area | Linux kernel xfrm ESP, including esp4 and esp6 paths |
| Usual companion issue | CVE-2026-43500, the RxRPC page-cache write path |
| Attack class | Local privilege escalation through page-cache corruption |
| Initial access required | Local code execution as an unprivileged user, service, container, or compromised account |
| Remote RCE by itself | Non |
| Real-world risk | High in shared execution environments, CI runners, container hosts, web-hosting nodes, developer boxes, and compromised Linux servers |
| Primary fix | Install vendor kernel updates and reboot into the fixed kernel |
| Temporary mitigation | Disable vulnerable modules only where operationally safe |
| Major caution | Disabling esp4 or esp6 can break IPsec tunnels that rely on kernel ESP processing |
NVD lists CVE-2026-43284 as a kernel.org CNA issue with a CVSS 3.1 base score of 8.8 High and a local attack vector. NVD also shows CISA-ADP scoring at 7.8 High and maps the issue to CWE-123, “Write-what-where Condition.” (nvd.nist.gov)
Ubuntu’s security page gives CVE-2026-43284 a High priority and describes a local attacker impact that includes privilege escalation and possible container escape. The same page explains the underlying shared-page-fragment handling problem and points administrators to Dirty Frag mitigation and fixed package guidance. (Ubuntu)
The operational lesson is simple: do not treat this as a low-priority kernel bug just because it is local. Treat it as a post-compromise amplifier. Any environment that lets untrusted users, tenants, build jobs, containers, application workers, or compromised accounts execute code on Linux should prioritize remediation.
Dirty Frag is a vulnerability class, not just a nickname
Dirty Frag is best understood as a page-cache write vulnerability class in Linux networking and cryptographic receive paths. The name points to the object being “dirtied”: a fragment associated with struct sk_buff, the central Linux networking structure used to represent packets.
The public Dirty Frag research repository by Hyunwoo Kim describes the chain as a combination of the xfrm ESP Page-Cache Write vulnerability, CVE-2026-43284, and the RxRPC Page-Cache Write vulnerability, CVE-2026-43500. The same write-up describes Dirty Frag as a descendant of Dirty Pipe and Copy Fail, and says it is deterministic, does not depend on a race window, and has a high success rate in tested scenarios. (GitHub)
That “deterministic” detail is what makes defenders nervous. A race-condition LPE often depends on timing, load, retry behavior, and kernel stability. Dirty Frag is closer to a logic bug in ownership tracking: a page that should have been treated as shared or externally backed reaches a kernel path that modifies it in place. If the attacker controls enough of that setup, the kernel writes where it should not.
The two halves of Dirty Frag cover different environmental constraints:
| Issue | Composant | Pourquoi c'est important | Typical blocker | Why the chain uses both |
|---|---|---|---|---|
| CVE-2026-43284 | xfrm ESP, esp4 and esp6 | Strong write primitive through ESP receive-side processing | Often needs namespace and xfrm setup conditions | Works well where unprivileged namespace creation and ESP paths are reachable |
| CVE-2026-43500 | RxRPC | Covers environments where ESP setup is blocked | Depends on RxRPC availability | Helps cover blind spots where xfrm ESP is not reachable |
Picus summarizes the two-part chain similarly: CVE-2026-43284 targets an IPsec ESP implementation flaw that bypasses copy-on-write protections, while CVE-2026-43500 targets RxRPC in-place decryption behavior. Picus also notes that chaining the two paths helps cover environmental blind spots across distributions. (picussecurity.com)
The practical mistake is to ask only, “Do we use IPsec?” CVE-2026-43284 concerns kernel code that can be reachable under local conditions, not only production site-to-site VPN traffic. The better question is, “Can untrusted or compromised local code reach vulnerable kernel paths on this host, and is the running kernel fixed?”
Why page cache is the attack surface
The Linux page cache is a performance feature. When a process reads a file, the kernel often keeps file-backed pages in memory so future reads do not need to hit storage again. Many processes can read the same file and benefit from the same cached data.
That shared cache is safe only if the kernel preserves ownership and write rules. If a low-privileged user can read /usr/bin/su, that does not mean the user can modify the cached pages behind /usr/bin/su. File permissions, memory mapping rules, and copy-on-write logic are supposed to enforce that boundary.
Dirty Frag breaks that expectation by routing a page-cache-backed page through a kernel packet-fragment path and then through an in-place cryptographic operation. The attacker is not simply opening a file and writing to it. The attacker is setting up a path where the kernel later performs the write on the attacker’s behalf, inside a subsystem that mistakenly believes the memory is safe to modify.
Qualys describes the Dirty Frag pattern as a zero-copy send path planting an attacker-controlled or attacker-readable page into a kernel data structure, followed by a downstream consumer that assumes it owns the buffer and performs an in-place write. Qualys compares Dirty Pipe, Copy Fail, and Dirty Frag as related page-cache write families with different sinks: struct pipe_buffer, algif_aead scatter-gather lists, and struct sk_buff fragments. (Qualys)
That is why conventional file-integrity thinking can be incomplete. A disk hash may still look clean while a cached page in RAM has been poisoned. Qualys explicitly warns that Dirty Frag does not touch files on disk and that tools relying on disk hashing may miss malicious cache state. It also notes that page cache contamination can persist until cache is dropped or the system reboots. (Qualys)
| Security assumption | Why it fails in this class |
|---|---|
| “The attacker cannot write the file on disk.” | The write is aimed at memory-backed page cache, not necessarily the disk inode. |
| “File hashes are clean.” | Disk-backed checksums may not reflect poisoned in-memory cache state. |
| “It is only local.” | Local execution is common after web-shell compromise, SSH theft, CI abuse, or container workload escape attempts. |
| “Kernel crypto is authenticated.” | The bug is about an unsafe in-place write before or during kernel processing, not about breaking cryptography in the abstract. |
| “A reboot is operationally expensive.” | A reboot may be required both to run the fixed kernel and to clear volatile poisoned cache state. |
The important mental model is ownership, not encryption strength. Dirty Frag does not need to defeat IPsec as a protocol. It abuses how kernel packet memory is represented, shared, and modified.
sk_buff, frags, and splice in plain English
Linux networking uses struct sk_buff, usually shortened to skb, to represent packets. The kernel documentation says sk_buff is the main networking structure representing a packet, but the structure itself is metadata and does not hold all packet data. Packet data lives in associated buffers, including a shared-info area that can hold page fragments. (docs.kernel.org)
That design is essential for performance. Modern kernels avoid copying data whenever they can. A packet may have a small linear header region plus payload fragments that point to pages elsewhere. That is normal.
splice() is another performance feature. The Linux man page says splice() moves data between two file descriptors without copying between kernel address space and user address space, with one of the descriptors referring to a pipe. (man7.org)
Again, zero-copy is not the vulnerability. Zero-copy becomes dangerous when later code forgets that the data it is about to modify may still be backed by memory it does not privately own.
In a safe path, packet data that comes from a shared or external page needs to be marked so later modifying paths can copy it first. That is where SKBFL_SHARED_FRAG matters. It is a marker that tells later code, in effect: “This skb contains a fragment whose backing memory is shared. Do not modify it in place unless you first make a private copy.”
CVE-2026-43284 appears when that shared-fragment truth is lost or not honored. Ubuntu’s CVE description says MSG_SPLICE_PAGES can attach pages from a pipe directly to an skb. TCP marks such skbs with SKBFL_SHARED_FRAG after skb_splice_from_iter(), so paths that may later modify packet data can make a private copy first. The IPv4 and IPv6 datagram append paths did not set that flag when splicing pages into UDP skbs. (Ubuntu)
That missing marker is not cosmetic. It changes the behavior of ESP input. Ubuntu explains that an ESP-in-UDP packet made from shared pipe pages can look like an ordinary uncloned nonlinear skb. ESP input then takes the no-COW fast path and decrypts in place over data not privately owned by the skb. (Ubuntu)
A simplified safe-versus-unsafe model looks like this:
Safe ownership flow:
file-backed page
-> splice into packet path
-> skb is marked as containing shared fragments
-> modifying subsystem sees shared-frag marker
-> kernel copies data into private memory
-> crypto or packet transformation writes only into owned memory
Unsafe Dirty Frag-style flow:
file-backed page
-> splice into packet path
-> skb shared-frag marker is missing or lost
-> modifying subsystem sees an ordinary nonlinear skb
-> no copy-on-write is performed
-> in-place decrypt writes into page-cache-backed memory
This is why the fix is not “remove IPsec” or “remove splice.” The fix is to preserve and respect ownership metadata before in-place writes.
How xfrm ESP becomes the vulnerable path
XFRM is Linux’s IP transformation framework. Cilium’s XFRM documentation explains that IPsec encryption in the Linux kernel relies on XFRM, and that XFRM is intended for packet transformations such as encryption and compression. It is configured through policies and states, which correspond to IPsec Security Policies and Security Associations. (docs.cilium.io)
ESP, Encapsulating Security Payload, is one of the IPsec protocols handled through that world. In normal operation, ESP transforms packets by encrypting, decrypting, authenticating, and processing payloads according to configured state. Performance matters, so kernel paths often try to avoid unnecessary copies.
CVE-2026-43284 is a case where a performance-minded fast path becomes unsafe. The ESP receive path sees a nonlinear skb and, under certain conditions, avoids copy-on-write. That is safe only if the fragments are privately owned. When the fragments actually point into shared or externally backed pages, in-place decrypt becomes a write into memory that should not be modified through that route.
Ubuntu’s description of the fix gives the cleanest authoritative explanation: mark IPv4 and IPv6 datagram splice fragments with SKBFL_SHARED_FRAG, matching TCP, and make ESP input fall back to skb_cow_data() when the flag is present. Private nonlinear skb fragments still use the existing fast path. (Ubuntu)
skb_cow_data() is the key defensive concept. “COW” means copy-on-write. If a packet path needs to modify data that may be shared, it should first copy that data into a private buffer. Dirty Frag exists because the kernel path can skip that private-copy step in a case where it should not.
A defensive pseudocode view is enough to understand the bug without turning the article into an exploit manual:
/*
* Simplified defensive model, not kernel source.
* The important point is ownership, not the exact implementation.
*/
if (skb_has_shared_frag(skb)) {
/*
* The packet data may point into externally backed pages.
* Do not decrypt or transform in place.
*/
err = skb_cow_data(skb, 0, &trailer);
if (err < 0)
return err;
}
/*
* Only after data is private should an in-place transform proceed.
*/
return esp_decrypt_or_verify(skb);
The vulnerable logic is not “ESP exists.” The vulnerable logic is “ESP modifies packet data without recognizing that the backing page is shared.”
Why RxRPC is part of the same story
CVE-2026-43500 is the RxRPC side of Dirty Frag. RxRPC is a less common protocol family than IPsec ESP, but it matters because the attack conditions differ.
The Linux kernel mailing list patch for RxRPC says the DATA-packet handler in rxrpc_input_call_event() and the RESPONSE handler in rxrpc_verify_response() copied skb data to a linear buffer before calling security operations only when skb_cloned() was true. An skb that was not cloned but still carried externally owned paged fragments could fall through to an in-place decryption path. The patch extends the gate to also unshare when skb_has_frag_list() ou skb_has_shared_frag() is true. (lkml.iu.edu)
That is the same ownership bug pattern in a different subsystem. The details differ. ESP and RxRPC use different paths, different primitives, and different environmental dependencies. But the security rule is identical: if packet fragments are backed by shared or external pages, do not modify them in place.
CloudLinux describes Dirty Frag as involving the in-place decryption path of esp4, esp6, and rxrpc, and says paged buffers not privately owned by the kernel can reach receive-side decryption paths through mechanisms such as pipe pages reaching sockets via splice(2) ou sendfile(2). (blog.cloudlinux.com)
This is why defenders should track both CVEs together during triage. A host may not be exposed to one path but still be exposed to the other. A mitigation that blocks only ESP does not automatically solve RxRPC. A mitigation that blocks only RxRPC does not automatically solve ESP.
Why CVE-2026-43284 is not “just another local bug”
Local privilege escalation vulnerabilities are often misunderstood because the word “local” sounds comforting. It should not.
Attackers frequently get local code execution before they get root. A stolen SSH password, a vulnerable web app that allows command execution, a malicious build step in CI, a compromised low-privileged service, or an untrusted container job can all provide local execution. Once a Linux kernel LPE is available, the attacker’s next question is not “Can I get in?” It is “Can I become root now?”
Microsoft’s Dirty Frag post explicitly frames exploitation scenarios this way: compromised SSH accounts, web-shell access, container escapes into the host environment, abuse of low-privileged service accounts, and post-exploitation activity following phishing or remote access compromise. (Microsoft)
Ubuntu makes the same distinction from a defender’s angle. On hosts without container workloads, Dirty Frag allows a local user to elevate privileges to root. In container deployments that may execute arbitrary third-party workloads, Ubuntu says the vulnerability may additionally facilitate container escape scenarios, while noting that a proof-of-concept exploit for container escape had not been published in that post. (Ubuntu)
That careful wording matters. Do not overclaim that every container is trivially escapable. Do not underclaim either. Container hosts share a kernel. A kernel local privilege escalation issue is automatically more concerning when untrusted workloads can run on that kernel.
Exposure ranking by environment
| Environnement | Priorité | Pourquoi |
|---|---|---|
| Shared hosting node | Critique | Many low-privileged users or app pools may run code on one kernel. |
| Kubernetes worker running third-party workloads | Critique | Containers share the host kernel; workload isolation depends heavily on kernel correctness. |
| CI/CD runner accepting external pull requests or untrusted build scripts | Critique | Build systems are designed to execute code, often near secrets. |
| Developer jump host with many SSH users | Haut | Low-privileged compromise can become full host compromise. |
| Internet-facing server with recent web-shell risk | Haut | Dirty Frag can convert app compromise into root. |
| VPN or IPsec gateway | High but handle carefully | ESP modules may be in active use; mitigation can break service. |
| Single-user workstation | Moyenne à élevée | Local malware can escalate; operational urgency depends on user behavior and exposure. |
| Appliance with no shell, no containers, and fixed vendor firmware | Vendor-dependent | Risk depends on whether local code execution is possible and whether the vendor kernel is affected. |
The safest prioritization rule is this: patch first where untrusted code can run. That includes systems you do not usually think of as “multi-user,” such as CI runners, notebook servers, browser automation workers, container hosts, and internal tools that execute user-supplied scripts.
A safe validation workflow
Do not validate Dirty Frag by running a public exploit on production systems. That may contaminate page cache, destabilize the host, violate policy, or create evidence-handling problems. A useful validation workflow proves exposure and remediation without weaponizing the bug.
Start with the running kernel, because installed packages do not matter if the host has not rebooted into the fixed kernel.
uname -a
uname -r
cat /etc/os-release
On Ubuntu and Debian-family systems, list installed kernel images and compare the running kernel to the vendor’s fixed version table.
dpkg-query -W -f='${binary:Package}\t${Version}\n' 'linux-image*' | sort
apt list --upgradable 2>/dev/null | grep -E 'linux-image|linux-generic|linux-headers' || true
Ubuntu’s mitigation post gives fixed versions for affected Ubuntu releases and tells administrators to check uname -r, list installed linux-image packages, upgrade packages, and reboot after installing kernel updates. (Ubuntu)
On RHEL, CentOS Stream, AlmaLinux, Fedora, Rocky, Oracle Linux, and related RPM-family systems, check the running kernel and the vendor advisory state. Backports often mean a fixed enterprise kernel will not have the same version number as upstream mainline.
uname -r
rpm -q kernel kernel-core kernel-modules 2>/dev/null
rpm -q --changelog kernel-core 2>/dev/null | grep -Ei 'CVE-2026-43284|dirty frag|xfrm|esp|rxrpc' | head -40
Then check whether the modules most often discussed in Dirty Frag guidance are loaded.
lsmod | awk '{print $1}' | grep -E '^(esp4|esp6|rxrpc)$' || true
If they are not loaded, do not stop there. Modules can autoload. Check whether the system knows about them and whether module-loading rules already block them.
for m in esp4 esp6 rxrpc; do
echo "== $m =="
modprobe -n -v "$m" 2>&1 || true
done
Check whether the host depends on IPsec or AFS-style functionality before applying module mitigations.
ip xfrm state 2>/dev/null | head -40
ip xfrm policy 2>/dev/null | head -40
systemctl --type=service --state=running | grep -Ei 'strongswan|libreswan|ipsec|afs|openafs' || true
The output is not a complete dependency map, but it catches obvious cases. If ip xfrm state shows active state, or if strongSwan, Libreswan, or AFS services are present, module blacklisting can break real workloads.
What to monitor for possible exploitation
Detection is difficult because this class can affect page cache without changing the file on disk. Runtime telemetry matters more than a single file hash.
Microsoft reported a sequence in limited observed activity where an external connection gained SSH access, spawned an interactive shell, staged and executed an ELF binary named ./update, triggered privilege escalation through su, modified a GLPI LDAP authentication file, performed reconnaissance, and accessed PHP session data. (Microsoft)
That does not mean every Dirty Frag case will look like GLPI. It means the useful detection pattern is post-compromise behavior around local execution, module usage, privilege transitions, and sensitive file access.
High-value detection signals include:
| Signal | Pourquoi c'est important | Caveat |
|---|---|---|
Unexpected su or setuid binary execution by service users | Public Dirty Frag and related page-cache LPEs often target privilege transition paths | Admin sessions and automation can be noisy |
New ELF execution from /tmp, web directories, CI workspaces, or user-writable paths | Common staging pattern after local foothold | Many build systems execute new binaries |
Sudden unshare, clone3, or namespace creation by unusual users | ESP path setup may rely on namespace capabilities in some environments | Containers and sandbox tools use namespaces normally |
ip xfrm manipulation from unexpected contexts | xfrm state and policy setup can be part of ESP-path experimentation | Legitimate IPsec tooling uses xfrm |
Loading or probing esp4, esp6, rxrpc, af_alg, or crypto modules | May reveal exploit setup or module availability checks | Kernel and VPN services can load these normally |
echo 3 > /proc/sys/vm/drop_caches or similar cache-clearing behavior | May follow exploit testing or cleanup | Admin troubleshooting also uses it |
| File-integrity mismatch after reboot versus before reboot | May reveal that prior suspicious behavior was cache-only | Reboot changes many runtime conditions |
Example auditd rules can help collect evidence, but they are not proof of exploitation by themselves:
# Module loading and namespace changes
-a always,exit -F arch=b64 -S init_module,finit_module,delete_module -k kernel-module-change
-a always,exit -F arch=b64 -S unshare,setns,clone,clone3 -k namespace-change
# xfrm tooling and privileged transition observation
-w /sbin/ip -p x -k iproute-exec
-w /usr/sbin/ip -p x -k iproute-exec
-w /bin/su -p x -k su-exec
-w /usr/bin/su -p x -k su-exec
# Cache manipulation
-w /proc/sys/vm/drop_caches -p w -k drop-caches
Treat these as visibility aids. A good investigation correlates user, parent process, working directory, binary hash, command line, loaded modules, kernel version, session source, and timing around privilege changes.
A Falco-style rule can also focus on suspicious combinations rather than one event:
- rule: Suspicious local privilege escalation preparation on Linux
desc: Detect unusual namespace, xfrm, module, or su activity from non-admin execution contexts
condition: >
spawned_process and
container.id != host and
proc.name in (unshare, ip, modprobe, insmod, su) and
not user.name in (root, approved_admin_users)
output: >
Suspicious LPE-related process in container or non-admin context
user=%user.name proc=%proc.cmdline parent=%proc.pcmdline container=%container.id
priority: WARNING
That sample is intentionally generic. Tune it to your fleet. The goal is to catch abnormal paths without drowning analysts in expected container runtime noise.
Mitigation, patching, and rollback
The primary remediation is to install the fixed kernel provided by your distribution and reboot into it. Kernel package installation alone is not enough. A host can have a fixed kernel installed and still be running a vulnerable kernel until reboot.
Ubuntu’s guidance recommends upgrading packages and rebooting after Linux kernel security updates are installed. It also notes that unattended upgrades may apply patches automatically, but a reboot is still required. (Ubuntu)
For Ubuntu-family systems, the practical sequence is:
sudo apt update
sudo apt full-upgrade
sudo reboot
After reboot:
uname -r
dpkg-query -W -f='${binary:Package}\t${Version}\n' 'linux-image*' | sort
For RHEL-family systems:
sudo dnf update kernel kernel-core kernel-modules
sudo reboot
After reboot:
uname -r
rpm -q kernel-core kernel-modules
If you cannot patch immediately, module blacklisting may reduce exposure. It must be handled as an emergency mitigation, not a clean replacement for patching.
Ubuntu says the mitigations disable kernel modules used for IPsec ESP and RxRPC and can affect IPsec deployments such as strongSwan, as well as AFS or other RxRPC applications. Ubuntu also warns that disabling only ESP or only RxRPC leaves the other vulnerability path exploitable. (Ubuntu)
CloudLinux makes the same operational warning: disabling esp4 or esp6 breaks IPsec tunnels that rely on the kernel data path, while rxrpc is mostly associated with AFS clients and is not typical on ordinary web-hosting servers. (blog.cloudlinux.com)
A cautious temporary mitigation flow looks like this:
# 1. Create module loading blocks
sudo tee /etc/modprobe.d/dirty-frag.conf >/dev/null <<'EOF'
install esp4 /bin/false
install esp6 /bin/false
install rxrpc /bin/false
EOF
# 2. Regenerate initramfs on Debian/Ubuntu-family systems
sudo update-initramfs -u -k all
# 3. Try to unload currently loaded modules
sudo rmmod esp4 esp6 rxrpc 2>/dev/null || true
# 4. Confirm current state
grep -E '^(esp4|esp6|rxrpc) ' /proc/modules && \
echo "One or more affected modules are still loaded" || \
echo "Affected modules are not loaded"
If modules cannot be unloaded because they are in use, a reboot may be needed for the blacklist to take effect. Before doing that, confirm IPsec and AFS dependencies with application owners. Breaking a VPN gateway during an incident can cause more damage than it prevents.
After the fixed kernel is deployed, remove the emergency mitigation if it is no longer needed:
sudo rm -f /etc/modprobe.d/dirty-frag.conf
sudo update-initramfs -u -k all
sudo reboot
For non-Ubuntu distributions, use the equivalent initramfs regeneration process, such as dracut, where appropriate.
Page-cache cleanup after suspected exploitation
If you suspect exploitation occurred before patching or mitigation, do not assume that disabling modules cleans the system. Microsoft warns that mitigation alone may not reverse changes introduced through successful exploitation attempts, and says organizations should validate critical file integrity and evaluate whether cache clearing is appropriate. It gives echo 3 | sudo tee /proc/sys/vm/drop_caches as an example, while warning that cache clearing can increase disk I/O and affect production performance. (Microsoft)
CloudLinux also warns that the exploit can modify legitimate system binaries in page cache as part of gaining root, and recommends dropping page cache after mitigation on systems that may have been targeted. (blog.cloudlinux.com)
In incident response, a reboot is often cleaner than relying on cache-drop commands, because it both clears volatile cache state and moves the host into the newly installed kernel. But production systems have uptime requirements, so the right sequence depends on business impact and the quality of evidence.
A practical response checklist:
1. Preserve evidence before disruptive action.
2. Record running kernel, uptime, loaded modules, active sessions, and suspicious processes.
3. Capture EDR, auditd, shell history, service logs, and process lineage where available.
4. Install vendor kernel updates.
5. Reboot into the fixed kernel during an approved emergency window.
6. Re-check running kernel and module state.
7. Validate critical setuid binaries and authentication files from trusted media or package manager metadata.
8. Rotate credentials if root compromise is plausible.
9. Review lateral movement paths from the affected host.
On Debian/Ubuntu-family systems, package verification may include:
sudo debsums -s 2>/dev/null | head -100
dpkg -V | head -100
On RPM-family systems:
sudo rpm -Va | head -100
These checks are not perfect. They may produce benign differences from configuration files, package scripts, or normal operations. They are starting points for triage, not final proof.
Why module mitigation can break production
Emergency mitigations are seductive because they are fast. Dirty Frag is exactly the kind of vulnerability where a fast mitigation can also break something important.
The ESP modules, esp4 and esp6, are used for kernel-side IPsec ESP processing. If a host terminates IPsec tunnels, transits VPN traffic, or uses strongSwan or Libreswan with kernel ESP, blocking those modules can interrupt connectivity. CloudLinux explicitly warns against applying that mitigation on hosts that terminate or transit IPsec or strongSwan or Libreswan tunnels. (blog.cloudlinux.com)
RxRPC is less common in typical web-hosting stacks, but it is not imaginary. It is associated with AFS and related uses. Ubuntu calls out AFS and other RxRPC applications as possible functionality affected by mitigation. (Ubuntu)
Before module blacklisting, ask:
| Question | Pourquoi c'est important |
|---|---|
| Does this host terminate IPsec VPNs? | Blocking esp4 or esp6 may break tunnels. |
| Does this host use strongSwan, Libreswan, or route-based IPsec? | These tools may depend on kernel XFRM and ESP. |
| Does this host run AFS or RxRPC-dependent workloads? | Blocking rxrpc may break niche but important applications. |
| Can the host be patched and rebooted faster than safely mitigating? | Patch plus reboot is cleaner than brittle module changes. |
| Is this a container worker or shared execution host? | Risk may justify emergency action even with operational cost. |
If the answer is unclear, do not guess. Pull network, platform, and application owners into the change. Dirty Frag is serious, but availability incidents caused by blind mitigation are also real incidents.
Container and Kubernetes risk
Dirty Frag is especially relevant to container platforms because containers share the host kernel. A container boundary is not a hardware boundary. It is a set of kernel-enforced isolation mechanisms. If an attacker can run code in a container and reach a kernel local privilege escalation path, the host becomes part of the risk analysis.
Ubuntu’s post says Dirty Frag may facilitate container escape scenarios in deployments that execute arbitrary third-party workloads, while carefully noting that a container-escape proof-of-concept had not been published in that post. (Ubuntu)
For Kubernetes and containerized environments, prioritize:
1. Worker nodes that run untrusted tenant workloads.
2. CI runners that build untrusted pull requests.
3. Notebook, sandbox, or browser automation infrastructure.
4. Clusters allowing privileged containers or broad hostPath mounts.
5. Nodes with old kernels and delayed reboot cycles.
6. Nodes with weak runtime detection or limited process telemetry.
Hardening steps that reduce blast radius include:
- Remove privileged containers unless strictly necessary.
- Minimize hostPath mounts and host namespace sharing.
- Restrict capabilities, especially CAP_SYS_ADMIN.
- Use seccomp and AppArmor or SELinux profiles.
- Disable unprivileged user namespaces where business-compatible.
- Keep worker node images patched and rotate nodes after kernel updates.
- Separate untrusted CI workloads from production secrets and networks.
Do not oversell any one hardening control. Kernel LPEs often move around individual restrictions. Defense works best as a stack: patched kernels, reduced local execution, container hardening, runtime telemetry, and fast node replacement.
Related CVEs that make Dirty Frag easier to understand
Dirty Frag belongs to a lineage of Linux page-cache and copy-on-write problems. The details differ, but the common theme is that performance optimizations around shared memory, pipes, zero-copy I/O, or in-place operations can become privilege escalation bugs when ownership tracking fails.
| CVE | Nom | Why it is relevant | Condition d'exploitation | Main risk | Atténuation |
|---|---|---|---|---|---|
| CVE-2016-5195 | Dirty COW | Classic copy-on-write failure in Linux memory handling | Local user races COW behavior | Local privilege escalation, exploited in the wild | Kernel update |
| CVE-2022-0847 | Tuyau sale | Page-cache-backed read-only files could be written due to stale pipe buffer flags | Local unprivileged user | Modify read-only file-backed cache and escalate | Kernel update |
| CVE-2026-31431 | Copy Fail | Related page-cache write class involving Linux crypto and AF_ALG behavior | Local unprivileged user under affected kernels | Root via controlled writes into page cache | Kernel update and module mitigation where applicable |
| CVE-2026-43284 | Dirty Frag ESP | xfrm ESP receive path can decrypt in place over shared skb frags | Local code execution and reachable ESP path conditions | Root through page-cache corruption | Kernel update, careful esp4 and esp6 mitigation if needed |
| CVE-2026-43500 | Dirty Frag RxRPC | RxRPC in-place decryption can hit externally backed paged frags | Local code execution and RxRPC availability | Root through page-cache corruption | Kernel update, careful rxrpc mitigation if needed |
| CVE-2026-46300 | Fragnesia | Related XFRM ESP-in-TCP page-cache class | Local unprivileged user under affected kernels | Root through page-cache manipulation | Kernel update and similar mitigation strategy where vendor-approved |
NVD describes Dirty COW, CVE-2016-5195, as a race condition in Linux copy-on-write handling that allowed local users to gain privileges by writing to a read-only memory mapping and notes exploitation in the wild in October 2016. (nvd.nist.gov)
NVD describes Dirty Pipe, CVE-2022-0847, as a flaw where uninitialized pipe buffer flags could allow an unprivileged local user to write to page-cache-backed read-only files and escalate privileges. (nvd.nist.gov)
NVD describes Copy Fail, CVE-2026-31431, as a Linux kernel algif_aead fix that reverted in-place operation because source and destination came from different mappings. That issue sits close to Dirty Frag conceptually because both involve in-place crypto behavior and page-cache write risk. (nvd.nist.gov)
Microsoft’s Dirty Frag update also references Fragnesia, CVE-2026-46300, as a new variant that manipulates Linux page-cache behavior for privilege escalation through a different bug, focused on esp/xfrm rather than the two-path ESP plus RxRPC Dirty Frag chain. (Microsoft)
The family resemblance is not branding trivia. It changes how defenders should review future kernel bugs. When a vulnerability involves zero-copy, pipe pages, skb fragments, page cache, in-place crypto, or missing copy-on-write boundaries, treat it as a candidate for privilege escalation even if the first advisory looks narrow.
Defensive validation should preserve evidence, not just produce a yes or no
A real remediation workflow for CVE-2026-43284 should produce evidence that another engineer can review later. A Slack message saying “patched Dirty Frag” is not enough.
For each host or cluster, preserve:
{
"asset": "worker-node-12",
"os_release": "Ubuntu 24.04 LTS",
"running_kernel_before": "6.8.0-example",
"running_kernel_after": "6.8.0-fixed-example",
"cve_checked": ["CVE-2026-43284", "CVE-2026-43500"],
"esp4_loaded_before": false,
"esp6_loaded_before": false,
"rxrpc_loaded_before": false,
"ipsec_dependency_confirmed": false,
"afs_dependency_confirmed": false,
"kernel_update_installed": true,
"reboot_completed": true,
"post_reboot_validation": "uname -r and package inventory captured",
"temporary_mitigation_used": false,
"evidence_location": "restricted-ticket-1234/artifacts/"
}
For a larger fleet, a CSV-like asset matrix is useful:
| Asset | Kernel before | Fixed kernel running | esp4 loaded | esp6 loaded | rxrpc loaded | Rebooted | Owner | Status |
|---|---|---|---|---|---|---|---|---|
| ci-runner-01 | vulnerable | yes | no | no | no | yes | DevInfra | closed |
| vpn-gw-02 | vulnerable | pending | yes | yes | no | no | NetOps | maintenance scheduled |
| k8s-worker-17 | vulnerable | yes | no | no | no | yes | Plate-forme | closed |
| shared-web-04 | unknown | no | no | no | no | no | Hosting | investigate |
For teams using AI-assisted security workflows, the useful automation is not “generate a paragraph about Dirty Frag.” The useful automation is to connect asset inventory, vendor advisory status, runtime evidence, module checks, reboot verification, and retest notes into a traceable evidence chain. Penligent’s public material positions the platform around AI-powered penetration testing and evidence-driven validation rather than scanner-only output, and its own Dirty Frag write-up focuses on the same ownership bug pattern around skb fragments, page cache, and module-mitigation risk. (Penligent)
That kind of workflow is especially valuable when a local kernel issue must be triaged across many hosts with different business owners. The question is not just “is CVE-2026-43284 present?” It is “which hosts can execute untrusted code, which ones cannot be rebooted immediately, which mitigations would break VPN or AFS, and which evidence proves the host is now running the fixed kernel?”
Common mistakes during Dirty Frag response
The first mistake is stopping at package installation. Kernel fixes require a reboot or livepatch mechanism. If uname -r still shows the old kernel, the host is still running the old kernel.
The second mistake is blind module blacklisting. Blocking esp4 and esp6 on an IPsec gateway can break production tunnels. Blocking rxrpc may affect AFS-related workloads. Ubuntu and CloudLinux both warn about functional impact from module-based mitigations. (Ubuntu)
The third mistake is treating disk hashes as complete evidence. Dirty Frag-style page-cache corruption may not show up as an on-disk file modification. Runtime telemetry, reboot state, process lineage, and suspicious privilege transitions matter.
The fourth mistake is assuming “not internet-facing” means “not important.” CI runners, shared hosts, developer boxes, internal build machines, and container workers may not expose a public port, but they often execute untrusted or semi-trusted code.
The fifth mistake is merging all Dirty Frag-related issues into one remediation ticket without tracking components. CVE-2026-43284 and CVE-2026-43500 have different affected paths and environmental conditions. A clean report should list both where relevant.
The sixth mistake is running public exploit code to “confirm” exposure. That is rarely necessary and can contaminate page cache, trigger security controls, or create legal and operational risk. Use vendor version checks, module checks, controlled lab reproduction, and approved security validation instead.
A practical incident-response sequence
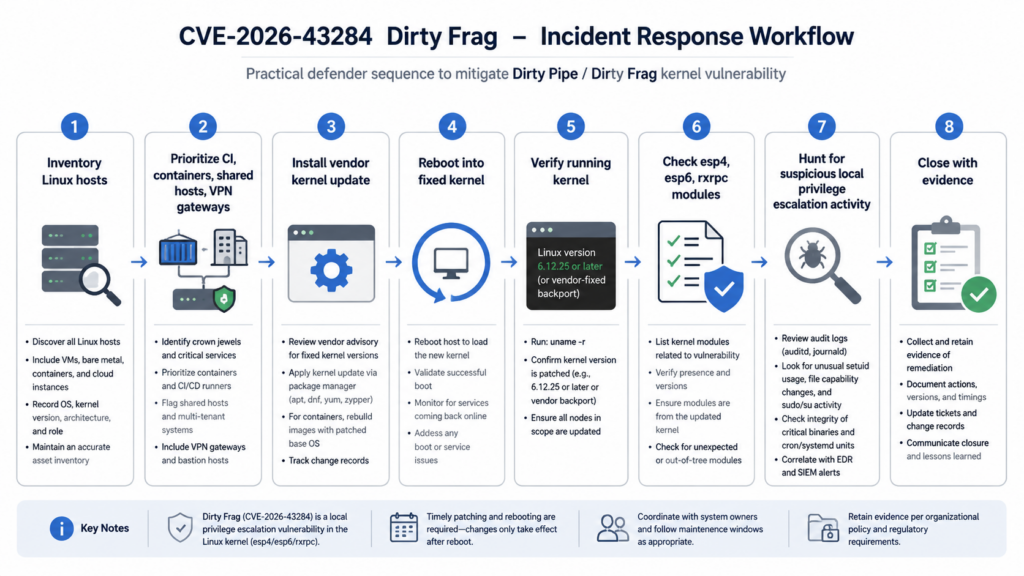
For an organization with many Linux hosts, a reasonable Dirty Frag response plan looks like this:
Phase 1 — Identify
- Pull all Linux assets from inventory.
- Flag shared execution systems, CI workers, Kubernetes nodes, VPN gateways, and user-accessible servers.
- Record OS, running kernel, installed kernel, and reboot status.
Phase 2 — Prioritize
- Put untrusted-code and multi-tenant environments first.
- Escalate hosts with public web-shell risk, compromised accounts, or recent suspicious local execution.
- Treat IPsec gateways separately because mitigation can break service.
Phase 3 — Patch
- Apply vendor kernel updates.
- Reboot or use vendor-supported livepatching where applicable.
- Verify the running kernel after the reboot.
Phase 4 — Mitigate only when needed
- If patching is delayed, evaluate temporary module blocks.
- Confirm IPsec and RxRPC dependencies before blocking.
- Document rollback steps.
Phase 5 — Hunt
- Search for suspicious local privilege transitions.
- Review new ELF execution from writable directories.
- Correlate SSH, web-shell, container, and CI execution with `su`, module loads, xfrm activity, and cache-clearing events.
Phase 6 — Close
- Preserve evidence.
- Rotate credentials if compromise is plausible.
- Retest high-risk hosts.
- Record host owner acceptance and residual risk.
This is also the point where security reporting discipline matters. A Dirty Frag finding should not be a generic “Linux kernel vulnerable” statement. It should identify the running kernel, distribution advisory, affected components, local execution preconditions, business exposure, mitigation side effects, patch status, reboot status, and remaining uncertainty.
Useful primary sources
NVD’s CVE-2026-43284 record is the baseline for CVSS, CWE, kernel.org CNA status, and patch references. Use it to anchor the CVE identity and official scoring context. (nvd.nist.gov)
Ubuntu’s Dirty Frag mitigation post is one of the clearest distribution-level resources because it includes impact, affected release guidance, commands for checking the running kernel, patch instructions, reboot requirements, and module mitigation warnings. (Ubuntu)
Hyunwoo Kim’s Dirty Frag repository is the primary public research artifact for the vulnerability class and timeline, but treat the exploit material as lab-only and authorization-bound. (GitHub)
Microsoft’s Dirty Frag post is valuable for operational defense because it connects the vulnerability to post-compromise scenarios, limited observed activity, mitigation guidance, cache integrity concerns, and detection themes. (Microsoft)
The Linux kernel sk_buff documentation and splice(2) man page help defenders understand why this bug class exists: skb is metadata over associated buffers, and splice moves data between file descriptors without copying through user space. (docs.kernel.org)
FAQ
Is CVE-2026-43284 a remote code execution vulnerability?
- No. CVE-2026-43284 is best treated as a local privilege escalation issue.
- An attacker generally needs local code execution first, such as a shell, service account, compromised web app, container workload, or CI job.
- The risk is still high because attackers often use LPEs after initial access to become root.
Is Dirty Frag the same thing as CVE-2026-43284?
- Not exactly.
- CVE-2026-43284 refers to the xfrm ESP page-cache write issue.
- Dirty Frag usually refers to a chain or class involving CVE-2026-43284 and CVE-2026-43500.
- Some public discussions also compare Dirty Frag with Copy Fail and Fragnesia because they share page-cache write themes.
Which systems should be patched first?
- Patch shared execution systems first: CI runners, container workers, shared hosting nodes, developer jump hosts, and systems running untrusted workloads.
- Patch internet-facing servers with any chance of web-shell or low-privileged service compromise.
- Treat IPsec gateways carefully, because temporary module mitigation may break VPN traffic.
- Do not wait only because the vulnerability is local.
How do I safely check whether a host is affected?
- Check the running kernel with
uname -r. - Compare it with your distribution’s fixed kernel version or vendor advisory.
- Check installed kernel packages, but remember that installed does not mean running.
- Check whether
esp4,esp6ourxrpcare loaded or can autoload. - Avoid running public exploit code on production systems.
Is disabling esp4, esp6, and rxrpc safe?
- It can reduce exposure when patching is delayed, but it is not always safe.
- Disabling esp4 or esp6 can break IPsec, strongSwan, Libreswan, and VPN paths that rely on kernel ESP.
- Disabling rxrpc can affect AFS or other RxRPC users.
- Use module blocking only after dependency checks and with a rollback plan.
Why might file-integrity monitoring miss Dirty Frag exploitation?
- The attack class can poison page-cache-backed memory instead of directly modifying files on disk.
- Disk hashes may remain unchanged while the in-memory cached version has been corrupted.
- Runtime telemetry, process behavior, suspicious privilege transitions, and cache-clearing events are important.
- A reboot or carefully evaluated cache drop may be needed after suspected exploitation.
Does patching require a reboot?
- In ordinary kernel-package workflows, yes.
- Installing a fixed kernel package does not change the kernel already running in memory.
- Reboot and then verify with
uname -r. - Vendor-supported livepatching may be an option in some environments, but it should be verified through the vendor’s tooling.
Can CVE-2026-43284 lead to container escape?
- Ubuntu states that in container deployments executing arbitrary third-party workloads, Dirty Frag may facilitate container escape scenarios.
- That does not mean every container is automatically exploitable in the same way.
- The practical defense is to patch host kernels, harden container runtime policy, reduce privileged containers, restrict host mounts, and rotate worker nodes after updates.
Fermeture
CVE-2026-43284 is a kernel ownership bug with real post-compromise consequences. The vulnerable path is technical, but the remediation priority is not complicated: patch the kernel, reboot into the fixed version, handle esp4, esp6, and rxrpc mitigations only with dependency awareness, and investigate suspicious local privilege transitions where exposure existed before remediation.
Dirty Frag also leaves a larger lesson for defenders. High-performance kernel features such as zero-copy I/O, page fragments, in-place crypto, and copy-on-write fast paths are not just implementation details. They are security boundaries. When those boundaries lose track of who owns memory, “local user” can become “root” very quickly.