OpenAI’s June 2026 Daybreak expansion is not just another “AI finds vulnerabilities” announcement. The important shift is narrower and more operational: AI-assisted security is moving from raw discovery toward validated remediation. OpenAI released the full version of GPT-5.5-Cyber through limited access for trusted defenders, updated the Codex Security plugin, and introduced Patch the Planet with Trail of Bits to help open-source maintainers move from findings to fixes. OpenAI describes the goal as moving beyond vulnerability discovery and accelerating end-to-end patch automation. (OpenAI)
That distinction matters. Security teams do not become safer because an AI model generates a longer list of suspected bugs. They become safer when a finding is scoped, reproduced, prioritized, patched, tested, disclosed responsibly, and verified as fixed. Patch the Planet is built around that loop. OpenAI says the initiative pairs AI-assisted security research with expert human review, while Trail of Bits researchers validate findings, develop and test patches, and coordinate disclosure with maintainers. (OpenAI)
The timing is also not accidental. On the same day, Five Eyes cyber agencies warned that frontier AI models are changing cyber risk on a timeline measured in months, not years. Their statement says AI accelerates the speed, scale, and sophistication of cyber threats, lowers barriers for malicious actors, and shrinks the window between vulnerability discovery and exploitation. (NSA)
For defenders, the practical question is no longer whether AI can assist vulnerability research. The question is whether organizations can absorb AI-generated findings without drowning maintainers, overloading developers, or shipping unsafe patches. OpenAI GPT-5.5-Cyber, Codex Security, and Patch the Planet should be evaluated through that lens.
What OpenAI Actually Announced
OpenAI’s Daybreak expansion has four main parts.
The first is GPT-5.5-Cyber, a more capable and more permissive model for advanced, authorized cybersecurity work. OpenAI calls it its strongest model yet for finding and helping patch software vulnerabilities. It is designed for deeper analysis across large codebases, including identifying security-relevant components, tracing whether vulnerable code is reachable, validating likely issues in controlled environments, developing and testing patches, and preparing evidence for human review. (OpenAI)
The second is Codex Security, now updated as a plugin and cloud workflow. OpenAI says Codex Security can run deep scans, review recent code changes, generate reports with severity and affected code locations, trace attack paths, build threat models, validate findings, and generate codebase-specific patches for review. It can also triage existing findings from scanners, advisories, bug bounty reports, or ticketing systems, then export to vulnerability management systems or integrate through artifacts such as SARIF and CodeQL queries. (OpenAI)
The third is Patch the Planet, an open-source security initiative founded with Trail of Bits and supported by partners including HackerOne and Calif. OpenAI lists cURL, NATS Server, pyca/cryptography, Sigstore, aiohttp, the Go project, freenginx, Python, and python.org among the initial participants. These projects sit in networking, cryptography, software supply chain, language infrastructure, and web infrastructure layers used by many downstream systems. (OpenAI)
The fourth is the Daybreak Cyber Partner Program, which gives trusted security partners access to OpenAI’s more capable models so they can bring these workflows into their own products and services. OpenAI says more than 30 open-source projects have committed to Patch the Planet, with initial participants including cURL, Go, Python, Sigstore, and pyca/cryptography. (OpenAI)
The announcement is best understood as a security workflow stack rather than a single model release:
| Couche | Ce qu'il fait | Pourquoi c'est important |
|---|---|---|
| GPT-5.5-Cyber | Performs deeper authorized security reasoning over large codebases and controlled validation tasks | Expands what AI can do in vulnerability analysis, exploitability reasoning, and patch development |
| Codex Security | Places scanning, threat modeling, evidence review, and patch suggestions inside developer workflows | Reduces the gap between security findings and code changes developers can review |
| Patch the Planet | Adds expert review, maintainer collaboration, patching, testing, and disclosure support for open source | Addresses the maintainer bottleneck instead of sending raw AI reports downstream |
| Trusted Access for Cyber | Controls who can access more permissive cyber capabilities | Attempts to balance defensive utility with misuse risk |
The most important phrase in OpenAI’s announcement is not “strongest model.” It is “move past vulnerability discovery.” Discovery is no longer the scarce resource by itself. The scarce resource is trusted remediation.
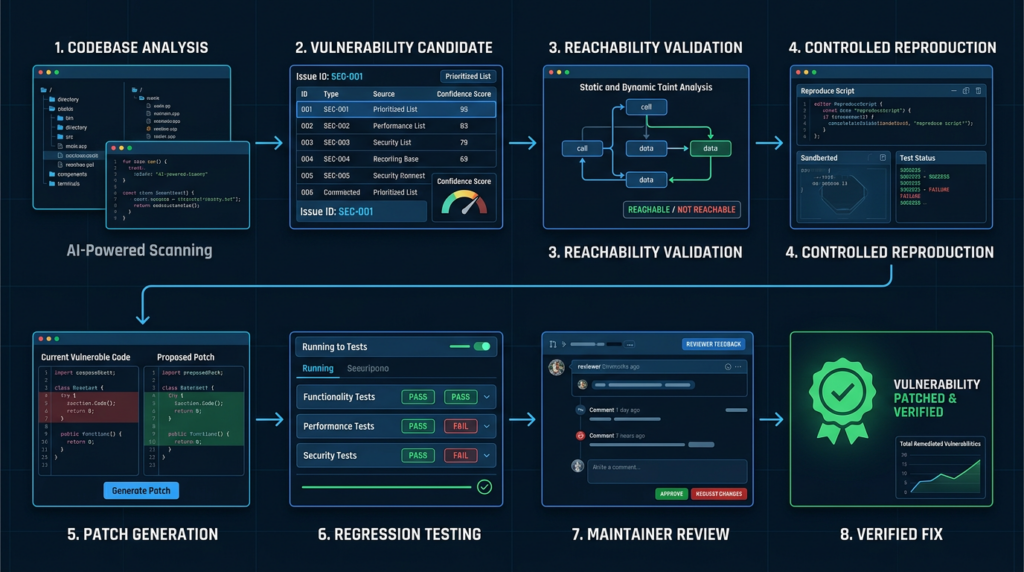
GPT-5.5-Cyber Is Not a Public Exploit Bot
OpenAI’s own access framing is important. GPT-5.5-Cyber is not positioned as a general public model for anyone to run unrestricted offensive tasks. OpenAI says it is intended for verified defenders whose authorized work requires advanced cyber capabilities and more permissive behavior, paired with stronger verification, monitoring, scoped controls, and review. For most defenders, OpenAI says GPT-5.5 with Trusted Access for Cyber and Codex Security remains the right starting point. (OpenAI)
OpenAI’s earlier Trusted Access for Cyber documentation describes TAC as an identity- and trust-based framework for verified defenders. It says approved defenders receive fewer classifier-based refusals for authorized workflows such as vulnerability identification, triage, malware analysis, binary reverse engineering, detection engineering, and patch validation, while safeguards continue to block activity such as credential theft, stealth, persistence, malware deployment, or exploitation of third-party systems. (OpenAI)
That boundary matters for security leaders evaluating the technology. More capable models create value when they are placed inside authorized workflows, but they also raise the cost of weak governance. A model that can reason across a codebase, generate a proof of concept in a lab, and propose a patch is useful only if the surrounding process proves authorization, limits scope, logs evidence, and keeps humans in control.
| Access level | Intended use | Cyber behavior | Governance requirement |
|---|---|---|---|
| Default GPT-5.5 | General coding, analysis, and knowledge work | Standard safeguards for general use | Normal product controls |
| GPT-5.5 with Trusted Access for Cyber | Verified defensive work in authorized environments | More useful for vulnerability triage, malware analysis, detection engineering, and patch validation | Identity verification, stronger account security, authorized scope |
| GPT-5.5-Cyber | Specialized authorized red teaming, penetration testing, and controlled validation | More permissive and more capable for advanced cyber tasks | Stronger verification, scoped controls, monitoring, and review |
Security teams should treat GPT-5.5-Cyber as a capability amplifier, not as a replacement for authorization, rules of engagement, or disclosure discipline. The deployment model is part of the security model.
The Benchmarks Show Capability, Not Operational Safety
OpenAI reported three benchmark results for the updated GPT-5.5-Cyber. On CyberGym, which measures whether an agent can reproduce known vulnerabilities in software environments, GPT-5.5-Cyber reached 85.6% versus 81.8% for GPT-5.5. On ExploitGym, which tests whether agents can turn known vulnerabilities into working exploits that achieve unauthorized code execution, GPT-5.5-Cyber reached 39.5% versus 25.95%. On SEC-bench Pro, which evaluates long-horizon vulnerability discovery and proof-of-concept generation across complex software targets, GPT-5.5-Cyber reached 69.8% versus 63.1%. (OpenAI)
Those numbers are significant, but they should not be read as a promise that every AI-generated finding is correct or every AI-generated fix is safe. Benchmarks measure defined tasks under defined conditions. Production remediation has messier constraints: incomplete test coverage, ambiguous ownership, platform-specific behavior, business logic, compatibility requirements, maintainers with limited time, and disclosure timelines.
A useful AI security system needs to answer questions that benchmarks often simplify:
| Question | Pourquoi c'est important |
|---|---|
| Is the affected code actually reachable by an attacker? | Many static findings are real code smells but not exploitable in the deployed configuration |
| What permissions are required? | A local privilege escalation, authenticated bug, unauthenticated remote bug, and CI-only issue have different urgency |
| Can the issue be reproduced safely? | A finding without replayable evidence is hard to prioritize and easy to misclassify |
| Does the proposed patch preserve intended behavior? | A security fix that breaks protocol compatibility or authentication logic may create operational risk |
| Does the fix include regression coverage? | Without a test, the same bug class can return later |
| Are disclosure and maintainer preferences respected? | Open-source remediation depends on trust, not just technical correctness |
The benchmark story is therefore important but incomplete. GPT-5.5-Cyber appears more capable at complex security reasoning than the baseline model, but the operational breakthrough is the combination of capability with review, evidence, and patch workflows.
Codex Security Moves Review Into the Developer Loop
Codex Security matters because developers do not live in vulnerability dashboards. They live in editors, terminals, pull requests, issue trackers, CI systems, and code review conversations. A security tool that produces a PDF outside that loop often becomes another backlog item. A tool that can inspect a repository, create a threat model, validate plausible findings, propose bounded patches, and produce reviewable artifacts has a better chance of changing the code.
OpenAI’s Codex Security documentation says the plugin scans code for vulnerabilities, validates plausible findings, and presents evidence and remediation guidance in a reviewable workspace. It is intended for code the user owns or is authorized to assess. The quickstart describes a read-only scan of a local repository, with the plugin generating a findings workspace and artifacts such as report.md, scan-manifest.json, findings.jsonet coverage.json. (Développeurs OpenAI)
The Codex Security overview also states that Codex Security cloud scans connected GitHub repositories, builds scan context from the repository, checks likely vulnerabilities against that context, validates high-signal issues in an isolated environment, and surfaces ranked results with evidence and suggested patch options. (Développeurs OpenAI)
The scan phases described in OpenAI’s developer documentation are a useful model for any AI-assisted security workflow:
- Threat modeling identifies assets, entry points, trust boundaries, and security invariants.
- Finding discovery reviews code for plausible broken controls and source-to-sink paths.
- Validation checks candidates and records evidence or proof gaps.
- Attack-path analysis evaluates realistic reachability, impact, and severity.
- Finalization validates the structured scan contract and generates a report. (Développeurs OpenAI)
That sequence is stronger than “ask an LLM to find bugs.” It gives reviewers a frame for deciding whether a finding deserves engineering time.
A practical review checklist for AI-generated findings should include:
| Evidence type | What it proves | Ce qu'il ne prouve pas |
|---|---|---|
| Source-to-sink path | Data can flow from an input to a sensitive operation | The path is reachable in production |
| Reproduction result | The behavior can be triggered in a controlled environment | The same behavior is exploitable in every deployment |
| Sanitizer output | Memory safety or undefined behavior evidence exists | The exploitability level or affected version range |
| Patch diff | A specific code change addresses the suspected root cause | The change is safe for all use cases |
| Regression test | The reported behavior no longer reproduces | Nearby variants are fully eliminated |
| Threat model note | The issue maps to a trust boundary or asset | The severity is automatically correct |
| Reviewer sign-off | A human accepted the evidence and scope | The system will never regress |
The right goal is not to eliminate human review. The right goal is to make human review more evidence-rich and less repetitive.
Patch the Planet Treats Maintainer Time as the Bottleneck
Patch the Planet is the most interesting part of the announcement because it targets the failure mode that many AI vulnerability tools create: too many plausible reports and not enough trusted remediation capacity.
OpenAI says Patch the Planet begins in consultation with maintainers. Researchers work with projects to understand needs, preferences, and where extra security work is useful, such as validation, patch development, CI/CD improvements, or longer-term security engineering. Once aligned, researchers investigate potential vulnerabilities, validate meaningful issues, develop or refine patches, support testing, and coordinate disclosure through the project’s existing channels. (OpenAI)
Trail of Bits’ own announcement is more concrete. The firm says that in the first week of Patch the Planet, its engineers worked across 19 projects and produced hundreds of discovered bugs, 64 pull requests, and 51 filed issues. It also says 37 pull requests were already merged and that the public tally undercounts the work because several projects use private channels such as HackerOne, GitHub Security Advisories, mailing lists, and private forks. (The Trail of Bits Blog)
The key design choice is that security engineers review every issue before it reaches a maintainer. OpenAI says Trail of Bits researchers reproduce evidence, check findings against project-specific documentation and threat models, remove duplicates, reassess severity, and prioritize confirmed vulnerabilities for remediation. Maintainers remain in control of what patches are deployed and how disclosure is handled. (OpenAI)
That is the difference between “AI-generated vulnerability output” and “maintainer-usable security work.”
| Weak AI-only workflow | Patch the Planet-style workflow | Pourquoi c'est important |
|---|---|---|
| Generate many suspected bugs | Generate, triage, and review candidates | Reduces maintainer noise |
| Submit raw reports | Reproduce evidence before submission | Makes reports actionable |
| Treat severity as model judgment | Reassess severity against project context | Prevents panic and misprioritization |
| Suggest generic patches | Develop patches aligned with maintainer preferences | Improves mergeability |
| Ignore disclosure process | Coordinate through established channels | Preserves trust |
| Stop at “bug found” | Add tests, CI improvements, fuzzing, and infrastructure | Leaves the project stronger |
The “patch” part of Patch the Planet is not a slogan. It is the operational center.
Why the First Projects Matter
The initial Patch the Planet projects are not random. cURL, NATS Server, pyca/cryptography, Sigstore, aiohttp, Go, freenginx, Python, and python.org represent layers that many systems inherit indirectly. A flaw in a network transfer library, cryptographic implementation, package infrastructure, language toolchain, or HTTP stack can have downstream effects far beyond one repository. OpenAI says these projects support networking, cryptography, software supply chain, and language infrastructure. (OpenAI)
That does not mean every downstream user is exposed to every issue found. It means these projects are leverage points. Security improvements at this layer can reduce risk across many dependent systems.
| Infrastructure area | Example projects | Why attackers care | Why defenders care |
|---|---|---|---|
| Networking | cURL, aiohttp, freenginx | Input parsing, protocol state, redirects, headers, TLS usage | Network libraries are widely reused and often exposed to attacker-controlled data |
| Messaging and distributed systems | NATS Server | Authentication, authorization, message routing, clustering | Messaging infrastructure often sits between sensitive internal services |
| Cryptography | pyca/cryptography, RustCrypto | Key handling, serialization, protocol invariants, side-channel mistakes | Crypto bugs are hard to diagnose and costly to patch late |
| Software supply chain | Sigstore, PyPI, python.org | Signing, release workflows, identity, provenance | Supply-chain systems become trust roots for many downstream packages |
| Language infrastructure | Go, Python | Runtime behavior, standard libraries, package tooling | Language ecosystems amplify both vulnerabilities and fixes |
This is where AI-assisted variant analysis and differential testing become useful. A model can help navigate unfamiliar code, generate harnesses, connect similar vulnerability patterns across projects, and produce the glue code needed to test assumptions. But the final step still requires project-specific judgment.
Historical CVE-Driven Variant Analysis Is the New Workhorse
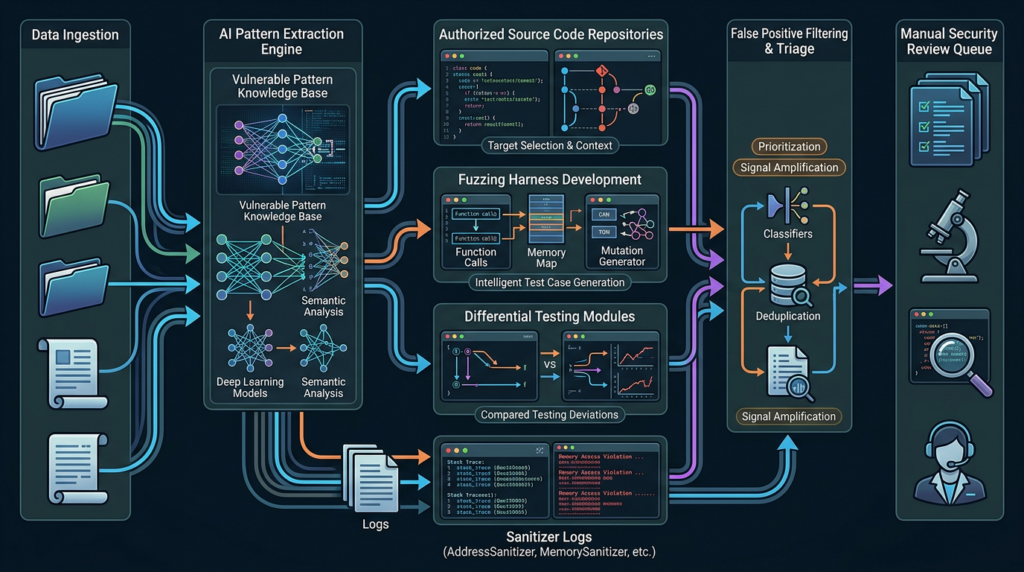
One of the most practical ideas described in the Patch the Planet announcement is a reusable pipeline for finding variants of known vulnerabilities. OpenAI says the team built an end-to-end system that ingests historical CVEs, extracts relevant vulnerability patterns, searches target codebases for related flaws, and sends candidates through specialized judging agents. The pipeline deduplicates results, filters likely false positives, and routes stronger evidence to engineers for manual confirmation. (OpenAI)
That approach is powerful because old vulnerabilities often encode bug classes, not just single bugs. A historical CVE can teach a system to look for related parser mistakes, state-machine violations, missing bounds checks, unsafe lifetime assumptions, or inconsistent security checks across similar code paths.
A safe high-level variant analysis workflow looks like this:
historical_cves.json
|
v
pattern_extractor
|
v
candidate_search_across_authorized_repos
|
v
duplicate_filter
|
v
false_positive_judges
|
v
manual_security_review
|
v
maintainer_report_or_internal_ticket
|
v
patch_review_and_regression_tests
The defensive value is not that the AI magically knows which bugs are exploitable. The value is that it can turn public vulnerability history into a repeatable search strategy, then keep enough context to assist with evidence and patch review.
The dnsmasq example shows why this matters. OpenAI says Codex Security independently identified vulnerable patterns corresponding to four of six dnsmasq CVEs later fixed in 2.92rel2: CVE-2026-4890, CVE-2026-4891, CVE-2026-4892, and CVE-2026-5172. (OpenAI) CERT/CC describes the broader dnsmasq issue set as including DNS cache poisoning, denial of service, and malformed DNS or DHCP-related conditions, including CVE-2026-4890 as a DNSSEC validation infinite-loop flaw that can allow remote denial of service. (kb.cert.org) SUSE’s advisory likewise lists dnsmasq fixes including CVE-2026-4890 for DNSSEC DoS, CVE-2026-4891 for heap-based out-of-bounds read in DNSSEC validation, and CVE-2026-4892 for heap-based out-of-bounds write in DHCPv6 implementation. (SUSE)
The lesson is not “AI found dnsmasq bugs, so patching is solved.” The lesson is that AI-assisted workflows can search for families of known weakness patterns faster than traditional manual review, but still need careful validation and upstream coordination.
Fuzzing Labs Are Where AI Can Save Boring Engineering Time
Fuzzing is not new. Good fuzzing campaigns require harnesses, build variants, seed corpora, coverage feedback, crash triage, minimization, sanitizers, and domain knowledge. The expensive part is often not the fuzzer itself. It is the glue code and maintenance required to aim fuzzing at the right surfaces.
OpenAI says Trail of Bits engineers used repeated Codex goal runs with GPT-5.5-Cyber to build a fuzzing lab covering dozens of entry points, variant builds, platforms, and novel test seeds in less than a day. Trail of Bits estimated the same lab would ordinarily take at least several weeks manually. (OpenAI)
This is exactly the kind of work AI agents are well suited for when supervised by experts: inspect project structure, identify parsers and entry points, draft harnesses, update build scripts, run tests, read failures, adjust the harness, and repeat.
A defensive fuzzing lab might be organized like this:
security-lab/
README.md
targets/
parser_fuzz_target.cc
protocol_state_fuzz_target.cc
config_loader_fuzz_target.cc
corpora/
parser/
protocol/
config/
dictionaries/
protocol.dict
scripts/
build_asan.sh
build_ubsan.sh
run_smoke_fuzz.sh
minimize_crash.sh
ci/
fuzz-smoke.yml
findings/
triage-template.md
A non-destructive CI smoke test might look like this:
name: fuzz-smoke
on:
pull_request:
push:
branches: [ main ]
jobs:
fuzz-smoke:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install build dependencies
run: |
sudo apt-get update
sudo apt-get install -y clang cmake ninja-build
- name: Build sanitizer targets
run: |
./security-lab/scripts/build_asan.sh
- name: Run short fuzz smoke test
run: |
./security-lab/scripts/run_smoke_fuzz.sh --seconds 60
This does not replace a full fuzzing campaign. It catches obvious regressions, keeps harnesses alive, and gives maintainers a place to extend security tests over time. That is often more useful than a one-time crash report.
Differential Testing Turns Protocol Assumptions Into Evidence
OpenAI also describes differential testing as part of the Patch the Planet workflow. The idea is simple: different implementations of the same protocol should usually behave the same way under the same input. When one implementation diverges, the difference may indicate a bug. OpenAI says Codex generated and iterated on shim and glue code so multiple implementations could be fuzzed against one another, producing a higher-signal set of candidates for expert review within days instead of weeks or months. (OpenAI)
Differential testing is especially useful for parsers, encoders, decoders, network protocols, file formats, and cryptographic serialization. It does not automatically prove a security vulnerability. A divergence may mean one implementation is more permissive, one is stricter, the specification is ambiguous, or the harness is wrong. But it gives researchers a sharper question: why did these implementations disagree?
A safe differential testing loop might record:
{
"test_id": "case-0001842",
"input_hash": "sha256:example",
"implementation_a": {
"result": "accepted",
"normalized_output_hash": "sha256:aaa"
},
"implementation_b": {
"result": "rejected",
"error": "invalid length"
},
"implementation_c": {
"result": "accepted",
"normalized_output_hash": "sha256:bbb"
},
"triage_status": "needs_spec_review",
"security_question": "Can an attacker use the acceptance difference to bypass validation?"
}
The AI can help generate the harness and summarize divergences. Humans still need to decide whether the difference is a security boundary violation.
Evidence Is the Difference Between a Finding and a Vulnerability
The security industry has too many “vulnerability-shaped” reports: plausible words, scary severity, weak proof. AI can make that problem worse by generating confident explanations around incomplete evidence. It can also make the problem better if the workflow requires reproducibility and counterevidence.
A strong AI-assisted report should include:
| Report field | Minimum useful content |
|---|---|
| Champ d'application | Repository, commit hash, component, configuration, platform, and authorization basis |
| Attack preconditions | Required access, input channel, feature flags, privileges, network exposure |
| Cause première | The broken invariant, missing check, lifetime error, trust boundary violation, or parser state problem |
| Reachability | How attacker-controlled data reaches the vulnerable code, or why reachability is uncertain |
| Reproduction | Safe local steps, test case, sanitizer output, crash trace, or behavioral proof |
| Impact | What the issue enables under realistic conditions, without overstating exploitability |
| Patch | Minimal diff or clear remediation guidance |
| Vérification | Regression test, before-and-after behavior, and remaining limitations |
| Disclosure status | Private, coordinated, public advisory, fixed release, or downstream notification |
Codex Security’s own scan documentation tells reviewers to inspect root controls or sinks, attacker-controlled input, validation method, remaining uncertainty, realistic reachability, severity rationale, and proposed remediation for each finding. It also tells users to dismiss findings whose evidence does not support the claimed path or impact. (Développeurs OpenAI)
That is a useful standard beyond Codex itself. A security team should not accept an AI-generated vulnerability just because the model can explain it. It should accept a finding when the evidence survives review.
What Daybreak Has Already Found
OpenAI’s Patch the Planet page lists early Daybreak findings across operating systems, network infrastructure, and browsers. The company says it is withholding exploit mechanics and project-specific details where disclosure is still underway, which is the correct posture for serious vulnerability work. (OpenAI)
The operating system examples are notable. OpenAI says GPT-5.5-Cyber identified security-relevant components across more than 30 million lines of Linux kernel code, flagged potential issues, and dynamically validated them, generating eight kernel pointer information leak PoCs and 24 local privilege escalation exploits. OpenAI also clarifies that hundreds of issues were identified and that the PoCs represent the subset for which PoCs were automatically generated. (OpenAI)
That caveat is important. “24 local privilege escalation exploits” is not the same as “24 disclosed Linux CVEs.” It means OpenAI generated working exploit artifacts for a subset of issues in its controlled research process. A precise article should preserve that distinction.
OpenAI also says its models identified a 23-year-old use-after-free in OpenBSD’s kernel implementation of System V semaphores and that researchers reproduced the issue, confirming that an unprivileged local user could escalate privileges to root. For FreeBSD, OpenAI says security researchers at Calif used Codex to find and validate several local privilege escalations, and that a broader FreeBSD campaign confirmed 34 vulnerabilities and produced seven LPE PoCs. (OpenAI)
On the network side, OpenAI cites dnsmasq variant findings and Calif’s “HTTP/2 Bomb” denial-of-service technique affecting major HTTP/2 implementations including NGINX, Apache, IIS, and Pingora. OpenAI says Calif’s analysis suggested that more than 880,000 Internet-facing websites were running affected server software with HTTP/2 enabled. (OpenAI)
On the browser side, OpenAI says its researchers found and reported five exploitable vulnerabilities in Chrome’s V8 JavaScript engine, including three identified and remediated within days of introduction. It also says that in roughly a week of focused WebKit work, over 10 exploitable Safari vulnerabilities were found and reported. (OpenAI)
The Firefox case is the cleanest publicly referenceable CVE example. OpenAI says OpenAI Preparedness identified a WebAssembly vulnerability, CVE-2026-8390, with GPT-5.5 during safety evaluations and that Mozilla patched it two days before Pwn2Own Berlin. NVD describes CVE-2026-8390 as a use-after-free in the JavaScript WebAssembly component fixed in Firefox 150.0.3. (OpenAI)
These examples show why AI-assisted research changes defender timelines. A model that can help navigate kernel code, browser engines, protocol implementations, and long-running open-source projects gives defenders more reach. But the same class of capability also means defenders should assume attackers will move faster.
The Five Eyes Warning Is the Other Half of the Story
The Five Eyes statement is blunt: frontier AI models are anticipated to exceed current industry expectations and fundamentally transform both offensive and defensive cyber capabilities on a timeline measured in months, not years. The statement also says AI lowers barriers for malicious actors, increases the speed and complexity of attacks, and shrinks the window between vulnerability discovery and exploitation. (NSA)
That warning should change how organizations think about patch windows. The old rhythm was often quarterly scans, periodic penetration tests, manual triage, and delayed remediation. That rhythm was already too slow for internet-facing systems. AI makes it less defensible.
Five Eyes agencies recommend reducing attack surface, accelerating patching processes, addressing legacy systems, strengthening identity and access controls, and preparing for incidents before they happen. They also say defenders must use AI to strengthen defense because adversaries are already using AI to move faster. (NSA)
A practical response should not be “buy more tools.” The statement itself warns that success will not come from having the most tools. It will come from getting the basics right, acting quickly, and integrating cybersecurity into business strategy. (NSA)
For security teams, that means AI security adoption should be tied to concrete outcomes:
| Résultats | Bad metric | Better metric |
|---|---|---|
| Vulnerability discovery | Number of alerts generated | Confirmed reachable findings per scoped asset |
| Patch speed | Time to create a ticket | Time from accepted finding to merged fix |
| Patch quality | Patch exists | Regression test proves vulnerable behavior no longer reproduces |
| Risk prioritization | CVSS alone | Exposure, exploitability, privilege, asset value, KEV, EPSS, business impact |
| Rapports | PDF generated | Evidence package supports replay, review, audit, and retest |
| La résilience | Tool count | Reduced external exposure and tested incident response |
AI changes the speed of the race. It does not remove the need for disciplined security engineering.
A Practical AI-Assisted Remediation Workflow
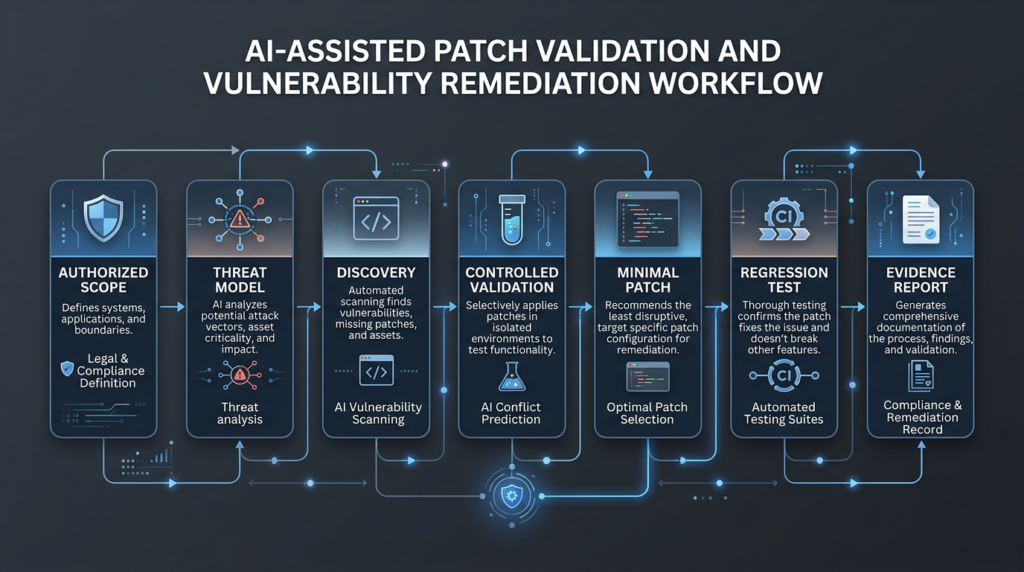
A serious AI vulnerability workflow should be designed as a controlled loop. The model may assist each stage, but the workflow should preserve scope, evidence, review, and rollback.
Step 1, Define scope and authorization
Before scanning, define the authorized target:
Target: internal repository or owned application
Commit: 4f7c9e1
Environment: local test container and staging only
Out of scope: production systems, third-party services, customer data
Allowed actions: static analysis, local tests, fuzzing harnesses, dependency review
Disallowed actions: unsolicited internet scanning, credential access, persistence, production exploitation
Reviewer: security engineering owner
This may feel bureaucratic, but it prevents the most dangerous failure mode: a powerful model operating without boundaries.
Step 2, Build a threat model before chasing bugs
Threat modeling should be specific. “Find vulnerabilities” is weak guidance. Better guidance names assets, entry points, trust boundaries, and security invariants.
Assets:
- user session tokens
- payment webhook secrets
- tenant isolation metadata
- admin-only configuration state
Entry points:
- public REST API
- webhook receiver
- file upload endpoint
- background job queue
Trust boundaries:
- unauthenticated internet user to API
- authenticated user to tenant-owned resources
- webhook provider to internal event processor
- CI runner to release signing workflow
Security invariants:
- tenant A must never read tenant B data
- webhook payloads must be verified before processing
- user-controlled file names must not influence storage paths
- admin actions require both role and audit logging
This kind of context helps AI tools and human reviewers avoid generic findings.
Step 3, Combine multiple discovery methods
AI should not replace established tools. It should orchestrate and interpret them.
Useful inputs include:
# Dependency audit for known vulnerable packages
npm audit --omit=dev
# Semgrep rules for common application security patterns
semgrep scan --config p/owasp-top-ten --json --output semgrep.json
# CodeQL database creation and analysis for supported languages
codeql database create codeql-db --language=javascript --source-root .
codeql database analyze codeql-db security-and-quality.qls --format=sarif-latest --output codeql.sarif
# Unit and integration tests before remediation
npm test
The model can summarize tool output, correlate it with application context, propose areas for manual review, and suggest additional tests. It should not be the only source of truth.
Step 4, Validate in a controlled environment
A finding becomes useful when it is tied to a reproducible condition. For a web application bug, that might be a local request against a test server. For a parser bug, it might be a unit test or fuzz case. For a memory bug, it might be sanitizer output.
A validation note should look like this:
Finding: tenant authorization bypass in invoice export route
Preconditions:
- attacker must be authenticated as a normal tenant user
- attacker must know or guess another tenant's invoice ID
- vulnerable route is enabled in default production configuration
Evidence:
- local integration test creates tenant A and tenant B
- tenant A user requests tenant B invoice export
- vulnerable build returns HTTP 200 with tenant B invoice metadata
- patched build returns HTTP 403
- regression test added: test_invoice_export_rejects_cross_tenant_access
This is more useful than a paragraph saying “access control may be broken.”
Step 5, Patch minimally and test behavior
A good security patch is often smaller than an AI agent wants to make it. Prefer minimal changes that enforce the violated invariant.
- const invoice = await invoices.getById(req.params.invoiceId);
+ const invoice = await invoices.getByIdForTenant(
+ req.params.invoiceId,
+ req.user.tenantId
+ );
if (!invoice) {
return res.status(404).json({ error: "not found" });
}
Then add regression coverage:
it("rejects cross-tenant invoice export", async () => {
const tenantA = await fixtures.createTenant();
const tenantB = await fixtures.createTenant();
const userA = await fixtures.createUser({ tenantId: tenantA.id });
const invoiceB = await fixtures.createInvoice({ tenantId: tenantB.id });
const res = await request(app)
.get(`/invoices/${invoiceB.id}/export`)
.set("Authorization", fixtures.authHeader(userA));
expect(res.status).toBe(403);
});
The point is not that this example maps to OpenAI’s announcement directly. The point is that any AI-assisted remediation system should converge on reviewable evidence, minimal patches, and regression tests.
Step 6, Retest and preserve an evidence package
A remediation package should include:
- original finding summary
- affected commit and patched commit
- reproduction steps in a local or staging environment
- test output before and after patch
- patch diff
- known limitations
- reviewer sign-off
- release or deployment status
This is where AI-assisted security becomes operational. The team is not just finding bugs; it is creating a defensible record of risk reduction.
For organizations running authorized testing against web applications, APIs, business logic, or agentic systems, this evidence-first workflow is also where AI-assisted pentesting platforms can complement code-side review. Penligent describes itself as an AI-powered penetration testing tool for authorized security testing, and its related analysis of AI vulnerability research argues that AI is compressing the patch window, making verified reproduction and remediation workflows more important for defenders. (Penligent) The useful pattern is not “let an agent do everything.” It is to connect discovery, controlled validation, evidence capture, retesting, and report generation so teams can act on confirmed risk rather than raw alerts.
Where AI-Generated Fixes Commonly Fail
AI-generated patches fail in predictable ways. Teams should review for these patterns before accepting any fix.
| Failure mode | Exemple | Review question |
|---|---|---|
| Symptom patching | Blocks one payload but not the root parser flaw | Did the patch enforce the violated invariant? |
| Overbroad rejection | Rejects valid user input to avoid a crash | Does the fix preserve expected behavior and compatibility? |
| Incomplete authorization | Checks role but not tenant boundary | Does the patch cover the actual trust boundary? |
| Unsafe refactor | Rewrites unrelated code and creates new bugs | Is the patch minimal and reviewable? |
| Missing regression test | Fix appears correct but has no test | Will CI catch this if it returns? |
| Version ambiguity | Patch applies to one branch but not maintained releases | Which versions are affected and fixed? |
| Exploitability overclaim | Model assumes remote exploitability without reachability proof | What preconditions are actually required? |
The safer pattern is to ask AI for candidate fixes and tests, not final authority. The final authority should be a reviewer who understands the code, the deployment model, and the project’s compatibility requirements.
Open-Source Maintainers Need Intake Standards
Patch the Planet’s maintainer-first design is important because AI-generated reports can create real costs for open-source projects. A maintainer receiving 200 plausible but unreviewed reports is not safer. They are interrupted.
Maintainers should require a minimum evidence standard for AI-assisted reports:
# Vulnerability report intake template
## Summary
One-sentence description of the suspected issue.
## Affected component
Repository, file, function, version or commit.
## Preconditions
Required privileges, configuration, platform, and exposure.
## Reproduction
Steps in a local test environment. No production targets.
## Evidence
Test output, crash trace, sanitizer log, failing regression test, or source-to-sink path.
## Impact
Realistic impact under stated preconditions.
## Proposed fix
Minimal patch or remediation guidance.
## Verification
How the reporter confirmed the fix works.
## Disclosure preference
Private advisory, embargo request, public issue, or maintainer-defined process.
Reports that cannot meet this standard can be triaged as low priority or returned for more information. That is not hostility toward AI-assisted research. It is how maintainers protect their time.
Security Teams Should Prioritize Reachable Risk
AI-assisted discovery increases the number of candidate issues. Prioritization becomes more important, not less.
A practical scoring model should combine:
| Signal | Pourquoi c'est important |
|---|---|
| Internet exposure | Externally reachable bugs usually require faster action |
| Authentication requirement | Unauthenticated bugs often carry higher urgency |
| Privilege level | Local, authenticated, admin-only, and unauthenticated paths differ |
| Criticité des actifs | Bugs touching identity, payment, secrets, signing, and tenant isolation deserve priority |
| Exploit maturity | Public exploitation or reliable PoC changes urgency |
| CISA KEV status | Known exploited vulnerabilities demand operational response |
| EPSS | Helps estimate exploitation likelihood, though it should not be used alone |
| Patch availability | A fixed upstream version changes the remediation path |
| Impact sur les entreprises | Availability, confidentiality, integrity, compliance, and customer trust differ by asset |
This is also why CVSS alone is insufficient. CVSS describes technical severity, not business risk in a specific environment. A medium-severity bug in an internet-facing identity service may deserve faster action than a high-severity bug in an unreachable lab component.
The Relationship Between Code Review and Pentesting Is Changing
GPT-5.5-Cyber and Codex Security focus heavily on code-aware workflows. That is valuable, but code review and penetration testing answer different questions.
Code-aware AI analysis asks:
Can we inspect this codebase, identify likely vulnerabilities, validate reachability, and propose patches?
Authorized penetration testing asks:
From the outside or from a defined attacker role, what can actually be reached, abused, chained, or misconfigured in the deployed system?
Both are needed. A code-level authorization bug may not be exposed because a route is disabled. A production misconfiguration may not be obvious from code. A dependency CVE may be unreachable. A business logic flaw may require workflow abuse rather than a source-code sink.
The mature workflow connects both sides:
Code finding -> controlled proof -> patch -> deploy -> retest from attacker perspective -> report evidence
That final retest is critical. A patch that looks correct in code may fail in production because a second path remains exposed, a cache layer bypasses new logic, or an API gateway route still permits old behavior.
How to Add AI Security Review to CI Without Creating Chaos
Security automation should be staged. Do not start by blocking every pull request on every AI-generated finding. Start with visibility, evidence, and calibration.
A conservative CI workflow might look like this:
name: security-review
on:
pull_request:
push:
branches: [ main ]
jobs:
static-security:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Run Semgrep
run: |
pipx install semgrep
semgrep scan --config p/owasp-top-ten --sarif --output semgrep.sarif || true
- name: Run tests
run: |
npm ci
npm test
- name: Upload security artifacts
uses: actions/upload-artifact@v4
with:
name: security-artifacts
path: |
semgrep.sarif
coverage/
test-results/
Then route findings through review:
Phase 1: Non-blocking alerts for security team review
Phase 2: Blocking only for confirmed high-confidence regressions
Phase 3: Auto-create tickets for accepted findings with evidence
Phase 4: Require regression tests for security fixes
Phase 5: Retest patched behavior before release
AI can summarize artifacts, propose patches, and draft tickets. Blocking decisions should be based on confidence, severity, and maturity of the rule or finding type.
Lessons From CVE-2026-8390 and Browser-Class Bugs
CVE-2026-8390 is a useful example because it shows how AI-assisted discovery can intersect with high-value targets without requiring public exploit details. NVD describes it as a use-after-free in Firefox’s JavaScript WebAssembly component, fixed in Firefox 150.0.3. OpenAI says the vulnerability was identified with GPT-5.5 during safety evaluations and patched by Mozilla before Pwn2Own Berlin, with no successful Firefox exploit demonstrated at the competition. (NVD)
Why is this relevant to GPT-5.5-Cyber and Patch the Planet?
First, browser engines are complex, high-impact targets where memory safety, JIT behavior, WebAssembly, sandboxing, and cross-platform behavior interact. A model that helps researchers navigate those interactions can accelerate legitimate defensive research.
Second, the fix mattered more than the finding. The public safety value came from Mozilla patching the issue before a competition where exploit attempts were expected. That reinforces the remediation-first theme.
Third, the disclosure boundary mattered. Public sources can describe the affected component and patched version without publishing exploit mechanics. That is the correct balance for a high-risk browser vulnerability.
The same principle applies to kernel LPEs, HTTP/2 DoS techniques, and DNS infrastructure bugs. Security writing should explain risk and remediation without turning a defensive article into an exploit manual.
What Defenders Should Do Now
Organizations do not need to wait for universal access to GPT-5.5-Cyber to improve. The workflow changes are available now.
Start with assets and exposure. Identify internet-facing services, identity systems, CI/CD pipelines, signing infrastructure, customer data paths, and business-critical APIs. AI-assisted analysis is most useful when pointed at assets that matter.
Then improve evidence standards. Every accepted finding should have a clear reproduction path, reachability analysis, affected version or commit, remediation recommendation, and verification plan.
Next, shorten the patch loop. Security teams should measure time from accepted finding to merged fix, deployed fix, and verified fix. Those are different milestones.
Finally, add AI where it reduces toil. Good use cases include threat model drafting, source-to-sink exploration, test generation, fuzz harness scaffolding, dependency incident review, patch explanation, and report drafting. Bad use cases include unsupervised scanning of third-party systems, auto-merging security patches without review, or mass-submitting unvalidated reports to maintainers.
Erreurs courantes
Treating every AI finding as true
AI systems can produce plausible false positives. Require reproduction, reachability, or clear proof gaps before assigning severity.
Treating every AI patch as safe
A patch can remove a crash while breaking compatibility, weakening authentication, or hiding a deeper invariant violation. Review minimality and add regression tests.
Ignoring deployment context
A vulnerability may depend on configuration, platform, compiler flags, feature flags, or network exposure. Code evidence must be mapped to actual deployment.
Submitting raw AI reports to open-source maintainers
Maintainers need evidence, not model confidence. Submit fewer, better reports with reproduction steps and patch suggestions.
Using AI only for discovery
The highest-value work is often after discovery: deduplication, validation, severity correction, patch generation, testing, and documentation.
Confusing exploitability with impact
A crash, out-of-bounds read, or use-after-free may be serious, but realistic impact depends on attacker control, environment, mitigations, and reachable paths.
Forgetting the attacker side of the equation
Five Eyes agencies warn that AI also accelerates offensive work. Defensive teams should assume attackers will use similar acceleration and reduce remediation delay accordingly. (NSA)
FAQ
What is OpenAI GPT-5.5-Cyber?
- GPT-5.5-Cyber is OpenAI’s specialized model for advanced, authorized cybersecurity work.
- OpenAI describes the updated model as its strongest yet for finding and helping patch software vulnerabilities.
- It is intended for verified defenders, not unrestricted public offensive use.
- Its reported strengths include large-codebase analysis, reachability reasoning, controlled validation, patch development, testing, and evidence preparation. (OpenAI)
What is Patch the Planet?
- Patch the Planet is a Daybreak initiative built by OpenAI with Trail of Bits to support open-source maintainers.
- It pairs AI-assisted vulnerability research with expert human review.
- The workflow includes validation, severity review, patch development, testing, disclosure coordination, and deployment support.
- Initial participants include projects such as cURL, NATS Server, pyca/cryptography, Sigstore, aiohttp, Go, freenginx, Python, and python.org. (OpenAI)
Is GPT-5.5-Cyber publicly available?
- No, not as a normal unrestricted public model.
- OpenAI says GPT-5.5-Cyber is released through continued limited access to trusted defenders.
- For most defensive teams, OpenAI positions GPT-5.5 with Trusted Access for Cyber and Codex Security as the starting point.
- Access is paired with stronger verification, monitoring, scoped controls, and review. (OpenAI)
How is Codex Security different from traditional SAST?
- Traditional SAST often relies heavily on patterns and can produce noisy findings.
- Codex Security is designed to use repository-specific context, threat modeling, validation evidence, and suggested patch options.
- OpenAI’s documentation says Codex Security cloud validates high-signal issues in an isolated environment before surfacing them.
- It still requires human review; the advantage is richer context and a workflow closer to remediation. (Développeurs OpenAI)
Can AI-generated vulnerability reports be trusted?
- They can be useful, but they should not be trusted blindly.
- A strong report needs scope, preconditions, reachability, reproduction evidence, realistic impact, patch guidance, and verification.
- Reports without evidence should be treated as leads, not confirmed vulnerabilities.
- Human review remains essential, especially for severity, exploitability, and patch safety.
What should maintainers do when AI reports a vulnerability?
- Ask for a minimal reproduction in a local environment.
- Require affected version or commit information.
- Ask for realistic preconditions and impact, not just a scary label.
- Prefer reports that include a small patch and regression test.
- Use private disclosure channels for potentially serious issues.
- Reject or defer reports that cannot provide evidence.
How should security teams validate an AI-generated fix?
- Reproduce the vulnerable behavior before applying the patch.
- Apply the smallest reasonable fix.
- Add a regression test that fails before the patch and passes after it.
- Run unit, integration, and security-specific tests.
- Retest from the attacker perspective where appropriate.
- Document remaining uncertainty and affected versions.
Does AI vulnerability discovery increase attacker risk?
- Yes, it can. The same capabilities that help defenders find and fix bugs can help attackers move faster.
- Five Eyes cyber agencies warn that AI lowers barriers for malicious actors and shrinks the window between vulnerability discovery and exploitation.
- The defensive response is not to ignore AI, but to use it inside controlled workflows that accelerate validation, patching, exposure reduction, and incident readiness. (NSA)
The Real Shift Is Remediation Capacity
OpenAI GPT-5.5-Cyber and Patch the Planet signal a new phase in software security. The headline capability is not simply that AI can find more bugs. The deeper change is that AI can help connect discovery to validation, validation to patching, patching to tests, and tests to evidence that humans can review.
That is also where the risk concentrates. If organizations use AI to generate more alerts without improving triage and patching, they will overload the same bottlenecks they already have. If they use AI to strengthen scoped review, reproduce issues safely, prioritize reachable risk, generate minimal fixes, and verify remediation, they can shorten the window that attackers increasingly seek to exploit.
The best defensive posture is disciplined acceleration: smaller attack surfaces, faster patch loops, better evidence, stronger identity controls, tested incident response, and AI workflows that keep human maintainers and security engineers in control.
