If you are asking which model is “best for cybersecurity,” you are already mixing together at least three different questions. One is about access: which model a real security team can actually pilot this quarter. Another is about workflow fit: which model helps with the kind of security work most teams do every day, such as patch review, configuration triage, binary analysis, detection support, or report writing. The third is about frontier capability: which model appears to be pushing hardest on vulnerability discovery and exploit development. OpenAI’s GPT-5.4-Cyber and Anthropic’s Claude Mythos Preview do not sit at the same point on that triangle, so treating them like ordinary “chatbot A versus chatbot B” competitors misses the point. (OpenAI)
The best short answer, based on public evidence, is not a single winner. GPT-5.4-Cyber has the stronger case if the question is deployable defender access and practical entry into real security workflows today. Claude Mythos Preview has the stronger public signal if the question is frontier exploit research, zero-day capability, and how far general-purpose models may now reach into serious vulnerability work. Those are different wins, and security buyers should not pretend otherwise. (OpenAI)
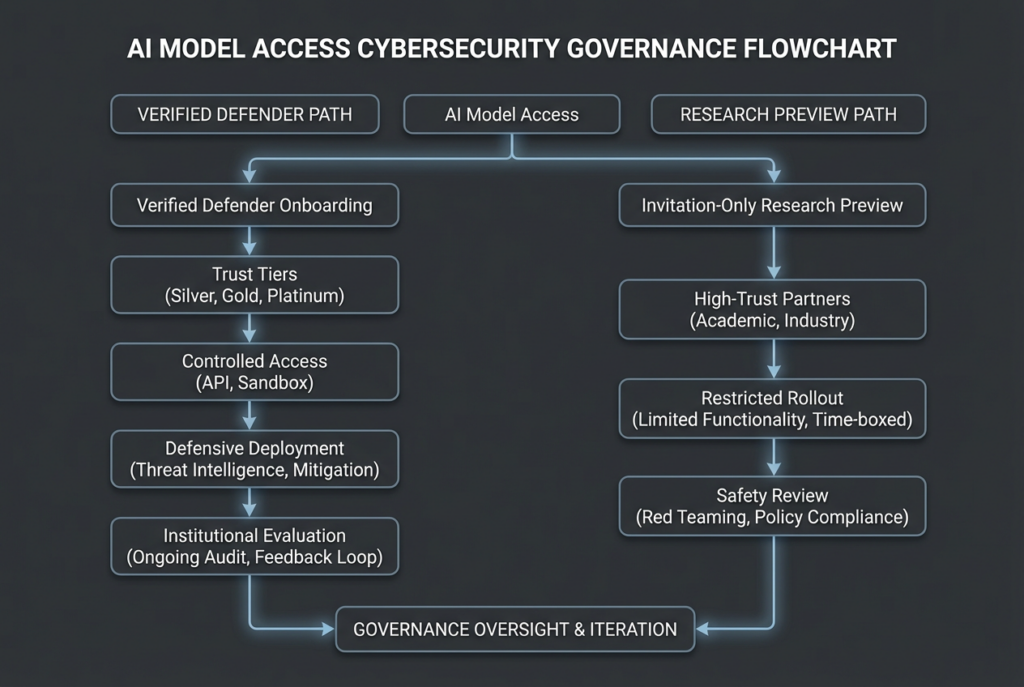
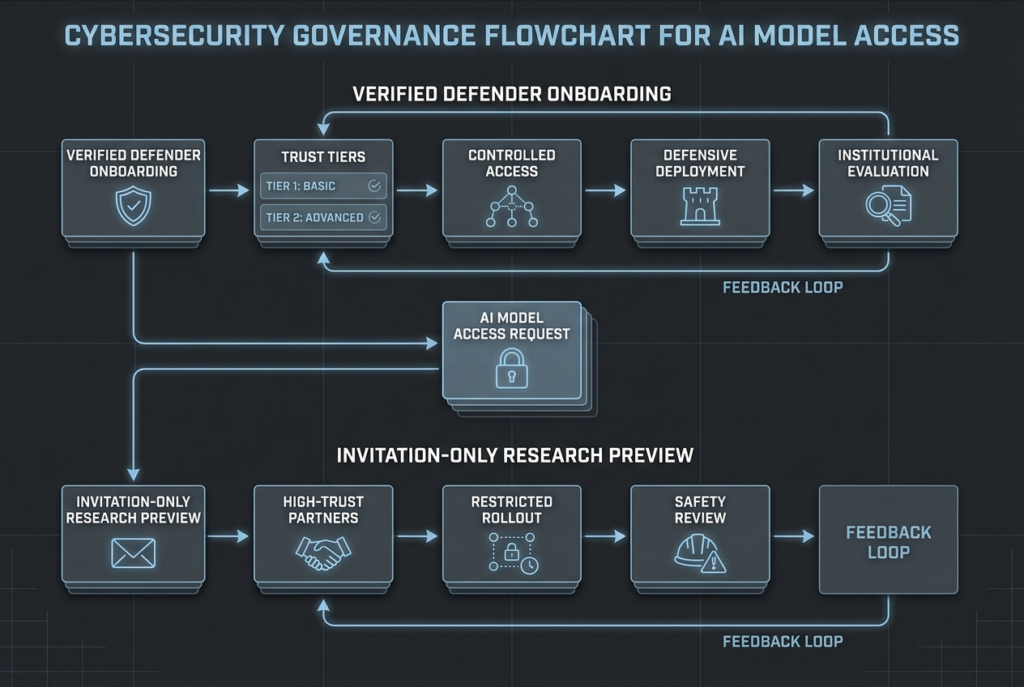
That distinction matters because both vendors are now handling cyber capability differently from ordinary model rollout. OpenAI has expanded Trusted Access for Cyber and placed GPT-5.4-Cyber behind higher verification tiers for defenders. Anthropic has put Mythos Preview into Project Glasswing as an invitation-only research preview tied to critical software defense. The delivery model is part of the model. In cyber, access control, deployment restrictions, auditability, and public evidence are not side details. They are part of the product. (OpenAI)
What OpenAI Has Actually Released
OpenAI first introduced Trusted Access for Cyber in February 2026 as an identity- and trust-based framework intended to reduce friction for legitimate cyber work while still preventing clearly prohibited activity. In that initial TAC announcement, OpenAI said users could verify identity through a dedicated cyber pathway, enterprises could request team access, and researchers needing even more permissive models could express interest in an invite-only program. The same announcement committed $10 million in API credits through the Cybersecurity Grant Program. (OpenAI)
On April 14, OpenAI expanded TAC and tied that expansion to GPT-5.4-Cyber. The company said it was scaling the program to thousands of verified individual defenders and hundreds of teams responsible for defending critical software. In OpenAI’s own wording, GPT-5.4-Cyber is a GPT-5.4 variant trained to be cyber-permissive, with fewer capability restrictions, a lower refusal boundary for legitimate cybersecurity work, and support for advanced defensive workflows including binary reverse engineering without source access. That is a very specific positioning statement. It is not just “our newest general model is good at security.” It is a declaration that a separate deployment track exists for cyber work. (OpenAI)
OpenAI also makes clear that the program is still being rolled out carefully. Because GPT-5.4-Cyber is more permissive, the company says it is starting with limited iterative deployment to vetted vendors, organizations, and researchers. It also notes that access to cyber-capable models may come with limitations in low-visibility usage settings, including some zero-data-retention scenarios and third-party platform usage where OpenAI has less direct visibility into the user and environment. For security teams in regulated environments, that caveat matters just as much as raw capability claims. (OpenAI)
A few days later, OpenAI announced that major security vendors and enterprises had joined TAC, and said GPT-5.4-Cyber had also been provided to the U.S. Center for AI Standards and Innovation and the UK AI Security Institute for cyber-capability and safeguard evaluations. That does not prove superiority over any competing model, but it does show OpenAI is trying to move GPT-5.4-Cyber into a broader defensive evaluation ecosystem rather than keeping it as a tiny private experiment. (OpenAI)
There is another layer here that often gets ignored in security conversations. Publicly available GPT-5.4 is already presented by OpenAI as a model with native computer-use capability, strong agentic web search, and up to 1 million tokens of context in Codex’s experimental long-context mode. OpenAI also reports leading or near-leading scores on OSWorld-Verified, BrowseComp, and other tool-use or computer-use evaluations for GPT-5.4. OpenAI has not published a separate public GPT-5.4-Cyber spec sheet with its own context matrix or tool-support table, but the company is clearly building the cyber variant on top of a model family already optimized for long-horizon tool use and interface-driving work. That is highly relevant to modern security workflows, which increasingly involve browsers, terminals, screenshots, structured tools, and long artifact chains rather than single-turn question answering. (OpenAI)
What Anthropic Has Actually Released
Anthropic’s public posture is almost the inverse. Project Glasswing is not framed as a broad-access trusted tier for defenders. It is framed as an initiative to secure the world’s most critical software with early access to a frontier model, Claude Mythos Preview. Anthropic says Glasswing launched with major partners including Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks, and that access has also been extended to more than 40 additional organizations that build or maintain critical software infrastructure. Anthropic says it has committed up to $100 million in usage credits and $4 million in donations to open-source security organizations for this effort. (anthropic.com)
Anthropic’s own model documentation is blunt about access. In the Claude model overview, Claude Mythos Preview is described as a research preview model for defensive cybersecurity workflows, offered separately as part of Project Glasswing, with invitation-only access and no self-serve signup. That one line alone changes the practical meaning of comparison. A model can be more impressive in frontier terms and still be less useful to most security teams this year if almost none of them can touch it. (Claude API Docs)
Project Glasswing’s model page adds more detail. Anthropic describes Mythos Preview as a general-purpose frontier model whose cyber strength is a consequence of broader coding and agentic ability. It says Mythos Preview has already identified thousands of zero-day vulnerabilities across critical infrastructure and that Project Glasswing participants can access it through the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry at a published research-preview price of $25 per million input tokens and $125 per million output tokens. OpenAI has not published a separate public price for GPT-5.4-Cyber, so on public documentation alone Anthropic is paradoxically tighter on access but clearer on some operational details. (anthropic.com)
Anthropic’s red-team writeup is also unusually explicit. The company says Mythos Preview is strikingly capable at computer security tasks, describes cases involving browser exploitation, local privilege escalation, and remote code execution, and says the model’s exploit capabilities emerged from broader gains in code, reasoning, and autonomy rather than an explicit exploit-training objective. In the public writeup Anthropic says Mythos Preview produced working Firefox exploit outcomes 181 times on a benchmark where Opus 4.6 managed only two successful exploit results in several hundred attempts, and says Mythos reached full control-flow hijack on ten fully patched OSS-Fuzz targets. Even if one remains cautious about extrapolating vendor-published evals, these are far stronger public claims than the industry was hearing from frontier model vendors a year earlier. (Red Anthropic)
The same red-team page says Anthropic has identified thousands of additional high- and critical-severity vulnerabilities that it is working to disclose responsibly. It reports that in a manually reviewed set of 198 vulnerability reports, expert contractors agreed exactly with Claude’s severity assessment 89 percent of the time and were within one severity level 98 percent of the time. Those figures do not tell us how Mythos would perform in your environment, on your proprietary code, or against your web estate. They do tell us Anthropic is putting unusually strong public weight behind the claim that frontier language models are moving beyond “helpful assistant for bug triage” and into much more consequential vulnerability work. (Red Anthropic)
Anthropic’s public safety material reinforces how seriously it takes that shift. In the public version of its Mythos Preview risk report, Anthropic says the model is used heavily within the company for coding, data generation, and other agentic use cases, is available to certain customers in a limited-release research preview, is not available for general access, and presents overall risk assessed as “very low, but higher than for previous models.” The report also says Mythos is significantly more capable, and used more autonomously and agentically, than prior models, especially in software engineering and cybersecurity tasks. That combination of high capability and heightened caution is central to understanding why Mythos is being deployed the way it is. (anthropic.com)
Anthropic’s implementation details matter too. Public docs say Mythos Preview has a 1 million token context window. They also say some tool behavior differs from ordinary Claude usage: web search is available for Mythos on the Claude API, Microsoft Foundry, and Vertex AI but not on Bedrock; code execution is supported on the Claude API and Microsoft Foundry only; forced tool use is not supported on Mythos; and prefilled final assistant messages are not supported. None of these constraints make Mythos weaker. They do mean teams evaluating it for production agent workflows need to read the fine print rather than assuming every Claude feature works the same way across every endpoint. (Claude API Docs)
The Access Model Is Part of the Security Model
Many AI comparisons treat access as an annoying commercial footnote. In security, it is often the first practical differentiator.
A model that is slightly weaker in frontier exploit work but reachable through a defensible verification program may do more for a real blue team than a stronger model locked behind invitations and strategic partnerships. OpenAI’s public materials point in exactly that direction. TAC is designed for verified defenders at scale, with individual identity verification, enterprise pathways, and additional access tiers for teams willing to authenticate themselves further as legitimate cyber defenders. That is not open access, but it is visibly closer to being a real program for working security practitioners. (OpenAI)
Anthropic’s public materials point in the opposite direction. Glasswing is explicitly about early access for organizations defending critical software and infrastructure, not about letting the wider security market experiment freely. That is a rational choice if you believe your model’s exploit capabilities are already strong enough to change the threat landscape. It is also a choice that narrows today’s addressable audience. For most readers, the question is not whether Mythos sounds impressive. It is whether their team can realistically obtain and govern it. Right now, Anthropic’s own docs say the answer is invitation only. (anthropic.com)
OpenAI and Anthropic are therefore solving different deployment problems. OpenAI appears focused on expanding defensive uptake while maintaining verification and safety controls. Anthropic appears focused on containing a sharper capability jump while it learns from high-trust users and designs a safer release path. Anthropic’s Opus 4.7 launch makes that explicit: the company says Mythos will stay limited while new cyber safeguards are tested first on the less capable Opus 4.7, whose cyber capabilities are stated to be below Mythos. That is not just product sequencing. It is deployment philosophy. (anthropic.com)
If you are a CISO, product security lead, or procurement owner, that difference should change your buying questions. With GPT-5.4-Cyber, you should be asking whether your team can satisfy the TAC verification path, what data-visibility constraints apply to your environment, and how much value the more permissive model adds over standard GPT-5.4 in the tasks you actually care about. With Mythos Preview, the first question is whether you can get access at all; the second is whether your organization is mature enough to use a research-preview frontier cyber model in a tightly measured way rather than as a magical shortcut. (OpenAI)
Public Capability Claims, What Is Confirmed and What Is Not
The strongest public statement OpenAI makes about GPT-5.4-Cyber is not a benchmark number. It is the claim that the model lowers the refusal boundary for legitimate cybersecurity work and adds capabilities for advanced defensive workflows, including binary reverse engineering of compiled software without source access. That matters because binary analysis is not just another coding task. It is closer to the edge of what makes security models genuinely useful when source code is unavailable, incomplete, or untrusted. If OpenAI’s public description maps well to production behavior, that could make GPT-5.4-Cyber unusually valuable for malware triage, appliance review, patch-diff analysis, and compiled-target assessment. (OpenAI)
The strongest public statement Anthropic makes about Mythos is more dramatic. Its red-team page says Mythos can autonomously identify and exploit serious vulnerabilities, including a browser chain, privilege escalation on operating systems, and remote code execution in FreeBSD’s NFS path. It also says Anthropic researchers with no formal security training have been able to ask Mythos to find remote code execution vulnerabilities overnight and receive working exploits by morning. That does not mean non-experts will suddenly become elite exploit developers on command. It does mean Anthropic is comfortable saying, in public, that the exploit-generation ceiling has moved sharply upward. (Red Anthropic)
At the same time, the public evidence remains asymmetric. OpenAI has published a clear access program and a clear cyber-permissive positioning statement, but not a rich public benchmark package specifically for GPT-5.4-Cyber. Anthropic has published richer frontier cyber claims and research-preview details for Mythos, but access remains tightly restricted and the broader market still cannot reproduce those results independently at scale. A serious comparison has to account for both asymmetries. If you ignore OpenAI’s easier defensive path, you miss practical value. If you ignore Anthropic’s much stronger published frontier exploit claims, you miss where the upper bound appears to be moving. (OpenAI)
Publicly available GPT-5.4 adds another clue. OpenAI says GPT-5.4 is the first general-purpose model it has released with native computer-use capability, strong browser and desktop performance, and agentic web-search gains. That matters because modern security work often fails not on raw reasoning but on operator loops: login flows, tool dispatch, artifact retrieval, config reading, repeated tests, and adaptive navigation through weird interfaces. Even before the cyber-tuned variant enters the picture, OpenAI is telling us its mainline frontier model is built to act in software environments, not just describe them. (OpenAI)
Mythos, by contrast, looks strongest where the task smells like deep software reasoning under high information density. Anthropic describes its cyber gains as a consequence of broader coding and agentic strength, not as a narrow hack-model specialization. That framing matters. A model that understands large software systems deeply enough to find and patch bugs may also become unusually strong at reverse reasoning from a patch to an exploit, from a crash to a root cause, or from a binary to a plausible source-level model of behavior. Anthropic’s public materials do not prove Mythos is the best model for every security task. They do strongly suggest it is the most important public signal right now that general-purpose models are crossing into serious vulnerability research territory. (anthropic.com)
Why Generic Benchmark Wins Do Not Settle Cybersecurity Work
Security teams make a mistake when they read one vendor’s coding score or long-context number and assume it answers the operational question. Research on LLM-based pentesting and vulnerability testing keeps showing why that shortcut fails.
The 2024 PentestGPT paper is still one of the cleanest statements of the problem. The authors built a benchmark around real penetration-testing targets and found that LLMs were competent at specific subtasks such as tool use, output interpretation, and suggesting next actions, but struggled to maintain the whole context of the testing scenario. That gap between local competence and end-to-end coherence is one of the oldest failure modes in LLM-assisted security work, and it has not disappeared just because frontier vendors now publish stronger cyber headlines. (USENIX)
AutoPenBench sharpens the point. Its benchmark includes 33 tasks spanning both in-vitro and real-world scenarios and compares fully autonomous against assisted penetration-testing agents. In the paper’s abstract, the fully autonomous agent achieves only a 21 percent success rate across the benchmark, while the assisted agent reaches 64 percent. The lesson is not that AI is useless in pentesting. It is that structure, scaffolding, and human intervention still matter a great deal, especially as tasks become messier and less scripted. (arXiv)
PentestEval pushes the argument even further. The paper decomposes penetration testing into multiple stages, uses 346 tasks across 12 realistic scenarios, and reports that end-to-end pipelines reach only a 31 percent success rate, with autonomous agents failing almost entirely. That is not a minor caveat. It means any claim that a frontier model is “best for cybersecurity” needs to be read through a stage-based lens. Models do not fail or succeed in one monolithic blob called security. They fail differently at information collection, weakness filtering, attack decision-making, exploit generation, revision, validation, and reporting. (arXiv)
That is why public vendor claims should be read as directional, not as complete procurement answers. OpenAI’s cyber-permissive defender model tells you something valuable about deployability and tool-facing workflows. Anthropic’s exploit-heavy Mythos disclosures tell you something valuable about upper-bound software security capability. Neither one eliminates the need for your own staged evaluation harness. The right mental model is not “Which model wins cyber.” It is “Which model fails least badly on the tasks I care about, with the evidence, permissions, and tooling I will actually provide.” (OpenAI)
A More Useful Way to Compare Cyber Models
Traditional pentest and security-assessment frameworks are still useful here, because they remind us what real security work looks like. NIST SP 800-115 is about planning and conducting technical security tests, analyzing findings, and developing mitigation strategies. OWASP’s Web Security Testing Guide is organized around information gathering, configuration review, identity, authentication, authorization, input validation, business logic, client-side testing, API testing, and reporting. That stage-oriented reality is a better foundation for model evaluation than a generic “best AI” leaderboard. (csrc.nist.gov)
Once you use that lens, the comparison gets clearer.
If the workload is heavy on interface driving, browser or desktop interaction, multi-step operator loops, and tool-mediated state changes, OpenAI’s public positioning gives GPT-5.4-Cyber a strong story. OpenAI is explicitly tying the cyber variant to reduced refusal friction for legitimate security work, while general GPT-5.4 is already being presented as a computer-use and agentic-search model. That combination is promising for tasks such as authenticated workflow testing, config verification across internal admin panels, reproducing complex abuse cases, or using security tools in a loop rather than as isolated commands. (OpenAI)
If the workload is heavier on code, patches, deep vulnerability research, exploit reasoning, compiled-target analysis, or large software-system inference, Mythos has the stronger public signal. Anthropic’s own materials repeatedly emphasize how Mythos discovers, reproduces, patches, and sometimes exploits real vulnerabilities. The FreeBSD example, the browser-chain language, the OSS-Fuzz results, and the large pool of reported but not yet publicly discussed findings all point in the same direction: Anthropic believes Mythos is already beyond the “assistant for secure coding” phase and into something closer to a frontier vulnerability-research collaborator. (Red Anthropic)
If the workload is primarily defensive triage, structured reporting, broad tool orchestration, and evidence management, the model is only one layer of the answer. This is where security teams often overfocus on the frontier model and underfocus on workflow design. A model that can reason beautifully but cannot be routed, verified, retested, and audited is not automatically the better security system. The academic literature on pentesting agents reinforces that point repeatedly: task decomposition and human review are not temporary crutches. They are part of the architecture. (USENIX)
The matrix below is a synthesis of what OpenAI and Anthropic have publicly documented about these cyber-focused offerings. It should be read as a public-evidence snapshot, not as a benchmark scoreboard. (OpenAI)
| Public comparison point | GPT-5.4-Cyber | Claude Mythos Preview | Why it matters |
|---|---|---|---|
| Access path | Higher tiers of OpenAI Trusted Access for Cyber for verified defenders | Invitation-only research preview under Project Glasswing | Determines who can actually pilot it |
| Self-serve route | Individual identity verification exists for TAC, plus enterprise request paths | No self-serve sign-up in public docs | Changes time-to-adoption |
| Public framing | Cyber-permissive GPT-5.4 variant with reduced refusal friction for legitimate cyber work | General-purpose frontier model whose cyber strength emerges from broader coding and agentic gains | Signals product philosophy |
| Public specialty statement | Advanced defensive workflows, including binary reverse engineering without source | Vulnerability discovery, exploit development, zero-day research, critical software defense | Signals expected best-fit tasks |
| Public pricing | No separate public GPT-5.4-Cyber price published | $25 per million input and $125 per million output tokens for participants | Matters for budgeting and scale |
| Public tool and context details | Broader GPT-5.4 family has native computer use and long-context support, but public GPT-5.4-Cyber spec is limited | Mythos docs publish 1M context and endpoint-specific tool limitations | Matters for integration planning |
The practical read is straightforward. OpenAI has published the clearer path for real defender onboarding. Anthropic has published the stronger public signal of a frontier exploit-capable research model. Those are not mutually exclusive truths. They describe two different market positions. (OpenAI)
Mapping the Models to Real Security Tasks
A better comparison starts by deciding what kind of “cybersecurity” you mean.
If by cybersecurity you mean source-aware AppSec, patch review, regression reasoning, code audit, advisory triage, and reproducible remediation guidance, then you want a model that can ingest diffs, understand root cause, avoid hallucinating exploitability, and produce outputs another engineer can verify. Mythos may have the more dramatic public research claims, but OpenAI’s GPT-5.4 family and Anthropic’s broader Claude family both already look capable enough to do meaningful work here. The cyber-specific differentiator becomes less about raw intelligence and more about how much refusal friction, tool reach, and deployment control you need in your environment. (OpenAI)
If by cybersecurity you mean reverse engineering and analysis of closed or compiled targets, GPT-5.4-Cyber’s public positioning becomes unusually relevant. OpenAI explicitly chose to call out binary reverse engineering in the TAC expansion post. Very few vendor announcements pick that example casually. It suggests OpenAI believes the cyber variant helps where source code is absent and compiled artifacts need to be interpreted directly. That is not a common need for every security team, but for malware analysts, firmware researchers, or defenders dealing with black-box vendor software, it is exactly the kind of claim worth testing. (OpenAI)
If by cybersecurity you mean exploit research, N-day weaponization, root-cause exploration of memory corruption, and high-value software security work, Mythos has the stronger public evidence today. Anthropic’s public writeup is simply more explicit on that front than anything OpenAI has published about GPT-5.4-Cyber. The caution is that explicitness is not the same thing as public availability. Mythos may be the more important signal for where the field is going even if GPT-5.4-Cyber is the more relevant option for what most defenders can pilot now. (Red Anthropic)
If by cybersecurity you mean workflowed pentesting, the answer becomes even less about the model in isolation. Academic work keeps showing that task decomposition, human supervision, and structured evaluation matter. OWASP and NIST both describe testing as a sequence of phases, not a single brilliant moment. So the better question becomes whether a model supports your workflow discipline: reading the right artifacts, preserving context, choosing tools correctly, validating results, and producing evidence another human can replay. Any model that looks incredible in a vendor demo but cannot survive that chain is not best for cybersecurity in the sense most teams actually care about. (csrc.nist.gov)
The matrix below shows a task-oriented way to think about fit.
| Security task | Better public fit today | Why |
|---|---|---|
| Defender onboarding and pilot access | GPT-5.4-Cyber | Verified TAC path is broader and more operationally reachable |
| Binary reverse engineering without source | GPT-5.4-Cyber | OpenAI explicitly highlights this workflow |
| Frontier vulnerability research and exploit reasoning | Claude Mythos Preview | Anthropic has published far stronger public evidence here |
| Large software-system vulnerability inference | Claude Mythos Preview | Public writeups emphasize deep coding and agentic software understanding |
| Browser or interface-driven operator loops | Slight edge to GPT-5.4-Cyber | Broader GPT-5.4 family is explicitly positioned around computer use |
| High-trust critical-software partner programs | Claude Mythos Preview | Project Glasswing is designed around that environment |
| Most teams without special access today | Neither, use broadly available models while building the harness | Access constraints dominate reality |
That last row is easy to overlook, but it may be the most honest one in the table. For many teams, the actual near-term decision is not GPT-5.4-Cyber versus Mythos. It is whether to enter OpenAI TAC, try to qualify for Glasswing, or build a real security evaluation pipeline on top of more generally accessible frontier models while waiting for access. Anthropic’s own red-team writeup tells defenders to start strengthening workflows now with currently available frontier models rather than waiting for Mythos-class access. (Red Anthropic)
Four CVEs That Expose the Difference Between Hype and Useful Security Work
A model comparison becomes much more honest when you stop asking it to “do cyber” and start asking it to reason about concrete cases. The four CVEs below are not here as exploit tutorials. They are here because they test different slices of security thinking.
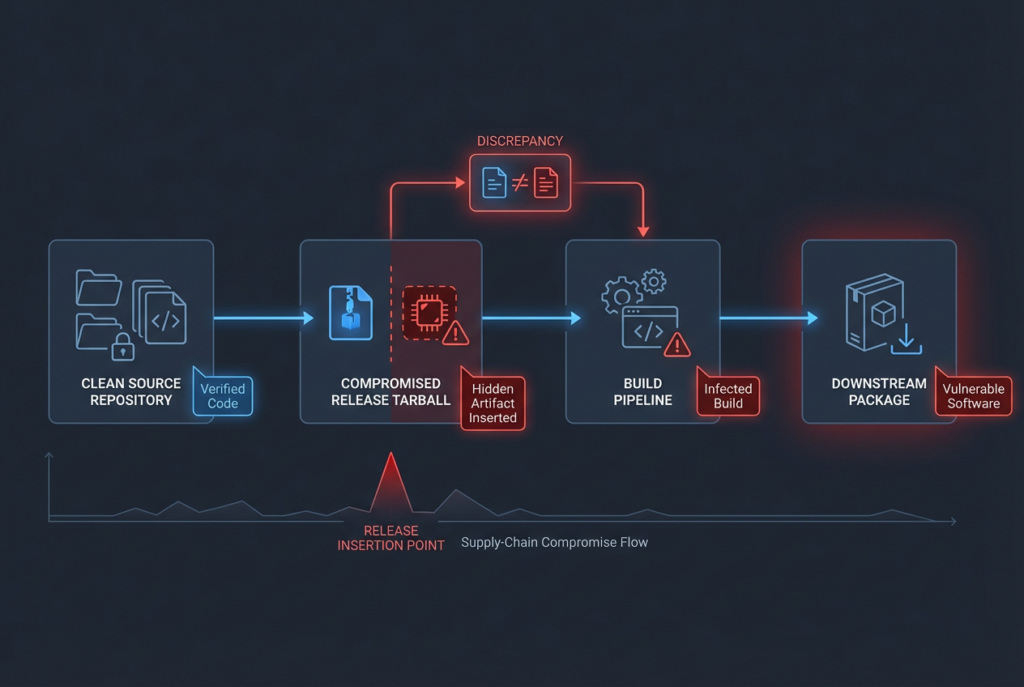
CVE-2024-3094, XZ Utils and Supply-Chain Forensics
CVE-2024-3094 is one of the cleanest tests for whether a model understands supply-chain reality instead of just code trivia. NVD describes malicious code in the upstream xz tarballs beginning with version 5.6.0 and explains that the compromised build process extracted a prebuilt object file from disguised test content, modifying liblzma behavior during the build. Microsoft’s guidance described it as a CVSS 10 software supply-chain compromise affecting versions 5.6.0 and 5.6.1 and said CISA recommended downgrading to a non-compromised version. (nvd.nist.gov)
Why is that a good model test? Because a weak model will summarize it as “critical backdoor in XZ, upgrade immediately” and stop there. A stronger security model will realize that the interesting part is not only the version number. It is the release-process discrepancy between repository and distributed tarball, the build-time trigger, the obfuscated extra files, and the consequence that artifact provenance matters as much as source review. In other words, this case tests whether the model knows where security actually lived in the incident. (nvd.nist.gov)
This kind of task feels closer to Mythos’s public strength profile than to ordinary chat coding, because it asks for deep reasoning over software production behavior. But it is also a case where a defender-focused workflow matters more than glamorous exploit prowess. The real operational question is whether the model can help you build a reliable evidence pack: affected build paths, artifact provenance checks, validation logic, downgrade or rollback guidance, and checks for exposure across CI, packaging, and deployment systems. A model that cannot structure that output cleanly is not especially useful, no matter how impressive its exploit lore sounds. (Red Anthropic)
A good internal evaluation prompt for this CVE is not “Explain XZ.” It is closer to this: identify what evidence would prove that a given internal package pipeline ever consumed a compromised tarball rather than a clean source tree, and separate what can be answered from source control alone from what requires build- and artifact-level investigation. That is a much better discriminator of useful security reasoning. It forces the model to think like a defender, not a summarizer.
CVE-2024-3400, PAN-OS and Advisory-to-Validation Reasoning
CVE-2024-3400 is a superb test of whether a model can read a vendor advisory like an operator rather than like a social-media thread. Palo Alto Networks describes it as a command-injection issue resulting from arbitrary file creation in the GlobalProtect feature of PAN-OS that may allow an unauthenticated attacker to execute arbitrary code with root privileges on the firewall. The same advisory also makes clear that Cloud NGFW, Panorama appliances, and Prisma Access are not affected, and that exposure requires specific PAN-OS branches with GlobalProtect gateway or portal configuration. It provides fixed versions, threat-prevention signatures, incident-response guidance, and device-level indicators to investigate exploitation. (security.paloaltonetworks.com)
This is exactly the kind of case where poor model behavior creates expensive noise. A shallow model often turns advisories like this into binary panic: “critical unauthenticated root RCE, patch now.” The patch-now part is true. The failure is that the model often loses the exposure conditions that determine whether a specific environment is actually vulnerable, whether mitigation signatures are already in place, what products are unaffected, and what operational checks can confirm attempted exploitation. For a real security team, that difference is the gap between useful triage and alert fatigue. (security.paloaltonetworks.com)
This case also shows how a model should support defenders after the headline. Palo Alto’s advisory includes concrete steps for verifying GlobalProtect exposure, mitigation guidance for Threat Prevention signatures, and a CLI log-grep pattern to identify attempted exploitation. That means this CVE is not just a reading-comprehension test. It is a test of whether the model can convert advisory text into an actionable runbook with affected versions, exposure prerequisites, logging checks, incident-handling advice, and upgrade paths without hallucinating unsupported details. (security.paloaltonetworks.com)
A short vendor-supplied example from the advisory is already enough to show the shape of a useful output. Palo Alto says this grep can help identify attempted exploitation in device logs:
grep pattern "failed to unmarshal session(.\+.\/" mp-log gpsvc.log*
That is the kind of detail a defender actually needs preserved and contextualized, not buried under generic explanation. (security.paloaltonetworks.com)
For model evaluation, the harder and more useful task is to ask for a two-part output: first, determine whether a specific PAN-OS estate is in scope based on product, version, and GlobalProtect configuration; second, produce a validation checklist that distinguishes “vulnerable,” “exposed,” “attempted exploit seen,” and “compromise cannot yet be ruled out.” If a model can do that cleanly, you are looking at something closer to production usefulness.
CVE-2025-24813, Apache Tomcat and Exploit Preconditions
CVE-2025-24813 is a good test because it punishes lazy vulnerability summaries. NVD describes it as a path-equivalence issue involving an internal dot in file names, potentially leading to remote code execution, information disclosure, or malicious content injection via a write-enabled Default Servlet in affected Tomcat versions. Apache’s security notice also made clear that the issue involved write enablement in the Default Servlet, which is disabled by default. CISA later added the vulnerability to its Known Exploited Vulnerabilities Catalog, meaning the issue moved from theoretical concern into active operational relevance. (nvd.nist.gov)
This is exactly the kind of bug that separates security-grade reasoning from keyword-grade reasoning. A weak model sees “Tomcat RCE” and writes a generic patch summary. A stronger model asks the important questions. Is the Default Servlet write-enabled in this deployment? Is the affected version actually present? What application behaviors or storage choices increase risk? Is the real risk file manipulation, information disclosure, content injection, or a full RCE path in this environment? Which elements are default, and which require configuration drift or unusual app behavior? (nvd.nist.gov)
This makes CVE-2025-24813 an ideal evaluation case for comparing how models reason about exploit preconditions. In real AppSec work, a great deal of time is spent deciding whether a scanner hit or an advisory actually maps to the deployed application in a materially exploitable way. The best model is not the one that writes the scariest summary. It is the one that most reliably converts a public disclosure into accurate environment questions, evidence requirements, and mitigation order. (csrc.nist.gov)
It is also a reminder that active exploitation does not erase the need for context. CISA’s KEV inclusion tells you urgency. It does not remove the responsibility to validate exposure conditions in your estate. That is exactly the kind of disciplined distinction a strong security model should preserve rather than flatten. (CISA)
CVE-2026-4747, FreeBSD and the Limits of Frontier Exploit Claims
CVE-2026-4747 belongs in this comparison for a different reason. FreeBSD’s advisory describes remote code execution via RPCSEC_GSS packet validation, credits Nicholas Carlini using Claude and Anthropic, and says all supported FreeBSD versions were affected at disclosure time. Anthropic’s public red-team writeup then uses that case to argue that Mythos Preview autonomously identified and exploited a 17-year-old FreeBSD vulnerability, yielding complete control over the server from an unauthenticated user on the internet. (The FreeBSD Project)
This is the kind of public claim that changes the conversation, but it is also the kind most likely to be overread. What does it prove? It proves that Anthropic is publicly attaching Mythos to a real, vendor-fixed vulnerability with unusually strong language around autonomous discovery and exploitation. What does it not prove? It does not prove Mythos is the best model for every pentest, or that it is automatically the best choice for black-box web testing, or that ordinary security teams can reproduce the same results on demand with minimal scaffolding. Those are very different claims. (Red Anthropic)
That distinction is essential for honest comparison. FreeBSD CVE-2026-4747 is highly relevant as a signal of frontier exploit research. It is much less relevant as proof that Mythos is the model you should standardize on for broad security operations tomorrow morning. In that sense, the case is almost a perfect metaphor for the whole article: public exploit capability and practical deployment fit are related, but they are not the same thing. (Red Anthropic)
A Reproducible Harness for Model Evaluation
If you really want to know which model is better for your security work, you need a harness, not a vibe. The harness does not need to be fancy. It does need to be structured enough that two different models can be given the same artifacts, the same constraints, and the same scoring rules.
A useful first step is a task manifest. The point is to force comparability. Do not ask one model a casual question and the other one a polished internal benchmark. Give both the same advisory text, patch diff, configuration snippets, logs, screenshots, and target objective. Decide in advance what counts as a good answer. For example, do you care about affected-version accuracy, identification of exploit preconditions, defensive checks, mitigation quality, evidence discipline, or report readability? Put that into the task definition before you run the test. (csrc.nist.gov)
A minimal manifest can look like this:
task_id: cve-2025-24813-triage
objective: Determine real exploitability conditions and defender actions for a Tomcat deployment
artifacts:
- advisory/apache_security_notice.txt
- nvd/cve_2025_24813.txt
- env/server_xml_snippet.xml
- env/default_servlet_config.txt
- env/session_persistence_notes.md
allowed_actions:
- summarize_artifacts
- reason_about_exposure
- produce_validation_checklist
forbidden_actions:
- invent_missing_configuration
- assume exploitation succeeded
expected_output:
format: json
fields:
- affected_versions
- exploit_prerequisites
- environment_questions
- validation_steps
- mitigation_steps
- confidence_notes
scoring:
affected_versions: 0.20
prerequisites: 0.25
validation_steps: 0.25
mitigation_steps: 0.15
evidence_discipline: 0.15
human_review_required: true
The next step is to build a fair evidence pack. That usually means pulling together the authoritative disclosure, affected-version information, and a minimal patch context or configuration snapshot. For public CVEs, git diff is often enough to create a strong test input without turning the exercise into exploit instruction. A small shell pipeline makes that repeatable:
mkdir -p evidence/tomcat
cd evidence/tomcat
git clone https://github.com/apache/tomcat.git
cd tomcat
# Example only: choose fixed tags that match the release train you care about
git diff 9.0.98..9.0.99 > ../patch.diff
git diff 10.1.34..10.1.35 >> ../patch.diff
cd ..
cp /path/to/apache_security_notice.txt .
cp /path/to/nvd_cve_2025_24813.txt .
That kind of workflow is valuable because it shifts the test away from generic “tell me about this CVE” prompting and toward real evidence handling. In practice, security teams almost always reason over a bundle: advisory text, version inventory, configuration state, patch context, and sometimes logs or screenshots. Models should be tested against that reality. (nvd.nist.gov)
Once the model outputs are structured, score them. That does not mean pretending security work can be fully automated into a single number. It means taking obvious ambiguity off the table. Did the model correctly identify the affected version range? Did it preserve the exploit prerequisites? Did it invent mitigations that the vendor never mentioned? Did it clearly separate known facts from environment assumptions? Those are scorable behaviors. (arXiv)
A simple validation layer in Python is enough to catch most low-value output:
import json
from dataclasses import dataclass, asdict
from typing import List, Dict, Any
@dataclass
class TriageResult:
affected_versions: List[str]
exploit_prerequisites: List[str]
environment_questions: List[str]
validation_steps: List[str]
mitigation_steps: List[str]
confidence_notes: str
REQUIRED_FIELDS = set(TriageResult.__annotations__.keys())
def validate_result(payload: Dict[str, Any]) -> Dict[str, Any]:
missing = REQUIRED_FIELDS - set(payload.keys())
extra = set(payload.keys()) - REQUIRED_FIELDS
checks = {
"missing_fields": sorted(missing),
"extra_fields": sorted(extra),
"has_prerequisites": bool(payload.get("exploit_prerequisites")),
"has_validation_steps": bool(payload.get("validation_steps")),
"has_confidence_notes": isinstance(payload.get("confidence_notes"), str)
}
score = 0
score += 20 if not missing else 0
score += 20 if checks["has_prerequisites"] else 0
score += 20 if checks["has_validation_steps"] else 0
score += 20 if checks["has_confidence_notes"] else 0
score += 20 if not extra else 0
return {"checks": checks, "schema_score": score}
if __name__ == "__main__":
sample = {
"affected_versions": ["9.0.0.M1-9.0.98", "10.1.0-M1-10.1.34"],
"exploit_prerequisites": [
"write-enabled Default Servlet",
"deployment-specific conditions must be validated"
],
"environment_questions": [
"Is Default Servlet write enabled?",
"Which Tomcat train is deployed?"
],
"validation_steps": [
"Confirm exact version",
"Review servlet write configuration"
],
"mitigation_steps": [
"Upgrade to a fixed version",
"Review risky non-default write settings"
],
"confidence_notes": "Do not assume uniform exploitability across all Tomcat deployments."
}
print(json.dumps(validate_result(sample), indent=2))
That does not replace expert review. It does make comparisons less sloppy.
One more rule matters: evaluate refusal behavior honestly. Security teams often dislike refusals and overreward permissiveness. That is backward. You want a model that is permissive enough for legitimate work and disciplined enough not to blur into unsafe or low-trust guidance. OpenAI’s entire TAC model exists because cyber requests are often dual-use and ordinary safeguards can create friction for defenders. Anthropic’s whole deployment posture for Mythos exists because it believes exploit capability has crossed into a more dangerous zone. A useful security benchmark should therefore measure not only “Did the model help?” but also “Did it stay inside the task boundary and separate evidence from speculation?” (OpenAI)
What Different Security Teams Should Do
Product Security and AppSec Teams
For AppSec, source review, patch triage, secure-design analysis, and remediation loops, the practical winner may be less absolute than the headlines suggest. If you can get into OpenAI TAC and your workflows are heavily tool-facing, browser-facing, or involve repeated environment interaction, GPT-5.4-Cyber may be the easier model to operationalize. OpenAI’s public messaging aligns closely with reduced refusal friction for legitimate work and with advanced defensive workflows in real defender hands. (OpenAI)
If your work skews toward deep codebase understanding, patch reasoning, vulnerability research, or complex exploitability analysis, Mythos may be more interesting conceptually. But unless you are in a position to obtain Glasswing access, the more realistic path may be to build your task harness now and use the best accessible frontier models available to your organization. Anthropic’s own public guidance says defenders should start using currently available frontier models to strengthen defenses today and learn how to adopt model-driven bugfinding before Mythos-class access becomes widespread. (Red Anthropic)
AI Security Engineers and Agent Security Teams
This audience should be especially careful not to reduce the question to exploit capability. Security work around agents is often about permissions, tool boundaries, prompt injection, memory, state, and runtime control. OpenAI’s public Safety Bug Bounty program explicitly calls out agentic risks such as third-party prompt injection and data exfiltration. Anthropic’s Mythos risk report, meanwhile, is structured around risks from autonomous model actions within an organization, including self-exfiltration and persistent rogue internal deployment in the threat pathways it considers. (OpenAI)
For that kind of work, the “best” model may actually be the one with the clearest control surface, the most transparent runtime behavior, and the easiest internal audit path, not the one that sounds scariest in frontier exploit writeups. This is one reason broad security teams should avoid importing pure exploit-research prestige into every cyber decision. Agent security is as much about trustworthy control as about raw capability. (OpenAI)
Red Teams and Pentesters
Red teams and authorized pentesters should be honest about what they need. A lot of offensive work is not elite exploit development. It is hypothesis generation, target understanding, authenticated flow exploration, stateful navigation, tool orchestration, evidence capture, retest planning, and report writing. OpenAI’s broader GPT-5.4 family looks strong for operator-style loops, and GPT-5.4-Cyber is explicitly tuned to reduce friction on legitimate cyber tasks. That makes it appealing for highly interactive offensive workflows where the bottleneck is often persistence, automation, and context handling rather than esoteric memory corruption research. (OpenAI)
Mythos is harder to evaluate from this vantage point because the public evidence is stronger on exploit research than on ordinary internet-scale black-box engagement work. Anthropic itself says Project Glasswing work is expected to focus on tasks such as local vulnerability detection, black-box testing of binaries, securing endpoints, and pentesting systems. That is relevant, but it is not identical to proving best-in-class performance for day-to-day external web assessments. Security teams should resist collapsing those categories into one. (anthropic.com)
This is also where workflow platforms matter more than most model debates admit. In practice, mature teams do not spend frontier-model budget on every step. They use cheaper capability for route clustering, false-positive rejection, or artifact preparation, and reserve expensive frontier passes for deep validation, longer exploit attempts, authenticated testing, and retesting after fixes. Penligent’s public writing makes that stage-allocation logic explicit, and its public product pages position the platform around end-to-end AI pentesting from asset discovery to validation, on-demand orchestration of security tools, attack-surface mapping, and evidence-backed report export. That is the right architectural layer to compare against your team’s real work, because it acknowledges that “best model” and “best workflow” are not the same question. (penligent.ai)
Bug Bounty Hunters and Independent Researchers
For independent researchers, access reality matters more than corporate marketing. Unless you have a path into Project Glasswing, Mythos is mostly a signal about where the frontier is going, not an option you can standardize on today. GPT-5.4-Cyber may be more reachable through TAC if your work is legitimate and you are willing to go through defender verification. That alone could make it more useful in practice even if you personally believe Mythos is the more interesting research artifact. (OpenAI)
The more important question for independents is not “Which model is smartest?” It is “Which model, at my access level and budget, improves my verified finding rate without wasting time?” That is a task-harness question. Use real advisories, diffs, and logged reproduction steps. Score the model on output quality, not on drama. The research literature on assisted agents versus fully autonomous agents strongly supports that discipline. (arXiv)
Common Mistakes When Comparing Cyber Models
The first mistake is treating frontier exploit capability as the same thing as overall cybersecurity usefulness. It is not. A model can be extraordinary at exploit research and still be a poor default for broad operational security work if it is difficult to access, hard to integrate, or unsuited to your most common task types. Mythos is the clearest current example of that tension. (Red Anthropic)
The second mistake is ignoring deployment and governance as if they were secondary. In cyber, the release path is part of the offering. OpenAI’s TAC and Anthropic’s Glasswing are not annoying commercialization layers. They are the mechanisms through which each company is deciding how dangerous or deployable these capabilities are. Security teams that ignore that are missing the product definition. (OpenAI)
The third mistake is comparing vendor-generated demos to your own environment without adjusting for evidence quality. Vendor writeups are useful. They are not your estate. Your environment has your auth stack, your logs, your brittle build chain, your weird appliances, your undocumented defaults, and your legal constraints. The benchmark that matters most is the one you can reproduce on your artifacts. (USENIX)
The fourth mistake is comparing models while ignoring workflow architecture. Security work is not just reasoning. It is also attack-surface identification, artifact management, tool invocation, evidence capture, retest discipline, and report output. This is exactly why comparing a frontier model directly to a security workflow platform is usually a category error. In actual use, the model is one component inside a broader control plane. Penligent’s public pricing and product pages make that visible in concrete terms by emphasizing profiling, mapping, validation, orchestration, and export rather than pretending the model alone is the whole story. (penligent.ai)
So Which One Is Best for Cybersecurity
If the question is which model fits real security work today for more teams, the public evidence favors GPT-5.4-Cyber. OpenAI has built a visible defender-access program, tied the model to reduced refusal friction for legitimate cyber tasks, highlighted binary reverse engineering as a first-class defensive workflow, and is clearly trying to move the model into a broader defensive ecosystem with third-party institutional evaluation. That is the profile of something meant to be operationalized, not merely admired. (OpenAI)
If the question is which model is the more important frontier signal for vulnerability discovery and exploit research, the public evidence favors Claude Mythos Preview. Anthropic has published much stronger explicit claims around zero-days, exploit construction, OSS-Fuzz outcomes, and large-scale vulnerability finding than OpenAI has published for GPT-5.4-Cyber. Whether those claims will generalize broadly, and how fast they will become available beyond invitation-only settings, remains a separate question. But the direction of the signal is hard to miss. (Red Anthropic)
If the question is what a serious security team should do right now, the answer is less glamorous and more useful. Build the staged evaluation harness first. Use real advisories, diffs, configs, binaries, and logs. Test task classes separately. Score evidence discipline, not just cleverness. Decide where permissiveness helps and where it creates risk. Then compare the models inside your workflow rather than outside it. The academic benchmark literature and both vendors’ deployment choices point to the same conclusion: in cybersecurity, the best model is not the one with the loudest claim. It is the one that survives your evidence, your process, and your controls. (USENIX)
And if your end goal is not merely to chat about findings but to turn them into something another human can verify, workflow layers matter. Publicly, Penligent describes that layer in practical terms: asset profiling, attack-surface mapping, tool orchestration, validation, and report export. Whether your team uses Penligent or a homegrown stack, that architectural idea is the right one. Route simple tasks cheaply. Reserve expensive frontier reasoning for the moments where it changes the answer. Keep humans at the verification boundary. In 2026, that is still the most credible way to get security value from frontier models without confusing capability theater for security work. (penligent.ai)
Further Reading and References
OpenAI, Introducing Trusted Access for Cyber and Trusted access for the next era of cyber defense. (OpenAI)
OpenAI, Introducing GPT-5.4 and Accelerating the cyber defense ecosystem that protects us all. (OpenAI)
Anthropic, Project Glasswing, Models overview, Assessing Claude Mythos Preview’s cybersecurity capabilities, and the public Mythos risk report. (anthropic.com)
Anthropic, Introducing Claude Opus 4.7. (anthropic.com)
USENIX Security 2024, PentestGPT: Evaluating and Harnessing Large Language Models for Automated Penetration Testing. (USENIX)
arXiv, AutoPenBench: Benchmarking Generative Agents for Penetration Testing and PentestEval: Benchmarking LLM-based Penetration Testing with Modular and Stage-Level Design. (arXiv)
NIST SP 800-115 and the OWASP Web Security Testing Guide. (csrc.nist.gov)
NVD, CISA, Palo Alto Networks, Apache, and FreeBSD on CVE-2024-3094, CVE-2024-3400, CVE-2025-24813, and CVE-2026-4747. (nvd.nist.gov)
Penligent, AI Pentesting After Mythos, the main product page, and pricing. For readers comparing model capability with evidence-driven offensive workflow design, these are the most directly related Penligent pages I found. (penligent.ai)

