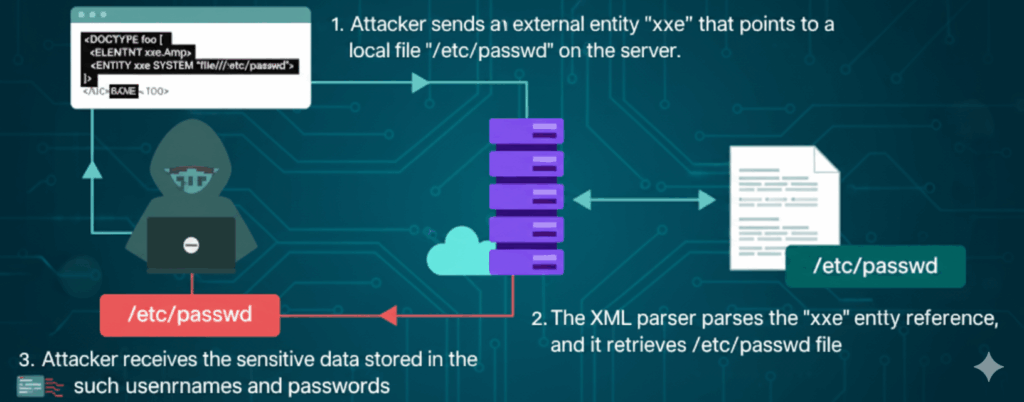
כשאתם קוראים כותרות על פגיעות, הזרקת XML כמעט ולא תופסת את אור הזרקורים. אין לה שם מוכר ומרשים כמו RCE או SQLi, והיא לא דרמטית מבחינה ויזואלית כמו ניצול מרחוק נוצץ. אבל במערך הארגוני של חברות רבות — נקודות קצה SOAP, ממשקי API XML ישנים, צינורות לעיבוד מסמכים ושילובים של SAML/SOAP — הזרקת XML היא מצב כשל שקט שהופך קלטות מהימנות לטעויות לוגיות.
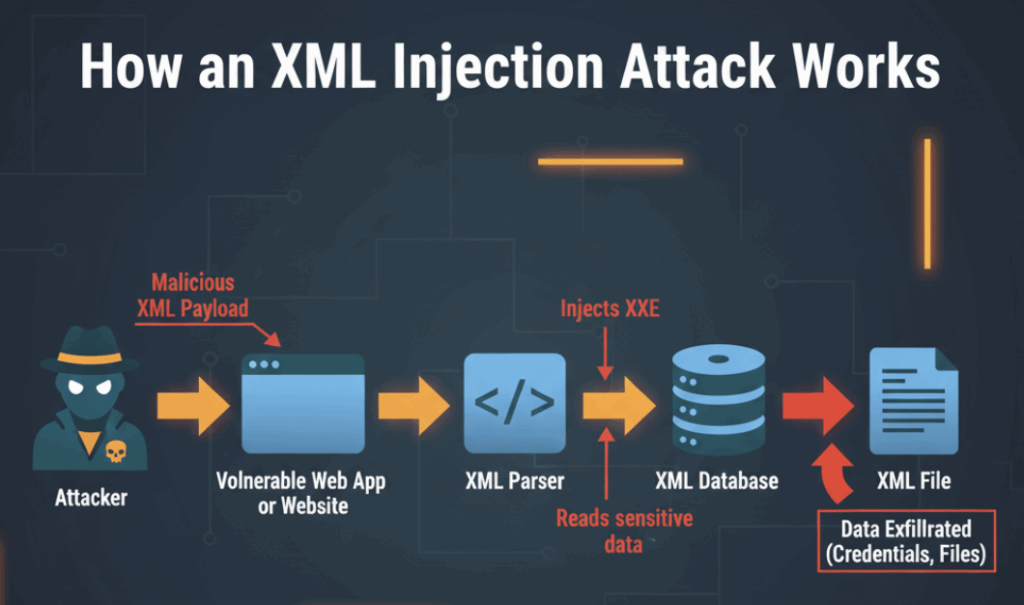
בעיקרו של דבר, הזרקת XML אינה ניצול בודד. זוהי משפחה של התנהגויות שבהן XML הנשלט על ידי התוקף משנה את האופן שבו השרת מפרש בקשה. משמעות הדבר יכולה להיות ששאילתת XPath מחזירה לפתע רשומות בלתי צפויות, שמנתח תחבירי פותר משאבים חיצוניים שלא התכוונת לקרוא, או שהרחבת ישויות צורכת CPU וזיכרון. מנקודת המבט של התוקף, אלה הם אבני בניין מעשיות: קריאת קבצים, הפעלת בקשות פנימיות או גרימת כאוס שימושי. מנקודת המבט של המגן, אותם חלקים הם מפת ניווט לתיקון פערים בלוגיקה ובנראות.
טעימה קטנה וממשית — בלי לתת לאף אחד תסריט
אין צורך במטענים מתוחכמים כדי להבחין בדפוס. דמיינו קוד בצד השרת שבונה XPath משדות הבקשה באמצעות חיבור מחרוזות תמים:
// תבנית פגיעה (מדומה) userId = request.xml.user.id role = request.xml.user.role query = "doc('/db/users.xml')/users/user[id = " + userId + " and role = '" + role + "']" result = xmlEngine.evaluate(query)
זה נראה בלתי מזיק אם userId ו תפקיד הם בעלי מבנה תקין. אך כאשר אתה מאפשר למשתמש לשלוט במבנה השאילתה, אתה מטשטש את הגבול בין נתונים ו לוגיקה. הזרקת XPath היא התוצאה הטבעית: שאילתה שברירית יכולה להיות מנוצלת כדי לשנות תנאי אמת ולהחזיר שורות שלא היו אמורות להופיע.
ציר נוסף הוא טיפול בישויות או ב-DTD. מנועי XML רבים מאפשרים הצהרות על סוג המסמך, ישויות והפניות חיצוניות — דבר שימושי להלחנה לגיטימית, אך מסוכן כאשר הוא מופעל עבור קלט לא מהימן. הכלל ההגנתי הוא פשוט: אם אינך זקוק להרחבת ישויות או לעיבוד DOCTYPE, כבה אותו.
מדוע ניתוח תצורה חשוב יותר מניצול פרצות מסתוריות
ישנן שתי רמות לבעיה זו. הראשונה היא באג בלוגיקה העסקית — העברת ערכים לא אמינים ללוגיקת השאילתה, יצירת תבניות XML ב-XPath או במאפיינים דמויי XPath, והנחה ש"מבנה תקין" פירושו "בטוח". ניתן לתקן זאת באמצעות תכנון: אימות, קנוניזציה והפרדת נתונים משאילתות.
השני הוא התנהגות הפרסר. פרסרי XML הם עוצמתיים; הם יכולים לאחזר תוכן קבצים, לבצע בקשות HTTP או להרחיב ישויות מקוננות שמנפחות את הזיכרון. יכולות אלה הן טובות בהקשרים מבוקרים, אך הרות אסון כאשר מתקבלים קלטות ציבוריות. לכן ההגנה המעשית היא חיזוק הפרסר בתוספת טלמטריה התנהגותית.
אמצעי נגד מעשיים וידידותיים למהנדסים (עם דוגמה)
אין צורך לאסור את השימוש ב-XML כדי להבטיח את האבטחה. יש צורך בשלושה שינויים הרגליים:
1) הגבל את יכולת הניתוח של הפרסר. ברוב השפות ניתן להשבית עיבוד של ישויות חיצוניות ו-DOCTYPE. לדוגמה, ב-Java (pseudo-API):
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); dbf.setFeature("", true); dbf.setFeature("", false);
dbf.setFeature("", false);
או ב-Python עם defusedxml (השתמש בספרייה שמגדירה התנהגות בטוחה כברירת מחדל):
מ-defusedxml.ElementTree ייבוא מ-fromstring tree = fromstring(untrusted_xml)
2) אימות וקנוניזציה. אם נקודת הקצה שלך זקוקה רק לקבוצה קטנה של תגיות, בצע אימות מול XSD או דחה DOCTYPEs בלתי צפויים. העדיף ניתוח למבני נתונים ושימוש בגישה פרמטרית על פני בניית שאילתות באמצעות שרשור מחרוזות.
3) מכשיר והתראה. הוסף ווים המנטרים אותות חריגים: חריגות בניתוח המתייחסות ל-DOCTYPE/ENTITY, DNS/HTTP יוצא פתאומי משירות הניתוח, או פעולות פתיחת קבצים שיוזמו במהלך הניתוח. אותות אלה ניתנים ליישום הרבה יותר מכל רשימת כללים סטטית.
אותות ניתנים לזיהוי המסייעים בפועל למגינים
כאשר אתה מכוון את הניטור, חפש התנהגויות אמיתיות, ולא חתימות טקסטואליות שבירות:
- שיחות DNS או HTTP יוצאות שמקורן בתהליך ה-parser שלך.
- ניסיונות גישה לקבצים בנתיבים מקומיים המתרחשים במהלך טיפול ב-XML.
- עקבות חריגות של מפרש המזכירות DOCTYPE או פתרון ישויות חיצוניות.
- תגובות הכוללות לפתע שדות או נתונים פנימיים בלבד (המעידים על מניפולציה של XPath או שאילתה).
- עליות חריגות ב-CPU/זיכרון בעת ניתוח קוד תחת עומס רגיל.
אלה הדברים שאתה יכול להתריע עליהם ולבצע מיון מהיר.
איך להתאמן בלי להיות פזיז
אם ברצונך לבצע ניסויים — לאמת כללי זיהוי, לאשר שהקשחת המנתח פועלת כראוי או להתאמן על אתגר בסגנון CTF — עשה זאת רק במעבדות מבוקרות. אל תדחוף XML פגום לייצור. במקום זאת, השתמש במכונות וירטואליות מבודדות, טווחי מעבדה הניתנים להוכחה או כלים המייצרים מרוסן, לא מנצל מקרי מבחן.
זרימת עבודה בשפה טבעית — Penligent בלולאה
זה המקום שבו אוטומציה מעשית משתלמת. לא צריך לכתוב עשרות בדיקות ביד רק כדי לאמת את הגדרות ה-parser או את לוגיקת הזיהוי. עם כלי pentest המונע על ידי שפה טבעית כמו Penligent, הזרימה נראית כך בשפה יומיומית:
"בדקו את נקודות הקצה של SOAP שלנו לצורך זריקת XML. השתמשו רק בבדיקות בטוחות, אספו חריגות של מפרש, אירועי גישה לקבצים וכל קריאות DNS/HTTP יוצאות. צרו שלבים של חיזוק עם סדר עדיפויות."
Penligent הופך משפט זה לבדיקות ממוקדות ומסוננות כנגד סביבת הבדיקה המורשית שלכם. הוא מריץ מקרי בדיקה ממוקדים (לא שרשראות ניצול בזמן אמת), אוסף נתוני טלמטריה (שגיאות ניתוח, יומני גישה לקבצים, החזרות DNS), מקשר בין ראיות ומחזיר רשימת תיקונים תמציתית. עבור שחקני CTF היתרון הוא המהירות: ניתן לאמת השערה וללמוד אם הזיהוי היה מופעל — ואז לחזור על התהליך — מבלי לכתוב סקריפטים של shell או ליצור עשרות קבצי payload.
מחשבה לסיום
הזרקת XML נראית לא מרשימה בדירוג הפגיעות, אך כוחה האמיתי טמון בחשאיות. היא מנצלת הנחות — שהשכבת הנתונים אינה מזיקה, שהמנתח מתנהג "כמצופה" ושהניטור יתפוס כשלים ברורים. התיקון אינו קשור לתיקון קסם אחד, אלא יותר להיגיינת עיצוב: צמצום הרשאות המנתח, הפרדת נתונים מהלוגיקה, אימות אגרסיבי ושימוש בכלים לאיתור האותות החשובים. כלים הממירים כוונות בשפה טבעית לאימות בטוח מסירים את העול ומאפשרים לצוותים להתמקד בתיקון ובלמידה — וזה בדיוק העניין באוטומציה הגנתית מודרנית.

