ל-Mythos יש חשיבות, אך לא משום שיש להתייחס לטקסט המוצר שהודלף כאל אמת מוחלטת. יש לו חשיבות משום שכמה סימנים עצמאיים מצביעים כעת לאותו הכיוון. המגזין Fortune דיווח כי חברת Anthropic חשפה בטעות טיוטת חומר אודות מודל עתידי עקב שגיאה בתצורת מערכת ניהול התוכן (CMS), ולאחר מכן אישרה כי החברה מפתחת מודל הכולל התקדמות משמעותית בתחומי ההסקת מסקנות, תכנות ואבטחת סייבר. הדיווח המשותף של CNN הציג את Mythos כנקודת מפנה אפשרית בתחום אבטחת הסייבר, תוך הדגשת העובדה שפרטי המודל נלקחו מחומר טיוטה שהודלף ולא מהשקה ציבורית רגילה. אי-הוודאות הזו חשובה. הפרשנות הבטוחה יותר היא לא שהציבור מחזיק כעת במפרט טכני מלא של Mythos. הפרשנות הבטוחה יותר היא שמדיניות השחרור הפנימית של מעבדת החלוץ, הבדיקות החיצוניות בגישה מוקדמת והשיח על יכולות הסייבר – כל אלה מרמזים שהצד ההתקפי של ה-AI היישומי מתקדם מהר יותר ממה שרוב הארגונים מתייחסים אליו. (מזל)
פרשנות זו מתחזקת כאשר משווים את Mythos לחומרים רשמיים ממעבדות אחרות. בדצמבר 2025 הודיעה OpenAI כי היא מתכננת ומבצעת הערכות כאילו כל מודל חדש עלול להגיע לרמות "גבוהות" של יכולות אבטחת סייבר, והגדירה את הסף הזה כמודלים המסוגלים לפתח פרצות מרחוק מסוג "יום אפס" (zero-day) נגד מערכות מוגנות היטב, או לסייע באופן משמעותי בפריצות מורכבות וחמקמקות לארגונים או למפעלים. זו אינה סיסמת שיווק. זוהי שפת מוכנות של מעבדה חלוצית המודיעה לשוק כי יכולות הסייבר ההתקפיות התקדמו מספיק כדי לדרוש אמצעי הגנה רב-שכבתיים וחשיבה על פריסה המציבה את ההגנה בראש סדר העדיפויות. (OpenAI)
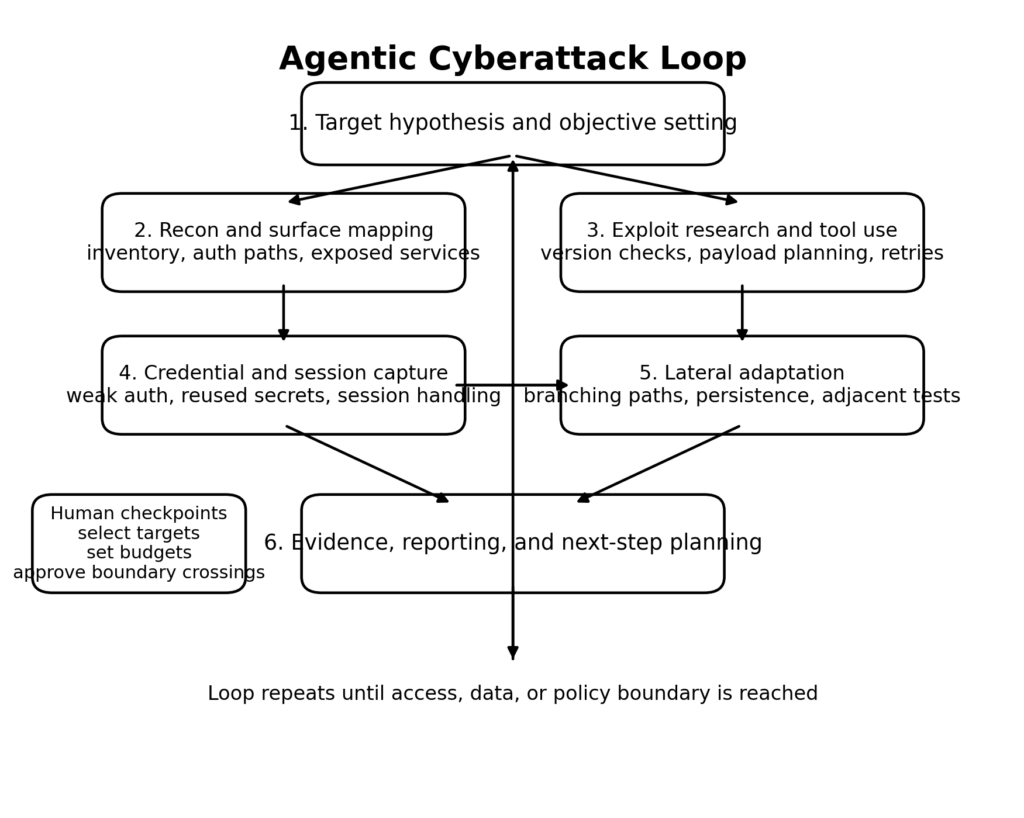
הגילוי של Anthropic עצמה בנובמבר 2025 העמיק את הדיון עוד יותר. החברה מסרה כי זיהתה את מה שלדעתה היה מתקפת הסייבר הגדולה הראשונה שתועדה שבוצעה ללא התערבות אנושית משמעותית, כאשר גורם הקשור למדינה ניצל את "קוד קלוד" (Claude Code) כדי לנסות לחדור לכ-30 ארגונים. Anthropic תיארה תהליך עבודה שבו ה-AI טיפל בסיור, במחקר ניצול, באיסוף אישורים, ביצירת דלת אחורית, בסיווג נתונים ובדיווח, כאשר בני אדם התערבו רק בנקודות החלטה מוגבלות. בין אם מסכימים עם כל מרכיבי המסגרת של Anthropic ובין אם לא, קשה להתעלם מהנקודה התפעולית: המערכת כבר לא רק ענתה על שאלות בנוגע לניצול. היא שימשה כחלק ממעגל תקיפה מתמשך המשתמש בכלים. (אנתרופי)
בפברואר 2026 תיעדה AWS דפוס שונה אך חשוב לא פחות. צוות מודיעין האיומים שלה מסר כי גורם דובר רוסית, שהמניע שלו היה כספי, השתמש במספר שירותי בינה מלאכותית גנרטיבית מסחריים כדי לפרוץ ליותר מ-600 מכשירי FortiGate ב-55 מדינות. AWS גם הבהירה נקודה מכרעת: לא נוצלה אף פגיעות ב-FortiGate בקמפיין זה. הגורם הצליח במשימתו באמצעות שילוב של יציאות ניהול חשופות, אישורים חלשים ואימות חד-גורמי, כאשר ה-AI סייעה בהרחבת טכניקות תקיפה מוכרות לאורך כל הקמפיין. פרט זה חשוב מכיוון שהוא מראה שהבעיה הבאה אינה רק גילוי באגים חדשים וקסומים על ידי ה-AI. הבעיה הבאה היא שה-AI מקלה על ניצול טעויות ישנות בקצב תעשייתי. (אמזון ווב סרוויסס בע"מ)
עד אפריל 2026, הוויכוח על השאלה האם בינה מלאכותית התקפית היא "אמיתית" הוא בעיקר דרך להתחמק מהשאלה הקשה יותר. השאלה הקשה יותר היא איזה סוג של בדיקות אבטחה ואימות נדרשים כעת למגינים. אם התוקפים יכולים לשלב סיור, שימוש בכלים, מחקר ניצול, לוגיקת ניסיונות חוזרים וטיפול בראיות במהירות רבה יותר מבעבר, אזי קו הבסיס ההגנתי לא יכול להיות לוח מחוונים של סורק בתוספת צ'אט-בוט שמשכתב טקסט CVSS לפרוזה ידידותית יותר. קו הבסיס חייב להיות זרימת עבודה שיכולה לבדוק, לאמת, לשחזר ולהוכיח. זה המקום שבו בדיקות חדירה מבוססות בינה מלאכותית מאומתות הופכות לשימושיות.
Mythos היה יריית אזהרה, לא מפרט מוצר
הדיון הציבורי סביב Mythos כבר נסחף לשני קצוות שליליים. מחנה אחד רואה בהדלפה הוכחה לכך שדגם בודד שטרם שוחרר כבר שינה את הכל. המחנה השני מבטל אותה בטענה שהחומר נלקח מטיוטות שהודלפו ולא מהודעת השקה רשמית או ממפרט טכני. אף אחת מהעמדות הללו אינה מועילה במיוחד. הגישה הנכונה יותר היא לראות ב-Mythos יריית אזהרה. יש להתייחס לפרטים בזהירות, מכיוון שהתיעוד הציבורי עדיין מורכב מתערובת של טיוטות שהודלפו, דיווחים עוקבים והצהרות חלקיות של החברה. אך המסר הכללי עולה בקנה אחד עם מה שמעבדות חלוצות וספקי אבטחה כבר אמרו בפומבי: יכולות הסייבר מתקדמות בקצב מהיר כל כך, עד שיש להתייחס הן לסיכון של שימוש לרעה והן להזדמנויות הגנתיות כאל בעיות הנדסיות דחופות. (מזל)
Axios הצליחה לשים את האצבע על ההיבט האסטרטגי החריף יותר. בדיווח שפרסמה בסוף מרץ נכתב כי בכירי תחום הבינה המלאכותית ובכירים בממשל מודאגים מכך שחברות כמו Anthropic, OpenAI ואחרות עומדות לשחרר מודלים שהם "מפחידים מרוב שהם טובים" בפריצה למערכות מתוחכמות בקנה מידה נרחב. באותו דוח תואר Mythos כמודל שמגביר את הסבירות להתקפות סייבר בקנה מידה גדול בשנת 2026, והזהיר כי סוכנים שנבנו על ידי עובדים ומחוברים למערכות עבודה עלולים ליצור דלתות כניסה חדשות לסביבות ארגוניות. המאמר הזה אינו מאמר טכני, אך המסגרת שלו עדיין שימושית מכיוון שהיא מקשרת בין שני מגמות שנדונות לעתים קרובות בנפרד: מודלים התקפיים משופרים ואימוץ פנימי רשלני של סוכנים. מגמות אלה מחזקות זו את זו. (Axios)
הכתבה ב-CNN העלתה את אותה הטענה מזווית אחרת. היא ציטטה מנהיגים בתחום האבטחה שהזהירו כי המודל הבא של כל מעבדה יציב איומי סייבר חמורים יותר, והציגה זאת לצד דעה מנוגדת של אנשי שטח שטענו כי למודלים עדיין חסר חלק מהשיקול הדעת הסביבתי שיש לתוקפים אנושיים. איזון זה הוא בריא. המסקנה הנכונה אינה שה-AI מחליף את המפעיל לחלוטין. המסקנה הנכונה היא שה-AI מצמצם יותר ויותר את העבודה, המומחיות והזמן שנדרשו בעבר לביצוע פעילות התקפית משמעותית, גם אם הכוונה אנושית עדיין חשובה ברגעים מכריעים. (KTVZ)
זו בדיוק הסיבה שצוותי אבטחה צריכים להתנגד לפיתוי להתמקד בתגובה שלהם סביב שם מותג אחד או דליפה אחת. Mythos הוא מעניין, אך השינוי הגדול יותר הוא חוצה-ספקים ומבני. OpenAI נערכת לקראת יכולות סייבר ברמה "גבוהה". Anthropic כבר חשפה שימוש לרעה בסוכנים בפעולות אמיתיות. AWS הראתה שגורמים בעלי מיומנות נמוכה יכולים להשתמש במספר מודלים מסחריים כדי להגדיל את היקף טכניקות תקיפה ישנות. NIST בונה במפורש פרופיל סייבר-AI שמתייחס לתקיפות סייבר מבוססות AI כאחד משלושת תחומי הסיכון המרכזיים שארגונים חייבים להתמודד איתם. ברגע שכל כך הרבה סימנים עצמאיים מסתדרים בשורה, נטל ההוכחה מתהפך. ההנחה המובנית צריכה להיות שיכולת התקפית סוכנתית היא כעת חלק ממודל האיום. (OpenAI)
יכולות הסייבר של הבינה המלאכותית כבר חצו את סף ה"עוזרת"
בדיונים רבים בתחום האבטחה עדיין מתייחסים לבינה מלאכותית כאילו הנושא המרכזי הוא שיפור יכולת הסיכום. זו גישה צרה מדי. השינוי החשוב יותר הוא המעבר מסיוע לפעולה מובנית. הפוסט שפרסמה OpenAI בדצמבר 2025 מועיל בהקשר זה, משום שהוא נמנע משימוש בסופרלטיבים מעורפלים. הפוסט מציין כי היכולות הסייבר במודלים של בינה מלאכותית מתקדמות במהירות, נותן דוגמה קונקרטית של ביצועי "לכידת הדגל" שעלו מ-27% ל-76% במהלך מספר חודשים, ומגדיר סף מוכנות הקשור לניצול פרצות "יום אפס" או סיוע משמעותי בפריצות חמקניות. המשמעות אינה רק בציון. המשמעות היא שמעבדות מתארות כעת מודלים במונחים של יכולת סייבר מבצעית ולא רק כמדד לחוכמה. (OpenAI)
דו"ח האירוע של Anthropic מחודש נובמבר 2025 ממחיש כיצד נראית יכולת סייבר מבצעית כאשר גורם בעל מוטיבציה משלב אותה בתכנון מתואם. בסיכום הציבורי של החברה נכתב כי התוקפים השתמשו ב-AI לא רק כיועץ, אלא לביצוע מתקפות הסייבר עצמן, וכי הם ניצלו את Claude Code כדי לנסות לחדור לכ-30 יעדים. החלק השימושי ביותר בדו"ח אינו הכותרת. זהו פירוט השלבים: בחירת מטרות בהובלת בני אדם, ולאחר מכן סיור מונחה בינה מלאכותית, זיהוי נקודות תורפה, יצירת קוד ניצול, איסוף אישורים, יצירת דלת אחורית, תמיכה בהוצאת נתונים ותיעוד ההתקפה. לרצף זה יש חשיבות מכיוון שהוא נראה כמו זרימת עבודה, ולא כמו פקודה בודדת. (אנתרופי)
המקרה של FortiGate ב-AWS מלמד לא פחות, שכן הוא מפריך את האשליה שרק מעבדות מובילות או גורמים ממשלתיים הם בעלי חשיבות. אמזון אמרה שהגורם שעקבה אחריו היה מוגבל מבחינה טכנית, אך ה-AI עדיין סייע בהרחבת הפעילות בכל שלב של הקמפיין. זו אחת ההדגמות הברורות ביותר של ה-AI כמכפיל יכולות עבור תוקפים חלשים. היא אומרת למגינים להפסיק לחשוב רק על יריבים גאוניים. תוקף בעל מיומנות בינונית עם התמדה, גישה לשירותי AI מסחריים ורשימת ממשקי ניהול חשופים כבר יכול להיות מסוכן באופן שלא היה ניתן בעבר להרחבה בעלות כה נמוכה. (אמזון ווב סרוויסס בע"מ)
המערכת האקולוגית הרחבה יותר מציגה את אותה תזוזה בסיסית. חברת Bugcrowd דיווחה בינואר 2026 כי 82 אחוזים מההאקרים משתמשים כיום ב-AI בתהליכי העבודה שלהם, לעומת 64 אחוזים ב-2023, בעיקר לצורך אוטומציה של משימות, האצת הלמידה וניתוח נתונים. הדו"ח של HackerOne לשנת 2025 מוסיף זווית נוספת: דיווחים תקפים על פגיעות ב-AI גדלו ב-210 אחוזים, כאשר הזרקת פקודות (prompt injection) עלתה ב-540 אחוזים כווקטור הצומח במהירות הרבה ביותר, ו-58 אחוזים מהחוקרים שנסקרו אמרו ש-AI עדיין מפספסת לוגיקה עסקית או ניצול שרשרת. ביחד, המספרים הללו מצביעים על שוק שבו בינה מלאכותית כבר הפכה לנורמה בתהליכי העבודה של החוקרים, אך עדיין אינה אמינה מספיק כדי להחליף את שיקול הדעת של המומחים. זהו בדיוק הסביבה שבה בדיקות חדירה מאומתות באמצעות בינה מלאכותית הופכות ליקרות ערך יותר מאשר התרברבות אוטונומית. (Bugcrowd)
הביטוי המרכזי הוא חצה את סף התפקיד של עוזר. לפני סף זה, הבינה המלאכותית מסייעת בעיקר למפעיל אנושי לבצע במהירות רבה יותר משימות בודדות כגון ניסוח תסריטים, סיעור מוחות בנוגע לתוכן, או סיכום יומנים. מעבר לסף זה, הבינה המלאכותית מתחילה להתנהג כעובד מוגבל המסוגל לשמור על הקשר לאורך זמן, להפעיל כלים, לקשר בין שלבים, להגיב לתפוקות ביניים, ולהמשיך לפעול עד שהיא מגיעה לתנאי עצירה. ברגע שזה קורה, מודל העבודה של התוקף משתנה. אדם בודד יכול לפקח על מספר לולאות. החזרה הופכת לזולה. ניסיון חוזר הופך לזול. חקירת השערות נלוות הופכת לזולה. זהו הרגע שבו למגינים נדרשת תוכנית בדיקה המבוססת על הוכחה, ולא רק על גילוי.
מתקפות סייבר סוכניות משנות את מאזן הכוחות של המגנים
הדרך הטובה ביותר להבין התקפות סוכניות היא להפסיק לדמיין צ'אט-בוט ולהתחיל לדמיין מעגל בקרה. המעגל מתחיל בהשערה לגבי היעד. הוא אוסף מידע, מחליט מה לבדוק בשלב הבא, משתמש בכלים, מפרש את התוצאות, מאחסן את מה שלמד, מנסה שוב כאשר משהו נכשל, ופונה לבני אדם רק כאשר הוא נתקל בעמימות או בגבול מדיניות. הדו"ח הציבורי של Anthropic עצמה מתאר דפוס זה באופן ישיר, כולל גישה לכלים, ביצוע רב-שלבי והתנהגות ארוכת טווח עם התערבות אנושית מוגבלת בלבד. זו הסיבה ש"סוכני" חשוב. הבעיה היא לא רק שמודל יכול לכתוב קוד ניצול. הבעיה היא שהוא יכול להמשיך לעבוד. (אנתרופי)
דבר זה משנה את חישוביו של המגן בארבעה היבטים לפחות. ראשית, המהירות משתפרת. מודל יכול לעבור מסיור ליצירת השערות לניצול תוך שניות, במיוחד בתוכנות המתועדות היטב או במקרים של תצורות שגויות המוכרות לכול. שנית, ההתמדה משתפרת. הלולאה אינה משתעממת, אינה זקוקה למנוחה ואינה שוכחת לנסות וריאציות סמוכות, אלא אם כן מתכנן התהליכים תוכנן בצורה לקויה. שלישית, העברת המיומנויות משתפרת. משימות שפעם דרשו היכרות מעמיקה של המפעיל ניתנות לפירוק למשימות קטנות יותר, שגם גורם חלש יותר יכול לפקח עליהן. רביעית, הדיווח משתפר. הדו"ח של Anthropic ציין במפורש ש-Claude שימש ליצירת תיעוד מקיף של ההתקפה, כולל קבצים מועילים של אישורים גנובים ומערכות שנותחו. תיעוד טוב יותר של התוקף פירושו שימוש חוזר טוב יותר והעברה טובה יותר בין קמפיינים. (אנתרופי)
מקרה FortiGate מוסיף גורם חמישי: נקודות תורפה ישנות הופכות למסוכנות יותר כאשר עלות הניצול שלהן בקנה מידה נרחב יורדת. ב-AWS ציינו כי הקמפיין לא הצריך פיתוח ניצול חדשני של FortiGate. הוא הצריך יציאות ניהול חשופות, פרטי הזדהות חלשים ואימות חד-גורמי. במילים אחרות, המחסום לא היה פיתוח ניצול מורכב. המחסום היה ביצוע משמעתית, חוזרת ונשנית, בהיקף נרחב. הבינה המלאכותית הורידה את המחסום הזה. זוהי נקודה מכרעת עבור המגנים, משום שהיא משמעותה שניהול חשיפה בסיסי וחיזוק זהויות הופכים להיות בעלי ערך רב עוד יותר, ולא פחות, בעידן של מתקפות סוכניות. (אמזון ווב סרוויסס בע"מ)
עם זאת, הנתונים הסטטיסטיים אינם נוטים באופן מוחלט לטובת התוקף. חברת Anthropic הודתה בפומבי כי לעתים קלוד "הזתה" פרטי הזדהות או טענה שהפיקה נתונים סודיים, בעוד שבפועל היו אלה נתונים ציבוריים. CNN ציטטה גם אנשי מקצוע שאמרו כי למודלים מתקדמים עדיין חסר חלק מההקשר שיש לתוקף אנושי לגבי איזה מידע הוא באמת בעל ערך בתוך ארגון. הדו"ח של HackerOne מוסיף אזהרה דומה מצד חוקרים שאומרים כי הבינה המלאכותית עדיין מחמיצה את ההיגיון העסקי ואת ההנמקה של ניצול שרשרת. למגבלות אלה יש חשיבות. הן משמעותן היא שהמגנים לא צריכים להגיב בפאניקה. עליהם להגיב במשמעת הנדסית. התגובה הנכונה לפרימיטיב תוקף לא אמין אך משתפר במהירות היא לולאת אימות הדוקה יותר בצד ההגנתי. (אנתרופי)
אחת הטעויות הגדולות ביותר שצוותי אבטחה עושים בתחום זה היא בלבול כיסוי עם אמת. מערכות אוטומטיות יכולות לבדוק נתיבים רבים יותר ממה שבן אדם מסוגל לבדוק באותו פרק זמן. אך אין זה אומר שכל מסקנה היא נכונה. מודל עלול לפרש לא נכון את המצב, לבלבל בין תגובת CDN להתנהגות המקור, לעשות שימוש חוזר בהפעלה מאומתת שנפגמה, או לטעון לקיומה של פגיעות על סמך דפוס תגובה שאינו נושא למעשה הרשאות. אם מגן מתייחס לכיסוי רחב יותר כשווה ערך לראיות חזקות יותר, התוצאה היא מבול של רעש שנוצר על ידי בינה מלאכותית. הבעיה האמיתית שיש לפתור אינה כיצד לייצר יותר ממצאים מועמדים. הבעיה האמיתית היא כיצד לאשר אילו מבין הממצאים הללו עומדים במבחן השחזור ובאימות עצמאי.
מדוע עוזרי טיסה וסורקים מבוססי בינה מלאכותית אינם מהווים בדיקות חדירה מבוססות בינה מלאכותית
המונח "בדיקות חדירה מבוססות בינה מלאכותית" הפך כיום למונח כה רחב, עד שלעתים קרובות הוא מסתיר את ההבחנות המדויקות שרוכשי פתרונות אבטחה זקוקים להן יותר מכל. ההגדרה של NIST נותרה נקודת הייחוס המרכזית. במונחים של NIST, בדיקת חדירה היא בדיקה המאמתת את המידה שבה מערכת, מכשיר או תהליך מתנגדים לניסיונות פעילים לפגוע באבטחתם. NIST SP 800-115 מוסיף כי בדיקות אבטחה טכניות כוללות תכנון וביצוע בדיקות, ניתוח ממצאים ופיתוח אסטרטגיות למזעור נזקים. הגדרה זו שימושית מכיוון שהיא מחריגה מיד קטגוריה גדולה של מוצרים שיכולים לדבר ברהיטות על נקודות תורפה, אך אינם יכולים לאמת את יכולת הניצול בהקשר. (csrc.nist.gov)
מדריך בדיקות אבטחת האינטרנט של OWASP מדגיש את אותה הנקודה מנקודת המבט של היישום. בדיקות אינטרנט אמיתיות כוללות ניהול זהויות, אימות, הרשאה, ניהול הפעלה, אימות קלט, לוגיקה עסקית, תצורה ועוד. החומר של OWASP בנושא הלוגיקה העסקית חשוב במיוחד, משום שהוא מזכיר לקוראים כי תקלות משמעותיות רבות אינן רק באגים פשוטים בקוד. מדובר בטעויות בזרימת העבודה, בבעיות בסדר השלבים, באי-התאמות במצב, ובהנחות שרק מתגלות כאשר בודק מנתח את הקשר בין בקשות ותפקידים שונים. כלי שאינו מסוגל לשמור על מצב, להסיק מסקנות לגבי הזרימה ולאמת את ההתנהגות בצד השרת אינו מבצע בדיקות חדירה כלליות לאינטרנט רק משום שהוא מסוגל להסביר הזרקת SQL. (קרן OWASP)
לכן יש להתייחס לסורקים, ל"טייסי משנה" ולבדיקות חדירה מבוססות בינה מלאכותית מאומתות כאל סוגים שונים של יכולות.
| סוג יכולת | מה הוא עושה טוב | מה שלרוב חסר | השימוש המומלץ ביותר | הסיכון הגדול ביותר לשימוש לא נאות |
|---|---|---|---|---|
| סורק פגיעות | ספירה מקיפה, התאמת גרסאות, טעויות תצורה ברורות, מלאי בקנה מידה של האינטרנט | מצב מאומת, לוגיקה עסקית, פגיעות בסביבה ספציפית, השפעה מצטברת | ניטור חשיפה רציף והיגיינה | התייחסות לחתימה תואמת כהוכחת סיכון |
| טייס משנה מבוסס בינה מלאכותית | סיכום, סיוע בבדיקת קוד, סיעור מוחות בנוגע לתוכן, גיבוש השערות, ניסוח דוחות | אימות עצמאי, טיפול אמין במצבים, ביצוע מוגבל, ראיות שניתן לשחזר | לעזור לבוחן אנושי לחשוב מהר יותר | להחליף בין הסבר משכנע לממצא מאומת |
| תהליך עבודה מאומת לבדיקות חדירה באמצעות בינה מלאכותית | תכנון המבוסס על סיור מקדים, בדיקות פעילות מוגבלות, השמעה מחדש עם שמירת מצב, אישור עצמאי, אריזת ראיות | החלפה מלאה של שיקול הדעת המקצועי בכל הנוגע להחלטות מעורפלות בנוגע להגיון עסקי או להיקף | אימות התקפה מורשה ובדיקה חוזרת | מתן הרשאות יתר והפיכת תהליך העבודה למבצע ללא פיקוח |
ההבדל אינו תיאורטי בלבד. הוא משפיע על תהליכי הרכש, על תכנון ההיקף, על תכנון זרימת העבודה ועל המשמעות האמיתית של דוח. סורק יכול לציין שקיים פורטל כניסה. קופילוט יכול להציע מה לבדוק סביב אותו פורטל. זרימת עבודה מאומתת של בדיקות חדירה מבוססות בינה מלאכותית צריכה להיות מסוגלת לקבוע, במסגרת ההרשאות והמדיניות, האם ניתן להגיע לפורטל ממקום לא מורשה, האם ניתן לעקוף את אמצעי הבקרה שלו, האם הפעלה נשארת מבודדת בין תפקידים, האם ניתן לשחזר את התוצאה, ואילו ראיות מדויקות דרושות למהנדס אחר כדי לאשר את הבעיה.
ההבחנה הזו כבר ניכרת בכמה מהפרסומים הציבוריים הטובים יותר של ספקי אבטחה התקפית. הפוסטים הטכניים האחרונים של Penligent מועילים בהקשר זה, משום שהם אינם מגדירים בדיקות חדירה מבוססות בינה מלאכותית (AI) כפלט של סורק המלווה בפרוזה נאה יותר. הם מגדירים זאת על סמך היכולת של המערכת לשמור על הקשר, לטפל ביישומים בעלי מצב (stateful), להוכיח את ההשפעה, ולהפיק ראיות שמהנדס אחר יוכל לשחזר; כמו כן, הם מתארים מסגרת עבודה המפרידה בין תכנון, ביצוע, אימות ודיווח, במקום לדחוס את הכל לתוך לולאת צ'אט אחת. גם אם צוות לעולם לא יאמץ את Penligent, מסגרת זו קרובה יותר למה שקונים בוגרים צריכים לדרוש מכל כלי בקטגוריה זו. (Penligent)
בדיקות חדירה מבוססות בינה מלאכותית מאומתות – בסיס ייחוס טוב יותר לצוותי אבטחה
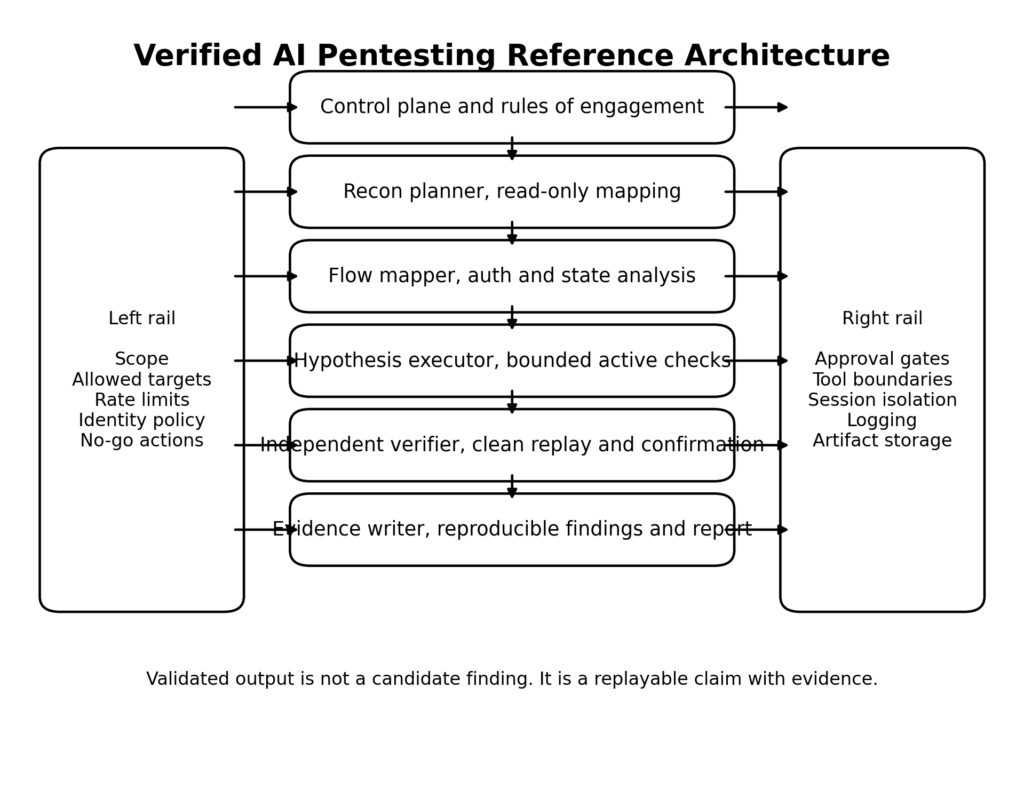
מאת בדיקת חדירות מבוססת בינה מלאכותית מאומתת, כלומר תהליך עבודה סוכני המסוגל לייצר השערות תוקפניות, לבצע בדיקות מוגבלות במסגרת הרשאה מפורשת, לשמור על מצב היישום הדרוש לבדיקת התנהגות אמיתית, ואז להוכיח או להפריך את טענותיו באמצעות ראיות עצמאיות. החלק האחרון הוא החשוב ביותר. זרימת העבודה אינה מסתיימת כאשר המודל אומר "ניצלתי את זה". היא מסתיימת כאשר הטענה עומדת במבחן השחזור בתנאים מבוקרים ומייצרת תוצרים שמישהו אחר יכול לבדוק. זהו סטנדרט שונה מאוד מ"המודל נשמע משכנע". (csrc.nist.gov)
דרך מועילה להתייחס לנקודת הייחוס הזו היא לשאול שש שאלות לגבי כל מערכת "בדיקת חדירה מבוססת בינה מלאכותית". האם היא מסוגלת להישאר בגבולות ההיקף מבלי להסתמך על מזלו של המפעיל? האם היא מסוגלת להפריד בין תכנון לקריאה בלבד לבין פעולות המשנות את המצב? האם היא מסוגלת לשמור על מצב מאומת לאורך תהליך רב-שלבי? האם היא מסוגלת להבחין בין ממצאים פוטנציאליים לממצאים מאומתים? האם היא מסוגלת להציג בדיוק את מה שעשתה? האם אדם אחר יכול לשחזר את הראיות? אם התשובה למספר שאלות אלה היא "לא", המערכת עשויה עדיין להיות בעלת ערך, אך היא עדיין אינה מהווה תהליך בדיקת חדירות אמין.
זהו גם המקום שבו חלק מההייפ סביב פעילות "צוות אדום" אוטונומית לחלוטין מתחיל להתפוגג. אוטונומיה מלאה נשמעת מרשימה עד שה"תוצאה חיובית כוזבת" הראשונה הופכת לעבודה הנדסית מבוזבזת, או עד שההגדרה הראשונית הרחבה מדי של ההרשאות גורמת למערכת לבדוק את הסביבה הלא נכונה, או עד שהניצול ה"מוצלח" הראשון מתגלה כ"תוצר לוואי" של הפעלה שלא ניתן לשחזר. בארגונים אמיתיים, זרימות העבודה המנצחות הן לעתים נדירות האוטונומיות ביותר. הן אלה ששומרות על השליטה ומקצרות את הדרך מהאות ועד להוכחה.
הניסוח הציבורי של Penligent בנושא זה בולט במיוחד, שכן הוא מגדיר במפורש את המערכת סביב "תהליכי עבודה סוכניים הנמצאים בשליטתכם", והפרסומים הטכניים החדשים שלה נוטים לכיוון אימות התקפי מסוג "human-in-the-loop" (מעורבות אנושית) ו"ראיות תחילה", ולא לכיוון אוטונומיה בלתי מוגבלת. זהו הכיוון הנכון עבור הקטגוריה. השאלה החשובה אינה האם סוכן יכול להוציא פקודות. השאלה החשובה היא האם ניתן לנעול את ההיקף, להגביל את הפעולות ולשמור על הראיות בצורה מספקת כדי שמהנדס אחר יוכל לבדוק מחדש ולפרסם תיקון. (Penligent)
ארכיטקטורת ייחוס לבדיקות חדירה מאומתות של בינה מלאכותית
מערכת בדיקות חדירה מבוססת בינה מלאכותית מאומתת צריכה להיות מתוכננת כפלטפורמת בדיקה מבוקרת, ולא כפקודה בודדת ומבריקה. ככל שזרימת העבודה הופכת להיות יותר סוכנתית, כך הארכיטקטורה הופכת להיות חשובה יותר. חומר ה-Claude Code הציבורי של Anthropic מועיל כאן, לא משום שסוכני קידוד ובדיקות חדירה הם אותו הדבר, אלא משום שהמסמכים חושפים תבניות עיצוב קונקרטיות המתאימות היטב לאימות התקפי מורשה: מצבי תכנון לקריאה בלבד, סוכנים-משנה מיוחדים, גבולות גישה לכלים, מודלי הרשאות, סנדבוקסינג, הוקס וניהול הקשר. הלקח הוא שהתנהגות סוכנים מועילה נובעת מהמערכת הסובבת, ולא רק מהמודל. (קלוד)
מישור הבקרה וכללי ההתנהלות בבדיקות חדירה מבוססות בינה מלאכותית
השכבה הראשונה חייבת להיות מישור בקרה. לפני שתהליך העבודה מזהה יעד, הוא זקוק להיקף פעולות הניתן לקריאה ממוחשבת, לאישורים מאושרים, למגבלות קצב, לפעולות אסורות, לכללי טיפול בנתונים ולדרישות רישום. אין מדובר בביורוקרטיה לשמה. זהו המנגנון המונע ממערכת מהירה להפוך למערכת רשלנית. פרופיל ה-Cyber AI המתהווה של NIST שימושי מכיוון שהוא מארגן במפורש את הבעיה בשלושה תחומי מיקוד: אבטחת מערכות AI, ביצוע הגנה סייברית מבוססת AI וסיכול מתקפות סייבר מבוססות AI. זרימת עבודה בוגרת של בדיקות חדירה (pentesting) נמצאת בחפיפה. היא משתמשת ב-AI להגנה, אך עליה להיות מאובטחת בעצמה, והיא קיימת בדיוק משום שמתקפות מבוססות AI הן אמיתיות. (NIST)
לכל הפחות, על מישור הבקרה לענות על השאלות הבאות לפני שליחת בקשה פעילה אחת: אילו דומיינים וכתובות IP נכללים בהיקף. אילו חשבונות ניתן להשתמש בהם, ובאיזו רמת הרשאות. אילו פעולות הן לקריאה בלבד, אילו מותרות באישור, ואילו אסורות על הסף. מה נחשב כהוכחה. היכן מאוחסנים הארטפקטים. מתי נדרש אישור אנושי. לאילו כלים יש גישה לרשת החיצונית. כיצד מוגבלות ניסיונות חוזרים. מרבית תהליכי העבודה הכושלים בתחום אבטחת ה-AI אינם נכשלים משום שהמודל חלש מדי. הם נכשלים משום שהמדיניות הסובבת אותם מעורפלת מדי.
נקודת התחלה פשוטה הניתנת לקריאה על ידי מחשב עשויה להיראות כך:
התקשרות: שם: customer-portal-retest היקף: דומיינים: - app.example.com - api.example.com טווחי CIDR: - 203.0.113.0/28 זהויות: - שם: basic-user סוג: test_account
- שם: readonly-admin סוג: test_account פעולות אסורות: - כתיבה הרסנית - הוצאת נתונים מעבר לרשומות הבדיקה שהוזנו - פיזור סיסמאות - הורדת קבצים המונית אישור נדרש עבור: - שינויים במצב מאומת - ניסיונות העלאת הרשאות
- כל פעולה מעל 30 בקשות בדקה דרישות ראיות: - השמעה חוזרת של הדפדפן - זוג בקשות ותגובות HTTP גולמיות - אישור יומן בצד השרת כאשר זמין רישום: store_commands: true store_http_transcripts: true store_screenshots: true
הקובץ הזה אמנם לא מרהיב, אבל הוא מאלץ את המערכת לפעול כמערכת בדיקה במקום כעוזרת הפועלת באופן חופשי. הוא גם יוצר הסכם שבני אדם יוכלו לבדוק מאוחר יותר.
בדיקת סיור תחילה, פעולה לאחר מכן בבדיקות חדירה של מערכות בינה מלאכותית
החומר שפרסמה חברת Anthropic בנושא "Plan Mode" הוא אחד הרעיונות הניתנים ביותר ליישום מעולם התכנות. המסמכים מתארים את "Plan Mode" כחקירה במצב קריאה בלבד, המשמשת למחקר ולאיסוף דרישות לפני ביצוע שינויים. בתחום האימות ההתקפי, המהלך המקביל הוא תכנון המבוסס על סיור מקדים. התחילו בזחילה, מיפוי נכסים, זיהוי גבולות אימות, קיבוץ נקודות קצה ופירוט קצוות אמון סבירים לפני שתבצעו כל פעולה המשנה את המצב. פעולה זו מפחיתה רעש, משמרת את איכות הראיות ומפחיתה באופן דרמטי את הסיכוי שסוכן יבזבז זמן על בדיקות לא רלוונטיות. (תיעוד ה-API של Claude)
תכנון שמבוסס על סיור מקדים הוא גם התרופה הטובה ביותר נגד הביטחון המוטעה שמקנים מודלים גדולים. מודל שמתחיל בבדיקות אקטיביות מוקדם מדי נוטה להיתקע בנקודת התורפה הראשונה שנראית סבירה שהוא מבחין בה. מודל שנאלץ להישאר בשלב התכנון למשך זמן מה יבנה לרוב מפה טובה יותר של המקומות שבהם נמצאים באמת הנתיבים המסוכנים. בפועל, משמעות הדבר היא להקדיש את החלק המוקדם של הריצה לשאלות כגון: אילו נקודות קצה דורשות אימות. אילו תפקידים קיימים. אילו זרימות הן רב-שלביות. אילו אסימוני מצב משמשים שוב. לאילו ממשקי ניהול ניתן לגשת מבחוץ. אילו שילובים של צד שלישי מרחיבים את הגבול. התשובות לעיתים רחוקות מרשימות, אך הן קובעות אם אימות מאוחר יותר יהיה משמעותי.
סוכנים משנה מתמחים גוברים על פקודה אחת ענקית
התיעוד של Claude Code מבית Anthropic תומך במפורש בסוכנים-משנה מותאמים אישית, בעלי הנחיות, כלים, מצבי הרשאה ושרתים MCP אופציונליים בעלי היקף מוגדר משלהם. תבנית עיצוב זו מתאימה באופן מפתיע היטב לבדיקות חדירה, שכן המשימות במסגרת פרויקט אמיתי שונות זו מזו במידה כזו, שאין להן לחלוק את אותו הקשר והרשאות. סיור אינו מיפוי זרימת דפדפן. מיפוי זרימת הדפדפן אינו אימות ניצול. אימות ניצול אינו דיווח. כאשר סוכן אחד מבצע את כל אלה, הגישה לכלי מתפשטת, ההקשר מזדהם, והייחוס של שגיאות הופך לקשה. (תיעוד ה-API של Claude)
הגישה המועדפת היא לפצל את זרימת העבודה למשימות מפורשות:
| שכבה | תפקיד עיקרי | כלים נפוצים | גבול ההרשאה | הכישלון שהוא מונע |
|---|---|---|---|---|
| עובד סיור | מלאי, זיהוי נקודות קצה, מיפוי משטח תפקידים | DNS, HTTP, סריקה, דפדפן לקריאה בלבד | ללא כתיבה, ללא אימות עם הרשאות מיוחדות | פעולה הרסנית או רועשת בשלב מוקדם |
| מפת זרימה | הבנת התנהגות האפליקציה בתהליכים רב-שלביים ומעברי אימות | דפדפן, פרוקסי, לכידת בקשות | חשבונות ניסיון בלבד | היעדר לוגיקה עסקית וקצוות מצב |
| מבצע ההשערה | לבצע בדיקות מוגבלות על מועמדים בעלי אות חזק | לקוח HTTP, דפדפן, ממשק שורת פקודה מאושר | נדרשת אישור לביצוע פעולות מסוכנות | דואר זבל המכיל פרצות אבטחה לא ממוקדות |
| בודק עצמאי | הפעל מחדש את הראיות ואמת את ההשפעה | פעילות דפדפן נפרדת, אסימונים חדשים, בדיקת יומנים | אין יצירת השערות | תוצאות חיוביות כוזבות המאששות את עצמן |
| מנסח ראיות | אימות החבילה, שלבים, תוצרים ומגבלות | אחסון מובנה, צילום מסך, השוואה | אין אינטראקציה עם היעד | אובדן יכולת הביקורת |
מבנה זה איטי יותר מלולאה אחת "כל-יכולה" במובן מצומצם אחד: יש בו יותר מבנה. אך הוא מהיר יותר במובן היחיד שחשוב לצוות אבטחה אמיתי. קל יותר לסמוך על התוצאה.
הגדרת הרשאות, סביבת בדיקה מבודדת ומלכודת האישורים
הדו"ח שפרסמה חברת Anthropic במרץ 2026 על מצב האוטומטי של Claude Code צריך להיות חומר קריאה חובה לכל מי שבונה או רוכש תהליכי עבודה בתחום האבטחה הסוכנתית. החברה מציינת כי המשתמשים מאשרים 93 אחוזים מבקשות האישור, ומזהירה כי לחיצות חוזרות ונשנות מובילות לעייפות מהאישור. זהו לקח מכריע עבור כלי אבטחה. אם האדם מאשר כמעט הכל, "מעורבות אנושית בתהליך" עלולה להפוך למראית עין בלבד. זרם בלתי פוסק של בקשות אינו זהה לשליטה משמעותית. (אנתרופי)
אותו פוסט גם מפרט בבהירות את מרחב הפשרות. סביבת סנדבוקס בטוחה יותר, אך כרוכה בעלויות תחזוקה נוספות ועלולה לפגוע ביכולות הדורשות גישה לרשת או למארח. ביטול מוחלט של ההרשאות הוא פתרון קל ליישום, אך אינו בטוח ברוב המקרים. בקשות ידניות נמצאות איפשהו באמצע, אך הנטייה הקיימת בעולם האמיתי לאשר אותן באופן אוטומטי פוגעת בערכן. עבור בדיקות חדירה מבוססות בינה מלאכותית, המסקנה פשוטה: אל תסתמכו על הצפה של בקשות ידניות כמודל הבטיחות העיקרי שלכם. השתמשו בהיקף מפורש, ברשימות מאושרות, במגבלות קצב, במסווגים ובסביבות ביצוע מבודדות במידת האפשר. שמרו את האישורים האנושיים לחציית גבולות אמיתית, ולא לכל פעולה שולית. (אנתרופי)
תיעוד הסוכנים המשניים של Anthropic מחזק את אותו הלקח מזווית אחרת. סוכנים משניים יכולים לרשת או להגביל כלים, להשתמש במצבי הרשאה שונים, ואף לקבל גישה לשרתי MCP שהשיחה הראשית אינה רואה. זהו בדיוק סוג הפירוט הדרוש לבדיקות חדירה של בינה מלאכותית. עובד הסיור לא צריך לקבל את אותן הרשאות כמו המבצע. כותב הראיות לא צריך לקבל כלל כלים לאינטראקציה עם היעד. המאמת צריך לפעול עם מצב חדש והנחות מצומצמות יותר מאשר מחולל ההשערות. תכנון ההרשאות אינו פרט יישום. זהו חלק מרכזי בנכונות. (תיעוד ה-API של Claude)
MCP וגבול הביצוע האמיתי
פרוטוקול Model Context Protocol (MCP) חשוב בהקשר זה משום שהוא הופך מערכת בינה מלאכותית ממנגנון להסקת מסקנות טקסטואליות לגורם פעיל ומחובר. Anthropic הציגה את MCP כסטנדרט פתוח לחיבורים דו-כיווניים מאובטחים בין מקורות נתונים וכלים המונעים על ידי בינה מלאכותית, ודוח הריגול הסייבר שלה מציין במפורש כי הגישה לכלים המשמשים בהתקפות אלה מתבצעת לעתים קרובות באמצעות MCP. משמעות הדבר היא שגבולות הביצוע של סוכן אינם עוד רק הפקודה שלו. הם כוללים מאגרים, דפדפנים, מסדי נתונים, קונסולות ניהול, חיפוש פנימי וכל שרת מותאם אישית שהארגון חושף. (אנתרופי)
לכך שתי השלכות. ראשית, כל מחבר הוא חלק מגבול האבטחה. מחבר דפדפן לקריאה בלבד אינו מהווה סיכון זהה לזה של מעטפת (shell) עם יציאה בלתי מוגבלת לרשת. מחבר חיפוש אינו מהווה את אותו הסיכון כמו מחבר מסד נתונים. שנית, אבטחה מיידית אינה מספיקה. אפילו מודל המותאם באופן מושלם הופך למסוכן אם שכבת הכלים מקבלת הרשאות יתר והיקפה מוגדר בצורה לקויה. השאלה הנכונה בנושא אבטחה אינה "האם אנו סומכים על המודל". השאלה הנכונה היא "למה המערכת המורכבת הזו יכולה לגעת בפועל, ובאילו כללים".
אימות עצמאי בבדיקות חדירה בתחום הבינה המלאכותית
המאפיין בעל ההשפעה הגדולה ביותר בתהליך בדיקת חדירות אמיתי של בינה מלאכותית הוא בודק עצמאי. לא חוות דעת שנייה מאותו הסוכן לאחר שהוא קורא שוב את התפוקה שלו. מסלול אימות נפרד באמת. הדיווח הציבורי של Anthropic על שימוש לרעה בהתקפה מועיל כאן, מכיוון שהוא חושף בשקט את נקודת התורפה המרכזית של האוטונומיה: מודלים יכולים להזות. הם יכולים לטעון שקיימים אישורים כאשר הם אינם קיימים. הם יכולים לטעון להצלחה כאשר הראיות מעורפלות. אם אותו סוכן שיצר את הטענה רשאי לאמת אותה, המערכת פגיעה לשגיאה המאשרת את עצמה. (אנתרופי)
בודק מעשי צריך לבצע לפחות אחת מארבע פעולות. עליו לשחזר את נתיב הדפדפן מתוך הפעלה נקייה. עליו לשחזר את נתיב ה-API באמצעות אסימונים חדשים ותיעוד מדויק של הבקשות. עליו לבצע בדיקה צולבת של הטענה מול נתוני טלמטריה בצד השרת, כגון רשומת יומן או מעבר בין מצבי אובייקט. או שעליו לאמת את ההשפעה באמצעות כלי אורתוגונלי, כגון יישום לקוח שני או בדיקת נראות ספציפית לתפקיד. הבחירה העיצובית הקריטית היא שהמאמת ישתמש בראיות במקום לעשות שימוש חוזר בהנחות של מחולל ההשערות.
אובייקט עם ראיות מינימליות יכול להיראות כך:
{ "finding_id": "AUTHZ-004", "title": "גישה לחשבוניות בין-דיירים באמצעות הפניה ישירה לאובייקט", "hypothesis": "משתמש בסיסי יכול לאחזר חשבונית של דייר אחר על ידי שינוי ה-invoice_id", "preconditions": [ "חשבון בדיקה של משתמש בסיסי",
"שני חשבונות דיירים שהוכנו מראש", "הפעלת דפדפן חדשה" ], "שחזור": [ "התחבר כמשתמש בסיסי של דייר A", "פתח את רשימת החשבוניות ותעד את בקשת החשבונית", "החלף את invoice_id בחשבונית ידועה של דייר B", "הפעל מחדש את הבקשה עם אסימון ההפעלה המקורי" ],
"expected_effect": "מטא-נתוני החשבונית של דייר B הופכים לגלויים לדייר A", "verification": { "method": [ "הפעלה חוזרת של הדפדפן מהפעלה נקייה", "תמלול HTTP גולמי", "אישור יומן גישה לאובייקט" ], "status": "confirmed" },
"תוצרים": [ "screenshot.png", "request.txt", "response.txt", "log-snippet.txt" ], "מגבלות": [ "אומת רק בסביבת ביניים", "ההשפעה מוגבלת למטא-נתונים, לא להורדת קבצים" ]
}
הסכימה הזו משעממת בכוונה. משעמם זה טוב. השעמום הוא זה שמאפשר למהנדס אחר להבחין בין "השערה מעניינת" ל"סיכון מאומת".

Fortinet CVE-2024-55591 ו-CVE-2025-24472: מדוע נתיבי הניהול בקצה הרשת מהווים יעדים מושלמים לתקיפה
אם אתם מחפשים סוג של פגיעות שהופך למסוכן יותר בעידן של מתקפות סוכנים, התחילו בממשקי הניהול החשופים לאינטרנט. צוות ה-PSIRT של Fortinet מפרט את CVE-2024-55591 ו-CVE-2025-24472 יחד בהודעת אזהרה קריטית, מסמן אותם כפגיעות ללא צורך באימות, ומציין כי ידוע על ניצולן. התיאור של NVD ל-CVE-2024-55591 מציין שתוקף מרחוק יכול להשיג הרשאות מנהל-על באמצעות בקשות מתוכננות למודול websocket של Node.js. התיאור של NVD ל-CVE-2025-24472 מצמצם את הבעיה השנייה בצורה מדויקת יותר, ומציין שתוקף לא מאומת בעל ידע מוקדם על מספרי סידורי המכשירים במעלה ובמורד הזרם עשוי להשיג הרשאות מנהל-על במכשיר במורד הזרם אם Security Fabric מופעל, באמצעות בקשות פרוקסי CSF מתוכננות. CISA הוסיפה את CVE-2024-55591 לקטלוג KEV בינואר 2025 ומציינת גם את CVE-2025-24472 בקטלוג KEV. (מעבדות FortiGuard)
ל-CVE-ים אלה יש רלוונטיות רבה למודלים של איומים סוכניים, ומסיבה פשוטה: הם ממוקמים בקצה הרשת, מכוונים למנהלי מערכת, ובעלי ערך רב. מערכת המסוגלת למנות באופן רציף ממשקים חשופים, להבחין בין נתיבי ניהול לנתיבי משתמשים, לקשר בין כותרות דף (banners) וטביעות אצבע של מוצרים, ולהחליט אילו בדיקות כדאי לבצע – יכולה לצמצם באופן דרמטי את המאמץ הנדרש לאיתור וניצול של חשיפות מסוג זה. גם כאשר מתקנים CVE ספציפי, הדפוס נותר זהה: מישורי ניהול חשופים בשילוב עם אימות חלש או ניתן לעקיפה מהווים מטרות אידיאליות לאיטרציה בקנה מידה של מכונות.
קמפיין ה-FortiGate ב-AWS שתועד בשנת 2026 מחזק את הנקודה הזו מכיוון הפוך. התוקף לא נזקק לפרצת "יום אפס" חדשה של Fortinet. יציאות ניהול חשופות, פרטי הזדהות חלשים ואימות חד-גורמי הספיקו, בשילוב עם הרחבת היקף ההתקפה בסיוע בינה מלאכותית. הלקח למגינים אינו "להיות ערניים רק ל-CVE האחרון". הלקח הוא "להתייחס לחשיפת משטח הניהול כאל בעיה המכפילה את העוצמה". כאשר קיימת עקיפת אימות קריטית, הסיכון ברור. כאשר אין באג כזה, נתיבי ניהול חשופים עדיין מסוכנים מכיוון שה-AI מוריד את העלות של ניסיון נתיבים סמוכים, שימוש חוזר בקודי גישה ושימוש לרעה בתצורה. (אמזון ווב סרוויסס בע"מ)
דפוס אימות בטוח ומאושר לסביבה שלכם הוא להתחיל באימות החשיפה, ולא בניצול. לדוגמה:
#!/usr/bin/env bash # הפעל רק על מערכות שבבעלותך או שקיבלת אישור מפורש לבדוק.
while read -r host; do echo "=== $host ===" nmap -Pn -p 443,8443,10443 --open "$host" curl -k -I --max-time 5 "https://$host/" | head -n 5
for path in /login /remote/login /remote/fgt_lang /admin /ssl-vpn/login; do code=$(curl -k -s -o /dev/null -w "%{http_code}" --max-time 5 "https://$host$path")
if [ "$code" != "000" ] && [ "$code" != "404" ]; then echo "$path -> HTTP $code" fi done done < approved_targets.txt
סקריפט זה אינו מוכיח את האפשרות לניצול, ואין זה תפקידו. תפקידו הוא לזהות את המקומות שבהם לאפשרות לניצול תהיה החשיבות הגדולה ביותר. בתהליך בדיקת חדירות מאומתת של בינה מלאכותית, הצעד הבא אינו "לשגר כל מטען". הצעד הבא הוא להחליט אילו נקודות תורפה ראויות למסלול אימות מוגדר, מתועד ומאושר.
ההתמודדות עם הסיכון חייבת להתבצע בכמה מישורים. יש להתקין תיקונים לגרסאות Fortinet המושפעות בהתאם להנחיות היצרן. יש להסיר את הגישה הציבורית לממשקי הניהול בכל מקום אפשרי. יש לדרוש אימות רב-גורמי (MFA) עמיד בפני פישינג ונתיבי גישה ניהוליים פרטיים. יש להשבית או להגביל באופן מחמיר תכונות המרחיבות את נתיבי האמון, אם אין בהן צורך. והחשוב ביותר: אין להפריד בין ניהול חשיפת הנכסים לבין חיזוק הזהויות. המקרה של AWS מהווה תזכורת לכך שבינה מלאכותית עלולה להפוך תיאום לקוי בין צוותים אלה ליתרון בידי התוקפים. (מעבדות FortiGuard)
PAN-OS CVE-2024-3400, מדוע RCE בקצה הרשת מאט את זמן התגובה
הפגיעות CVE-2024-3400 של Palo Alto Networks מהווה דוגמה מועילה נוספת, שכן היא ממחישה כיצד פגיעות RCE בקצה הרשת (Internet Edge) משתלבות באותו דפוס כללי. בהודעת האזהרה של הספק נכתב כי הפגיעות היא הזרקת פקודות הנובעת מיצירת קבצים שרירותית בתכונת GlobalProtect של מערכת ההפעלה PAN-OS, והיא עלולה לאפשר לתוקף לא מאומת להריץ קוד שרירותי עם הרשאות root בחומות האש המושפעות. Palo Alto הבהירה גם כי Cloud NGFW, מכשירי Panorama ו-Prisma Access אינם מושפעים. CISA פרסמה הנחיות בנושא באפריל 2024. (אבטחת Palo Alto Networks)
ל-CVE זה יש חשיבות כאן משתי סיבות. ראשית, מדובר בסוג של פגיעות שמניב תוצאות מיידיות כאשר בוחרים נכון את היעד. אם תהליך עבודה יכול לזהות במדויק נקודות חשיפה של GlobalProtect ולהתאים אותן לתצורות הפגיעות, הזמן שבין סקירת המלאי ברשת לבין ניסיונות תקיפה משמעותיים יכול להתקצר במהירות. שנית, עוד לפני שאוטומציה של נתיב ניצול אמין, בינה מלאכותית יכולה להאיץ את כל מה שקשור לניצול: מיון סביבות, ניתוח גרסאות, קיבוץ קמפיינים, קביעת סדרי עדיפויות לנתיבי תקיפה ורישום הערות לאחר הפריצה. זו הסיבה שצוותים צריכים להפסיק לחשוב רק במונחים של "האם המודל יכול לייצר קוד ניצול". שאלה טובה יותר היא "כמה מהעבודה הסובבת של המפעיל המודל יכול כעת להחליף או לדחוס".
המסר ההגנתי דומה למקרה של Fortinet, אך מעט רחב יותר. עבור RCE בקצה הרשת, רשימת החשיפות המאושרת היא הכל. אילו נכסים הפונים לאינטרנט מאפשרים גישה מרחוק. אילו תכונות מופעלות. לאילו מכשירים ניתן להגיע מרשתות לא מורשות. אילו יומנים יעידו על ניצול לרעה של הבעיה. אילו אמצעי בקרה יגבילו את היקף הנזק במקרה של אובדן השליטה בקצה הרשת. תהליך בדיקת חדירות מבוסס AI מאומת הוא בעל ערך רב במיוחד במקרה זה, מכיוון שהוא יכול להפוך את הודעות הספקים ונתוני הנכסים למשימות הוכחה ספציפיות לסביבה, במקום לפאניקה כללית בנוגע לתיקונים.
תהליך אימות טוב עבור סביבת הארגון שלכם יתחיל בבדיקת תקינות התצורה. יש לוודא שהמאפיין הרלוונטי מופעל. יש לוודא שניתן לגשת לממשק הניהול או לממשק הגישה מרחוק מרשתות לא מהימנות. יש לוודא אילו אמצעי בקרה מפצים קיימים, כגון הגבלות IP, מתווכי גישה מובנים או פילוח. רק אז החליטו אם יש צורך בבדיקה פעילה יותר במסגרת ההרשאה. המטרה היא לתרגם כותרת CVE להצהרת סיכון ספציפית לסביבה, במקום לאפשר לארגון להתנדנד בין שאננות לדחיפות כללית.
איתור ואימות: תהליך עבודה מעשי לצוותי אבטחה
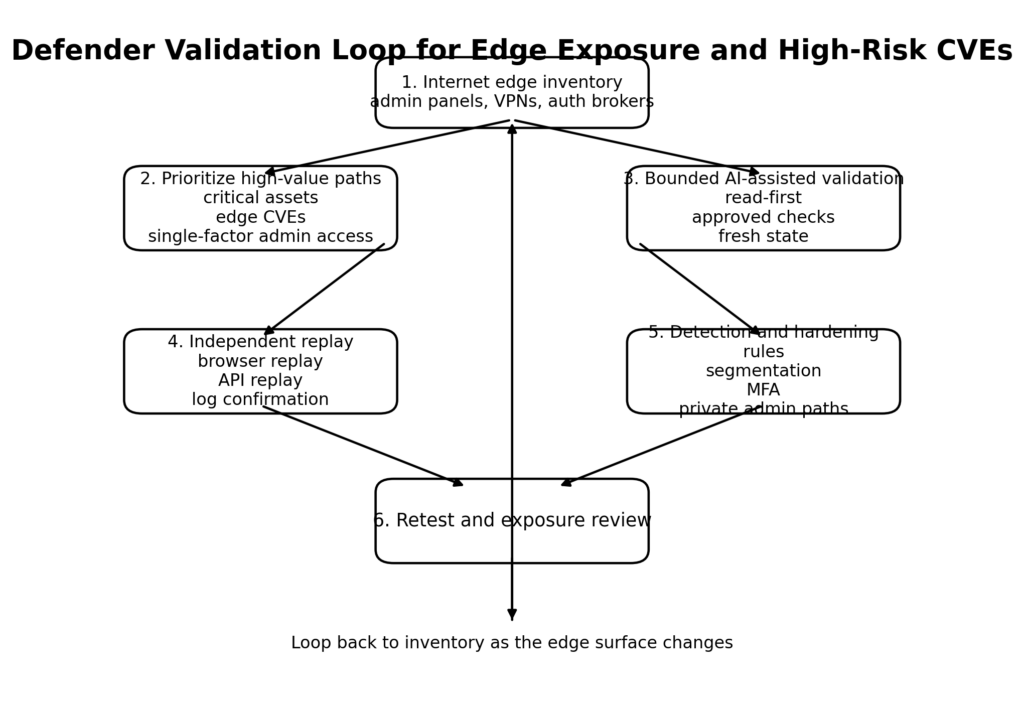
הדרך המהירה ביותר לאבד את הערך שבשימוש ב-AI בתחום האבטחה היא להשתמש בו רק בשלב ה-PDF. עד שהממצא הופך לטקסט כתוב, רוב העבודה החשובה כבר הסתיימה. המקום הנכון ליישם את ה-AI הוא בשלב מוקדם יותר: קורלציה בין נכסים, יצירת נתיבי בדיקה אפשריים, תכנון השמעה חוזרת, איסוף ראיות ותמיכה בבדיקות חוזרות. אך שימושים אלה מועילים רק כאשר הם משולבים עם נקודות ביקורת ואימות ברורות.
ניתן לחלק את תהליך העבודה המעשי של צוותי האבטחה לששה שלבים.
ראשית, יש לבנות מערך נתונים של נקודות תורפה בקצה הרשת. הכוונה היא לאתר כל ממשק ניהול, מתווך אימות, שער VPN, סביבת ביניים ולוח בקרה נשכח שניתן להגיע אליהם מרשתות לא מהימנות. המקרה של AWS FortiGate מזכיר לנו שתוקפים אינם זקוקים לחידושים כאשר מפת החשיפה לקויה. הם זקוקים לנקודות תורפה נגישות. (אמזון ווב סרוויסס בע"מ)
שנית, יש לסווג את החשיפה לפי ערך ולפי עלות התפעול. אתר שיווק ציבורי אינו זהה לממשק ניהול ציבורי. פורטל מאובטח עם גבולות הפעלה ברורים אינו זהה ללוח בקרה משותף המוגן באמצעות אימות חד-גורמי. הבינה המלאכותית מסוכנת ביותר כאשר היא יכולה להקדיש משאבים מועטים לממשקים בעלי ערך גבוה ואנטרופיה נמוכה. לכן, נקודות קצה ניהוליות, מכשירים בקצה הרשת ותהליכי עבודה עסקיים חוזרים ונשנים צריכים לעמוד בראש תור האימות.
שלישית, יש לכפות על מערכת ה-AI לפעול במצב של "סיור תחילה" (recon-first) תוך התחשבות במדיניות, לפני שמאפשרים ביצוע בדיקות אקטיביות. "מצב התכנון" (Plan Mode) הציבורי של Anthropic ומודל הסוכנים המשניים (subagent) הם דפוסים שימושיים שניתן לאמץ כאן. יש לאפשר לעובד התכנון למפות את משטח התקיפה. יש לאפשר לעובד הזרימה להבין את תהליכי האימות ואת השלבים העסקיים. ורק אז יש לאפשר למבצע לגעת בכל דבר שעלול לשנות את המצב. (תיעוד ה-API של Claude)
רביעית, יש להפריד בין יצירת השערות לאישורן. זהו השלב שבו תוכניות אבטחה רבות המבוססות על בינה מלאכותית נכשלות בשקט. ממצא פוטנציאלי אינו ממצא. צילום מסך אינו הוכחה. קוד תגובה מפתיע אינו הוכחה. ניצול פגיע שעובד בסשן דפדפן מזוהם אינו הוכחה. על הבודק לשחזר את התוצאה ממצב נקי תוך שמירה על תנאי הקדם, ובמידת האפשר, לבצע בדיקה צולבת של הטענה מול יומני השרת או מצב האובייקט.
חמישית, יש לתעד את הראיות באופן מסודר. לכל ממצא צריך להיות מזהה קבוע, יעד מוגדר, תנאים מוקדמים, שלבים מדויקים, תוצרים והצהרת ביטחון המשקפת את מה שאכן אושר. זהו ההבדל בין בינה מלאכותית ככלי עזר לכתיבה לבין בינה מלאכותית כמאיץ תפעולי. הראשונה יוצרת פסקאות מסודרות יותר. השנייה יוצרת מסמך העברה שהמהנדס הבא בתור יוכל להשתמש בו.
שישית, יש להזין את התוצאה חזרה לתהליכי הזיהוי והחיזוק. ממצא התקפי מאומת אינו רק דוח לצוות היישומים. הוא מהווה מידע עבור צוות ה-Blue Team, צוות ה-IAM, צוות ניהול הנכסים וצוות הפלטפורמה. פרופיל ה-Cyber AI של NIST מועיל מכיוון שהוא מתייחס לסיכול התקפות המונעות על ידי בינה מלאכותית ולשימוש בבינה מלאכותית לצורכי הגנה כפעילויות קשורות, ולא כעולמות נפרדים. ארגון בוגר סוגר את המעגל הזה. (NIST)
שאילתת זיהוי בסיסית לבדיקת העומס על ממשק הניהול עשויה להיראות כך:
let AdminPaths = dynamic([ "/login", "/admin", "/remote/login", "/ssl-vpn/login", "/api/v1/auth", "/php/login.php" ]);
AppRequests | where UrlPath has_any (AdminPaths) | summarize requests=count(), failed_auth=countif(StatusCode in (401,403)), distinct_sources=dcount(SourceIp), user_agents=dcount(UserAgent) לפי bin(Timestamp, 5m), Host | where requests > 100 or failed_auth > 20 or distinct_sources > 15 | סדר לפי Timestamp יורד
והשרטוט המקביל בסגנון סיגמא לרעש הזהות סביב משטחי הניהול עשוי להיראות כך:
כותרת: פרץ חשוד בממשקי הניהול id: 8f2f0c78-3c57-4c65-9f89-verified-ai-pentest-example סטטוס: ניסיוני מקור יומן: קטגוריה: שרת אינטרנט זיהוי: בחירה:
cs-uri-stem|מכיל: - "/admin" - "/remote/login" - "/ssl-vpn/login" תנאי: בחירה שדות: - c-ip - cs-user-agent - cs-host - sc-status רמה: בינונית
הדוגמאות הללו הן כלליות בכוונה. הרעיון הוא לא ש"כלל קבוע מראש" אחד יפתור את הבעיה. הרעיון הוא שפעילות התקפית שאושרה צריכה להפוך ללוגיקת טלמטריה קונקרטית, ולא רק לפסקה בדוח.
מדוע הלוגיקה העסקית עדיין מאלצת את בני האדם להיות מעורבים בתהליך
אחת התפיסות המוטעות הנפוצות ביותר בנוגע לפריצות באמצעות סוכנים היא שברגע שהמודל מסוגל לשלב כלים, החלק הקשה כבר מאחורינו. ההנחיות של OWASP בנושא לוגיקה עסקית מהוות תזכורת מועילה לכך שזה לא נכון. פגמים בלוגיקה העסקית תלויים לעתים קרובות ברצף, בתפקיד, בעיתוי, בקשרים בין נתונים ובהנחות המוטמעות בעיצוב זרימת העבודה. מודל עשוי להיות טוב בזיהוי תבניות בתיעוד או בקוד, אך הוא עדיין עלול לפספס את מה שהופך זרימה למעניינת מבחינה כלכלית או תפעולית בתוך מערכת אמיתית. (קרן OWASP)
דו"ח HackerOne לשנת 2025 מעלה את אותה הטענה מנקודת המבט של החוקרים. על פי הדו"ח, 58 אחוזים מהחוקרים שנשאלו סבורים כי הבינה המלאכותית (AI) מתעלמת מהלוגיקה העסקית או מפרצות שרשרת, ורק 12 אחוזים מאמינים שהיא יכולה להחליף אותם. ממצא זה צריך לעצב את האופן שבו צוותים מיישמים בינה מלאכותית בבדיקות חדירה. יש להשתמש בבינה מלאכותית כדי להרחיב את הכיסוי, להאיץ את תהליך המיון, לתעד באופן פורמלי את שלבי השחזור ולהכין ראיות. השאירו את האחריות על שיקול הדעת הערכי, שיקול הדעת לגבי היקף הבדיקה ופרשנות של זרימות רב-שלביות מעורפלות בידי בני האדם. הטעות היא לא להשתמש ב-AI. הטעות היא לבקש ממנו לגשר על הפער בין "אולי" ל"מוכח" ללא מבנה בקרה מתאים. (HackerOne)
זו גם הסיבה שבגללה הטיפול במצב (state) הוא כה חשוב. בעיות הקשורות ללוגיקה העסקית מתגלות לרוב רק כאשר אותו משתמש עובר בתהליך בסדר לא סטנדרטי, כאשר תפקיד אחד יורש מצב שמור במטמון מתפקיד אחר, כאשר אסימון (token) תקף זמן רב יותר ממה שמציע ממשק המשתמש, או כאשר גישה ישירה לאובייקט עוקפת את הנתיב המיועד. אלה אינם דברים שמסכם ללא מצב (stateless summarizer) יכול לזהות. הם דורשים השמעה חוזרת, הפעלות נקיות, חשבונות מבוקרים ומשמעת ראייתית. בפועל, מערכות ה-AI הטובות ביותר בתחום זה אינן אלה ש"חושבות הכי קשה". הן אלה שעוזרות לבוחן האנושי לשמר את המצב ולהסיק מסקנות לגביו מבלי לאבד את הדרך של מה שאכן אושר.
דפוסי כשל נפוצים בבדיקות אבטחה של בינה מלאכותית סוכנתית
אופן הכשל הנפוץ הראשון הוא מתן הרשאות יתר. צוותים מתלהבים מהאוטונומיה, מחברים את הסוכן למספר רב מדי של מערכות, ואז מבלבלים בין טווח ההגעה ליכולת. מודל שמסוגל לגשת למעטפת המערכת, לדפדפן, למאגר הקוד, למערכת מעקב אחר תקלות, למאגר הסודות ול-Wiki הפנימי אינו בהכרח שימושי יותר. לרוב, פשוט קשה יותר להבין אותו. MCP ודפוסי חיבור דומים מדגישים את החשיבות של נקודה זו עוד יותר, מכיוון שגבולות הביצוע המעשיים של המערכת הולכים ומתרחבים. (אנתרופי)
אופן הכשל השני הוא "תיאטרון האישורים". הנתונים של Anthropic עצמה, המצביעים על כך שהמשתמשים מאשרים 93 אחוזים מהבקשות לאישור, אמורים לערער באופן סופי את הטענה לפיה חלונות קופצים תכופים משמעם בטיחות. אדם שלוחץ על "המשך" בכל בקשה אינו מפעיל שליטה משמעותית. שליטה אמיתית נובעת מגבולות שהוגדרו מראש, מרשימות אישור ספציפיות לכל כלי, זהויות מוגבלות, ביצוע מבודד, ושערים עם חיכוך גבוה רק במקומות שבהם הם באמת חשובים. (אנתרופי)
אופן הכשל השלישי הוא אימות עצמי. במצב זה, המודל מציע פגיעות, מבצע בדיקה משכנעת למחצה, מפרש את התפוקה המרובת הרעשים שלו כהצלחה, ואז מנסח דוח מלוטש שגורם לכל השרשרת להיראות אמינה יותר מכפי שהייתה. ככל שהמערכת מתוחכמת יותר, כך הדבר הופך למסוכן יותר. השמעה חוזרת בלתי תלויה אינה אופציונלית. זהו מחיר האמון.
אופן הכשל הרביעי הוא התייחסות להקשר הסביבתי כאל דבר משני. פגיעות CVE עשויה להיות קריטית ועדיין לא רלוונטית לתצורה הספציפית שלכם. התנהגות חשודה עשויה להיות ניתנת לשחזור ועדיין להיות בעלת השפעה מועטה במודל הגישה שלכם. לעומת זאת, בעיה בדרגת חומרה בינונית בתהליך עבודה משותף של מנהלים עשויה להיות חשובה בהרבה מתאימות גרסאות שזוכה לכותרות. אימות המותאם לסביבה הוא זה שמבדיל בין בדיקות תקיפה משמעותיות לבין "תיאטרון אבטחה" כללי.
אופן הכשל החמישי הוא מתן אפשרות לסוכנים שבנו עובדים ליצור נתיבי תקיפה חדשים למערכות פנימיות ללא פיקוח. Axios כינה זאת "בינה מלאכותית צללית", ולמרות שהמונח רחב יותר מבדיקות חדירה, האזהרה התפעולית היא אמיתית. אם צוותים מחברים סוכנים באופן אגבי למערכות עבודה, לכלים פנימיים או למקורות נתונים רגישים, הם עלולים להרחיב את שטח ההתקפה עוד לפני שקבעו כיצד יש לנהל את אותם סוכנים. סיכון זה שייך לאותה שיחה כמו בינה מלאכותית התקפית, ולא למזכר מדיניות נפרד. (Axios)
מה על רוכשי פתרונות אבטחה לשאול לפני שהם נותנים אמון בכלי בדיקת חדירות מבוסס בינה מלאכותית
קונה טכני הבוחן קטגוריה זו צריך לשאול תחילה שאלות "משעממות". כיצד מוגדר היקף הפעילות? כיצד מטפלים בזהויות? מה קורה כאשר המערכת נתקלת באי-ודאות? האם היא מסוגלת לשמור על מצב מאומת נקי? האם היא מבחינה בין ממצאים פוטנציאליים לממצאים מאומתים? אילו תוצרים היא מאחסנת? האם בודק אנושי יכול לשחזר את השלבים? כיצד מוגבלת הגישה לכלי? כיצד פועל מודל האישור בפועל? שאלות אלו חושפות הרבה יותר ממטריצת תכונות המלאה בכינויים כמו "אוטונומי".
קריטריון ההערכה הנכון אינו האם המערכת מסוגלת לייצר פעילות שנראית תוקפנית. כלים רבים מסוגלים לעשות זאת. הקריטריון הנכון הוא האם המערכת מסוגלת לעבור מתצפית להוכחה שניתן להגן עליה מבלי לאבד שליטה. זו הסיבה שהניסוח של NIST עדיין חשוב, שההיקף של OWASP עדיין חשוב, ושהדיווחים הציבוריים האחרונים של OpenAI, Anthropic, AWS, Bugcrowd ו-HackerOne צריכים להיקרא במשותף. השוק אומר לנו שהיקף התוקפים הולך וגדל, שהחוקרים כבר משתמשים רבות ב-AI, ושלוגיקת העסקים ואיכות הראיות עדיין שומרות על מרכזיותם של בני האדם. המוצרים המנצחים יהיו אלה שנבנו עבור המציאות הזו ולא נגדה. (csrc.nist.gov)
השינוי האמיתי הוא מעבר מבינה מלאכותית שמסבירה את הסיכון לבינה מלאכותית שמוכיחה את הסיכון
קל להסיט את השיח על בינה מלאכותית התקפית מהמסלול, משום שהוא רווי בשמות עצם דרמטיים: "יום אפס", "אוטונומי", "תוכנת ריגול", "על-אנושי", "נשק סייבר". חלק מהשפה הזו מתאר מגמות אמיתיות בתחום. אך ההבחנה המועילה יותר היא פחות קולנועית. השינוי האמיתי הוא מ-AI שמסביר סיכונים ל-AI שמוכיח סיכונים. הסבר על סיכונים הוא מועיל, אך הוא עדיין בעיקר משימה לשונית. הוכחת סיכונים דורשת מישורי בקרה, טיפול במצבים, ביצוע בהיקף מוגדר, אימות עצמאי, אובייקטי ראיות וממצאים הניתנים לשחזור. זו הבעיה ההנדסית שצוותי האבטחה צריכים לפתור כרגע.
Mythos, אם וכאשר יושק לציבור, לא יהיה הדגם היחיד שיש לו חשיבות. OpenAI כבר הודיעה כי היא נערכת לקראת דגמים פורצי דרך שעשויים להגיע ליכולות סייבר גבוהות. Anthropic כבר תיעדה מקרים של שימוש לרעה בסוכנים. AWS כבר הוכיחה שבינה מלאכותית יכולה להגביר פעולות הדורשות מיומנות נמוכה בקנה מידה נרחב. NIST כבר קוראת לארגונים לחשוב במונחים של אבטחת מערכות בינה מלאכותית, שימוש בבינה מלאכותית לצורכי הגנה, וסיכול משותף של מתקפות המונעות על ידי בינה מלאכותית. הצעד הנבון כעת הוא לא לחכות לעוד כותרת דרמטית על השקה. הצעד הנבון הוא לחזק את המקומות שבהם לתוקפים סוכניים יש את המנוף הגדול ביותר, ולבנות תהליך אימות חזק מספיק כדי לדעת מה אמיתי לפני שהאויב יודע זאת. (OpenAI)
קריאה נוספת ומקורות
- OpenAI, חיזוק החוסן הקיברנטי עם התקדמות יכולות הבינה המלאכותית. (OpenAI)
- אנתרופיק, סיכול קמפיין הריגול הסייבר הראשון שדווח עליו, אשר תוזמר על ידי בינה מלאכותית. (אנתרופי)
- בלוג האבטחה של AWS, גורם מאיים המשתמש בבינה מלאכותית מצליח לגשת למכשירי FortiGate בהיקף נרחב. (אמזון ווב סרוויסס בע"מ)
- NIST, הטיוטה להנחיות ה-NIST: חשיבה מחודשת על אבטחת סייבר בעידן הבינה המלאכותית. (NIST)
- מרכז המצוינות הלאומי של NIST, פרופיל בינה מלאכותית בסייבר. (nccoe.nist.gov)
- מרכז המחקר למדעי המחשב של ה-NIST, בדיקת חדירות ערך במילון. (csrc.nist.gov)
- NIST SP 800-115, מדריך טכני לבדיקת אבטחת מידע והערכתה. (csrc.nist.gov)
- OWASP, מדריך לבדיקות אבטחת אתרים. (קרן OWASP)
- OWASP, מבוא ללוגיקה עסקית. (קרן OWASP)
- צוות התגובה לאירועי אבטחה של Fortinet (PSIRT), FG-IR-24-535. (מעבדות FortiGuard)
- NVD, CVE-2024-55591 ו CVE-2025-24472. (NVD)
- Palo Alto Networks, CVE-2024-3400. (אבטחת Palo Alto Networks)
- CISA, Palo Alto Networks מפרסמת הנחיות בנוגע לפגיעות ב-PAN-OS (CVE-2024-3400). (cisa.gov)
- Bugcrowd, בתוך מוחו של האקר 2026 הודעה. (Bugcrowd)
- HackerOne, דוח אבטחה בהובלת האקרים 2025. (HackerOne)
- CNN שידרה כתבה על "מיטוס" באמצעות KTVZ. (KTVZ)
- הכתבה ב"פורצ'ן" על הדלפת המידע מ-Mythos ועל השגיאה במערכת ה-CMS של Anthropic. (מזל)
- פנליג'נט, קלוד מיטוס ואבטחת סייבר: מה באמת מגלה הדלפה זו למגינים. (Penligent)
- פנליג'נט, כלי בדיקת חדירות מבוסס בינה מלאכותית: איך תיראה תקיפה אוטומטית אמיתית בשנת 2026. (Penligent)
- פנליג'נט, ערכת הכלים "Claude Code" לבדיקות חדירה מבוססות בינה מלאכותית. (Penligent)
- פנליג'נט, עוזר צוות אדום בתחום הבינה המלאכותית: מה עומד במבחן במבצע אמיתי. (Penligent)
- דף הבית של Penligent. (Penligent)

