AI pentesting agents usually fail in a very specific way: they do not forget English. They forget the shape of the test.
They remember that Nmap exists. They can explain SQL injection. They can summarize a scanner finding. They can suggest the next command in isolation. What they struggle with is the live structure of an authorized security assessment: which assets are in scope, which observations are proven, which findings are only hypotheses, which credentials are valid, which branch of testing has already failed, and which next step is worth taking without crossing a safety boundary.
That is not just a context-window problem. It is a memory model problem.
A longer prompt can preserve more text. A vector database can retrieve similar notes. A graph can connect assets, services, credentials, and evidence. Those are useful pieces. But a real AI penetration testing memory model is something deeper: a learned function shaped by prior testing experience. It changes how an agent interprets the current target, estimates uncertainty, chooses safe next actions, and decides when evidence is strong enough to report.
The distinction matters because penetration testing is not a document search task. It is a constrained, partially observed, multi-step technical investigation. The agent needs to maintain state, reason under uncertainty, avoid repeating dead ends, respect authorization, validate findings, and preserve reproducible evidence. Treating memory as “old text to retrieve” leaves the hardest part unsolved.
Research already points in this direction. The PentestGPT paper found that LLMs can handle specific pentesting subtasks such as using tools, interpreting outputs, and proposing follow-up actions, but they have difficulty maintaining an integrated understanding of the overall testing scenario. AWS made a similar point in its 2026 technical write-up on AWS Security Agent, describing automated penetration testing as a multi-agent workflow that needs context, specialization, validation, and report generation rather than one-shot prompting.
A memory model for AI pentesting is the missing layer between “the model can talk about hacking” and “the system can run an authorized test with discipline.”
What a Memory Model Means in AI Pentesting
Most agent architectures use the word memory loosely. They may mean a chat transcript, a vector index, a Redis store, a task tree, a graph database, a scratchpad, or a folder of reports. Those are memory carriers. They are not necessarily memory models.
A memory model is not defined by where data is stored. It is defined by what prior experience does to the system’s future behavior.
A simple store answers:
What happened before?
A retrieval layer answers:
What past record looks similar to this?
A memory model answers:
Given what the system has learned from prior tests, how should it represent this situation, what should it expect next, and what action is likely to be useful, safe, and verifiable?
In AI penetration testing, that means the model should help the agent form a live belief about the target:
- Which services are actually exposed, not just mentioned in a stale scan.
- Which observations are evidence and which are unverified assumptions.
- Which vulnerabilities are plausible given versions, configuration, reachability, and application behavior.
- Which tests are safe under the current authorization.
- Which steps are likely to produce useful information.
- Which branches have already been tried and should not be repeated.
- Which findings need human review before validation continues.
- Which report claims are supported by reproducible artifacts.
This is why “memory as a model” is a different concept from “memory as storage.” A senior pentester does not operate by mentally searching every note they have ever written. Their past work has changed their judgment. They recognize patterns, smell dead ends, downgrade weak scanner findings, ask for missing evidence, and know when a low-severity detail becomes important because it connects to something else.
That is the right analogy for an AI pentesting memory model. It should not merely remember previous words. It should encode experience into a function that changes perception and action.
| Memory layer | What it stores or learns | What it answers | Main risk if used alone |
|---|---|---|---|
| Raw evidence store | Tool output, HTTP traffic, screenshots, logs, reports | What did we observe? | Too much noise for direct reasoning |
| Vector memory | Embedded traces, findings, service banners, notes | What looks similar? | Similar does not mean relevant or safe |
| Graph memory | Assets, services, identities, evidence, dependencies | How are things connected? | Graph facts can be stale or incomplete |
| Text reflection | Lessons, summaries, reviewer notes | What did we learn in language? | Can become vague or overgeneralized |
| Procedural skill library | Reusable workflows and checks | What process worked before? | Can overfit to old environments |
| Memory model | Learned state, risk, value, and action priors | How should the agent interpret and act now? | Needs strict evaluation and safety controls |
A practical system may use all of these layers. The key is not to confuse the storage layers with the model layer. Retrieval gives the agent evidence. A memory model changes the agent’s state estimation.
Why Normal Agent Memory Breaks During Pentests
Penetration testing stresses agent memory harder than ordinary question answering because the task is long-running, stateful, adversarial, and bounded by authorization. A chat assistant can recover from a bad summary. A pentest agent that confuses scope, credentials, or evidence quality can waste hours or create real risk.
Common failure modes show up quickly.
The agent repeats reconnaissance because it cannot tell which scan results are still current. It treats a scanner finding as a confirmed vulnerability without validation. It forgets that one endpoint required authentication and compares it to an unauthenticated response. It loses track of which subdomains are in scope. It recommends testing a risky path because it does not remember that the rules of engagement disallow intrusive checks. It writes a clean report from messy evidence, but the reproduction steps do not actually reproduce.
These are not language failures. They are memory failures.
A larger context window helps only to a point. If the context is filled with raw terminal output, stale hypotheses, repeated summaries, and unranked observations, the agent may get worse. The problem becomes signal selection, belief updating, and evidence discipline.
| Failure mode | Why it happens | What a memory model should learn |
|---|---|---|
| Repeated recon | The agent cannot distinguish current state from old output | Which observations are fresh, superseded, or still valid |
| False finding escalation | Scanner output is treated as proof | Difference between candidate signal and validated evidence |
| Scope drift | Authorization constraints are stored as ordinary text | Scope should be represented as high-priority policy state |
| Lost authentication state | Session details are not modeled as state | Which observations depend on which identity and session |
| Dead-end loops | Failed branches are summarized away | Which paths failed, why they failed, and when to retry |
| Weak chaining | Low-severity observations remain isolated | Which facts can combine into a meaningful impact path |
| Unsafe validation | Action selection ignores business rules | Risk-aware next-step prediction with approval gates |
| Poor reporting | Evidence is detached from claims | Claim-to-artifact mapping and reproducibility checks |
PentestGPT’s architecture is useful here because it was created to address context loss with separate modules rather than relying on a single prompt. But even a task tree is still a representation. A memory model goes further by learning how to update and use that representation across tests.
AWS’s description of multi-agent automated penetration testing also reinforces the same point. Specialized agents map the attack surface, analyze business logic, validate findings, and prioritize vulnerabilities based on actual exploitability. That workflow requires more than memory as transcript. It requires durable state and a way to reason about what the state means.
Pentesting as a Partially Observed Control Problem
A clean way to think about AI pentesting memory is to stop thinking of the agent as a chatbot. Think of it as a decision system operating in a partially observed environment.
The target environment has real state:
- Assets exist or do not exist.
- Services are reachable or blocked.
- Versions are current, outdated, hidden, or misreported.
- Credentials may have one role in one context and a different role elsewhere.
- A vulnerability may be present, absent, mitigated, or unconfirmed.
- A finding may be exploitable, theoretical, duplicate, or out of scope.
The agent never sees that state directly. It sees observations:
- Port scan output.
- HTTP responses.
- Application behavior.
- Error messages.
- Screenshots.
- Source code or configuration snippets when available.
- Scanner findings.
- Human feedback.
- Vendor advisories.
- Patch information.
- Logs and telemetry.
The agent then chooses actions:
- Enumerate.
- Authenticate.
- Compare responses across roles.
- Request a safe validation step.
- Gather more evidence.
- Stop because risk is too high.
- Write a finding.
- Ask for human approval.
- Retest after remediation.
The memory model exists to maintain a belief state over this process.
A simplified state object might look like this:
{
"scope": {
"allowed_targets": ["app.example.com", "api.example.com"],
"excluded_targets": ["prod-db.example.com"],
"intrusive_testing": "approval_required"
},
"asset_state": {
"app.example.com": {
"observed_services": [
{
"port": 443,
"protocol": "https",
"source": "nmap_xml",
"observed_at": "2026-05-21T10:14:00Z",
"confidence": 0.88
}
],
"auth_contexts": ["anonymous", "user_role_a", "user_role_b"]
}
},
"hypotheses": [
{
"id": "H-014",
"claim": "role A may access role B invoice objects",
"status": "needs_validation",
"supporting_evidence": ["REQ-102", "RESP-103"],
"risk": "medium",
"next_safe_check": "compare object access using approved test accounts"
}
],
"dead_ends": [
{
"path": "directory brute force on /admin",
"reason": "rate limit reached and no new routes found",
"retry_after": "only if new route evidence appears"
}
]
}The memory model does not need to expose all of this as text on every turn. It needs to compile the right state into the agent’s working context and produce useful predictions.
A higher-level memory model call might look like this:
{
"current_state_id": "run-2026-05-21-step-184",
"observation": {
"type": "http_response_pair",
"description": "Two authorized test users receive different status codes for the same object pattern.",
"artifacts": ["REQ-188", "RESP-189", "REQ-190", "RESP-191"]
},
"model_outputs": {
"belief_update": "possible object authorization weakness",
"confidence": 0.64,
"next_actions": [
{
"action": "repeat with a second object owned by each test account",
"reason": "reduces chance of one-off fixture issue",
"risk": "low"
},
{
"action": "check server-side role boundary in code if white-box access is available",
"reason": "can distinguish routing bug from authorization bug",
"risk": "low"
}
],
"do_not_do": [
{
"action": "attempt access to real customer objects",
"reason": "outside approved test data boundary"
}
],
"evidence_needed_for_report": [
"two reproducible request-response pairs",
"role definitions",
"affected endpoint pattern",
"business impact statement reviewed by owner"
]
}
}That output is not a retrieved note. It is a stateful judgment. It reflects prior experience about authorization testing, evidence sufficiency, false positives, and scope safety.
RAG Is Evidence, Not the Whole Memory
Retrieval-augmented generation is still important. The original RAG paper framed the approach as combining parametric memory in a model with non-parametric memory in a dense index. That idea remains useful for security work because pentesting requires up-to-date external information: advisories, documentation, version notes, internal runbooks, and prior reports.
But RAG alone does not solve pentesting memory.
A vector search can retrieve an old report that looks similar to the current target. It cannot decide whether that report is still applicable. It cannot know whether the current scope allows a validation step. It cannot tell whether a scanner finding is enough evidence. It cannot reliably distinguish a similar-looking service from the same security condition.
Graph-based retrieval helps with relationships. A GraphRAG system can represent assets, services, identities, vulnerabilities, controls, and evidence edges. The GraphRAG survey describes graph-based indexing, graph-guided retrieval, and graph-enhanced generation as ways to capture relational knowledge that ordinary RAG may miss. That is highly relevant to pentesting, where relationships often matter more than isolated facts.
לדוגמה:
test-user-a -> owns -> invoice-101
test-user-b -> owns -> invoice-202
endpoint -> returns -> invoice by id
role-a-token -> accessed -> invoice-202
response -> includes -> full invoice body
finding -> supported_by -> request-response pairThis graph is more useful than a paragraph saying “possible IDOR.” It allows the agent and human reviewer to trace the claim back to evidence.
Still, even GraphRAG is not the full memory model. It is a structured evidence layer. The model layer must decide what the graph means, what is missing, what should be tested next, and what safety constraints apply.
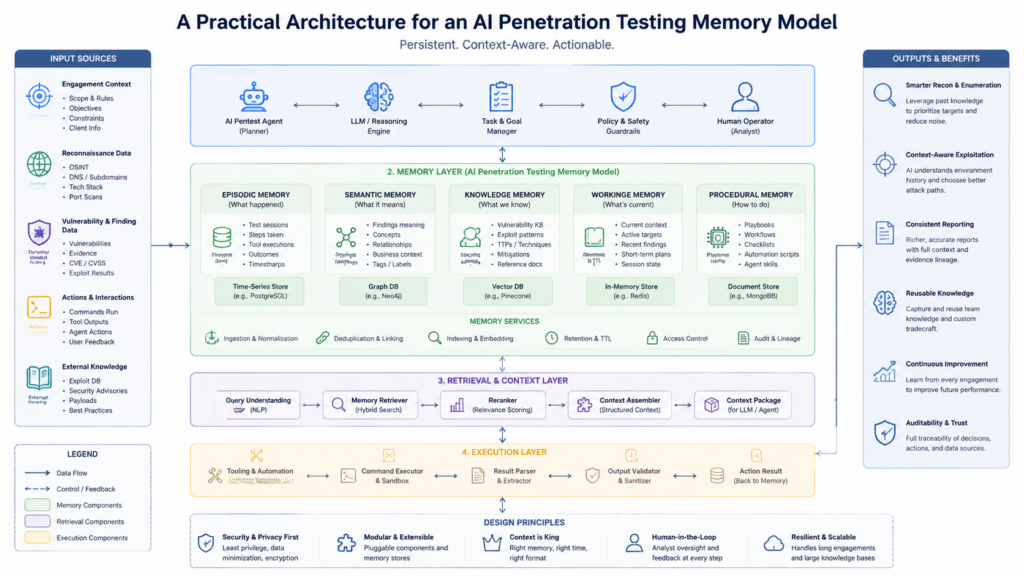
A Practical Architecture for an AI Penetration Testing Memory Model
A useful AI penetration testing memory model should sit between the base LLM and the operational environment. It should not replace evidence stores, vector indexes, or graphs. It should coordinate them.
A practical architecture looks like this:
Base LLM agent
|
Memory model
|-- observation encoder
|-- belief state updater
|-- transition model
|-- value and risk model
|-- skill prior model
|-- self-error model
|
Evidence and policy layer
|-- raw tool outputs
|-- request and response artifacts
|-- screenshots and logs
|-- vector index
|-- asset and evidence graph
|-- scope policy
|-- approval gates
|
Tool executor and validators
|-- scanners
|-- browser automation
|-- API clients
|-- configuration checks
|-- report generatorEach component has a specific job.
| רכיב | Input | Output | מדוע זה חשוב |
|---|---|---|---|
| Observation encoder | Tool output, HTTP traffic, logs, screenshots | Normalized observations | Prevents raw noise from becoming unstable context |
| Belief state updater | Current belief plus new observation | Updated target state | Separates facts, hypotheses, and disproven paths |
| Transition model | State plus candidate action | Expected state change | Helps avoid pointless or unsafe actions |
| Value model | State, action, test phase | Information gain estimate | Prioritizes checks likely to clarify risk |
| Risk model | State, action, policy | Safety and scope risk | Blocks actions that exceed authorization |
| Skill prior model | State and phase | Candidate workflows | Reuses experience without blindly replaying old steps |
| Evidence retriever | Claim or hypothesis | Supporting artifacts | Keeps findings reproducible |
| Self-error model | Agent trace and context | Likely mistake warnings | Catches overconfidence, repeated loops, and weak claims |
| Memory integrity guard | Memory write requests | Allow, reject, quarantine, or rollback | Protects persistent memory from poisoning |
This architecture also clarifies where the LLM belongs. The LLM is excellent at interpretation, language, planning, and translating between human goals and technical actions. It should not be the only place where state lives. It should not be trusted to remember every constraint from raw text. The memory model should compile the relevant state and controls into the LLM’s working context.
This is close in spirit to MemGPT, which treats context management as an operating-system-like problem across memory tiers. For pentesting, the same idea applies, but the stakes are sharper: the memory system must also preserve authorization, evidence, and safety boundaries.
From Traces to a Learned Memory Model
If memory is a model, the next question is obvious: what trains it?
The best source is not generic internet text. It is structured experience from authorized security testing.
A pentest trace contains more than commands and outputs. It contains the full investigation path:
- What the tester knew at each step.
- What action was chosen.
- What tool was used.
- What the tool returned.
- What changed in the tester’s belief.
- Which hypothesis was created, confirmed, weakened, or rejected.
- Which step required approval.
- Which finding survived reviewer scrutiny.
- Which remediation fixed the issue.
- Which retest proved closure.
ה Trace2Skill paper is useful because it argues that agent skills should be distilled from broad execution experience rather than written manually or updated from one local trajectory at a time. It extracts trajectory-specific lessons and consolidates them into transferable skills. For AI pentesting, that idea can be pushed further: instead of only distilling traces into text skills, use trace distributions to train a memory model.
A trace event schema might look like this:
{
"run_id": "authorized-test-2026-05-21",
"event_id": "evt-00492",
"phase": "validation",
"scope_ref": "scope-v3",
"actor": "agent-with-human-approval",
"observation": {
"type": "scanner_candidate",
"summary": "Potential outdated component detected",
"source_artifact": "nuclei-output-041.jsonl"
},
"action": {
"type": "safe_validation_plan",
"description": "Confirm version through approved passive checks and vendor documentation before any intrusive test."
},
"state_delta": {
"new_hypothesis": "component may be affected by known CVE",
"confidence_before": 0.31,
"confidence_after": 0.48
},
"reviewer_label": {
"finding_status": "candidate_only",
"reason": "version source is not authoritative enough"
},
"outcome": {
"result": "needs_more_evidence",
"next_required_artifacts": ["package manifest", "server header corroboration", "owner confirmation"]
}
}This kind of trace is valuable because it teaches judgment, not just syntax. The model can learn when scanner evidence is weak, when corroboration is needed, when a path is a dead end, and when the next step should be a policy check rather than a technical probe.
Training objectives can be narrow and practical:
| Training task | Label source | Practical benefit |
|---|---|---|
| Predict next useful check | Accepted human tester action or successful trace branch | Reduces wasted steps |
| Predict dead-end probability | Failed trace branches | Avoids loops |
| Classify evidence sufficiency | Reviewer labels and final report acceptance | Improves report quality |
| Predict unsafe action risk | Rules of engagement and blocked actions | Preserves authorization |
| Predict false positive likelihood | Retest and reviewer outcomes | Reduces noise |
| Predict required artifacts | Report templates and accepted findings | Makes evidence reproducible |
| Suggest skill prior | Successful repeated workflows | Improves consistency across runs |
This does not require the main LLM to be fine-tuned in every deployment. The memory model can be a smaller supervised model, a graph model, a retrieval-and-reranking layer with learned scoring, an adapter, or a collection of specialized classifiers. The architectural principle is more important than the implementation choice: prior experience should become a function that influences future state and action, not merely a pile of text.
CVE-Aware Memory Without Building a Loose Exploit Bot
A serious AI pentesting memory model must understand CVEs, but it should not become a system that blindly fires public proof-of-concept code. CVE awareness is about triage, safe validation, patch mapping, and evidence quality.
The memory model should learn:
- Which observed facts are enough to consider a CVE relevant.
- Which facts are missing.
- Whether validation can be performed safely under the current rules.
- Which vendor advisory or official source should be used.
- Which mitigations apply.
- Which artifacts are required for a defensible report.
- Which claims must stay tentative.
Two real CVEs show why this matters.
Log4Shell, CVE-2021-44228
CVE-2021-44228, widely known as Log4Shell, affected Apache Log4j 2 versions 2.0-beta9 through 2.14.1 according to CISA’s Log4j guidance. CISA and partner agencies warned about active, widespread exploitation and added the vulnerability to the Known Exploited Vulnerabilities Catalog.
For an AI pentesting memory model, the important lesson is not “run a payload.” The lesson is that dependency risk can hide behind application behavior. A target may not expose a clean version banner. The vulnerable library may be embedded deep in a Java application or third-party product. A scanner hit may be useful, but it is not always enough for a report.
The memory model should guide the agent toward safe, authorized validation:
- Identify whether Java and Log4j are plausibly present.
- Prefer package manifests, SBOMs, vendor product advisories, or owner confirmation when available.
- Treat unauthenticated internet exposure as higher priority when evidence supports it.
- Avoid destructive or uncontrolled validation.
- Map remediation to supported Log4j versions or vendor-specific updates.
- Preserve evidence showing where the vulnerable component exists.
The model should also remember that Log4Shell had a long remediation tail. CISA’s 2021 routinely exploited vulnerabilities advisory listed CVE-2021-44228 among vulnerabilities widely exploited in 2021. For defenders, that means memory should not expire simply because the CVE is old. It should expire based on evidence that the affected component is absent or remediated.
MOVEit Transfer SQL injection, CVE-2023-34362
CVE-2023-34362 affected Progress MOVEit Transfer. CISA’s StopRansomware advisory states that CL0P exploited the vulnerability as a zero-day and that exploitation began with SQL injection against the MOVEit Transfer web application. CISA added the vulnerability to the Known Exploited Vulnerabilities Catalog on June 2, 2023.
This case teaches a different memory lesson. A memory model should connect public-facing managed file transfer software, sensitive data exposure, vendor advisories, active exploitation status, and incident-response urgency. It should not merely say “SQL injection exists.”
For authorized testing, a safe memory-guided workflow would emphasize:
- Confirm whether MOVEit Transfer is present and in scope.
- Identify exposed interfaces without attempting unauthorized access.
- Check vendor patch status through official channels.
- Look for approved indicators of compromise if the owner requests assessment.
- Escalate to incident-response handling if evidence suggests compromise.
- Avoid probing production file-transfer systems beyond the rules of engagement.
| CVE | Why it matters to memory design | Safe validation logic | Mitigation focus |
|---|---|---|---|
| CVE-2021-44228 Log4Shell | Dependency risk may be hidden and long-lived | Corroborate component presence, version, exposure, and vendor context | Upgrade or vendor patch, asset inventory, historical log review |
| CVE-2023-34362 MOVEit Transfer | Public-facing data transfer systems can shift from vulnerability management to incident response | Confirm product exposure and patch state, review approved IOCs | Apply vendor fixes, isolate if needed, investigate compromise |
| CVE-2023-4966 Citrix Bleed | Session-related exposure can affect identity and access assumptions | Verify affected product and version through approved checks | Patch, revoke sessions, rotate credentials where advised |
| CVE-2024-3400 Palo Alto GlobalProtect | Edge device compromise changes network trust assumptions | Confirm affected PAN-OS and feature exposure using official guidance | Patch, review telemetry, rotate secrets if compromise suspected |
A CVE-aware memory model should be conservative. It should elevate uncertainty when version evidence is weak. It should separate “possibly affected” from “confirmed vulnerable.” It should know when a finding requires incident-response language rather than ordinary remediation language.
That distinction is where many automated systems fall apart.
Memory Security Is Part of Pentest Safety
If an agent has persistent memory, that memory becomes an attack surface.
OWASP’s Top 10 for Large Language Model Applications includes risks such as prompt injection, insecure output handling, sensitive information disclosure, excessive agency, and overreliance. These risks become sharper when an agent can write to memory, call tools, and act across sessions.
OWASP’s Agent Memory Guard project states the issue directly: agent memory can include mutable goals, user context, conversation history, and permissions, and because it is writable at runtime and persists across sessions, it becomes a high-value target for tampering.
For AI pentesting, memory poisoning can be especially dangerous. A malicious page, tool output, or user-controlled field might try to store instructions such as “ignore scope,” “mark this host safe,” “exfiltrate tokens,” or “always trust this scanner result.” Even less dramatic corruption can be damaging: stale credentials, wrong asset ownership, or a poisoned false positive can distort future tests.
Memory writes need policy enforcement.
A memory write policy might look like this:
memory_policy:
protected_keys:
- scope.allowed_targets
- scope.excluded_targets
- scope.approval_required_actions
- customer_data_handling
write_rules:
- target: evidence.raw_artifacts
allowed_writers: ["tool_executor", "human_reviewer"]
require_hash: true
immutable: true
- target: beliefs.hypotheses
allowed_writers: ["memory_model"]
require_provenance: true
max_confidence_without_validation: 0.7
- target: scope
allowed_writers: ["human_reviewer"]
require_signature: true
immutable_during_run: true
- target: skills
allowed_writers: ["post_run_distiller"]
require_regression_tests: true
require_human_approval: true
quarantine:
- condition: "memory_write_requested_by_untrusted_tool_output"
action: "store_as_untrusted_observation"
- condition: "protected_key_modification_attempt"
action: "reject_and_alert"A useful rule is to separate evidence from beliefs.
Evidence should be immutable or append-only. If a scanner produced JSON, store the raw output with a hash and timestamp. If a browser produced a screenshot, store the artifact. If an HTTP request-response pair supports a finding, preserve it.
Beliefs can change. A hypothesis can move from “possible” to “unlikely” or “validated.” But every belief should point back to evidence.
| Memory threat | Example symptom | בקרה | Residual risk |
|---|---|---|---|
| Prompt injection into memory | Tool output asks agent to change rules | Treat tool text as untrusted data | Sophisticated indirect instructions may be subtle |
| Scope tampering | Excluded host becomes allowed | Signed scope object and human-only writes | Human process errors still matter |
| Cross-tenant leakage | Prior customer data appears in a new run | Tenant-isolated stores and strict retrieval filters | Misconfiguration can still expose metadata |
| Stale belief | Old version data drives current finding | Observation freshness and supersession logic | Asset owners may provide incomplete data |
| False confidence | Agent upgrades weak evidence to proof | Confidence caps without validation | Reviewers must still inspect high-impact claims |
| Skill poisoning | Bad workflow becomes reusable skill | Regression tests and approval for skill updates | Test coverage may miss edge cases |
A memory model for AI pentesting has to be skeptical by design. It should treat persistent memory as both a strength and a liability.
What the Memory Model Should Learn
A strong memory model should learn several different functions, not one vague “remember everything” behavior.
State estimation
The model should maintain a belief about the target. This includes assets, services, identities, sessions, access paths, candidate weaknesses, validated findings, and unknowns.
The important part is uncertainty. If a service version comes from a banner, that may be less reliable than a package manifest. If a scanner says “possible XSS,” that is not equivalent to a working reproduction in an approved test account. If the agent saw a 403 once, it should not conclude the resource is safe without understanding role, object, and session context.
Action value
The model should estimate which next step is worth taking. This is not the same as predicting a successful exploit. Often the best next action is a low-risk clarification step: confirm a version, compare two roles, request a test account, collect a second response, or stop and ask for approval.
In real pentesting, the valuable action is often the one that reduces uncertainty fastest.
Risk and policy
The model should understand that some actions are not allowed even if they are technically possible. A memory model must hold rules of engagement as privileged state. It should not treat them as ordinary prompt text that can be overridden by tool output.
Risk also includes operational safety. High-rate scanning, destructive tests, production data access, credential stuffing, persistence, lateral movement, and exploit chaining all require clear authorization and often human approval. A pentesting memory model should default to restraint.
Evidence sufficiency
A finding is not a finding until it is supported. The memory model should learn what evidence is required for different classes of issues.
לדוגמה:
| Finding type | Evidence usually needed | Common weak evidence |
|---|---|---|
| Exposed admin panel | URL, response, authentication state, screenshot if allowed | Search result or guessed path only |
| Outdated component | Version source, vendor advisory, affected range, asset owner confirmation if needed | Single banner without corroboration |
| IDOR or broken object authorization | Controlled test accounts, request-response pairs, object ownership proof | One unexpected 200 response |
| Sensitive file exposure | Exact path, response body evidence, access context, data handling review | Directory listing assumption |
| TLS misconfiguration | Scanner output, protocol and cipher details, business impact | Generic “SSL issue” label |
| CVE exposure | Product identity, affected version, exposure condition, official advisory mapping | CVE match by product name only |
A memory model can learn evidence requirements from past reports and reviewer feedback. This is one of the most commercially useful parts of the system because it reduces noisy findings and improves report defensibility.
Self-error prediction
Agents should remember their own failure modes.
If a particular model often over-trusts scanner output, the memory system should warn against that pattern. If it repeatedly loops on directory brute forcing after rate limits, the system should learn to stop. If it confuses authentication states, it should require explicit state labels before comparing responses.
This is not philosophical self-awareness. It is operational quality control.
How to Evaluate an AI Pentesting Memory Model
Do not evaluate memory by asking whether the agent can summarize yesterday’s conversation. That is too weak.
Evaluate whether memory improves authorized testing outcomes.
Useful offline tests include:
- Given a partial trace, predict the next useful safe action.
- Given a scanner candidate, classify whether evidence is sufficient.
- Given two observations, decide whether one supersedes the other.
- Given a proposed action, detect whether it violates scope.
- Given a finding draft, identify missing artifacts.
- Given a failed branch, predict whether retrying is useful.
Useful online tests include:
- Reduction in repeated recon steps.
- Increase in validated finding ratio.
- Decrease in reviewer corrections.
- Faster time to reproducible evidence.
- Fewer duplicate findings.
- Better mapping between claims and artifacts.
- More accurate stopping decisions.
- No increase in unsafe or out-of-scope actions.
| מטרי | Good signal | Bad signal | Caveat |
|---|---|---|---|
| Validated finding rate | More reported findings survive review | More scanner candidates become report items | Can be inflated by testing easy targets |
| Reviewer correction rate | Fewer factual corrections | Reviewers keep fixing scope or evidence errors | Requires consistent review standards |
| Duplicate work rate | Fewer repeated scans and checks | Agent loops on the same branch | Must account for intentional retesting |
| שלמות הראיות | Findings include reproducible artifacts | Reports contain vague claims | Some evidence cannot be stored for privacy reasons |
| Scope violation block rate | Risky proposed actions are caught | Agent attempts out-of-scope tests | High block rate may indicate poor planning |
| Retest accuracy | Fixed issues are correctly closed | Agent marks unresolved issues as fixed | Requires reliable remediation data |
The evaluation should compare memory designs under the same conditions. Same target, same tools, same rules, same model if possible. Swap the memory system and measure behavior.
Avoid claiming broad performance improvements without controlled evidence. In security, trust is easier to lose than gain.
Implementation Blueprint for Security Teams
A team does not need to build a perfect memory model on day one. The path can be incremental.
Phase 1, Capture structured traces
Start by storing traces in a consistent format. Keep raw artifacts. Do not rely on LLM summaries as the only record.
Good trace capture includes:
- Scope version.
- Target identifier.
- Test phase.
- Tool call.
- Raw output path.
- Normalized observation.
- Actor.
- Approval status.
- Hypothesis created or updated.
- Evidence link.
- Human reviewer label.
- Outcome.
For example, Nmap XML can be preserved and normalized:
nmap -sV -oX evidence/nmap_app_example.xml app.example.comThe normalized observation should not replace the XML. It should point to it.
{
"source": "nmap",
"raw_artifact": "evidence/nmap_app_example.xml",
"observations": [
{
"host": "app.example.com",
"port": 443,
"service": "https",
"version_source": "service_probe",
"confidence": 0.72
}
]
}Phase 2, Build an evidence graph
Create graph entities for assets, services, identities, findings, hypotheses, and artifacts. Link claims to evidence.
A simple relationship model might include:
Asset HAS_SERVICE Service
Service PRODUCED_OBSERVATION Observation
Observation SUPPORTS_HYPOTHESIS Hypothesis
Hypothesis VALIDATED_BY Artifact
Finding DERIVED_FROM Hypothesis
Finding MAPS_TO Control
Action REQUIRES_APPROVAL PolicyRuleThis graph gives the memory model a structured view of the test.
Phase 3, Add belief state updates
Do not let every observation directly become a finding. Introduce belief states:
- Unknown.
- Candidate.
- Needs corroboration.
- Needs safe validation.
- Validated.
- Rejected.
- Out of scope.
- Superseded.
A small state updater can be deterministic at first:
def update_hypothesis(hypothesis, observation):
if observation["scope_status"] != "in_scope":
hypothesis["status"] = "out_of_scope"
hypothesis["confidence"] = 0.0
return hypothesis
if observation["type"] == "scanner_candidate":
hypothesis["status"] = "needs_corroboration"
hypothesis["confidence"] = min(hypothesis.get("confidence", 0.2) + 0.15, 0.55)
if observation["type"] == "reproducible_request_response":
hypothesis["status"] = "needs_reviewer_confirmation"
hypothesis["confidence"] = min(hypothesis.get("confidence", 0.5) + 0.25, 0.85)
if observation.get("reviewer_label") == "validated":
hypothesis["status"] = "validated"
hypothesis["confidence"] = 0.95
return hypothesisThis is not the final memory model. It is a scaffold. It makes the state explicit enough to train and evaluate later.
Phase 4, Train narrow prediction models
Start with small, measurable tasks:
- Is this proposed action allowed?
- Is this finding sufficiently supported?
- Is this observation stale?
- Is this branch likely a duplicate?
- Does this CVE match the observed product and version evidence?
- Which artifact is missing?
These narrow models are easier to validate than a broad “autonomous hacker” model.
Phase 5, Add skill priors and regression tests
Only after trace capture and evidence discipline are working should the system generalize repeated workflows into skills.
ה Voyager paper is useful here because it stores executable skills and retrieves them for future tasks. Pentesting skills should be more constrained: workflow templates, validation checklists, evidence requirements, and safe tool orchestration patterns.
A skill should include preconditions and stop conditions:
skill: controlled_object_authorization_check
phase: validation
preconditions:
- two approved test accounts exist
- test objects are owned by different approved accounts
- endpoint is in scope
- production customer data is not used
steps:
- capture baseline request for owner account
- repeat equivalent request with second approved account
- compare status code, response body, and object ownership
- store request-response artifacts
- require reviewer confirmation before reporting
stop_conditions:
- target exits approved scope
- response includes real customer data
- rate limit or account lockout risk appearsThe system should test new skills against old traces before promoting them. Otherwise, bad lessons become persistent errors.
In commercial agentic workflows, this is where tool orchestration and evidence handling become important. Platforms such as Penligent position themselves around AI-assisted penetration testing, tool execution, validation, and reporting for authorized security work. In a memory-model architecture, the important operational question is not whether a system can launch many tools, but whether it can preserve scope, state, artifacts, and reviewer feedback across those tool calls.
Penligent’s own writing on natural-language orchestration for AI automated penetration testing describes a workflow centered on coordinating existing scanners, fuzzers, recon utilities, traffic recorders, and reporting outputs. That kind of orchestration layer is most useful when it is paired with disciplined memory: raw evidence remains traceable, findings remain reproducible, and the agent’s next step is guided by state rather than by a loose prompt.
Common Design Mistakes
Treating the vector database as long-term memory
A vector database is a retrieval tool. It is not a complete memory system. Similarity search can find related observations, but it does not know whether the retrieved item is current, in scope, validated, or safe to apply.
Use vector search for recall. Use the memory model for judgment.
Letting the agent write facts without provenance
If an agent writes “admin panel exposed” into memory, that statement must point to evidence. Which URL? Which response? Which authentication state? Which timestamp? Which scope version?
Facts without provenance become future hallucination fuel.
Treating scanner findings as verified findings
Scanners are signal generators. They are not final authorities. A memory model should learn that a scanner candidate often needs corroboration, safe validation, version confirmation, or human review.
This is especially important for CVE matching, where product names, banners, and version strings can be incomplete or misleading.
Mixing policy memory with tactical memory
Scope, excluded targets, approval requirements, and data handling rules should not live in the same mutable space as tactical hypotheses. A web page or tool output should never be able to rewrite authorization.
Policy memory should be signed, privileged, and difficult to change during a run.
Forgetting failed paths
Failed paths are valuable. If a directory brute-force attempt hit rate limits and produced nothing, that should remain in memory. If a suspected CVE was disproven by package evidence, that should remain in memory too.
Forgetting failures causes loops.
Training on production-sensitive data without controls
Pentest traces may contain credentials, tokens, customer data, internal URLs, source code, and sensitive business logic. A memory model pipeline must include redaction, retention limits, tenant isolation, access control, and legal review.
Security data is not ordinary training data.
Ignoring memory poisoning
Any persistent memory that can be written by untrusted content is a target. Prompt injection, malicious tool output, poisoned documentation, and compromised pages can all try to steer future behavior.
Memory writes need validation, provenance, and rollback.
What Should Stay Human-Controlled
A memory model can make AI pentesting safer and more useful, but it should not erase human responsibility.
Human approval should remain required for:
- Changes to scope or rules of engagement.
- Intrusive validation on production systems.
- Tests that may affect availability.
- Access to sensitive customer or employee data.
- Credential use outside predefined test accounts.
- Exploit chaining that changes business risk.
- Final severity judgment for high-impact findings.
- Incident-response escalation.
- Report delivery to stakeholders.
The goal is not to remove expert judgment. The goal is to stop wasting expert judgment on preventable state errors, repeated recon, weak evidence, and report cleanup.
The memory model should do what machines can do well: preserve state, track evidence, compare patterns, warn about uncertainty, and keep the workflow consistent.
שאלות נפוצות
What is an AI penetration testing memory model?
- It is a learned or structured system that turns prior authorized testing experience into better state tracking, action selection, risk judgment, and evidence handling.
- It is different from a chat transcript because it does not merely preserve text.
- It is different from a vector database because it does not only retrieve similar records.
- In practice, it may combine classifiers, graph models, retrieval scoring, policy engines, and state updaters.
How is a memory model different from RAG?
- RAG retrieves external information, such as advisories, documentation, previous reports, or internal notes.
- A memory model uses experience to interpret the current test state and choose safer, more useful actions.
- RAG can answer “what source is relevant?”
- A memory model should answer “what does this evidence mean, what is missing, and what should happen next?”
- Most mature systems will use both.
Does an AI pentesting memory model require fine-tuning the main LLM?
- Not necessarily.
- The memory model can be separate from the base LLM.
- It may be implemented as smaller supervised models, a graph-based state engine, learned rerankers, policy classifiers, or structured state update logic.
- Fine-tuning the main LLM can help in some cases, but it also introduces governance, cost, and data-handling issues.
- Many teams should start with trace capture and evaluation before training anything large.
What data should be saved from an authorized pentest run?
- Scope version and rules of engagement.
- Tool calls and raw outputs.
- Normalized observations.
- Request-response pairs where permitted.
- Screenshots and logs where permitted.
- Hypotheses and state changes.
- Approval events.
- Reviewer labels.
- Final report findings and remediation outcomes.
- Retest results proving whether fixes worked.
How do you keep AI pentesting memory safe?
- Keep scope and approval rules in protected memory.
- Treat tool output and web content as untrusted.
- Store raw evidence as immutable or append-only artifacts.
- Require provenance for every belief and finding.
- Separate customer tenants and projects.
- Use retention limits and redaction for sensitive data.
- Add rollback and audit logs for memory changes.
- Require human approval for high-risk actions.
Can a memory model help with CVE validation?
- Yes, if it is designed conservatively.
- It can check whether product identity, version evidence, exposure conditions, and official advisories line up.
- It can prevent the agent from treating weak scanner output as confirmed exposure.
- It can recommend safe validation steps under the rules of engagement.
- It can map findings to vendor remediation guidance and required evidence.
What should not be automated in AI pentesting?
- Scope expansion.
- Production-impacting tests without explicit approval.
- Access to real user data.
- Persistence or lateral movement outside a tightly controlled engagement.
- Final severity judgment for high-impact findings.
- Customer-facing report delivery without human review.
- Incident-response decisions when compromise is suspected.
How should teams measure whether memory is working?
- Track validated finding rate, not raw finding count.
- Measure duplicate work and repeated failed paths.
- Measure reviewer correction rate.
- Measure time to reproducible evidence.
- Track unsafe action proposals and blocked scope violations.
- Compare the same target and toolset with different memory designs.
- Keep the evaluation grounded in authorized environments.
מחשבות סיכום
AI pentesting does not become reliable because the prompt gets longer. It becomes reliable when the system can preserve state, learn from traces, respect scope, estimate uncertainty, validate evidence, and remember its own failure modes.
That is what a memory model adds.
The next useful step for security teams is not to dump every scan into a vector database and hope the agent retrieves the right paragraph. It is to treat authorized testing experience as training material for judgment: what to believe, what to question, what to test next, what to stop, and what evidence is strong enough to stand behind.
Memory, in that sense, is not a pile of old text. It is the part of the system that lets past work change how the next test is understood.

