ההכרזה של Anthropic על Mythos הובילה אנשים רבים לשאול את השאלה הלא נכונה. השאלה הבולטת הייתה: "איזה מודל הוא כעת ההאקר הטוב ביותר?" השאלה המועילה יותר היא מורכבת יותר ובעלת אופי תפעולי: כמה מהמודל דרוש בכל שלב של בדיקת חדירה, אילו תשתית תומכת חייבת להתקיים סביבו, כיצד מאמתים את דבריו, ומה בעצם מקבלים תמורת כל דולר כאשר עוברים מסימן מועמד לממצא שניתן להגן עליו? החומרים הציבוריים של Anthropic עצמה מתארים מערכת, לא פקודה קסומה. פרויקט Glasswing אומר ש-Mythos Preview מצא אלפי פגיעויות יום-אפס בכל מערכות ההפעלה והדפדפנים העיקריים, והדו"ח של צוות האדום של Anthropic מתאר תשתית פשוטה אך אמיתית: להפעיל קונטיינר מבודד, לתת למודל לבדוק את הקוד ולהריץ את היעד, לחזור על התהליך עם ניפוי באגים, ולהפיק דוח באגים עם שלבי הוכחת היתכנות. תשובתה של AISLE לא הכחישה את היכולת הזו. היא טענה כי הרבה ממה שחשוב בתהליך הזה כבר זמין למודלים קטנים יותר, זולים יותר, ובמקרים מסוימים גם מודלים פתוחים, ברגע שתהליך העבודה מובנה נכון. (anthropic.com)
ההבחנה הזו חשובה משום ש"בדיקות חדירה מבוססות בינה מלאכותית" מתחילות לשמש כמעט לכל דבר שכולל מודל שפה גדול (LLM) המחובר לסורק. תקן NIST SP 800-115 עדיין מגדיר בדיקות אבטחה טכניות סביב תכנון, ביצוע, ניתוח ממצאים ואסטרטגיית הפחתה. מדריך בדיקות האבטחה ברשת של OWASP עדיין מתייחס לבדיקות אבטחה כאל מסגרת מובנית להערכת יישומים ושירותי אינטרנט, ולא כאל שטף של הערות שנוצרו על ידי מודל. רשימת 10 המובילים של OWASP לאבטחת API עדיין מציבה את "אישור ברמת אובייקט שבור" בראש הרשימה, מכיוון שהכשלים הקשים במערכות אמיתיות מתרחשים בדרך כלל ביחסי אובייקטים, גבולות תפקידים, מעברי מצב והיגיון עסקי, ולא רק במחרוזות תואמות תבנית. ברגע שנקודת הייחוס הזו משוחזרת, הרבה יותר קל להתייחס לדיון בנושא Mythos. בדיקת חדירה אינה תשובה מודלית. זוהי תהליך מוגדר, המבוסס על ראיות, שהופך אי-ודאות להוכחה. (csrc.nist.gov)
התרומה הטובה ביותר של AISLE לדיון אינה בכך שהיא "הפריכה" את Mythos, אלא בכך שהיא פירקה את התהליך למרכיביו. הסיפור הציבורי של Anthropic דוחס באופן טבעי את הסריקה, זיהוי הפגיעות, המיון, הערכת הניצול, בניית הניצול והתיקון ליכולת רציפה אחת. AISLE טוענת כי דחיסה זו נוחה מבחינה רטורית אך מטעה מבחינה תפעולית. במסגרת זו, אבטחת סייבר מבוססת AI היא מערך של משימות שונות עם מאפייני קנה מידה שונים: סריקה רחבת טווח, זיהוי פגיעות, מיון והבחנה בין תוצאות חיוביות כוזבות, יצירת תיקונים ולעיתים בניית ניצול. הנקודה הנוספת שלה היא זו שצוותי אבטחה צריכים להפנים: פונקציית הייצור של אבטחת AI אינה רק מודיעין לכל אסימון. היא כוללת גם אסימונים לכל דולר, אסימונים לשנייה, ומומחיות האבטחה המוטמעת במבנה התומך שמנתב, מאמת ומגביל את המודל. זו אינה תיקון קטן. זהו ההבדל בין רכישת הדגמה לבין בניית פרקטיקה. (מעבר)
בדיקות חדירה מבוססות בינה מלאכותית הן עדיין תהליך עבודה, ולא מודל ענק
הדרך הטובה ביותר להבין את בדיקות החדירה של בינה מלאכותית בשנת 2026 היא להפסיק להתייחס אליהן כאל תחרות חשיבה מופשטת ולהתחיל להתייחס אליהן כאל בעיה של תכנון זרימת עבודה. זרימת עבודה אבטחתית אמיתית צריכה לבצע מספר משימות בו-זמנית. עליה לצמצם את היקף הבדיקה מבלי לאבד הקשר חשוב. עליה לשמור על מצב בין בקשות, תפקידים או הפעלות. עליה להבחין בין בעיה סבירה לבעיה שניתן לשחזר. עליה לשמור ראיות מספיקות כדי שמהנדס אחר יוכל לשחזר את מה שקרה. עליו להימנע מהגזמת ההשפעה כאשר תנאי מסוים אינו בר-השגה בפועל. ואם המערכת מבצעת ניצול או אימות פעיל, עליה לעשות את כל זאת מבלי להפר את משמעת ההיקף או לייצר ראיות שלא יעמדו בבדיקה. אלה הן דרישות הנדסיות לפני שהן דרישות מודל. (csrc.nist.gov)
זו הסיבה שהשיח העכשווי בנושא מבחני ביצועים מתרחק בשקט מ"שאלות טריוויה" סטטיות בתחום האבטחה, ומתמקד במשימות מקצה לקצה. מבחן הביצועים CTI-REALM של מיקרוסופט מתמקד במפורש בהנדסת זיהוי בעולם האמיתי, ולא בשאלות ותשובות מבודדות. הוא בוחן קריאת מודיעין איומים, ניתוח נתוני טלמטריה, יישום חוזר של KQL ולוגיקת Sigma, ואימות תוצאות מול המציאות בשטח. התחום המדויק הוא הנדסת זיהוי ולא בדיקות חדירה, אך הלקח המבני זהה: מדד אבטחה הופך לשימושי יותר ככל שהוא מתקרב לתהליך העבודה שבני אדם נדרשים לבצע בפועל. עתיד ההערכה ההתקפית צפוי לנוע באותו הכיוון. ההערכה הטובה ביותר לא תסתפק בשאלה האם מודל יכול לתאר באג. היא תשאל האם מערכת מוגבלת יכולה למצוא את המקום הנכון לחפש בו, להפריד בין רעש לאות, להוכיח את התנאי, לשמר את עקבות הארטפקט, ולתקשר את התוצאה באופן שמהנדס אחר יבטח בו. (מיקרוסופט)
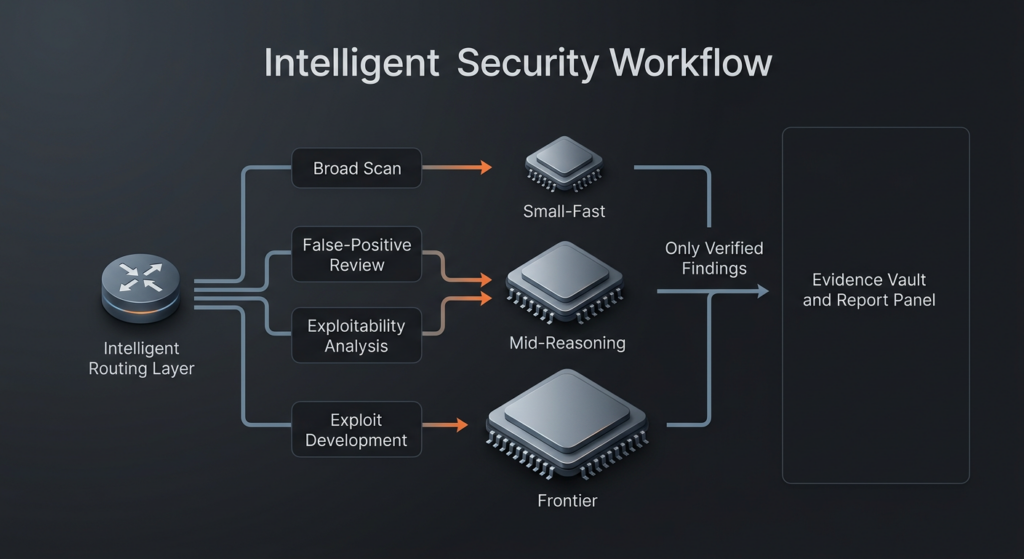
לפיכך, ארכיטקטורת בדיקות חדירה מבוססת בינה מלאכותית יעילה דומה פחות למבנה מונוליטי ויותר לצוות שליחים. מודל מהיר וזול יכול לרוב לבצע את העבודה הראשונית של רישום נקודות קצה, קיבוץ נתיבים, זיהוי תבניות מסגרות או איתור אזורי קוד שראוי להעמיק בהם. מודל הסקה חזק מעט יותר יכול לבצע סינון תוצאות חיוביות כוזבות, דירוג פגיעות וניקוי השערות. המודל היקר ביותר לא צריך להיות ברירת המחדל שלכם לכל דבר. הוא צריך להיות דרגת ההסלמה שלכם למקומות שבהם מרחב החיפוש צר מספיק והערך הצפוי גבוה מספיק, כך שכדאי לשלם עבור חשיבה ברמה מתקדמת. זו הגרסה המעשית של הנקודה המרכזית שלכם: המטרה היא לא לשכור את המודל החכם ביותר בעולם בכל שלב. המטרה היא להפעיל את הכמות הנכונה של בינה מלאכותית בשלב הנכון, במסגרת זרימת עבודה שאינה מבזבזת כיסוי, כסף או תשומת לב של בודקים. (מעבר)
הטבלה שלהלן מסכמת את תפיסת הצינור הזו באמצעות הפירוק של AISLE, המבנה שפרסמה Anthropic, ומסגרת בדיקות החדירה הקלאסית של NIST ו-OWASP. (אדום אנתרופי)
| שלב הצינור | מה המערכת באמת עושה | צוואר בקבוק דומיננטי | דגמים קטנים או בינוניים מספיקים לרוב | כאשר מודל פורץ דרך מצדיק את הוצאותיו | מעקה בטיחות הנדסי שאינו נתון למשא ומתן |
|---|---|---|---|---|---|
| צמצום נכסים והקשר | מיפוי היעד וצמצום מרחב החיפוש | כיסוי ומהירות | כן | לעיתים רחוקות | גבולות קשיחים של תחום ומניפסטים של יעדים |
| איתור מועמדים | איתור נתיבי קוד, מסלולים או התנהגויות חשודים | תמורה לדולר | כן | מדי פעם | יומנים הניתנים לצפייה חוזרת של מה שנבדק |
| מיון ובקרת תוצאות חיוביות כוזבות | הבחנה בין בעיות שנראות סבירות לבעיות אמיתיות | דיוק והקשר | לעתים קרובות | לפעמים | בדיקת רקע לפני קידום |
| הערכת פגיעות | הערכת השאלה האם ההשפעה היא אמיתית בסביבה זו | הסקת מסקנות מתוך התחשבות בסביבה | לפעמים | לעתים קרובות | הנחות סביבתיות ברורות |
| בניית פרצות | הפיכת מצב להשפעה מעשית | חיפוש מוגבל לטווח ארוך | לעיתים רחוקות יותר | לעתים קרובות | בקרות ביצוע ואישור מבודדות |
| דיווח ובדיקה חוזרת | תרגום הממצאים למשהו שמהנדס אחר יכול לסמוך עליו | איכות הממצאים ויכולת השחזור שלהם | כן | לעיתים רחוקות | שלבי השחזור, השינויים וההוכחה לבדיקה חוזרת |
הדגמים הקטנים כבר משפיעים יותר מכפי שרבים מוכנים להודות
הניסויים של AISLE הם בעלי ערך רב משום שהם מתמודדים עם הבעיה בדיוק ברמה הנכונה. החברה לא טענה שמודלים קטנים יכולים לשחזר באופן אוטונומי את כל צינור העבודה של Anthropic מקצה לקצה על מאגרי קוד גדולים. היא העלתה שאלה מצומצמת יותר: ברגע שמבודדים את הקוד הרלוונטי, איזה חלק מההיסק המוצג בפומבי ב-Mythos יכולים מודלים זולים או פתוחים לשחזר? זה קרוב הרבה יותר לאופן שבו מערכת גילוי בנויה היטב פועלת בפועל. שלד טוב מקדיש זמן לצמצום קבוצת המועמדים. בשלב שבו אתם מבקשים מהמודל להסיק מסקנות ברצינות, לא צריך להמשיך לזרוק עליו בסיס קוד שלם בתקווה לקבל השראה. (מעבר)
בבדיקת השכפול NFS של FreeBSD שביצעה AISLE, כל הדגמים שנבדקו זיהו את העומס היתר. בין אלה נכלל גם GPT-OSS-20b, המתואר כמודל MoE בנפח 20B עם 3.6B פרמטרים פעילים, שלדברי AISLE עלותו כ-$0.11 למיליון טוקנים, ועדיין הצליח להסיק נכונה כי קיימת סכנה לביצוע קוד מרחוק בפונקציה המבודדת. במקרה של OpenBSD SACK, התוצאות היו שונות מאוד. המודל הקטן יותר לא הצליח לשחזר את השרשרת המלאה, אך מודל פתוח עם 5.1 מיליארד פרמטרים פעילים הצליח בכך. המסקנה הרחבה יותר של החברה הייתה שהדירוגים השתנו באופן דרמטי בין המשימות, כולל תרגיל הבחנה בין תוצאות חיוביות כוזבות של OWASP, שבו מודלים פתוחים קטנים יותר השיגו ביצועים טובים יותר מכמה מודלים מתקדמים. בין אם מסכימים עם כל פרט במתיודולוגיה של AISLE ובין אם לא, קשה להתעלם מהמסר הכללי: אין מודל יחיד ויציב שהוא הטוב ביותר בכל משימות האבטחה, והשיפוע של היכולות אינו חלק. (מעבר)
תוצאה זו לא אמורה להפתיע בודקי חדירות מנוסים. עבודת אבטחה מלאה ברמות קושי לא אחידות. פגם בבקרת גישה המסתתר בתהליך עבודה בעל שלושה תפקידים ומודע למצב (stateful) עשוי להיות קשה יותר לאימות מאשר בעיה של פגיעה בזיכרון, שה"אורקל" של הקריסה שלה ברור. מקרה משעמם של הזרקת SQL מדומה עשוי להיות קשה יותר לאבחון נכון מאשר הצפת ערימה רועשת אך אמיתית, אם לאחרון יש סימנים ברורים לפגיעה בזיכרון והראשון דורש חשיבה מעמיקה על אופן הזרימה בפועל של הנתונים. המשימות שונות זו מזו במידה רבה כל כך, עד שלעתים קרובות תווית של "המודל הטוב ביותר" מספקת פחות מידע מאשר מדיניות ניתוב. השאלה המועילה אינה איזה מודל מנצח בקטגוריה. השאלה היא איזה מודל מנצח בשלב זה, במסגרת תקציב זה, עם בודק זה, במחיר זה, תחת דרישת זמן ההשהיה הזו. (מעבר)
יש כאן גם נקודה בסיסית בתחום כלכלת החיפוש. אם איתור המועמדים ובדיקת הסינון הראשונית ניתנים לביצוע בעלות נמוכה מאוד, הגורם המגן יכול להרשות לעצמו כיסוי רחב בהרבה. AISLE מציג טיעון זה באופן ישיר: אלפי "בלשים" סבירים המבצעים חיפוש נרחב עשויים להשיג תוצאות טובות יותר מבלש מבריק אחד שנאלץ לנחש היכן לחפש. בפועל, משמעות הדבר היא שצוות אבטחה עשוי לקבל אותות שימושיים יותר על ידי הצפת הצינור המוקדם במודלים זולים ושמירת ההיגיון היקר לממצאים שעברו את מסנני הראיות. הרעיון מרגיש אנטי-קלימטי מכיוון שהוא ניהולי ולא מיתי. זו גם הדרך שבה תוכניות אבטחה בוגרות מנצחות בדרך כלל. הן אינן ממקסמות את הגאונות בכל שלב. הן ממקסמות את התפוקה מבלי לאבד את האמון. (מעבר)
המיתוס עדיין חשוב דווקא כשהעבודה נעשית קשה
אף אחד מהדברים הללו אינו מעיד על כך שמודלים מסוג "פרונטיר" איבדו מהרלוונטיות שלהם. הראיות של Anthropic עצמה מצביעות על כך שהפער עדיין משמעותי בחלק הקשה ביותר של המערכת. בדו"ח צוות ה-Red Team שלה, Anthropic מציינת כי Mythos Preview נמצאת בליגה אחרת לגמרי מ-Opus 4.6 בכל הנוגע לפיתוח ניצולים אוטונומיים. בבדיקת ביצועים שנבעה מפגיעויות במנוע ה-JavaScript של Firefox שהתגלו בעבר, Anthropic טוענת ש-Opus 4.6 יצר ניצולים פעילים רק פעמיים מתוך מאות ניסיונות, בעוד ש-Mythos Preview יצר 181 ניצולים פעילים והגיע לשליטה ברשומות 29 פעמים נוספות. החברה מציינת גם כי Mythos Preview זיהתה וניצלה באופן אוטונומי פגיעות בת 17 שנים ב-FreeBSD, CVE-2026-4747, לאחר שסרקה מאות קבצים בקרנל. אלה אינם הישגים זניחים בקצה ההפצה. מדובר בהבדלים גדולים בדיוק באזור שבו הניצול עובר מ"כנראה שיש כאן משהו לא בסדר" ל"אני יכול לבצע את המהלך הזה". (אדום אנתרופי)
לכך יש חשיבות מכיוון שבניית ניצול היא מיומנות שונה מזיהוי פגיעות. לעתים קרובות היא דורשת תכנון לטווח ארוך יותר, התאמה למגבלות, שימוש יצירתי חוזר באבני בניין, והתמדה מספקת כדי לחזור על אסטרטגיות שכשלו. תהליכי עבודה רבים בתחום האבטחה אינם זקוקים כלל לרמת אוטונומיה כזו. מקרים רבים של שימוש הגנתי או כבד באימות מסתיימים הרבה לפני ניצול מלא של הפגיעות. אך אם תהליך העבודה שלכם אכן דורש יצירת ניצול מעמיקה תחת אילוצים, אז יכולת מודל החלוץ אינה פרט שיווקי. זהו ההבדל בין מצב מועמד לשרשרת פעילה. המסקנה הנכונה אינה שהמודל החזק ביותר אינו נחוץ. המסקנה היא שהמודל החזק ביותר צריך להיות ממוקם במקום שבו היתרון שלו באמת מצטבר, ולא מבוזבז בכל מעבר בעל ערך נמוך. (אדום אנתרופי)
הארכיטקטורה של Anthropic עצמה מרמזת על אותו לקח. הפוסט הפומבי של "צוות האדום" (Red Team) של החברה אינו מתאר תרחיש שבו Mythos ממציא באגים באופן ספונטני יש מאין. הוא מתאר סביבה מבוססת קונטיינרים, גישה לקוד, ניסויים איטרטיביים, אימות ויצירת דוחות באגים. במילים אחרות, אפילו בחזית הטכנולוגיה, התוצאות הטובות ביותר של המודל מופיעות כאשר הוא משולב בתוך מבנה המעניק לו מקום, זיכרון, כלים, משוב ותנאי הצלחה. זו אינה חולשה בטענה. זהו העיקר. ככל שהמודל נעשה מסוגל יותר, כך זרימת העבודה הסובבת אותו נעשית בעלת ערך רב יותר, משום שעלות הכישלון ללא מגבלות עולה עם היכולת. (אדום אנתרופי)
ההיבט הכלכלי של בדיקות חדירה מבוססות בינה מלאכותית מתמקד בממצאים מאומתים, ולא בהצגת ביצועים למטרות ראווה
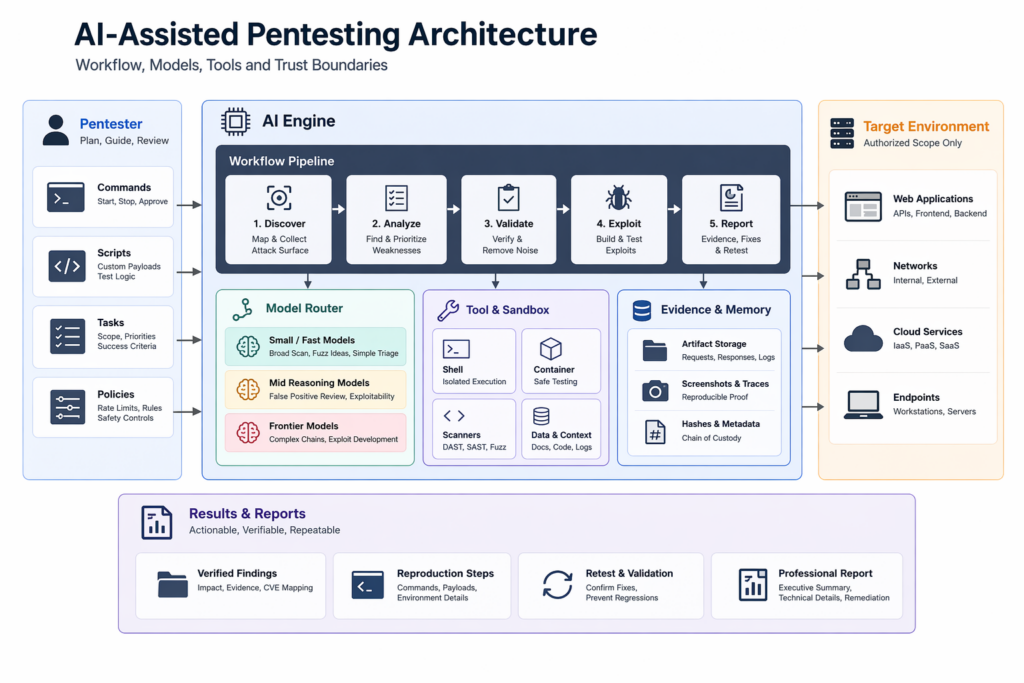
צוותי אבטחה צריכים להתייחס בחשדנות רבה לכל דיון בנושא תמחור שמתחיל ומסתיים בעלות על אסימון. יחידת החישוב האמיתית בבדיקות חדירה אינה "עלות למיליון אסימונים". היא קרובה יותר לעלות לממצא מאומת, לעלות לכל תוצאה חיובית אמיתית שנשמרה לאחר בדיקה אנושית, לזמן שחלף מהאות הראשוני ועד להוכחה ניתנת לשחזור, ולעלות תשומת הלב של הבודק שבוזבזה על רעש. ההגדרה של NIST כבר מצביעה בכיוון זה על ידי הכללת ניתוח והפחתה, ולא רק זיהוי. בפעולות אבטחה, לממצא שאינו עומד בבדיקה חוזרת יש ערך שלילי. הוא גוזל תשומת לב, יוצר חוב דיווחי, ויכול לפגוע באמון בכל התהליך. (csrc.nist.gov)
בעמוד "Project Glasswing" של Anthropic נכתב כי "Mythos Preview" יהיה זמין למשתתפים במחיר של $25 למיליון אסימוני קלט ו-$125 למיליון אסימוני פלט לאחר תקופת זיכוי השימוש, עם התחייבות לזיכויים בסך של עד $100 מיליון במהלך תקופת התצוגה המקדימה למחקר. לעומת זאת, בכתבה של AISLE מודגשת עלות של $0.11 למיליון אסימונים עבור מודל פעיל של 3.6B באחת ממשימות השכפול שלה. המספרים הללו אינם זהים לחלוטין, אך הכיוון ברור מספיק גם בלי לנסות ליצור דיוק כוזב: ההבדלים במחירים בין המודלים גדולים, וזה חשוב ברגע שמפסיקים לחשוב במונחים של הדגמות ומתחילים לחשוב במונחים של זרימות עבודה מתמשכות, חוזרות ונשנות בייצור. מערכת שברירת המחדל שלה היא המודל היקר ביותר בכל שלב אינה "רצינית" בהגדרה. ייתכן שהיא פשוט לא כלכלית ומנוהלת בצורה גרועה. (anthropic.com)
הדרך הטובה ביותר להתייחס לעלויות היא לשאול היכן השקעת כספים במודל "חזית" משנה את התוצאה הסופית. אם מודל זול מסוגל לקבץ נתיבים בצורה נכונה, לזהות משטח תקיפה סביר או לדחות תוצאות חיוביות כוזבות ברורות, אזי כל דולר שתשקיעו בשימוש במודל "חזית" כדי לחזור על אותה עבודה הוא דולר שלא תוכלו להשקיע באימות מעמיק יותר, בניסיונות ניצול לטווח ארוך יותר, בבדיקת זרימה מאומתת או בבדיקה חוזרת לאחר תיקונים. כלכלה נכונה של בדיקות חדירה קשורה אפוא להקצאת שלבים. כיסוי זול קונה לכם שטח פנים. חשיבה מעמיקה יותר קונה לכם בהירות. חשיבה מתקדמת קונה לכם ניסיונות פריצה שבהם מרחב החיפוש כבר דחוס מספיק, כך שהמודיעין, ולא הרוחב, הוא הגורם המגביל. (מעבר)
הטבלה שלמטה מהווה לוח מחוונים שימושי יותר לניתוח הכלכלי של בדיקות חדירה מבוססות בינה מלאכותית מאשר כל שקף השוואתי של ספק כלשהו. זוהי סיכום של תהליך העבודה וההיגיון התמחורי המשתקפים במקורות שצוינו לעיל. (csrc.nist.gov)
| מטרי | מדוע זה חשוב יותר מציוני מבחני ביצועים גולמיים | עיוות נפוץ | מה צריכה לשאול קבוצה ממושמעת |
|---|---|---|---|
| עלות לממצא מאומת | זה המקום שבו האות הופך לערך שניתן להגן עליו | לראות בכל מועמד ניצחון | כמה ממצאים עומדים במבחן הצפייה החוזרת והבדיקה |
| עלות לכל תוצאה חיובית אמיתית שנותרה לאחר המיון | רעש פוגע באמון המבקר | מספרים מנופחים של "בעיות שנמצאו" | מהו נטל הדחייה של תוצאות חיוביות כוזבות |
| הזמן מרגע קבלת האות ועד לקבלת ההוכחה | המהירות חשובה רק אם היא מובילה לראיות | מדידת זמן ההשערה הראשונה בלבד | כמה זמן ייקח עד שיהיה תיעוד של תהליך ההעתקה ושל הממצאים? |
| כיסוי לכל דולר | דגמים זולים יכולים להרחיב את מרחב החיפוש | שימוש יתר בדגמים יקרים בשלבים קלים | אילו שלבים רוויים בכיסוי בעלות נמוכה |
| מועד הבדיקה החוזרת לאחר התיקון | ערך האבטחה נשמר רק אם התיקונים אומתו | דיווח ללא בדיקה חוזרת | באיזו מהירות יכול תהליך העבודה לאשר תיקון |
| דקות עבודה אנושיות לכל ממצא שזכה לקידום | הבעיה האמיתית היא בדרך כלל תשומת הלב של הסוקרים | הסתרת עבודת הניקוי של האנליסט | כמה מאמץ ידני עדיין נדרש עבור כל ממצא מאומת |
מקרים אמיתיים מראים מדוע זרימת עבודה עדיפה על מיתוסים תיאורטיים
הפער בין "התנהגות מעניינת של המודל" ל"ערך אמיתי בבדיקות חדירה" מתבהר כאשר בוחנים קטגוריות פגיעות בפועל. הדבר החשוב אינו היכולת של מודל שפה גדול (LLM) לתאר אותן. הדבר החשוב הוא האם המערכת מסוגלת לצמצם את ההקשר כראוי, להבין את תחולת הפגיעות, לאמת את ההשפעה ולשמור על הראיות מבלי לייצר ביטחון כוזב. המקרים שלהלן מועילים משום שהם מדגישים חלקים שונים בתהליך. חלקם מתגמלים חשיבה סמנטית. חלקם מתגמלים מודעות סביבתית. חלקם מענישים צוותים שמבלבלים בין ידע ב-CVE לידע בניצול. חלקם אינם מתאימים לתפיסה של סורק טהור. כולם מובילים לאותה מסקנה: איכות המודל חשובה, אך עיצוב זרימת העבודה קובע אם איכות זו הופכת לעבודה אבטחתית אמינה. (פרויקט FreeBSD)
CVE-2026-4747, RPCSEC_GSS ב-FreeBSD וההבדל בין זיהוי להוכחה
CVE-2026-4747 הוא הדוגמה הברורה ביותר, שכן הוא מופיע הן במצגת של Anthropic והן בהודעה הרשמית של FreeBSD. FreeBSD מציינת כי הבעיה היא פגיעות המאפשרת הרצת קוד מרחוק בתהליך אימות חבילות RPCSEC_GSS, המשפיעה על כל הגרסאות הנתמכות בעת החשיפה, ומציינת את "ניקולס קרליני באמצעות Claude, Anthropic" כמי שגילה אותה. הפוסט של צוות Red Team של Anthropic מתאר את Mythos Preview כמי שזיהה וניצל את הבאג באופן אוטונומי לחלוטין לאחר שסרק מאות קבצים בקרנל, בעוד שהשחזור של AISLE טוען שברגע שהפונקציה הפגיעה מבודדת וההקשר הארכיטקטוני הרלוונטי מסופק, אפילו מודלים קטנים יותר יכולים לזהות את העומס יתר ולהסיק את ההשלכות הקריטיות. זהו בדיוק סוג המקרה שמבדיל בין חיפוש בקנה מידה של מאגר קוד לבין הסקת מסקנות לגבי פגיעות מקומית. זה לא מוכיח שמודלים קטנים יכולים לבצע את כל העבודה. זה מוכיח שחלק משמעותי מה"חלק החכם" הופך לנגיש הרבה יותר מוקדם בעקומת יכולות המודל ממה שרבים הניחו. (פרויקט FreeBSD)
הלקח התפעולי מועיל אף יותר מהלקח הסמלי. CVE-2026-4747 אינו רק כותרת חדשותית משום שהוא קשור לבינה מלאכותית. חשיבותו נובעת מכך שהוא נמצא בנקודת המפגש בין ניתוח פרוטוקולים, הקשר של הקרנל, חומרת הפגיעות ואימות. תהליך בדיקת חדירות שמסתפק בציון "אפשרות לעומס יתר במסלול האימות" אינו מספיק. תהליך עבודה רציני חייב לשמר את הנחות החבילה, אזור הקוד, טיעון הניצול, הסביבה המדויקת ושלבי השחזור. לכן מדד ההצלחה הנכון אינו "המודל מצא באג", אלא "המערכת הניבה ממצא שמהנדס אחר יכול לתקן ולסמוך עליו". (csrc.nist.gov)
OpenBSD SACK: ההיגיון העדין הוא המקום שבו הניתוב מתחיל להיות משמעותי
הבאג ב-SACK של OpenBSD המוזכר בפוסט של Anthropic מהווה מבחן טוב יותר לחשיבה עדינה מאשר המקרה של FreeBSD. Anthropic מתארת אותו כבאג בן 27 שנים, שתוקן בינתיים, במערכת הפעלה הידועה באבטחתה. השחזור של AISLE מועיל מכיוון שהוא מבהיר את הקושי הבסיסי: הבעיה אינה דפוס פגיעה בזיכרון ברור עד כדי גיחוך. היא כרוכה באימות גבול תחתון, התנהגות הצפה חתומה במאקרו של השוואת רצפים, ושרשרת המובילה למצב מצביע null רק תחת ערכי חבילות שנבחרו בקפידה. AISLE מדווחת כי מודל פתוח פעיל בגודל 5.1B שיחזר את השרשרת הציבורית המלאה בעוד שמספר מודלים אחרים נכשלו בחלק מההנמקה. זו אינה חגיגת ניצחון למודלים קטנים. זהו שיעור בניתוב. חלק מהשלבים כבר הפכו למוצר בסיסי. אחרים עדיין דורשים הסלמה סלקטיבית. (אדום אנתרופי)
המסקנה המעשית עבור בודקי חדירות היא שדווקא במקרים של באגים עדינים, על המערכת לנקוט בגישה שמרנית בכל הנוגע לקידום תוצאות. מודל שמצהיר בביטחון כי הוא "עמיד בפני תרחישים כאלה" בסיבוב אחד, ואז מגלה שרשרת ניצול מורכבת במשפחת מודלים אחרת, מהווה תזכורת לכך שהקונצנזוס בין המודלים אינו זהה לאמת. עבור סוג זה של בעיות, על תהליך העבודה לשמר את הנחות החבילות, תנאי הגבול ותוצרי ההוכחה הניתנים להפעלה לפני שממצא הופך לסמכותי. ככל שרשרת ההנמקה קשה יותר, כך שער הראיות צריך להיות חזק יותר. (מעבר)
FFmpeg H.264: סמנטיקה יכולה לגבור על אינטואיציה המבוססת על כוח גולמי
הדוגמה של FFmpeg שמציגה Anthropic חשובה מסיבה אחרת. החברה טוענת ש-Mythos Preview איתרה פגיעות בת 16 שנים במסלול המפענח של H.264, הנובעת מחוסר התאמה בין מונה פרוסות של 32 סיביות לבין טבלת בעלות של 16 סיביות, שהותחלה בערך סנטינל. Anthropic מתארת את הבאג ככזה ששרד בדיקה קפדנית באחד מפרויקטי המדיה הנבדקים ביותר בעולם, כולל שנים של בדיקות פוזינג. בין אם רוצים להדגיש את הגיל, את המוניטין של בסיס הקוד או את היסטוריית הבדיקות, הלקח ההנדסי הוא זהה: לא כל הבאגים בעלי הערך הגבוה נראים כמו הסוגים של תקלות שאסטרטגיות חיפוש מסורתיות מגלות בקלות. חלק מהכשלים טמונים באי-התאמות סמנטיות, בהנחות סנטינל ובמבני מצב נדירים, שסביר בהחלט לפספס אם המערכת שלכם מותאמת בעיקר לחתימות ידועות או לזיהוי תבניות שטחי. (אדום אנתרופי)
זה הופך את FFmpeg לטיעון משכנע בעד תהליכי עבודה משולבים. סורקים "טהורים" מתקשים להתמודד עם מלכודות סמנטיות. סוכני חשיבה "טהורים" ללא בודקי תקינות נוטים לביטחון עצמי מופרז. המערכת הנכונה משלבת חקירה סמנטית עם בודק תקינות חזק מספיק כדי לדחות סיפורים לא תקינים. בהקשרים של בטיחות זיכרון, זה עשוי להיות מנקה זיכרון או "אורקל קריסה". בהקשרים של יישומי אינטרנט, זה עשוי להיות מערך השמעה חוזרת ומודל מצב המודע להרשאות. בהקשרים של ממשקי API, זה עשוי להיות השמעה חוזרת של עסקאות המובחנת לפי תפקידים על פני אובייקטים. הדפוס המנצח אינו "להחליף כלים בשפה". הוא "להשתמש בשפה כדי להנחות כלים לעבר הניסויים הנכונים". (אדום אנתרופי)
CVE-2024-3094, XZ והמגבלות של בדיקות חדירה מבוססות בינה מלאכותית המונעות מכותרות
דלת האחורי ב-XZ מהווה לקח מועיל, שכן הוא מעניש חשיבה פשטנית בנוגע לפגיעות. ה-NVD מתאר קוד זדוני בקבצי tar של xz במעלה הזרם, החל מגרסה 5.6.0, הכולל הוראות בנייה נוספות לחילוץ קובץ אובייקט מוסתר ששינה את התנהגות liblzma במהלך הבנייה. זוהי בעיה הקשורה לשרשרת האספקה ולתוצרי המהדורה, ולא רק בעיה של קריאת קוד בתוך המאגר. מערכת שרק סורקת עצי מקור או כותרות גרסה עלולה בקלות לפספס את הדבר החשוב ביותר. הלקח האמיתי הוא שהיישום יכול להיות תלוי בנתיב השחרור, בסביבת הבנייה, בשילוב החבילה ובהתנהגות ההפצה במורד הזרם. זהו בדיוק המקרה שבו סיוע ה-AI טוב רק כטוב הראיות והמקור שהוא יכול לאתר. (nvd.nist.gov)
בכל הנוגע לבדיקות חדירה מבוססות בינה מלאכותית, CVE-2024-3094 מהווה אזהרה מפני בלבול בין הבנת חדשות בנושא פגיעות לבין אימות תפעולי. מודל שיכול להסביר את XZ ברהיטות לא עזר לכם, אלא אם כן המערכת יכולה לענות על שאלות קשות יותר: האם הגרסה המושפעת אכן הושקה, האם נתיב הבנייה שלכם צרך את הארטפקטים שזויפו, אילו גרסאות חבילות עברו בנתיב זה, אילו קבצים בינאריים קישרו לספרייה ששונתה, ואילו גבולות אמון נפרצו. מקרים של שרשרת אספקה הם המקומות שבהם הסיפור של "המודל הגדול ביותר מנצח" מתפרק הכי מהר, כי צוואר הבקבוק הוא לרוב מקור המידע, ולא הניסוח. (nvd.nist.gov)
CVE-2024-6387, regreSSHion וההבדל בין חומרת הפגיעות לבין השפעתה בפועל
NVD מתאר את CVE-2024-6387 כנסיגה באבטחה בשרת OpenSSH, שבה מצב תחרות (race condition) בטיפול באותות עלול לאפשר לתוקף מרוחק לא מאומת לגרום להתנהגות מסוכנת על ידי כישלון באימות בתוך פרק זמן מוגבל. הנקודה החשובה במאמר זה אינה הדיון בנוגע לניצול פגיעות בסביבות ספציפיות. הנקודה היא שתהליך העבודה חייב להתייחס לסביבה, לתזמון, לחשיפה ולעדיפות תפעולית בפועל, במקום להסתפק ב"באג מרחוק קריטי". מערכות אבטחה מבוססות בינה מלאכותית רבות נשמעות משכנעות דווקא במקומות שבהם הן הכי פחות שימושיות: הן יכולות לחזור על חומרת הבעיה מבלי לבצע את המשימה הקשה יותר של הערכת הישימות. (nvd.nist.gov)
זו הסיבה שדירוג הפגיעות לא צריך להסתמך על ניתוח חד-פעמי של טקסט מודל. מערכת יעילה צריכה לבחון האם השירות פונה לאינטרנט, האם הגרסה הפגיעה חשופה מלכתחילה, האם אמצעי בקרה מתקנים משנים את חלון ההתקפה, וכיצד ייראה תנאי ההוכחה הצפוי תחת אימות בטוח. מודל יכול לסייע. תהליך העבודה הוא זה שצריך לקבל את ההחלטה. ככל שהצוות בוגר יותר, כך הוא צריך להתרשם פחות מניסוח שוטף של תיאור ה-CVE, וכך הוא צריך להתעניין יותר במה שהמערכת יכולה להוכיח לגבי סביבה זו. (csrc.nist.gov)
CVE-2024-3400 ו-CVE-2024-4577, היישום אינו אופציונלי
התיאור של NVD ל-CVE-2024-3400 הוא ברור: הזרקת פקודות הנובעת מיצירת קבצים שרירותית ב-GlobalProtect בגרסאות ספציפיות של PAN-OS ותצורות תכונות מסוימות עשויה לאפשר הרצת קוד ברמת root ללא אימות, בעוד ש-Cloud NGFW, מכשירי Panorama ו-Prisma Access אינם מושפעים. CVE-2024-4577 קשור לא פחות לתצורה, אך באופן שונה: NVD מציין כי גרסאות PHP מושפעות ב-Windows במצב CGI עלולות לפרש באופן שגוי תווים תחת דפי קוד ספציפיים ולאפשר אפשרויות PHP הנשלטות על ידי התוקף, עם השלכות עד כדי ביצוע קוד שרירותי. אלה דוגמאות מושלמות לכך שבדיקות חדירה אמיתיות המבוססות על בינה מלאכותית (AI) אינן יכולות להסתפק בחיפוש CVE. עליהן לענות על שאלות תצורה. האם התכונה מופעלת? האם סוג המכשיר מושפע? האם מצב CGI נמצא בשימוש? איזה דף קידוד נמצא בשימוש? האם ניתן להגיע לתנאי זה מהנתיב החשוף? (nvd.nist.gov)
אלה אינם מקרים קיצוניים. אלה דוגמאות שגרתיות הממחישות מדוע החלק האמצעי של בדיקת חדירות קשה יותר מהחלק הקדמי. החלק הקדמי הוא זיהוי האפשרות. החלק האמצעי הוא הפרדת האמת הסביבתית מהשפה הכללית של הסיכונים. בחלק האמצעי הזה, תהליכי העבודה, אחזור הנתונים, שמירת המצב ואיסוף הראיות מוכיחים את ערכם. זהו גם המקום שבו מודלים קטנים או בינוניים יכולים לעתים קרובות לבצע עבודה מצוינת, אם המערכת כבר אספה את העובדות הסביבתיות הנכונות. צוואר הבקבוק אינו תמיד עומק החשיבה המופשטת. לפעמים הוא קשור לשאלה האם זרימת העבודה בכלל טרחה לאסוף את העובדות שהופכות את הפגיעות לממשית. (csrc.nist.gov)
הטבלה שלהלן מסכמת את הדפוס. היא נועדה לשמש ככלי עזר לקבלת החלטות ולא כקטלוג. (פרויקט FreeBSD)
| תיק | מדוע זה חשוב במקרה זה | מה לא נכון בגישה שמתייחסת רק לדוגמניות | מה יש למערכת שמציבה את זרימת העבודה בראש סדר העדיפויות להציע |
|---|---|---|---|
| CVE-2026-4747 FreeBSD RPCSEC_GSS | דוגמה מובהקת לגילוי, לחומרה ולהוכחה | מבלבל בין חשיבה מבודדת לבין אוטונומיה מקצה לקצה | בידוד פונקציות, הקשר חבילות, מתקן לשחזור, עקבות תופעות |
| באג SACK ב-OpenBSD | בודק את יכולת החשיבה העדינה ואת ההיגיון של ניצול פגיעויות | מתייחס להסבר אחד משכנע כאל אמת מוחלטת | אימות רב-שלבי וקידום זהיר |
| פגם ב-FFmpeg H.264 | מראה כי באגים סמנטיים יכולים לשרוד בדיקות קפדניות | ריכוז גבוה במיוחד של תקלות שניתן לזהות בקלות | הסקת מסקנות סמנטית הקשורה למאמתים |
| CVE-2024-3094 XZ | הקשר של שרשרת האספקה עדיף על סריקה של המקור בלבד | בהנחה שבדיקת הריפו מספיקה | ניתוח מקור, נתיב בנייה ורכיבי גרסה |
| CVE-2024-6387 regreSSHion | רמת החומרה אינה זהה לעדיפות התפעולית | חוזר על נוסח ה-CVE ללא הערכת מידת הרלוונטיות | אימות תוך התחשבות בחשיפה ובסביבה |
| CVE-2024-3400 PAN-OS | יש חשיבות להיקף התכונות והמוצר | מתעלם מתנאי הקדם של התצורה | בדיקות תאימות בהתאם למוצר |
| CVE-2024-4577 PHP-CGI | למקום ולמצב ההפעלה יש חשיבות | השוואת גרסאות נחשבת כהוכחה ליכולת ניצול | אימות זמן ריצה ודף קידוד |
בניית תהליך העבודה שהופך מודלים קטנים יותר לשימושיים
מערכת ריאליסטית לבדיקות חדירה של בינה מלאכותית מתחילה בגבולות, ולא בהנחיות. עוד לפני שמודל כלשהו רואה את היעד, על המערכת לדעת כבר מראש אילו מחשבים מורשים, אילו סוגי מחשבים אסורים, מהו קצב הבקשות המרבי, אילו זהויות ותפקידים זמינים לבדיקות מאומתות, אילו קטגוריות של פעולות דורשות אישור מפורש, ואילו תוצרים יש לשמור לבדיקה מאוחרת יותר. מודלים הופכים למסוכנים בעיקר כאשר הם אינם משולבים במדיניות שתוקפה עולה על השטף הזמני שלהם. סוכן חזק אינו בטוח יותר משום שהוא חזק יותר. הוא בטוח יותר משום שהוא מוגבל בצורה מדויקת יותר. זה נכון לגבי מודל חדשני בדיוק כפי שזה נכון לגבי מודל זול. (csrc.nist.gov)
מפרט היקף פשוט אינו מרשים במיוחד, אך הוא מהווה את ההבדל בין תהליך עבודה מסודר לבין גימיק. המבנה שלהלן אינו נועד לשמש כקובץ הפקה שלם. הוא מציג את המידע המינימלי שתהליך העבודה צריך לקבוע באופן רשמי לפני שסוכן כלשהו מתחיל בבדיקות פעילות.
engagement: target_id: prod-api-2026-04 owner: security-team@example.com authorization_ticket: CHG-48219 allowed_hosts: - api.example.com
- auth.example.com forbidden_hosts: - payments.internal.example.com - admin-vpn.example.com allowed_identities: - customer_basic - customer_premium - support_agent prohibited_actions:
- מחיקת נתונים הרסנית - איפוס סיסמאות למשתמשים אמיתיים - הרחבת הרשאות בסביבת הפקה מחוץ לשער האישור rate_limits: max_rps: 3 burst: 10 evidence: output_dir: findings/prod-api-2026-04
save_http: true save_screenshots: true save_terminal_logs: true save_reproducers: true escalation: frontier_model_required_for: - business_logic_chain - sandbox_escape_attempt - סינתזה של ניצול רב-שלבי
ברגע שקיימים גבולות, השלב הראשון צריך בדרך כלל להיות זול ורחב היקף. יש למפות את נקודות הקצה של המלאי. לקבץ מסלולים דומים. לאסוף תיעוד ורמזים ממסגרות. להשוות תגובות בין תפקידים שונים. לתעד זמנים, הפניות מחדש, מעברי קוקיות ומזהי אובייקטים. בפרויקטים עתירי קוד, יש לאנדקס את הפרויקט ולדרג אזורים שעשויים להיות קריטיים מבחינה אבטחתית. בבדיקות אינטרנט דינמיות, יש למפות מצבים ומעברים. זו היא צמצום מרחב החיפוש. זהו המקום שבו מודלים זולים וכלים דטרמיניסטיים פועלים היטב יחד. אתם עדיין לא מבקשים פריצת דרך. אתם רוכשים רוחב מאורגן. (מעבר)
השלב השני הוא השלב שבו מערכות רבות מתחילות לבזבז כסף. במקום להפנות כל נקודה חשודה למודל הגדול ביותר שקיים, תהליך עבודה מסודר שואל שאלה מצומצמת יותר: האם מודל צנוע בשילוב עם בודק יכול לפתור את הבעיה? בעבודות הקשורות לבטיחות זיכרון, זה עשוי להתבטא במנקה זיכרון, באורקל קריסות או במנגנון שחזור מינימלי. בעבודות הקשורות לאינטרנט ול-API, זה עשוי להתבטא בהשמעה דיפרנציאלית בין תפקידים, מזהי אובייקטים או מצבי תהליך עבודה. עבור CVEs הרגישים לתצורה, זה עשוי להתבטא בלכידת סביבה לפני הסלמת ההשערה. אין לקדם מודל רק משום שהבאג נשמע חמור. יש לקדם אותו משום שהמאמת קובע כי אי-הוודאות מוגבלת כעת למידע ולא לראיות. (אדום אנתרופי)
ניתן לתאר את מדיניות הניתוב באמצעות קוד. שוב, העניין אינו ביישום המדויק. העניין הוא שבחירת המודל הופכת להחלטה מדינית התלויה באיכות הראיות, ולא לברירת מחדל קבועה התלויה ביוקרת הספק.
def choose_model(stage, signal_strength, validator_confidence, complexity): if stage in {"asset_mapping", "endpoint_clustering", "first_pass_review"}: return "small_fast_model"
אם שלב נמצא ב-{"triage", "false_positive_review"}: אם validator_confidence >= 0.8: החזר "small_or_mid_model" החזר "mid_reasoning_model" אם שלב נמצא ב-{"exploitability_assessment", "business_logic_analysis"}:
אם complexity == "high": החזר "frontier_model" החזר "mid_reasoning_model" אם stage נמצא ב-{"exploit_construction", "sandbox_escape", "multi_bug_chain"}: החזר "frontier_model" החזר "mid_reasoning_model"
זהו גם המקום שבו הנרטיבים המוצלחים ביותר בקטגוריה מתחילים להיראות דומים. דף הבית הציבורי של Penligent אינו מציג את העבודה כ"שאל את המודל הטוב ביותר ותקווה לטוב". הוא מציג בקדמת הבמה תהליך תפעולי בן שלושה שלבים: "איתור נקודות תורפה. אימות הממצאים. ביצוע ניצול", ומשלב זאת עם "תוצאות מבוססות ראיות שניתן לשחזר" ו"ערוך הנחיות, נעל את ההיקף והתאם פעולות לסביבתך". גם אם קונה לעולם לא יגע במוצר הזה, אלה השאלות הנכונות שיש לשאול כל פלטפורמה בתחום זה, מכיוון שהן מתאימות לדרישות הנדסיות אמיתיות: הוכחה לפני קידום, תוצרים לפני טענות, ושליטת המפעיל לפני הצגת אוטונומיה למראית עין. (penligent.ai)
צינור הנתונים חשוב לא פחות ממנתב המודלים. אם תהליך העבודה אינו שומר מספיק חומר גלם כדי לשחזר ממצא מאוחר יותר, הוא למעשה מאמן את עצמו בדממה לדווח על השערות כעל עובדות. זו הדרך המהירה ביותר להרוס את האמון בבדיקות המבוצעות בסיוע בינה מלאכותית. קטע הקוד שלמטה משעמם בכוונה. זו הסיבה שהוא שימושי.
TARGET_ID="prod-api-2026-04" OUT="findings/$TARGET_ID/candidate-017" mkdir -p "$OUT" cp scope.yaml "$OUT/"
cp target-map.json "$OUT/" cp request.txt "$OUT/" cp response.txt "$OUT/" cp role-a-session.txt "$OUT/" cp role-b-session.txt "$OUT/" cp payload.txt "$OUT/"
cp terminal.log "$OUT/" cp screenshot.png "$OUT/" cp reproducer.sh "$OUT/" cp notes.md "$OUT/" sha256sum "$OUT"/* > "$OUT/artifact_hashes.txt"
ראיות אבטחה טובות הן לרוב משעממות לפני שהן הופכות לבעלות ערך. המודל יכול לסייע בכתיבת הערות, בהשוואת עקבות, בהסברת קריסה או בהצעת הענף הבא שיש לבדוק. אך תהליך העבודה עדיין זקוק לנתוני סביבה, לבקשות גולמיות, לפלט הביצוע ולנתיב השחזור. אין בכך כדי להתנגד לבינה מלאכותית. זו הדרך למנוע מהבינה המלאכותית להפוך למגבר ביטחון לטענות שלא אומתו. (penligent.ai)
הדיווח הוא השלב האחרון, ולא התוצר הגלוי הראשון
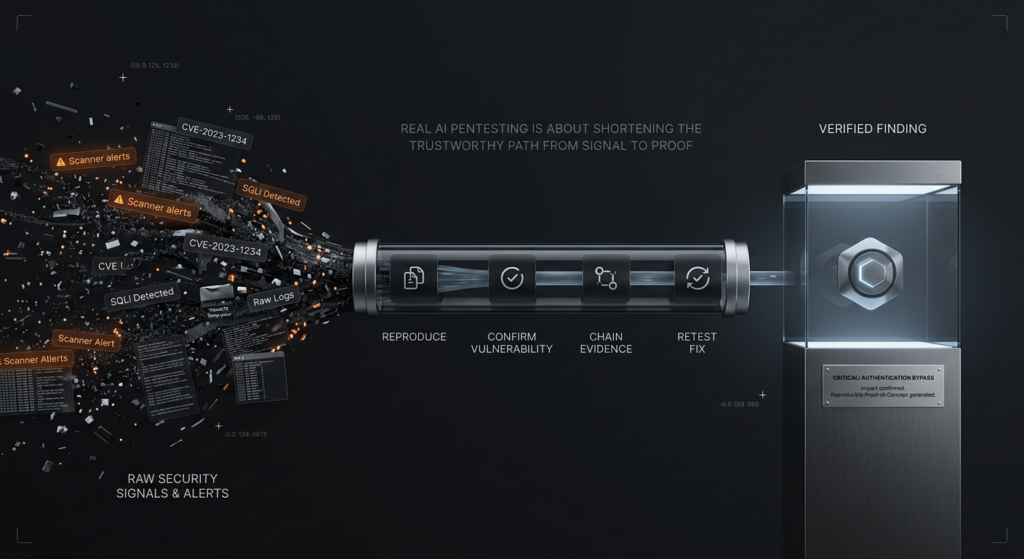
אחת ההרגלים המזיקים ביותר בתחום כלי אבטחת ה-AI היא יצירת דוחות מלוטשים בטרם המערכת זכתה בהם. המסגרת של NIST מועילה כאן, שכן היא ממקמת את הניתוח וההפחתה בתוך תהליך הבדיקה ולא אחריו. דוח אינו תוצר של מודל שפה מתוחכם. הוא האריזה של תוצאה מאומתת. זה נשמע מובן מאליו, אך חלק מפתיע מהשוק עדיין טועה בסדר הפעולות. מערכת מוצאת רמז, כותבת סיפור, ומאפשרת לדוח עצמו להלבין אי-ודאות ולהפוך אותה לסמכות. בודקי חדירות צריכים לסרב לדפוס הזה. הקונים צריכים להעניש אותו. (csrc.nist.gov)
דפוס עבודה בריא בהרבה הוא להגדיר "שער" לאישור. ממצא אינו הופך לממצא מאומת רק משום שההסבר נשמע טוב או שהערכת ה-CVSS נראית סבירה. הוא הופך למאומת כאשר בתהליך העבודה יש מספיק תיעוד כדי לשחזר את הבעיה, מספיק הקשר סביבתי כדי לתמוך ביישום, ומספיק ראיות כדי להפוך את התיקון ליעיל ולא ספקולטיבי. ניתן להגדיר שער מינימלי באמצעות לוגיקת מדיניות.
def promote_to_verified(candidate): required = [ candidate.reproducer, candidate.artifacts.http_or_binary_trace, candidate.environment_notes, candidate.impact_statement, candidate.remediation_basis, ]
if not all(required): return False, "חסרים ארטפקטים נדרשים" if candidate.finding_type == "access_control" and not candidate.role_differential_proof: return False, "חסרים ראיות להבדל בהרשאות"
אם candidate.finding_type == "memory_corruption" ולא candidate.validator_signal: החזר False, "חסר אימות קריסה או סניטייזר" אם candidate.severity ב-{"critical", "high"} ולא candidate.retest_plan: החזר False, "חסרים קריטריוני בדיקה חוזרת" החזר True, "מאומת"
זהו המקום שבו אספקת המוצר והמשמעת ההנדסית נפגשות סוף סוף. דפי התמחור והמוצרים של Penligent מדגישים ייצוא דוחות הכוללים ראיות ושלבי שחזור, שחזור פרצות בלחיצה אחת עם דיווח על שרשרת הראיות, ואספקה ברמה צוותית המוכנה לביקורת. החומר הציבורי של Hacking Labs בנושא דוחות בדיקות חדירה של בינה מלאכותית גם הוא מציג את הבעיה כהוכחה של מה שקרה לאחר מכן, ולא רק כיצירת קובץ PDF יפה יותר כעת. כיוון זה הוא בריא מבחינה טכנית, מכיוון שהוא מתייחס לדיווח כביטוי משני של תוצרים ולא כתחליף לתוצרים. שוב, הלקח מתעלה מעבר לספק בודד: המערכות שראויות לאמון הן אלה שיכולות להסביר כיצד טענה הופכת לראיה. (penligent.ai)
דפוסי הכשל שעדיין מעכבים צוותים
הטעות הנפוצה ביותר היא לרכוש את המודל הגדול ביותר שקיים ולהעביר דרכו את כל הנתונים. זה נראה מרשים. לרוב, התוצאה היא השילוב הגרוע ביותר בין עלות, זמן השהיה ועייפות של הבודקים. שלבים פשוטים זוכים להקצאה מוגזמת של משאבים. שלבים קשים עדיין נכשלים כי צוואר הבקבוק לא היה הבינה המלאכותית אלא משמעת הקשר או מחסור במאמתים. הצוות מגיע אז למסקנה ש"בדיקות חדירה מבוססות בינה מלאכותית לא עובדות", כאשר הבעיה האמיתית הייתה שהן התייחסו לאיכות המודל כתחליף לאיכות זרימת העבודה. המסגרת של AISLE סביב אסימונים לדולר, אסימונים לשנייה ומומחיות אבטחה מובנית היא תרופה יעילה. בצינורות רציניים, מהירות וכיסוי אינם הערות שוליים. הם חלק ממשוואת היכולות. (מעבר)
טעות שנייה היא לבלבל בין הרחבת יכולות הסורק לבין בדיקות חדירה. ההנחיות של OWASP בנושא בדיקות נותרות כלליות מסיבה טובה. בדיקה אמיתית כוללת מיפוי, התנהגות מאומתת, טיפול במצבים, בדיקות הרשאה והיגיון עסקי. מערכת שאינה מסוגלת לשמר הקשר רב-תפקידי או להסיק מסקנות לגבי בעלות על אובייקטים עשויה עדיין להיות שימושית, אך היא אינה מבצעת בדיקות חדירה כלליות במובן המוחלט שבו מתייחסים אליה רוב העוסקים בתחום. זה חשוב במיוחד עבור ממשקי API, שבהם אי-תקינות בהרשאות ברמת האובייקט (Broken Object Level Authorization) נותרת סיכון מרכזי, מכיוון שמזהים עוברים דרך נתיבים, כותרות, מטענים ומצב זרימת עבודה משתמע. עוזר AI שאינו מבין את השטח הזה ייצר בדרך כלל כמות גדולה של טקסט בנושא אבטחה וכמות מועטה של ראיות לגבי סיכונים. (owasp.org)
טעות שלישית היא להתייחס להדגמות של פרצות כאל הערך המלא. Mythos התפרסמה בזכות העובדה שבניית הפרצות בה היא מוחשית ומפחידה, והנתונים של Anthropic עצמה מצביעים על כך שקיימת יכולת פורצת דרך בתחום זה. אך ארגונים רבים אינם נכשלים משום שחסר להם כותב פרצות אוטונומי לחלוטין. הם נכשלים משום שאינם מצליחים לעמוד בקצב של מיון מודע לסביבה, בדיקת זרימת עבודה מאומתת, תיעוד ראיות שניתן לשחזר, או בדיקה חוזרת לאחר התקנת תיקונים. תוכניות אבטחה נתקלות בדרך כלל בבקבוק צוואר בבקבוק של המרת אות גולמי לפעולה מהימנה. זו הסיבה שהמערכות החזקות ביותר בשוק מדגישות יותר ויותר ממצאים מאומתים, יכולת שחזור ואיכות מסירה. הניצול המפחיד אינו חסר רלוונטיות. הוא פשוט אינו בקבוק הצוואר היחיד, ולעתים קרובות אינו הראשון. (אדום אנתרופי)
טעות רביעית היא התעלמות מיכולת ההתערבות האנושית. מערכות סוכניות חזקות יותר זקוקות לבקרות הדוקות יותר, ולא רופפות יותר. המסגרת הציבורית שהציג Penligent סביב "היקף נעול" ו"פעולות הניתנות להתאמה אישית" היא חיובית מאותה סיבה שהמבנה המובנה במכולות של Anthropic הוא חיובי: המערכת שימושית בסביבה אמיתית רק אם המפעילים יכולים להגביל את תחומי פעולתה ואת האופן שבו מקודמות פעולות מסוכנות. אוטונומיה ללא פיקוח אינה בגרות. זו ביטחון עצמי מדומה. (אדום אנתרופי)
מה באמת כדאי לקבוצות למדוד
בשלב זה, המדדים הנכונים אמורים להיות ברורים מאליהם, אך רוב הצוותים עדיין אינם מיישמים אותם כראוי. הם מודדים את מספר הבעיות שנמצאו, את ההפרשים ביחס לסטנדרטים, או את משך הזמן הממוצע לניתוח, אך מתעלמים מהמשתנים הקובעים אם תוכנית בדיקות חדירה מבוססת בינה מלאכותית היא אמינה. המדדים המרכזיים צריכים למדוד את המעבר מ"סימן" ל"הוכחה", את עמידות הממצאים בבדיקה, ואת העלות של מעבר זה. אלה הם המשתנים שמגלים אם תהליך העבודה אכן לומד. (csrc.nist.gov)
| מטרי | איך זה נראה | איך זה נראה | מדוע זה חשוב |
|---|---|---|---|
| שיעור ההמרה של מועמדים למשתמשים מאומתים | נמוך יותר, אך יציב וניתן להסבר | הציונים גבוהים על הנייר משום שהמועמדים זוכים לציונים גבוהים מדי | מציין אם שערי הראיות הם אמיתיים |
| הזמן הממוצע עד להופעת התופעה שוב | כצפוי, יש מחסור בשיעורים שניתן לחזור עליהם | ארוך ומבולגן, למרות הדגמות מרשימות | מודד את התועלת התפעולית |
| דקות עבודה של בודק לכל ממצא שקיבל קידום | ירידה לאורך זמן | הנטל הסמוי של הניקוי המוטל על האנליסטים | מציין אם ה-AI דוחס את העבודה או מייצא אותה |
| שיעור ההצלחה בבחינה חוזרת לאחר תיקון הליקויים | גבוה ומבוסס היטב | הממצאים נעלמים בתוך הצבר הדיווחים | מציין אם המשלוח סוגר את המעגל |
| פירוט הוצאות לפי שלב | רוב המאמצים מתמקדים בשלבים הקשים | רוב הכסף מבוזבז בשלבים קלים | מציין אם מדיניות הניתוב תקינה |
| נתח שוק של פתרונות לוגיקה עסקית | עלייה ככל ששיטות הבדיקה המבוססות על מצב משתפרות | קרוב לאפס, מכיוון שתהליך העבודה לא יוצא ממצב הסורק | מציין אם המערכת מסוגלת להתמודד עם סיכונים אמיתיים ביישום |
לפיכך, השאלה החשובה ביותר בבחירת מוצר בשנת 2026 אינה "באיזה מודל אתם משתמשים?", אלא "כיצד המערכת שלכם הופכת אות גולמי לממצא מאומת, ואילו תוצרים קיימים בכל שלב?" שאלה חשובה נוספת היא "היכן אתם משקיעים את תקציב ההסקת המסקנות היקר שלכם?" אם ספק אינו יכול לענות על אף אחת מהשאלות הללו באופן ספציפי, סביר להניח שיש לו סיפור על מודל, ולא תהליך עבודה של בדיקות חדירה. זה לא הופך את המוצר לחסר תועלת. זה רק אומר שלא כדאי לקנות אותו כאילו הוא פותר את הבעיה הקשה יותר. (csrc.nist.gov)
בדיקת חדירות מבוססת בינה מלאכותית לאחר Mythos פירושה ניתוב, ולא פולחן
למיתוס יש חשיבות. החומרים שפרסמה Anthropic לא מאפשרים להתעלם מכך בכנות. נראה שהמודל הרחיב באופן משמעותי את הגבולות בתחום ניצול פרצות באופן אוטונומי, ו"פרויקט Glasswing" אינו הודעה שולית. Anthropic אומרת שהיוזמה כוללת שותפים מרכזיים להשקה, מעל 40 ארגונים נוספים, התחייבויות גדולות לזיכויי שימוש, ותוכנית מפורשת לחקור כיצד נוהלי האבטחה צריכים להתפתח בתגובה. זה לא אות משחק. זהו סימן לכך שהמעבדות המובילות מאמינות שאבטחת סייבר הפכה לאחד התחומים החשובים ביותר בעולם האמיתי עבור מודלים סוכניים מתקדמים. (anthropic.com)
AISLE חשובה מסיבה הפוכה אך לא פחות חשובה. היא מאלצת את התחום להפסיק לתאר את אבטחת ה-AI כאילו כל היכולות מגיעות בגוש אחד בלתי ניתן לחלוקה. תוצאותיה מצביעות על כך שחלקים משמעותיים מהתהליך כבר נגישים למודלים קטנים וזולים יותר, במיוחד לאחר שצמצמו את נתיב הקוד הרלוונטי או את ההקשר היעד. כמו כן, היא מגדירה מחדש את המושג "הצלחה" במונחים של קבלת המפתחים, תיקון מהימן ותכנון ברמת המערכת. זה קרוב יותר למה שצוותי האבטחה באמת צריכים מאשר כל טבלת דירוג מופשטת של "המודל הסייבר הטוב ביותר". (מעבר)
הסינתזה הנכונה אינה פשרה לשמה. היא חדה יותר מכך. מודלים מתקדמים הופכים לחשובים ביותר בראש הערימה, במיוחד ליצירת ניצולים תחת אילוצים ולהסקת מסקנות לטווח ארוך. אך החפיר האמיתי בבדיקות חדירה של בינה מלאכותית אינו המודל הגדול ביותר כשלעצמו. זהו המסלול הקצר ביותר והאמין ביותר מהאות ועד ההוכחה. מסלול זה נבנה מבקרת היקף, צמצום הקשר, ניתוב מודלים, מאמתים, שימור תוצרים, משמעת בדיקה חוזרת, ומסירה שמהנדס אחר יכול לאמת. אם בונים מסלול זה היטב, מודלים קטנים יותר הופכים להיות בעלי עוצמה מפתיעה. אם בונים אותו בצורה גרועה, אפילו המודל הטוב ביותר בעולם ייתן לכם בעיקר פרוזה יקרה. (אדום אנתרופי)
עבור צוותים שבונים או רוכשים בתחום זה, זהו הלקח האמיתי שיש להפיק מתקופת "Mythos". אל תשאלו רק מי בעל האינטליגנציה הגבוהה ביותר. שאלו מי יודע היכן להשקיע אותה, היכן להגביל אותה וכיצד להוכיח אותה. בשנת 2026, זה מה שמבדיל בין הדגמת אבטחה מרשימה לבין תהליך עבודה בתחום האבטחה שניתן ליישם בפועל בתוך ארגון הנדסי. (csrc.nist.gov)
לקריאה נוספת
- Anthropic, פרויקט Glasswing. (anthropic.com)
- צוות "אנתרופיק פרונטיר" (Red Team), הצצה ל"קלוד מיטוס". (אדום אנתרופי)
- AISLE, אבטחת סייבר מלאכותית לאחר "Mythos", "The Jagged Frontier". (מעבר)
- מיקרוסופט, מבחן הביצועים CTI-REALM ועבודת אבטחת ה-AI של MSRC. (מיקרוסופט)
- NIST SP 800-115, מדריך טכני לבדיקה והערכה של אבטחת מידע. (csrc.nist.gov)
- מדריך OWASP לבדיקות אבטחת אתרים. (owasp.org)
- עשרת האיומים המובילים בתחום אבטחת ממשקי API של OWASP לשנת 2023. (owasp.org)
- הודעת אבטחה של FreeBSD בנוגע ל-CVE-2026-4747. (פרויקט FreeBSD)
- דף הבית של Penligent. (penligent.ai)
- Penligent, כלי בדיקת חדירות מבוסס בינה מלאכותית: איך תיראה תקיפה אוטומטית אמיתית בשנת 2026. (penligent.ai)
- פנליג'נט, בודק חדירות מבוסס בינה מלאכותית בשנת 2026. (penligent.ai)
- Penligent, המדריך המקיף לבדיקות חדירה מבוססות בינה מלאכותית לשנת 2026. (penligent.ai)