חברת Anthropic לא הציגה את "Claude Mythos Preview" כעוד גרסה מצטברת של המודל. היא תיארה את המודל כאירוע אבטחת סייבר חמור דיו כדי למנוע את הפצתו לקהל הרחב, להגביל את השימוש בו לתוכנית הגנתית הפועלת בהזמנה בלבד, ולשלב אותו עם מדיניות גילוי חדשה המבוססת על איתור פגיעויות בקנה מידה של מכונות. על פי התיעוד של Anthropic עצמה, Mythos Preview הוא מודל חלוצי, רב-תכליתי ובלתי-מופץ, הזמין רק כתצוגה מקדימה למחקר מוגבל עבור עבודת אבטחת סייבר הגנתית במסגרת Project Glasswing, ללא אפשרות להרשמה עצמית. (אנתרופי)
למסגור הזה יש חשיבות מכיוון שהוא משנה את השאלה המובנית. השאלה כבר אינה האם מודלים פורצי דרך יכולים לסייע בעבודת האבטחה. התיעוד הציבורי של Anthropic כבר עונה על כך. השאלה האמיתית היא איזה סוג של עבודת אבטחה חצה את הקו מ"הדגמה מעבדתית מעניינת" ל"יכולת המשבשת את הפעילות", ואילו חלקים מהשיח הציבורי הקדימו את מה שאנשים מבחוץ יכולים לאמת באופן עצמאי. Anthropic טוענת ש-Mythos Preview מצאה וניצלה פרצות יום אפס בכל מערכות ההפעלה הגדולות ובכל דפדפני האינטרנט הגדולים, תוך שהיא מדווחת כי יותר מ-99 אחוזים מממצאיה נותרים חסויים מכיוון שעדיין לא תוקנו. השילוב הזה הוא בדיוק הסיבה שבגללה הרגע הזה מרגיש שונה: טענות היכולת הן גדולות, אך מערך ההוכחות הציבורי קטן בכוונה. (red.anthropic.com)
הפרשנות הנכונה אינה שאננה ואינה נמהרת. ה-Claude Mythos Preview אינו מוכיח בפומבי כי הבינה המלאכותית פתרה כל צורה של בדיקות חדירה מסוג "קופסה שחורה" הפונות לאינטרנט. עם זאת, הוא מספק את הראיות הציבוריות החזקות ביותר עד כה לכך שמחקר פגיעות באמצעות בינה מלאכותית, פיתוח ניצולים והפיכתם לנשק מסוג N-day מתקדמים בקצב מהיר מספיק כדי לאלץ שינויים בחלונות הזמן לתיקונים, בתהליכי הגילוי ובתהליכי האימות. "עידן ה-zero-day החדש" אינו סיסמה. זהו שינוי בקצב. (red.anthropic.com)
המאמר "Claude Mythos Preview" משנה את נטל ההוכחה במחקר על פגיעות בבינה מלאכותית
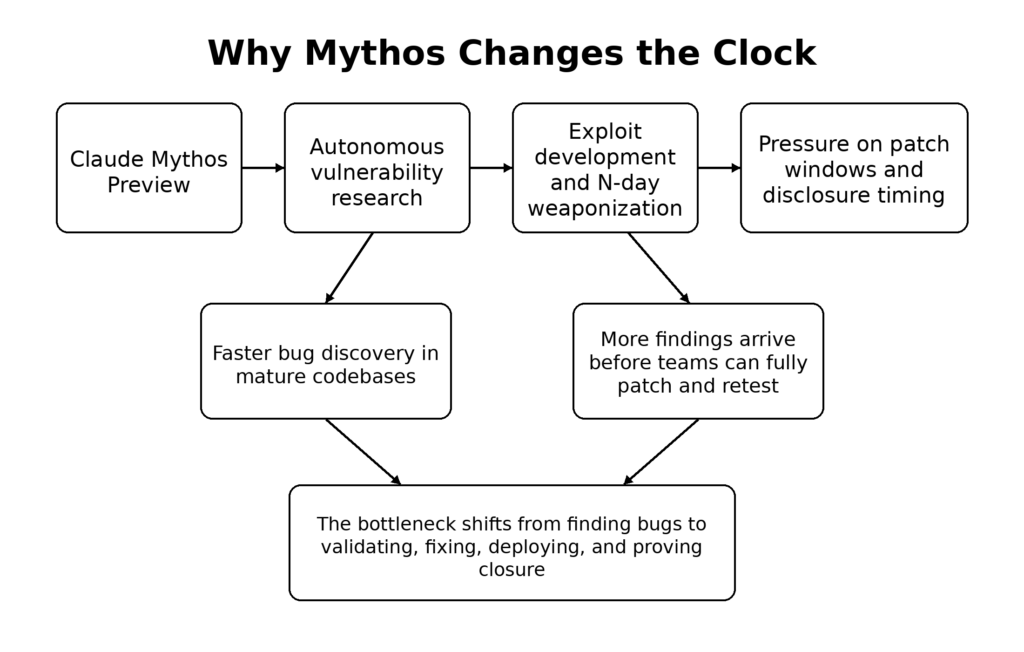
במאמר הטכני המרכזי של Anthropic מופיעות ארבע טענות שמהנדסי אבטחה צריכים להתייחס אליהן כאל מוקד העניין. ראשית, Mythos Preview הוא מודל לשימוש כללי, שיכולות האבטחה שלו נובעות מהתקדמות רחבה יותר בתחומי הקוד, ההיגיון והאוטונומיה הסוכנתית, ולא מהכשרה מצומצמת המיועדת ספציפית לניצול פרצות. שנית, Anthropic טוענת כי יכולות אלה כוללות כעת גילוי פרצות "יום אפס" (zero-day) עם חשיפת הקוד המקור, בניית ניצולים, הנדסה לאחור של קבצים בינאריים שעברו ניקוי, והמרת פגיעויות ידועות לניצולים פעילים. שלישית, Anthropic מציינת במפורש כי יכולות אלה יוצרות תקופת מעבר שבה התוקפים עשויים להרוויח יותר מהמגנים אם נוהלי השחרור לא ישתנו. רביעית, החברה פועלת על פי מסקנה זו על ידי הגבלת הגישה והקמת פרויקט Glasswing סביב מפעילי תוכנה קריטית מרכזיים. (red.anthropic.com)
שילוב זה הוא חדש בתחום הפרסומים הציבוריים בנושא אבטחת בינה מלאכותית. חומרים קודמים של Anthropic בנוגע ל-Mozilla ו-Firefox כבר הוכיחו ש-Claude Opus 4.6 מסוגל לזהות באגים חדשים בבסיס הקוד של דפדפן מרכזי, להגיש 112 דיווחים ייחודיים ולסייע בקידום תיקונים ב-Firefox 148. Anthropic פרסמה גם תוצאות ניצול מוגבלות בקפידה עבור Opus 4.6: מתוך כמה מאות ניסיונות וכ-$4,000 נקודות זכות API, המודל הצליח להפוך באגים ב-Firefox לניצולים מתפקדים רק פעמיים, ואפילו אלה עבדו רק בסביבת בדיקה שהוחלשה בכוונה. התיעוד הציבורי הזה אמר למגינים משהו חשוב אך עדיין מוגבל למדי: איתור באגים באמצעות בינה מלאכותית הפך לרמה עולמית מהר יותר מפיתוח ניצולים באמצעות בינה מלאכותית. (אנתרופי)
גרסת ה-Mythos Preview משנה את האיזון הזה. חברת Anthropic טוענת שכאשר ביצעה מחדש את מבחן הביצועים של ניצול הפגיעות ב-Firefox עם גרסת ה-Mythos Preview, המודל יצר ניצולי פגיעות תקינים 181 פעמים והגיע לשליטה ברשומות ב-29 מקרים נוספים. בבדיקת הביצועים הפנימית שלה בסגנון OSS-Fuzz, Anthropic טוענת ש-Sonnet 4.6 ו-Opus 4.6 הגיעו לרוב לרמות קריסה בדרגת חומרה נמוכה, בעוד ש-Mythos Preview הגיע לחטיפת זרימת בקרה מלאה בעשרה יעדים שעברו תיקון מלא. אלה לא רק מספרים גדולים יותר. הם מרמזים כי פיתוח ניצולים כבר אינו החלק המפגר בבירור בתהליך. (red.anthropic.com)
דו"ח הסיכונים של Anthropic מוסיף רובד נוסף שקל לפספס בכותרות. הדו"ח הציבורי, שעברו בו צנזורה, מציין כי Mythos Preview נראה כמודל המתאים ביותר לצרכים שהשיקה Anthropic, אך גם מציין כי הוא בעל יכולות גבוהות משמעותית, אוטונומי יותר, וחזק במיוחד במשימות הנדסת תוכנה ואבטחת סייבר. באותו דוח נכתב כי Anthropic זיהתה שגיאות בתהליכי ההכשרה, הניטור, ההערכה והאבטחה במהלך פיתוח Mythos, ומסיקה כי הסיכון הכולל הוא "נמוך מאוד, אך גבוה יותר מאשר במודלים קודמים". זוהי אינדיקציה לניהול כמו גם לאיכות הבטיחות. מערכות בעלות יכולות גבוהות יותר עשויות להתנהג טוב יותר בממוצע, אך עדיין ליצור סיכון תפעולי גבוה יותר, מכיוון שהן מופקדות על משימות קשות יותר, מקבלות אפשרויות פעולה רחבות יותר, ומסוגלות לעקוף מכשולים בצורה טובה יותר. (אנתרופי)
פרויקט Glasswing והסיבה שבגללה Anthropic לא פתחה את Mythos Preview לקהל הרחב
פרויקט Glasswing אינו עניין שולי. זוהי התגובה המדינית להערכת היכולות שביצעה Anthropic. בהודעה הרשמית של Anthropic נכתב כי הפרויקט מאגד את Amazon Web Services, Anthropic, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, קרן לינוקס, Microsoft, NVIDIA ו-Palo Alto Networks במטרה לאבטח תוכנות קריטיות. Anthropic אומרת שהקימה את הפרויקט כי Mythos Preview חשף עובדה חדה: מודלי AI הגיעו לרמת יכולת קידוד שבה הם יכולים לעלות על כל בני האדם, למעט המיומנים ביותר, באיתור וניצול פגיעויות בתוכנה. (אנתרופי)
הצהרה זו חזקה יותר מהטענה הרגילה שלפיה "בינה מלאכותית יכולה לסייע באבטחת אפליקציות". היא מציינת שהמודל אינו רק עוזר לבדיקת קוד, למיון או לניסוח תיקונים. היא קובעת שהמודל ראוי להיכלל באותה שיחה עם חוקרי פגיעות מהשורה הראשונה. התיעוד הרשמי של הפלטפורמה מחזק את העובדה ש-Anthropic מתייחסת לכך כאל תצוגה מקדימה של מחקר מבוקר בקפדנות, המיועדת אך ורק לתהליכי עבודה הגנתיים בתחום אבטחת הסייבר, ללא גישה לשירות עצמי. זה יוצא דופן כשלעצמו, אך מה שבאמת חשוב הוא ההיגיון התפעולי שעומד מאחוריו: אם מודל יכול לדחוס את מחקר הניצול, אזי ניהול השחרור וניהול הגילוי הופכים לפונקציות אבטחה, ולא רק לפונקציות מוצר. (אנתרופי)
מדיניות הגילוי המתואם של פגיעויות של Anthropic מפרטת את ההיגיון הזה במפורש. החברה מציינת כי היא שואפת לעמוד בלוח זמנים של 90 יום לגילוי, להעביר את הטיפול לרכז חיצוני כאשר צוות התחזוקה אינו מגיב תוך 30 יום, לשאוף לחלון זמן של שבעה ימים לתיקון או למיתון פגיעויות קריטיות המנוצלות באופן פעיל, ובאופן כללי להמתין 45 יום לאחר שהתיקון זמין לפני פרסום הפרטים הטכניים המלאים. לוחות הזמנים הללו מוכרים לכל מי שחווה גילוי מתואם רגיל, אך ההבדל כאן הוא בהיקף ובקצב המשוערים. Anthropic מציינת כי הדוחות נבדקים על ידי בני אדם, ממצאים שמקורם ב-AI מסומנים ככאלה, והיקף ההגשות לפרויקט צריך להיות מותאם לקצב שבו צוות התחזוקה יכול לקלוט אותן. זה לא רק עניין של היגיינה תהליכית. זו הודאה בכך ש-AI יכולה לייצר יותר תוצאות פגיעות ממה שתהליכי העבודה המסורתיים של צוות התחזוקה תוכננו לקלוט. (אנתרופי)
זהו המקום שבו "עידן ה-zero-day" הופך למציאות מעשית ולא רק לרטוריקה. אם קצב הגילוי הממוחשב עולה על קצב הסינון של הספקים ועל פריסת התיקונים בהמשך התהליך, אזי הגורם המגביל באבטחה כבר אינו כישרון הגילוי הגולמי, אלא התפוקה הארגונית. הצוותים שיסתגלו במהירות הרבה ביותר לא יהיו אלה עם ההדגמה המרשימה ביותר. אלה יהיו הצוותים שיוכלו לקבל החלטות, לאמת, לתקן, לבדוק מחדש ולפרוס מחדש מהר יותר מהקצב שבו מצטברים הממצאים החדשים. (red.anthropic.com)
מה שהתיעוד הציבורי מוכיח כיום, ומה שהוא אינו מוכיח

הדרך הברורה ביותר להתייחס ל-"Mythos Preview" היא לחלק את המידע הציבורי לשלוש קטגוריות: מקרים שניתן לאמת באופן עצמאי, מקרים המפורטים מבחינה טכנית אך נכתבו על ידי הספקים, וטענות כלליות שהראיות המפורטות לגביהן נותרות חסויות מכיוון שהתיקונים עדיין אינם מוכנים. בפוסט של Anthropic עצמה נכתב כי למעלה מ-99 אחוזים מהפגיעויות שהיא מצאה טרם תוקנו, ולכן לא ניתן לחשוף אותן באופן אחראי. עובדה זו לבדה מסבירה את מרבית הבלבול סביב ההשקה. השיח הציבורי מתייחס לכל הטענות כאל מידע גלוי באותה מידה, אך הן אינן כאלה. (red.anthropic.com)
| תחום יכולות | ראיות פומביות | מה שאנשים מבחוץ יכולים לאמת כיום | מה שנשאר ברובו פרטי |
|---|---|---|---|
| גילוי פרצות יום אפס בקוד פתוח | Anthropic פרסמה דוגמאות מפורטות של תיקונים ב-OpenBSD, FFmpeg ו-FreeBSD, וכן ממצאים נוספים שלא צוינו בשמם. (red.anthropic.com) | התיקונים OpenBSD errata 025 ו-FreeBSD SA-26:08 פורסמו; FFmpeg 8.1 פורסם; קיימים תיקונים ספציפיים ומסמכי אזהרה. (openbsd.org) | רוב הממצאים הנותרים אינם מתפרסמים משום שלא תוקנו. (red.anthropic.com) |
| פיתוח פרצות אבטחה באופן אוטונומי | Anthropic פרסמה פרטים על ניצול פגיעות ב-FreeBSD, תיאורים של ניצולי N-day ב-Linux, ושיפורים בביצועים בהשוואה ל-Opus 4.6. (red.anthropic.com) | נתוני הביצועים והתיאורים של ניצול הפגיעות פתוחים לעיון הציבור, אך כדי לשחזר אותם נדרשים אותם באגים, אותן סביבות בדיקה ואותן סביבות עבודה. (red.anthropic.com) | שרשראות ניצול רבות של דפדפנים ומערכות הפעלה עדיין נתונות לאיסור פרסום. (red.anthropic.com) |
| הנדסה לאחור של קבצים בינאריים שעברו ניקוי | לדברי Anthropic, Mythos משחזר קוד מקור סביר מקבצים בינאריים שעברו ניקוי, ולאחר מכן מנתח את הקוד המשוחזר יחד עם הקובץ הבינארי המקורי. (red.anthropic.com) | המתודולוגיה פתוחה לציבור. לעומת זאת, היעדים והתוצאות הבסיסיים, שהם בקוד סגור, אינם פתוחים לציבור ברובם. (red.anthropic.com) | רוב החומר בתיק נותר חסוי. (red.anthropic.com) |
| פגיעויות בלוגיקת יישומים אינטרנטיים | Anthropic מפרטת בפומבי קטגוריות כגון עקיפת אימות, עקיפת כניסה והתקפות DoS הרסניות. (red.anthropic.com) | הראיות ברמת הקטגוריה הן פומביות. מחקרי המקרה המפורטים אינם פומביים. (red.anthropic.com) | ההוכחות הפומביות לבדיקות חדירה לאתרי אינטרנט הפונים לרשת, המתבצעות בשיטת "הקופסה השחורה", נותרות מוגבלות. (penligent.ai) |
| בקרות שחרור וממשל | פרויקט Glasswing, הגישה המוגבלת למוזמנים בלבד ומדיניות ה-CVD הייעודית פורסמו ברבים. (אנתרופי) | תנוחת השחרור נראית במלואה. | הסף הפנימי המדויק שהוביל לנקודת המבט הזו ניכר רק בחלקו מתוך דוח הסיכונים שעברו בו השחורות. (אנתרופי) |
ההגזמה הנפוצה ביותר בדיונים סביב Mythos היא איחוד הקטגוריות הללו לקטגוריה אחת. חברת Anthropic פרסמה ראיות חזקות במיוחד לגילוי פגיעות תוך צפייה בקוד המקור, וכן ראיות הולכות ומתחזקות לבניית ניצולים. היא לא פרסמה מקרה ציבורי שניתן לשחזר, המראה את Mythos מבצע באופן אוטונומי את מחזור הבדיקות המלא של יישום אינטרנט מסוג "קופסה שחורה" כנגד יעד אינטרנטי פעיל, הכולל את סוגי המצב המורכב, הזהויות, מגבלות הקצב, בקרות המפצות והמוזרויות הסביבתיות המגדירות בדיקות חדירה ליישומים אמיתיים. תיאור המסגרת של Anthropic עצמה מציין כי הפרויקט הנבדק וקוד המקור שלו ממוקמים במכולה מבודדת. בסעיף ההנדסה לאחור שלה נכתב כי קוד המקור המשוחזר והבינארי המקורי מסופקים במצב לא מקוון. זוהי יכולת אמיתית וחשובה, אך היא אינה זהה להוכחה ציבורית של אוטומציה אוניברסלית של בדיקות חדירה מסוג "קופסה שחורה". (red.anthropic.com)
ההבחנה הזו חשובה משום שקונים, צוותי "רד טים" ומנהלי אבטחה זקוקים לאוצר מילים אחיד. מחקר פגיעות ב-AI בשיטת "תיבת הלבן" הוא כבר בעל חשיבות אסטרטגית. אימות בקנה מידה אינטרנטי בשיטת "תיבת השחור" הוא עניין אחר. בלבול בין השניים מוביל לרכש לא נבון, לציפיות לא מציאותיות ולסדר עדיפויות הנדסי שגוי. המסקנה הנכונה אינה ש-Mythos זוכה לפרסום מוגזם. המסקנה הנכונה היא שההאצה במחקר הפגיעות היא דבר מוחשי ביותר, בעוד שחלק מהפרשנויות הרחבות ביותר בתחום אבטחת היישומים עדיין מקדימות את הראיות הציבוריות. (red.anthropic.com)
למתודולוגיה של Anthropic יש חשיבות לא פחותה מהתוצאות
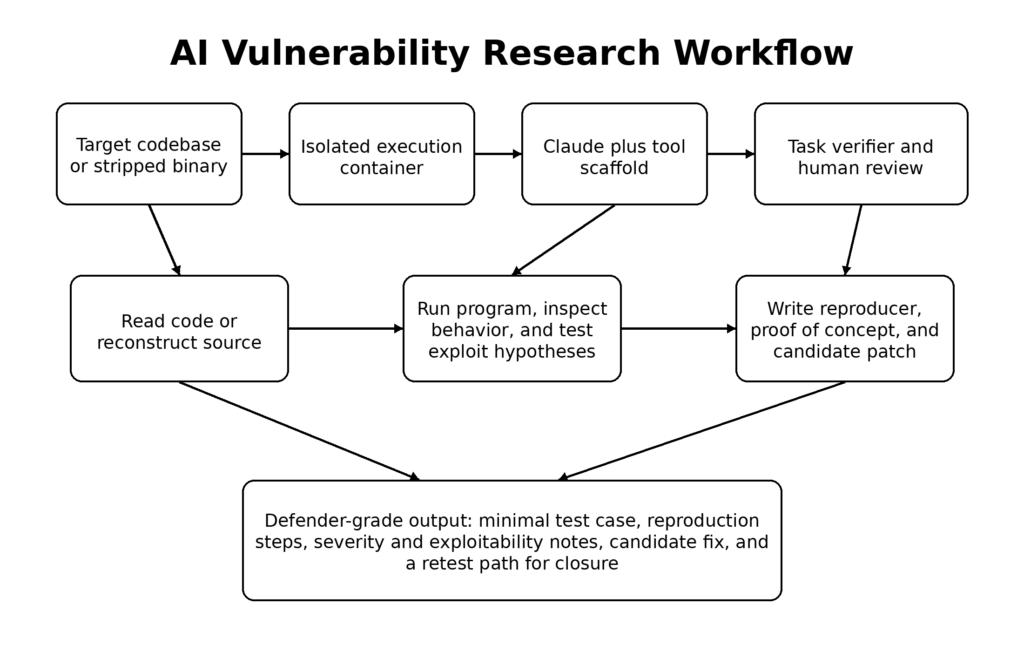
אחת הסיבות שבגללן Mythos ראוי לתשומת לב רצינית היא ש-Anthropic לא הציגה את תוצאותיה כקסם מסתורי. החברה הקדישה חלק משמעותי מהמאמר למתודולוגיה, ודווקא לפרטים המתודולוגיים הללו צריכים המפתחים להקדיש את תשומת לבם. Anthropic אומרת שבחרה להתמקד קודם כל בפגיעויות בטיחות הזיכרון מסיבות פרגמטיות: הן נפוצות, חמורות, וקל יחסית לאמת אותן בעזרת כלים כמו AddressSanitizer. המאמר גם מציין שלצוות המחקר היה ניסיון מספיק בניצול פגיעויות כדי לאמת את הממצאים ביעילות. זו נקודה שקטה אך מכרעת. מחקר פגיעויות ב-AI לא מבטל את הצורך באימות על ידי מומחים. הוא משנה את המיקום של המומחיות בתוך התהליך. (red.anthropic.com)
המסגרת שאנתרופיק מתארת גם היא מעניינת. החברה מציינת כי היא מפעילה קונטיינר מבודד הכולל את הפרויקט הנבדק ואת קוד המקור שלו, מפעילה את Claude Code עם Mythos Preview, ומנחה אותו ברמה גבוהה לאתר פרצת אבטחה. לאחר מכן, Claude קורא את הקוד, מגבש השערות, מריץ את התוכנית, מאשר או שולל חשדות, מוסיף לוגיקת ניפוי באגים או משתמש במנפיקי באגים, ובסופו של דבר מוציא תוצאה של "אין באג" או דוח באגים עם הוכחת היתכנות ושלבי שחזור. זרימת העבודה הזו נראית פחות כמו צ'אט-בוט ויותר כמו חוקר פגיעות מתחיל עד בינוני עם סבלנות אינסופית, מעבר מהיר בין הקשרים ונכונות להמשיך לנסות. (red.anthropic.com)
שיתוף הפעולה עם Mozilla מספק דוגמה מוקדמת ומועילה לאופן שבו מערכת מסוג זה הופכת לשימושית במקום למטרד. חברת Anthropic טוענת כי Claude Opus 4.6 איתר פגיעות מסוג Use After Free במנוע ה-JavaScript של Firefox לאחר כעשרים דקות של בדיקה, ולאחר מכן חוקרים אימתו את הבאג באופן עצמאי והגישו אותו יחד עם תיקון מוצע. לאחר מכן, Mozilla סייעה בעיצוב תהליך הדיווח ועודדה הגשה מרוכזת של מקרי בדיקה הגורמים לקריסת המערכת. התיאור של Anthropic על העבודה הזו מדגיש שלושה מרכיבים בבנייה של אמון בהגשות: מקרי בדיקה מינימליים, הוכחות קונספט מפורטות ותיקונים מועמדים. אלה אינם קוסמטיים. הם המרכיבים המדויקים שמאפשרים למנהלי המערכת להמיר את פלט המודל לפעולה הנדסית. (אנתרופי)
Anthropic מייחסת חשיבות רבה גם למה שהיא מכנה "בודקי משימות". במאמר שפורסם ב-Mozilla, היא טוענת כי מודלים משיגים ביצועים מיטביים כאשר הם יכולים לבדוק את עבודתם מול סימנים מהימנים, הן לצורך אימות הבאג המקורי והן לצורך אימות התיקונים המוצעים מול רגרסיות. לקח זה תקף הרבה מעבר ל-Firefox. צוות אבטחה שמשלב מודל במאגר קוד ללא שכבת בדיקה חזקה, בונה למעשה צינור הזיות יקר. צוות שמספק למודל "אורקל קריסה" אמין, מערך בדיקות, סוויטת רגרסיה וסביבת ביצוע מבוקרת, בונה משהו שקרוב הרבה יותר לכלי הנדסי. (אנתרופי)
OpenBSD והערך שבאיתור באג ישן במערכת קשה
המקרה של OpenBSD בחברת Anthropic הוא מסוג הדוגמאות שאנשי אבטחה נוטים להיאחז בהן, משום שהוא קונקרטי ובעל משמעות סמלית כאחד. חברת Anthropic טוענת כי Mythos Preview איתרה באג בן 27 שנים בטיפול של OpenBSD באישור סלקטיבי של TCP (TCP Selective Acknowledgment), אשר תוקן בינתיים. ה-errata הרשמי של OpenBSD 7.8 מאשר כי תיקון 025, מתאריך 25 במרץ 2026, טיפל במצב שבו מנות TCP עם אפשרויות SACK לא חוקיות עלולות היו לגרום לקריסת הקרנל. תוצר התיקון המקביל מראה כי התיקון הוסיף בדיקת גבול תחתון על sack.start ביחס ל- snd_una וגם שמר על נתיב נספח באמצעות p != NULL. (openbsd.org)
ההסבר הטכני של Anthropic ממחיש מדוע הבאג הזה מעניין. על פי התיאור, OpenBSD עקבה אחר מצב ה-SACK כרשימה מקושרת של "חורים". קצה טווח שאושר נבדק מול חלון השידור, אך לא תחילתו. מצב זה יצר מסלול לוגי שבו בלוק SACK בודד יכול היה למחוק את ה"חור" היחיד ברשימה וגם לנסות להוסיף "חור" חדש, ובסופו של דבר לכתוב דרך מצביע null. Anthropic מסבירה עוד כי מעגל מספר הרצף של TCP והשוואות חתומות הפכו מצב שנראה בלתי אפשרי לבר-השגה. בין אם הקורא מסכים עם כל פרט פרשני בהסבר של Anthropic ובין אם לאו, התיקון הציבורי והתיקון הרשמי מבהירים כי סוג הבאג היה אמיתי והתיקון לא היה קוסמטי. (red.anthropic.com)
הדוגמה של OpenBSD חשובה משלוש סיבות. ראשית, היא מראה שהוכחה פומבית לא חייבת לבוא לידי ביטוי כ-RCE נוצץ או כ-CVE שמככב בכותרות. OpenBSD הגדירה זאת כתיקון אמינות, אך קריסת קרנל הניתנת להפעלה מרחוק היא עדיין בעיה אבטחתית בעלת השפעה תפעולית ממשית. שנית, היא מדגימה את סוג ההנמקה של תנאי גבול שהמודלים מתחילים לבצע היטב: מכונות מצבים, מקרי קצה אריתמטיים, הנחות סנטינל וענפים של "זה אמור להיות בלתי נגיש". שלישית, היא מדגישה את האופן שבו ה-AI משנה את כלכלת החיפוש. Anthropic טוענת כי מצאה את הבאג ב-OpenBSD לאחר כאלף הרצות של סקאפלד, בעלות כוללת של פחות מ-$20,000, תוך שהיא מוצאת גם עשרות בעיות נוספות, ומציינת כי עלות ההרצה המוצלחת הספציפית הייתה פחות מ-$50 רק בדיעבד. זה אינו הוכחה לכך שציד באגים מסוג "יום אפס" הפך לפתע לזול במובן הכללי, אך זוהי עדות חזקה לכך שחלקים מתהליך החיפוש הופכים להיות מקבילים הרבה יותר. (red.anthropic.com)
להלן סקיצה פשוטה של קוד מדומה הגנתי, המציגה את סוג הלוגיקה הגבולית הרלוונטית בעיבוד SACK:
if (sack.end > snd_max) ignore(); if (sack.start < snd_una) ignore(); // תיקון של OpenBSD הוסיף בדיקה כזו walk_hole_list(); delete_or_shrink_holes();
if (last_hole != NULL && rcv_lastsack < sack.start) append_new_hole();
הנקודה היא לא שהמגנים צריכים לשנן באג אחד של OpenBSD. הנקודה היא שמערכות בינה מלאכותית כבר מספיק טובות כדי להמשיך ולבחון את הלוגיקה של גבולות מצב, שאליהן תוכנות פוזר לא תמיד מצליחות להגיע ובני אדם עלולים שלא לחזור אליהן במשך שנים. זה משנה את מידת האמון שצוותים יכולים לתת ברעיון שבסיס קוד בוגר כבר "נבדק מספיק". (ftp.openbsd.org)
FFmpeg ומדוע מקרי קצה סמנטיים חשובים יותר ממספר הקריסות
מקרה FFmpeg מהווה אזהרה מסוג אחר. Anthropic טוענת ש-Mythos Preview מצאה פגיעות בת 16 שנים בקודק H.264 של FFmpeg. ההסבר של החברה מתמקד באופן שבו FFmpeg עוקבת אחר איזה סלייס (slice) מחזיק בכל מקרובלוק (macroblock) בפריים. Anthropic טוענת שהרשומות בטבלה הן מספרים שלמים של 16 סיביות, מונה הסלייס הוא מספר שלם של 32 סיביות ללא גבול עליון, והטבלה מותחלת עם memset(..., -1, ...), ועוזב 65535 כמשמר עבור "ללא בעלים". אם תוקף מייצר מסגרת עם 65,536 פרוסות, מספר הפרוסה 65535 מתנגש עם ה-sentinel, והמפענח עלול להסיק ששכן שאינו קיים שייך לאותו פרוסה, מה שמוביל לכתיבה מחוץ לגבולות הזיכרון ולקריסת המערכת. חברת Anthropic טוענת שההנחה הבסיסית בנוגע ל-sentinel מקורה בהשקת תקן H.264 בשנת 2003, והפכה לפגיעה לאחר שינוי מבני שבוצע בשנת 2010, אשר עדיין בא לידי ביטוי בהיסטוריית הפרויקט. (red.anthropic.com)
דוגמה זו מועילה דווקא משום ש-Anthropic אינה מגזימה בתיאוריה. החברה מציינת במפורש כי הבאג אינו חמור במיוחד, וככל הנראה יהיה קשה להפוך אותו לניצול פעיל. איפוק זה הוא חשוב. בדיונים רבים מדי בנושא אבטחת בינה מלאכותית מתייחסים לכל באג זיכרון שהתגלה כאילו הוא נמצא במרחק גאדג'ט אחד בלבד מפגיעה מוחלטת. הלקח הטוב יותר הוא עדין יותר: מודלים מתחילים להסיק מסקנות יעילות לגבי אי-שינויים סמנטיים, ערכי סנטינל, רוחבי טיפוס ומבני קלט נדירים אך תקפים, שה-fuzzing המסורתי עלול לדגום באופן חלקי. סוג כזה של הסקת מסקנות מרחיב את מרחב החיפוש לגילוי פגיעות, גם כאשר הבאג המתקבל אינו ניתן לניצול בקלות. (red.anthropic.com)
FFmpeg מספקת גם נקודת אחיזה תפעולית לאנשי האבטחה. חברת Anthropic מציינת כי שלוש פגיעויות ב-FFmpeg שזוהו על ידי Mythos תוקנו ב-FFmpeg 8.1, והאתר הרשמי של FFmpeg מאשר כי גרסה 8.1 "Hoare" שוחררה ב-16 במרץ 2026. זהו סוג הקשר שצוותי האבטחה צריכים לדאוג לו כעת: לא רק שמודל מצא באג, אלא האם ניתן לעקוב אחר הממצא במסלול השחרור, האם הצרכנים במורד הזרם יודעים שהם צריכים לעדכן, והאם מנהלי החבילות וצוותי המוצר ערוכים לקלוט את נפח החשיפות המסייעות ב-AI. (red.anthropic.com)
| תיק "מיטוס" הציבורי | מדוע זה חשוב מבחינה טכנית | מה על המגנים ללמוד |
|---|---|---|
| OpenBSD SACK | לוגיקת פרוטוקולים עם שמירת מצב, חישובים בקצה הרשת, תחזוקת רשימות מקושרות בתנאי עקיפה. (red.anthropic.com) | ערימות רשת בוגרות עדיין מסתירות הנחות שבריריות. "לא היו קריסות לאחרונה" אינו הוכחה לבטיחות. |
| FFmpeg H.264 | התנגשויות Sentinel, אי-התאמת רוחב שלם, מבנים נדירים אך חוקיים על פי המפרט, ושימוש שגוי מבחינה סמנטית בתבניות אתחול. (red.anthropic.com) | ה-fuzzing נותר הכרחי אך אינו מספיק; ההיסק הסמלי והסמנטי הולך ומשתפר. |
| FreeBSD RPCSEC_GSS | עומס יתר קלאסי בשילוב עם בניית פרצת אבטחה במסלול שירות אמיתי הפונה לקרנל. (פרויקט FreeBSD) | הבינה המלאכותית כבר אינה מוגבלת לזיהוי תקלות; היא הופכת לרלוונטית יותר ויותר בתחום הנדסת התפעול. |
| פרצת אבטחה מסוג N-day ב-ipset של לינוקס | ניתן עדיין לשדרג פרימיטיבים של כתיבה של סיבית אחת לרמת שורש באמצעות שרשרת ניצולים סבלנית. (red.anthropic.com) | זמן התגובה לתיקונים מסוכן יותר כאשר מודלים יכולים להאיץ את פיתוח הפרצות. |
FreeBSD CVE-2026-4747 וכיצד נראית מחלוקת בנוגע לקוד פתוח
מקרה FreeBSD הוא ככל הנראה הדוגמה הציבורית החשובה ביותר של Mythos, שכן הוא המקום שבו מתלכדים גילוי פגיעות באמצעות בינה מלאכותית, בניית ניצול וחוסר הסכמה לגבי מקור הפגיעות. Anthropic טוענת ש-Mythos Preview זיהתה באופן אוטונומי לחלוטין ואז ניצלה פגיעות בת 17 שנים לביצוע קוד מרחוק בשרת ה-NFS של FreeBSD, שסווגה כ-CVE-2026-4747, ומתארת אותה ככזו המאפשרת שליטה מלאה בשרת החל ממשתמש לא מאומת בכל מקום באינטרנט. בדו"ח הטכני של Anthropic מיוחסת התקלה לנתיב RPCSEC_GSS המעתיק נתונים הנשלטים על ידי התוקף למאגר ערימה (stack buffer) של 128 בתים, ללא בדיקת אורך מספקת, מה שמאפשר התקפת ROP קונבנציונלית בתנאים נוחים במיוחד. (red.anthropic.com)
ההודעה הרשמית של FreeBSD מאשרת את עיקרי התיאור הזה, אך נוקטת בגישה זהירה יותר בכל הנוגע להשלכות. בהודעה נכתב כי כל חבילת נתונים RPCSEC_GSS מאומתת על ידי שגרה המעתיקה חלק מהחבילה למאגר ערימה מבלי לוודא שהמאגר גדול מספיק, וכי לקוח זדוני יכול לגרום לעומס יתר בערימה מבלי לעבור אימות תחילה. אך כאשר היא מתארת את ההשפעה, אותה הודעה מציינת כי ביצוע קוד מרחוק במרחב הקרנל אפשרי על ידי משתמש מאומת המסוגל לשלוח חבילות לשרת ה-NFS של הקרנל בזמן ש- kgssapi.ko הדו"ח נטען, ומציין כי שרתים מסוג RPC במרחב המשתמש המקושרים לספרייה הפגיעה ניתנים לניצול מרחוק על ידי כל לקוח המסוגל לשלוח אליהם מנות. ה-NVD מאמץ את הניסוח הזהיר יותר בנוגע להשלכות, ובזמן שפורסם בדף הציבורי, מציג ציון ADP של 8.8 (גבוה), בעוד שציון ה-NVD עצמו טרם הוזן. (פרויקט FreeBSD)
פער זה הוא בדיוק מסוג הדברים שעל אנשי אבטחה להתרגל אליהם בעידן הבינה המלאכותית. ישנן לפחות שלוש פרשנויות סבירות להבדל זה. האחת היא שהפעלת הצפת הערימה (stack overflow) אינה מאומתת, בעוד שהספק נותר שמרני לגבי התנאים הדרושים לביצוע RCE אמין בקרנל. פרשנות נוספת היא שרצף הניצול המוצלח של Anthropic הדגים מצב סופי חזק יותר ממה שהאזהרה הייתה מוכנה להכליל בעת הפרסום. הפרשנות השלישית היא שההבדל פשוט משקף את הפער הרגיל בין דוח מחקר המתמקד בתקרה הטכנית לבין הודעת אזהרה של ספק המתמקדת בהצהרות מוגבלות וניתנות לתמיכה. מה שחשוב הוא לא לבחור צדדים באופן תיאטרלי. מה שחשוב הוא לקרוא את שני המקורות בקפידה ולהתנגד לדחף לשטח אותם למשפט אחד פשטני מדי. (red.anthropic.com)
ראוי לציין גם את פרטי התיקון. בהודעת האבטחה של FreeBSD נכתב כי כל הגרסאות הנתמכות הושפעו, והיא מפרטת את הענפים שתוקנו, בהם 15.0-RELEASE-p5, 14.4-RELEASE-p1, 14.3-RELEASE-p10 ו-13.5-RELEASE-p11, לצד תיקונים בענף היציב. כמו כן נכתב כי אין פתרון זמני זמין, למעט במערכות ללא kgssapi.ko הקובצים הטעונים אינם פגיעים במסלול הליבה. זוהי דוגמה קלאסית לכך שפעולות תיקון, ולא רק מנויים על התראות אבטחה, הן שיקבעו מי יישאר מוגן בעולם שבו בינה מלאכותית יכולה לסייע בפיתוח פרצות אבטחה במהירות רבה יותר. (פרויקט FreeBSD)
תהליך עבודה מעשי לטיפול ראשוני במערכות FreeBSD נראה כך:
# זיהוי גרסאות הקרנל וסביבת המשתמש הפועלות freebsd-version -ku # בדיקה אם מודול ה-RPCSEC_GSS של הקרנל קיים kldstat | grep kgssapi
# אם אתה משתמש בחבילות בסיס sudo pkg upgrade -r FreeBSD-base # אם אתה משתמש בערכות הפצה בינאריות sudo freebsd-update fetch sudo freebsd-update install sudo shutdown -r now
הפקודות הללו אינן תחליף למשמעת תחזוקה, אך הן ממחישות את השאלה האמיתית בתחום האבטחה. בעידן ה-Mythos, השאלה "האם יש תיקון" הופכת לחלק הקל. השאלה "האם ביצעתי רישום, קביעת סדרי עדיפויות, פריסה ואימות במהירות מספקת" היא החלק הקשה. (פרויקט FreeBSD)
CVE-2024-53141 בקרנל לינוקס ומדוע "N-day" הפך למודל איום מרכזי
אם המקרה של FreeBSD מדגים פוטנציאל לניצול יום-אפס, הרי ש-Linux ipset הדוגמה ממחישה מדוע יש להעלות את רמת העדיפות של ניצול פרצות מסוג N-day בסדר העדיפויות של הגורמים המגנים. ה-NVD מתאר את CVE-2024-53141 כבעיה בקרנל לינוקס ב- bitmap_ip_uadt כאשר אי-ביצוע בדיקת טווח עלול להוביל לפגיעות מקומית בדרגת חומרה גבוהה. בדף ה-NVD מצוין ציון CVSS 3.1 של 7.8 (דרגת חומרה גבוהה), וטווחי הגרסאות המושפעות משתרעים על פני מספר ענפי ליבה. תיאור ההודעה של אובונטו משקף את אותה סיבת שורש, ומסביר שכאשר IPSET_ATTR_IP_TO אינו קיים, אך IPSET_ATTR_CIDR קיים, הערכים מעובדים באופן שמותיר פער בבדיקת הטווח ומאפשר לפגיעות להתרחש. (nvd.nist.gov)
תרומתה של Anthropic בפוסט של Mythos אינה לטעון כי היא גילתה את הבאג הזה. נכתב במפורש כי סעיף זה נוגע ל"N-day" שניתן ל-Mythos Preview. העניין היה ניצול הפגיעות. התיעוד של Anthropic מפרט כיצד אינדקס מחוץ לגבולות ב- ipset ניתן להפוך אותה לפרימיטיב כתיבה מוגבל של סיבית אחת, ולאחר מכן להגביר אותה בהדרגה באמצעות סמיכות בין דפים פיזיים, מניפולציה של PTE, ובסופו של דבר שינוי של ערך מטמון הדפים עבור /usr/bin/passwd כדי להשיג הרשאות root. בין אם כל קורא מעוניין לעקוב אחר שרשרת זו במלואה ובין אם לאו, המשמעות מבחינת האבטחה ברורה: פגיעויות מקומיות שתוקנו, שבעבר הושמו בסל ה"נגיע לזה בקרוב", הופכות למסוכנות יותר אם מודלים יכולים לצמצם את העבודה הנדרשת להנדסת ניצול כדי להפוך אותן לנשק. (red.anthropic.com)
זהו המקום שבו קטלוג הפגיעות המנוצלות הידועות (KEV) של CISA הופך לרלוונטי יותר, ולא פחות. CISA מתארת את קטלוג ה-KEV כמשאב שנועד לסייע לקהילת אבטחת הסייבר ולמגיני הרשתות לנהל את תהליך התיקון על סמך ראיות לניצול בפועל. הרעיון העומד בבסיס ה-KEV היה תמיד שלא כל ה-CVE ראויים לאותה דחיפות. יכולות מסוג Mythos אינן מבטלות את ההיגיון הזה. הן מחזקות אותו. אם הסיוע הממוחשב מקצר את הזמן שבין פרסום התיקון לניצולו, אזי על המגינים להתייחס ל"תוקן בפומבי ונגיש בסביבת שלי" כתנאי להחמרה חמורה בהרבה ממה שעשו לפני מספר שנים. (CISA)
הטעות התפעולית שארגונים רבים עדיין עושים היא למיין תורי תיקונים על סמך תוויות חומרה פומביות בלבד. זה מעולם לא היה אידיאלי, והמצב מחמיר ככל שפיתוח הניצולים מתגבר. בטווח הקצר, על הצוותים לתת עדיפות במיון לשילוב של גורמים: שטח התקפה חשוף, חציית גבולות הרשאות, פרימיטיבים של פגיעה בזיכרון, עדכניות התיקון, בהירות ה-commit הרלוונטי לניצול, וזמינות של בודקים שמאפשרים שחזור בסיוע בינה מלאכותית בעלות נמוכה. הערת תיקון ברורה בתוספת נתיב פריסה נגיש מסוכנים כעת יותר מ-CVSS שנשמע מפחיד יותר ברכיב שאף אחד לא יכול לפגוע בו. (red.anthropic.com)
הנדסה לאחור, שרשראות דפדפנים, והגבולות הציבוריים של סיפור המיתוס
הטענות הנועזות ביותר של Anthropic חורגות מהמקרים שגורמים חיצוניים יכולים לבחון באופן מלא כיום. על פי המאמר, Mythos Preview מסוגל לקחת קובץ בינארי סגור-מקור ומרוקן, לשחזר עבורו קוד מקור מתקבל על הדעת, ולאחר מכן לנתח את קוד המקור המשוחזר יחד עם הקובץ הבינארי המקורי כדי לאתר נקודות תורפה. כמו כן נטען כי המודל מצא באופן עצמאי פונקציות קריאה וכתיבה בסיסיות במספר דפדפנים, חיבר אותן ל-JIT heap sprays, ובמקרה אחד שילב ניצול דפדפן עם בריחה מסביבת הבדיקה (sandbox escape) והעלאת הרשאות מקומיות, כך שדף אינטרנט זדוני יכול היה בסופו של דבר לכתוב ישירות לליבת מערכת ההפעלה. אלה הן הצהרות יוצאות דופן. Anthropic מקפידה לגדר חלק מהן בהתחייבויות עתידיות לחשוף פרטים לאחר תיקון. (red.anthropic.com)
על קוראי תחום האבטחה להפיק שני לקחים מהפרק הזה. הראשון הוא שהנדסה לאחור ומחקר פגיעויות במצב לא מקוון הם כשלעצמם יכולות משמעותיות. שחזור קוד מקור סביר מקבצים בינאריים שעברו ניקוי הוא בעל ערך, גם אם אין זה עדיין הוכחה פומבית למחקר פגיעויות בקנה מידה נרחב, המתבסס אך ורק על קבצים בינאריים, שהוא אמין באופן אוניברסלי. השני הוא ש"גבול ההוכחה הפומבית" עדיין חשוב. Anthropic אומרת לקוראים שהדברים האלה קרו, אבל הממצאים המפורטים הדרושים לשחזור חיצוני עצמאי עדיין לא פורסמו ברובם. זה לא הופך את הטענות לשקריות. זה אומר שצריך לנסח נכון את רמת הביטחון. "ראיות חזקות שנכתבו על ידי הספק עם יכולת שחזור ציבורית מוגבלת" זה לא כמו "עובדה שהוכרעה בפומבי". (red.anthropic.com)
ההבחנה הזו הופכת לחשובה עוד יותר כאשר השיח עובר ממחקר על פרצות עם חשיפת קוד המקור לבדיקת יישומים אינטרנטיים הפונים לרשת. חברת Anthropic מפרטת בפומבי קטגוריות חשובות של באגים לוגיים, כולל עקיפת אימות מלאה, עקיפת כניסה לחשבון ומצבי מניעת שירות הרסניים. לקטגוריות באגים אלה יש חשיבות רבה בסביבות SaaS אמיתיות. אך הדו"ח הציבורי של Anthropic אינו מספק מקרי בוחן מפורטים עבור ממצאים אלה, והראיות המתודולוגיות החזקות ביותר שלה נותרו מרוכזות בהקשרים של קוד גלוי או לא מקוון. דרך מועילה לתאר את המצב היא זו: Mythos Preview קידמה בבירור את מצב המחקר בנושא ניצול פרצות ב-AI, אך התיעוד הציבורי טרם סגר לחלוטין את הפער בין מחקר ניצול פרצות בעל מידע רב לבין בדיקות חדירות מקצה לקצה של קופסאות שחורות במערכות פעילות. (red.anthropic.com)
זו גם הסיבה שצוותים מנוסים צריכים להפסיק להתייחס להסקת מסקנות בשיטת "הקופסה הלבנה" ולאימות בשיטת "הקופסה השחורה" כאל קטגוריות מוצרים מתחרות. מדובר בשלבים שונים בתוך מעגל אבטחה אמין יותר. המאמרים הטכניים שפרסמה חברת Penligent בנושא זה מספקים כאן כיוון מועיל: הם טוענים שבינה מלאכותית המודעת למקור יכולה לצמצם את החיפוש ולמפות את הגורמים השורשיים הסבירים, בעוד שאימות המכוון ליעד עדיין נדרש כדי להוכיח את הנגישות וההשפעה בסביבה הפרוסה. זוהי פרשנות הגיונית ל"רגע המיתוס". העבודה שברור כי היא מצטמצמת ראשונה היא החלק הקדמי והיקר של מחקר הניצול. העבודה שעדיין דורשת אינטראקציה זהירה עם המערכת היא ההוכחה כנגד משטח היעד האמיתי. (penligent.ai)
בטיחות הזיכרון נותרת נושא מרכזי, אך באגים לוגיים אינם נעלמים
יש נטייה לראות בהשקת Mythos פרסומת ענקית לשפות בטוחות לזיכרון, ויש בכך מידה של אמת. החומר הציבורי החזק ביותר ש-Anthropic פרסמה עד כה מתרכז בעיקר בתחום שאינו בטוח לזיכרון: טיפול ב-TCP ב-OpenBSD, RPCSEC_GSS בקרנל FreeBSD, מפענח H.264 של FFmpeg ושרשראות ניצול בקרנל לינוקס. ההנחיות של ממשלת ארה"ב נעות באותו הכיוון כבר שנים. בדצמבר 2023 פרסמו ה-NSA, ה-CISA ושותפים את "The Case for Memory Safe Roadmaps" (הטיעונים בעד מפות דרכים לבטיחות זיכרון), ובו טענו כי מעבר לשפות בטוחות לזיכרון יכול לחסל סוגים נרחבים של פגיעויות בבטיחות זיכרון. ביוני 2025 הדגישו ה-NSA וה-CISA שוב כי צמצום הפגיעויות הקשורות לזיכרון הוא קריטי וכי התוצאות של אי-טיפול בהן עלולות לכלול פרצות, קריסות והפרעות תפעוליות. (משרד המלחמה של ארצות הברית)
אך המאמר על Mythos גם מבהיר מדוע בטיחות הזיכרון אינה יכולה להוות את התשובה המלאה. חברת Anthropic טוענת כי ב-Mythos Preview התגלו מספר רב של עקיפות אימות מלאות, עקיפות כניסה לחשבונות ומצבי מניעת שירות (DoS) העלולים למחוק נתונים מרחוק או לגרום לקריסת שירות. כמו כן, המאמר מתאר עקיפת KASLR בקרנל לינוקס, שאינה נובעת מקריאה קלאסית מחוץ לגבולות הזיכרון, אלא ממצביע קרנל שנחשף בכוונה. מדובר בכשלים לוגיים ותכנוניים, ולא רק בטעויות בניהול הזיכרון. מעבר ל-Rust או לשפה אחרת הבטוחה לזיכרון יקטין משטח סיכון אחד חשוב מאוד, אך לא ינטרל פערים באישור, אי-התאמות במודל האבטחה או דליפות מידע ש"פועלות כפי שנקבעו בקוד" ועדיין אינן בטוחות. (red.anthropic.com)
| משפחת פגיעויות בדיון על Mythos | במה יכולה בטיחות השפה לסייע | מה זה לא פותר |
|---|---|---|
| פגיעה בזיכרון במנתחי תחביר, בקרנלים ובערימות רשת | מבטל או מצמצם קריאות וכתיבות מחוץ לתחום, UAFs ושחרורים כפולים כאשר נעשה שימוש בפועל בתת-הקבוצה הבטוחה. (משרד המלחמה של ארצות הברית) | פתחי מילוט לא בטוחים, גבולות FFI וטעויות תכנון עדיין מהווים בעיה. הדוגמה של Anthropic ל-VMM הבטוח לזיכרון התבססה על פעולה לא בטוחה. (red.anthropic.com) |
| עקיפת אימות ושגיאות בלוגיקת הכניסה | מעט מאוד עזרה ישירה מעבר להקפדה על נהלי יישום בטוחים יותר. | בעיות בהיגיון ההרשאות, טעויות בגבולות האמון ופגמים בתהליכי העבודה עדיין קיימים. (red.anthropic.com) |
| דליפות מידע ועקיפת KASLR | עשוי להפחית כמה דליפות זיכרון. | חשיפה מכוונת של מצביעים או מטא-נתונים עלולה להישאר פגיעה גם בקוד הבטוח לזיכרון. (red.anthropic.com) |
המסקנה המעשית היא שמנהלי אבטחה צריכים להימנע מדיכוטומיות כוזבות. הם אינם צריכים לבחור בין אבטחת זיכרון לבין מהירות התגובה לפריצות. הם זקוקים לשניהם. תוכניות עבודה שמטרתן אבטחת זיכרון מהוות צעד מבני להפחתת סיכונים בטווח הארוך. אימות, תיקון ובדיקה חוזרת מהירים יותר הם צרכים תפעוליים בטווח הקצר, בעולם שבו פיתוח פריצות מתגבר בקצב מהיר יותר מהיכולת לשכתב את בסיס התוכנה המותקן. (משרד המלחמה של ארצות הברית)
מדריך המשחק למגן בעידן המיתוס
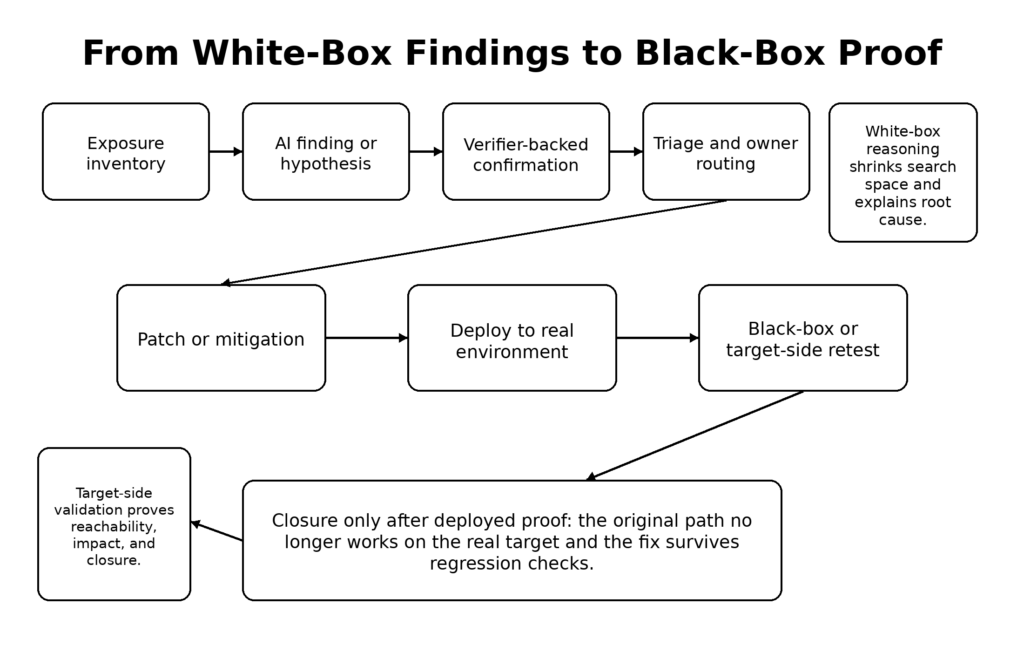
העצה הפומבית של Anthropic למגינים היא ישירה, והיא מהווה אחד החלקים המועילים ביותר בהודעה. החברה אומרת שארגונים צריכים לחשוב מעבר לאיתור פגיעות, ולכלול גם מיון, ביטול כפילויות, שלבי שחזור, תיקון מועמדים, בדיקת תצורה שגויה בענן, בדיקת יחסי ציבור ועבודת הגירה. היא טוענת במפורש שצוותים צריכים לקצר את מחזורי התיקון, לבחון מחדש את אכיפת התיקונים, לאפשר עדכון אוטומטי במידת האפשר, להתייחס לעליות בתלות הנושאות תיקוני CVE כדחופות, לבחון מחדש את הטיפול בחשיפה, ולבצע אוטומציה של התגובה לאירועים, מכיוון שגילוי מהיר יותר יביא ליותר ניסיונות נגד חלון הזמן שבין החשיפה לתיקון. (penligent.ai)
ההנחיות הללו נכונות, אך כדאי לתרגם אותן למודל תפעולי קונקרטי. השינויים המיידיים הנדרשים מצוותי האבטחה אינם דבר מסתורי. הם נוגעים לנהלים וניתנים למדידה.
ראשית, יש להפריד בין השערות מודל לממצאים מאומתים. מודל עשוי להיות יעיל מאוד בזיהוי פגיעויות פוטנציאליות, אך על הארגון להעביר ממצא לטיפול בעדיפות גבוהה רק לאחר שעבר את שלב האימות. בהתאם למטרה, בודק זה עשוי להיות ASan, מערך רגרסיה, כלי לשחזור, בדיקת אינטגרציה שנכשלה, הוכחת תפיסה עם מינימום קריסות, או אימות מול היעד בסביבה מורשית. זהו הלקח שהפיקה Anthropic מ-Firefox, וזו הדרישה המינימלית לשמירה על איכות אות גבוהה ככל שנפח התפוקה של המודל עולה. (אנתרופי)
שנית, יש לעבור מעבודת אבטחה המבוססת על לוח שנה לעבודת אבטחה המבוססת על תור. מחזור סקירה רבעוני היה הגיוני כאשר צוואר הבקבוק היה גילוי אנושי. זה פחות הגיוני אם גילוי בסיוע מודלים מפיק ממצאים מאומתים מדי יום. יחידת הניהול הנכונה היא כעת תור המתעדכן ברציפות עם כללי התיישנות ברורים, רמזים לניצול, חשיבות הנכסים ומצב הבדיקה החוזרת. ארגונים שעדיין מתייחסים לבדיקות אבטחה כאל אירוע של מסירת דוחות ירגישו איטיות גם אם ירכשו את הכלים החדישים ביותר. (red.anthropic.com)
שלישית, התייחסו לתיקונים המוצעים כאל תוצרים בעלי חשיבות עליונה. הניסיון של Anthropic עם Mozilla מזכיר לנו שדיווחי באגים מועילים הרבה יותר כאשר הם כוללים מקרי בדיקה מינימליים, הוכחות היתכנות (PoC) ותיקונים מוצעים. אין צורך למזג את התיקון המוצע באופן עיוור. עם זאת, הוא חייב להיות זמין בשלב מוקדם מספיק כדי שהמהנדסים יוכלו להעריך את היקף ההשפעה ואת סיום הטיפול בבעיה באותה שיחה. בתהליך טיפול בפגיעות במהירות של מחשב, המעבר מ"נמצאה תקלה" ל"יש תיקון סביר" צריך להתרחש בתוך שעות או ימים, ולא במגזרים ארגוניים נפרדים לאורך שבועות רבים. (אנתרופי)
רביעית, יש לאכוף סגירה באמצעות בדיקות חוזרות, ולא מתוך אופטימיות. אחת הדרכים הקלות ביותר לאבד קרקע בעידן Mythos היא לשחרר תיקון, לסמן כרטיס כ"בוצע" ולעולם לא להריץ מחדש את מסלול האיתור המקורי מבחוץ. במערכות אמיתיות יש פרוקסי, שערים, דגלי תכונות, מופעים מיושנים, מאגרי "קנרי", תהליכים ברקע ושינויים בתצורה. השוואת קוד אינה זהה לסגירה בפועל לאחר הפריסה. זהו הנקודה שבה אימות תיבת שחורה או תיבת אפור עדיין חשוב, וזהו גם הנקודה שבה לצוותים שכבר משתמשים בפלטפורמות אימות הפונות למטרה יש יתרון. החומרים הציבוריים של Penligent, למשל, מתארים זרימת עבודה סוכנתית הממוקדת בביצוע משימות מבוקר, בקרת היקף ואיסוף ראיות כנגד מטרות אמיתיות. בין אם צוות משתמש בפלטפורמה המדויקת הזו ובין אם לא, האינסטינקט הארכיטקטוני נכון: חשיבה מודלית צריכה להסתיים בראיות הניתנות לביקורת, ולא בפרוזה משכנעת. (penligent.ai)
דוגמה תמציתית לרישום פגיעות המוכן לשימוש במודל נראית כך:
{ "report_id": "AI-2026-0410-0017", "component": "rpcsec_gss", "asset_class": "kernel_nfs", "claim_type": "stack_overflow",
"evidence_source": "reproducer_plus_human_validation", "internet_exposed": true, "exploitability_state": "publicly_described_vendor_claim",
"patch_status": "vendor_patch_available", "owner_team": "platform_kernel", "retest_required": true, "notes": "אין להעלות את רמת החומרה ל'קריטית' עד שנספחים תוצרי האימות ומאושר כי הפריצה טופלה." }
מבנה מסוג זה חשוב יותר מהמודל שחיבר את הטקסט הראשוני. ברגע שהמודל מייצר תוצאות משמעותיות, לאיכות הסכימה, לניתוב ולתהליך האימות יש חשיבות רבה יותר מאשר לאלגנטיות של הפקודה. (אנתרופי)
להלן דוגמה פשוטה ב-Python לקביעת סדר עדיפויות לממצאים נכנסים שנוצרו על ידי בינה מלאכותית בתור התיקונים. הדוגמה משעממת בכוונה, וזה בדיוק העניין. החלק הקשה אינו מתמטיקה מתוחכמת של דירוג, אלא בניית תהליך שניתן לחזור עליו, המשקף את הלחץ האמיתי שמפעילים ניצולי פגיעות.
from dataclasses import dataclass @dataclass class Finding: component: str internet_exposed: bool verifier_passed: bool patch_available: bool privilege_boundary: bool memory_corruption: bool days_open: int
def priority_score(f: Finding) -> int: score = 0 if f.internet_exposed: score += 30 if f.verifier_passed: score += 25 if f.patch_available: score += 15
if f.privilege_boundary: score += 15 if f.memory_corruption: score += 10 if f.days_open > 7: score += 10 if f.days_open > 30: score += 10 return score
queue = [ Finding("rpcsec_gss", True, True, True, True, True, 2), Finding("ffmpeg_h264", False, True, True, False, True, 10), Finding("internal_auth_flow", True, False, False, True, False, 5), ]
for item in sorted(queue, key=priority_score, reverse=True): print(item.component, priority_score(item))
צוותים יכולים להרחיב זאת באמצעות מידע על בעלות על סביבות, חשיבות עסקית, חלונות זמן להקפאת שינויים או שרשרת תלות. הרעיון המרכזי הוא שממצאים המגובים על ידי בודקים, החשופים לאינטרנט ומערבים חריגה מהרשאות, צריכים לעלות במהירות, במיוחד כאשר כבר קיים תיקון ומערכת בינה מלאכותית יכולה לסייע לאחרים להפוך אותו לנשק מהר יותר מבעבר. (CISA)

פעולות ל-30 יום, 90 יום ו-180 יום עבור צוותי אבטחה
| טווח הזמן | מה לשנות עכשיו | מדוע זה חשוב בעידן ה-zero-day |
|---|---|---|
| 30 הימים הראשונים | לערוך רשימה של שירותים הנגישים מבחוץ, שירותים הפונים אל הליבה ומנתחי נתונים קריטיים; לזהות היכן ימומשו ממצאים שנוצרו על ידי בינה מלאכותית מבחינה תפעולית; להגדיר דרישות אימות לדוחות בעלי עדיפות גבוהה. (פרויקט FreeBSD) | לרוב הצוותים כבר יש כלים. אך עדיין אין להם מעגל של ניתוב ואימות מהיר מספיק. |
| 90 הימים הראשונים | יש להוסיף שדות מיון מובנים, ציפיות לגבי תיקונים אפשריים ובדיקות חוזרות חובה; להחמיר את הסכמי רמת השירות (SLA) לתיקונים בנוגע לבעיות נגישות של פגיעה בזיכרון ושביל אימות; ולהגדיר מראש מסלולי הסלמה במקרה של חשיפת מידע. (אנתרופי) | גילוי בסיוע בינה מלאכותית מגדיל את היקף הדיווחים ומקצר את פרק הזמן הבטוח שבין זמינות התיקון לבין האפשרות לנצל את הפגיעות. |
| 180 הימים הראשונים | יש לבנות תהליך אימות מחדש רציף המכוון ליעדים עבור ממשקים בסיכון גבוה; לתאם בין צוותי אבטחת האפליקציות (AppSec), SRE וצוותי הפלטפורמה סביב הגדרה משותפת לתיקון תקלות; ולהרחיב את תוכניות העבודה בתחום אבטחת הזיכרון, ככל שהדבר אפשרי. (משרד המלחמה של ארצות הברית) | התגובה העמידה מתבטאת בלולאה תפעולית מהירה יותר ובצמצום מבני של קוד המועד לטעויות. |
הטעות הגדולה ביותר שצוותים עלולים לעשות היא לנסות להגיב ל"רגע המיתוס" באמצעות "תיאטרון רכש". רכישת תוכנית גישה לדוגמה או תוסף של "בינה מלאכותית לאבטחה" לא תציל ארגון שניהול התיקונים שלו איטי, שהבעלים שלו אינם ברורים, שהמאמתים שלו חלשים, ושחסרים בו ראיות לפריסה. הטעות השנייה בגודלה תהיה לדחות את כל זה משום שהטענות הרחבות ביותר עדיין אינן ניתנות לשחזור באופן עצמאי. זהו סטנדרט מחמיר מדי לתכנון תפעולי. כאשר ספק כבר פרסם מקרים שתוקנו ב-OpenBSD, FreeBSD ו-FFmpeg; תיעד קפיצות משמעותיות במדדי ביצועים; ושינה את מדיניות השחרור והגילוי סביב המודל, למגינים אין צורך בשחזור ציבורי מושלם כדי להצדיק שינוי בתהליכי העבודה שלהם. (openbsd.org)
מה צריכים רוכשי פתרונות אבטחה לשאול לאחר הצגת ה-Mythos
רוכשים טכניים שיעריכו מוצרי אבטחת בינה מלאכותית בשנת 2026 צריכים להיות תובעניים הרבה יותר מהמקובל כיום בשוק. השאלה הראשונה היא האם הראיות החזקות ביותר של המוצר נובעות מניתוח קוד מקור גלוי או מאימות מול היעד. זו אינה שאלה מכשילה. לשני הגישות יש ערך, אך הן נותנות מענה לבעיות שונות. אם הדוגמאות הטובות ביותר של ספק מסתמכות כולן על גישה לקוד מקומי, שחזור בינארי מפושט או רתמות לא מקוונות, אז הקונים לא צריכים להסיק שהמוצר כבר הוכיח את עצמו בבדיקות "קופסה שחורה" בסביבות דמויות-ייצור. התיעוד הציבורי של Anthropic הוא מקרה בוחן שימושי הממחיש עד כמה קל לטשטש את הגבולות בין הקטגוריות הללו בשיח השיווקי. (red.anthropic.com)
השאלה השנייה היא איזו שכבת אימות קיימת. עבודתה של Anthropic עצמה מצביעה שוב ושוב על אמצעי האימות: ASan, בדיקות רגרסיה, תוצרי שחזור מינימליים והוכחת סגירות. מערכת המסוגלת לייצר הסברים יפים ללא אמצעי אימות אמין היא, במקרה הטוב, עוזרת למיון ראשוני, ולא תהליך אבטחה אמין. על הרוכשים לבקש לראות את תיעוד התוצרים, ולא רק את מסך הסיכום. (red.anthropic.com)
השאלה השלישית היא כיצד הפלטפורמה מטפלת בבדיקות חוזרות ובסגירת תקלות. איתור פגיעות ללא אימות חוזר מצד היעד יוצר "חוב כרטיסים". בשוק הנוכחי, חלק מהחומרים הציבוריים של Penligent מועילים דווקא משום שהם מתעקשים להפריד בין ממצאי "תיבת לבנה" לבין הוכחות "תיבת שחורה", ולהפוך את הראיות לתוצר מרכזי. על הרוכשים לתגמל הבחנה זו בכל מקום בו הם מוצאים אותה. השאלה אינה האם כלי מסוים "משתמש ב-AI". השאלה היא האם הוא יכול לעזור להעביר ממצא מהיפותזה לחשיפה מאומתת ולסגירה מאומתת. (penligent.ai)
השאלה הרביעית היא אילו הנחות בנוגע לחשיפה ולעומס על המפעילים מניח הספק. חברת Anthropic נאלצה לפרסם מדיניות תפעולית ייעודית ומתואמת בנושא חשיפה, שכן גילוי שנוצר על ידי בינה מלאכותית עלול להציף את האחראים על התחזוקה אם מטפלים בו באופן לא אחראי. כל פלטפורמה רצינית הטוענת כי היא מפיקה ממצאי אבטחה בקנה מידה נרחב צריכה להיות מסוגלת להסביר כיצד היא מונעת הצפת דיווחים, כיצד היא מסמנת חומר שמקורו בבינה מלאכותית, כיצד בני אדם מאמתים אותו, וכיצד היא נמנעת מלהפוך את האחראים על התחזוקה לתשתית מיון ללא תשלום. (אנתרופי)
הגרסת ההדגמה של Claude Mythos היא אבן דרך, אך לא סוף הסיפור
המסקנה הברורה ביותר היא גם הפחות פופולרית. התצוגה המקדימה של Claude Mythos היא הסימן הציבורי החזק ביותר עד כה לכך שמחקר הפרצות ב-AI נכנס לשלב חדש. חברת Anthropic פרסמה מקרים ספציפיים שטופלו, הבדלים משמעותיים במדדי ביצועים, מדיניות פרסום עם גישה מוגבלת, ומסגרת גילוי שתוכננה סביב גילוי בסיוע מחשב. די בכך כדי להצדיק שינויים הגנתיים משמעותיים כבר כעת. (red.anthropic.com)
במקביל, לתיעוד הציבורי עדיין יש מגבלות שיש לציין בכנות. מרבית הממצאים נותרים חסויים משום שלא תוקנו. הטענות הכלליות ביותר בנוגע לדפדפנים, באגים בלוגיקת האינטרנט ויעדים בקוד סגור אינן ניתנות עדיין לשחזור עצמאי מתוך תוצרים ציבוריים. המקרה של FreeBSD מראה שגם בקרב מקורות איכותיים, הניסוח בנוגע להשלכות עשוי להיות שונה בין המעבדה שגילתה את הפגיעות לבין ההודעה הרשמית של הספק. אלה אינן סיבות לבטל את הממצאים. הן סיבות לקרוא אותם בעיון. (red.anthropic.com)
הדבר הראשון ש-Mythos משנה אינו השאלה הפילוסופית האם בינה מלאכותית מסוגלת לפרוץ. שאלה זו כבר אינה רלוונטית. מה שהוא משנה הוא את לוח הזמנים. הוא מקצר את הזמן שבין הגילוי לבין תובנה שמישה. הוא מאיים לקצר את הזמן שבין זמינות התיקון לבין האפשרות לנצל את הפגיעות. הוא מעלה את הערך של בודקים, תיקונים פוטנציאליים ובדיקות חוזרות. הוא הופך את קצב החשיפה ואת ניהול התיקונים לחלק ממערך האבטחה. צוותים שיבינו זאת יתאימו את עצמם עם הזמן. צוותים שיחכו להוכחה ציבורית מושלמת לכל טענה כנראה עדיין יגיעו לשם, אך הם יגיעו לשם מאוחר יותר ממה שהם צריכים. (red.anthropic.com)
קריאה נוספת וקישורים למקורות
- אנתרופיק, הערכת יכולות אבטחת הסייבר של Claude Mythos Preview. (red.anthropic.com)
- אנתרופיק, פרויקט Glasswing. (אנתרופי)
- אנתרופיק, חשיפה מתואמת של פרצות אבטחה שהתגלו על ידי Claude. (אנתרופי)
- אנתרופיק, תצוגה מקדימה של דוח הסיכונים של קלוד מיטוס, גרסה ציבורית שעברה עריכה. (אנתרופי)
- אנתרופיק, שיתוף פעולה עם Mozilla לשיפור האבטחה ב-Firefox. (אנתרופי)
- תיקון 025 ל-OpenBSD 7.8 עבור אפשרויות SACK לא חוקיות. (openbsd.org)
- הודעת אבטחה של FreeBSD SA-26:08.rpcsec_gss ורישום ב-NVD עבור CVE-2026-4747. (פרויקט FreeBSD)
- רשומות NVD וספקים עבור CVE-2024-53141 בקרנל לינוקס. (nvd.nist.gov)
- דף המהדורה של FFmpeg 8.1 וה-commit ההיסטורי משנת 2010 של שיפוץ קוד ה-H.264 שעליו מצטטת Anthropic. (ffmpeg.org)
- הנחיות ה-NSA וה-CISA בנוגע לתוכניות עבודה ושפות תכנות הבטוחות לזיכרון. (משרד המלחמה של ארצות הברית)
- פנליג'נט, תצוגה מקדימה של Claude Mythos אינה בדיקת חדירות מסוג "קופסה שחורה". (penligent.ai)
- פנליג'נט, Claude Code Security ו-Penligent: מממצאי בדיקת "קופסה לבנה" להוכחת "קופסה שחורה". (penligent.ai)
- דף הבית של Penligent. (penligent.ai)

