One of the most revealing security stories of April 2026 did not start with ransomware, a nation-state intrusion, or a zero-day exploit. It started with a meme. According to 404 Media, a hacker got into a backend system used by Doublespeed, an a16z-backed startup, and tried to make the company’s AI-generated TikTok accounts post memes calling a16z the “antichrist.” The joke is memorable. The important part is what sat behind it: a centralized system for creating fake influencers, generating videos, posting comments, and managing a phone farm tied to large numbers of social accounts. 404 Media also wrote that this was at least the second time the company had been compromised. (404 Media)
That is why this story matters far beyond the usual cycle of social media outrage. Most conversations about AI slop stop at the output layer. People argue about synthetic faces, uncanny captions, low-grade product videos, or whether a clip “looks AI.” This incident points to something much more important: the control plane behind industrialized influence work. Doublespeed’s own public site describes a “TERMINAL” that can orchestrate actions on thousands of social accounts, generate and deploy content in bulk, define hyper-specific personas, manage account parameters on real devices, build workflows that turn trending content into new variations, and clone successful content into multiple versions designed to avoid suppression. Its a16z Speedrun profile described the company as an “attention intelligence platform” that deploys social agents at scale and lets one person orchestrate what used to take a 30-person creator team. (Doublespeed)
That combination is the real story. A model can generate almost unlimited scripts, captions, thumbnails, and persona biographies. A phone farm and its backend make those outputs operational. The result is not just fake content. It is infrastructure: personas, workflows, deployment pipelines, account control, feedback loops, and device-level execution. Once that infrastructure exists, it creates two separate security problems at the same time. The first is external harm, because the system can manipulate platform signals and public attention at scale. The second is internal fragility, because the same centralized backend becomes a high-value target that can be hijacked, studied, or turned against its operator.
This article stays close to what is publicly documented. 404 Media’s visible reporting establishes the breach, the repeated compromise history, and the broad purpose of the system. Doublespeed’s public site and a16z’s profile provide unusually direct descriptions of the operating model. TikTok and Meta publish the framework they use to distinguish spam, fake engagement, platform manipulation, and coordinated inauthentic behavior. OpenAI’s latest threat reporting adds a useful broader point: malicious AI use is rarely limited to one model or one platform, and actors typically combine AI with ordinary web infrastructure and social accounts rather than replacing traditional operations entirely. That is exactly the frame needed here. (404 Media)
The breach was news. The stack is the story.
The Doublespeed breach and the public record
The public timeline is already enough to show a pattern. In October 2025, 404 Media reported that Doublespeed was selling “synthetic influencers” to manipulate social media as a service, describing it as an astroturfing system that could orchestrate actions on thousands of social accounts through bulk content creation and deployment. In December 2025, 404 Media reported that a hacker had gained control of a 1,100-phone farm tied to covert, AI-generated ads on TikTok. In April 2026, 404 Media reported a new compromise in which a hacker accessed a backend system and attempted to use AI-generated TikTok accounts to post anti-a16z memes. That is not an isolated embarrassment. It is a repeated exposure of the same operational core. (404 Media)
What is clear is more important than what is missing. The publicly visible reporting does not identify the exact vulnerability class that led to the latest breach. It does not publish a full exploit chain, an authenticated-versus-unauthenticated breakdown, or a precise architectural diagram of Doublespeed’s internal systems. It does not need to. From a security engineering perspective, the important public fact is that the backend existed, it had enough authority to control or influence large numbers of synthetic accounts, and it was reachable enough to be compromised more than once. When a single administrative surface can touch hundreds or thousands of identities and devices, the backend stops being routine application infrastructure and becomes the crown jewel. (404 Media)
A useful way to read this incident is to separate verified public facts from structural implications. The public facts tell us that Doublespeed was operating a phone-farm-backed synthetic influencer system and that attackers got into its backend. The structural implications follow from how such systems work in general and from how Doublespeed described its own product. If a platform lets operators bulk-create personas, edit account state, fine-tune content, build workflows, and push content through real devices, then the same platform necessarily concentrates permissions, secrets, scheduling logic, and audit data. That concentration is why these systems are effective. It is also why they are so dangerous when compromised.
The table below summarizes the public record and the more careful structural meaning of each piece. The factual column is limited to what is documented publicly. The “why it matters” column is analysis, not hidden inside-the-company knowledge. (404 Media)
| Publicly documented element | What is clearly established | מדוע זה חשוב מבחינה טכנית |
|---|---|---|
| April 2026 backend compromise | A hacker accessed a backend system tied to AI-generated TikTok accounts | The backend had meaningful control over social identities and publishing paths |
| December 2025 phone farm compromise | A hacker reportedly gained control of more than 1,000 phones | Device orchestration was centralized enough to be reached and abused |
| October 2025 reporting on synthetic influencers | Doublespeed marketed large-scale social account orchestration | The system was designed for coordinated bulk activity, not one-off creator tooling |
| Public site claims about real devices and workflow building | Account operations and content pipelines were productized | The company exposed the operational categories defenders should care about most |
| a16z profile calling it “attention intelligence” | The business model was scale, automation, and conversion | This was not accidental misuse of a generic AI tool, but a built system for scaled influence |
That repeated pattern is what makes the story significant for security teams. It tells us that the interesting question is not “Did a hacker post a prank meme?” The interesting question is “What does a modern AI content factory need in order to function, and where does that make it weak?”
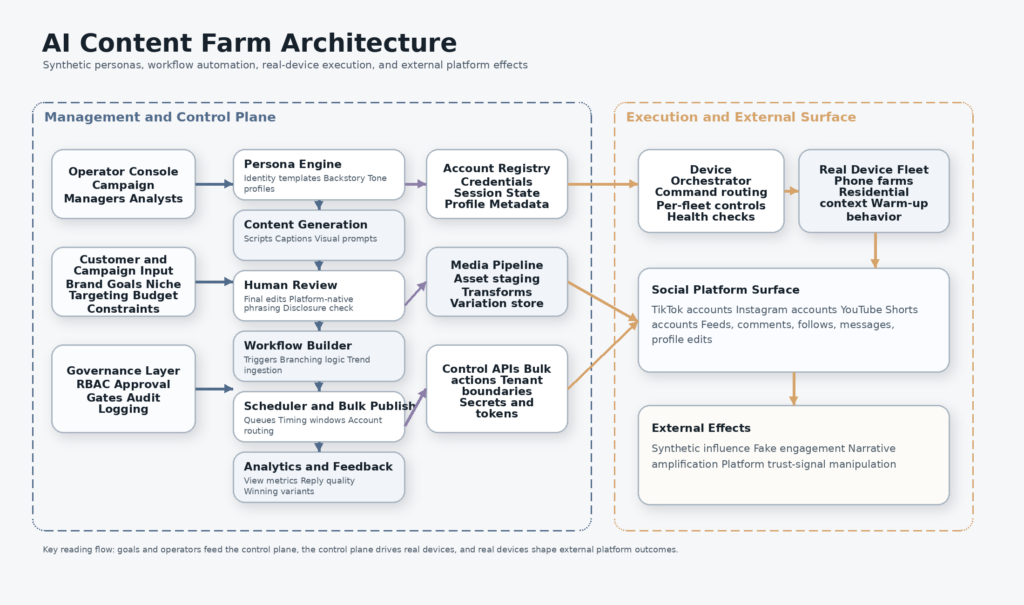
AI content farm architecture, from personas to device fleets
Doublespeed’s public site is unusually blunt. It says the company’s terminal orchestrates actions on thousands of social accounts through bulk content creation and deployment. It offers hyper-specific personas, attention intelligence, instrumented human-like action, content fine-tuning, bulk posts, account management on real devices, a workflow builder, and content cloning where “winners get cloned, not repeated.” The same site also advertises “physical U.S. device deployment” and says humans add the last 5 percent that makes platforms trust the content is real. The a16z Speedrun profile pushes the same idea in investor language: build and deploy social agents at scale, capture mindshare, learn from every interaction, and drive conversions around the clock. (Doublespeed)
Those phrases matter because each one points to a different subsystem. “Hyper-specific personas” implies a state layer for identity consistency. A persona is not only a profile picture and a bio. It is a bundle of prompt context, behavioral defaults, target demographic, likely interests, posting tone, engagement patterns, and sometimes a narrative background designed to make future content look coherent. “Content fine-tuning” implies a generation pipeline with a human review pass. “Bulk posts” implies queueing, scheduling, media management, and some form of account routing. “Account management” implies device association, credential handling, profile mutation, and probably permissions around which operators can touch which assets. “Workflow builder” implies composable triggers, chained models, and automation logic that can react to trends or campaign signals. (Doublespeed)
That is why calling this a bot farm undersells the system. A classic bot farm is primarily about execution volume. It automates actions. An AI content farm does that too, but it adds a synthetic identity layer and a content intelligence layer. It does not just click, like, follow, and repost. It manufactures personas, varies narratives, tunes style, learns from engagement, and ships those outputs through devices and accounts built to look distinct enough to pass routine platform defenses. That is closer to a distributed content operation than a simple spam script.
The architecture can be understood as six layers. First comes persona generation, which makes the account legible as a believable “someone.” Second comes content generation, which produces scripts, captions, shot lists, visual prompts, and engagement replies. Third comes the human editing pass, which removes the obvious machine smell and adds the small inconsistencies that make content feel native to a platform. Fourth comes deployment, which schedules and routes the content into specific accounts. Fifth comes engagement simulation, where accounts warm up, follow, comment, scroll, and interact to strengthen trust signals. Sixth comes measurement, where successful content is harvested into future training or prompt context, closing the optimization loop. Doublespeed’s public material describes almost every part of that chain in plain language. (Doublespeed)
The table below maps the public claims to a more useful security model. It is not a leaked architecture diagram. It is a translation of the public feature set into the operational stack defenders should expect to see. (Doublespeed)
| Publicly described capability | Operational role | What defenders should infer |
|---|---|---|
| Hyper-specific personas | Persistent synthetic identities for different niches and demographics | There is likely a stateful persona layer, not just one-off content prompts |
| Attention intelligence | Performance tracking and feedback-driven optimization | Successful outputs likely feed future generation or deployment decisions |
| Human-like action | Warm-up, interaction, and behavioral mimicry | Detection has to look at behavioral linkage, not just content quality |
| Bulk posts | Scaled scheduling and publishing | Queueing systems, APIs, and content-routing logic become key attack surfaces |
| Account management on real devices | Control over profiles and behavioral state across many accounts | Device orchestration and admin permissions are central security boundaries |
| Workflow builder | Trigger-based automation and multi-step content pipelines | The platform probably includes privileged automation logic and reusable flows |
| Content cloning and variation | Scaling narratives without exact duplicates | Simple duplicate detection is necessary but not sufficient |
Once you look at it this way, the significance of the breach becomes obvious. The incident did not merely expose an embarrassing startup. It exposed the minimum viable architecture for industrialized synthetic influence in 2026.
Synthetic influencers are not just fake faces
A useful mistake to avoid is reducing synthetic influencers to avatars or face-swapped videos. The public material around Doublespeed suggests something more systematic. The persona is only one node in a larger machine. It needs a behavioral history, a niche, a recognizable tone, a set of content constraints, a relationship to current trends, and a device-backed presence that looks plausible over time. That is why the site talks about “background” and content that “persists their character,” not just one-off profile generation. It is trying to solve continuity. (Doublespeed)
Continuity is what makes these systems useful to operators and difficult for investigators. One synthetic creator can be dismissed as gimmickry. A fleet of accounts with stable but differentiable personas, variable content, and realistic interaction patterns is much harder to write off as noise. The goal is not perfection. In fact, the site’s own language about the final human 5 percent is revealing. The point is not to make the content flawless. The point is to make it believable enough to earn the platform’s procedural trust and the viewer’s casual acceptance. Real people are inconsistent. Believable synthetic personas have to be inconsistent in the right ways. (Doublespeed)
That is also where a lot of trust and safety discussion goes wrong. Teams often overinvest in detecting obviously AI-written captions, stiff voiceovers, or image artifacts. Those signals still matter, but they are fragile. The strongest operations adapt. They can rewrite captions, shift pacing, inject platform slang, vary video edits, and blend human touch-up into the pipeline. The more durable signals are not purely linguistic. They live in account linkage, device reuse, workflow timing, media genealogy, operator behavior, and narrative synchronization.
This is one reason the current story is so useful for researchers. The site itself describes the move from content generation to content operations. “Workflow builder” and “infrastructure-as-code for content ops” are not the language of a casual creator assistant. They are the language of orchestration. “Winners get cloned, not repeated” is not a statement about creativity. It is a statement about experimental distribution and content mutation under performance pressure. “Bulk content creation and deployment” is not a creator feature. It is a fleet feature. (Doublespeed)
Seen clearly, the synthetic influencer is the visible artifact of a backend workflow. That backend is where the leverage is. It is also where the best security and intelligence questions sit. Who can define a persona template? Who can mutate it? Who can push content to how many accounts in how little time? What secrets and tokens sit inside the routing layer? What logs exist when something goes wrong? What happens if a single privileged operator token is stolen? A content-centric understanding cannot answer any of that. A control-plane understanding can.
Why phone farms still matter in AI-driven social manipulation
At first glance, a phone farm can look outdated. Why would anyone still care about racks of real phones in an era of powerful generative models, browser automation, and large-scale cloud compute? The answer is simple: models solve content abundance, but real devices still solve trust. Doublespeed’s public site says account management is orchestrated on real devices and explicitly advertises physical U.S. device deployment. That is not decorative marketing language. It is a statement about how the company expects platform defenses to work. (Doublespeed)
Most anti-abuse systems do not rely on one signal. They fuse device, network, account age, behavioral patterning, session continuity, interaction timing, and link analysis. If an operator runs thousands of accounts through a small pool of obvious emulators or cheap browser automation, platform defenses tend to cluster that activity fast. That is why real-device fraud operations persist in adjacent areas such as account abuse, engagement fraud, and identity-based scams. Arkose Labs, for example, describes device intelligence as useful for finding automation, spotting emulators and virtual machines masquerading as legitimate mobile devices, and revealing fraud farms that rotate device profiles. That is the same defensive logic a phone-farm operator is trying to resist. (Arkose Labs)
The real-device layer does not replace the AI layer. It complements it. The model generates infinite variants. The device layer gives those variants a place to live that looks harder to dismiss as synthetic. Once you understand that split, the economics of the stack become clearer. The model is the cheap, fast content engine. The phone farm is the expensive, operationally annoying execution engine. Together, they let an operator industrialize both narrative production and trust-signal evasion.
There is also a subtler reason phone farms matter. Platforms increasingly look beyond text and media artifacts and toward clusters of technical linkage. TikTok’s own public explanation of deceptive behavior says the company focuses on coordination, shared technical similarities such as the same devices, fake personas, attempts to manipulate or corrupt public debate, and platform manipulation through automation or operating accounts in bulk. It also draws a useful distinction: not every deceptive operation is a covert influence operation, but financially motivated fake engagement and bulk-operated accounts are still prohibited and investigated. That means operators need enough device and account diversity to avoid being caught by the easier cases, even if they are not running a geopolitical campaign. (TikTok Newsroom)
This is also why the “AI content factory” framing is more accurate than “AI bot spam.” The phone farm is not an afterthought. It is the physical trust anchor for a synthetic media pipeline. The backend is the scheduler. The device fleet is the actuator. The persona layer is the wrapper. The model is the content engine. All four matter.
The backend attack surface behind AI-generated influencers
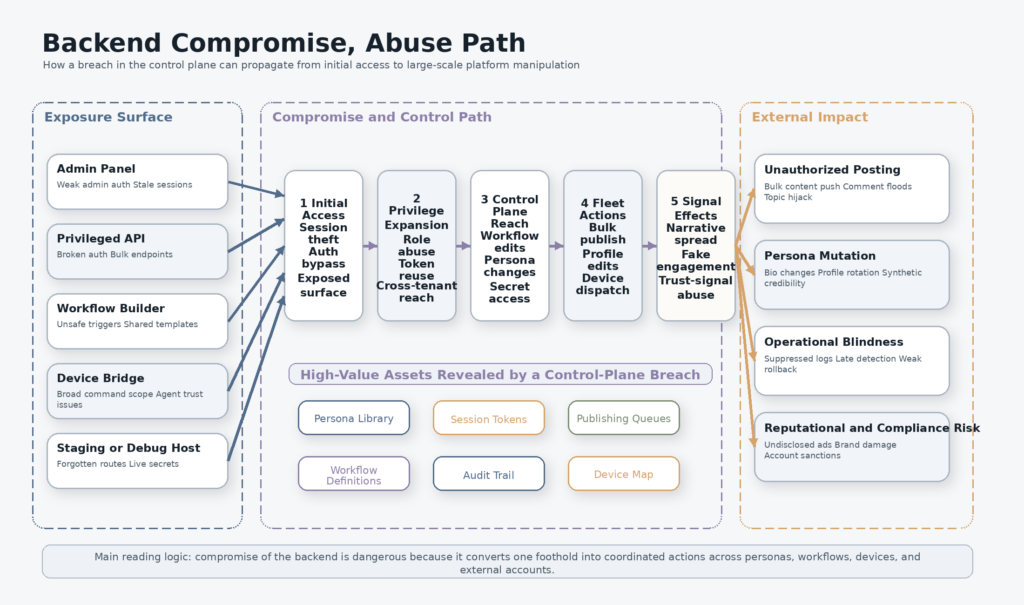
Once a system is built to orchestrate thousands of accounts, the backend becomes more valuable than any single account it controls. That is the central security lesson of the Doublespeed story. If an attacker can compromise one fake influencer account, they get one channel. If they can compromise the backend, they may get the scheduling layer, the account management layer, the persona library, the device map, the workflow builder, the media pipeline, the customer list, and the analytics loop.
A backend like this almost certainly includes at least some of the following categories, whether they are packaged as separate services or combined into one application. There is the admin panel for operators. There are privileged APIs for account state changes and content publishing. There are queues for scheduled deployment. There is storage for persona definitions and media assets. There are device bindings or agent channels for actions performed on physical phones. There are tokens and credentials for the various platforms being targeted. There is an analytics layer that measures performance and may feed results back into prompts or model chains. There is usually an abuse-prevention layer too, though in this case the abuse target is the outside platform rather than the system itself.
Each one of those categories introduces common security failure modes. Admin panels fail through missing MFA, weak session controls, bad RBAC, cross-tenant leakage, and forgotten staging instances. Content APIs fail through broken authorization, undocumented bulk endpoints, mass assignment, or queue abuse. Device bridges fail through overly broad command channels, insufficient authentication, or exposed debugging paths. Workflow builders fail through template injection, unsafe trigger logic, unreviewed automation paths, or privilege escalation between low-trust and high-trust components. Analytics and retraining systems fail through poisoned inputs, weak segregation between customers, and secrets leakage in logs or prompt context. None of that requires a novel AI vulnerability. It requires ordinary application security mistakes in a system that happens to have extraordinary downstream leverage.
The table below maps the likely attack surface categories to the kinds of security outcomes that matter most in a synthetic influence system. It is intentionally written from a defender’s perspective. (404 Media)
| Backend surface | Why it exists | Failure mode that matters most | Likely consequence |
|---|---|---|---|
| Admin console | Manage campaigns, accounts, and operators | Missing MFA, broken RBAC, weak session handling | Broad fleet takeover, silent campaign changes |
| Bulk publish APIs | Push content to many accounts quickly | Broken auth, undocumented endpoints, mass assignment | Large-scale unauthorized posting or suppression |
| Persona library | Store voice, demographics, and content constraints | Cross-tenant access, weak object auth | Persona theft, cloning, contamination |
| Device orchestration channel | Send actions to real phones | Overly broad commands, agent spoofing, exposed admin paths | Control of many devices or account actions |
| Workflow builder | Chain prompts, triggers, and automation logic | Unsafe triggers, privilege escalation, template injection | Mass automation of malicious or unintended workflows |
| Media pipeline | Transform, stage, and distribute assets | Unsafe uploads, bucket exposure, path traversal, weak signing | Asset theft, payload swapping, stealth edits |
| Analytics and feedback loop | Rank content and guide future generation | Data poisoning, poor segregation, secrets leakage | Manipulated optimization, bad training signals |
| Audit and logging | Understand what happened | Incomplete logs, mutable logs, poor alerting | Delayed detection and weak incident response |
This is why backend compromise is such a big deal even when the public story sounds absurd. A meme posted through a hijacked content factory is funny. A backend that can update bios, push bulk posts, touch real devices, or repurpose successful content variations is a strategic control surface. If you are investigating the system, the backend is where you will find the operational truth. If you are defending the system, the backend is where you will most likely lose it.
Coordinated inauthentic behavior, fake engagement, and platform manipulation
The public discussion around this incident often collapses several different problems into one. That makes analysis worse. TikTok’s public explanation is useful precisely because it separates them. The company says covert influence operations are coordinated, inauthentic networks trying to mislead users or systems and influence public discussion on important social issues. It also says that many deceptive activities on a platform are not covert influence operations at all. Some are financially motivated spam or fake engagement. Those may operate at much greater scale, use more obvious tactics, and still be strictly prohibited. TikTok’s examples explicitly include bulk-operated accounts, automation used to register or run accounts in volume, spam, fake engagement, fake personas with intent to mislead, and the marketing of services that artificially inflate engagement. (TikTok Newsroom)
Meta’s framework reaches the same destination through a different label. In its coordinated inauthentic behavior reporting, Meta says it views CIB as coordinated efforts to manipulate public debate for a strategic goal where fake accounts are central to the operation. That phrasing is important because it ties fake identities, coordination, and strategic manipulation together instead of focusing only on individual pieces of content. (About Facebook)
The Doublespeed case sits in the overlap between those categories. The public evidence most clearly supports the “platform manipulation” and “fake engagement” side, because the company publicly described large-scale account orchestration, real-device deployment, persona construction, and behavior designed to look human to platform systems. Depending on the campaign and content, the same infrastructure could also support more politically or socially sensitive influence operations. TikTok’s policy explanation makes that distinction explicit: financially motivated inauthentic activity may touch elections or sensitive topics without meeting the stricter standard for covert influence operations, but it is still prohibited. (404 Media)
That distinction matters for defenders because it changes how you investigate. If you only look for geopolitical influence ops, you will miss large-scale synthetic engagement systems built for commercial gain. If you only look for fake engagement, you may underplay the possibility that the same infrastructure can be re-tasked into more strategic narrative manipulation. The backend does not care whether the campaign objective is product sales, affiliate revenue, political messaging, or trend hijacking. The same persona layer, device layer, and workflow layer can be repurposed.
This is also why threat intelligence and trust and safety teams should pay attention to systems like this even when the visible output is silly or low quality. A synthetic influencer factory is reusable infrastructure. Today it may push shaky product videos. Tomorrow it may be pointed at reputational attacks, stock rumors, crisis amplification, or real-time topic capture around breaking events. OpenAI’s most recent malicious-use reporting makes a parallel point from the model provider side: threat actors typically use AI alongside websites and social media accounts, and activity is seldom limited to one platform or one model. In other words, the model is one component inside a larger operational chain. (OpenAI)
The right conclusion is not that every AI-generated influencer is secretly a nation-state asset. The right conclusion is that the line between spam infrastructure, fraudulent engagement infrastructure, and influence infrastructure is operationally thinner than many teams pretend. The stack is often the same. The objective changes.
Detection for AI content farms, focus on behavior not just content
The most common failure in detecting synthetic influence systems is overfitting to content artifacts. Defenders look for identical captions, obvious AI voice patterns, repeated visual templates, or predictable hashtag bundles. Those can help, especially early in an operation. They are not enough once the operator has a workflow builder, a human editing pass, and enough data to learn which mutations survive moderation.
Behavioral linkage is harder to fake than surface style. TikTok’s own published criteria emphasize coordination, shared technical similarities such as devices, fake personas, and attempts to manipulate public discussion or platform systems. That is the right instinct. A serious detection program should prioritize signals that content variation alone cannot erase. (TikTok Newsroom)
The first class of signals is account-to-device and account-to-operator linkage. If many seemingly unrelated accounts share device clusters, session timing, routing paths, or operator tokens, that is stronger evidence than shared captions. The second class is batch behavior. Organic creators do not normally update dozens of bios, profile images, or content queues within the same short time windows under one administrative context. The third class is narrative synchronization. If many niche personas pivot into the same theme with slight wording changes at highly correlated times, that is usually worth investigating even when the exact text differs. The fourth class is feedback-loop behavior. Systems that harvest winning content and spawn variants often create family trees of related media or scripts, even if the final outputs are non-identical.
A lightweight content-similarity pass still has value, but it should be used as one layer in a broader graph. The following Python example shows a simple way to cluster near-duplicate captions or scripts by normalized shingles. It will not catch sophisticated paraphrase at scale, but it is enough to surface families of suspicious content for further review.
import re
from collections import defaultdict
from itertools import combinations
def normalize(text: str) -> str:
text = text.lower()
text = re.sub(r"http\S+", " ", text)
text = re.sub(r"[^a-z0-9\s]", " ", text)
text = re.sub(r"\s+", " ", text).strip()
return text
def shingles(text: str, k: int = 4) -> set[str]:
tokens = normalize(text).split()
if len(tokens) < k:
return {" ".join(tokens)}
return {" ".join(tokens[i:i+k]) for i in range(len(tokens) - k + 1)}
def jaccard(a: set[str], b: set[str]) -> float:
if not a and not b:
return 1.0
return len(a & b) / len(a | b)
def cluster_posts(posts: dict[str, str], threshold: float = 0.45):
shingle_map = {post_id: shingles(text) for post_id, text in posts.items()}
parent = {post_id: post_id for post_id in posts}
def find(x):
while parent[x] != x:
parent[x] = parent[parent[x]]
x = parent[x]
return x
def union(a, b):
ra, rb = find(a), find(b)
if ra != rb:
parent[rb] = ra
for a, b in combinations(posts.keys(), 2):
score = jaccard(shingle_map[a], shingle_map[b])
if score >= threshold:
union(a, b)
groups = defaultdict(list)
for post_id in posts:
groups[find(post_id)].append(post_id)
return list(groups.values())
sample_posts = {
"acct_01": "This kitchen gadget changed my morning routine. Here is why I use it every day.",
"acct_19": "This kitchen gadget changed my daily routine. Here is why I use it every single morning.",
"acct_44": "I stopped buying coffee out after trying this machine for a week. Not sponsored.",
"acct_72": "After a week with this machine I stopped buying coffee outside. Not sponsored."
}
clusters = cluster_posts(sample_posts, threshold=0.35)
print(clusters)
That kind of clustering becomes much more useful when you join it to device, account, and timing data. A mediocre content match plus tight device reuse and synchronized publishing is a stronger lead than a perfect text match on its own. A trust and safety team should think in graphs, not in isolated posts.
The following SQL pattern is a better fit for the operational side. It assumes an internal audit log with timestamps, operator context, device IDs, account IDs, and endpoint names. The point is to detect abnormal fan-out around sensitive bulk operations.
WITH recent_admin_activity AS (
SELECT
DATE_TRUNC('minute', event_time) AS minute_bucket,
operator_id,
session_token_id,
device_id,
account_id,
endpoint
FROM audit_logs
WHERE event_time >= NOW() - INTERVAL '24 hours'
AND endpoint IN (
'/api/accounts/bulk-update',
'/api/posts/bulk-publish',
'/api/workflows/execute',
'/api/personas/update',
'/api/devices/dispatch'
)
)
SELECT
minute_bucket,
operator_id,
session_token_id,
COUNT(*) AS total_actions,
COUNT(DISTINCT account_id) AS accounts_touched,
COUNT(DISTINCT device_id) AS devices_touched
FROM recent_admin_activity
GROUP BY 1, 2, 3
HAVING COUNT(DISTINCT account_id) >= 25
OR COUNT(DISTINCT device_id) >= 10
OR COUNT(*) >= 50
ORDER BY total_actions DESC;
This is the kind of query that catches the backend story rather than the content story. It is particularly effective when paired with alerting on unusual role transitions, impossible-travel session patterns, changes to workflow definitions, or sudden spikes in persona edits.
The most durable detection strategy is a three-layer model. The first layer is content similarity and media lineage. The second is behavioral coordination across accounts and devices. The third is privileged backend activity. Most teams overbuild the first layer and underbuild the third. The Doublespeed story is a reminder to reverse that priority.
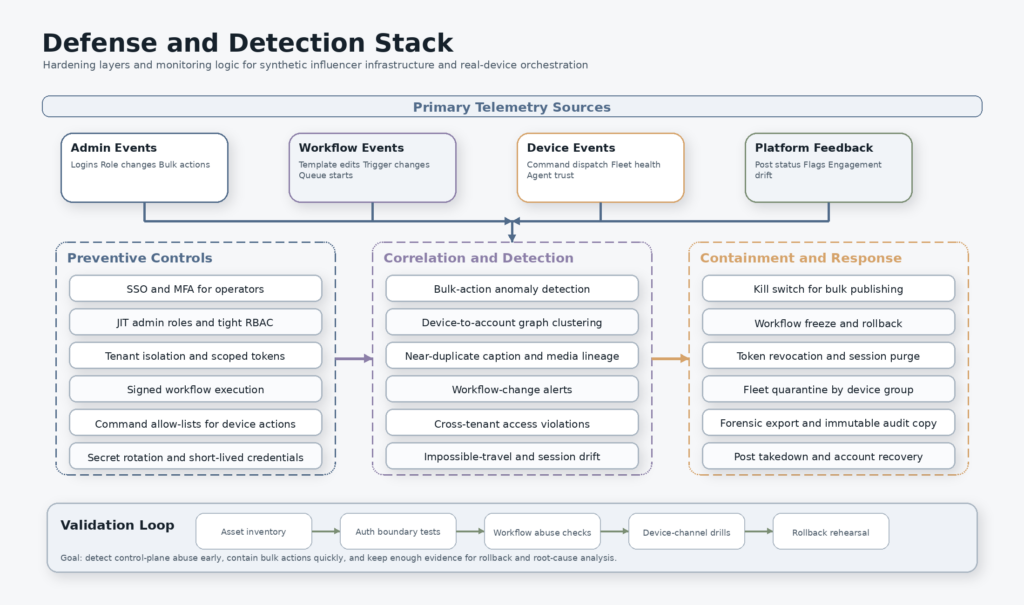
Security validation for social automation backends

If you operate any form of social automation platform, creator orchestration stack, affiliate content engine, or influence-analytics product, you should be validating the backend like a high-risk management plane rather than a normal SaaS dashboard. The danger is not just that an attacker steals data. The danger is that a compromise lets an attacker drive, contaminate, or expose a fleet of synthetic identities and real devices.
The right place to start is asset inventory. You need a complete list of admin panels, staging hosts, API domains, device-bridge services, media buckets, analytics endpoints, webhooks, identity providers, and message brokers. Many teams inventory the customer-facing app and forget the operator-facing tooling. In a system like this, the operator-facing tooling is the point. If an attacker can find a forgotten admin hostname, a debug interface, or a staging environment wired to live systems, that may be enough to bypass the front door.
The second step is authorization boundary testing. That means testing more than the login page. You should verify that unauthenticated requests cannot reach privileged endpoints, that low-privilege operators cannot call bulk actions, that customer tenants cannot read each other’s personas or campaign state, and that device-dispatch paths cannot be triggered from ordinary account-management roles. In an orchestration platform, the dangerous bugs are often not flashy. They are the “should have been forbidden” bugs: broken object-level authorization, hidden bulk endpoints, unsafe admin defaults, and stale session tokens that survive role changes.
A minimal regression test for privileged routes can be surprisingly useful. The following shell pattern is not an exploitation script. It is a simple way to ensure that sensitive routes consistently return denial rather than accidental exposure when requested without valid authorization.
BASE_URL="https://admin.example.com"
while read -r path; do
code=$(curl -sk -o /dev/null -w "%{http_code}" "${BASE_URL}${path}")
printf "%s %s\n" "$code" "$path"
done <<'EOF'
/api/accounts/bulk-update
/api/posts/bulk-publish
/api/personas
/api/workflows
/api/devices/dispatch
/api/audit/export
EOF
The third step is workflow abuse testing. If your system includes a builder that chains models, triggers, content templates, or account actions, treat it as code execution by another name. You want to know whether low-trust inputs can alter high-trust automation, whether a persona or content template can poison shared flows, whether one tenant can cause another tenant’s automation to run, and whether the review process for sensitive workflows is actually enforced. A workflow builder that can turn trending content into variations at scale is powerful. It is also exactly the kind of component that amplifies small permission mistakes into large operational failures. Doublespeed’s own public site advertises this kind of capability directly. (Doublespeed)
The fourth step is device-channel hardening. If real phones or remote agents are involved, the control path to those devices must be treated as critical infrastructure. That means strong mutual authentication, narrow command scopes, replay protection, key rotation, and clear separation between monitoring and control actions. A device bridge that accepts broad instructions from a compromised backend becomes an industrial sabotage path, not just a bad API. The December 2025 404 Media report is instructive here because it framed the compromise in terms of control over more than 1,000 smartphones, not just access to data. (404 Media)
The fifth step is evidence quality. You need enough immutable logging and audit context to answer uncomfortable questions after an incident. Which operator session edited which workflow? Which token published which content? Which persona template changed? Which device group received commands? Which campaign objects were exported? Which secrets were accessed? Without that evidence, you cannot tell the difference between a prank, a sabotage event, a customer dispute, or a systemic backend compromise.
On the validation side, what matters is not magical autonomy. It is operator-controlled repeatability. Penligent’s public materials emphasize end-to-end AI pentesting from asset discovery to validation, automated attack-surface mapping, baseline probing, sensitive API discovery, authenticated flow testing, and evidence-chain reporting. That is the right general shape for testing orchestration backends and admin APIs, provided the scope is locked, the targets are authorized, and human reviewers are still making the final call on what is real. (Penligent)
That last condition matters. Penligent’s public pricing page also states that the product is for authorized security testing only and requires explicit permission from the target owner. That is exactly the right framing for this category of work. Systems that can move quickly from asset discovery to workflow validation are useful. Systems used without authorization are simply part of the problem. (Penligent)
Control plane CVEs and why they matter here
There is no public CVE attached to the Doublespeed incidents, and there is no reason to invent one. But adjacent management-plane vulnerabilities are still useful because they show the same structural lesson: when one backend controls many endpoints, a single auth or command flaw becomes a force multiplier.
Fortinet’s advisory for CVE-2024-47575 is the cleanest example. Fortinet describes it as missing authentication in fgfmsd, rates it critical, says it is known exploited, and states that the impact is execution of unauthorized code or commands. That bug was not about a social media content farm. It was about a management plane. The reason it matters here is architectural, not brand-specific: when the centralized manager is compromised, the blast radius grows with everything it administers. (מעבדות FortiGuard)
Ivanti Endpoint Manager Mobile provides an even tighter analogy to the device-management side of this story. NVD describes CVE-2025-4427 as an authentication bypass in the API component of Ivanti EPMM that allows attackers to access protected resources without proper credentials. NVD describes CVE-2025-4428 as a code injection vulnerability that allows authenticated attackers to execute arbitrary code via crafted API requests, and notes that CVE-2025-4428 is in CISA’s Known Exploited Vulnerabilities Catalog. The technical details are different from anything publicly confirmed in the Doublespeed case. The strategic lesson is the same: a mobile-management backend is a juicy target because it concentrates access to fleets of managed devices and the APIs that govern them. (NVD)
These examples help for two reasons. First, they remind defenders not to wait for a glamorous AI-specific exploit category. Ordinary authentication and control-plane flaws are often enough. Second, they make the risk concrete for buyers and engineers who still hear “phone farm” and imagine a low-tech warehouse problem rather than a security architecture problem. The dangerous part is not the rack of phones. The dangerous part is the administrative surface that binds them together.
A short comparison makes the point clearer. (מעבדות FortiGuard)
| CVE | Product type | Publicly described weakness | מדוע זה חשוב במקרה זה |
|---|---|---|---|
| CVE-2024-47575 | Centralized management plane | Missing authentication, known exploited, unauthorized code or commands | Shows how catastrophic a management-plane auth failure can be |
| CVE-2025-4427 | Mobile device management API | Authentication bypass in API component | Illustrates how weak API authorization can expose protected control paths |
| CVE-2025-4428 | Mobile device management API | Code injection leading to remote code execution, known exploited via KEV listing | Shows how API flaws in device-management software can become operational takeover |
The honest takeaway is narrower and stronger than hype. You do not need an “AI zero-day” to compromise an AI-enabled influence system. You just need to compromise the part that coordinates the fleet.
Undisclosed synthetic endorsements and the FTC angle
The Doublespeed story is not just a platform integrity issue. It also brushes up against an advertising and consumer-protection problem. In the December 2025 report, 404 Media wrote that the hack revealed products being promoted by AI-generated accounts, often without the required disclosure that the content was advertising. Separately, the FTC’s endorsement guidance states that endorsements must be honest and not misleading and that material connections between advertisers and endorsers must be disclosed. The FTC’s public materials are written with ordinary influencers in mind, but the principle is broader: if a message looks like an independent recommendation and is actually advertising, the lack of disclosure matters. (404 Media)
This matters because synthetic influencer infrastructure creates a tempting compliance fiction. Operators may assume the disclosure rules apply to human creators, while synthetic personas are just “content assets.” That is the wrong way to think about it. The public policy question is not whether the face is generated. The question is whether the consumer is being misled about authorship, independence, sponsorship, or genuine experience. If a fake persona is being used to simulate authentic endorsement, the deception risk does not disappear because a model helped write the script.
For security buyers, this is more than a legal footnote. It changes due diligence. A vendor promising AI-driven creator automation or synthetic persona deployment should be evaluated not only for account security and platform risk, but also for disclosure handling, brand safety controls, auditability, and who has authority to launch campaigns without human review. The backend that publishes undisclosed promotions is not just a moderation risk. It is a liability surface.
Why OpenAI’s threat reports matter to this story
OpenAI’s February 2026 threat report is valuable here not because it mentions Doublespeed, but because it articulates a broader pattern that fits the case almost perfectly. OpenAI writes that malicious actors typically use AI in combination with other, more traditional tools such as websites and social media accounts, and that the activity is seldom limited to one platform or one AI model. That framing helps explain why the most important thing about an AI content factory is not the model name. It is the workflow that turns models, web infrastructure, identities, and platform accounts into a repeatable operation. (OpenAI)
That has two practical implications. The first is that defenders should stop looking for single-tool explanations. An operation can use one model for script generation, another for images, a workflow system for assembly, human editors for final smoothing, device fleets for execution, and external analytics for optimization. The second is that the backend becomes the point where all of those pieces touch. That makes it the place where you are most likely to find secrets, logs, templates, scheduling data, persona definitions, and cross-platform linkage.
This is also why the current wave of discussion about “AI influence” often feels shallow. People jump straight to model capabilities and ignore the surrounding stack. But the surrounding stack is where the persistence comes from. Without accounts, device trust, deployment logic, and analytics, a model is just a generator. With them, it becomes part of an operation.

Common mistakes when investigating synthetic influencer networks
The first common mistake is treating every synthetic persona as the same thing. A disclosed virtual spokesperson, a harmless fictional mascot, an undisclosed commercial shill, a fake-engagement ring, and a covert influence network are not identical. Platforms themselves distinguish between these categories because the intent, coordination, visibility, and harm models differ. TikTok explicitly says many deceptive behaviors are not covert influence operations, even when they touch similar topics, and Meta’s CIB framework centers strategic manipulation where fake accounts are core to the operation. A serious analyst should keep those categories separate even when the underlying tooling overlaps. (TikTok Newsroom)
The second mistake is assuming the problem is “AI content” rather than “AI-enabled operations.” A low-quality synthetic video is easy to mock. A coordinated system that can spin up personas, route content through device-backed accounts, learn from engagement, and adapt faster than manual moderation is much more important. The difference is the control plane. The backend is what turns a pile of generated assets into an operating system for narrative distribution.
The third mistake is believing content inspection alone will solve the problem. It will not. Not if the operator has variation pipelines, human fine-tuning, and enough account diversity to survive basic duplicate detection. You need content lineage, device linkage, workflow telemetry, and privileged action monitoring together. That is not glamorous, but it is how you catch the real thing.
The fourth mistake is treating this as only a social platform problem. Marketing agencies, affiliate programs, app-growth teams, e-commerce sellers, and brands buying “creator scale” services all touch adjacent risk. If a vendor’s operating model depends on large-scale persona automation and device-backed deployment, the customer should ask who controls the backend, how campaigns are approved, how disclosures work, how logs are stored, what a compromise would expose, and whether the vendor can demonstrate real authorization boundaries.
The fifth mistake is waiting for a named CVE before acting. Control-plane systems fail in many boring ways: bad RBAC, shared secrets, weak operator hygiene, stale sessions, misconfigured queues, exposed admin paths, unsafe webhooks, and poor tenant isolation. The adjacent CVEs are helpful because they illustrate how central managers fail. They are not prerequisites for concern.
What the Doublespeed story changes
The strongest takeaway from this case is that AI-enabled content manipulation should be studied as infrastructure, not just media. The headlines emphasized the absurdity of the attempted meme post. The public site and the repeated compromises tell a deeper story. A modern synthetic influencer factory can be modeled as a stack with identity, content, workflow, execution, and feedback layers. Each layer creates its own security and abuse risks. The backend is where they meet. (404 Media)
For trust and safety teams, the lesson is to shift some attention away from “does this post look AI-generated” and toward “what technical and behavioral signals indicate a coordinated account-and-device operation.” For security teams, the lesson is to treat operator backends and workflow builders as high-value targets rather than internal convenience tools. For buyers, the lesson is to audit any vendor selling scale, automation, and influence under creator-friendly language. For researchers, the lesson is that stories like this are valuable because they briefly reveal the control plane that usually stays hidden behind the output.
The larger shift is conceptual. In 2026, the interesting AI abuse stories are less about one model doing one bad thing and more about how ordinary software categories are being reassembled around models. A phone farm plus workflows plus personas plus content generation plus analytics is not science fiction. It is a product category. That product category deserves the same kind of scrutiny security teams already apply to identity systems, mobile management planes, CI/CD platforms, and customer-support tooling. The fact that the visible surface is social content does not make the backend any less security-critical.
The most important sentence in this whole discussion is probably the simplest one. This incident matters not because a phone farm got hacked, but because the hack briefly exposed the control plane of an AI-generated influence factory.
קריאה נוספת ומקורות
- 404 Media, Hacker Compromises a16z-Backed Phone Farm, Tries to Post Memes Calling a16z the Antichrist (404 Media)
- 404 Media, a16z-Backed Startup Sells Thousands of Synthetic Influencers to Manipulate Social Media as a Service (404 Media)
- 404 Media, Hack Reveals the a16z-Backed Phone Farm Flooding TikTok With AI Influencers (404 Media)
- Doublespeed, doublespeed.ai public product site (Doublespeed)
- a16z Speedrun, Doublespeed company profile (A16Z Speedrun)
- TikTok Newsroom, How TikTok counters deceptive behaviour (TikTok Newsroom)
- Meta, July 2021 Coordinated Inauthentic Behavior Report (About Facebook)
- OpenAI, Disrupting malicious uses of AI (OpenAI)
- FTC, Endorsements, Influencers, and Reviews (Federal Trade Commission)
- FTC, FTC’s Endorsement Guides, What People Are Asking (Federal Trade Commission)
- צוות התגובה לאירועי אבטחה של Fortinet (PSIRT), CVE-2024-47575 advisory (מעבדות FortiGuard)
- NVD, CVE-2025-4427 (NVD)
- NVD, CVE-2025-4428 (NVD)
- Penligent homepage (Penligent)
- Penligent pricing and public feature overview (Penligent)
- פנליג'נט, Overview of Penligent.ai’s Automated Penetration Testing Tool (Penligent)
- פנליג'נט, מתקפות סייבר מסוג "Agentic" מצריכות בדיקות חדירות מבוססות בינה מלאכותית מאומתות (Penligent)

