ניתן לחוש בפילוג בחדר: מחצית הצוות מחייכת משום שהסריקות האוטומטיות מאפשרות כיסוי מהיר יותר; המחצית השנייה מכווצת את גבותיה משום שהאוטומציה גם עושה טעויות בקנה מידה ארגוני. ירידה sqlmap לצינור מונע בינה מלאכותית, והפער הזה הופך לתהום. אתה מקבל טווח הגעה וחזרות — וגם את הפוטנציאל להפעיל סריקות רועשות או לא מורשות באמצעות פקודה אחת, מזדמנת.
זו לא בהלה מוסרית. זה מתח מעשי. sqlmap הוא כלי: בוגר, ישיר, ומאוד טוב בחשיפת אותות הזרקה. אם אתה נותן למודל להפעיל sqlmap עבודה ואז תשכח מה היא עשתה, תראה שלוש תוצאות בפועל:
תגליות שימושיות שבהן בדיקת הזרקה מדגישה פגם לוגי אמיתי;
• תוצאות חיוביות כוזבות הגוזלות שעות עבודה של אנליסטים;
• ולעיתים רחוקות, תקלות תפעוליות כאשר סריקה פוגעת באופן בלתי צפוי בייצור.
המעניין הוא לא האם כלים כמו sqlmap האם הם טובים או רעים — הם מה שהם — אלא איך לשלב אותם בתהליך שמאפשר שיקול דעת אנושי ופיקוח. כאן הדיון נהיה מעניין: האם עלינו לסמוך על בינה מלאכותית שתכתוב ותפעיל פקודות סריקה? או שמא יש להתייחס לבינה מלאכותית כאל אנליסט זוטר שמציע בדיקות, כאשר בני האדם הם אלה שמאשרים אותן בסופו של דבר?
להלן אני מתאר פרספקטיבה מאוזנת, עם מודול קוד מינימלי ובטוח כדי להראות כיצד צריכה להיראות אוטומציה (ללא ניצול, תזמור בלבד), בנוסף למחסומים המעשיים שאתם באמת צריכים.
תזמור ברמה גבוהה
חשבו על זה כעל הצנרת שצריכה להיות בין הפקודה של ה-AI לבין כל סורק. היא לעולם לא מכילה מטעני ניצול — רק כוונה, היקף ושלבי ניתוח.
# תזמור מדומה: AI מציע בדיקות, המערכת אוכפת מדיניות, המנתח מבצע מיון def request_scan(user_prompt, target_list): intent = ai_interpret(user_prompt) # לדוגמה, "בדוק סיכון SQLi" scope = policy.enforce_scope(target_list, intent)
אם לא scope.authorized: החזר "הסריקה לא מאושרת עבור היעדים המבוקשים." job = scheduler.create_job(scope, mode="non-destructive") # הסורק מופעל באמצעות רץ מבוקר שמאכוף כללים run = scanner_runner.execute(job, scanner="sqlmap-wrapper", safe_mode=True)
telemetry = collector.gather(run, include_logs=True, include_app_context=True) findings = analyzer.correlate(telemetry, ruleset="multi-signal") report = reporter.build(findings, prioritize=True, require_human_review=True) return report
הערות על הקוד המדומה לעיל:
ה sqlmap-wrapper הוא שכבה קונספטואלית המטילה מצבים לא הרסניים ומגבלות קצב;
מנתח.קורלציה פירושו "אל תסתמך רק על תוצאות הסורק — בדוק שוב באמצעות יומני WAF, עקבות שגיאות DB וטלמטריה של האפליקציה".

מדוע העטיפה חשובה
תוצאת הסורק הגולמית היא האזנת סתר רועשת. יחיד sqlmap הפעלה יכולה לייצר עשרות שורות "מעניינות" שהן, בהקשרן, בלתי מזיקות.
עטיפה מעוצבת היטב עושה שלוש דברים:
אכיפת היקף — רק יעדים מותרים, רק סביבות מורשות; ללא סריקות ייצור מקריות.
מצבי בטיחות ומגבלות קצב — כפה אפשרויות לא הרסניות, הגבל בקשות כדי למנוע השפעה על זמן הפעילות.
קורלציה קונטקסטואלית — התאם את תוצאות הסורק לאותות בזמן ריצה (חסימות WAF, שגיאות DB, חביון חריג) לפני שתעניק לציון מהימנות גבוה.
Penligent ממוקמת בדיוק בשכבת הקורלציה והמיון.
הוא לא מעודד את פלט הסורק הגולמי. הוא מעכל אותו, משווה אותו לנתוני הטלמטריה, ואומר:
"זה שווה כרטיס כי זה תואם לשגיאות DB + התראות WAF."
או: "כנראה רעש — יש לאמת לפני שמסלימים את העניין."
המחלוקת: דמוקרטיזציה לעומת נשק
זה המקום שבו הדעות מתחממות. האוטומציה מורידה את הרף לבדיקות — זהו טיעון הדמוקרטיזציה, והוא נכון.
צוותי אבטחה וצוותי פיתוח קטנים יכולים לקבל כיסוי משמעותי במהירות.
אך אותה קלות שימוש מגבירה את הסיכוי לשימוש לא נכון בשוגג.
אתה יכול לדמיין הודעת Slack שנשלחה בחיפזון והופכת לסריקה רחבה ורועשת.
או מודל שלא כוונן כראוי, המציע בדיקה אגרסיבית עבור נקודת קצה רגישה.
אם אתם עושים זאת, יש שתי שאלות חשובות:
- מי יכול לבקש סריקה? (כללי אישור + אימות)
- מי חותם על כרטיס התיקון? (מהנדסים עם הקשר, לא בוט אוטומטי)
התייחסו ל-AI כאל מכפיל פרודוקטיביות, ולא כאל תחליף לממשל.
רשימת בדיקה מעשית למחסומים (לצוותים המעוניינים במהירות ובטיחות)
- אישור ראשון: סריקות רק לאחר אישור מאומת, מתועד וניתן לבדיקה.
- ברירות מחדל לא הרסניות שנכפו: עטיפה מחייבת בדיקות לקריאה בלבד והפסקות זמן שמרניות.
- מיון רב-אותות: פלט הסורק חייב להיות מותאם לפחות למקור אות אחד נוסף לפני קביעת סדר העדיפויות האוטומטי.
- שער אנושי בלולאה: פריטים בעלי חומרה קריטית דורשים אישור אנושי לפני תיקון או בדיקות קפדניות.
- משחקיות חוזרת וראיות: יומני בקשות/תגובות מלאים וניתנים להפעלה חוזרת, בתוספת הקשר (גרסת האפליקציה, מנוע מסד הנתונים, כללי WAF).
- מגבלות קצב וטווח פיצוץ: מגבלות לכל יעד ומגבלות על ריבוי משימות גלובלי.
- כללי שמירה ופרטיות: סריקות הנוגעות למידע אישי מסווגות ומטופלות בהתאם למדיניות הגנת המידע.
היכן Penligent משתלב במחזור
Penligent אינו מחליף סורקים — הוא מיישם את התוצאות שלהם.
השתמש ב-Penligent כדי:
- הפוך כוונה של מבחן בשפה טבעית למשימה שנבדקה על פי מדיניות.
- הפעל בדיקות סורק מטוהרות (באמצעות עטיפות בטוחות).
- אסוף נתוני טלמטריה מרשומות האפליקציה, WAF, מסד הנתונים והרשת.
- קשרו בין אותות ופרסמו רק ממצאים בעלי רמת ודאות גבוהה עם צעדי תיקון.
החלק האחרון חשוב.
בעולם אוטומטי, מיון הופך למיומנות נדירה: להבחין בין בעיות אמיתיות לרעשי רקע.
Penligent מבצע אוטומציה של מיון, אך שומר על מעורבותו של הבודק האנושי בהחלטות בעלות השפעה רבה.
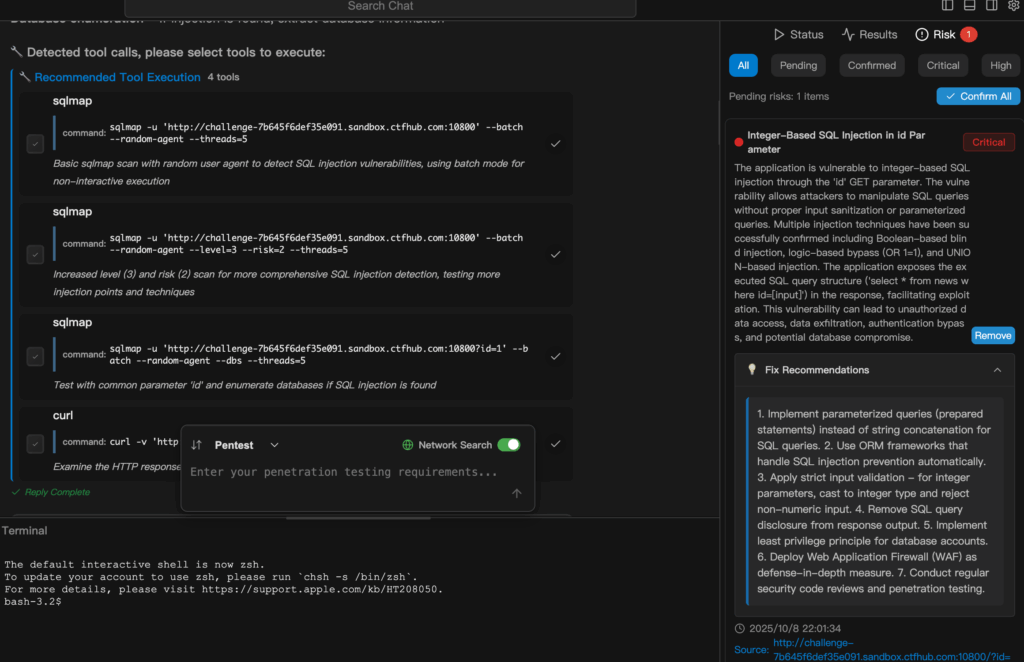
האמת הלא נעימה
האוטומציה תאתר יותר בעיות מהר יותר מאשר בני אדם לבדם.
זה נשמע נהדר — עד שאנשי הארגונים מבינים שזה גם יוצר יותר כרטיסים, יותר הפרעות ויותר פוטנציאל להשפעה מקרית.
המיומנות האמיתית היא לתכנן את זרימת העבודה כך שיחס האות לרעש ישתפר ככל שתתרחב, ולא יפגע.
אם אתה מתעקש על אמת מידה קונקרטית:
אוטומציה ללא המיון מגדיל את כמות התוצאות החיוביות השגויות ביחס ישיר לנפח הסריקה.
אוטומציה עם מיון מגביר את תפוקת התיקון בפועל.
ההבדל הוא בשכבת הניתוח.
הערה אחרונה — טיעון שראוי להעלות
יש שיאמרו "אסרו על סריקות שיוזמת הבינה המלאכותית" משום שהסיכונים הם קיומיים.
זו ראייה קצרת טווח. המטרה היא לא לאסור על השימוש ביכולות, אלא לבנות מעקות בטיחות כדי שהיכולות יסייעו למגנים ולא לתוקפים.
אם הארגון שלך אינו יכול ליישם מדיניות, ביקורת וקורלציה, אל תפעיל את מתג האוטומציה.
אם הדבר אפשרי, העלייה בפריון היא אמיתית: פחות שלבים ידניים, אימות מהיר יותר של השערות ומשוב טוב יותר בין זיהוי לתיקון.

