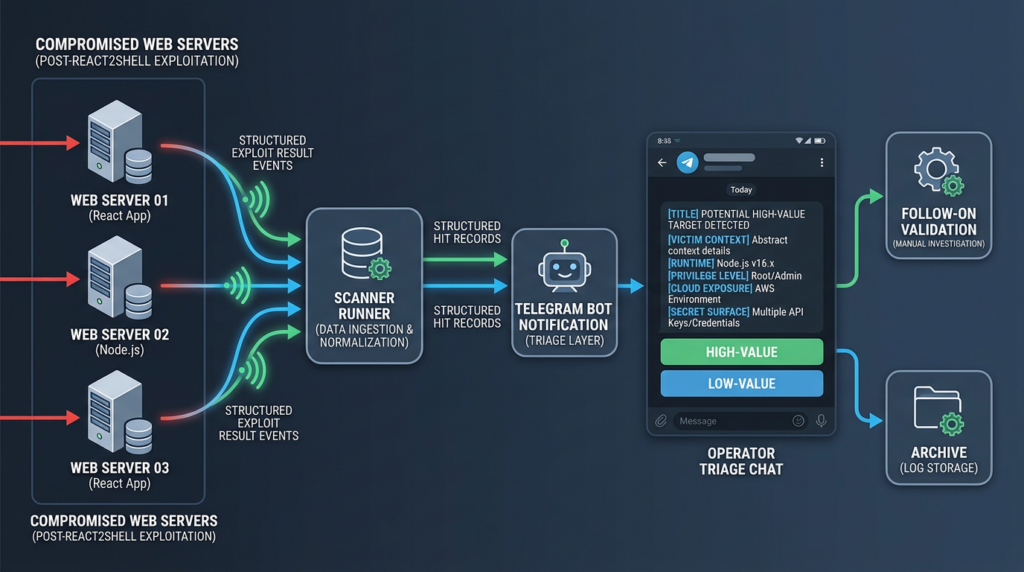
A newly exposed attacker server showed something more important than another round of React2Shell exploitation. It showed a working breach pipeline: target feeds, a scanner framework, an exploit module, .env harvesting, cloud storage, Telegram notifications, and operator-side triage. Cybersecurity News summarized the public reporting as a campaign in which hackers used automated tooling, AI assistance, and Telegram bots to track more than 900 successful React2Shell exploits. The underlying DFIR Report investigation is more revealing: the exposed host contained more than 13,000 files across 150-plus directories tied to exploitation, victim-data staging, credential harvesting, access validation, and workflow management. (साइबर सुरक्षा समाचार)
That distinction matters. The central lesson is not only that CVE-2025-55182 was a severe React Server Components vulnerability. It is that a high-impact framework bug can become the intake valve for a larger credential-harvesting operation. The attacker did not need every target to be equally valuable. They needed enough confirmed hits, enough secrets, and a fast way to separate ordinary compromises from victims with cloud keys, payment credentials, AI provider tokens, database access, identity-provider secrets, and source-control tokens. The Telegram bot was not a gimmick. It was the notification layer that turned exploit output into real-time breach triage. (The DFIR Report)
The DFIR Report named the platform “Bissa scanner” and described it as a mature, modular operation designed to exploit targets at scale, harvest and validate secrets, and use an AI-enabled workflow to improve collection and triage. Artifacts on the exposed host showed Claude Code and OpenClaw embedded in the operator’s day-to-day workflow, supporting troubleshooting, orchestration, and refinement of the collection pipeline. That does not mean an AI model autonomously hacked hundreds of companies. It means AI tooling was part of the attacker’s operating environment, much like shell scripts, scanners, storage buckets, and chat bots. (The DFIR Report)
The exposed server showed a breach operation, not a random scanner
The most useful way to read the Bissa scanner incident is to separate initial exploitation from operational conversion. Initial exploitation is the moment a vulnerable server accepts a malicious request and gives the attacker code execution or another useful primitive. Operational conversion is everything that happens next: collecting environment files, ranking victims, checking which keys work, deciding where to spend human attention, and preserving data for follow-on use.
The exposed server made that conversion layer visible. According to DFIR Report, the host was used for multi-victim exploitation, staging, review, and validation. Its files were not just a disorganized dump of stolen material. The structure showed scripts for exploitation, victim-data staging, credential harvesting, access validation, and operator workflow management. Logs indicated a large-scale React2Shell operation that scanned millions of targets and confirmed more than 900 successful exploits. (The DFIR Report)
Cybersecurity News highlighted the same core storyline in shorter news form: the operation used a tool called Bissa scanner to target internet-facing web applications, harvest sensitive credentials, and send successful exploit alerts to the attacker’s Telegram account. It also reported that the campaign targeted millions of web servers and pulled out .env files that often contain passwords, API keys, and access tokens. (साइबर सुरक्षा समाचार)
For defenders, the word “scanner” can be misleading. Many teams hear “scanner” and imagine noisy probes that rarely matter. Bissa scanner looks closer to an attacker acquisition system. It consumed target feeds, assigned an exploit module, executed collection logic, stored results, and pushed confirmed hits into a notification channel. That resembles a sales pipeline more than a one-off exploit script: source leads, qualify leads, enrich records, score value, route the best opportunities to an operator.
The operator also appeared to think in terms of reusable workflow. DFIR Report found references to acquirer files, lease files, exploit modules, local result directories, cloud archive buckets, and Telegram-linked bot infrastructure. That kind of structure is what allows a campaign to scale past what one human can watch manually. The attacker’s advantage came from connecting ordinary pieces into an end-to-end system.
What React2Shell gave the attacker
React2Shell is the common name for CVE-2025-55182, a critical vulnerability in React Server Components. NVD describes it as a pre-authentication remote code execution vulnerability affecting React Server Components versions 19.0.0, 19.1.0, 19.1.1, and 19.2.0, including react-server-dom-parcel, react-server-dom-turbopack, और react-server-dom-webpack. The vulnerable code unsafely deserializes payloads from HTTP requests to Server Function endpoints. (एनवीडी.एनआईएसटी.जीओवी)
React’s own advisory was direct. The React team stated that the vulnerability allowed unauthenticated remote code execution by exploiting a flaw in how React decodes payloads sent to React Server Function endpoints. The advisory also warned that an application may still be vulnerable even if it does not explicitly implement Server Function endpoints, as long as it supports React Server Components. The initial fixed React versions were 19.0.1, 19.1.2, and 19.2.1. (react.dev)
The practical reason React2Shell became dangerous at scale is that it sat at a framework boundary. React Server Components are not just browser UI code. They introduce a client-server protocol surface where structured client requests are interpreted by server-side framework code. When that boundary fails, an attacker does not necessarily need an application-specific bug in a business route. The vulnerable behavior can live below the application’s business logic, inside the framework machinery that many engineers do not inspect closely.
Microsoft summarized why the risk was unusually high: default configurations could be vulnerable without special setup or developer error, public proof-of-concept exploits were readily available with near-100 percent reliability, exploitation required no user authentication, and a single malicious HTTP request could be enough. (माइक्रोसॉफ्ट)
That is exactly the kind of vulnerability attackers like to industrialize. A good mass-exploitation primitive has several properties. It is remotely reachable. It does not require credentials. It affects a popular stack. It can be tested automatically. It produces useful post-exploitation access. It is easy to explain to tooling. React2Shell met enough of those conditions to attract state-linked groups, financially motivated actors, opportunistic scanners, malware operators, and now exposed credential-harvesting infrastructure. Google Threat Intelligence Group reported widespread exploitation across many threat clusters shortly after public disclosure, ranging from opportunistic cybercrime actors to suspected espionage groups. (गूगल क्लाउड)
The CVE map defenders need to keep straight
The core identifier is CVE-2025-55182. It tracks the upstream React Server Components issue. Next.js had a related downstream advisory, and public discussion often included CVE-2025-66478, but multiple sources later treated that Next.js identifier as a duplicate of CVE-2025-55182 because the root cause was the same upstream React issue. Rapid7 explained that CVE-2025-66478 was assigned for the Next.js context but later rejected as a duplicate of CVE-2025-55182. (रैपिड7)
Next.js users still needed separate operational guidance because framework versions, routing modes, and deployment patterns mattered. The GitHub advisory for Next.js listed affected versions as >=14.3.0-canary.77, >=15, और >=16, with patched versions including v15.0.5, v15.1.9, v15.2.6, v15.3.6, v15.4.8, v15.5.7, and v16.0.7, along with patched canary releases. (गिटहब)
React’s follow-up update also matters. The React advisory was later updated to include additional React Server Components vulnerabilities: CVE-2025-55183 for source code exposure, CVE-2025-55184 and CVE-2025-67779 for denial of service, and CVE-2026-23864 for another denial-of-service issue. React’s January 26, 2026 update provided newer Next.js upgrade guidance across release lines, including 14.2.35, 15.0.8, 15.1.12, 15.2.9, 15.3.9, 15.4.11, 15.5.10, 16.0.11, and 16.1.5. (react.dev)
| Identifier | What it represents | Why it matters in response |
|---|---|---|
| सीवीई-2025-55182 | Upstream React Server Components pre-auth RCE | The canonical React2Shell identifier |
| सीवीई-2025-66478 | Next.js downstream tracking identifier | Often appears in older alerts and tools, but should be mapped back to CVE-2025-55182 |
| CVE-2025-55183 | RSC source code exposure | Relevant when teams are cleaning up beyond the first RCE patch |
| CVE-2025-55184 | RSC denial of service | Requires broader patch review for RSC environments |
| CVE-2025-67779 | RSC denial of service related to incomplete remediation | Shows why “we patched once” may not be enough |
| CVE-2026-23864 | Later RSC denial-of-service issue | Relevant for teams still standardizing React and Next.js baselines |
The mistake to avoid is treating these identifiers as separate queues owned by separate teams. A React platform team may track CVE-2025-55182. A Next.js application team may track CVE-2025-66478. An infrastructure team may only see WAF detections labeled “React2Shell.” Incident response breaks when those names do not converge into one exposure model.
The Bissa scanner workflow
DFIR Report’s recovered artifacts described a React2Shell exploitation workflow built around Bissa scanner. The scanner relied on an acquirer file containing targets and a lease file defining the exploit type. Those files showed the operator obtaining target feeds from ZIP archives, assigning the cve_2025_55182 module, and deploying a payload intended to enumerate .env files, cloud metadata, Kubernetes service account context, local credential stores, database and Redis access, cryptocurrency wallet material, and other high-value secrets. (The DFIR Report)
A safe defender-level model of the pipeline looks like this:
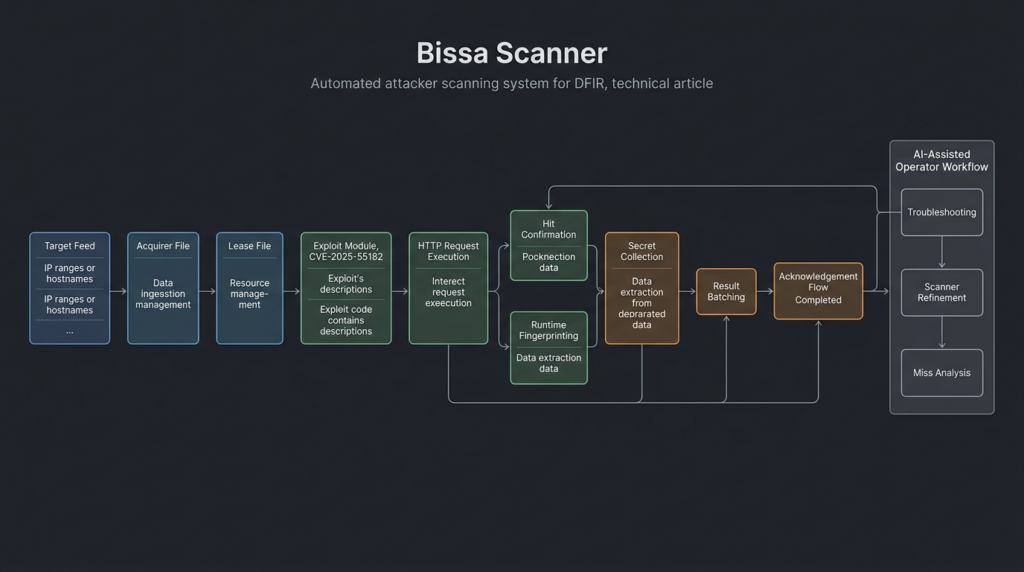
That model explains why .env files mattered so much. Remote code execution is powerful, but RCE itself is often only a temporary foothold. Secrets are portable. A stolen cloud key may outlive the vulnerable server. A GitHub token may lead to source code and CI/CD secrets. A Stripe or PayPal key may expose payment workflows. An AI provider token may create immediate cost abuse. A database URI may grant direct access to customer data. The attacker’s goal was not simply to prove exploitation. It was to convert exploitation into durable access and business value.
The cloud archive layer reinforces that point. DFIR Report said the operator used S3-compatible Filebase as an off-box archive for harvested victim .env files. The scanner watched a local results/ directory, batched .env files into ZIPs, and uploaded them to a Filebase bucket under an archives/ prefix. The recovered bucket history showed hundreds of raw env-batch-*.zip objects, more than 30,000 distinct .env filenames, and over 65,000 archived file entries between April 10 and April 21, 2026. (The DFIR Report)
That is not casual looting. It is repeated batching, upload, retention, and reprocessing. The repeated re-batching of the same victim files suggests the operator was preserving and operationalizing results over time, not just grabbing files once and moving on.
Telegram bots turned successful exploits into a triage queue
The Telegram layer is one of the most important details in the reporting. DFIR Report found runner scripts across the Bissa scanner harness with a hardcoded Telegram bot token tied to @bissapwned_bot, along with a destination chat ID. It also found evidence suggesting a separate @bissa_scan_bot handle inside the AI-control subsystem. (The DFIR Report)
Each @bissapwned_bot message carried an identity header and delivered one line per confirmed CVE-2025-55182 hit. DFIR Report said each line distilled the victim’s identity, runtime context, privilege level, cloud posture, and recoverable secret surface into an at-a-glance record. That allowed the operator to triage hundreds of exploitation events directly from Telegram. (The DFIR Report)
This is the key operational shift:
Old model:
Exploit script writes local logs
Operator later reviews files manually
Bissa-style model:
Exploit framework confirms hit
Bot sends structured alert
Operator sees victim value immediately
High-value hits get follow-on attention
Telegram was not special because it is technically advanced. It was useful because it reduced friction. The operator did not need to tail logs, SSH into a box, open result directories, or parse raw scanner output after every batch. The bot converted scanner output into a human-readable feed. It likely made the difference between “we have lots of noisy hits” and “we can quickly spot the companies worth deeper attention.”
Defenders should take this seriously because attackers increasingly separate collection from triage. A vulnerability can be exploited at machine speed, but the most valuable decisions still involve prioritization. Which victim has cloud admin keys. Which .env contains production database credentials. Which company has payment keys. Which access should be validated first. A notification bot is a simple way to route those decisions to a human operator without slowing the scanner.
The secret categories show the real blast radius
DFIR Report said the credential haul spanned every tier of modern SaaS, with AI providers emerging as the single largest category. The reported categories included AI platforms such as Anthropic, Google, OpenAI, Mistral, OpenRouter, Groq, Replicate, DeepSeek, and HuggingFace; cloud providers such as AWS, Cloudflare, Azure, Google Cloud/Firebase, DigitalOcean, and Alchemy; messaging services such as Resend, Telegram, SendGrid, Twilio, Vonage, and Postmark; payment platforms such as Stripe, PayPal, Shopify, and Square; plus databases, source control, authentication providers, mobile revenue tools, mapping services, crypto custody providers, and Slack. (The DFIR Report)
That list is a map of modern application dependency. A compromised .env file can contain everything a runtime needs to talk to the outside world. In many organizations, those keys are not scoped tightly enough, not rotated often enough, and not monitored carefully enough. That turns a web framework RCE into a multi-platform identity problem.
| Secret type | Why attackers care | Likely defender impact |
|---|---|---|
| AI provider API keys | Immediate billing abuse, model access, possible data-path exposure | Cost spikes, policy violations, potential data handling concerns |
| Cloud access keys | Resource creation, storage access, IAM discovery, lateral movement | Cloud compromise, data theft, persistence, infrastructure abuse |
| Database URLs | Direct customer data access if network and credentials allow it | Data breach, data tampering, regulatory exposure |
| Payment provider keys | Access to payment settings, transaction metadata, platform workflows | Fraud risk, operational disruption, sensitive business-data exposure |
| Messaging provider tokens | Phishing, spam, account verification abuse, notification hijacking | Brand abuse, customer trust damage, fraud enablement |
| Source control tokens | Repository access, CI/CD workflow abuse, supply-chain risk | Code theft, secrets discovery, build pipeline compromise |
| Authentication secrets | Session signing, OAuth integration abuse, identity boundary failure | Account takeover, forged tokens, privilege escalation |
| Crypto custody keys | Transaction or wallet infrastructure risk depending on scope | Direct financial loss if high-privilege keys are exposed |
OWASP’s Secrets Management Cheat Sheet explains why centralized storage, provisioning, auditing, rotation, and management of secrets are necessary: services often share secrets, which makes it difficult to identify the source of compromise or leak. (cheatsheetseries.owasp.org)
The lesson is not that environment variables should never exist. In many platforms, environment variables are a common deployment mechanism. The lesson is that secrets stored in environment variables must be treated as high-risk runtime material, not as harmless configuration. They need least privilege, short lifetimes where possible, controlled injection, audit trails, rotation plans, and emergency revocation.
AI assistance was part of the attacker’s operating environment
The AI angle in this incident needs careful wording. It would be inaccurate to reduce the story to “AI hacked 900 companies.” The public evidence supports a narrower and more useful conclusion: AI-assisted tools were embedded in the operator’s workflow.
DFIR Report said Claude Code and OpenClaw were present on the exposed host and supported troubleshooting, orchestration, and refinement of the collection pipeline. The report also said Claude project transcripts showed the operator using Claude Code to read the scanner codebase, understand lease and acknowledgement flow, troubleshoot misses, review benchmark output, and document the project well enough to rebuild parts of the acquisition layer. OpenClaw logs showed a local AI-control surface with a websocket gateway, browser control, model settings, and Telegram-linked provider handle. (The DFIR Report)
That is how AI is likely to show up in many real offensive workflows: not as a single magic exploit generator, but as glue inside operations. An attacker can use an assistant to inspect code, summarize logs, compare failed runs, generate shell glue, reason about target categorization, or maintain documentation. Those tasks are mundane, but they compound. A scanner that improves faster, misses fewer targets, and produces cleaner alerts is more dangerous than a chaotic pile of scripts.
The same point applies defensively. A security team does not become safer by asking a model if a CVE matters. It becomes safer when it connects asset discovery, dependency inventory, runtime telemetry, controlled validation, secret scanning, credential rotation, and evidence capture into one repeatable process. AI can help in that process, but only if the workflow forces verification instead of accepting confident text as truth.
Why React2Shell drew fast exploitation
React2Shell had the traits of a high-velocity vulnerability. It affected popular framework paths, required no authentication, and could be reached over HTTP in vulnerable deployments. Google Threat Intelligence Group reported that after the December 3, 2025 disclosure, it observed widespread exploitation by multiple threat clusters, including opportunistic cybercrime actors and suspected espionage groups. Google also observed payloads and post-compromise behaviors that included tunneling tools, downloaders, backdoors, and XMRig cryptocurrency miners. (गूगल क्लाउड)
AWS Security reported that CVE-2025-55182 was an unsafe deserialization vulnerability in React Server Components, discovered by Lachlan Davidson and disclosed to the React Team on November 29, 2025. AWS listed key facts: CVSS 10.0, unauthenticated remote code execution, affected React Server Components in React 19.x and Next.js 15.x/16.x with App Router, and the critical detail that applications could be vulnerable even without explicitly using server functions if they supported React Server Components. (अमेज़न वेब सर्विसेज़, इंक.)
NVD’s page also records that CVE-2025-55182 was added to CISA’s Known Exploited Vulnerabilities catalog on December 5, 2025, with required action to apply mitigations per vendor instructions or discontinue use if mitigations were unavailable. (एनवीडी.एनआईएसटी.जीओवी)
Attackers responded the way attackers usually respond to a critical, internet-reachable, unauthenticated RCE: they tested it quickly, shared tooling, copied payload logic, mixed real and fake exploits, and moved into post-exploitation. Google specifically warned that there were many non-functional exploits and false claims during the first days after disclosure, alongside legitimate exploit code and even malware targeting security researchers. (गूगल क्लाउड)
That last point matters for defenders and researchers. Downloading random proof-of-concept repositories during a high-profile CVE response is itself a risk. Treat PoCs as untrusted code. Review them offline. Run them in throwaway environments. Never execute them on a workstation that holds production credentials, cloud sessions, SSH keys, browser profiles, or source code access.
Exposure checks for React and Next.js estates
The first defensive job is not to run a live exploit. It is to build an exposure inventory. For React2Shell, that means finding vulnerable React Server Components packages, affected Next.js versions, RSC-enabled frameworks, internet-facing routes, and deployments that may not match the repository state.
Start with package inventory:
npm ls next react react-dom \
react-server-dom-webpack \
react-server-dom-parcel \
react-server-dom-turbopack
For pnpm:
pnpm why next
pnpm why react-server-dom-webpack
pnpm why react-server-dom-parcel
pnpm why react-server-dom-turbopack
For Yarn:
yarn why next
yarn why react-server-dom-webpack
yarn why react-server-dom-parcel
yarn why react-server-dom-turbopack
Search lockfiles across monorepos:
find . -maxdepth 4 \( \
-name package-lock.json -o \
-name pnpm-lock.yaml -o \
-name yarn.lock \
\) -print0 | xargs -0 grep -En \
'react-server-dom-(webpack|parcel|turbopack)|next@|next:'
Search application manifests:
find . -maxdepth 5 -name package.json -print0 \
| xargs -0 grep -En '"next"|"react-server-dom-webpack"|"react-server-dom-parcel"|"react-server-dom-turbopack"'
For containerized environments, do not trust the repository alone. Inspect the deployed image:
docker run --rm --entrypoint sh your-image:tag -c '
node -v 2>/dev/null || true
npm ls next react react-dom react-server-dom-webpack react-server-dom-parcel react-server-dom-turbopack 2>/dev/null || true
'
If the container does not include npm metadata, inspect filesystem traces carefully:
docker run --rm --entrypoint sh your-image:tag -c '
find /app -maxdepth 5 -type f \( -name package.json -o -name package-lock.json -o -name pnpm-lock.yaml \) -print
'
The exposure decision should not stop at “package exists.” Ask whether the application uses React Server Components, whether it runs Next.js App Router, whether the affected route is reachable from the internet, whether the vulnerable version is actually deployed, and whether the service was online during known exploitation windows. React’s advisory explicitly says that applications not using server-side React code and applications not using a framework, bundler, or plugin that supports React Server Components are not affected by this vulnerability. (react.dev)
Log hunting without publishing exploit payloads
Defenders can hunt for suspicious RSC traffic without copying weaponized payloads. The goal is to look for unusual request patterns, suspicious content types, unexpected server-action traffic, anomalous POST bursts, and post-exploitation behavior.
For Nginx access logs:
grep -Ei 'POST|text/x-component|_rsc|server action|server-action|react-server' \
/var/log/nginx/access.log* \
| head -200
For compressed logs:
zgrep -Ei 'POST|text/x-component|_rsc|server action|server-action|react-server' \
/var/log/nginx/access.log*.gz \
| head -200
For JSON application logs:
jq -r '
select(
(.method == "POST") and
(
(.headers["content-type"]? // "" | test("text/x-component|multipart|octet-stream"; "i")) or
(.path? // "" | test("_rsc|server"; "i"))
)
)
' app.log
Those searches do not prove exploitation. They identify traffic worth reviewing against application behavior, deployment dates, WAF events, and process telemetry. A React or Next.js application may legitimately use RSC-related request patterns. The suspicious signal comes from combinations: unusual POST bodies, routes that should not be public, high request volume from scanning infrastructure, errors followed by success responses, and runtime behavior that the app should never produce.
The stronger post-exploitation signals are often outside HTTP. Look for a Node.js web process spawning shell utilities, downloaders, interpreters, miners, or persistence mechanisms. Unit 42 reported post-exploitation activity after CVE-2025-55182 that included reconnaissance, privilege checks, network interface mapping, credential and DNS enumeration, and download of malicious binaries using tools such as डब्ल्यूगेट और घुमाव. (इकाई 42)
Process telemetry that catches the next stage
A useful detection pattern for web RCE is parent-child process anomaly. Production Node.js web servers should rarely spawn दे घुमा के, श, घुमाव, डब्ल्यूगेट, अजगर, perl, nc, chmod, crontab, or package managers during normal request handling. Some build systems and server-side rendering workflows complicate this rule, but it remains a strong triage signal.
A Sigma-style rule can capture the idea:
title: Node.js Web Process Spawning Suspicious Shell Utilities
id: 8b2a4b44-7a3d-4c2d-9b52-react2shell-post-exec
status: experimental
description: Detects Node.js or Next.js runtime processes spawning shell utilities commonly used after web RCE.
logsource:
product: linux
category: process_creation
detection:
selection_parent:
ParentImage|endswith:
- '/node'
- '/next-server'
- '/npm'
selection_child:
Image|endswith:
- '/sh'
- '/bash'
- '/curl'
- '/wget'
- '/python'
- '/python3'
- '/perl'
- '/nc'
- '/ncat'
- '/chmod'
- '/crontab'
condition: selection_parent and selection_child
fields:
- UtcTime
- Hostname
- User
- ParentImage
- ParentCommandLine
- Image
- CommandLine
falsepositives:
- Build pipelines running on the same host as production
- Misconfigured runtime that performs dependency installation at startup
level: high
For Microsoft Defender XDR style hunting, adapt the query to your table names and telemetry coverage:
DeviceProcessEvents
| where Timestamp > ago(30d)
| where InitiatingProcessFileName in~ ("node", "npm", "next-server")
| where FileName in~ ("sh", "bash", "curl", "wget", "python", "python3", "perl", "nc", "ncat", "chmod", "crontab")
| project Timestamp, DeviceName, InitiatingProcessCommandLine, FileName, ProcessCommandLine, AccountName
| order by Timestamp desc
For Linux audit logs, if process execution is available:
ausearch -x node -ts recent 2>/dev/null | aureport -x --summary
On Kubernetes, correlate pod logs, process events from runtime security tooling, egress connections, and secret access. If a compromised web pod reads service account context, cloud metadata, or mounted secrets, the attacker may not need to persist on the original web process. Kubernetes documentation recommends projected service account tokens because they expire automatically and are rotated by kubelet before expiration, unlike older long-lived service account token secrets. (Kubernetes)
Cloud and identity hunting after .env exposure
अगर .env files may have been exposed, the response must move beyond web logs. The attacker’s next step may use valid credentials from a different IP, region, user agent, or service. That activity may look like normal API access unless you understand expected usage.
For AWS CloudTrail, start with key and identity events:
eventSource = iam.amazonaws.com
AND eventName IN (
CreateAccessKey,
UpdateAccessKey,
AttachUserPolicy,
PutUserPolicy,
CreateUser,
CreateRole,
AssumeRole,
CreateLoginProfile
)
Then review unusual use of existing keys:
eventSource != signin.amazonaws.com
AND sourceIPAddress NOT LIKE 'your_known_cidr%'
AND userAgent NOT LIKE '%your_expected_agent%'
For Google Cloud, review service account key creation and IAM policy changes:
protoPayload.methodName="google.iam.admin.v1.CreateServiceAccountKey"
OR protoPayload.methodName="SetIamPolicy"
OR protoPayload.methodName:"serviceAccounts.keys.create"
For Azure, review application credentials, service principal changes, and role assignments:
AuditLogs
| where TimeGenerated > ago(30d)
| where OperationName has_any ("Add service principal credentials", "Add app role assignment", "Add member to role")
| project TimeGenerated, OperationName, TargetResources, InitiatedBy, Result
For GitHub, review unusual token usage, new deploy keys, GitHub Actions secrets changes, workflow modifications, and repository access from unexpected IPs. GitHub’s secret scanning documentation states that secret scanning scans Git history across all branches for hardcoded credentials, API keys, passwords, tokens, and other known secret types. Push protection is designed to block supported secrets before they reach a repository. (GitHub दस्तावेज़)
Secret scanning is not enough after a runtime .env theft. Repository scanning finds secrets in code history. Runtime theft may expose secrets that were never committed to Git. You need both: code perimeter controls to prevent future leaks, and runtime secret inventory to know what could have been read from a compromised process.
Patch, redeploy, rotate, hunt
For React2Shell, patching is mandatory, but it is not the end of response. Vercel’s bulletin recommended upgrading affected Next.js versions immediately and stated that upgrading to a patched version is the only complete fix for Next.js. It also strongly encouraged teams whose application was online and unpatched as of December 4, 2025 at 1:00 PM PT to rotate secrets, starting with the most critical ones. (Vercel)
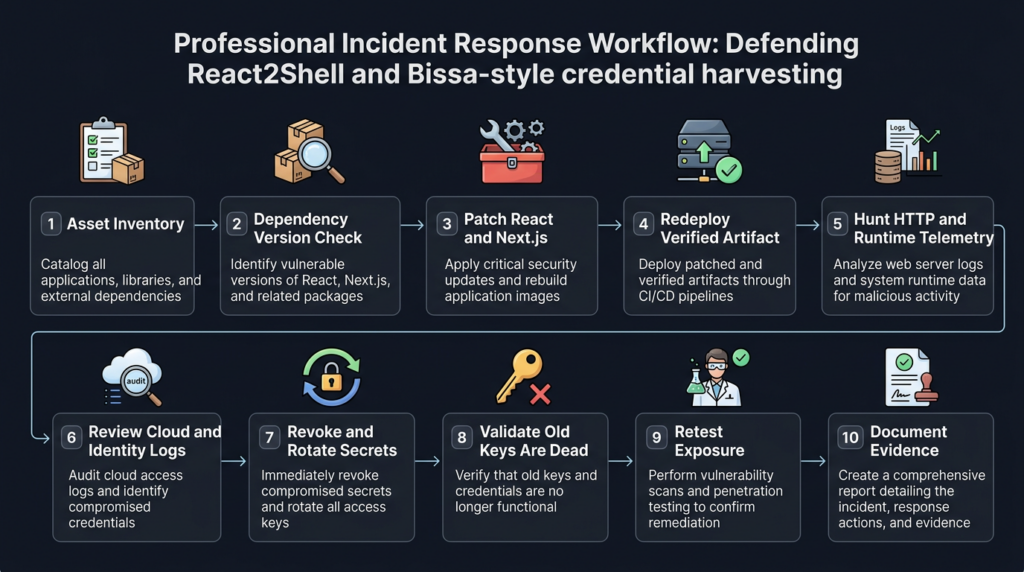
A clean response sequence looks like this:
1. Identify affected applications and deployed versions.
2. Patch React, Next.js, and affected RSC dependencies.
3. Redeploy and confirm the running artifact changed.
4. Review whether the app was internet-facing during exploitation windows.
5. Hunt for suspicious HTTP, process, network, and cloud activity.
6. Revoke and rotate exposed or potentially exposed credentials.
7. Validate that old credentials no longer work.
8. Review cloud, database, payment, AI provider, and source-control logs.
9. Add monitoring for re-use attempts and canary tokens.
10. Document evidence and repeat the check across every environment.
The order matters. Some teams patch first and declare victory. That leaves stolen keys alive. Other teams rotate secrets before redeploying, then expose the new secrets to the same vulnerable runtime. Some rotate production keys but forget preview deployments, staging environments, serverless functions, CI secrets, or developer tokens. Severe RCE incidents punish incomplete sequencing.
AWS Secrets Manager describes rotation as periodically updating a secret in both the secret store and the database or service. AWS also supports automatic rotation, including managed rotation for many supported secrets. (AWS Documentation)
A practical rotation tracker should include at least these fields:
| Secret | Owner | दायरा | Last used | Exposed location | Rotation action | मान्यकरण |
|---|---|---|---|---|---|---|
| AWS access key | मंच | Production account | CloudTrail | .env on web runtime | Deactivate, create replacement, update workload | Old key denied, app healthy |
| Database URI | Backend | Production DB | DB logs | Runtime env | Rotate password, update app secret | Old password denied |
| OpenAI API key | AI feature team | App backend | Provider dashboard | Runtime env | Revoke and replace | Billing and usage reviewed |
| Stripe key | Payments | Payment service | Stripe logs | Runtime env | Roll key per provider guidance | Webhook and payment flows tested |
| GitHub token | DevOps | CI/CD | GitHub audit | Runtime or CI | Revoke token, replace with least privilege | No failed workflow drift |
| Slack token | Internal tooling | Notification bot | Slack audit | Runtime env | Revoke and reinstall if needed | Bot functionality confirmed |
Secrets should be rotated based on privilege and blast radius, not alphabetically. Cloud root-level or admin-like credentials come first. Production database credentials come before low-risk monitoring keys. Source-control tokens with write access come before read-only analytics tokens. Payment and identity-provider secrets deserve special handling because incorrect rotation can break production flows or create fraud risk.
.env files are not the only place secrets hide
The Bissa scanner reporting focused heavily on .env collection, but defenders should not limit the search to files named .env. Modern applications leak secrets through many adjacent paths:
.env
.env.local
.env.production
.env.production.local
.env.staging
.env.backup
.env.old
docker-compose.yml
Kubernetes Secret manifests
Helm values files
CI/CD variables
build artifacts
serverless deployment bundles
container image layers
debug logs
crash dumps
process environment snapshots
cloud metadata credentials
local credential stores
A read-only filesystem sweep can identify obvious risky files inside a server or container image:
find /app /var/www /srv -type f \
\( -name ".env*" -o -name "*secret*" -o -name "*credential*" -o -name "docker-compose*.yml" -o -name "values*.yaml" \) \
-maxdepth 8 2>/dev/null
For source repositories, use secret scanning tools and push protection. GitHub push protection blocks supported secrets before they are pushed and can generate alerts when a contributor bypasses a block. (GitHub दस्तावेज़)
For build artifacts, inspect what is actually shipped. A secret that never appears in Git can still appear in a Docker layer, a Next.js build output, an accidentally public deployment preview, or a serverless bundle. The rule is simple: treat every artifact that runs or ships as a possible secret container.
Runtime containment reduces the value of RCE
React2Shell showed why runtime containment matters. If a web process has broad access to production secrets, cloud metadata, service account tokens, and internal networks, a single RCE can become an enterprise incident. If the same process has narrow permissions, short-lived identity, network egress controls, and no direct access to privileged secrets, the blast radius shrinks.
Useful controls include:
| Control | What it limits | Why it matters after web RCE |
|---|---|---|
| Least-privilege runtime identity | Cloud and database actions available to the app | Prevents one web process from becoming cloud admin |
| Short-lived credentials | Time window for stolen tokens | Reduces value of archived secrets |
| Secret manager access policies | Which workloads can read which secrets | Prevents broad .env sprawl |
| Network egress allowlists | Outbound connections to unknown hosts | Makes exfiltration and payload download harder |
| Metadata service protections | Cloud credential theft from instance metadata | Reduces cloud pivot risk |
| Read-only filesystems | Runtime file modification | Limits persistence and tool staging |
| No shell in production images where feasible | Post-exploitation convenience | Makes common payload chains harder |
| Process execution monitoring | Shell and downloader behavior | Detects RCE after initial request |
| Canary tokens | Unauthorized secret access | Creates early warning on credential misuse |
No single control fixes React2Shell. The goal is to make a successful exploit less useful and more visible. Attackers build pipelines because they expect many environments to turn RCE into secrets quickly. Break that assumption.
WAF rules are useful, but not a substitute for patching
React’s advisory said hosting providers worked on temporary mitigations but warned users not to depend on those mitigations and to update immediately. (react.dev) Google Threat Intelligence Group also recommended patching immediately and using WAF rules as a temporary mitigation while vulnerability management programs patch and verify vulnerable instances. (गूगल क्लाउड)
That is the right order. WAF rules can buy time. They can block known request patterns. They can reduce commodity scanning. They can help central teams protect applications whose owners have not patched yet. But a WAF cannot reliably prove that every framework-level deserialization path is safe. It also cannot rotate keys that were already stolen.
A useful WAF response includes:
1. Enable vendor-provided React2Shell protections where available.
2. Log blocked and allowed RSC-like traffic for investigation.
3. Compare WAF events with application logs and process telemetry.
4. Prioritize patching internet-facing apps with matching traffic.
5. Remove emergency assumptions only after live deployment verification.
Do not use the absence of WAF alerts as evidence that an app was safe. The best evidence is a deployed patched version, runtime telemetry review, and secret rotation decisions based on exposure.
Detecting attacker triage patterns
The Bissa scanner case highlights a detection category that many programs underuse: attacker workflow artifacts. Defenders often focus on the exploit request and miss the operating model around it. In this case, the operating model included Telegram notifications, S3-compatible storage, ZIP archives, local result directories, and AI-control logs.
You can hunt for similar patterns without relying on exact Bissa indicators:
Outbound HTTPS from web runtime to unusual object storage endpoints
Repeated creation of ZIP archives under temporary or application directories
Access to many .env-like files in short time windows
Node.js parent process spawning archive tools or shell utilities
Unexpected Telegram API traffic from production web servers
Unexpected cloud metadata access from application containers
Credential validation attempts shortly after suspicious web requests
For Linux file activity where auditd or EDR provides file events:
DeviceFileEvents
| where Timestamp > ago(30d)
| where FileName matches regex @"^\.env(\..*)?$"
| summarize count(), min(Timestamp), max(Timestamp) by DeviceName, InitiatingProcessFileName, InitiatingProcessCommandLine
| order by count_ desc
For suspicious archive creation:
DeviceProcessEvents
| where Timestamp > ago(30d)
| where FileName in~ ("zip", "tar", "gzip", "7z")
| where ProcessCommandLine has_any (".env", "results", "archive", "batch")
| project Timestamp, DeviceName, InitiatingProcessCommandLine, ProcessCommandLine
For Telegram API traffic from servers that should not use Telegram:
DeviceNetworkEvents
| where Timestamp > ago(30d)
| where RemoteUrl has_any ("api.telegram.org", "telegram.org")
| project Timestamp, DeviceName, InitiatingProcessFileName, InitiatingProcessCommandLine, RemoteUrl, RemoteIP
Not every environment has this telemetry. The point is to think beyond the CVE string. A mature attacker pipeline leaves operational traces: staging, packaging, uploading, notifying, validating, and sorting.
AI provider keys deserve special attention
DFIR Report observed AI provider credentials as the largest category in the exposed haul. (The DFIR Report) That deserves attention because many companies still treat AI API keys as developer convenience tokens rather than production secrets.
AI keys can be abused in several ways:
| Abuse path | What happens | What to check |
|---|---|---|
| Cost abuse | Attacker runs high-volume inference | Provider usage dashboard, unusual model mix, region and IP anomalies |
| Data-path exposure | Requests may reveal prompt or application context depending on architecture | Application logs, provider logs, prompt storage, customer-data handling |
| Product abuse | Attacker uses your key to power their own service or bot | Sustained traffic outside normal user patterns |
| Quota exhaustion | Legitimate features fail when quota is consumed | Rate limit dashboards and error spikes |
| Policy exposure | Key is used for disallowed workloads | Provider policy alerts and abuse notifications |
Rotation alone may not be enough. Review usage history before revocation where possible, preserve evidence, and check whether the key had access to fine-tuned models, files, vector stores, logs, or administrative operations. Some provider APIs separate inference keys from admin capabilities; many teams do not enforce that separation carefully.
Source control and CI/CD tokens are a supply-chain risk
A stolen GitHub token or CI/CD secret can be more dangerous than a stolen web server credential. It may allow an attacker to read private repositories, discover more secrets, modify workflows, inject build steps, or create persistence through deploy keys and automation users.
After React2Shell exposure, review:
New deploy keys
New GitHub Apps
Personal access token usage
Workflow file changes
Secrets added or modified
Actions runner registration
Unexpected repository clones
Branch protection changes
Package publishing tokens
Container registry pushes
GitHub secret scanning can identify hardcoded credentials across repository history, and push protection can prevent supported secrets from being pushed in the first place. (GitHub दस्तावेज़) But if an attacker stole a runtime .env, the key may never appear in Git. The CI/CD review must include provider audit logs and token revocation, not just code scanning.
A useful containment move is to replace long-lived personal access tokens with GitHub Apps, OIDC-based cloud deployment, or narrowly scoped automation credentials where possible. The exact implementation depends on the platform, but the principle is stable: avoid broad, long-lived, human-owned tokens in production runtimes.
Kubernetes and cloud metadata are common post-exploitation targets
DFIR Report said the Bissa scanner workflow attempted to enumerate Kubernetes service account context and cloud metadata along with .env files and local credential stores. (The DFIR Report) That is predictable. Once an attacker has code execution inside a cloud workload, metadata and service identity are obvious next targets.
For Kubernetes, review:
kubectl get serviceaccount -A
kubectl get rolebindings,clusterrolebindings -A
kubectl get secrets -A --field-selector type=kubernetes.io/service-account-token
Look for service accounts attached to web workloads that can list secrets, read config maps across namespaces, create pods, exec into pods, or access cluster-admin roles. A web application usually does not need broad Kubernetes API permissions.
For pods, consider disabling automatic service account token mounting where not needed:
apiVersion: v1
kind: Pod
metadata:
name: web-app
spec:
automountServiceAccountToken: false
containers:
- name: web
image: example/web:latest
Where service account tokens are needed, prefer projected tokens and narrow RBAC. Kubernetes documentation states that projected tokens expire automatically and are rotated by kubelet before expiration. (Kubernetes)
For cloud metadata, enforce provider-specific protections such as IMDSv2 on AWS EC2, metadata concealment where supported, workload identity instead of static keys, and egress monitoring for metadata access patterns. The best design is to make runtime credentials short-lived, audience-bound, and scoped to the exact resources the service needs.
Safe validation for security teams
A safe validation workflow should prove exposure without publishing or running weaponized exploit logic against production. For React2Shell, that means combining version checks, reachable-surface mapping, WAF and log review, and controlled testing in authorized environments.
A practical validation checklist:
Application inventory:
- Does this service use Next.js App Router or another RSC-enabled framework
- Which React and react-server-dom package versions are deployed
- Which image or serverless artifact is live
Reachability:
- Is the service internet-facing
- Are preview deployments public
- Are staging environments indexed or linked
- Are internal apps reachable through VPN or partner networks
Runtime:
- Does the process run on Node.js server runtime
- What secrets are available to the process
- What cloud identity is attached
- What network egress is allowed
Evidence:
- Deployed package version
- Request logs for suspicious RSC-like traffic
- Process execution telemetry
- Outbound network telemetry
- Secret rotation status
For teams using automated offensive validation, the standard should be evidence, not claims. A tool should show what it checked, which asset was in scope, which version or behavior was observed, whether the issue was reachable, and what proof was collected without damaging the application. Penligent’s public docs state that the product is for authorized security testing only and requires explicit permission from the target owner, and its React2Shell writeups focus on exposure mapping, affected packages, patch guidance, and controlled validation rather than unsafe exploit publication. (पेनलिजेंट.एआई)
That kind of workflow is useful during framework-wide incidents because the hard part is rarely a single command. The hard part is connecting asset discovery, dependency state, live reachability, runtime risk, secret exposure, retest evidence, and reporting across many services before attackers finish the same prioritization exercise.
Common mistakes that keep this class of incident alive
The first mistake is treating React2Shell as only a frontend issue. React Server Components changed the security boundary. The affected code path lived in server-side framework behavior, not in the browser-only part of React. React’s advisory makes clear that the vulnerable packages relate to Server Components and that unauthenticated malicious HTTP requests to Server Function endpoints could lead to remote code execution. (react.dev)
The second mistake is patching the repository but not the deployment. A lockfile update does not protect an old container, stale serverless function, forgotten preview environment, or abandoned staging host. Attackers scan what is reachable, not what is merged.
The third mistake is rotating only the obvious keys. .env files often contain secondary credentials that become primary after compromise: webhook secrets, OAuth client secrets, JWT signing keys, database replicas, Redis URLs, monitoring DSNs, analytics write keys, and internal service tokens. Some of these do not look dangerous until combined with another system.
The fourth mistake is assuming no alert means no compromise. Bissa-style workflows are designed to collect and sort results quickly. If logs are thin, outbound traffic is not monitored, and process execution is invisible, the attacker may leave few obvious signs at the web layer.
The fifth mistake is ignoring preview and development deployments. Vercel’s bulletin specifically warned about deployment protection and shareable deployment links during the React2Shell response. (Vercel) Preview deployments often have weaker access controls but real secrets because teams want staging to behave like production.
The sixth mistake is trusting random PoCs. Google warned that the early React2Shell ecosystem included non-functional exploits, false information, legitimate exploit code, and exploit samples containing malware targeting security researchers. (गूगल क्लाउड) In a high-profile CVE event, researchers and defenders become targets too.
A practical hardening baseline for React and Next.js teams
A hardened React and Next.js response should include dependency, deployment, runtime, and secret controls.
For dependency hygiene:
npm outdated next react react-dom
npm audit --omit=dev
For exact package checks:
node -e '
const fs=require("fs");
for (const f of ["package-lock.json","package.json"]) {
if (fs.existsSync(f)) console.log(`Found ${f}`);
}
'
For monorepos, enforce central visibility:
find apps packages services -name package.json -maxdepth 4 -print \
| while read f; do
echo "### $f"
grep -E '"next"|"react"|"react-dom"|"react-server-dom' "$f" || true
done
For deployment verification:
# Example only: adapt to your deployment platform.
# The goal is to record the artifact, build ID, image digest, and package baseline.
docker image inspect your-image:tag --format '{{json .RepoDigests}}'
docker run --rm --entrypoint node your-image:tag -e 'console.log(process.version)'
For secret minimization:
Do not give the web runtime organization-wide cloud keys.
Do not store source-control tokens in general app environments.
Do not reuse the same AI provider key across production, staging, and development.
Do not give preview deployments production payment keys.
Do not let a web pod list all Kubernetes secrets.
Do not rely on manual memory for key ownership.
For egress control:
Allow production web services to reach required APIs.
Block or alert on unexpected object storage endpoints.
Block or alert on Telegram API traffic unless explicitly required.
Block or alert on direct miner pool traffic.
Review outbound DNS for newly seen domains after suspicious requests.
For response readiness:
Maintain a secret owner map.
Practice emergency rotation for cloud, database, payment, source-control, and AI keys.
Keep provider-specific revocation steps documented.
Preserve logs for at least the expected investigation window.
Use canary tokens in places attackers are likely to collect.
Verify fixed deployments with evidence.
Why continuous validation beats one-time cleanup
React2Shell was not a single bad week. It was a stress test for how modern engineering organizations respond to framework-level risk. Public disclosure happened. Exploitation followed quickly. Related CVEs and updates appeared after the initial advisory. Attackers mixed real PoCs, fake PoCs, malware, scanners, backdoors, miners, and credential harvesters. Vendors published patches, bulletins, WAF guidance, and secret-rotation advice. The environment changed faster than a quarterly scan cycle can handle. (react.dev)
One-time cleanup fails because exposure is not static. A team patches one service but misses another. A preview deployment remains public. A stale container stays running. A developer forks an old branch. A secret is rotated in production but not in CI. A WAF rule blocks one payload shape while another scanner tries a different one. A related CVE changes the required baseline.
Continuous validation does not mean reckless exploitation. It means repeatedly answering a small set of evidence-based questions:
What do we expose
What versions are actually deployed
Which services are reachable
Which secrets can those services read
What would a successful RCE let an attacker do next
Did our patch remove the reachable behavior
Did our secret rotation invalidate the stolen value
Can another engineer verify the evidence
That is the defender equivalent of the Bissa scanner lesson. Attackers built a pipeline to find, exploit, collect, notify, and prioritize. Defenders need a pipeline to discover, verify, contain, rotate, retest, and document.
The larger meaning of the Bissa scanner case
The Bissa scanner exposure shows how modern mass exploitation is becoming more operationally disciplined. The attacker did not need a custom implant for every target. They used a high-impact framework vulnerability, automated acquisition, secret collection, cloud archiving, Telegram notifications, and AI-assisted workflow management. That stack turned a public CVE into a repeatable credential-harvesting process.
React2Shell was the entry point, but secrets were the prize. Telegram was the dashboard. AI tooling was the operator assistant. Filebase was the archive. The exposed server was the accidental window into the whole system.
Security teams should treat this as a warning about time and workflow. Attackers are not waiting for annual pentests, quarterly reviews, or perfect asset inventories. They are scanning continuously, validating quickly, and routing high-value results to human operators. A defender program built around slow ticket queues and manual spreadsheet triage will lose ground even when engineers understand the vulnerability itself.
The response is not panic. It is disciplined engineering: patch the framework, verify the running deployment, hunt for exploitation, rotate secrets based on blast radius, reduce runtime privilege, monitor post-exploitation behavior, and keep validating as the ecosystem changes.
React2Shell will not be the last framework bug that turns a clean developer abstraction into a server-side attack surface. The next one may involve another rendering protocol, plugin system, AI agent tool interface, server action model, package build step, or edge runtime. The durable lesson is the same: any boundary that converts untrusted input into privileged server behavior deserves continuous scrutiny, and any runtime that holds powerful secrets must be designed as if that boundary can fail.
References and further reading
React, Critical Security Vulnerability in React Server Components. (react.dev)
NVD, CVE-2025-55182. (एनवीडी.एनआईएसटी.जीओवी)
Next.js GitHub Security Advisory, RCE in React Server Components. (गिटहब)
Vercel, React2Shell Security Bulletin. (Vercel)
Microsoft Security Blog, Defending against CVE-2025-55182 React2Shell. (माइक्रोसॉफ्ट)
Google Threat Intelligence Group, Multiple Threat Actors Exploit React2Shell. (गूगल क्लाउड)
AWS Security Blog, China-nexus cyber threat groups rapidly exploit React2Shell. (अमेज़न वेब सर्विसेज़, इंक.)
Rapid7, React2Shell critical unauthenticated RCE affecting React Server Components. (रैपिड7)
Unit 42, Exploitation of Critical Vulnerability in React Server Components. (इकाई 42)
The DFIR Report, Bissa Scanner Exposed, AI-Assisted Mass Exploitation and Credential Harvesting. (The DFIR Report)
Cybersecurity News, Hackers Use Telegram Bots to Track 900+ Successful React2Shell Exploits. (साइबर सुरक्षा समाचार)
OWASP Secrets Management Cheat Sheet. (cheatsheetseries.owasp.org)
GitHub Docs, About secret scanning and push protection. (GitHub दस्तावेज़)
AWS Secrets Manager, rotation and best practices. (AWS Documentation)
Kubernetes documentation, service accounts and projected tokens. (Kubernetes)
Penligent, React2Shell CVE 2025 55182, why one request became a server-side execution boundary. (पेनलिजेंट.एआई)
Penligent, React2Shell CVE, How a React Server Components Bug Turned One Request Into Remote Code Execution. (पेनलिजेंट.एआई)
Penligent documentation and authorized testing disclaimer. (पेनलिजेंट.एआई)