A model load should not silently become a shell.
That is the practical lesson behind CVE-2026-4372, a Hugging Face Transformers vulnerability involving malicious model configuration, internal attention implementation fields, and a code path that could execute attacker-controlled Python code even when the user did not intentionally opt into remote model code. NVD describes the issue as a critical remote code execution vulnerability in Transformers versions before 5.3.0, triggered when a victim loads a crafted model with APIs such as AutoModelForCausalLM.from_pretrained(). The malicious repository can use config.json to set _attn_implementation_internal to an attacker-controlled Hugging Face Hub repository, causing the library to download and execute code from that repository with the victim process’s privileges. NVD also states that this path bypasses the intended protection of trust_remote_code.(एनवीडी)
The wording matters. This is not just another “do not run untrusted code” warning. Hugging Face already has an explicit flag for that boundary. Transformers documentation says trust_remote_code डिफ़ॉल्ट रूप से False, and that users should only set it to True for repositories they trust and whose code they have read, because code from the Hub will execute locally.(Hugging Face) CVE-2026-4372 is serious because it undermined that mental model. A user could avoid enabling remote code and still hit a path where configuration influenced code loading.
The safer way to think about the issue is this: machine learning model repositories are software supply-chain inputs, not passive data blobs. A repository can contain weights, configuration, tokenizer files, custom Python modules, model cards, and metadata that changes how libraries behave. In modern AI systems, model loading often happens in CI jobs, notebooks, evaluation workers, fine-tuning pipelines, inference servers, and internal experimentation platforms. If those environments have API tokens, cloud credentials, mounted datasets, build secrets, or production network access, the difference between “load a model” and “execute attacker code” is operationally huge.
The core facts
| आइटम | Conservative reading |
|---|---|
| सीवीई | CVE-2026-4372 |
| Affected project | Hugging Face Transformers |
| Primary vulnerable behavior | Malicious config.json can influence internal kernel loading and lead to Python code execution |
| Key field called out by NVD | _attn_implementation_internal |
| API path called out by NVD | AutoModelForCausalLM.from_pretrained() |
| Security boundary affected | The expected protection of trust_remote_code=False |
| Fix | Upgrade to Transformers 5.3.0 or later |
| NVD status | NIST had not yet provided its own CVSS score when the NVD entry was captured, while the CNA score listed by NVD was 7.8 High |
| Weakness categories listed by NVD | CWE-502 and CWE-1066 |
| Publication timeline | NVD lists the CVE as published on May 24, 2026 and last modified on June 4, 2026 |
NVD’s affected version range is broad: versions before 5.3.0 are marked as vulnerable. Pluto Security’s technical analysis narrows the practical exploitation conditions, stating that the vulnerable path existed from Transformers 4.56.0 through the 5.2.x line and required the kernels package to be installed. That distinction is important for triage. Treat the official version boundary as the patching rule. Use the narrower technical condition to prioritize investigation and exposure review, not to delay upgrading.(एनवीडी)
Why model loading is a security boundary
Transformers made model use simple for good reasons. The normal developer experience is intentionally clean: pick a model identifier, call from_pretrained(), let the library download the model weights and configuration, and start inference or fine-tuning. Hugging Face documentation describes from_pretrained() as the standard way to load pretrained weights and configuration from the Hub.(Hugging Face)
That convenience is also why the boundary is security-sensitive. Loading a model may involve more than parsing static tensors. It can pull files from a remote repository, deserialize metadata, choose architecture classes, initialize model components, select attention implementations, import custom modules, and cache artifacts locally. Each of those steps can become part of the trust chain.
The difference between a safe artifact and an executable software input is not obvious to every developer who touches AI workflows. A data scientist may see a model ID in a notebook and think the risk is mainly model quality. A platform engineer may see an evaluation job and think the risk is cost. A red teamer sees something else: a remote identifier passed into a loader that can change runtime behavior.
Hugging Face’s own documentation acknowledges this boundary. For custom models, the docs warn users to take extra precautions, note that Hub files are malware-scanned, and still tell users to avoid executing malicious code. They also recommend pinning a specific revision as an added security measure when loading models with custom code.(Hugging Face)
That advice remains correct, but CVE-2026-4372 shows why a single flag cannot be the only guardrail. A model-loading security design has to assume the configuration plane itself can be hostile. It should validate keys, constrain internal dispatch decisions, restrict sources, limit network access, and run with minimal secrets.
What made CVE-2026-4372 different
Many malicious model risks depend on a user explicitly agreeing to run model repository code. In the ordinary custom-code workflow, a user sets trust_remote_code=True, and that flag should represent a conscious decision to run Python code from a model repository.
CVE-2026-4372 is different because the attack path did not depend on that explicit decision in the way users would expect. NVD states that a crafted config.json could cause arbitrary Python code to be downloaded and executed from an attacker-controlled Hugging Face Hub repository while bypassing trust_remote_code.(एनवीडी)
That breaks an important security promise at the usability layer. Security flags are not only technical controls; they are also communication tools. They tell developers when a behavior crosses a trust boundary. If a developer sees no trust_remote_code=True in a codebase, they may assume the pipeline never runs remote model code. CVE-2026-4372 shows why that assumption was not safe for affected Transformers versions.
The issue sits at the intersection of three design areas:
| Design area | यह क्यों मायने रखती है |
|---|---|
| Configuration deserialization | config.json controls model behavior and can influence internal attributes |
| Kernel dispatch | High-performance model paths can involve specialized kernels and dynamic loading logic |
| Trust signaling | Users rely on trust_remote_code to distinguish static model loading from remote code execution |
A vulnerability at this intersection is easy to underestimate. It does not look like a classic web RCE. There is no exposed /admin endpoint, no SQL injection, no obvious reverse shell in the vulnerable project. Instead, the exploit path hides in a common AI workflow: “load this model and run evaluation.”
How the vulnerable path worked
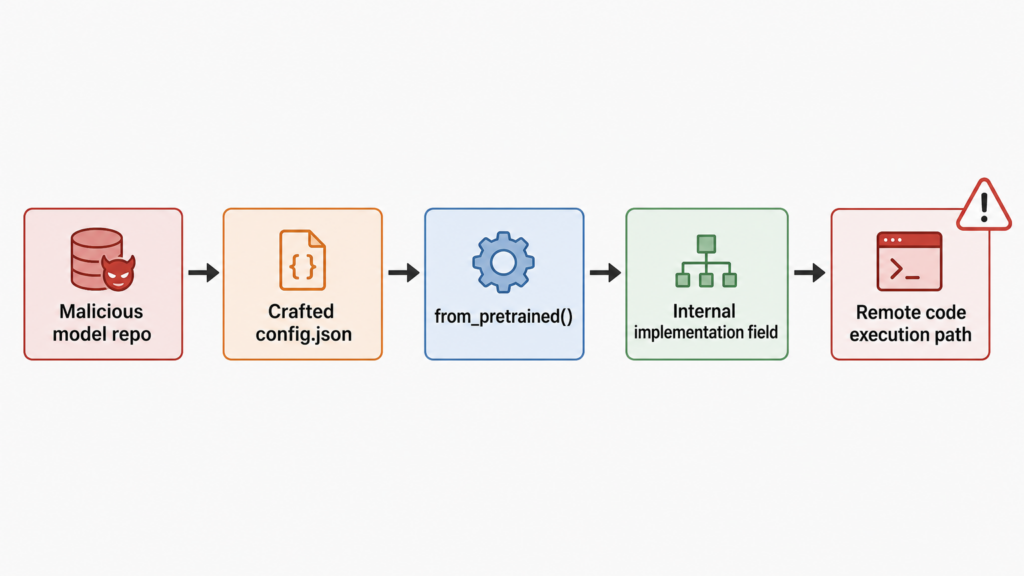
config.json Can Trigger Code ExecutionThe vulnerable behavior can be understood without turning it into a copy-paste exploit.
First, a malicious actor prepares a model repository. The important object is not necessarily the model weights. The important object is the configuration file. NVD specifically calls out the malicious use of config.json और _attn_implementation_internal field.(एनवीडी)
Second, a victim loads the model using a normal Transformers API. NVD names AutoModelForCausalLM.from_pretrained() as the relevant path. In real environments, the same pattern can appear inside notebooks, evaluation scripts, internal model registries, training pipelines, or third-party tools that wrap Transformers.(एनवीडी)
Third, affected Transformers versions deserialize configuration in a way that lets the hostile field influence internal model behavior. The GitHub patch for the issue is revealing because it shows exactly what changed. Before the fix, configuration keyword arguments were generically applied to the configuration object. The patch adds a guard that avoids deserializing specific problematic internal fields, including _attn_implementation_internal और _experts_implementation_internal.(गिटहब)
Fourth, the model-loading flow reaches kernel-loading logic. The patch also changed the kernel repository trust logic. The old matching behavior accepted a broader pattern for kernel repositories; the patched code restricts default trust to kernels-community and requires trust_remote_code for other repositories. A maintainer comment in the pull request states that the project kept default trust limited to its own published kernels and allowed others only with trust_remote_code.(गिटहब)
The high-level chain looks like this:
| मंच | Attacker-controlled input | Victim action | Security impact |
|---|---|---|---|
| Model selection | A malicious or compromised model repository | Victim chooses or automation pulls a model ID | The remote repository enters the trust boundary |
| Configuration load | Crafted config.json | Transformers parses model configuration | Internal attributes may be set from hostile metadata |
| Dispatch decision | _attn_implementation_internal value | Loader selects an implementation path | Code-loading behavior can be redirected |
| Kernel retrieval | Attacker-controlled repository reference | Library downloads implementation code | Python code enters the local runtime |
| कार्यन्वयन | Python module code | Victim process imports or executes it | Code runs with local process privileges |
This is why the vulnerability is best treated as a model supply-chain execution bug. The attacker does not need to exploit memory corruption in the victim’s CPU or GPU stack. The attacker abuses trusted automation around model retrieval and initialization.
Why the CVSS vector can look less dramatic than the real workflow risk
NVD’s entry lists the CNA vector as CVSS:3.0/AV:L/AC:L/PR:N/UI:R/S:U/C:H/I:H/A:H, with a 7.8 High score. The local attack vector and required user interaction can make the issue sound less urgent than a network-exposed unauthenticated service RCE.(एनवीडी)
For AI teams, that reading can be misleading. In a modern model pipeline, “user interaction” may be an automated process accepting a model identifier from a queue, a benchmark list, a pull request, a notebook cell, or a model registry update. “Local attack vector” may still mean attacker-controlled code runs inside a cloud-hosted GPU worker with access to tokens, datasets, internal endpoints, and expensive compute.
The risk depends less on the CVSS label and more on how model loading is wired into the organization.
A local research laptop with no secrets, no sensitive datasets, and only pinned internal models has a very different risk profile from a shared evaluation platform that automatically pulls arbitrary Hugging Face models submitted by users. A CI job that tests third-party models with long-lived cloud credentials is more dangerous than a locked-down container with no outbound network and no mounted secrets.
Security teams should ask four questions:
| Question | यह क्यों मायने रखती है |
|---|---|
| Can untrusted users influence model IDs or repository URLs? | Turns a dependency bug into an attacker-reachable workflow |
| Does the model-loading environment contain secrets? | Determines post-execution blast radius |
| Is outbound network access allowed? | Enables second-stage payloads, exfiltration, and command retrieval |
| Are model loads logged with repository, commit, and version data? | Determines whether investigation is possible after patching |
The presence of Transformers alone does not mean compromise. The combination of old Transformers, risky model intake, sensitive execution context, and weak logging is what creates serious exposure.
Affected conditions and how to prioritize
The safest remediation rule is simple: upgrade Transformers to 5.3.0 or later anywhere the library is installed. Hugging Face’s v5.3.0 release notes list a kernel-related security fix and reference the PR that fixed the issue.(गिटहब)
Prioritization is still necessary because large organizations may have Transformers in many places: production inference services, developer laptops, Docker images, notebooks, Airflow jobs, benchmark harnesses, internal platforms, and research repositories. Some installations load only fixed internal artifacts. Others pull from public model hubs on every run.
Use this table to triage:
| पर्यावरण | Exposure level | क्यों |
|---|---|---|
| Public-facing service that accepts user-provided model IDs | आलोचनात्मक | Attackers may be able to influence the exact model loaded |
| Shared model evaluation platform pulling public Hub repositories | उच्च | Model intake is part of normal workflow |
| CI pipeline that benchmarks external model repositories | उच्च | Automation may load untrusted models without human inspection |
| Notebook environment with cloud tokens and old Transformers | उच्च | Manual model loading can still expose valuable credentials |
| Production inference service using one internal pinned model | मध्यम | Risk depends on whether the model artifact path can change |
| Offline research environment with no secrets and fixed model cache | Lower | Execution impact is constrained, but still patch |
| Patched environment on Transformers 5.3.0 or later | Lower | Known vulnerable path is fixed, but general model supply-chain risk remains |
Pluto Security’s analysis adds a useful nuance: the vulnerable path it analyzed required the kernels package to be installed and was introduced in the 4.56.0 line.(Pluto Security) Do not use that detail as an excuse to keep old versions. Use it to decide which logs, images, and environments deserve immediate inspection.
Detection and validation without running the model

Do not validate CVE-2026-4372 by loading a suspicious model. That repeats the dangerous action. Start with dependency inventory, static model artifact checks, cache inspection, code search, and runtime telemetry.
Check installed Transformers and related packages
Run this inside each relevant Python environment:
python - <<'PY'
import importlib.metadata as md
for package in ["transformers", "kernels", "huggingface_hub", "torch"]:
try:
print(f"{package}=={md.version(package)}")
except md.PackageNotFoundError:
print(f"{package}: not installed")
PY
For pip-based environments:
python -m pip show transformers kernels huggingface_hub torch
python -m pip freeze | grep -E '^(transformers|kernels|huggingface-hub|torch)=='
For Conda environments:
conda list | grep -E 'transformers|kernels|huggingface_hub|pytorch'
For containers, inspect both the build file and the final image. Many vulnerable environments survive because the source repository was patched but a long-lived Docker image still contains an old dependency.
docker run --rm your-image:tag python - <<'PY'
import importlib.metadata as md
for package in ["transformers", "kernels"]:
try:
print(package, md.version(package))
except md.PackageNotFoundError:
print(package, "not installed")
PY
If you use lockfiles, search them directly:
grep -R "transformers==" requirements*.txt pyproject.toml poetry.lock Pipfile.lock conda*.yml .
This is not enough by itself. Model-loading code is often embedded in notebooks, scripts, internal platforms, or third-party tools. The dependency check tells you where the vulnerable library may exist. It does not tell you whether risky models were loaded.
Search for model-loading call sites
Search for common load patterns:
grep -R --line-number \
-E "from_pretrained\\(|AutoModel|AutoModelForCausalLM|AutoTokenizer|pipeline\\(" \
./src ./notebooks ./scripts 2>/dev/null
For Python projects, a small AST-based scan reduces noise:
import ast
from pathlib import Path
TARGET_NAMES = {
"from_pretrained",
"AutoModel",
"AutoModelForCausalLM",
"AutoTokenizer",
"pipeline",
}
for path in Path(".").rglob("*.py"):
try:
tree = ast.parse(path.read_text(encoding="utf-8"))
except Exception:
continue
for node in ast.walk(tree):
if isinstance(node, ast.Call):
name = ""
if isinstance(node.func, ast.Attribute):
name = node.func.attr
elif isinstance(node.func, ast.Name):
name = node.func.id
if name in TARGET_NAMES:
print(f"{path}:{node.lineno}: call to {name}")
This does not prove exploitation. It gives you a map of places where model-loading behavior exists and where input sources should be reviewed.
Scan model repositories and caches for dangerous configuration keys
The most useful defensive static check is to look for the internal fields that the patch restricted. The GitHub fix explicitly avoids deserializing _attn_implementation_internal और _experts_implementation_internal, which makes them high-value indicators during review.(गिटहब)
A quick shell scan:
grep -R --line-number \
-E '"_attn_implementation_internal"|"_experts_implementation_internal"' \
~/.cache/huggingface ./models ./checkpoints 2>/dev/null
A safer JSON-aware scanner:
import json
from pathlib import Path
RISKY_KEYS = {
"_attn_implementation_internal",
"_experts_implementation_internal",
}
SEARCH_ROOTS = [
Path.home() / ".cache" / "huggingface",
Path("./models"),
Path("./checkpoints"),
]
def scan_config(path: Path):
try:
data = json.loads(path.read_text(encoding="utf-8"))
except Exception:
return
found = sorted(RISKY_KEYS.intersection(data.keys()))
if found:
print(f"[!] {path}")
print(f" risky keys: {', '.join(found)}")
for root in SEARCH_ROOTS:
if not root.exists():
continue
for config in root.rglob("config.json"):
scan_config(config)
This script intentionally does not import Transformers, load the model, execute repository code, or resolve remote references. It treats configuration as untrusted input and reads it as JSON only.
Review downloaded repository provenance
A model cache path alone is not enough. You need model ID, revision, download time, and the process that initiated the load. Hugging Face caches can preserve repository-like directory names, but enterprise teams should not depend on cache naming as their only audit trail. Build explicit logging into model intake:
from datetime import datetime, timezone
from transformers import AutoConfig
def logged_config_load(model_id: str, revision: str | None = None):
print({
"event": "model_config_load",
"model_id": model_id,
"revision": revision,
"time": datetime.now(timezone.utc).isoformat(),
})
return AutoConfig.from_pretrained(
model_id,
revision=revision,
trust_remote_code=False,
)
This example loads only configuration, not the model. In production, the logging should happen before any remote model artifact is fetched, and the model ID should come from an allowlist or approval workflow, not raw user input.
Add a CI gate for vulnerable versions
A build should fail if it resolves Transformers below your minimum accepted version.
from importlib.metadata import version, PackageNotFoundError
from packaging.version import Version
MIN_TRANSFORMERS = Version("5.3.0")
try:
installed = Version(version("transformers"))
except PackageNotFoundError:
raise SystemExit("transformers is not installed")
if installed < MIN_TRANSFORMERS:
raise SystemExit(
f"Blocked: transformers {installed} is below required {MIN_TRANSFORMERS}"
)
print(f"OK: transformers {installed}")
Wire it into CI:
name: dependency-security-check
on:
pull_request:
push:
jobs:
check-transformers:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.11"
- run: python -m pip install -r requirements.txt
- run: python security/check_transformers_version.py
Use this as a guardrail, not the only control. A repository can pass CI while an old notebook server, Docker image, or scheduled job remains exposed.
Runtime signals worth hunting
If an environment loaded untrusted or semi-trusted models before patching, static checks are not enough. You need to look for signs of unexpected code retrieval and execution.
| Signal | यह क्यों मायने रखती है | Limitation |
|---|---|---|
| Python process connects to an unexpected Hugging Face repository | The vulnerable path involves remote repository retrieval | Normal model loading also contacts the Hub |
| New files appear under Hugging Face cache after a suspicious job | Indicates repository content was downloaded | Cache may be cleaned or shared across jobs |
| Python imports modules from cache paths | May show code execution from downloaded artifacts | Requires endpoint telemetry or audit hooks |
| Outbound connections after model load | May indicate second-stage payload retrieval or exfiltration | Many ML jobs legitimately download dependencies |
| Cloud API calls from notebook or GPU worker identities | Credentials may have been exposed to executed code | Requires cloud audit logs |
| New processes spawned by Python during model load | May indicate post-execution activity | Not all payloads spawn child processes |
| Unexpected reads of environment variables or credential files | Malicious code often harvests secrets first | Requires EDR, auditd, or language-level instrumentation |
On Linux, teams with auditd can monitor sensitive credential paths in shared ML hosts:
sudo auditctl -w /home -p r -k home_read_watch
sudo auditctl -w /var/run/secrets -p r -k container_secret_watch
sudo auditctl -w /root/.aws -p r -k aws_credential_watch
This is noisy and should be tuned. It is more useful in a short investigation window than as a permanent broad rule.
For containerized model loading, log network egress at the job or namespace level. If you cannot explain why a model evaluation job contacted a domain after loading a model, treat it as suspicious until proven otherwise.
उपचार
The first fix is dependency upgrade. Install Transformers 5.3.0 or newer across every environment that can load models. NVD explicitly recommends upgrading to 5.3.0 or later, and the v5.3.0 release references a kernel-related security fix.(एनवीडी)
python -m pip install --upgrade "transformers>=5.3.0"
For pinned projects:
transformers>=5.3.0
For Poetry:
poetry add "transformers>=5.3.0"
poetry lock
For Conda, use the channel and package strategy your organization already trusts, then verify the installed version from inside the environment:
python - <<'PY'
import transformers
print(transformers.__version__)
PY
Patch the dependency, rebuild containers, restart long-running workers, and clear stale runtime environments. A notebook server that keeps an old kernel alive can remain exposed even after the repository lockfile is updated.
Patch first, then reduce blast radius
Upgrading fixes the known vulnerable code path. It does not solve every model supply-chain risk. The next step is to make model loading less powerful.
A safer model-loading environment should have:
| Control | लक्ष्य |
|---|---|
| No long-lived secrets in environment variables | Prevent immediate credential theft |
| No production cloud role attached to evaluation jobs | Reduce impact of arbitrary code execution |
| Read-only dataset mounts when possible | Limit tampering and data destruction |
| No write access to source repositories | Prevent supply-chain persistence |
| Restricted outbound network | Block second-stage downloads and exfiltration |
| Model allowlist | Prevent arbitrary repository selection |
| Revision pinning | Prevent silent changes under a trusted model name |
| Separate cache per trust zone | Avoid cross-contamination between untrusted and trusted jobs |
Hugging Face documentation encourages pinning a specific revision when loading custom models, which is good practice beyond this CVE.(Hugging Face) A model name by itself is a moving pointer. A commit hash is a more stable artifact reference.
A controlled loading wrapper should reject raw user-provided model IDs unless they match an approved pattern:
from dataclasses import dataclass
@dataclass(frozen=True)
class ApprovedModel:
model_id: str
revision: str
APPROVED_MODELS = {
"internal/llm-eval-baseline": ApprovedModel(
model_id="internal/llm-eval-baseline",
revision="0123456789abcdef0123456789abcdef01234567",
),
"vendor/safety-classifier": ApprovedModel(
model_id="vendor/safety-classifier",
revision="abcdef0123456789abcdef0123456789abcdef01",
),
}
def resolve_model(user_choice: str) -> ApprovedModel:
try:
return APPROVED_MODELS[user_choice]
except KeyError:
raise ValueError(f"Model is not approved: {user_choice}")
Then use the approved model object:
from transformers import AutoModelForCausalLM, AutoTokenizer
approved = resolve_model("internal/llm-eval-baseline")
tokenizer = AutoTokenizer.from_pretrained(
approved.model_id,
revision=approved.revision,
trust_remote_code=False,
)
model = AutoModelForCausalLM.from_pretrained(
approved.model_id,
revision=approved.revision,
trust_remote_code=False,
)
The wrapper should live in a shared internal package, not as copy-pasted notebook code. If every team creates its own loader, policy drift is guaranteed.
Do not treat Safetensors as a complete fix
Safetensors is valuable. Hugging Face documentation describes Safetensors as a safer and faster alternative where available, and the Hub security documentation explains why pickle-based formats are dangerous: Python pickle can execute arbitrary code during loading through imports, builtins, and object construction behavior.(Hugging Face)
But CVE-2026-4372 is not simply “pickle is unsafe.” The issue involves configuration-driven control flow and kernel-loading behavior. A model can use Safetensors for weights and still include hostile configuration or other risky repository content. Safetensors reduces one class of deserialization risk. It does not make a model repository inert.
A practical policy should say:
| पुरातात्विक अवशेष | Security rule |
|---|---|
| Weights | Prefer Safetensors over pickle-based formats |
| Configuration | Validate keys and reject unexpected internal fields |
| Custom code | Require explicit approval, code review, and pinned revision |
| Tokenizers | Treat tokenizer files and supporting code as part of the artifact |
| Repository metadata | Log source, revision, author, and approval status |
| Runtime | Isolate model loading even for apparently safe artifacts |
This is the model-supply-chain equivalent of saying a signed package is better than an unsigned one, but a signed package should still be installed in a controlled environment with least privilege.
Secure model intake for teams that pull from the Hub
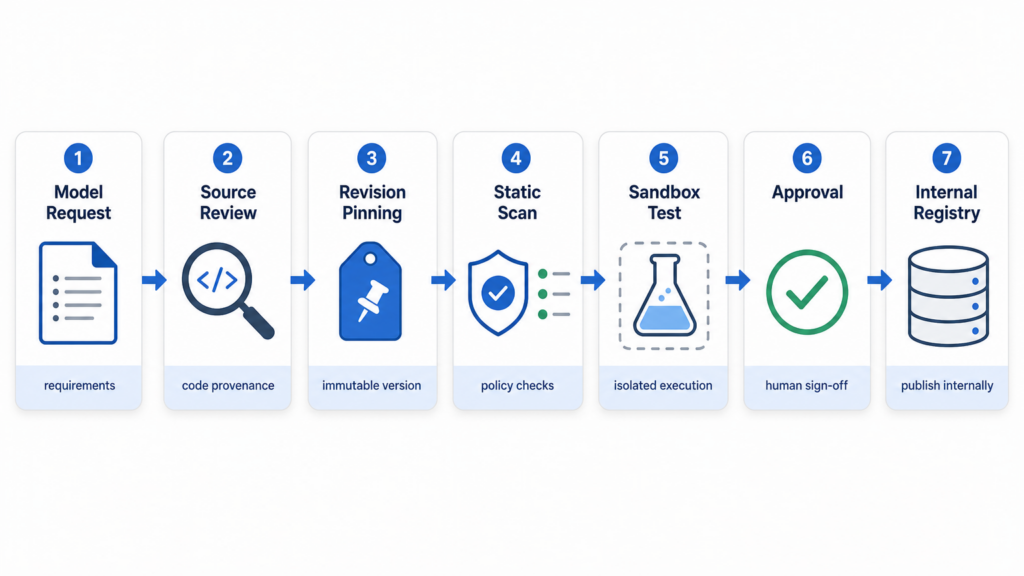
Many AI teams cannot simply ban public models. Research, benchmarking, red teaming, fine-tuning, and compatibility testing often require external model intake. The answer is not to stop using the Hub. The answer is to make model intake explicit.
A secure intake process should include:
| कदम | Required evidence |
|---|---|
| Request | Who requested the model, why it is needed, and where it will run |
| Source review | Model ID, author, repository age, files present, and whether custom code exists |
| Revision pin | Exact commit hash selected for testing |
| Static scan | Configuration keys, file types, pickle presence, custom Python files |
| Sandbox test | Load in an isolated environment with no secrets and controlled egress |
| Approval | Human review for use beyond sandbox |
| Promotion | Copy approved artifact into an internal registry or cache |
| Retest | Recheck after dependency upgrades or model revision changes |
Hugging Face Hub provides security features such as malware scanning, token controls, commit signing support, and other repository-level protections. Its documentation also states that files are scanned with ClamAV and that security scanning is not a substitute for user responsibility.(Hugging Face)
That split responsibility is the right model. The platform can scan and flag known problems. The consuming organization still has to decide which artifacts to run, where to run them, and what credentials are exposed.
A minimal sandbox runner might look like this:
docker run --rm \
--network none \
--read-only \
--cap-drop ALL \
--security-opt no-new-privileges \
-e HF_HOME=/tmp/hf-cache \
-v "$PWD/model-test:/work:ro" \
python:3.11-slim \
python /work/static_model_review.py
For a real model load test, you may need network access to fetch artifacts. In that case, do the fetch step separately, store the artifact by digest or pinned revision, then test offline. Avoid giving the loading process direct access to cloud metadata services, production databases, SSH keys, package publishing tokens, or internal control planes.
What to do if an untrusted model was loaded before patching
If an exposed environment loaded untrusted or unknown model repositories before the upgrade, treat it as a potential code execution event. The response should be proportionate, but it should not be casual.
Start with containment:
1. Stop the affected notebook, worker, or service.
2. Preserve logs and cache directories before cleanup.
3. Record installed package versions and container image digests.
4. Identify model IDs and revisions loaded during the exposure window.
5. Rotate credentials available to the process.
6. Review cloud, network, and endpoint logs for post-load activity.
7. Rebuild the environment from a clean patched base image.
Do not start by deleting everything. Deleting cache directories before preserving evidence may destroy the only record of which repositories were loaded.
Prioritize credential rotation based on what the process could access:
| Credential type | Why rotate |
|---|---|
| Hugging Face tokens | Malicious code may access private models or publish artifacts |
| Cloud access keys | GPU workers often run with storage or compute permissions |
| GitHub tokens | Notebooks and CI jobs often pull private repositories |
| Package registry tokens | Build environments may have publish rights |
| Database credentials | Evaluation jobs sometimes access internal datasets |
| Slack or webhook tokens | Useful for data exfiltration and persistence |
If the environment had a cloud instance role, inspect cloud audit logs for unusual API calls. If it had access to object storage, check reads and writes. If it ran in Kubernetes, inspect service account permissions, pod logs, network policy, and mounted secrets.
The absence of obvious malware files is not proof of safety. A payload can read environment variables and exfiltrate them without persistence. A payload can run only in memory. A payload can trigger a single outbound request and exit. Incident review should focus on what the process could do, not only what files remain.
Building a safer loader policy
A mature loader policy has three parts: input control, execution control, and evidence.
Input control answers: which model can be loaded?
Execution control answers: what can the loading process access?
Evidence answers: can we reconstruct what happened?
A practical policy can be expressed as code and infrastructure:
model_security_policy:
minimum_transformers_version: "5.3.0"
allow_public_hub_models: false
require_revision_pin: true
require_static_config_scan: true
reject_config_keys:
- "_attn_implementation_internal"
- "_experts_implementation_internal"
allow_pickle_weights: false
require_safetensors_when_available: true
require_custom_code_review: true
runtime:
network: "restricted"
secrets: "none"
filesystem: "read-only where possible"
cache_scope: "per trust zone"
logging:
model_id: true
revision: true
caller: true
dependency_versions: true
container_digest: true
This kind of policy is easier to enforce if model loading is centralized. If every team directly calls from_pretrained() from notebooks and scripts, security becomes advisory. If teams use an internal loader package or model gateway, controls can become defaults.
For organizations validating AI-adjacent attack surfaces, automated security workflows are useful when they preserve scope, evidence, and human approval. A platform such as Penligent can sit in that controlled validation layer for dependency inventory, retesting, evidence capture, and report generation around issues like model-loading RCE, while patching and isolation remain the primary controls. Penligent’s related technical write-up on NVIDIA Merlin RCE and SafeTensors is relevant because it treats ML artifacts as software supply-chain inputs rather than inert files.(पेनलिजेंट)
The key is not automation for its own sake. The key is repeatability. CVE-2026-4372 is the kind of issue that appears in many places at once: notebooks, old Docker images, research scripts, CI runners, batch jobs, and internal tools. A manual one-time check misses stragglers. A controlled repeatable workflow finds them again after the first fix.
Related CVEs and incidents that clarify the pattern
CVE-2026-4372 is part of a broader class of AI supply-chain failures where model or framework loading crosses into code execution. Two comparisons are especially useful.
CVE-2025-32434, when a safety flag was not enough
PyTorch CVE-2025-32434 is relevant because it also involved a model-loading safety expectation that did not hold. The official PyTorch advisory describes a critical issue where torch.load साथ weights_only=True could still lead to remote code execution, affecting PyTorch 2.5.1 and earlier and fixed in 2.6.0.(गिटहब)
The parallel is not that the bugs are identical. The parallel is the failure mode: a user-facing safety control was expected to prevent arbitrary code execution, but a vulnerable loading path still allowed it. In PyTorch, the issue centered on unsafe loading behavior around serialized artifacts. In CVE-2026-4372, the issue involved Transformers configuration and kernel-loading behavior. Both teach the same defensive lesson: “safe mode” flags reduce risk only if every path behind them preserves the intended boundary.
| संवेदनशीलता | अवयव | Safety expectation | Failure pattern | प्राथमिक सुधार |
|---|---|---|---|---|
| CVE-2026-4372 | Hugging Face Transformers | trust_remote_code=False should prevent remote model code execution | Malicious configuration influenced internal code-loading behavior | Upgrade Transformers to 5.3.0+ |
| CVE-2025-32434 | PyTorch | weights_only=True should constrain unsafe loading | torch.load path could still result in code execution | Upgrade PyTorch to 2.6.0+ |
Security teams should use both cases to update review checklists. Do not only ask, “Did the developer set the safe flag?” Ask, “Does the installed version actually enforce the safe flag across all relevant loading paths?”
The Open OSS privacy filter incident, a different path to the same supply-chain problem
In May 2026, HiddenLayer reported a malicious Hugging Face model repository that posed as an OpenAI privacy filter project and shipped a loader intended to fetch and execute infostealer malware on Windows systems. The incident was not the same mechanism as CVE-2026-4372, but it shows the same ecosystem risk: model repositories can be used to distribute executable behavior under the appearance of ordinary AI artifacts.(hiddenlayer.com)
The difference matters. CVE-2026-4372 was a vulnerability in how Transformers handled malicious configuration and kernel-loading logic. The privacy-filter incident was a malicious repository abusing user trust and repository presentation. One is a framework bug. The other is supply-chain deception. Both hit the same operational point: teams that pull external models need intake controls, sandboxing, revision pinning, and logging.
That is why model security should not be delegated entirely to framework flags or platform scanning. Those controls help, but they do not replace basic software supply-chain discipline.
Common mistakes that leave teams exposed
Patching the app but not the notebook fleet
Many organizations patch production services first and leave research infrastructure behind. That is understandable but dangerous. Notebook environments often have broader secrets than production services because they are used for experimentation. They may include cloud credentials, GitHub tokens, private dataset access, and writable storage.
If a notebook server loaded public models with an old Transformers version, include it in the exposure review.
Checking only source repositories
Dependency state lives in more places than Git. Docker images, Conda environments, cached virtualenvs, long-running Kubernetes pods, managed notebook images, and old CI runners can preserve vulnerable versions.
A good fix ticket should not say “updated requirements.txt.” It should say:
Updated dependency lockfile.
Rebuilt runtime image.
Verified installed version inside final image.
Restarted workers.
Checked notebooks and batch jobs.
Scanned model caches.
Reviewed logs for untrusted model loads.
Assuming trust_remote_code=False ends the conversation
trust_remote_code=False remains an important default, but CVE-2026-4372 exists precisely because the intended boundary was bypassed in affected versions. Keep the flag. Upgrade the library. Add source controls and sandboxing.
Confusing weight safety with repository safety
Using Safetensors is a good control for weight deserialization risk. It does not validate config.json, repository Python files, tokenizer behavior, dynamic loading logic, or the environment in which the model runs.
Letting model IDs come from untrusted input
Any service that accepts a model ID from a user and passes it directly into from_pretrained() should be treated as a high-risk design. This includes internal tools. Internal users can make mistakes, and internal systems can be compromised.
Use allowlists, approval workflows, and revision pins.
Running suspicious models to see what happens
Do not test an unknown model by loading it in your normal environment. That is the behavior the attacker wants. Static review comes first. If execution is necessary, use an isolated sandbox with no secrets, controlled network access, and disposable infrastructure.
व्यावहारिक कठोरता चेकलिस्ट
The following checklist is intentionally operational. It is written for teams that need to close the issue, not just understand it.
| Priority | Action | Evidence to keep |
|---|---|---|
| Immediate | Upgrade Transformers to 5.3.0 or later | Package version output from every runtime |
| Immediate | Identify installations with kernels installed | Environment inventory |
| Immediate | Search for from_pretrained() call sites | Repository scan results |
| Immediate | Scan model caches for risky internal config keys | Scanner output and reviewed paths |
| उच्च | Rebuild Docker images and notebook bases | Image digests and build logs |
| उच्च | Rotate credentials exposed to untrusted model-loading jobs | Rotation tickets and audit notes |
| उच्च | Restrict model loading to approved IDs and pinned revisions | Policy and allowlist |
| मध्यम | Add CI gate for vulnerable dependency versions | CI logs |
| मध्यम | Add runtime logging for model ID, revision, caller, and dependency version | Log samples |
| मध्यम | Separate caches by trust zone | Infrastructure change record |
| Long term | Move model intake into a central service or loader package | Architecture documentation |
A security ticket for CVE-2026-4372 should not close with “upgraded package” unless the organization has verified where the package actually runs and whether untrusted models were loaded before the upgrade.
अक्सर पूछे जाने वाले प्रश्न
Is CVE-2026-4372 a remote code execution vulnerability?
- Yes, but the practical trigger is model loading rather than a classic exposed network endpoint.
- NVD describes it as a critical remote code execution vulnerability in Hugging Face Transformers before 5.3.0.
- The attacker needs the victim or an automated workflow to load a malicious model repository.
- The impact can still be severe if the loading environment has secrets, cloud permissions, internal network access, or sensitive datasets.(एनवीडी)
Does trust_remote_code=False protect against CVE-2026-4372?
- Not reliably in affected Transformers versions.
- The core issue is that malicious configuration could reach a code-loading path despite the user not opting into remote code execution.
- Keep
trust_remote_code=Falseas a default, but do not treat it as sufficient on old versions. - Upgrade to Transformers 5.3.0 or later and add model source controls.(एनवीडी)
Which Transformers versions should be upgraded?
- Upgrade any Transformers installation below 5.3.0.
- NVD marks versions before 5.3.0 as affected.
- Pluto Security’s analysis narrows the practical vulnerable path to the 4.56.0 through 5.2.x range with the
kernelspackage installed, but the safe operational rule is still to upgrade to 5.3.0 or later. - Verify the installed version inside containers, notebooks, CI runners, and long-running services, not only in the source repository.(एनवीडी)
Do Safetensors prevent CVE-2026-4372?
- No, not by themselves.
- Safetensors helps reduce risk from unsafe weight deserialization.
- CVE-2026-4372 involves configuration-driven behavior and kernel-loading logic, so weight format alone is not a complete control.
- Use Safetensors where possible, but also validate configuration, restrict model sources, pin revisions, and sandbox model loading.(Hugging Face)
How can I check whether my environment is exposed?
- Check whether Transformers is installed below 5.3.0.
- Check whether the
kernelspackage is installed. - Search code for
from_pretrained(),AutoModelForCausalLM,AutoTokenizer, औरpipeline()call sites. - Scan Hugging Face caches and local model directories for
_attn_implementation_internalऔर_experts_implementation_internal. - Review logs for untrusted model IDs loaded before patching.
- Prioritize environments that loaded public or user-supplied model repositories.
Should I delete all Hugging Face cache directories?
- Do not delete caches before preserving evidence if you are investigating possible exposure.
- Cache directories may help identify which repositories and revisions were loaded.
- After evidence collection, clearing caches can be useful to remove stale artifacts and force clean downloads from approved sources.
- Separate future caches by trust zone so untrusted testing artifacts do not mix with production-approved models.
What should I do if an untrusted model was loaded before patching?
- Stop the affected job, notebook, or service.
- Preserve logs, cache contents, dependency versions, and container image identifiers.
- Identify which model repositories and revisions were loaded.
- Rotate any credentials available to the process.
- Review endpoint, cloud, and network logs for suspicious activity after model load time.
- Rebuild from a clean image with Transformers 5.3.0 or later.
- Add model allowlisting, revision pinning, and sandboxing before resuming untrusted model evaluation.
What matters after the patch
CVE-2026-4372 should change how teams think about model loading. The lasting issue is not a single internal field name. The lasting issue is that AI artifact loading has become a code execution boundary in many organizations, while too many workflows still treat it like downloading a dataset.
Upgrade Transformers. Rebuild every runtime that can load models. Check caches and logs before deleting evidence. Rotate exposed credentials when untrusted models were loaded. Pin model revisions. Reject arbitrary model IDs from user input. Run external model evaluation in isolated environments with minimal secrets and controlled egress.
The next bug may not use _attn_implementation_internal. It may not involve kernels. It may not be in Transformers. The durable defense is to treat model repositories as software supply-chain inputs, with the same seriousness applied to packages, containers, plugins, and CI scripts.