Anthropic has made the strongest public cybersecurity claim any frontier AI lab has made so far. In launching Project Glasswing, it said Claude Mythos Preview has already found thousands of high-severity vulnerabilities, including bugs across every major operating system and web browser, and that the model will not be made generally available. Project Glasswing was introduced with launch partners that include AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks, along with a commitment of up to $100 million in usage credits and $4 million in direct donations to open-source security organizations. VentureBeat turned that announcement into the headline most people remember: Anthropic’s most powerful cyber model was too dangerous to release publicly. (Anthropic)
That announcement is worth taking seriously. It is not worth reading loosely.
On the public record, the strongest evidence Anthropic has provided is not settled proof of stable, scalable, binary-only black-box vulnerability research. It is proof of two narrower and still very important things. First, Mythos appears to be extremely strong at source-visible, white-box vulnerability discovery and exploit triage. Second, Anthropic says the model is strong at reverse engineering stripped binaries into plausible source, then analyzing that reconstructed code together with the original binary. Those are real capabilities. They are not the same thing as saying the model has already been publicly proven to perform true binary-only black-box vulnerability research in the way that many readers now seem to assume. (Red Anthropic)
That distinction matters because “closed source” and “binary only” are not interchangeable. A workflow that starts by reconstructing readable source from a stripped binary has already recovered part of the semantic structure that makes source-level research easier. It has crossed an important technical threshold, but it has not erased the difference between source-assisted analysis and genuine binary-only research. If that sounds like pedantry, it is not. In vulnerability research, a claim about what the analyst or model can see is often a claim about most of the difficulty. (Red Anthropic)
The real story, then, is not that Anthropic has a mysteriously dangerous cyber model that has already solved the hardest version of software exploitation. The real story is that Anthropic has published unusually strong evidence for source-visible AI bug finding, unusually provocative evidence for source-assisted reverse engineering, and much thinner public evidence for the stronger claim now circulating in headlines: that AI has already crossed into reliable binary-only black-box vulnerability hunting. That stronger claim has not been publicly demonstrated with the same level of clarity. (Red Anthropic)
Project Glasswing turned a model claim into a trust claim
Project Glasswing is not just a product preview. It is a governance and trust announcement. Anthropic says Mythos Preview is an unreleased frontier model whose cyber capability is strong enough that it should be restricted to a coalition of large companies and maintainers working on critical software. It says the work is meant to focus on local vulnerability detection, black box testing of binaries, endpoint security, and penetration testing of systems, and that Anthropic will share public learnings within 90 days where disclosure is possible. That framing matters because the moment a company says a model is too cyber-capable for general access, the burden on its public evidence rises. The question stops being “Is this impressive?” and becomes “What exactly has been shown, under what conditions, and how much of the claim is public rather than private?” (Anthropic)
Anthropic’s own risk report reinforces that this is not a normal marketing cycle. The public version says Mythos Preview is not available for general access and describes the model as significantly more capable, more autonomous, and particularly strong at software engineering and cybersecurity tasks. The same report also says Anthropic identified errors in its training, monitoring, evaluation, and security processes during Mythos development. Anthropic judged the overall risk to be very low, but also said those errors reflected a standard of rigor that would be insufficient for more capable future models. That admission should not be ignored, because Glasswing asks the public to trust Anthropic both as a model developer and as a steward of a cyber-capable system. (Anthropic)
News coverage understandably emphasized the dramatic part. VentureBeat foregrounded the “too dangerous to release” framing and described Mythos as the center of Anthropic’s attempt to turn frontier AI cyber capability into a defensive advantage before hostile actors get similar tools. That is a fair summary of the public positioning. It is also exactly why the technical boundary has to be drawn carefully. High-stakes framing does not lower the evidentiary bar. It raises it. (Venturebeat)
What Anthropic Mythos publicly proves
The most important paragraph in Anthropic’s Mythos writeup is not the one about every major operating system and browser. It is the one describing the scaffold. Anthropic says that for the bugs it publicly discusses, it launches an isolated container that runs the project under test and its source code, then invokes Claude Code with Mythos Preview and prompts it to find a security vulnerability. In a typical run, the model reads code, develops hypotheses, runs the project, confirms or rejects those hypotheses, uses debugging as needed, and outputs either a no-bug judgment or a report with proof-of-concept and reproduction steps. Anthropic also says it often assigns agents to different files to improve coverage and asks the model to rank files by bug-likelihood. That is a serious workflow. It is also unmistakably a source-visible workflow. (Red Anthropic)
Anthropic further explains why it centered public examples on memory-safety bugs. Critical infrastructure still contains large bodies of C and C++ code. The obvious bugs in heavily audited codebases tend to be gone, so the remaining bugs are harder and more meaningful. Memory-safety issues are easier to validate cleanly because tools like AddressSanitizer sharply separate real bugs from hallucinations. And Anthropic’s team says it has substantial memory-corruption experience, which speeds internal verification. None of that weakens the result. It clarifies the result. Anthropic’s strongest public demonstrations sit in exactly the part of the problem space where white-box signal, sanitizer feedback, and exploit-oriented reasoning combine most cleanly. (Red Anthropic)
That clarification becomes even more important in Anthropic’s closed-source section. The company says Mythos is “extremely capable” at reverse engineering stripped binaries into plausible source code. From there, it gives Mythos both the reconstructed source and the original binary, instructing it to find vulnerabilities in the closed-source project and validate against the original binary where appropriate. That is an important claim. It is also the sentence that should stop anyone from describing the public evidence as clean proof of binary-only black-box research. Anthropic’s own description makes clear that the public closed-source workflow reintroduces source-like structure before the main vulnerability analysis stage. (Red Anthropic)
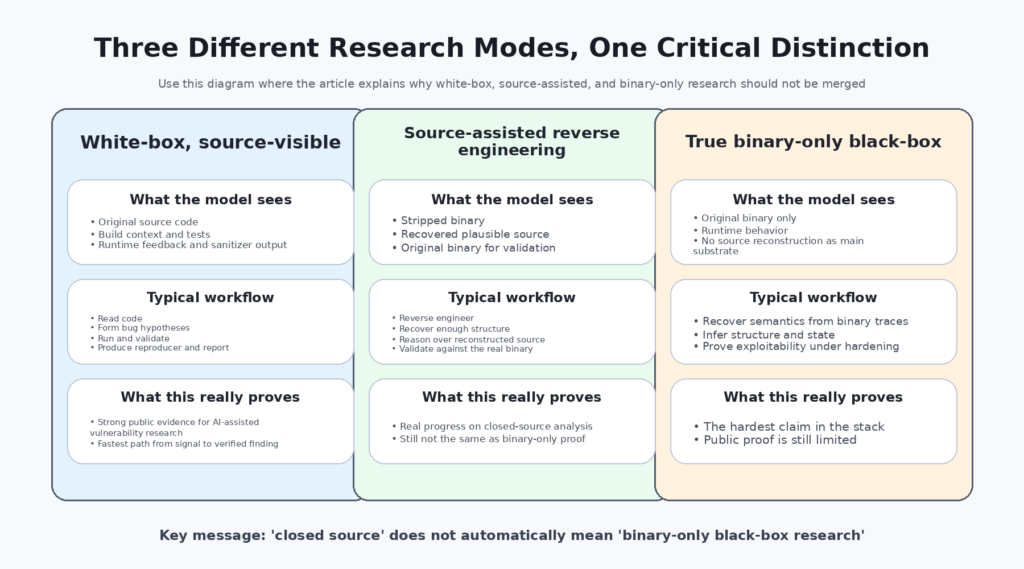
That difference is easier to see when the problem is broken into three distinct modes.
| Research mode | What the model sees | What Anthropic has publicly shown | What is still missing from the public record |
|---|---|---|---|
| White-box source-visible research | Original source code, build context, runtime feedback | Strong public evidence, including the main published case studies and scaffold description | Little ambiguity about the setup, but still limited public replication data |
| Source-assisted reverse engineering | Reconstructed source plus original binary | Publicly claimed by Anthropic for closed-source targets | Independent public artifacts showing the full pipeline and reproducible evaluation |
| True binary-only black-box research | Original binary and runtime behavior only, with no recovered source used as the main reasoning substrate | Not cleanly demonstrated in Anthropic’s public materials | Clear evidence on stripped binaries, hardened targets, disclosed human-assist level, and reproducible outcomes |
Anthropic has earned attention for the first two rows. The third row is where the language in public discussion has raced ahead of the public proof. (Red Anthropic)

White-box bug finding, source-assisted reverse engineering, and binary-only testing are not the same problem
Security people often say “source helps,” but that phrase is too gentle. Source code does not merely help. In many classes of research, source changes the nature of the task. Source exposes type information, names, module boundaries, control-flow intent, build configuration, assertions, logging, tests, and high-level data-structure semantics. It makes it easier to attach sanitizers, instrument edge cases, and ask whether a bug is real or just a crash-shaped shadow. It gives the analyst a legible map. Binaries almost always erase some of that map. Optimizations inline functions, collapse abstractions, reorder code, coalesce constants, and make human reasoning more expensive. Stripping symbols finishes the job. (Red Anthropic)
Reverse engineering partially rebuilds that map. Decompilers turn machine instructions into C-like or pseudo-C representations. String tables, imports, relocation information, and runtime traces restore context. Good analysts can get very far that way. Modern AI systems can help there. But the point is precisely that they have to rebuild context before they can reason as effectively as they do in the source-visible case. That rebuild step is not incidental. It is one of the hardest parts of the entire problem. (Red Anthropic)
Academic work has said this plainly. In a 2022 ASIACCS paper on the convergence of source-code and binary vulnerability discovery, Mantovani and coauthors argued that source-code and binary vulnerability discovery remain different research areas even though decompilers can bridge part of the gap. Their experiments found that the same vulnerabilities could be detected from decompiled code in 71 percent of cases, but false positives rose substantially and the differences between original and decompiled code materially affected the ability of analysis tools to understand what they were seeing. That is exactly the nuance the current public conversation keeps flattening. A decompiled view can be useful enough to recover many bugs. It is still not the same as original source, and its usefulness varies by target and by bug class. (s3.eurecom.fr)
This is why the phrase “closed-source vulnerability research” needs to be unpacked whenever it is used as evidence. There is a huge difference between “the model looked only at a stripped binary and runtime traces” and “the model first produced a plausible source reconstruction and then reasoned over that representation with the original binary nearby.” Both are impressive. They are not the same task. Conflating them is like treating an analyst who works from clean decompiler output, runtime logs, and function prototypes as equivalent to one who starts from raw machine code and a dead process. The second person is doing something harder. (Red Anthropic)
The public cases are important, and they are still source-first
Anthropic’s OpenBSD example deserves attention. In the Mythos writeup, Anthropic says the model found a now-patched 27-year-old bug in OpenBSD’s SACK handling that could let an adversary crash any OpenBSD host that responds over TCP. OpenBSD’s 7.8 errata page shows a March 25, 2026 reliability fix stating that TCP packets with invalid SACK options could crash the kernel. That public alignment matters. It means Anthropic is not pointing to a purely private, impossible-to-check story. There is a real public patch trail. (Red Anthropic)
But the existence of the patch does not change the methodological point. Anthropic’s own scaffold description says the public cases were run in a container with the project and its source code. That means the OpenBSD case supports a strong, meaningful claim: Mythos can do subtle source-visible systems bug finding in old, security-sensitive code. It does not, by itself, prove that Mythos can achieve the same quality of result when dropped into a stripped-binary-only environment without source reconstruction. The bug is real. The distinction is still real. (Red Anthropic)
The FreeBSD case is even more revealing because it shows how exploitability narratives can blur in public discussion. Anthropic says Mythos fully autonomously found and exploited a 17-year-old FreeBSD NFS vulnerability, triaged as CVE-2026-4747, and describes it as allowing anyone to gain root from anywhere on the internet. The FreeBSD advisory and the NVD record are more granular. They say the stack overflow itself does not require the client to authenticate first, but for the kernel NFS server, remote code execution is described as possible by an authenticated user able to send packets to the vulnerable server while the relevant component is loaded. The advisory also notes that userspace applications running an RPC server with the affected library would be vulnerable to remote code execution from any client able to send them packets, while saying FreeBSD base did not include such applications. (Red Anthropic)
That difference does not prove Anthropic is wrong. It may have an exploit chain that effectively removes the practical meaning of the authentication boundary in the kernel case. Anthropic’s public writeup, in fact, describes using an unauthenticated NFSv4 EXCHANGE_ID response to recover values needed to construct a live entry in the relevant table, which is part of why its description of the attack path is more aggressive than the initial advisory summary. But the discrepancy is still instructive. It shows why outside readers should not casually flatten a lab’s exploitability framing, a vendor advisory, and an NVD description into one neat sentence. “Unauthenticated internet root” is a much stronger public claim than “stack overflow with these conditions and these affected components.” If the public evidence is going to be treated as proof of a broader AI capability shift, that kind of detail matters. (Red Anthropic)
Anthropic also says it has identified thousands of additional high- and critical-severity vulnerabilities and is manually validating reports before disclosure. It reports that in 198 manually reviewed reports, expert contractors matched Claude’s severity judgment exactly 89 percent of the time and were within one severity level 98 percent of the time. Those numbers are impressive if they hold up. They are also self-reported, contractor-mediated statistics inside Anthropic’s disclosure process, not an independent public benchmark. A mature reading gives them weight without treating them as the last word. (Red Anthropic)
Reverse engineering is real progress, but it is not binary-only proof
The fairest way to read Anthropic’s closed-source section is that it signals real progress in source-assisted reverse engineering. That is a big deal. Recovering a stripped binary into a plausible source representation rich enough for further vulnerability analysis is hard. Doing it well enough that the resulting representation becomes a useful substrate for bug hunting is harder. A model that can do that reliably is not just autocompleting pseudocode. It is bridging part of the semantic loss introduced by compilation and symbol stripping. (Red Anthropic)
Still, “bridging part of the gap” is the right phrase, not “erasing the gap.” Reconstructed source is not original source. It reflects decompiler choices, inferred types, missing abstractions, guessed names, and sometimes deeply misleading structure. It may be good enough for certain classes of reasoning and still poor enough to distort others. The Mantovani paper is useful here because it quantifies a point every reverse engineer already knows qualitatively: decompiled code can preserve enough signal to recover many vulnerabilities, but not without new noise and analysis failure modes. That is why source-assisted vulnerability discovery and binary vulnerability discovery remain different research fields. (s3.eurecom.fr)
A realistic reverse-engineering workflow makes the distinction obvious. Even before looking for bugs, the analyst or agent needs to determine binary type, architecture, hardening state, dynamic libraries, syscall boundaries, input surfaces, configuration expectations, and whatever fragments of semantic structure can be recovered from imports, strings, and execution traces. That work is not just setup. It is part of the vulnerability research. If a model gets to skip some of that by first building itself a workable source-level view, that is still impressive. But it has changed the task.
A minimal comparison makes the point more concrete.
Source-visible triage often starts like this:
CC=clang CFLAGS="-O1 -g -fsanitize=address,undefined -fno-omit-frame-pointer" \
./configure
make -j
ASAN_OPTIONS=detect_leaks=1 ./target_program < repro_input
With source, the researcher can rebuild the target with sanitizers, line info, and debug-friendly settings, then move directly from crash to file, line, and data structure. That is not a shortcut in a trivial sense. It is access to the program’s semantics.
Stripped-binary triage often starts more like this:
file ./target.bin
checksec --file=./target.bin
readelf -hW ./target.bin
readelf -lW ./target.bin
readelf -sW ./target.bin | head
strings -a -n 8 ./target.bin | head -100
objdump -d ./target.bin | head -200
At that point, the real work has barely begun. The analyst still needs to recover calling conventions, code boundaries, structures, protocol assumptions, and state transitions, then confirm that a suspected flaw is both real and security-relevant. That is the world “binary-only” refers to. It is not the world Anthropic has publicly documented as its main closed-source workflow. (Red Anthropic)
This is also where more sober product writing tends to sound more credible than splashy model claims. Penligent’s public article on AI in binary exploitation CTFs says the field looks stronger from a distance than it does up close, arguing that the hard part is not text generation but exact interaction with a target process and attention to technical detail. Another Penligent article on AI pentest copilots makes a similar point from a different angle, saying the useful question is how to close the gap between signal and proof without hiding the evidence trail. Those are not proof points about Mythos. They are examples of the vocabulary security tooling companies should probably be using when they talk about AI and binaries. (penligent.ai)
Binary-only bug hunting is where the real difficulty starts
The phrase “find a vulnerability” hides too much. In the binary-only world, at least five different tasks are packed into that sentence. The first is anomaly detection: the model spots code or behavior that looks wrong. The second is bug validation: it shows that the condition is reachable and causes a fault or semantic failure. The third is security relevance: it establishes that the fault matters from an attacker’s perspective rather than being a harmless crash in a dead path. The fourth is exploit primitive construction: it demonstrates control over memory, control flow, privilege, or a similarly meaningful primitive. The fifth is operational reliability: it shows that the primitive survives real mitigations, target variability, and environmental noise. Those steps are hard to cleanly separate in source-visible work. They are much harder to collapse into a dependable chain in binary-only work. (Red Anthropic)
Modern mitigations are part of why. Kernel and browser exploitation rarely stop at “there is a memory corruption bug.” They quickly become questions about ASLR or KASLR, control-flow integrity, stack protection, pointer authentication, sandbox boundaries, seccomp profiles, and whatever product-specific hardening is layered on top. An analyst working from source can at least see more of the intended design and more of the guardrails that need to be bypassed. An analyst starting from stripped binaries has to infer much more of that from behavior or from recovered structure. Anthropic’s public post itself emphasizes that Mythos can chain subtle race conditions, KASLR bypasses, sandbox escapes, JIT sprays, and ROP techniques. Those are the right words for serious exploitation. They are also the kinds of tasks where public evidence needs to be unusually precise, because the step from “can explain” to “can deliver operationally” is large. (Red Anthropic)
The practical burden is even heavier in firmware and embedded targets. Those systems bring unfamiliar ABIs, sparse telemetry, weird boot assumptions, side-channel-heavy debugging, and tighter coupling to physical or virtualized hardware. Anthropic says Mythos has found firmware vulnerabilities that let it root smartphones, but those cases are still undisclosed because the relevant issues are not patched. That means the public is being asked to infer the hardest part of the capability from descriptions rather than artifacts. There are valid reasons for that during responsible disclosure. It is also why the correct public conclusion has to be narrower than the underlying internal claim. (Red Anthropic)
A useful way to think about this is as a ladder.
| Stage | What must be established | Why source helps | Why binary-only is harder |
|---|---|---|---|
| Suspicion | There may be a bug here | Readable logic and named structures accelerate hypothesis generation | Control flow and semantics must be recovered first |
| Reproduction | The bug can actually be triggered | Sanitizers, tests, and recompilation make replay easier | Replay may require reverse-engineered inputs and ad hoc instrumentation |
| Security impact | The bug is exploitable or meaningfully abusable | Source exposes guards, assumptions, and dataflow | Impact often depends on mitigations and hidden runtime state |
| Exploit primitive | The bug yields control or bypasses trust boundaries | Source clarifies memory layouts and side effects | Primitive construction may require deeper dynamic reasoning |
| Operational repeatability | The result survives hardening and noise | Build and configuration context are visible | Target state, protection, and environment must be inferred |
For readers evaluating AI cyber claims, the key habit is to ask which rung has really been reached. A vendor saying “we found a vulnerability” may mean “we found a crash in a source-visible build with excellent instrumentation.” That can still be valuable. It is not yet proof that the same system can reach the top rung against stripped binaries in realistic environments. (Red Anthropic)
Google, OpenAI, and DARPA point to the same lesson
This evidence problem is not unique to Anthropic. It appears across the field, including in the best public work.
Google Project Zero’s Big Sleep announcement remains one of the strongest public examples of an AI system finding a real memory-safety issue in widely used software. The case was SQLite. Google says the bug was found and fixed before it appeared in an official release, which meant users were not impacted. That is a strong defensive outcome and a public milestone worth remembering. But Google also says the methodology gave the agent a starting point in the form of recent commits, a commit message, and a diff, then asked it to review the current repository for related issues. Google explicitly describes this as variant analysis and says that task is a better fit for current LLMs than open-ended vulnerability research. That is a source-rich, repository-aware workflow, not binary-only black-box research. (Google Project Zero)
That matters because it reveals an industry pattern. The most credible public AI bug-finding evidence so far tends to cluster around source-visible or strongly source-structured work. That includes Anthropic’s public Mythos cases. It includes Google’s Big Sleep case. It does not make the work less important. It does show that the field’s loudest headlines sometimes outpace the actual distribution of public artifacts. (Red Anthropic)
DARPA’s Cyber Grand Challenge is a helpful historical anchor for the same reason. The challenge was about automatic defensive systems that could reason about flaws, formulate patches, and deploy them on a network in real time. The final event in 2016 featured Cyber Reasoning Systems that identified flaws and scanned an air-gapped network to find affected hosts. That history matters for two reasons. First, automated binary reasoning is not a brand-new fantasy created by LLM marketing. Second, the hard part has always been getting constrained challenge success to generalize to messy real-world software. LLMs change the balance by improving high-level reasoning, planning, and tool use. They do not magically erase the real-world gap that CGC never pretended away. (darpa.mil)
OpenAI’s public safety material adds another useful comparison because it is explicit about evaluation limits. OpenAI’s 2025 Preparedness Framework says cybersecurity is a priority risk category as models become more capable. Its GPT-5.3-Codex system card says High cybersecurity capability would mean removing existing bottlenecks to scaling cyber operations, either by automating end-to-end attacks against reasonably hardened targets or by automating the discovery and exploitation of operationally relevant vulnerabilities. But the same system card immediately stresses that its current benchmarks all have important limitations: CTFs test prescripted attack paths, CVE-Bench is limited to free and open-source web applications, and Cyber Range scenarios are still cleaner and less defended than real networks. The card says strong benchmark performance is necessary but not sufficient to conclude a model can conduct scalable, end-to-end operations against hardened targets. That level of caution is exactly what a mature public discourse needs. (OpenAI)
OpenAI’s later cyber-resilience post makes the same point more directly. It says cyber capability in AI models is advancing quickly, with measured improvement on CTF-style tasks, but describes high cyber capability in terms of working zero-day remote exploits against well-defended systems or meaningful assistance with complex stealthy intrusion operations. In other words, the benchmark story and the operational story are related but not identical. That is the same distinction many readers should be applying to Anthropic’s announcement. (OpenAI)
Strong public claims need an evidence ladder
The safest way to evaluate AI cyber announcements is to build an evidence ladder and force each claim onto the right rung.
At the bottom is benchmark skill. Can the model solve CTF challenges, repository tasks, or structured evaluation scenarios? This matters, but it says less about real-world targets than people often think. Above that is controlled real-world source-visible work, where the model analyzes actual code with clear runtime affordances. Above that is source-assisted reverse engineering, where closed-source binaries are transformed into workable high-level representations and then analyzed. Above that is true binary-only testing, where the model works from the original artifact and runtime observations without leaning on a recovered source view as its primary reasoning substrate. At the top is operationally relevant exploitation against defended, variable targets, with independent confirmation and clear disclosure of human assistance. (OpenAI)
Anthropic’s public material clearly reaches the second rung and makes a serious run at the third. It does not, on the public record, give enough detail to treat the fourth and fifth rungs as settled. That does not diminish the accomplishment. It disciplines the conclusion. (Red Anthropic)
A buyer, security lead, or journalist trying to judge an AI bug-hunting claim should ask at least these questions:
- Did the model have the original source code.
- If the target was closed source, did the workflow reconstruct source or rely on decompiler output.
- Was the binary stripped.
- Were hardening settings disclosed.
- Was exploitability independently confirmed outside the vendor’s own lab.
- Was the level of human assistance stated precisely.
- Were false positives and severity disagreements measured.
- Was the target a toy challenge, an open-source repo, or a real deployed system.
- Was the result reproduced on more than one machine or build.
- Was the public artifact strong enough that another security team could learn something concrete from it.
Those questions are not anti-AI. They are pro-evidence.
Anthropic’s disclosure story is impressive, and still incomplete
Anthropic’s article is unusually detailed in some areas and unavoidably thin in others. It gives a public scaffold. It names public cases. It gives cryptographic commitments for some still-unpatched results. It explains why certain exploit details cannot be disclosed yet. It says professional contractors are manually validating reports before disclosure. As transparency norms go, that is stronger than most AI-company cyber language. (Red Anthropic)
But the disclosure model also reveals the exact reason public readers should resist sweeping conclusions. The strongest claims are mostly in the undisclosed section: the browser chains, the smartphone rooting, the firmware results, the unpublished closed-source findings, the broader claim that the model has operated successfully across every major operating system and browser. Those claims may all be true. They may even understate what Anthropic has privately observed. Still, once the public record becomes more assertion-heavy than artifact-heavy, the right reading is “promising and possibly transformative,” not “case closed.” (Red Anthropic)
This is why the “too dangerous to release” framing can mislead even when it is sincere. It invites people to treat the non-public part of the story as a substitute for the public part. In security research, that is backwards. Secrecy can be necessary during patching. It cannot carry the full epistemic load of a field-defining technical claim. (Venturebeat)
What real proof of AI binary vulnerability research would look like
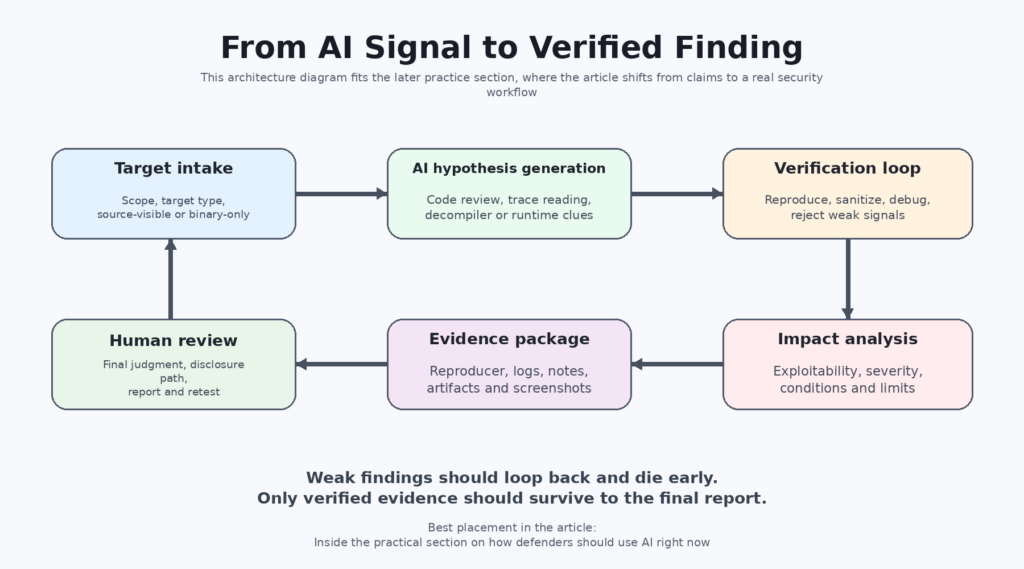
If a lab or vendor wanted to make the stronger claim cleanly, the public evidence would need to look more like a formal systems result than a dramatic announcement.
It would need target diversity. Not one or two curated examples, but a set of stripped binaries across different classes such as userland daemons, kernel components, browser subsystems, and firmware-like code. It would need strict source-visibility controls and a clear statement of whether decompiler output or reconstructed source was used. It would need precise human-assist disclosure: initial prompt only, bounded triage help, exploit debugging help, or something else. It would need reproducible artifacts, whether through patched public cases, vendor acknowledgments, or challenge targets whose exact properties were disclosed. And it would need metrics beyond “we found a lot”: false positive rate, time to validate, exploit success rate, environmental assumptions, and differences between crash discovery and weaponizable exploitation. (Red Anthropic)
The best public cyber model cards already hint at this standard. OpenAI’s system card separates vulnerability identification, exploitation capability, and end-to-end cyber operations, then spells out benchmark limitations. DARPA’s old challenge structure also separated flaw discovery, proof of vulnerability, and patching under constrained rules. These distinctions are not academic. They are the difference between a model that can reason well about bugs and a model that can materially change the offense-defense balance on defended systems. (OpenAI)
A stronger public evaluation framework might look like this.
| Criterion | Weak evidence | Better evidence | Strong evidence |
|---|---|---|---|
| Visibility controls | Unclear what the model saw | Source or decompiler use is stated | Inputs and visibility constraints are fully specified |
| Target realism | Toy or benchmark only | Real software in controlled conditions | Real software across classes and hardened settings |
| Human assist disclosure | Not disclosed | Broadly described | Task-by-task assist level stated |
| मान्यकरण | Internal only | Vendor advisory or patch | Independent or multi-party confirmation |
| Exploitability | Narrative only | Reproducible crash or PoC | Reliable effect under stated mitigations |
| Generalization | One-off demo | Multiple public cases | Consistent results across target classes |
Anthropic’s current public record sits in the “better evidence” column for several categories and in the “weak to better” range for others. That is already significant. It is just not the same as the strongest conclusion now floating around social media and headlines. (Red Anthropic)
The practical reading for defenders is more useful than the dramatic reading
The good news is that the narrower interpretation is still operationally important. If Anthropic’s public material is read as evidence that source-visible AI vulnerability research is becoming materially stronger, defenders should already care. That is not hypothetical. Google’s Big Sleep case showed a real memory-safety bug fixed before public release. Anthropic’s public OpenBSD and FreeBSD stories, whatever their exact generalization limits, indicate that source-visible systems bug finding with agentic workflows is moving into territory that used to be reserved for small groups of expert researchers. OpenAI’s preparedness material points in the same direction by treating advanced cyber capability as a serious governance category rather than a benchmark curiosity. (Google Project Zero)
That leads to a much better practical conclusion than “the model is too dangerous.” The practical conclusion is that organizations should use AI where the evidence is already strongest: source-available code review, variant analysis, triage, sanitizer-backed validation, de-duplication, reproduction support, and report assembly that preserves evidence rather than replacing it with polished prose. Anthropic itself says current generally available frontier models remain extremely competent at finding vulnerabilities even if they are less capable than Mythos at exploit generation. It explicitly recommends that organizations start learning those workflows now rather than waiting for Mythos-class systems to arrive broadly. (Red Anthropic)
That advice aligns with more grounded product writing in the market. Penligent’s article on AI pentest reports says the real problem is not how to make AI write a PDF, but how to turn security evidence into a result another human can verify, prioritize, and replay. That is the right framing for this entire category. The value of AI in security is often not “it found a magical bug.” It is “it helped compress the path from observation to verified finding without inventing evidence.” (penligent.ai)
A minimal engineering workflow for that looks less like a flashy autonomous demo and more like disciplined state handling:
# Example artifact-oriented finding pipeline
mkdir -p findings/$TARGET_ID
cp scope.txt findings/$TARGET_ID/
cp build-info.txt findings/$TARGET_ID/
cp crash-input.bin findings/$TARGET_ID/
cp sanitizer-log.txt findings/$TARGET_ID/
cp reproducer.sh findings/$TARGET_ID/
cp notes.md findings/$TARGET_ID/
That is boring on purpose. Good security evidence is usually boring before it becomes valuable. The AI system can help generate hypotheses, explain a crash, compare traces, organize logs, and draft the report, but the workflow still needs explicit artifacts, environmental notes, and reproducible proof. (penligent.ai)

How technical buyers should evaluate AI pentest and AI bug-hunting products
Buyers evaluating AI security products should be even more skeptical than readers evaluating lab announcements. Labs at least tend to publish model cards, risk reports, or research notes. Product demos often collapse multiple layers of difficulty into one polished result.
A useful first question is whether the product is strongest at source-visible workflows, source-assisted reverse engineering, or genuinely binary-only work. A useful second question is whether the vendor’s public language keeps those categories separate. If a company treats “closed source,” “decompiled,” and “binary only” as interchangeable marketing terms, that is already a warning sign. The difference is not cosmetic. It predicts what kinds of findings the system can likely validate, how much operator help it needs, and where it will fail under pressure. (Red Anthropic)
A third question is whether the vendor talks more about claims or more about evidence. A mature offensive-security workflow should preserve logs, captured states, reproduction steps, scope context, and confidence levels. Penligent’s public material on AI pentest copilots makes this point directly by arguing that a pentest copilot should be judged by the properties of penetration testing, not the properties of a chatbot. It says the system has to preserve observations, adapt when a hypothesis fails, gather evidence, and distinguish exploitable reality from noise. Whether a team uses Penligent or any other platform, that is a much healthier set of buying criteria than asking who has the loudest autonomous exploit demo. (penligent.ai)
A fourth question is whether the product can survive retest. That sounds almost embarrassingly basic, but it is the right test. If the finding cannot survive independent replay, then it does not matter how fluent the system sounded while it was producing it. The same Penligent report article makes that point bluntly: an AI pentest report is only useful if it can survive retest. That standard is portable across the whole market. It is the right standard for buyers, for maintainers, and for anyone trying to judge whether AI is actually shortening the path to a fix. (penligent.ai)
Why the language around binaries should stay strict
The binary question deserves special discipline because it is where hype most easily outruns proof.
Binary exploitation looks like a perfect LLM problem from a distance. There is code, there are patterns, there are memory bugs, there are known techniques, and there are often reusable primitives. But up close, the task becomes mercilessly precise. Offsets matter. Calling conventions matter. Exact allocator behavior matters. Race windows matter. Kernel-versus-userland boundaries matter. One wrong inference about structure layout or one smoothed-over assumption about state can ruin the entire chain. This is exactly why source reconstruction is such a meaningful intermediary step: it gives the model a more forgiving reasoning substrate. It is also exactly why that step should not be hidden inside the phrase “black box binary testing.” (Red Anthropic)
This is not a semantic complaint. It is a capability complaint. The industry should want vendors and labs to separate these task classes because the separation helps defenders deploy the right tools in the right places. A platform that is strong at source-visible variant analysis can still save an enormous amount of time. A platform that is strong at report drafting and evidence organization can still materially improve remediation speed. A model that can rebuild plausible source from stripped binaries can still expand what is possible in firmware and proprietary software review. None of that requires pretending the hardest binary-only frontier has already been publicly crossed. (Red Anthropic)
The fairest conclusion on Anthropic Mythos
Anthropic deserves credit for publishing more detail than most companies would have. It published a real scaffold. It tied public case studies to real patches and advisories. It admitted that its strongest public evidence is only a subset of what it claims to have observed privately. It paired the announcement with a concrete disclosure and partnership framework rather than a vague “trust us.” Those are all signs of a serious effort. (Red Anthropic)
At the same time, the right standard for reading the announcement is still stricter than most coverage has used. On the public record, Anthropic Mythos has not been fully demonstrated as a solved binary-only black-box vulnerability research system. It has been demonstrated as a very strong source-visible vulnerability research system, a strong exploit-triage system, and an apparently promising source-assisted reverse-engineering system. That is already a major development. It just is not the same claim. (Red Anthropic)
That distinction is not hostile to Anthropic. It is healthy for the field. If labs, vendors, and reporters start using binary language carelessly now, defenders will make worse buying decisions, maintainers will get noisier disclosure expectations, and the public conversation will become less useful precisely when these systems are becoming worth taking seriously. The right question is not whether Mythos is impressive. The right question is what, exactly, has been publicly proven. (Venturebeat)
The most useful response from security teams in 2026 is therefore not panic and not dismissal. It is disciplined adoption. Use AI aggressively where the evidence is already strongest. Demand precise language around binaries. Treat every autonomous exploit story as an engineering claim that must survive hard questions about visibility, validation, assistance, and reproducibility. If more of the industry adopts that standard, the AI cyber field will get sharper faster, and the signal-to-noise ratio will improve for everyone who actually has to secure systems. (OpenAI)
Further reading and reference links
Primary external sources
- Anthropic, Project Glasswing: Securing critical software for the AI era (Anthropic)
- Anthropic, Assessing Claude Mythos Preview’s cybersecurity capabilities (Red Anthropic)
- Anthropic, Claude Mythos Preview Alignment Risk Update (Anthropic)
- FreeBSD, FreeBSD-SA-26:08.rpcsec_gss (The FreeBSD Project)
- NVD, CVE-2026-4747 (एनवीडी)
- OpenBSD, OpenBSD 7.8 Errata (openbsd.org)
- Google Project Zero, From Naptime to Big Sleep (Google Project Zero)
- OpenAI, Our updated Preparedness Framework (OpenAI)
- OpenAI, GPT-5.3-Codex System Card (OpenAI)
- OpenAI, Strengthening cyber resilience as AI capabilities advance (OpenAI)
- DARPA, Cyber Grand Challenge (darpa.mil)
- Mantovani, Compagna, Shoshitaishvili, Balzarotti, The Convergence of Source Code and Binary Vulnerability Discovery – A Case Study (s3.eurecom.fr)
- VentureBeat, Anthropic says its most powerful AI cyber model is too dangerous to release publicly — so it built Project Glasswing (Venturebeat)
- Penligent, How to Use AI in CTFs (penligent.ai)
- Penligent, AI Pentest Copilot, From Smart Suggestions to Verified Findings (penligent.ai)
- Penligent, How to Get an AI Pentest Report (penligent.ai)
- Penligent, Pentest AI, What Actually Matters in 2026 (penligent.ai)
- Penligent homepage (penligent.ai)

