A breach can start between your scheduled tests
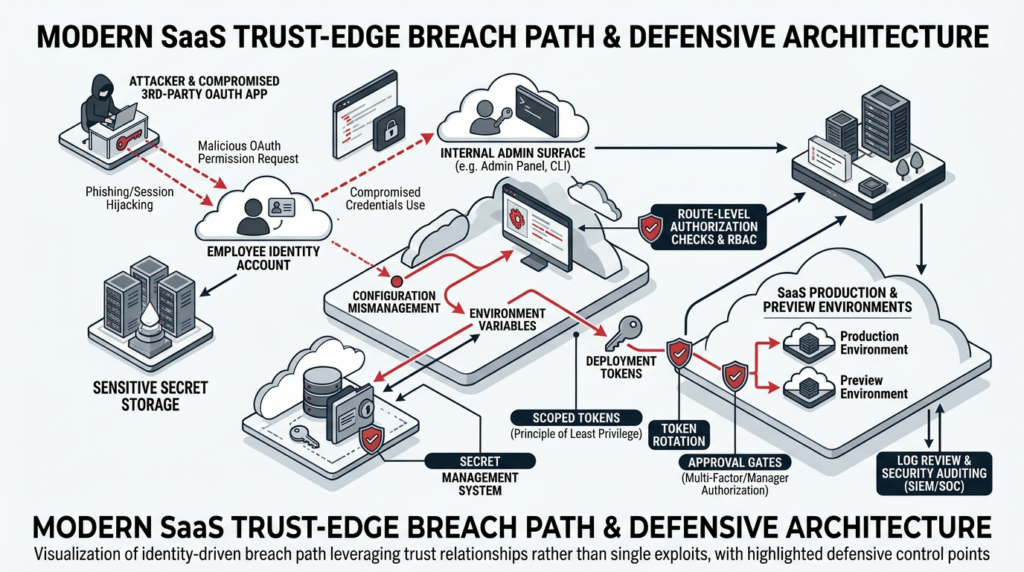
In April 2026, Vercel disclosed unauthorized access to certain internal systems after the compromise of a third-party AI tool was used to take over an employee’s Google Workspace account. The company said the attacker gained access to some Vercel environments and to environment variables that were not marked as sensitive, advised customers to inspect activity logs, rotate exposed secrets, review deployments, and check for use of the compromised OAuth application. That is the modern problem in one incident: the dangerous security change did not wait politely for the next quarterly or semiannual penetration test window. It emerged in the gap between formal assessments, through a trust edge that many traditional pentest calendars treat as background plumbing rather than a front-line attack surface. (Vercel)
A company can pass a scheduled pentest in January and still be materially exposed in April because an engineer authorizes a new OAuth app, a framework ships a critical patch that has not been rolled out everywhere, a CI workflow dependency is silently compromised, or a preview deployment leaks more than production does. That is not a criticism of pentesting as a discipline. It is a criticism of treating point-in-time pentesting as if it were a complete operating model for modern security. The cadence is wrong for the environment. (Vercel)
Annual pentests are a compliance floor, not an operating model
It is worth being precise here. Periodic penetration testing is still necessary. PCI DSS guidance says penetration testing must be performed at least annually and after any significant change. NIST SP 800-115, written in a very different era of software delivery, notes that because penetration testing is costly and can affect production systems, annual penetration testing may be sufficient in some environments, while regularly scheduled network and vulnerability scanning can run in between. Neither source says annual testing is worthless. Both treat it as one part of a larger verification pattern. (PCI Security Standards Council)
The problem is that many teams operationalized that guidance as a calendar ritual instead of a change-sensitive security loop. In a world of cloud deployments, fast-moving package ecosystems, third-party SaaS integrations, ephemeral environments, and agentic AI features, “significant change” is no longer a rare event. It is a recurring property of normal engineering work. That means annual or twice-yearly pentests remain useful as deep human-led assessments and compliance evidence, but they cannot be the only answer to the question that matters most: can an attacker turn today’s exact conditions into access, persistence, privilege, or impact? That conclusion is an inference from the way current systems change, but it is squarely aligned with PCI’s requirement to retest after significant change and OWASP’s treatment of security testing as an activity integrated across development, deployment, and maintenance. (PCI Security Standards Council)
OWASP’s Web Security Testing Guide does not frame testing as something that happens only at the end of a project. Its structure explicitly includes security tests integrated in development workflows, deployment, and maintenance and operations. That matters because it reflects an old but still underused truth: security testing belongs inside the software lifecycle, not outside it as an annual ceremony. What has changed is that the number of meaningful trust and execution boundaries has exploded. (owasp.org)
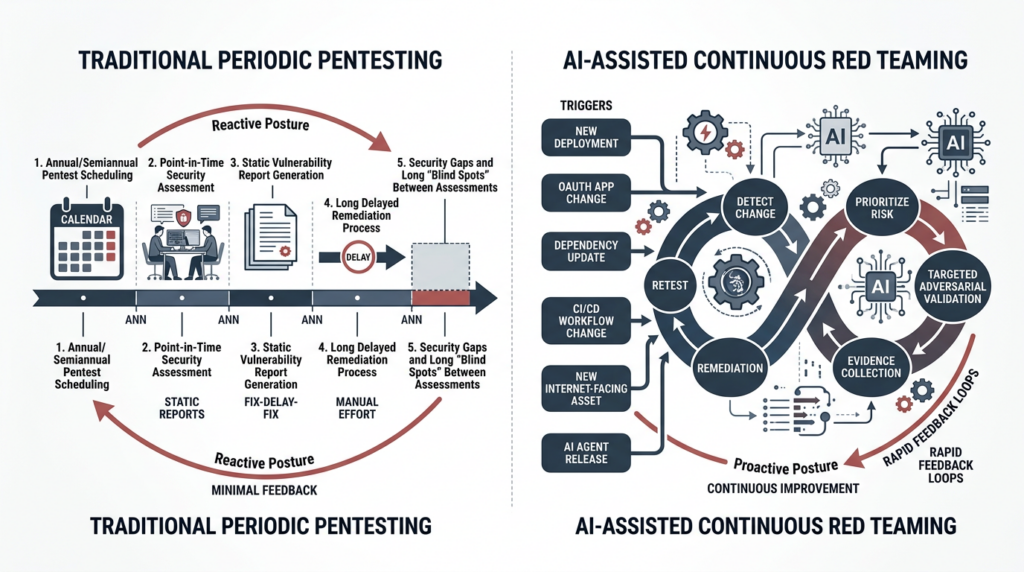
Continuous red teaming, defined for modern environments
For the rest of this piece, continuous red teaming means a structured, recurring, evidence-driven program of adversarial validation tied to high-risk assets and meaningful change events. It does not mean nonstop exploit attempts against production. It does not mean a scanner with a more aggressive marketing page. It does not mean a threat emulation marathon every week. It means building a loop that asks, over and over again, whether the environment that exists right now can be turned into compromise by realistic attacker behavior.
That definition matters because teams often blur together four very different activities. Continuous monitoring tells you what changed. Vulnerability scanning tells you whether known bad conditions are present. Manual red teaming and adversary emulation tell you how far a sophisticated human operator can go, often over a long horizon and sometimes under stealth constraints. Continuous red teaming sits in between: it turns current change, current exposures, and current attacker-relevant conditions into targeted adversarial verification. NIST SP 800-137 defines continuous monitoring as maintaining ongoing awareness of vulnerabilities and threats to support risk decisions, and says controls and risks should be assessed at a frequency sufficient for risk-based decisions. NIST SP 800-115 says penetration testing is useful for understanding how well a system tolerates real-world attack patterns, what sophistication an attacker needs, what countermeasures matter, and how well defenders detect and respond. Put together, those two ideas point to the model security programs actually need: continuous monitoring to know what changed, and recurring targeted adversarial testing to prove what those changes mean. (nvlpubs.nist.gov)
MITRE’s ATT&CK material helps sharpen the distinction further. ATT&CK presents adversary emulation and red teaming as structured ways to emulate specific threats and plan operations, and points to CALDERA as an automated adversary emulation system for post-compromise behavior. CISA’s SILENTSHIELD work likewise describes long-term, no-notice simulations of nation-state cyber operations. Those are valuable, high-end activities. But most teams cannot run them every time they ship a new auth flow, connect a new OAuth application, or add a new model tool. Continuous red teaming is the practical layer between point-in-time pentests and full-scale campaign simulation. (attack.mitre.org)
The simplest way to distinguish the layers is this:
| Method | Primary question | Typical cadence | Main output | Main limitation |
|---|---|---|---|---|
| Continuous monitoring | What changed and what is observable now | Near real time | Alerts, inventories, logs, drift signals | Does not prove exploitability |
| Vulnerability scanning | Is a known weakness present | Daily to weekly | Findings by signature, version, or configuration | Often weak on business logic and trust edges |
| निरंतर रेड टीमिंग | Can current conditions be turned into real attacker progress | Trigger-based and recurring | Proof, replayable evidence, retest status | Needs disciplined scope and human oversight |
| Annual or campaign red team | How far can skilled operators go under realistic assumptions | Periodic | Deep adversary narrative, control gaps, detection insights | Too slow and expensive to be the only layer |
The first two categories are strongly grounded in NIST continuous monitoring and scanning traditions; the last two inherit from penetration testing and adversary emulation practices. The table is a synthesis rather than a direct quotation from any single source. (nvlpubs.nist.gov)
AI red teaming and red teaming with AI are not the same job
Another confusion slows teams down. In NIST terminology, artificial intelligence red-teaming is a structured effort to find flaws and vulnerabilities in an AI system. OpenAI’s external red teaming paper uses the term similarly and explains it as a way to discover novel risks, stress test mitigations, bring in outside domain expertise, and add independence to risk assessment. That is one important activity. It is about testing the model or AI system itself. (एनआईएसटी कंप्यूटर सुरक्षा संसाधन केंद्र)
This article is about a different but related activity: using AI-assisted workflows to continuously red team modern systems, including web applications, APIs, cloud environments, CI/CD chains, identity edges, and AI-enabled applications. If you deploy agentic products, you probably need both. You need to red team the AI system because model behavior, tool use, and prompt-hijack paths create real security risk. And you need to use AI in your wider red-team workflow because modern systems now change too quickly for entirely manual validation to keep up. NIST’s Generative AI Profile explicitly recommends regular adversarial testing for GAI systems and also describes human-AI red teaming as a valid pattern, noting that GAI-led red teaming can be more cost effective than humans alone, while still requiring structured oversight and analysis. (nvlpubs.nist.gov)
The distinction matters operationally. “AI red teaming” by itself can mislead buyers and practitioners into thinking that any product with adversarial prompts against a chatbot has solved the broader exposure problem. It has not. A team running a customer-facing SaaS product with middleware auth, preview deployments, OAuth apps, workflow secrets, and model tools needs a program that crosses all of those layers. That is a different engineering job from running a one-off prompt attack campaign against the model. (एनवीडी.एनआईएसटी.जीओवी)
What AI actually changes in the loop
AI changes the economics of continuous red teaming in six places. It can compress noisy scanner or tool output into usable next-step context. It can preserve state between partial findings and retests. It can turn raw findings into structured hypotheses for replay. It can decide which of several trigger events deserves a targeted test first. It can generate evidence bundles and draft remediation-oriented summaries for different audiences. And it can help turn human red-team observations into repeatable automated checks.
That is not theory. PentestGPT showed that large language models can be effective at using common penetration-testing tools, interpreting outputs, and proposing subsequent actions, but also documented persistent trouble with long-term context, difficult targets, and accurate exploitation code construction. AutoPenBench extended that picture in a more recent benchmark: fully autonomous agents achieved a 21 percent success rate and were judged insufficient for production, while human-assisted agents reached 64 percent and presented a more viable path. The engineering conclusion is straightforward. AI is useful as a force multiplier inside a disciplined workflow. It is not yet a substitute for operator judgment, scoped execution control, and evidence review. (यूज़ेनिक्स)
That is also why the strongest AI-assisted offensive workflows today are not the ones that pretend to be autonomous geniuses. They are the ones that constrain scope, preserve context, orchestrate tools, and insist on replayable proof. Penligent’s public materials are notable here not because first-party marketing should settle a technical debate, but because the shape of the workflow is sensible: operator-controlled agentic workflows, editable prompts, explicit scope locking, and reporting framed as the end of an evidence chain rather than a pretty PDF generator. That shape aligns far better with current research than the fantasy that a model can spray ideas at a target and call the result a penetration test. (पेनलिजेंट.एआई)
Human-guided AI red teaming beats full autonomy today
Security teams should be honest about what belongs to humans and what belongs to machines. Humans should still approve scope, decide when a test crosses from safe validation into potentially disruptive exploitation, interpret business impact, handle ambiguous findings, and judge whether an apparent success is actually meaningful. Humans are also still better at noticing weak trust assumptions that no benchmark has encoded yet. (nvlpubs.nist.gov)
AI should handle the parts that security teams are chronically bad at sustaining under time pressure: diffing environments, correlating signals across tools, surfacing likely attack paths from changes, preserving procedural memory between attempts, generating negative tests after auth or routing changes, packaging artifacts, and turning successful validations into retest tasks. In other words, AI should do most of the stateful, repetitive, synthesis-heavy work that gets dropped when the queue is long. That division of labor is consistent with NIST’s human-AI red-teaming framing and with the benchmark evidence showing that human-assisted agents are materially more credible than fully autonomous ones in realistic testing tasks. (nvlpubs.nist.gov)
This is not a disappointing conclusion. It is the operationally useful one. The wrong dream is “replace the red team.” The right goal is “increase the number of meaningful adversarial validations you can run per change window without destroying evidence quality.” That is what makes continuous red teaming achievable for teams that do not have a large offensive security staff.
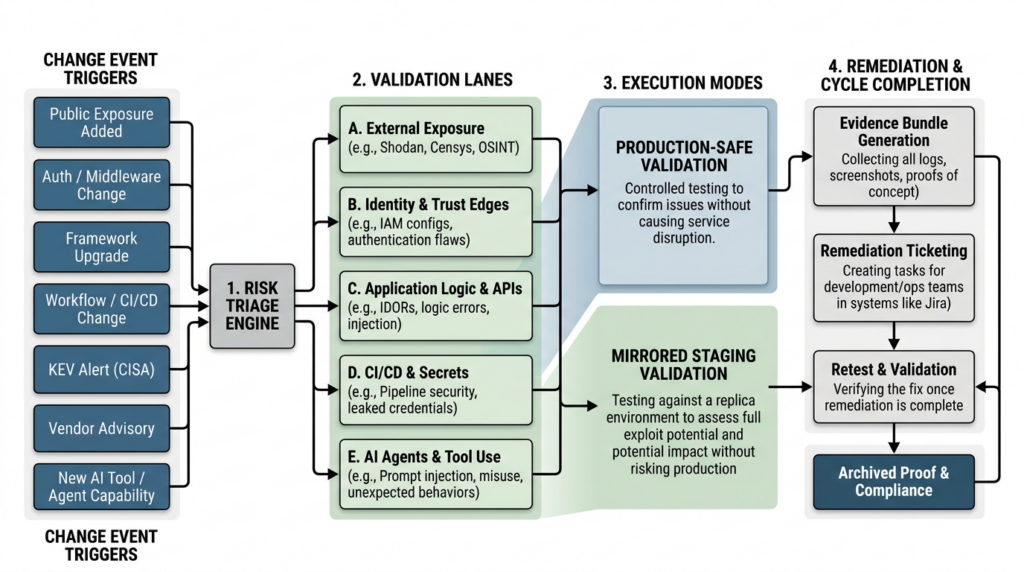
A trigger-based model for continuous penetration testing
A serious continuous red teaming program starts with trigger logic, not with a slogan. The easiest failure mode is to say “continuous” and then run the same shallow checklist every night. That produces alert fatigue, false confidence, and almost no exploitability signal.
A better model starts by identifying the exact events that should trigger targeted adversarial verification. PCI already tells you that significant change should force retesting. CISA’s incident response lessons learned advise organizations to continuously discover and validate internet-facing assets through automated asset management and scanning. NIST continuous monitoring says assessment frequency should be sufficient to support risk-based decisions. The implication is simple: tie offensive verification to the same changes your engineers already know are risky. (PCI Security Standards Council)
The most important triggers usually include new public exposure, auth and session logic changes, framework or dependency upgrades, changes to CI/CD workflows, new or modified cloud permissions, new third-party integrations, secrets handling changes, KEV additions, emergency vendor advisories, new model or tool-calling capabilities, and launches of high-value features. Every one of those can materially alter the feasible attack path without waiting for your next manual engagement. The Vercel incident, the Next.js middleware advisory, the tj-actions compromise, and the agent-security findings from NIST’s large-scale competition all fit inside that model. (Vercel)
The trigger model becomes more usable when it is explicit:
| Trigger | यह क्यों मायने रखती है | Minimum validation | Evidence to keep | Suggested owner |
|---|---|---|---|---|
| New public endpoint, subdomain, or preview environment | New entry point may bypass hardened paths | Enumeration, auth boundary checks, exposure review | Headers, screenshots, service fingerprint, route map | Platform or app security |
| Auth, session, middleware, or SSO change | Trust boundary may move silently | Negative access tests, session replay checks, privilege boundary tests | Request traces, expected vs actual responses, route matrix | Application security |
| Framework or dependency upgrade | Security semantics may change | Version inventory, patch coverage, targeted regression tests | SBOM diff, version proof, retest logs | AppSec and engineering |
| Workflow or CI/CD change | Secret and trust edges may shift | Workflow review, permission diff, secret handling checks | Workflow diff, token inventory, logs | डेवसेकऑप्स |
| KEV or vendor critical advisory | Known attacker interest just changed | Fast targeted checks on exposed assets | Asset list, version confirmation, mitigation proof | Security operations |
| New model, tool, or agent capability | Prompt-hijack and tool abuse risk changes | Tool permission tests, prompt injection scenarios, output validation | Conversation logs, tool call records, policy decisions | AI security and product |
This table is an operating synthesis grounded in PCI retest logic, CISA continuous validation guidance, NIST monitoring, and the practical security implications of recent incidents and advisories. (PCI Security Standards Council)
The five lanes of continuous red teaming
Most teams fail here by trying to “test everything continuously.” That is not a strategy. It is an excuse for weak coverage. The better pattern is to define a small number of lanes that map directly to the kinds of changes attackers actually exploit.
Those lanes should be broad enough to matter and narrow enough to operationalize. For most modern organizations, five lanes are enough to start: external exposure and attack surface drift, identity and trust edges, application logic and APIs, CI/CD and secret handling, and AI-agent attack surfaces. If you can build a working trigger-and-evidence loop in those five lanes, you will already be ahead of most security programs that still treat pentesting as a calendar deliverable.
External exposure and attack surface drift
The first lane is what the internet can see today, not what the CMDB thought existed last month. This is where continuous red teaming overlaps with attack surface management, but it is not the same thing. Discovery alone tells you that a host, path, or service exists. Red teaming asks what an attacker can do with it now.
This lane should cover new domains and subdomains, preview or staging environments, alternate ports, legacy admin paths, framework-specific metadata leaks, TLS and CDN drift, forgotten test applications, and route exposure caused by deployment or reverse-proxy changes. OWASP’s testing structure still puts information gathering, attack surface identification, entry-point discovery, and architecture mapping at the front of web testing for a reason. You cannot validate what you have not actually mapped. CISA’s guidance to continuously discover and validate internet-facing assets is the same idea at the organizational level. (owasp.org)
The key operational shift is to treat “newly reachable” as a security event. A preview deployment, a temporary helpdesk app, a forgotten dashboard, or a subdomain pointed at a new service should not wait for the next pentest window. They should trigger a small, fast validation package: service enumeration, auth boundary checks, route discovery, metadata review, safe access-control probes, and screenshot-backed confirmation of what is reachable. The evidence bundle should prove not just that the surface exists, but that the expected protections exist with it.
A simple trigger file can keep this lane from becoming ad hoc:
# trigger-rules.yml
rules:
- event: public_exposure_added
match:
- "dns/**"
- "ingress/**"
- "terraform/network/**"
- "k8s/ingress/**"
run:
- external-enumeration
- auth-boundary-negative-tests
- header-and-cdn-review
- screenshot-and-route-capture
That example is illustrative, but the logic matters. You do not need a perfect platform on day one. You need deterministic rules that translate a change into a repeatable validation package.
Identity, auth, and trust edges
Modern breaches often begin at the trust edge, not in the flashy exploit chain. OAuth grants, service-account permissions, environment variables, deployment tokens, session middleware, weak separation between internal and public flows, and over-broad integrations all belong here.
Vercel’s April 2026 bulletin is a crisp example. The company said the incident originated with the compromise of a third-party AI tool used by an employee, which then enabled takeover of that employee’s Google Workspace account and access to some Vercel environments and environment variables not marked as sensitive. The immediate customer guidance was not “run a code scanner.” It was to inspect activity logs, rotate secrets, review suspicious deployments, use sensitive environment variables, and rotate deployment protection tokens. That is a trust-edge incident. The attacker moved through authorization and secret-handling surfaces, not a classic application RCE. (Vercel)
This is exactly why periodic pentests miss the most expensive failures. Traditional engagements are often scoped around the application under test, not the full set of adjacent trust boundaries that engineering gradually accumulates. A continuous red teaming program should treat auth and identity changes as first-class triggers. That means route-level negative tests after middleware changes, OAuth app inventory reviews, policy and permission diffs after IaC changes, service-account drift checks, secret-read path validation, and retests after token rotation or SSO modifications. The most damaging auth bug is often not “authentication broken everywhere.” It is “one path no longer enforces the rule everyone assumes exists.” (एनवीडी.एनआईएसटी.जीओवी)
Application logic and APIs
This lane is where shallow automation breaks down and where disciplined AI assistance can be most useful. Application logic and API flaws are rarely just version problems. They live in state transitions, object ownership, idempotency assumptions, race conditions, role mismatches, and business rules that engineering has not written down as testable security invariants.
OWASP’s testing guide still reflects that reality. Its web testing model includes identity management, authentication, authorization, session management, input validation, business logic testing, and API testing as separate areas because these failures do not collapse into one generic scanner outcome. They require context, sequence, and an understanding of how the application is intended to behave. (owasp.org)
Continuous red teaming should turn those business assumptions into reusable negative tests. If an order should never be cancellable after fulfillment, that should be a recurring adversarial test after state-machine changes. If object ownership should be enforced across all API routes, that should be replayed after auth middleware, model bindings, serializer changes, or endpoint additions. If admin-only actions are implemented through route middleware or policy wrappers, those paths should be replayed after framework upgrades and deployment changes. This is where AI is useful not as an exploit magician but as a context-preserving assistant that can transform diffs, logs, and prior finding history into a fresh set of targeted negative tests.
A simple CI trigger can make this practical:
name: targeted-security-validation
on:
push:
branches: [main]
paths:
- "src/auth/**"
- "app/api/**"
- "middleware.ts"
- "policies/**"
- "package-lock.json"
- "pnpm-lock.yaml"
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Build trigger manifest
run: python scripts/build_trigger_manifest.py
- name: Run auth and API regressions
run: python scripts/run_targeted_security_tests.py manifest.json
- name: Archive evidence
run: python scripts/archive_artifacts.py manifest.json
That workflow is intentionally boring. It should be. Security validation becomes sustainable when it looks like normal engineering, not a one-off consulting event.
CI/CD, dependencies, and secret handling
The fourth lane is where modern programs quietly lose control: workflows, build agents, action dependencies, artifact trust, and secret propagation. A team can be excellent at application testing and still be one compromised workflow dependency away from a large secret spill.
The GitHub advisory for CVE-2025-30066 is a good illustration. The tj-actions/changed-files GitHub Action was compromised in a supply-chain attack that impacted more than 23,000 repositories. Multiple version tags were moved to point at a malicious commit, and CI/CD secrets were exposed in workflow logs. The issue was active between March 14 and March 15, 2025, and was later patched in v46.0.1. That is not a hypothetical “supply chain risk” slide. It is exactly the kind of event that makes a six-month testing cycle look structurally mismatched to the way modern delivery systems fail. (गिटहब)
This lane needs its own adversarial discipline. When workflow definitions change, continuous red teaming should diff permissions, inspect secret reachability, validate network egress expectations, review action pinning, and confirm that logs do not expose sensitive material under failure conditions. When a dependency advisory lands, the job is not just to patch. It is to prove whether the dependency is reachable in your environment, whether the vulnerable path is present, whether secrets or credentials are exposed, and whether the fix is effective on the systems that matter.
A minimal evidence object for this lane might look like this:
{
"finding_id": "CICD-SECRET-001",
"trigger": "workflow_dependency_change",
"asset": ".github/workflows/release.yml",
"hypothesis": "Secrets may be exposed through compromised action execution or logs",
"validation_steps": [
"Review workflow permissions and action pinning",
"Replay build in isolated environment",
"Inspect logs for secret disclosure patterns",
"Verify token rotation completed"
],
"artifacts": [
"workflow_diff.txt",
"replay_log.txt",
"token_inventory_before_after.json"
],
"retest_status": "pending"
}
Again, the point is not the exact schema. The point is to make secret and trust-edge validation explicit and replayable.
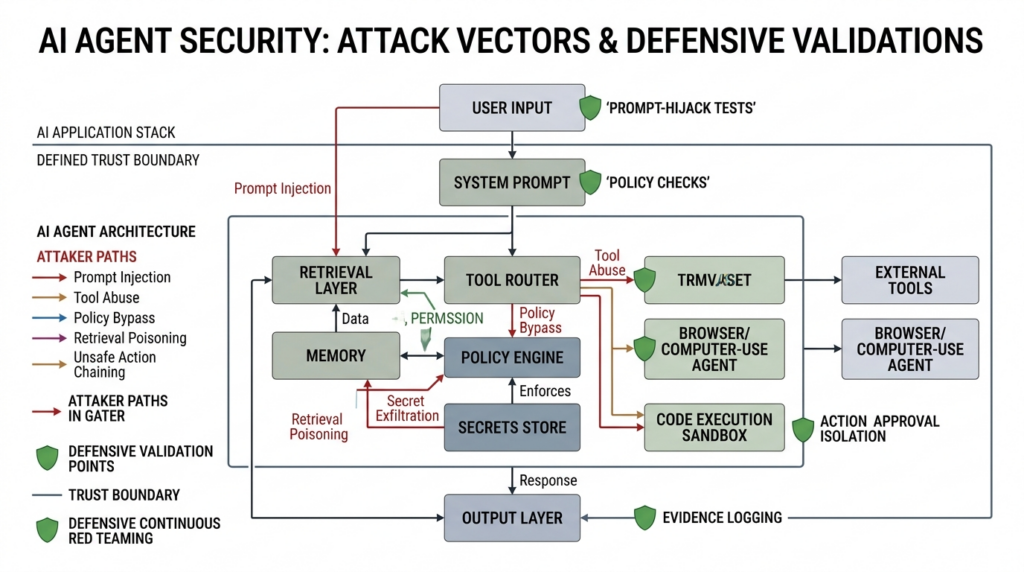
AI agents, tool use, and prompt-hijack surfaces
If your product includes retrieval, tool calling, code execution, browser use, or computer-use agents, you need a fifth lane. This is the lane many teams are about to underestimate in the same way they previously underestimated cloud IAM and CI/CD.
NIST’s March 2026 summary of a large-scale red-teaming competition on AI agent security should have ended the debate. Across more than 250,000 attack attempts from over 400 participants, at least one successful attack was found against all 13 target frontier models in agentic scenarios such as tool use, coding agents, and computer use agents. NIST also found families of attacks that transferred across models and scenarios, which matters because defenders often overfit to one model or one narrow prompt-defense pattern. (एनआईएसटी)
OpenAI’s external red teaming paper helps explain why this lane requires ongoing work. It emphasizes that red teaming is particularly valuable when systems are evolving quickly, when new forms of interaction appear, and when models gain access to new tools and actions such as code execution or function calling. NIST’s GAI Profile similarly recommends regular adversarial testing and structured human feedback for systems where harms may not be fully captured by existing benchmarks. In practice, if your AI application can read private documents, call external services, act on behalf of a user, or execute code, then prompt-hijack scenarios and tool-abuse scenarios are not edge cases. They are core security validation cases. (OpenAI CDN)
Continuous red teaming for AI applications should therefore include at least five recurring checks: can untrusted content override higher-priority instructions, can tool permissions be escalated indirectly, can the system exfiltrate secrets from memory or retrieved context, can the model induce unsafe actions through ambiguous tool schemas, and can policy or provenance controls be bypassed under realistic user and document flows. These checks are not one-and-done because the attack surface changes when you swap models, change retrieval sources, add tools, update safety prompts, or modify orchestration code. If your application is agentic, every capability release is also a trust-boundary change.
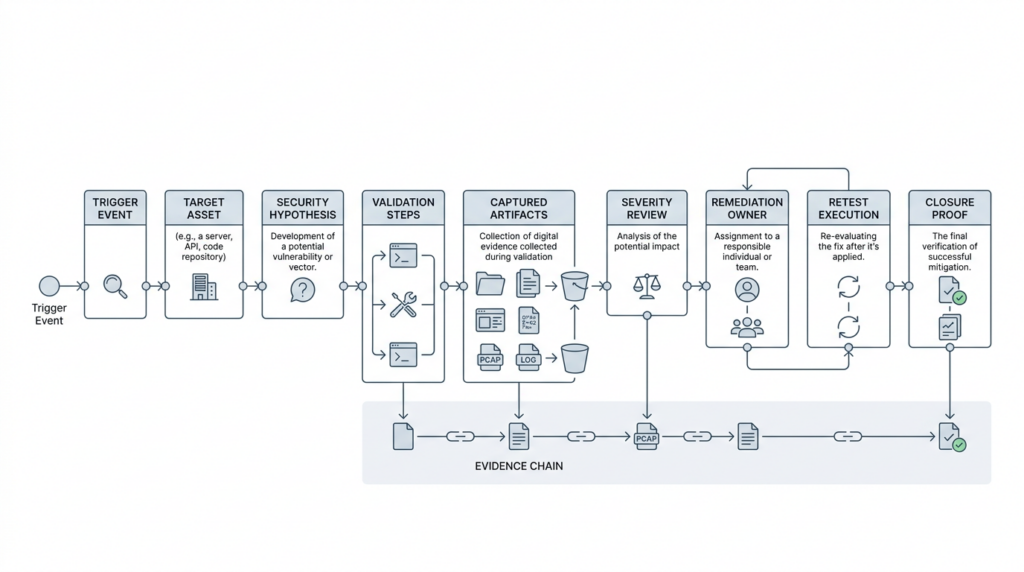
Evidence is the product
The output of continuous red teaming should not be an alert feed. It should be an evidence pipeline. That is the only way the work survives handoff to engineering, incident response, auditors, or leadership.
NIST SP 800-115 is useful here because it treats reporting and remediation as part of the assessment lifecycle, not a decorative appendix. It notes that different report formats may be required for different audiences. It also says mitigation should be verified by audit and retesting, and explicitly notes that additional vulnerabilities may be uncovered during follow-up security tests. That is a powerful reminder that remediation is not the end of the story. Every fix needs a replayable proof that the original path is closed, and that proof may surface adjacent weaknesses. (nvlpubs.nist.gov)
That means each finding in a continuous red teaming program should have a minimum evidence bundle: trigger event, target asset, expected security invariant, actual observed behavior, exact validation steps, artifacts, remediation owner, retest timestamp, and final disposition. If a human cannot replay the finding or a machine cannot schedule the retest, the output is too weak for a high-frequency program.
This is another place where AI should be judged by evidence discipline rather than prose quality. Penligent’s public article on AI pentest reporting gets that right when it argues that the real problem is not “how to make AI write a PDF,” but how to turn security evidence into a report another person can verify, prioritize, and act on. That is the correct mental model for continuous red teaming too. The report is not the product. The evidence chain is the product, and the report is one rendering of it. (पेनलिजेंट.एआई)
Real CVEs that show why cadence matters
The abstract argument becomes easier to believe when you look at vulnerabilities that map directly onto real trust boundaries.
CVE-2025-29927 and the cost of assuming middleware is the security boundary
The Next.js advisory for CVE-2025-29927 states that authorization checks could be bypassed if the application relied on middleware for those checks. GitHub’s advisory lists affected and patched versions, and NVD adds a mitigation note: if patching is not immediately feasible, external requests containing the x-middleware-subrequest header should be prevented from reaching the application. This is a textbook example of why continuous red teaming needs a framework-aware auth lane. If your access control logic depends on middleware execution, a framework defect can instantly turn expected-deny routes into expected-allow routes, and a routine framework update or partial rollout can leave parts of your fleet in inconsistent states. (गिटहब)
The relevant question for defenders is not just “are we on a vulnerable version.” It is also “where in our estate is authorization implemented in middleware,” “which routes would become exposed if middleware is skipped,” and “do our negative access tests actually prove that those routes are still blocked after a framework change.” That is a continuous red teaming problem because it combines version inventory, architectural dependency, and route-level proof.
CVE-2024-3400 and why perimeter advisories must trigger immediate validation
Palo Alto Networks described CVE-2024-3400 as a command injection vulnerability in PAN-OS GlobalProtect that could allow an unauthenticated attacker to execute arbitrary code with root privileges on affected firewalls. The advisory also made clear that only specific PAN-OS versions and configurations were impacted, and that Cloud NGFW, Panorama, and Prisma Access were not. CISA’s KEV catalog separately lists the issue as known exploited. This is exactly the kind of vulnerability that destroys slow testing rhythms: internet-facing, high impact, and configuration-dependent. (security.paloaltonetworks.com)
A continuous red teaming program responds to this kind of event with a fast, specific workflow: identify internet-facing GlobalProtect assets, map versions and relevant feature configurations, validate whether the exposure exists, apply or confirm mitigation, and then retest until proof is archived. The program does not need a broad “network pentest” to justify this work. The vendor advisory and KEV status are already enough to trigger targeted adversarial validation on the exact assets that matter.
CVE-2024-4577 and the risk of legacy deployment corners
PHP’s 8.x changelog records CVE-2024-4577 as a bypass of the older CVE-2012-1823 issue in PHP-CGI. CISA’s KEV catalog lists it as known exploited. Independent analysis from watchTowr noted that exploitation affected Windows-based PHP used in CGI mode and highlighted locale-specific conditions that made the issue especially dangerous in some deployments. Even if a given organization decides that its exact configuration is unlikely to match, the lesson is broader: risky deployment modes often survive in obscure, forgotten parts of an environment long after most engineers assume they are gone. (php.net)
That makes CVE-2024-4577 a strong case study for the “legacy corner” problem. Continuous red teaming should not limit itself to the newest frameworks and most visible services. It should also continuously ask which outdated execution modes, edge configurations, regional deployments, or inherited systems still exist and whether they are internet reachable. Asset discovery without adversarial validation will usually understate the risk of these corners, because the exposure is often a combination of deployment model, version, and reachability rather than a single clean scanner signature.
CVE-2025-30066 and why supply chain validation belongs in the loop
The tj-actions incident is useful because it forces defenders to widen the red-team lens. CVE-2025-30066 was not about a route in your production application. It was about a GitHub Action dependency in CI/CD. Yet the impact was severe because compromised version tags pointed repositories at a malicious commit and exposed secrets in workflow logs. If your security validation model excludes build workflows, action permissions, release automation, and secret propagation, then it excludes one of the places attackers increasingly prefer to operate. (गिटहब)
This is where continuous red teaming becomes more valuable than periodic pentesting in a narrow sense. A traditional pentest may never touch your workflow dependency graph. A trigger-based program can. When workflow files change, when a dependency advisory lands, or when anomaly detection flags suspicious egress, the program can launch a targeted sequence: permission diff, log review, replay in an isolated environment, secret rotation, and post-rotation validation. That is not glamorous offensive work. It is the work that prevents workflow compromise from becoming production compromise.
How to build the pipeline without turning production into a blast zone
One reason teams resist continuous red teaming is a reasonable fear that “continuous” means “constantly hammer production with exploits.” It should not. NIST SP 800-115 is clear that penetration testing uses real attacks and can damage or disrupt systems, which is why planning and risk control matter. That caution is even more important in a high-frequency program. (nvlpubs.nist.gov)
The practical answer is to split validation into production-safe modes and mirrored-environment modes. Production-safe validation includes passive enumeration, access-control negative tests, policy assertions, version and configuration confirmation, secret and permission reachability checks, workflow diffing, and logging review. Mirrored or staging validation includes the more invasive proof work that might stress the target, alter state, or create reliability risk. The point is not to avoid proof. It is to run the right proof in the right place while maintaining the same evidence format across both modes.
A sane pipeline therefore has six phases: detect the trigger, prioritize the asset and lane, select a validation profile, execute tests in the appropriate environment, archive evidence, and schedule retest after remediation. That is the same basic loop NIST uses in monitoring and assessment, just adapted to modern change velocity. (nvlpubs.nist.gov)
Teams that need a platform layer rather than a pile of scripts should judge products against that exact loop. Public Penligent material is relevant here because it emphasizes authorized use, scope control, and verification and reporting as one connected workflow rather than separate post-processing steps. Used that way, a platform is not replacing engineering judgment or vendor guidance. It is helping turn repeated targeted validation into a repeatable operational system. (पेनलिजेंट.एआई)
Metrics that show whether the program works
The wrong metric is “number of tests run.” A team can automate thousands of useless checks and still miss the path that matters. The right metrics measure change response, evidence quality, and remediation closure.
A useful starter set looks like this:
| मेट्रिक | यह क्यों मायने रखती है | Common failure pattern | Improvement action |
|---|---|---|---|
| Mean time from high-risk change to targeted validation | Measures whether the loop is fast enough | Validation begins days after deployment | Move trigger parsing into CI and change management |
| Percentage of high-risk changes that triggered tests | Measures coverage of the operating model | Security depends on manual memory | Expand trigger rules and ownership |
| Findings that survive manual replay | Measures evidence quality | AI-generated findings collapse under review | Tighten artifact requirements |
| Retest closure rate | Measures whether fixes are verified | Tickets close without proof | Make retest mandatory before close |
| Internet-facing assets with current validation status | Measures exposure freshness | Unknown or stale assets | Improve discovery and asset-owner mapping |
| Secret rotation completion after trust-edge incidents | Measures response depth | Credentials rotated selectively or not at all | Automate token inventory and retest |
| AI-agent scenarios with recent adversarial validation | Measures coverage of new execution boundaries | Agent features launch without security replay | Add tool-use and prompt-hijack lane |
These metrics are recommendations, not standardized industry thresholds. Their value is that they focus leadership on what continuous red teaming is supposed to produce: faster validation after risky change, better proof, and fewer unverified assumptions.
A 30-60-90 day rollout
Teams do not need to solve every lane at once. They need to start where change is both frequent and dangerous.
In the first 30 days, define the trigger catalog and choose the first ten high-value assets or systems. Build one evidence schema, one retest state model, and one owner map. Start with three lanes: external exposure, auth and identity, and CI/CD and secrets. Those three usually give the fastest reduction in untested trust edges.
By day 60, integrate triggers into engineering workflows. Framework and dependency updates should generate targeted regression tests. Workflow changes should trigger secret and permission checks. New public endpoints should generate route and auth validation. At this stage, the program should already be able to answer a simple operational question: what changed this week that required adversarial verification, and where is the proof that it happened.
By day 90, add the AI-agent lane if the business has tool use, retrieval, or model-mediated action paths. Add KEV- and vendor-advisory-driven fast checks for exposed assets. Add report variants for engineering, leadership, and audit audiences. Keep the annual manual pentest. Keep occasional full adversary emulation. But stop pretending those exercises are enough by themselves.
The strategic shift is not from manual to automated, or from human to AI. It is from schedule-driven security to change-driven verification. That is the real transition.
Continuous red teaming is not a replacement for pentesting
It is an extension of pentesting into the cadence modern systems require. Deep human-led engagements still matter. Campaign-based red teams still matter. Purple-team exercises still matter. They answer questions that a trigger-based loop cannot fully answer. CISA’s no-notice red-team operations and MITRE’s adversary emulation model remain important reference points for mature programs. (cisa.gov)
What has changed is that the space between those deeper engagements is now where many material security failures are born. Framework vulnerabilities change auth behavior. Third-party integrations shift trust edges. Workflow dependencies leak secrets. Agentic features create new attack paths. Continuous red teaming exists to keep those failures from hiding in the gap between formal tests. If the six-month pentest is the only offensive validation your program performs, then the real attacker is working on a much shorter loop than you are. (एनवीडी.एनआईएसटी.जीओवी)
अधिक पठन और संदर्भ
- Vercel, Vercel April 2026 security incident. (Vercel)
- PCI Security Standards Council, Penetration Testing Guidance. (PCI Security Standards Council)
- NIST, SP 800-115 Technical Guide to Information Security Testing and Assessment. (nvlpubs.nist.gov)
- NIST, SP 800-137 Information Security Continuous Monitoring. (nvlpubs.nist.gov)
- OWASP, Web Security Testing Guide. (owasp.org)
- MITRE ATT&CK, Adversary Emulation and Red Teaming. (attack.mitre.org)
- CISA, Lessons learned from incident response engagements, including continuous discovery and validation of internet-facing assets. (cisa.gov)
- CISA, SILENTSHIELD red-team operations. (cisa.gov)
- NIST, Artificial intelligence red-teaming glossary. (एनआईएसटी कंप्यूटर सुरक्षा संसाधन केंद्र)
- NIST, AI RMF Generative AI Profile. (nvlpubs.nist.gov)
- NIST, Insights into AI Agent Security from a Large-Scale Red-Teaming Competition. (एनआईएसटी)
- OpenAI, OpenAI’s Approach to External Red Teaming for AI Models and Systems. (OpenAI CDN)
- USENIX Security 2024, पेंटस्टजीपीटी. (यूज़ेनिक्स)
- EMNLP Industry 2025, AutoPenBench. (ACL Anthology)
- GitHub Advisory and NVD, CVE-2025-29927. (गिटहब)
- Palo Alto Networks and CISA KEV, CVE-2024-3400. (security.paloaltonetworks.com)
- PHP and CISA KEV, plus watchTowr analysis, CVE-2024-4577. (php.net)
- GitHub Advisory, CVE-2025-30066. (गिटहब)
- Penligent, Project Glasswing Shows Why AI Defense Needs Continuous Penetration Testing. (पेनलिजेंट.एआई)
- Penligent, How to Get an AI Pentest Report. (पेनलिजेंट.एआई)
- Penligent homepage, including scope-control language and authorized-use disclaimer. (पेनलिजेंट.एआई)

