Copy Fail is CVE-2026-31431, a Linux kernel local privilege escalation flaw in the crypto subsystem. The short version is sharp: a low-privileged local user can combine AF_ALG, splice(), AEAD decryption behavior, and an authencesn scratch write to place four controlled bytes into the page cache of a readable file. In public demonstrations, that primitive was used against a setuid-root binary to gain root on tested mainstream Linux distributions. Theori and Xint’s public write-up describes the bug as a deterministic path, not a race-dependent trick, and NVD records the CVE as a Linux kernel issue now listed in CISA’s Known Exploited Vulnerabilities catalog. (xint.io)
The phrase “four-byte write” can make the bug sound smaller than it is. The impact comes from where those bytes land. Copy Fail does not need to modify the file on disk through the normal write path. It corrupts the page cache, the in-memory file data the kernel can later use for reads, mappings, and execution. Xint’s disclosure states that the corrupted page is not marked dirty for ordinary writeback, so disk-based checksum comparisons can miss the execution-time corruption while the cached page remains active. (xint.io)
The vulnerability is not remotely exploitable by itself. An attacker needs local code execution first. That boundary matters. It also does not make the bug comfortable. A low-privilege shell from a web exploit, a malicious dependency running in CI, a compromised developer account, an untrusted container workload, or a multi-tenant Linux shell is exactly the kind of foothold local privilege escalation bugs are built to amplify. Microsoft described Copy Fail as affecting multiple major Linux distributions and cloud Linux workloads, with early exploitation activity observed primarily around proof-of-concept testing at the time of its report. CISA’s KEV listing means defenders should treat the patch window as operationally urgent rather than theoretical. (microsoft.com)
Copy Fail deserves more than a patch note because it is a clean example of a modern kernel boundary failure. splice() was designed for efficient data movement. AF_ALG was designed to expose kernel crypto operations to userspace. AEAD code uses scatterlists to describe non-contiguous input and output buffers. authencesn uses destination memory as temporary scratch space for Extended Sequence Number handling. Each design choice has a reason. The vulnerability appears when their assumptions collide.
The facts that matter first
| आयाम | What defenders should know |
|---|---|
| सीवीई | CVE-2026-31431 |
| Common name | Copy Fail |
| संवेदनशीलता वर्ग | Linux kernel local privilege escalation |
| Main component | algif_aead in the AF_ALG userspace crypto interface, with the authencesn AEAD template |
| Core primitive | Controlled four-byte write into the page cache of a readable file |
| Attack prerequisite | Low-privileged local code execution |
| Remote by itself | नहीं |
| Public exploit status | Theori’s GitHub repository contains public exploit material and tested distribution notes |
| Practical outcome | Public demonstrations use page-cache corruption of setuid-root binaries to obtain root |
| Container relevance | Page cache is a host kernel resource, so containerized workloads can be exposed when untrusted code runs on vulnerable nodes |
| प्राथमिक सुधार | Apply vendor kernel updates and reboot into the fixed kernel |
| Interim mitigation | Disable the affected algif_aead module or block risky AF_ALG access where compatible with the environment |
| Detection focus | Runtime behavior, especially unusual AF_ALG socket use, splice() adjacency, suspicious setuid execution, and non-root processes spawning su in abnormal contexts |
Canonical stated that the affected component is the Linux kernel module algif_aead, assigned the issue CVE-2026-31431, and scored it CVSS 3.1 7.8 High for Ubuntu. Ubuntu also distinguished ordinary hosts from container deployments, noting that the published exploit executes in non-container workloads and that container deployments running potentially malicious workloads may face container escape scenarios. (Ubuntu)
The Xint technical write-up gives the deepest public explanation of the root cause. It describes a logic bug in the kernel’s authencesn cryptographic template that lets an unprivileged local user trigger a deterministic four-byte page-cache write into any readable file. It also says a 732-byte Python script was used to obtain root on tested Ubuntu, Amazon Linux, RHEL, and SUSE systems, and that the primitive crosses container boundaries because page cache is shared across the host. (xint.io)
NVD’s record connects the vulnerability to CWE-669, Incorrect Resource Transfer Between Spheres, and shows CISA KEV metadata with a required action date of May 15, 2026, for covered federal civilian agencies. That classification is useful because Copy Fail is not best understood as “crypto math went wrong.” The cryptographic operation is only the path. The security failure is that a resource from one sphere, page-cache-backed file data, entered a sphere where it could be treated as writable output. (एनवीडी)
Why Copy Fail is not just another Linux LPE
Linux local privilege escalation bugs are common enough that teams sometimes triage them mechanically: check CVSS, check whether the host is internet-facing, patch during the next maintenance window. Copy Fail punishes that habit. The attacker does not need a remote network vector inside this CVE. They need any prior way to run code as a low-privileged user. In real infrastructure, that can mean a compromised web service account, a CI job executing untrusted code, a container running third-party workloads, a shared build box, a notebook environment, or a developer VM.
The most important practical difference is reliability. Dirty COW, CVE-2016-5195, was a race condition in the Linux kernel’s copy-on-write handling that allowed local users to gain privileges by writing to a read-only memory mapping. Dirty Pipe, CVE-2022-0847, involved uninitialized pipe buffer flags and allowed unprivileged local users to write to pages in the page cache backed by read-only files. Copy Fail belongs in the same mental family of “read-only trust boundary becomes writable,” but the mechanism is different: it comes from AF_ALG, splice(), AEAD scatterlist handling, and authencesn scratch-space behavior. (एनवीडी)
Theori and Xint explicitly contrast Copy Fail with older Linux privilege escalation bugs because the published path does not require winning a timing race, guessing kernel offsets, compiling a per-target payload, or tuning for a particular distribution. Sysdig’s analysis similarly describes Copy Fail as a straight-line logic flaw and notes that the public PoC chains AF_ALG binding, page-cache-backed splice() input, and an AEAD receive operation into persistent page-cache corruption. (xint.io)
That does not mean every Linux machine has the same business risk. A single-user workstation with no untrusted local code has a different exposure profile than a Kubernetes node running arbitrary build jobs. A hardened appliance with no Python runtime and no untrusted shell access differs from a multi-tenant jump host. But defenders should not dismiss the issue simply because the CVE is local. In many real intrusions, “local code execution as nobody” is the opening move, not the end state.
The page cache is the wrong place to lose a trust boundary
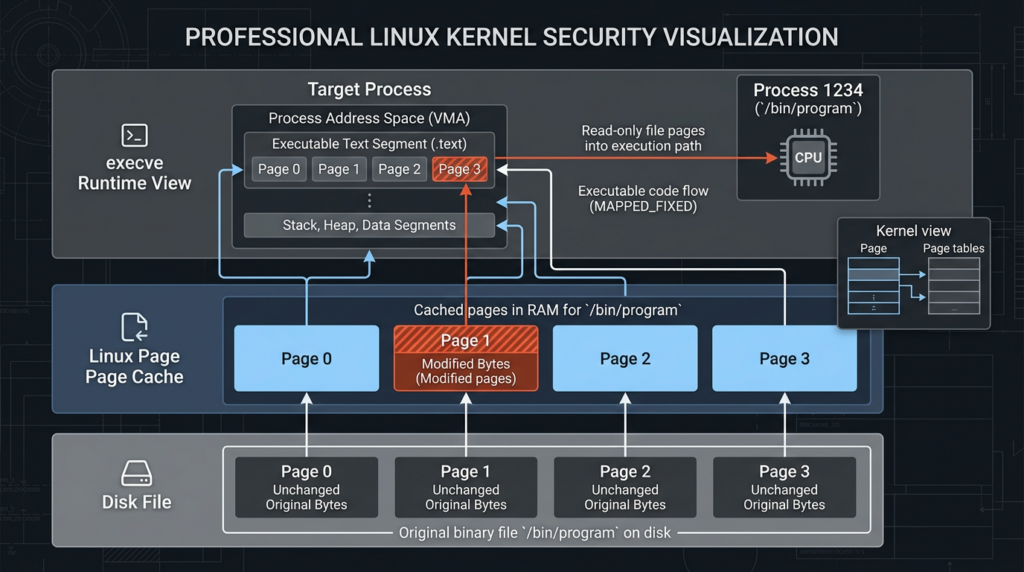
The page cache is one of the reasons Linux is fast. File contents read from disk are kept in memory so the kernel can serve future reads, memory mappings, and executable loads without repeatedly going back to storage. That behavior is normal. It is also security-sensitive. When an executable file is used, the bytes the kernel sees may come from cached pages rather than from a fresh disk read.
Copy Fail matters because it can alter that cached view without performing a normal file write. The target file can remain unchanged on disk. The inode permissions can still say read-only. Package verification can still hash the vendor-supplied file and report no difference. A file integrity monitor that only watches disk writes can miss the event. But if the page cache contains modified bytes and execve() later loads from that cached data, the runtime behavior can differ from the disk artifact a defender inspected.
This is why “we verified the package hash” is not a complete answer after suspected exploitation. It is useful for package integrity. It is not sufficient to exclude transient page-cache corruption. Xint’s write-up states that the corrupted page is not marked dirty for writeback, ordinary on-disk checksum comparisons miss it, and the in-memory version is visible system-wide while cached. (xint.io)
A safer mental model looks like this:
Disk:
/usr/bin/su contains the expected vendor bytes.
Page cache:
The kernel holds cached pages used by read, mmap, and exec paths.
Buggy path:
A file-backed page enters a crypto scatterlist by reference.
Boundary failure:
That page is later treated as part of a writable destination.
Result:
The cached execution view can differ from the file stored on disk.
The lesson is bigger than this CVE. When high-performance kernel paths preserve references rather than copying data, they preserve provenance too. That provenance matters. A page from a read-only file is not just a buffer; it carries a security boundary. If a later subsystem loses that boundary, a tiny write can become a privilege transition.
What splice() contributes
The Linux splice() system call moves data between two file descriptors without copying between kernel address space and user address space. The man page states that at least one of the file descriptors must refer to a pipe. In normal systems programming, that is a performance feature. It lets data move efficiently through kernel-managed buffers. (Man7)
In Copy Fail, splice() is not the vulnerability by itself. Its role is to deliver page-cache-backed file data into a path that later interacts with the kernel crypto API. When file data is moved through splice(), the downstream path may receive references to cached file pages rather than independent copies. If every later subsystem treats those pages as read-only input, the optimization is safe. If later code chains them into an output scatterlist and an algorithm writes past the intended boundary, the optimization becomes an attack primitive.
That distinction matters for defenders. Blocking every use of splice() is not a realistic mitigation for most Linux systems. The dangerous combination is narrower: untrusted local code that can drive AF_ALG AEAD operations in a way that includes page-cache-backed file data and reaches the vulnerable authencesn behavior. The best fix is still the kernel patch. Interim controls should focus on algif_aead और AF_ALG exposure, not a broad war against ordinary file descriptor plumbing.
What AF_ALG exposes
AF_ALG is the userspace socket interface for the Linux kernel crypto API. Kernel documentation says the API is accessible from user space and includes message digests, symmetric ciphers, AEAD ciphers, and random number generators. The same documentation identifies AF_ALG as socket family 38, explains that applications create an AF_ALG socket, bind to a cipher, accept an operation socket, send input, and read or receive output. (Kernel Documentation)
That interface is legitimate. Userspace programs may use kernel crypto for reasons such as hardware acceleration, API consistency, or access to kernel-provided algorithms. The security issue is not that AF_ALG exists. The issue is that any userspace-facing kernel API expands the attack surface of the code reachable from low-privileged processes.
AEAD operations are especially easy to underestimate. AEAD data is not a simple input buffer and output buffer. It involves associated authenticated data, ciphertext, plaintext, tags, IVs, integrity checks, scatterlists, and error paths. Kernel documentation describes AEAD decryption input as AAD, ciphertext, and authentication tag. That layout is central to Copy Fail because the authentication tag region becomes the place where page-cache-backed references survive into an output scatterlist. (Kernel Documentation)
The result is a bug that feels surprising only if one thinks of crypto APIs as isolated math. In the kernel, crypto APIs are memory management APIs too. They move data across trust boundaries. They expose algorithm-specific code paths. They process user-controlled lengths, flags, and buffer layouts. Copy Fail is a reminder that “crypto subsystem” does not mean “only cryptographers need to care.”
The root cause, in-place AEAD operation meets page-cache-backed tag pages
The public root-cause analysis points to a 2017 optimization in algif_aead.c that performed AEAD operations in-place. Xint explains that for decryption, the input layout is AAD, ciphertext, and authentication tag. The vulnerable path copied AAD and ciphertext into the receive buffer, but did not copy the authentication tag pages. Instead, it retained scatterlist entries for the tag and chained those entries onto the output scatterlist. (xint.io)
That produced a dangerous structure:
Input path:
[ AAD ][ Ciphertext ][ Authentication tag backed by file page cache ]
Output path after partial copying:
[ Receive buffer containing copied AAD and ciphertext ][ Chained tag pages ]
Critical mistake:
The chained tag pages still refer to file page-cache memory.
Sysdig describes the same root cause: after the 2017 in-place optimization, the kernel set req->src = req->dst and chained tag pages from the source scatterlist into the output scatterlist via sg_chain(). When userspace fed the socket through splice(), those tag pages referenced the page cache of the spliced file. (sysdig.com)
This is why “copy fail” is an accurate name. The bug is not simply that something copied incorrectly. It is that something security-sensitive was not copied when it needed to be separated from its original trust boundary. Copying the tag into fresh output-owned memory would have broken the connection to the target file’s page cache. Chaining the tag pages by reference preserved that connection and allowed later writes to cross into file-backed memory.
NVD’s description of the fix captures the design correction: the Linux kernel resolved the issue by reverting crypto: algif_aead back to out-of-place operation, mostly reverting the 2017 commit except for associated data copying, because source and destination come from different mappings and there was no benefit to operating in-place in this path. (उपयुक्त®)
The trigger, authencesn writes where the destination should not extend
The vulnerable in-place layout is only half of the story. The other half is authencesn. Xint describes authencesn as an AEAD wrapper used by IPsec for Extended Sequence Number support. During processing, it rearranges sequence number bytes and uses destination memory as scratch space. The critical write is four bytes at an offset described as assoclen + cryptlen, beyond the intended AEAD output boundary. (xint.io)
In a safe layout, that scratch write would land in memory owned by the operation. In Copy Fail, the destination scatterlist can extend into chained tag pages that still reference page cache. The scratch write crosses from a crypto output buffer into a file-backed page. Xint’s write-up states that the attacker can control the target file, the offset, and the four-byte value, and that the HMAC operation can fail while the page-cache corruption persists. (xint.io)
The public exploit path targets a setuid-root binary. The idea is not that four bytes magically become root in one write. The attack repeats the primitive at chosen offsets to place enough controlled bytes into the cached view of a trusted executable. When the setuid-root binary is executed, the kernel follows the modified cached view. In the demonstrated path, that yields code execution as UID 0. Sysdig summarizes the public PoC as binding an AF_ALG socket, splicing page-cache pages of /usr/bin/su into the crypto pipeline, and issuing a receive operation whose associated data supplies the four-byte value. (sysdig.com)
Reproducing exploit payloads is unnecessary for defensive engineering and risky in operational environments. The useful point is the primitive: low-privileged local code can transform readable file-backed pages into attacker-influenced executable bytes under a vulnerable kernel. That is enough to drive patch priority, detection strategy, and incident response.
Why setuid binaries make the primitive dangerous
Setuid-root binaries are designed to execute with elevated privileges while being launched by ordinary users. They are not automatically unsafe. They are part of classic Unix privilege design. But they are also attractive targets when an attacker can alter the executable view of the binary without changing disk permissions.
A setuid binary creates a direct privilege transition. If a low-privileged user can influence the bytes executed by such a binary, the impact can jump from user-level code execution to root. Copy Fail’s public path uses that transition. The attacker does not need write permission to the binary on disk. They need the ability to corrupt the page cache backing the binary and then execute it while the corrupted page is active.
This is why setuid inventory matters during emergency triage. It does not replace patching. It helps defenders understand exploit targets, hardened baseline drift, and post-compromise risk. A host with unnecessary setuid binaries exposes more potential landing zones for privilege transitions. That has been true for decades, and Copy Fail makes it newly urgent.
A safe inventory command for defenders is:
sudo find / -xdev -perm -4000 -type f -printf '%m %u %g %p\n' 2>/dev/null | sort
That command does not test exploitation. It lists setuid files on the current filesystem so teams can compare against an approved baseline. On production systems, do not delete setuid binaries blindly. Package managers, authentication tools, and system utilities may require them. Instead, compare with a known-good baseline for the distribution and remove only what is unnecessary and approved by system owners.
Affected systems and the version trap
Copy Fail was described by Xint as affecting Linux distributions shipped since 2017, and Theori’s GitHub repository lists tested environments including Ubuntu 24.04 LTS, Amazon Linux 2023, RHEL 10.1, and SUSE 16. Xint’s technical write-up ties the bug to a 2017 algif_aead in-place optimization and shows a directly tested matrix across several kernel lines. (xint.io)
That does not mean defenders should rely only on upstream version numbers. Enterprise distributions backport security fixes. A kernel that looks old by upstream numbering can be patched by the vendor. A kernel that looks recent can still be vulnerable if it includes the affected code and lacks the fix. Ubuntu stated that the vulnerability affects Ubuntu releases before Resolute 26.04 and that mitigations disabling the affected kernel module were released in kmod while kernel packages implementing the proposed patch would follow. (Ubuntu)
Sysdig listed vulnerable upstream ranges including Linux kernel 4.14 through 7.0 release candidates and fixed versions including 7.0, 6.19.12, and 6.18.22, while also noting vulnerable downstream distribution backports in older LTS lines. That is useful as an upstream reference, but distribution advisories remain the authority for managed fleets. (sysdig.com)
The practical rule is simple: ask the vendor, not just uname. Your triage should capture both the running kernel and the installed fixed package. A host can have the fixed kernel installed but still be running the vulnerable kernel until reboot. That reboot gap is common during emergency patching and is one of the easiest ways to get a false sense of safety.
Safe fleet triage commands
The following script collects evidence without attempting exploitation. It is intended for authorized administrators on systems they own or manage. It checks the running kernel, common package manager views, whether algif_aead appears loaded, whether the machine looks like a container host, and whether a reboot may be pending on common Linux families.
#!/usr/bin/env bash
set -euo pipefail
echo "== Host =="
hostnamectl 2>/dev/null || hostname
echo
echo "== Running kernel =="
uname -a
echo
echo "== algif_aead module state =="
if lsmod 2>/dev/null | awk '{print $1}' | grep -qx 'algif_aead'; then
echo "algif_aead is currently loaded"
else
echo "algif_aead is not shown as loaded by lsmod"
fi
if modinfo algif_aead >/dev/null 2>&1; then
echo "algif_aead module metadata is present"
else
echo "algif_aead module metadata not found or built-in status unknown"
fi
echo
echo "== Installed kernel packages, best effort =="
if command -v rpm >/dev/null 2>&1; then
rpm -q kernel kernel-core 2>/dev/null || true
fi
if command -v dpkg >/dev/null 2>&1; then
dpkg -l 'linux-image*' 2>/dev/null | awk '/^ii/ {print $2, $3}' || true
fi
echo
echo "== Container runtime hints =="
for cmd in docker containerd crictl kubectl; do
if command -v "$cmd" >/dev/null 2>&1; then
echo "$cmd found at $(command -v "$cmd")"
fi
done
echo
echo "== Reboot required hints =="
if [ -f /var/run/reboot-required ]; then
echo "Debian or Ubuntu reboot-required flag is present"
fi
if command -v needs-restarting >/dev/null 2>&1; then
needs-restarting -r || true
fi
This script cannot prove a system is not exploitable. It is a collection helper. Use it to populate an asset table, then compare each host against the vendor advisory for that distribution. The minimum useful report should include hostname, cloud instance ID, cluster name, running kernel, installed kernel package, reboot status, algif_aead exposure, workload type, owner, and remediation deadline.
Patch first, then reduce exposure
The main remediation is to apply the vendor kernel update and reboot into the fixed kernel. Copy Fail sits in kernel code. Updating userland packages alone does not remove the vulnerable execution path if the running kernel remains old. Microsoft’s guidance starts with identifying affected products and versions, applying available patches, and using vendor mitigations when patches are not available. (microsoft.com)
A practical emergency runbook should look like this:
| समय खिड़की | Action | Notes |
|---|---|---|
| 0 to 24 hours | Identify and patch high-risk nodes | Prioritize CI runners, Kubernetes workers, multi-tenant hosts, bastions, developer jump boxes, cloud build agents, and systems running untrusted code |
| 0 to 24 hours | Reboot into the fixed kernel | Confirm the running kernel changed after reboot |
| 0 to 24 hours | Apply interim mitigation where patching is delayed | Disable algif_aead or block AF_ALG access only after checking application compatibility |
| 24 से 72 घंटे | Hunt for suspicious AF_ALG and setuid behavior | Focus on runtime behavior rather than disk hashes alone |
| 24 से 72 घंटे | Rotate secrets on suspicious nodes | Treat root-capable local exploitation as possible host compromise |
| Within one week | Reduce unnecessary setuid and container privilege surface | Remove unneeded setuid binaries, enforce seccomp defaults, eliminate privileged containers where possible |
| चल रहे | Add kernel interface exposure to threat modeling | Track untrusted local code paths, especially CI and shared compute |
For systems where immediate patching is not possible, Xint and Unit 42 both describe disabling the affected algif_aead module as an interim mitigation. The common pattern is to prevent the module from loading and remove it if currently loaded. Test this first if the host uses kernel crypto features through AF_ALG. (xint.io)
printf 'install algif_aead /bin/false\n' | sudo tee /etc/modprobe.d/disable-algif-aead.conf
sudo modprobe -r algif_aead 2>/dev/null || true
sudo update-initramfs -u 2>/dev/null || true
The update-initramfs line applies to Debian-family systems when available. Red Hat-family systems may require different initramfs tooling depending on policy and whether the module is included early in boot. Treat module blacklisting as a temporary control, not a substitute for a fixed kernel.
Blocking AF_ALG in sandboxed workloads
Some workloads do not need access to AF_ALG at all. If untrusted code runs inside containers, a seccomp profile that denies socket(AF_ALG, ...) can reduce exposure while patches roll out. Linux kernel documentation identifies AF_ALG as socket family 38, and Kubernetes documentation shows that seccomp profiles can apply syscall actions and argument-based rules through runtime support. (Kernel Documentation)
A minimal OCI-style seccomp fragment for blocking AF_ALG socket creation looks like this:
{
"defaultAction": "SCMP_ACT_ALLOW",
"syscalls": [
{
"names": ["socket"],
"action": "SCMP_ACT_ERRNO",
"errnoRet": 1,
"args": [
{
"index": 0,
"value": 38,
"op": "SCMP_CMP_EQ"
}
]
}
]
}
This is not a universal drop-in profile. It should be merged into a broader runtime profile, tested with the actual workload, and rolled out through the platform’s approved control plane. Some legitimate applications may use AF_ALG. If they do, blocking family 38 can break them. For many web workloads, build jobs, and test containers, AF_ALG access is unnecessary and should be questioned.
For Kubernetes, at minimum, use the runtime default seccomp profile for ordinary workloads. Kubernetes documentation states that most container runtimes provide default syscall profiles and that pods can request RuntimeDefault through the pod or container security context. It also notes that privileged containers always run unconfined and cannot have a seccomp profile applied. (Kubernetes)
apiVersion: v1
kind: Pod
metadata:
name: workload-with-runtime-default-seccomp
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
containers:
- name: app
image: example/app:stable
securityContext:
allowPrivilegeEscalation: false
privileged: false
runAsNonRoot: true
That manifest does not specifically block Copy Fail. It is a baseline. For this CVE, high-risk clusters should pair patching with targeted seccomp controls where feasible, admission control that rejects privileged workloads by default, and node isolation for untrusted compute.
Container impact, what changes and what does not
Containers share the host kernel. That is the most important sentence in container security. Namespaces and cgroups isolate many resources, but they do not give each container its own independent kernel. A kernel local privilege escalation can become a node problem when untrusted code runs in a container.
Xint states that the Copy Fail primitive crosses container boundaries because the page cache is shared across the host. Ubuntu’s advisory similarly separates non-container deployments from container deployments and warns that when container deployments execute potentially malicious workloads, the vulnerability may facilitate container escape scenarios, while carefully noting the state of published PoC information at the time of the advisory. (xint.io)
Defenders should prioritize container hosts by trust level. A Kubernetes worker running only tightly controlled first-party services is still important, but a node running user-submitted build jobs, plugin execution, notebooks, browser automation, sandboxed AI tools, or third-party CI workloads should be near the top of the list. The attacker’s hardest step is not necessarily Copy Fail. It is getting any code to run locally. Platforms that intentionally run untrusted code provide that starting point.
The risky node patterns are familiar:
| Node pattern | Why Copy Fail priority is high |
|---|---|
| CI runners executing pull requests | Running untrusted code is part of the workflow |
| Shared build farms | Low-privileged build users may share a kernel |
| Multi-tenant Kubernetes clusters | Namespace isolation does not remove kernel exposure |
| Privileged container workloads | Seccomp and namespace protections are often reduced |
| Nodes with hostPath mounts | Host filesystem access can worsen blast radius |
| Notebook or data science platforms | Users may execute arbitrary Python or shell commands |
| Browser automation sandboxes | Renderer or plugin escapes can turn into local footholds |
| Developer jump hosts | SSH access by many users increases local attack paths |
A good mitigation plan for containers should include patching nodes, draining and rebooting nodes cleanly, enforcing RuntimeDefault seccomp where possible, eliminating privileged containers, restricting hostPath, keeping build workloads on isolated node pools, and rotating secrets that were accessible from any suspicious node.
Detection should not depend on file hashes
Copy Fail attacks the page cache, so disk hashes can be clean while runtime behavior is compromised. That does not make detection impossible. It changes what defenders should watch. The detection surface is the syscall sequence, the use of unusual kernel crypto sockets, suspicious setuid execution, and the post-exploitation behavior that follows a successful privilege escalation.
Sysdig published a detection idea around unexpected AF_ALG AEAD crypto socket creation, especially SOCK_SEQPACKET, and noted that legitimate AF_ALG users such as disk encryption tooling can exist. Unit 42 published a hunting query focused on non-root users launching su via unusual parent processes, explicitly warning that false positives are possible but that the pattern may identify Copy Fail exploitation attempts. (sysdig.com)
A simple auditd rule can record AF_ALG socket creation on x86_64 systems:
sudo auditctl -a always,exit -F arch=b64 -S socket -F a0=38 -k af_alg_socket
sudo auditctl -a always,exit -F arch=b32 -S socket -F a0=38 -k af_alg_socket
Then search recent audit logs:
sudo ausearch -k af_alg_socket
This is a starting point, not a polished production detector. It can generate noise if legitimate crypto tooling uses AF_ALG. It also does not prove exploitation because AF_ALG use is not automatically malicious. The goal is to identify unexpected processes using a rare kernel interface in environments where no application should need it.
A bpftrace monitor can give a live view on hosts where bpftrace is approved:
sudo bpftrace -e '
tracepoint:syscalls:sys_enter_socket
/args->family == 38/
{
printf("%s pid=%d uid=%d socket(AF_ALG,type=%d,protocol=%d)\n",
comm, pid, uid, args->type, args->protocol);
}
'
For many production teams, the better long-term approach is to capture this through EDR, eBPF runtime security, or cloud workload protection telemetry rather than ad hoc shell commands. The detection logic should answer: which process created AF_ALG sockets, who launched it, what container or workload did it belong to, did it invoke splice(), did it later spawn su or another setuid binary, and did the effective UID change unexpectedly?
A practical Falco-style detection starting point
A runtime rule should be tuned to the environment. The following Falco-style rule is deliberately conservative. It focuses on unexpected AF_ALG socket creation by excluding common crypto and disk-encryption tooling. Treat it as a starting point for internal testing, not a universal detector.
- list: expected_af_alg_users
items:
- cryptsetup
- systemd-cryptsetup
- veritysetup
- integritysetup
- kcapi-dgst
- kcapi-enc
- kcapi-rng
- rule: Unexpected AF_ALG Socket Creation
desc: Detect possible use of the Linux kernel userspace crypto API by an unexpected process
condition: >
evt.type=socket and
evt.rawres >= 0 and
(evt.arg.domain contains AF_ALG or evt.rawarg.domain=38) and
not proc.name in (expected_af_alg_users)
output: >
Unexpected AF_ALG socket created
user=%user.name uid=%user.uid proc=%proc.name
cmdline=%proc.cmdline parent=%proc.pname container=%container.id
priority: WARNING
tags:
- linux
- privilege_escalation
- cve_2026_31431
A stronger rule can look for adjacency between AF_ALG socket use, splice(), and abnormal execution of setuid binaries. The challenge is state. A single event may not be suspicious. A sequence is suspicious. This is where eBPF-based runtime platforms, EDR process graphs, and SIEM correlation help more than one-line alerts.
A useful correlation model is:
Signal 1:
Unexpected process creates AF_ALG socket.
Signal 2:
Same process or child performs splice activity.
Signal 3:
Same user context launches su, passwd, mount, pkexec, or another setuid binary.
Signal 4:
A process gains UID 0 or spawns a root shell outside normal sudo, sshd, systemd, or login paths.
Response:
Isolate host, preserve telemetry, patch and reboot, rotate exposed credentials.
This model intentionally avoids relying on exploit hashes. Public exploit code can be modified in minutes. Runtime behavior is harder to remove without changing the exploit path.
Hunting for suspicious privilege transitions
Unit 42’s public query focuses on non-root users launching su through unusual parent processes. The idea is strong because public Copy Fail demonstrations often use su as the setuid target, but the detector should not be limited to su. Attackers can adapt to other setuid binaries or use the obtained root context for different actions. (इकाई 42)
For SIEMs that store process events, a generic hunting query should look for low-privileged users causing a setuid binary launch from unexpected parents. In pseudo-SQL:
SELECT
host,
user_name,
parent_process_name,
process_name,
process_command_line,
MIN(event_time) AS first_seen,
MAX(event_time) AS last_seen,
COUNT(*) AS executions
FROM process_events
WHERE os = 'linux'
AND user_id <> 0
AND process_name IN ('su', 'passwd', 'chsh', 'chfn', 'mount', 'umount', 'pkexec')
AND parent_process_name NOT IN ('bash', 'sh', 'zsh', 'ksh', 'sudo', 'sshd', 'login', 'systemd')
GROUP BY host, user_name, parent_process_name, process_name, process_command_line
ORDER BY last_seen DESC;
That query will produce false positives. Automation frameworks, configuration management agents, and unusual administrative wrappers may appear. The purpose is not to convict a process from one row. It is to find hosts where the process tree does not match normal human administration or service behavior.
Pair that with AF_ALG socket telemetry:
SELECT
host,
container_id,
user_name,
process_name,
parent_process_name,
process_command_line,
event_time
FROM syscall_events
WHERE os = 'linux'
AND syscall = 'socket'
AND socket_family = 'AF_ALG'
ORDER BY event_time DESC;
The strongest lead is a host where unexpected AF_ALG use and abnormal setuid execution occur near each other under the same workload, user, container, or process tree.
What incident responders should do after suspected exploitation
A suspected Copy Fail exploitation event should be handled as potential host compromise. The page-cache primitive may be transient, but successful exploitation gives root. Once root exists, the attacker can read secrets, alter logs, install persistence, tamper with workloads, access cloud metadata, and move laterally. The local kernel bug is only the escalation step.
A practical response sequence is:
1. Isolate the host or node from the network where possible.
2. Preserve volatile evidence before reboot if incident response policy allows it.
3. Capture process lists, network connections, loaded modules, audit logs, container metadata, and EDR timelines.
4. Identify secrets accessible to the host, workloads, CI jobs, or containers.
5. Patch the kernel and reboot into the fixed version.
6. Rebuild container nodes rather than trusting long-lived mutable state.
7. Rotate credentials and tokens that may have been accessible after root.
8. Review workload admission, seccomp, privileged container use, and setuid baseline.
9. Hunt laterally for the same signals across similar hosts.
A reboot clears the corrupted page cache, but it is not a complete fix. If the vulnerable kernel comes back after reboot, the host remains exploitable. If the attacker used root to establish persistence, rebooting may not remove it. If cloud or CI secrets were exposed, patching does not invalidate those secrets.
For Kubernetes, suspicious nodes should be cordoned and drained. Workloads should be rescheduled onto patched nodes. Secrets mounted into pods on the suspicious node should be considered exposed according to the organization’s incident response policy. CI runners should be treated even more aggressively because they often hold deployment keys, registry credentials, cloud tokens, and source access.
Why CISA KEV and Microsoft’s wording are not contradictory
Some readers notice a tension in public reporting. Microsoft wrote that active exploitation had been limited and primarily observed in proof-of-concept testing at the time of its report, while CISA added CVE-2026-31431 to the Known Exploited Vulnerabilities catalog. These statements can both be true. (microsoft.com)
CISA KEV is not a claim that every organization is being mass-exploited. It means CISA has enough evidence of exploitation to require action for covered federal civilian agencies under its operational rules. Microsoft’s wording describes what its telemetry team was seeing in early investigation: preliminary testing activity and concern that exploitation could increase as working PoC code and patch lag coexist. (microsoft.com)
For defenders, the right conclusion is not to debate semantics. The vulnerability has a public exploit path, broad distribution relevance, kernel-level impact, container implications, and KEV status. That combination is enough to justify accelerated patching, especially on systems that run untrusted local code.
Common mistakes during Copy Fail response
The first mistake is treating “local” as “low priority.” Local privilege escalation bugs are often the second stage of a real compromise. A web RCE that lands as www-data, a malicious package script running in CI, or a compromised SSH account becomes much more damaging if root is one deterministic step away.
The second mistake is patching but not rebooting. Kernel updates usually install new files. They do not replace the running kernel until the machine boots into them. A report that shows “fixed package installed” but “old vulnerable kernel running” should remain open.
The third mistake is relying on disk hashes. Disk integrity checks are valuable, but Copy Fail’s page-cache behavior means clean disk hashes do not prove that the cached execution view was never corrupted. Xint’s disclosure specifically highlights that the corrupted page is not marked dirty for writeback and that on-disk checksum comparisons can miss the modification. (xint.io)
The fourth mistake is running a public exploit in production to “check.” Do not do that. A reliable exploit is still an exploit. It can crash systems, alter runtime state, create audit issues, or normalize unsafe testing behavior. Use vendor advisories, kernel package checks, controlled lab validation, and runtime telemetry.
The fifth mistake is ignoring CI and build infrastructure. Production web servers often get emergency patch attention first. Build workers and test runners may lag, even though they intentionally execute untrusted or semi-trusted code. For Copy Fail, CI infrastructure may be more exposed than a locked-down server.
The sixth mistake is assuming containers solve the issue. Containers share the kernel. A vulnerable host kernel remains the enforcement layer for the containers running above it. Seccomp, AppArmor, SELinux, namespaces, and admission control help reduce attack surface, but they are not replacements for a patched kernel.
A better internal Copy Fail report
A useful internal report should not stop at “CVE present.” Infrastructure owners need enough detail to take action without reading every public write-up. Security leaders need enough evidence to prioritize emergency work. Incident responders need enough context to decide whether to rotate secrets or rebuild nodes.
A strong report includes:
Host identity:
Hostname, instance ID, cloud account, cluster, node pool, owner.
Kernel state:
Running kernel, installed kernel package, vendor fixed version, reboot status.
Exposure:
Multi-tenant use, CI runner status, container host status, untrusted workload presence.
Mitigations:
Patch applied, reboot complete, algif_aead blocked if applicable, seccomp controls applied.
Detection:
AF_ALG socket events, suspicious splice adjacency, abnormal setuid execution, root transitions.
Response:
Whether the host was isolated, rebuilt, or returned to service.
Secrets:
Tokens, keys, service accounts, registry credentials, and cloud roles exposed to the host.
Evidence:
Command output, package advisory mapping, runtime telemetry, timestamps, owner sign-off.
This is where automation can help without turning the process into a black box. In authorized testing and validation workflows, teams can use Penligent to organize asset discovery, CVE-focused verification, tool output, evidence collection, and retesting into a repeatable report rather than a scattered set of screenshots and terminal history. Penligent’s own Copy Fail write-up, automated penetration testing materials, and vulnerability management guidance all frame the same operational problem: security teams need proof, prioritization, and a remediation trail, not just a CVE name. (पेनलिजेंट.एआई)
That kind of workflow is especially useful after emergency kernel vulnerabilities because the same questions repeat across hundreds or thousands of assets. Which nodes are still running the old kernel? Which workloads had untrusted execution? Which systems were retested after reboot? Which reports can be handed to infrastructure owners without losing the evidence chain?
How to prioritize hosts
Not every host can be patched at the same minute. Prioritization should be driven by exploitability, not just asset criticality. A lightly used internal server with no untrusted shell access may be less urgent than a CI runner that handles external pull requests. A Kubernetes worker with privileged third-party jobs may be more urgent than a static database server with tightly controlled access, even if the database contains more valuable data.
A practical priority order is:
| Priority | Host category | Reason |
|---|---|---|
| आलोचनात्मक | CI runners, build agents, package builders | They execute untrusted or semi-trusted code by design |
| आलोचनात्मक | Kubernetes nodes running untrusted workloads | Shared kernel and container boundary risk |
| आलोचनात्मक | Multi-tenant Linux servers | Low-privileged local users share host kernel |
| उच्च | Internet-facing servers with recent app RCE exposure | LPE can follow initial compromise |
| उच्च | Developer jump hosts and bastions | Many users and credentials concentrate risk |
| उच्च | AI agent sandboxes and code execution platforms | Tools may run arbitrary commands or generated code |
| मध्यम | Single-purpose internal servers with limited shell access | Still patch, but lower exploitation opportunity |
| मध्यम | Single-user workstations | Risk depends on local malware, browser compromise, and user behavior |
| Lower | Ephemeral nodes rebuilt from patched images | Confirm image state and runtime kernel |
The “AI agent sandbox” row matters. Many organizations are adding internal agents that can run shell commands, inspect repositories, execute tests, or operate build environments. If such agents run on vulnerable Linux kernels and can be influenced by untrusted content, a local kernel LPE can turn tool execution into host compromise. This is not unique to Copy Fail, but Copy Fail is a timely example of why AI-assisted automation needs strong sandboxing, short-lived credentials, patched kernels, and runtime monitoring.
Defensive validation without exploit reproduction
Security teams often need to prove remediation. For Copy Fail, that proof should not be a production exploit run. Safer validation has three layers.
First, validate patch state:
uname -r
rpm -q kernel kernel-core 2>/dev/null || true
dpkg -l 'linux-image*' 2>/dev/null | awk '/^ii/ {print $2, $3}' || true
Second, validate exposure reduction:
lsmod | awk '{print $1}' | grep -x algif_aead || echo "algif_aead not loaded"
grep -R "algif_aead" /etc/modprobe.d /usr/lib/modprobe.d 2>/dev/null || true
Third, validate runtime controls in container environments:
kubectl get pods -A -o jsonpath='{range .items[*]}{.metadata.namespace}{" "}{.metadata.name}{" seccomp="}{.spec.securityContext.seccompProfile.type}{" privileged="}{range .spec.containers[*]}{.securityContext.privileged}{" "}{end}{"\n"}{end}'
That Kubernetes command is intentionally rough. Real clusters should use policy engines and admission controllers to enforce and report security context. The command is useful during an incident when a responder needs quick visibility into pods that may be missing seccomp settings or using privileged containers.
A clean remediation evidence package should include the vendor advisory, the installed fixed package version, proof that the running kernel matches the fixed kernel, node reboot time, runtime control status, and retest output. It should not include exploit screenshots unless the test occurred in an isolated lab with explicit authorization.
Why the fix removes in-place complexity
The kernel fix reverts algif_aead to out-of-place operation. NVD’s description says the change mostly reverts commit 72548b093ee3 except for copying associated data and notes that there is no benefit to operating in-place in algif_aead because source and destination come from different mappings. (उपयुक्त®)
That sentence is more important than it looks. Performance optimizations often trade copying for reference sharing. In many code paths, that is the right engineering choice. But when the source and destination come from different mappings and one side may include page-cache-backed file data, reducing copies can increase security coupling. The kernel fix restores separation: source data and destination data no longer share the dangerous scatterlist relationship that allowed page-cache pages to be treated as writable output.
A simplified before-and-after model:
Vulnerable model:
src and dst point into a combined scatterlist.
Tag pages from the source can be chained into destination.
authencesn scratch write can walk into page cache.
Fixed model:
source and destination are separated.
Page-cache-backed source pages stay source-only.
Destination writes land in destination-owned memory.
That design lesson applies beyond Linux crypto. Any system that uses zero-copy transfers, shared memory, scatter-gather I/O, DMA buffers, memory-mapped files, or cross-subsystem references should treat provenance as a security property. The question is not only “can this code write?” It is “what object does this pointer still represent, and whose trust boundary came with it?”
How AI-assisted discovery changes the defender’s clock
Theori and Xint state that the finding was AI-assisted and began with a human researcher’s insight into the Linux crypto subsystem and page-cache-backed data. Their write-up says the operator prompt asked Xint Code to examine userspace-reachable code paths in the Linux crypto/ subsystem with the observation that splice() can deliver page-cache references of read-only files, including setuid binaries, to crypto transmit scatterlists. The scan reportedly identified Copy Fail as the highest severity output after about an hour. (xint.io)
The useful takeaway is not that AI “replaces” vulnerability researchers. The useful takeaway is that a skilled operator plus automated code reasoning can compress exploration time across complex subsystems. That changes the defender’s clock. Bugs that once required long manual audit cycles may surface faster. Public proof-of-concept code may appear sooner. Distribution patch timelines, cloud image updates, and enterprise reboot windows are now part of the exploitability equation.
Security teams should respond by improving their own loop: ingest vulnerability intelligence, map assets, validate exposure, patch, reboot, verify, hunt, and report. The organizations that struggle are usually not missing CVE feeds. They are missing the operational bridge between “we know about the vulnerability” and “we can prove which systems are fixed.”
The disclosure and patch timeline
Xint’s published timeline says the vulnerability was reported to the Linux kernel security team on March 23, 2026, acknowledged on March 24, patches were proposed and reviewed on March 25, patches were committed to the mainline kernel on April 1, the CVE was assigned on April 22, and public disclosure occurred on April 29. (xint.io)
That timeline created a familiar enterprise problem. Upstream fixes, distribution packages, cloud images, appliances, and running hosts do not all update at the same speed. Some communities moved quickly. AlmaLinux, for example, published Copy Fail patch information and listed patched kernel versions for AlmaLinux 8, 9, 10, and Kitten 10 after initially using testing repositories and later production repositories. (AlmaLinux OS)
The operational gap is the dangerous part. A public exploit path plus uneven patch availability gives attackers and defenders the same clock. Defenders should track not only whether a patch exists somewhere, but whether their exact vendor channel has shipped it, whether the package has been installed, whether the host has rebooted, and whether golden images or autoscaling templates have been rebuilt.
Hardening beyond the emergency patch
The emergency patch closes the known bug. Hardening reduces the blast radius of the next bug.
Start with untrusted local code. Build systems, plugin runners, notebook platforms, AI code execution tools, and multi-tenant compute should run on isolated node pools with short-lived credentials. Do not run them on the same hosts that hold long-lived production secrets. If an LPE turns a low-privileged job into root, the node should not be a treasure chest.
Reduce setuid surface. Inventory setuid-root binaries and compare them against distribution baselines. Remove legacy tools that are no longer needed. Prefer capabilities, service-specific privilege separation, or policy-controlled privilege mechanisms where appropriate. Do not make ad hoc changes without package and service owner review.
Apply container defaults deliberately. Use RuntimeDefault seccomp, avoid privileged containers, set allowPrivilegeEscalation: false, run as non-root where possible, restrict hostPath, and enforce policy through admission control. Kubernetes documentation is clear that privileged containers run unconfined for seccomp, which makes them a poor fit for untrusted workloads. (Kubernetes)
Segment CI. External pull request jobs should not share hosts with trusted release signing, deployment credentials, production cloud roles, or internal package publishing tokens. If a build agent must handle untrusted code, assume local code execution is available to the attacker and design the environment so root on that runner does not become root over the business.
Watch rare kernel interfaces. AF_ALG is legitimate, but rare in many application environments. Make rare syscall families visible. Alerting on unexpected use will not catch every kernel exploit, but it gives defenders a chance to see unusual paths before they become common tradecraft.
Red team and bug bounty perspective
For authorized testers, Copy Fail is a reminder that local exploitability is context. A bug bounty program may mark a local kernel LPE as out of scope if the target is a web app. An internal red team may treat the same bug as critical if it turns a container escape into domain-level impact through secrets on the node. The value depends on the chain.
A responsible test plan should avoid production exploit runs unless explicitly approved. Better questions include:
Can an attacker-controlled workload execute local code on this node?
Does the node run a vulnerable kernel according to vendor guidance?
Can the workload access AF_ALG or load algif_aead?
Does the workload run with seccomp unconfined?
Are privileged containers allowed?
What secrets are available to the node or workload?
Would root on this node allow lateral movement, registry access, cloud metadata access, or deployment key theft?
Was the node patched, rebooted, and retested?
This framing produces better reports. It connects the CVE to business impact without dropping exploit payloads into environments that do not need them. It also helps security buyers evaluate tooling: the useful platform is not the one that shouts “critical” the loudest, but the one that connects exploit preconditions, asset context, evidence, and remediation proof.
What to tell executives without losing technical accuracy
The executive version should be short but precise:
Copy Fail is a Linux kernel local privilege escalation vulnerability.
It is not a remote exploit by itself.
It becomes serious when an attacker already has low-privileged code execution.
The public technique can turn a small page-cache write into root on vulnerable systems.
CI runners, Kubernetes nodes, multi-tenant hosts, and developer jump boxes are highest priority.
The fix is to apply vendor kernel updates and reboot.
Disk file hashes alone are not enough to rule out exploitation.
Suspicious hosts may require secret rotation and rebuild, not only patching.
Avoid saying “all Linux is hacked” or “containers are broken.” Those statements are inaccurate and unhelpful. Also avoid saying “it is only local, so it can wait.” That ignores how modern attack chains work. The accurate middle is more useful: Copy Fail is a local kernel LPE with public exploit material, broad distribution relevance, and high value after any initial foothold.
Engineering lessons from Copy Fail
Copy Fail is a vulnerability in code, but the lesson is architectural. The bug formed at the intersection of multiple subsystems: a zero-copy data movement primitive, a userspace-accessible kernel crypto API, AEAD scatterlist behavior, algorithm-specific scratch writes, page cache semantics, and setuid execution.
Several engineering lessons follow.
First, reference preservation is a security decision. When a subsystem chains or shares a buffer by reference, it carries the original object’s trust boundary forward. If the next subsystem does not understand that boundary, a read-only object can become writable in practice.
Second, error paths still matter. In Copy Fail, the crypto operation can fail while the side effect persists. Security review should ask what writes occur before authentication failure, validation failure, or cleanup.
Third, small writes can be enough. Exploitability is not only about write size. It is about attacker control, repeatability, placement, and privilege context. Four bytes in the wrong executable page can matter more than megabytes in the wrong log file.
Fourth, local interfaces deserve remote-level discipline when they are reachable from sandboxed, containerized, or multi-tenant workloads. The boundary between “local” and “remote” is thinner when remote users can cause local code execution through CI, plugins, serverless jobs, notebook kernels, browser automation, or AI agent tool calls.
Fifth, performance optimizations need threat models. The 2017 in-place optimization was attractive because avoiding copies can be valuable. The fix removed that complexity because source and destination came from different mappings. That is exactly the kind of tradeoff security review must catch.
Final remediation checklist
Use this checklist to drive closure:
Asset mapping:
Identify all Linux hosts, cloud VMs, Kubernetes nodes, CI runners, build agents, and developer jump hosts.
Vendor mapping:
Pull the advisory for each distribution and kernel stream.
Patch:
Install the fixed kernel package from the vendor channel.
Reboot:
Confirm the running kernel is the fixed kernel.
Interim control:
Disable algif_aead or block AF_ALG in high-risk untrusted workloads where compatible.
Container hardening:
Enforce RuntimeDefault seccomp, reject privileged containers by default, restrict hostPath, isolate untrusted workloads.
Detection:
Hunt for unexpected AF_ALG socket creation, splice adjacency, abnormal setuid execution, and root transitions.
Incident response:
Isolate suspicious nodes, preserve volatile evidence where possible, rotate exposed secrets, rebuild nodes.
Reporting:
Record host identity, kernel state, exposure, mitigation, reboot proof, detection results, and owner sign-off.
Prevention:
Reduce setuid surface, segment CI, shorten credential lifetime, and monitor rare kernel interfaces.
The strongest Copy Fail response is boring in the best way: patch quickly, reboot, verify, harden, hunt, and document. The interesting kernel details explain why urgency is justified. The operational discipline is what prevents a four-byte primitive from becoming a business incident.
References and further reading
Xint technical write-up on Copy Fail CVE-2026-31431, including root cause, tested distributions, remediation, and disclosure timeline. (xint.io)
Theori GitHub repository for Copy Fail CVE-2026-31431, including public repository metadata and tested distribution notes. (गिटहब)
NVD record for CVE-2026-31431, including CISA KEV metadata and CWE classification. (एनवीडी)
Microsoft Defender research on Copy Fail impact, cloud workload exposure, mitigation guidance, and detection coverage. (microsoft.com)
Ubuntu advisory on Copy Fail, affected Ubuntu releases, non-container and container deployment impact, and mitigation direction. (Ubuntu)
Sysdig technical analysis of Copy Fail root cause, exploitation flow, affected versions, and runtime detection ideas. (sysdig.com)
Unit 42 analysis and managed threat hunting query ideas for Copy Fail CVE-2026-31431. (इकाई 42)
Linux kernel documentation for the userspace crypto API and AF_ALG. (Kernel Documentation)
लिनक्स splice() manual page. (Man7)
Kubernetes documentation on RuntimeDefault seccomp profiles and seccomp behavior for privileged containers. (Kubernetes)
NVD records for Dirty COW CVE-2016-5195 and Dirty Pipe CVE-2022-0847, useful historical comparisons for Linux privilege escalation and page-cache-related risk. (एनवीडी)
Penligent’s Copy Fail CVE-2026-31431 write-up, focused on the page-cache-to-root attack chain and defensive interpretation. (पेनलिजेंट.एआई)
Penligent’s automated penetration testing overview and vulnerability management guide, relevant for teams converting CVE intelligence into validation evidence and remediation workflows. (पेनलिजेंट.एआई)