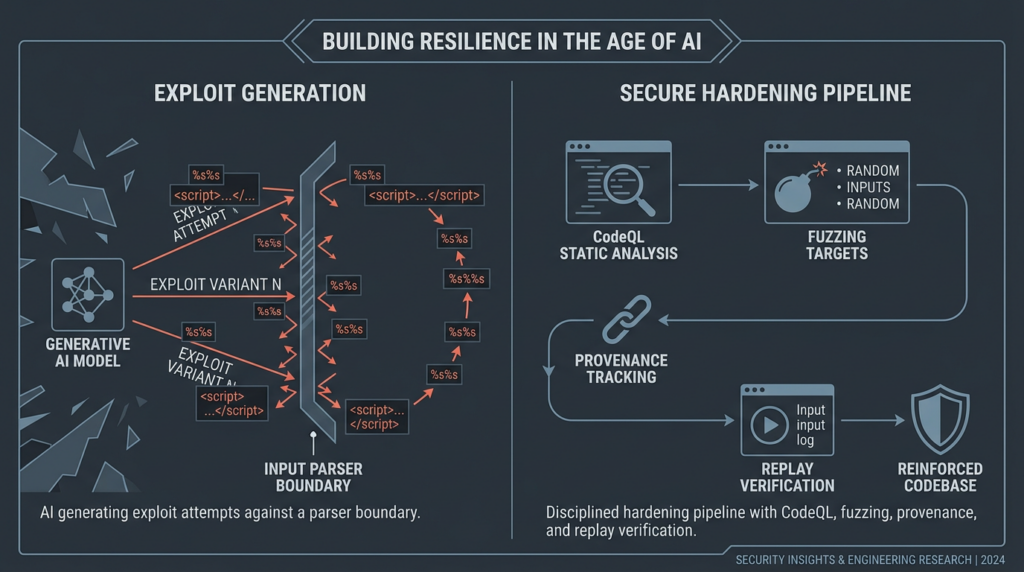
The phrase landed because the evidence changed. In April 2026, Anthropic said its unreleased Claude Mythos Preview had already found thousands of high-severity vulnerabilities, including flaws across every major operating system and web browser, and had capabilities strong enough that the company restricted access through Project Glasswing instead of offering a normal public release. The UK AI Security Institute then published an independent evaluation showing that Mythos was the first model to solve a 32-step simulated corporate network attack from initial reconnaissance to full takeover, completing the full chain in 3 of 10 attempts and averaging 22 of 32 steps overall. (मानवजनित)
That combination matters. A frontier lab making strong claims is one thing. A government-backed evaluator showing that performance continues to rise with larger token budgets is another. AISI said the tested models continued making progress as token budgets increased, and that Mythos still scaled up at the 100 million token limit they used in the cyber range. That is the factual backbone behind the intuition David Breunig expressed in his essay: hardening may increasingly require defenders to spend more tokens finding exploits than attackers spend using them. (AI Security Institute)
The metaphor is useful, but it is not complete. Some parts of cybersecurity are indeed starting to look like proof of work. Other parts still look like classic engineering discipline, release integrity, memory safety, access control, and evidence handling. The right conclusion is not that defenders should simply buy infinite inference. The right conclusion is that secure software delivery now needs an explicit hardening phase, backed by budgets, repeatable pipelines, and verification strong enough to keep candidate findings from becoming noisy theater. (Drew Breunig)
Why This Phrase Landed in April 2026
Breunig’s framing was not built on vague doom. It was built on a very specific shape of benchmark. Anthropic’s own security write-up said Mythos Preview could identify and exploit zero-days in every major operating system and every major web browser during internal testing, and that even non-experts inside Anthropic could ask it to find remote code execution vulnerabilities overnight and wake up to working exploits. Project Glasswing put the same point in institutional language: AI models had reached a level where they could surpass all but the most skilled humans at finding and exploiting software vulnerabilities, which is why Anthropic limited access to selected defensive use cases. (Red Anthropic)
AISI’s evaluation provided the independent context that made the argument harder to dismiss. The institute said Mythos represented a step up over earlier frontier models and tested it not only on isolated CTF tasks but also on “The Last Ones,” a 32-step corporate network attack simulation that AISI estimated would take humans about 20 hours to complete. Mythos was the first model to complete the range end to end. More importantly, the benchmark curve was plotted as a function of total token spend, not just fixed prompt-and-response quality. That is why the discussion shifted from “can it do a demo” to “what happens when the budget keeps scaling.” (AI Security Institute)
Breunig captured the intuition in one sentence: if exploit discovery keeps improving with more inference compute, defenders may need to buy more search than attackers buy exploitation. He called that a proof-of-work style security economy and described it as a low-temperature lottery. The point was not that security had become identical to cryptocurrency mining. The point was that success in some security tasks may increasingly track who can sustain the larger search loop. (Drew Breunig)
That is a serious claim, but it is not a universal one. AISI also said its ranges had important differences from real-world environments. They lacked active defenders, lacked operational penalties for noisy attacker behavior, and were easier than hardened, monitored enterprise systems. The institute explicitly said it could not conclude from the evaluation that Mythos could reliably attack well-defended environments. That caveat matters, because it tells us where the proof-of-work framing is strongest and where it remains premature. (AI Security Institute)
The strongest reading is narrower and still transformative. The parts of security that resemble verifiable search problems are being compressed into budget problems. Vulnerability discovery, exploit variant generation, harness generation, crash triage, chain construction, and replayable validation all benefit from massive iterative search. These were never purely human intuition tasks. They were human intuition plus repetition. AI changes the repetition term first. (Drew Breunig)
What Proof of Work Means in Security
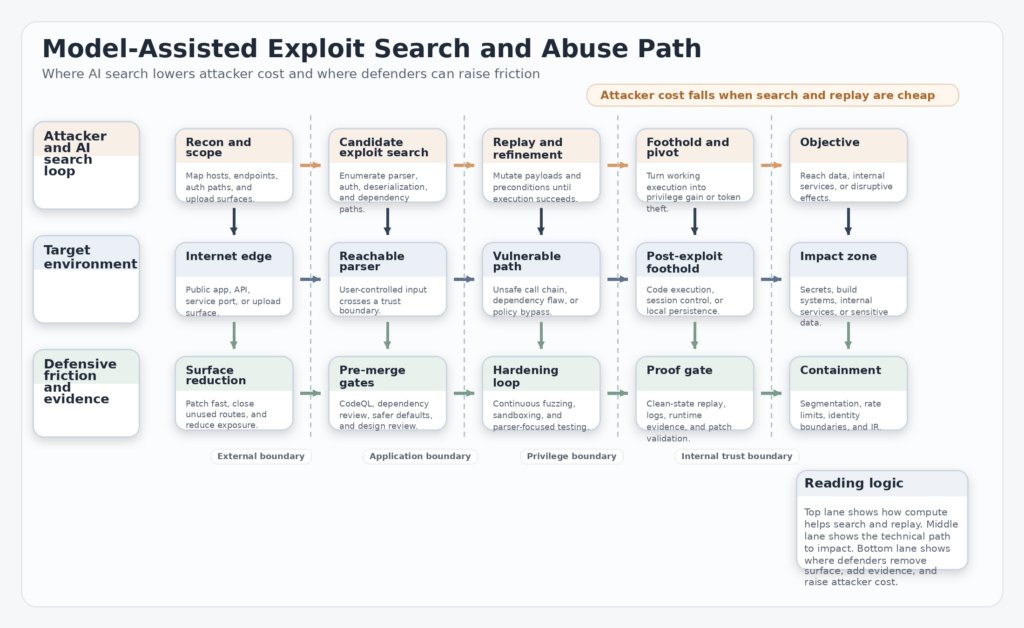
In older software security economics, the expensive thing was expert labor. A specialist reverse engineer, kernel exploit developer, or experienced auditor carried a scarce skill set, and the limiting factor on both offense and defense was the number of people who could reason at that level. AI changes the shape of scarcity. The scarce input is no longer only expertise. It becomes expertise expressed as prompts, workflows, harnesses, tooling, replay environments, and compute budgets that can be repeatedly applied. (Red Anthropic)
That shift matters because exploit work contains many subproblems that are unusually machine-friendly. The target exists already. The system provides feedback. The correctness conditions are concrete. Either the crash reproduces, the privilege boundary falls, or it does not. Either the harness covers new code paths, or it does not. Either the provenance matches expectations, or it does not. Security work contains ambiguity, but many of its inner loops are sharply testable. That is why Breunig emphasized that finding exploits is a verifiable search problem. (Drew Breunig)
The consequence is asymmetry. Attackers do not need universal capability. They need one useful path. Defenders need broad confidence that important paths have been closed or made materially more expensive. When search quality improves with more token spend, the attacker’s minimal success condition and the defender’s maximal coverage burden start to diverge. That is the deepest reason the proof-of-work metaphor feels uncomfortable: it highlights that the defender must often buy breadth while the attacker only buys one hit. (AI Security Institute)
At the same time, the metaphor can be overextended. Security is not only vulnerability discovery. It also includes architecture, defaults, access boundaries, release provenance, monitoring, response, and customer-safe product design. CISA’s Secure by Design materials repeatedly push this point. The burden of safety should not rest only on the customer’s ability to configure defenses perfectly; software manufacturers are supposed to take ownership of customer security outcomes, embrace transparency and accountability, and build leadership structures that prioritize those outcomes. That is not a compute-scaling argument. It is a design responsibility argument. (सीआईएसए)
So the right model is layered. Some security work is turning into proof-of-work style search. Some security work should instead eliminate whole classes of defects before that search race matters. A product team that treats all of security as “run more AI against it later” is designing its own tax. A product team that treats design, review, provenance, and hardening as separate disciplines can spend compute where compute is most valuable rather than where process failed earlier. (एनआईएसटी कंप्यूटर सुरक्षा संसाधन केंद्र)
From Pentest Engagements to Continuous Hardening
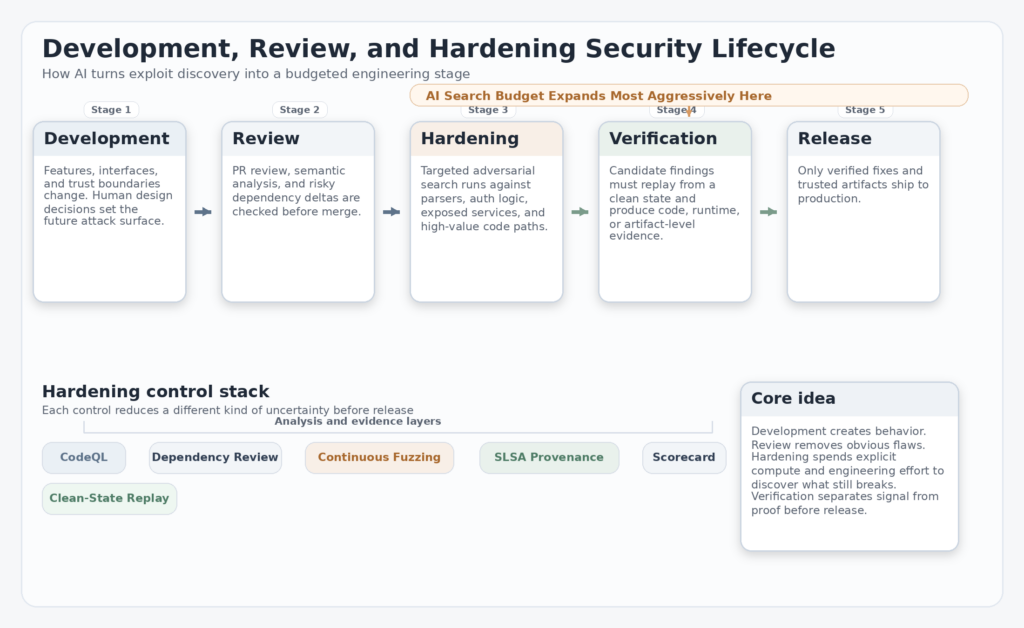
One of Breunig’s most useful observations was organizational rather than philosophical. If the Mythos-style claims hold, software delivery is likely to settle into a three-stage cycle: development, review, and hardening. That is a better model than lumping all security into code review or occasional pentests. Development is where features and behavior change fastest. Review is where maintainability, correctness, and obvious foot-guns get caught. Hardening is where the team spends explicit effort trying to break what survives review. (Drew Breunig)
This distinction matches how secure development standards already think, even if they do not use the same vocabulary. NIST’s Secure Software Development Framework describes a core set of high-level practices that can be integrated into any SDLC and says following them should reduce the number of vulnerabilities in released software, mitigate the impact of unaddressed flaws, and address root causes to prevent recurrence. That is broader than code review, and it fits naturally with a dedicated hardening stage. (एनआईएसटी कंप्यूटर सुरक्षा संसाधन केंद्र)
The pressure to split review from hardening is partly economic. Human attention is the bottleneck in development. Human judgment is also central in review. Hardening is different. Once a system has stabilized enough to be worth stress-testing, a lot of the work can be parallelized through static analysis, dependency gating, fuzzing, range-based testing, provenance verification, and agentic search loops. The budget constraint becomes more visible there than in earlier phases. That is why it makes sense as a separate stage rather than an extension of PR review. (Drew Breunig)
It also changes how security teams should talk to engineering leadership. If hardening is a real stage, then it needs real inputs and outputs. Inputs include a target surface, a token or time budget, a coverage strategy, and a policy for when evidence counts as valid. Outputs include replayable proof, a patch, a release decision, or a documented negative result. Without that structure, AI-driven testing becomes theater: lots of output, little confidence. (SLSA)
This is where “proof of work” becomes operational rather than rhetorical. The question is not whether AI can draft scary findings. The question is whether your delivery pipeline can spend effort in a disciplined way that changes shipped risk. Budgets without evidence become waste. Evidence without repair becomes backlog. Repair without provenance becomes supply-chain drift. Mature hardening is the practice of tying all three together. (पेनलिजेंट)
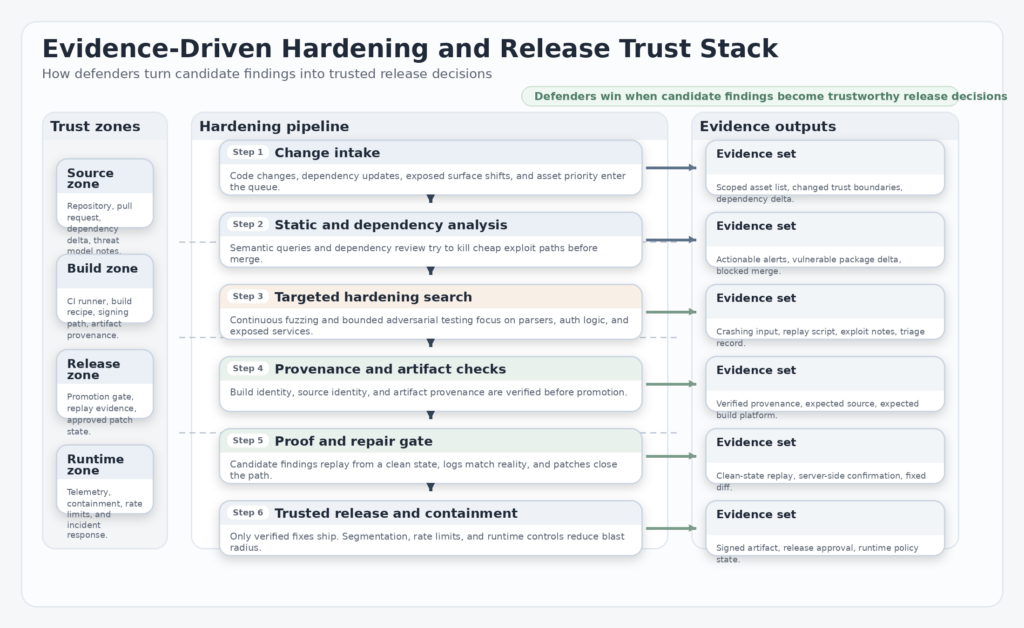
What a Real Hardening Stage Contains
A real hardening stage is not one tool and not one benchmark. It is a stack. Each layer answers a different question, and each layer fails differently. Static analysis asks whether known dangerous patterns or semantically equivalent variants are present. Dependency review asks whether you are about to import risk before it becomes part of production. Fuzzing asks what breaks under adversarial, varied input. Provenance asks whether the artifact you are shipping is really the artifact you think you built. Project trust signals ask whether the dependencies you rely on are maintained with credible security hygiene. (GitHub दस्तावेज़)
The proof-of-work era does not make these layers obsolete. It makes them more urgent. If attackers gain cheaper exploit search, defenders cannot answer by relying on a single annual pentest and a dependency scanner. They need overlapping controls that shorten the path from code change to security evidence. That is the only way to keep search costs from escaping into perpetual reactive spending. (Drew Breunig)
| Hardening layer | Primary question | Typical evidence | Main failure mode |
|---|---|---|---|
| Semantic static analysis | Did we introduce a dangerous pattern or a variant of one | actionable code-level alert, dataflow path, patch | false confidence when custom frameworks are poorly modeled |
| Dependency review | Are we about to import known risky components | pull request diff, advisory exposure, version delta | too late if only run after merge |
| Continuous fuzzing | What breaks under broad adversarial input | crashing input, reproducer, root-cause triage | coverage plateaus and harness gaps |
| Provenance verification | Is this artifact authentic and expected | attestation, source identity, build platform identity | provenance exists but is never verified |
| Project trust signals | Is this dependency maintained with healthy security practices | scorecard checks, branch protection, release hygiene | score becomes proxy for trust instead of a prompt for review |
The table is simple on purpose. The layers are not interchangeable. They answer different questions, and an attacker only needs the one you skipped. The hardening phase works when those answers arrive early enough to change the release, not after the postmortem. (GitHub दस्तावेज़)
Semantic static analysis with CodeQL
GitHub’s documentation describes CodeQL as a code analysis engine used to automate security checks and surface results as code scanning alerts. The important technical idea is not just “scan code.” It is that code can be represented in a queryable form so teams can find vulnerability variants, not only exact string matches. GitHub’s CodeQL documentation explicitly frames it as a way to identify vulnerabilities and errors in a codebase, and CodeQL’s own docs describe scaling knowledge of a single vulnerability into variant hunting across large codebases. (GitHub दस्तावेज़)
That matters in a proof-of-work setting because exploit economics favor repetition. If a model or a human researcher finds one deserialization sink, one auth bypass pattern, or one untrusted dataflow into a dangerous API, the defender should be trying to eradicate the whole family, not the one observed instance. Semantic querying is one of the best existing ways to do that in CI. (CodeQL)
name: codeql
on:
pull_request:
push:
branches: [main]
jobs:
analyze:
runs-on: ubuntu-latest
permissions:
actions: read
contents: read
security-events: write
strategy:
matrix:
language: [javascript, python]
steps:
- uses: actions/checkout@v4
- uses: github/codeql-action/init@v3
with:
languages: ${{ matrix.language }}
- uses: github/codeql-action/autobuild@v3
- uses: github/codeql-action/analyze@v3
The practical limitation is equally important. Static analysis is only as good as the model of the program it can build. GitHub’s docs explicitly note support for custom or niche frameworks, which is another way of saying that default analysis is not omniscient. A team adopting CodeQL as part of hardening should treat it as a semantic multiplier, not as proof that an absence of alerts means an absence of exploitable states. (GitHub दस्तावेज़)
Dependency changes before merge
GitHub’s dependency review documentation is refreshingly blunt: the feature lets you catch insecure dependencies before you introduce them to your environment. That “before” is the whole point. In an older security model, dependency scanning often happened downstream, after merge, when the vulnerable component was already in the build graph and the remediation tax had become a scheduling problem. In a proof-of-work environment, that delay is expensive, because it expands the number of paths attackers may search before you notice you imported them. (GitHub दस्तावेज़)
Dependency review also exposes a subtle truth about modern risk. Many exploit paths are not born in the code you wrote. They are inherited from things you upgraded casually. If hardening becomes a budget problem, one of the highest-return investments is to keep avoidable dependency risk out of the graph altogether. Preventing an unnecessary risky import is usually cheaper than hardening every downstream code path that import activates. (GitHub दस्तावेज़)
name: dependency-review
on:
pull_request:
jobs:
dependency-review:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
steps:
- uses: actions/checkout@v4
- uses: actions/dependency-review-action@v4
with:
fail-on-severity: high
This layer is also where organizational discipline shows up fastest. Teams that bypass dependency review under deadline pressure are borrowing directly against future hardening budgets. The point of the gate is not bureaucracy. The point is to prevent trivial additions to the search space. (GitHub दस्तावेज़)
Continuous fuzzing and AI generated harnesses
Fuzzing is one of the clearest examples of security work that already looked like proof of work before frontier models arrived. OSS-Fuzz exists because scalable, repeated, automated input generation finds classes of bugs that humans do not reliably enumerate by hand. Google’s OSS-Fuzz docs say the service runs fuzzers for open source projects and privately alerts developers to detected bugs, and the project’s repository states that as of May 2025 it had helped identify and fix more than 13,000 vulnerabilities and 50,000 bugs across 1,000 projects. (Google GitHub)
What changed is that AI started helping on the most manual part of the loop: harness generation and iteration. In 2023, Google said LLMs could increase code coverage in OSS-Fuzz projects by generating additional fuzz targets and described a fully automated process from identifying under-fuzzed code to generating, compiling, revising, and evaluating new targets. In 2024, Google reported that AI-powered fuzzing had expanded coverage across 272 C and C++ projects, added more than 370,000 lines of new coverage, and led to 26 new vulnerabilities, including CVE-2024-9143 in OpenSSL. Google also made a point security teams should repeat to themselves: line coverage does not guarantee a function is free of bugs. (Google Online Security Blog)
That last sentence is crucial. A proof-of-work mindset can easily collapse into “run more until coverage looks pretty.” Google’s own experience is the opposite lesson. Better fuzzing is not only more compute. It is better target selection, better project context, better compile-repair loops, better runtime feedback, and better triage. AI improves these loops because it can emulate more of a developer workflow, not because a single model magically substitutes for all security reasoning. (Google Online Security Blog)
hardening_target:
surface: parser_or_decoder_changed_in_pr
budget:
fuzz_runtime_hours: 8
triage_tokens: 5_000_000
gates:
- harness_compiles
- new_coverage_delta > 0
- all_new_crashes_triaged
- project_bug_vs_driver_bug classified
- exploit_relevance documented
outputs:
- reproducer
- root_cause_note
- patch_or_acceptance_decision
The most important operational move is to aim fuzzing at the code where attacker-controlled input crosses trust boundaries: parsers, protocol handlers, media decoders, archive extractors, authentication helpers, and privilege-adjacent logic. That is where the proof-of-work framing is most predictive, because the search loop is rich and the impact can be large. (Google Online Security Blog)
Provenance verification and release integrity
If AI exploit search is one side of the story, supply-chain integrity is the other. SLSA exists because knowing how an artifact was built, where it came from, and whether its provenance matches expectation is part of software security, not an afterthought. The SLSA overview describes the framework as a checklist of standards and controls to prevent tampering, improve integrity, and secure packages and infrastructure. Its levels documentation explains that build provenance records who built the artifact, how it was built, and what inputs were used, and that higher levels add more protection against tampering. The verification docs make the key point even more directly: provenance does nothing unless somebody inspects it. (SLSA)
That is the exact kind of sentence security teams should print and stick to a wall. Provenance exists all over the industry now. Verification is much rarer. Many organizations have moved from “no metadata” to “metadata somewhere,” but not to “enforced expectations before release.” In a world where exploit discovery scales, shipping unverifiable artifacts is reckless because it means you may be hardening one object while releasing another. (SLSA)
| SLSA build level | What you get | What it mainly helps prevent |
|---|---|---|
| Build L1 | provenance exists and describes build platform, process, and top-level inputs | mistakes and missing build visibility |
| Build L2 | hosted build platform and authenticated provenance | tampering after the build |
| Build L3 | hardened build platform with stronger isolation and secret protection | tampering during the build, including harder insider and tenant attacks |
The table also explains why provenance is not just for compliance teams. If your artifact is supposed to come from one canonical repository, one constrained build definition, and one controlled build platform, then verification can stop entire families of supply-chain substitution attacks before they become incident response work. That is an enormous defensive return on a relatively boring operational discipline. (SLSA)
release_policy:
expected_source_repo: github.com/example/app
expected_build_platform: ci-prod-linux
expected_branch: refs/tags/v*
must_have_provenance: true
fail_release_if:
- source_repo_mismatch
- unsigned_or_unverifiable_provenance
- unapproved_external_build_parameter
- build_from_fork
Proof of work does not replace provenance. It makes provenance more important. The more cheaply attackers can search for exploit chains, the less tolerance defenders should have for ambiguity about what exactly they built and shipped. (SLSA)
Project level trust signals with OpenSSF Scorecard
OpenSSF Scorecard is best understood as a decision aid, not a verdict. The project says it helps users evaluate trust, risk, and security posture for their use case by auto-generating a security score for open source projects based on automated checks. The value is not that a number can certify safety. The value is that maintainers and consumers can surface missing branch protection, weak release hygiene, sparse testing, or other patterns that deserve closer review before a dependency becomes business critical. (OpenSSF)
In a proof-of-work environment, these signals help defenders decide where to spend scarce hardening energy. The question is not “is this dependency safe.” The question is “does this dependency deserve deeper review, vendor engagement, local containment, or replacement because the cost of being wrong is too high.” Scorecard helps move that decision earlier. (OpenSSF)
Three CVEs That Explain the New Reality Better Than Theory
Abstract arguments about security economics are easy to wave away. Real vulnerabilities make the point faster. Three cases in particular show why the new environment is not just hype.
Log4Shell shows why cheap exploit paths change everything
NVD describes CVE-2021-44228 as a Log4j issue in which attacker-controlled log messages or parameters could lead to arbitrary code execution loaded from attacker-controlled LDAP and related endpoints when message lookup substitution was enabled. Apache’s own release notes for Log4j 2.15.0 say the vulnerability was addressed there, that JNDI behavior was restricted, and that lookups in log messages were disabled by default. Apache also documented mitigations for teams that could not upgrade immediately, including setting log4j.formatMsgNoLookups=true, using %{nolookups} in PatternLayout, or removing JndiLookup और JndiManager classes from लॉग4जे-कोर. CISA’s guidance likewise described Log4Shell as a critical remote code execution vulnerability affecting Log4j 2.0-beta9 through 2.14.1. (एनवीडी)
Log4Shell matters here because it is exactly the kind of vulnerability class that becomes economically terrifying when exploit search becomes cheaper. The exploitability condition is concrete, the affected surface is distributed widely through dependencies, and the payoff is large. In an AI-mediated environment, this is the sort of problem attackers can search for at scale across codebases, configs, and exposed applications. Defenders therefore need the opposite: dependency visibility, fast version identification, and immediate hardening gates that stop risky patterns from surviving merge or deployment. (एनवीडी)
The main defensive lesson is not “always patch faster,” though that is true. The lesson is that some bug classes are so composable and so machine-searchable that they should be structurally minimized rather than handled as occasional emergency work. Secure by Design is trying to push the industry in exactly that direction. (सीआईएसए)
regreSSHion shows why repeated hardening beats one-time auditing
CVE-2024-6387 is a different story. NVD describes it as a security regression in OpenSSH’s sshd involving unsafe signal handling and a race condition that an unauthenticated remote attacker may be able to trigger by failing authentication within a set time period. OpenSSH’s 9.8 release notes are more concrete: versions 8.5p1 through 9.7p1 on Portable OpenSSH were affected, arbitrary code execution with root privileges may be possible, successful exploitation had been demonstrated on 32-bit Linux with glibc and ASLR, and the issue was serious enough that 9.8 shipped as a release containing fixes for two security problems, one of them critical. (एनवीडी)
This case is not as famous as Log4Shell, but in some ways it is a better fit for the “proof of work now” thesis. The bug was not a naive input sanitization mistake in a toy application. It was a regression in widely deployed infrastructure software. That means defenders cannot treat “already audited once” as a durable state. Every new change, refactor, portability fix, release engineering decision, and downstream patch can reopen old risk in forms that require repeated discovery. That is exactly where continuous hardening pays for itself. (एनवीडी)
OpenSSH’s own 9.8 notes also show an underappreciated defensive pattern. Alongside the security fix, the release introduced PerSourcePenalties, enabled by default, so sshd could penalize client addresses that repeatedly fail authentication, never complete authentication, or crash the server. The notes say the goal is to make it significantly more difficult for attackers to find weak accounts or exploit bugs in sshd itself. That is not a patch for the vulnerability class. It is attack-cost engineering. It is exactly the kind of control defenders should think about more often in a world where search loops accelerate. (OpenSSH)
The practical takeaway is straightforward: when a flaw is regression-prone, the answer is not just “ship the patch.” The answer is “treat the service as a permanent hardening target.” That means repeated semantic review, boundary-focused fuzzing where possible, release cadence discipline, exposure-aware rate limiting, and better default friction for attacker iteration. (OpenSSH)
XZ shows where the proof of work metaphor breaks
CVE-2024-3094 is the counterexample that prevents simplistic thinking. NVD says malicious code was discovered in upstream xz tarballs starting with version 5.6.0 and explains that the build process extracted a prebuilt object from disguised test material and modified specific functions during the liblzma build. Debian’s advisory says the upstream source tarballs were compromised and injected malicious code at build time into liblzma5, and that Debian reverted affected branches back to upstream 5.4.5 code. (एनवीडी)
This incident matters because it was not primarily a “find a bug in source code with more fuzzing” problem. It was a release integrity and provenance problem. If your review process focused on the canonical repository but your build consumed a different artifact, you were looking at the wrong object. More compute would not have saved a team that lacked verification of what exactly entered the build. (एनवीडी)
That is why SLSA belongs in this discussion. The proof-of-work metaphor is strongest when the security question is “can we search for exploit paths faster than attackers search for them.” XZ reminds us that another equally important question is “are we even searching the right artifact.” Provenance, verification, and controlled build platforms are not side quests. They are preconditions for meaningful hardening. (SLSA)
Where the Proof of Work Metaphor Is Right and Where It Fails
The metaphor is right about one big thing: some offensive and defensive tasks now scale with inference budgets in ways that were hard to imagine even a few years ago. Anthropic’s internal write-up, Project Glasswing, AISI’s independent range results, and Google’s AI-assisted fuzzing work all point in the same direction. AI can help discover more vulnerabilities, generate or refine exploitation steps, increase coverage, and compress technical labor into repeatable loops. That is not speculative anymore. (Red Anthropic)
The metaphor fails when people use it to flatten all of cybersecurity into “whoever buys more tokens wins.” That is not what the evidence shows. AISI explicitly said its ranges were easier than hardened environments and that the evaluation did not establish Mythos could reliably defeat well-defended systems. Google explicitly said code coverage is not proof that a function is free of bugs. SLSA explicitly says provenance does nothing if nobody verifies it. Those are not side notes. They are the boundaries of the claim. (AI Security Institute)
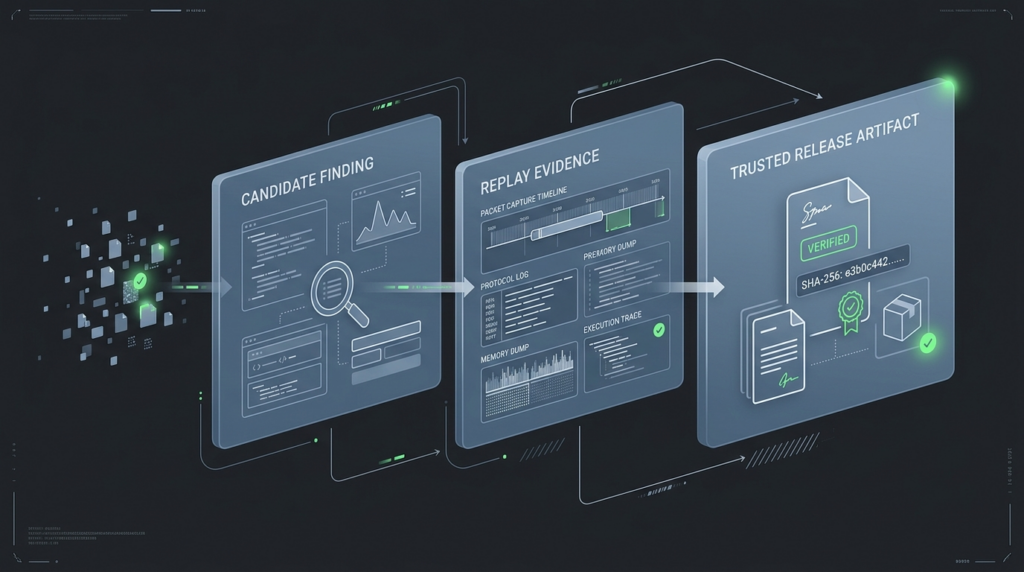
The other way the metaphor fails is organizational. Search can be parallelized. Repair still bottlenecks on judgment, ownership, rollout safety, and product priorities. A company can discover ten times as many candidate issues and still become less secure if it cannot verify, prioritize, and remediate them cleanly. Security maturity is not “how much output did the model produce.” It is “how short is the trustworthy path from candidate signal to verified repair.” One Penligent article about AI pentesting after Mythos puts that point well by arguing that the moat is not the biggest model by itself but the shortest trustworthy path from signal to proof. Another makes the equally important operational point that a candidate finding is not a finding and that replay from clean state matters. (पेनलिजेंट)
That distinction is where a lot of AI security programs will quietly succeed or fail. If your workflow stops at screenshots, weird response codes, or first-pass crashes, then more compute can actually increase confusion. If your workflow requires preserved preconditions, clean-state replay, object-state or log confirmation, and evidence suitable for another human to validate, then more compute can be turned into more trustworthy hardening. (पेनलिजेंट)
This is also where targeted AI pentesting tools become more useful than generic chat interfaces. The goal is not simply to produce more text about risk. The goal is to generate candidate attack paths, execute bounded tests, replay them, collect evidence, and feed fixes back into the release pipeline. Penligent’s own writing on verified AI pentesting is relevant here because it emphasizes the separation between hypothesis generation and confirmation. That is the right separation for any team trying to use AI without drowning in false confidence. (पेनलिजेंट)
The design-level boundary matters too. CISA’s Secure by Design materials and related alerts on eliminating classes such as buffer overflows keep returning to the same message: manufacturers should reduce whole categories of defects and own customer security outcomes rather than leaving those problems to downstream configuration and emergency patching. If a class of vulnerability can be made rarer through memory-safe choices, safer defaults, tighter interfaces, or stronger release practices, that is usually a better strategic move than planning to outspend attackers forever in the hardening stage. (सीआईएसए)
Building an AI Aware Hardening Pipeline
A mature AI-aware hardening pipeline starts with scoping, not tools. The wrong way to budget hardening is to spread effort evenly across the whole codebase. The right way is to rank surfaces by attacker value and defender regret: authentication flows, exposed protocol handlers, media and archive parsers, build and release logic, package ingestion, privilege boundaries, browser-adjacent logic, and infrastructure components with broad downstream blast radius. That ranking determines where expensive search should go first. (मानवजनित)
Then the pipeline needs explicit gates. A practical order is this: run semantic code analysis on changed code, block risky dependency deltas before merge, launch targeted fuzzing where attacker-controlled input changed, verify artifact provenance before release, and require clean-state replay for any candidate exploit claim. The output of each gate should be reviewable by another engineer. If a team cannot explain why a control passed or failed, that control is not yet part of a trustworthy hardening system. (GitHub दस्तावेज़)
| Asset type | Why it deserves hardening first | Recommended stack | Evidence that should exist before release |
|---|---|---|---|
| Authentication and session logic | one bypass can invalidate every downstream control | CodeQL, review, focused adversarial tests, replay checks | reproducer or negative test, no new high alerts |
| Parsers and decoders | broad attacker-controlled input, historically bug-rich | fuzzing, sanitizer builds, crash triage | harness delta, crash triage, patch or risk note |
| Internet-facing network services | direct exploit surface and wormability risk | static analysis, rate limiting, hardened defaults, provenance | fixed versions, config proofs, release attestation |
| Build and release pipeline | compromise here poisons downstream trust | SLSA provenance, signing, verification, protected build infra | verified provenance, source identity, immutable release record |
| High-reuse dependencies | inherited risk multiplied across services | dependency review, Scorecard, vendor advisories | approved version delta, review note, contingency plan |
This is also where AI pentesting platforms can fit without taking over the article. In practice, teams need a bounded system that can turn candidate paths into replayable evidence and then into reports or fix tickets. That is the context in which Penligent’s own material is most relevant: not as a replacement for SSDF, SLSA, or engineering ownership, but as one possible engine for candidate generation, retesting, evidence collection, and reportable proof in a controlled workflow. (पेनलिजेंट)
There is a second budgeting lesson here. The metric that matters is not “how many findings per run.” It is “how much verified risk reduction per unit of engineering friction.” Some hardening work should stop because the marginal evidence is weak. Some should continue because the component is business-critical, attack-rich, and historically fragile. The proof-of-work era rewards teams that can make that distinction deliberately instead of reactively. (AI Security Institute)
What Security Leaders Should Budget for Now
First, budget for repeated hardening of critical surfaces, not only emergency response. AISI’s results imply that cyber capability continues to climb with larger token budgets. That makes one-time audits less reassuring for exposed, high-value components. The right response is to turn hardening into cadence. (AI Security Institute)
Second, budget for evidence quality. AI will make candidate findings cheaper before it makes trustworthy remediation automatic. That means the scarce resource inside many organizations will be verification, not discovery. Teams that plan only for more findings will overload themselves. Teams that plan for replay, triage, and patch ownership will get real defensive leverage. (पेनलिजेंट)
Third, budget for release integrity and dependency governance. XZ demonstrated that some of the worst modern failures are about what got built and shipped, not just what static analysis or fuzzing would have found in a trusted source tree. That means provenance verification, controlled build platforms, and pre-merge dependency gates are no longer optional hygiene. They are frontline controls. (Debian)
Fourth, budget for design-level defect reduction where possible. The cheapest hardening loop is the one you never need because the vulnerable design never shipped. CISA’s Secure by Design push is directionally correct here. Eliminate whole classes where you can. Spend proof-of-work budgets where you must. (सीआईएसए)
The Real Meaning of Cybersecurity Is Proof of Work Now
The phrase is memorable because it captures something real. Frontier AI has moved exploit discovery and vulnerability search closer to a budgeted loop. Anthropic’s official material, Project Glasswing, AISI’s independent evaluation, and Google’s work on AI-assisted fuzzing all support that broad direction. Defenders should take that seriously. (मानवजनित)
But the phrase becomes dangerous when used lazily. Security is not only brute-force search. It is also design, defaults, verification, provenance, and organizational honesty about what counts as proof. Log4Shell shows why cheap exploit paths can become catastrophic when widely distributed through dependencies. regreSSHion shows why continuous hardening beats one-time confidence. XZ shows why provenance and build integrity can matter more than another scan. Put together, those cases point to the same conclusion: the future of defense is not just more AI. It is tighter loops between discovery, verification, remediation, and release integrity. (एनवीडी)
That is the version of the idea worth keeping. Some parts of cybersecurity now look like proof of work. The winning defenders will be the ones who know exactly which parts those are, and who build pipelines disciplined enough to turn compute into verified security instead of just more output. (Drew Breunig)
Further Reading and Reference Links
- Anthropic, Assessing Claude Mythos Preview’s cybersecurity capabilities. (Red Anthropic)
- Anthropic, Project Glasswing: Securing critical software for the AI era. (मानवजनित)
- UK AI Security Institute, Our evaluation of Claude Mythos Preview’s cyber capabilities. (AI Security Institute)
- David Breunig, Cybersecurity Looks Like Proof of Work Now. (Drew Breunig)
- NIST, SP 800-218 Secure Software Development Framework. (एनआईएसटी कंप्यूटर सुरक्षा संसाधन केंद्र)
- CISA, Secure by Design materials and related alerts. (सीआईएसए)
- GitHub Docs, About code scanning with CodeQL. (GitHub दस्तावेज़)
- GitHub Docs, About dependency review. (GitHub दस्तावेज़)
- OSS-Fuzz documentation and repository overview. (Google GitHub)
- Google Security Blog, AI-Powered Fuzzing: Breaking the Bug Hunting Barrier. (Google Online Security Blog)
- Google Security Blog, Leveling Up Fuzzing: Finding more vulnerabilities with AI. (Google Online Security Blog)
- SLSA, What is SLSA, Security levels, और Verifying Artifacts. (SLSA)
- OpenSSF, Scorecard. (OpenSSF)
- Apache Log4j release notes and Log4Shell guidance. (अपाचे लॉगिंग सेवाएँ)
- OpenSSH 9.8 release notes for the
sshdrace condition fix. (OpenSSH) - Debian advisory for the XZ compromise rollback. (Debian)
- Penligent, मायथोस के बाद एआई पेनटेस्टिंग. (पेनलिजेंट)
- Penligent, Agentic Cyberattacks Need Verified AI Pentesting. (पेनलिजेंट)
- पेनलिजेंट होमपेज। (पेनलिजेंट)