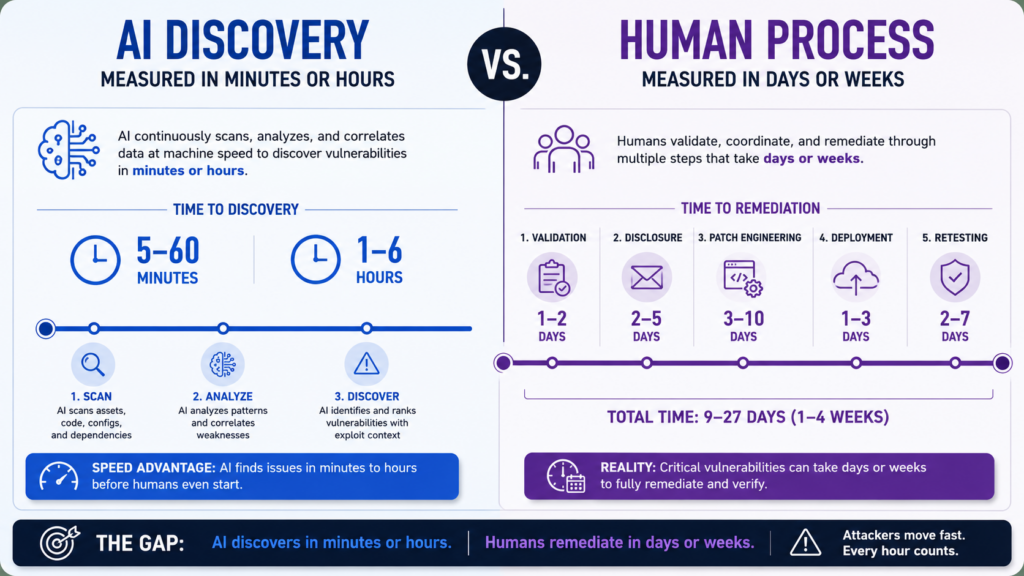
AI vulnerability discovery is crossing an important line. The scarce resource in security is no longer simply the ability to find bugs. It is the ability to prove which findings are real, decide which ones matter, coordinate disclosure, ship safe patches, deploy them across messy environments, and verify that risk is actually gone.
Anthropic’s first public update on Project Glasswing made that shift unusually clear. The company said that roughly 50 partners used Claude Mythos Preview to find more than 10,000 high- or critical-severity vulnerabilities across systemically important software, then stated the larger lesson directly: progress in software security used to be limited by how quickly defenders could find vulnerabilities, but is now limited by how quickly they can verify, disclose, and patch the volume of vulnerabilities found by AI. (मानवजनित)
That is the real story. Not “AI found bugs.” Not “AI solved security.” The more durable change is that AI vulnerability discovery is becoming abundant while remediation capacity remains scarce.
For security engineers, bug bounty hunters, red teamers, and technical buyers evaluating AI security tools, that difference matters. A tool that produces more findings can still make an organization less effective if it floods engineers with ambiguous reports. A system that turns raw findings into reproducible evidence, exploitability context, owner-ready tickets, safe remediation plans, and retestable proof is much more valuable. The next phase of application security, vulnerability management, and AI pentesting will be judged less by the number of candidate issues generated and more by the quality of verified remediation.
What Project Glasswing actually shows
Project Glasswing was launched as a controlled effort to give selected defenders access to Claude Mythos Preview, an unreleased model Anthropic describes as having unusually strong cyber capabilities. Anthropic’s launch page framed the project as an attempt to help organizations secure critical software before similarly capable AI models can be turned against it. (मानवजनित)
The one-month update is more concrete. Anthropic reported that most partners found hundreds of high- or critical-severity vulnerabilities in their own software, with several partners saying their bug-finding rate increased by more than 10x. Cloudflare, one named example, found 2,000 bugs across critical-path systems, 400 of which were high or critical severity, with a false-positive rate Cloudflare’s team considered better than human testers. (मानवजनित)
Anthropic also said it used Mythos Preview to scan more than 1,000 open-source projects. The model estimated 23,019 total vulnerabilities, including 6,202 high- or critical-severity issues. Of 1,752 high- or critical-rated issues assessed by independent security research firms or Anthropic, 90.6% were confirmed as valid true positives, and 62.4% were confirmed as high or critical severity. (मानवजनित)
Those numbers are striking, but they should be read carefully. Mythos Preview is not publicly released. Many findings remain inside responsible disclosure windows. Anthropic is publishing aggregate statistics and selected examples rather than a fully open dataset of every finding, exploit, patch, and verification artifact. That is reasonable from a safety perspective, but it means serious readers should treat Project Glasswing as early evidence of a capability shift, not as a complete public benchmark.
The most important part of the update is not the headline count. It is the drop-off between generated findings, triaged findings, disclosed vulnerabilities, patched vulnerabilities, and public advisories. Anthropic’s disclosure dashboard said that, as of May 22, 2026, it had disclosed 1,596 vulnerabilities across 281 open-source projects; 97 were known to have been patched, and 88 had been assigned a CVE or GHSA. The dashboard explicitly notes that independent human triage and review are the rate-limiting step. (Red Anthropic)
That is the shape of the new bottleneck.
AI can create a high volume of plausible vulnerability candidates. Humans, maintainers, product teams, security engineers, and infrastructure owners still have to convert those candidates into eliminated risk.
Why AI vulnerability discovery is scaling now
Traditional vulnerability research is constrained by expertise and attention. A good researcher has to understand the target, read unfamiliar code, reason about trust boundaries, identify suspicious data flows, craft inputs, build harnesses, triage crashes, test exploitability, avoid false positives, and communicate impact. That work is hard because it combines software engineering, systems knowledge, security intuition, and patience.
AI changes the economics by turning many pieces of that workflow into repeatable sub-tasks.
A capable model can read a codebase faster than a human can skim it. It can summarize architecture, identify entry points, map parsers, search for dangerous sinks, propose fuzz targets, generate harnesses, compare patches, explain suspicious control flow, write reproduction steps, and draft reports. The model does not need to be perfect for the economics to change. If it can cheaply produce 100 candidates and a smaller triage layer can validate the 10 that matter, the discovery process becomes much more scalable than manual review alone.
Anthropic’s update describes not only a model, but a workflow around the model. The tools it plans to make available to qualifying customers include skills for repeated security work, a harness that helps Claude map codebases and spin up scanning subagents, and a threat model builder that maps a codebase to identify attack targets and prioritize model work. (मानवजनित)
That architecture matters. AI vulnerability discovery is not just a chat prompt. It is a pipeline:
| Workflow layer | What it does | Why it changes discovery speed |
|---|---|---|
| Codebase mapping | Builds a working model of packages, services, interfaces, parsers, trust boundaries, and sensitive operations | Reduces the human time required to understand a new target |
| Threat modeling | Identifies likely attacker goals and high-value paths through the system | Focuses scanning on meaningful areas rather than every line equally |
| Candidate generation | Finds suspicious patterns, missing checks, unsafe state transitions, parser inconsistencies, and risky dependencies | Produces more leads than manual review can produce in the same time |
| Harness generation | Builds tests, fuzz inputs, or replay conditions around suspicious logic | Converts static suspicion into executable evidence |
| Triage | Deduplicates, reproduces, and reassesses severity | Separates useful findings from noise |
| रिपोर्टिंग | Packages affected versions, reproduction steps, impact, and remediation guidance | Makes findings easier for maintainers and product teams to act on |
A scanner can already match known CVEs. A SAST tool can already flag risky patterns. A fuzzer can already find crashes. The shift is that AI can sit across these tools, preserve context, generate glue code, explain why a path matters, and keep iterating when the first attempt fails.
That is why AI vulnerability discovery is not just “faster scanning.” It is a higher-level orchestration layer around many existing security techniques.
External evaluations point in the same direction
Anthropic’s own claims are not the only relevant signal. Several external evaluations suggest that frontier models are improving quickly on offensive and defensive security tasks.
The UK AI Security Institute evaluated Claude Mythos Preview and found continued improvement on capture-the-flag tasks and significant improvement on multi-step cyber-attack simulations. AISI said that, in controlled evaluations where the model was explicitly directed and given network access, Mythos Preview could execute multi-stage attacks on vulnerable networks and discover and exploit vulnerabilities autonomously, tasks that would take human professionals days of work. (AI Security Institute)
AISI also reported that Mythos Preview succeeded 73% of the time on expert-level CTF tasks and was the first model to solve its 32-step corporate network attack simulation, “The Last Ones,” from start to finish, succeeding in 3 of 10 attempts. (AI Security Institute)
XBOW’s evaluation is useful because it is not pure hype. Its testers found Mythos Preview extremely powerful for source code audits, strong in native-code vulnerability discovery and reverse engineering, and a significant step up on XBOW’s web exploit benchmark. But they also noted limitations: it was less powerful at validating exploits than at finding issues, and its judgment was mixed, sometimes too literal or conservative and sometimes overstating practical relevance. (Xbow)
That distinction is critical. It supports the central thesis: AI vulnerability discovery is scaling faster than verified exploitability judgment.
ExploitGym, a benchmark from Berkeley RDI, reached a similar conclusion from another angle. It tested whether AI agents could turn vulnerability reports and crashing inputs into working exploits. Claude Mythos Preview successfully exploited 157 of 898 instances, while GPT-5.5 exploited 120 within the task limits. The authors concluded that autonomous exploitation is no longer hypothetical, but their results also show that success depends on domain, mitigations, tooling, time budget, and agent setup. (Berkeley RDI)
ExploitBench, focused on V8 bugs, evaluated multiple frontier models and described Mythos Preview as a private research-preview model rather than a generally available system. Its results again suggest that the most capable models can climb several steps up the exploit-development ladder under controlled benchmark conditions. (arXiv)
The safest interpretation is not that any AI model can now hack anything. The better interpretation is that the floor is rising. Tasks that used to require a small number of elite researchers are becoming easier to partially automate. Discovery, crash analysis, exploit reasoning, and report drafting are no longer bounded only by human hours.
The new constraint is what happens after the model says, “I found something.”
Finding a vulnerability is not the same as removing risk
A vulnerability finding is not a security outcome. It is an input to a security process.
To remove risk, a team has to answer a series of questions:
| Question | यह क्यों मायने रखती है |
|---|---|
| Is the finding real? | AI can produce plausible but wrong explanations. A report without reproduction is still a claim. |
| Is it reachable? | A vulnerable function in dead code or disabled configuration may not be exploitable in a specific environment. |
| Is it exploitable? | A bug may crash a process without giving the attacker control, or require conditions that do not exist in production. |
| What is the impact? | Confidentiality, integrity, availability, authentication, tenant isolation, and business workflow impact differ. |
| Who owns the fix? | Many findings cross teams, vendors, packages, containers, and third-party products. |
| Is there a patch? | A vendor patch, source patch, compensating control, or configuration change may each require different handling. |
| Can the patch be deployed safely? | Patches can break compatibility, performance, integrations, or business-critical behavior. |
| Was remediation verified? | Closing a ticket without retesting only proves that a process ended, not that risk disappeared. |
This is why AI vulnerability discovery can become dangerous if it is treated as the finish line. The model’s output may be true, but still unusable. It may be important, but not urgent. It may be urgent, but blocked by an owner gap. It may be patched upstream, but still present in downstream appliances, containers, statically linked binaries, or embedded firmware.
Anthropic’s open-source workflow illustrates the human burden. The company says it or external security firms reproduce issues, reassess severity, check whether fixes already exist, and write detailed reports to maintainers. It also says maintainers are already facing a flood of low-quality AI-generated bug reports, and some have asked Anthropic to slow disclosures because they need more time to design patches. (मानवजनित)
That is not a small operational detail. It is the main lesson.
AI can accelerate the front of the pipeline. The back of the pipeline still depends on trust, engineering capacity, release management, disclosure norms, deployment operations, and retesting.
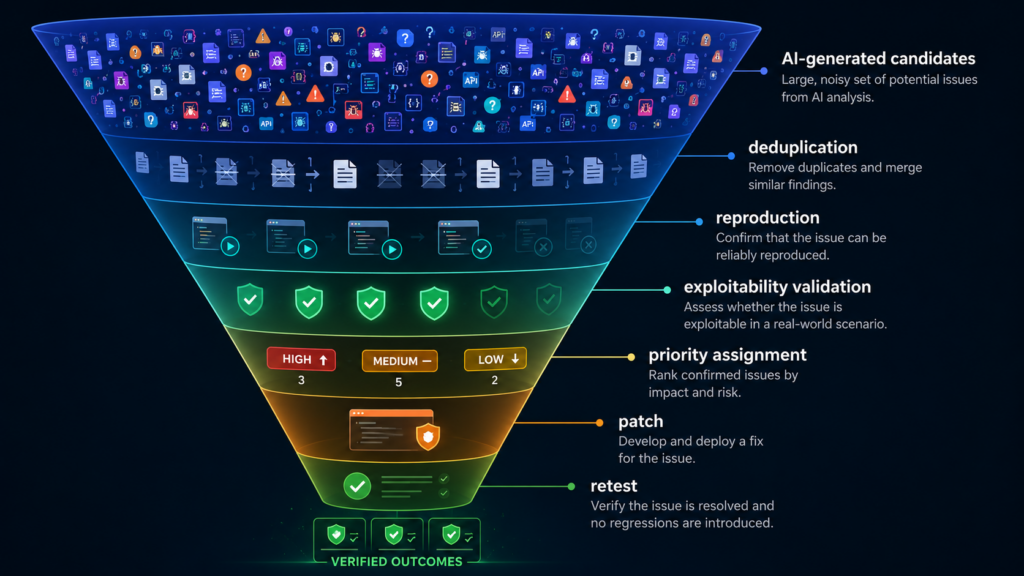
The remediation funnel
The remediation funnel is the best way to reason about this new phase of security.
A candidate finding enters the top. A fixed, deployed, and retested system exits the bottom. Every stage requires evidence. Every stage can drop work. Every stage creates delay.
| मंच | Input | Required evidence | Main bottleneck | Common failure |
|---|---|---|---|---|
| Candidate intake | AI-generated finding, scanner alert, researcher report | Target, affected component, suspected weakness, initial reasoning | Volume | Duplicates, vague claims, hallucinated code paths |
| Reproduction | Test case, request, input file, harness, crash, log | Deterministic replay or clear conditions for failure | Environment setup | “Works on my machine” reports with no stable reproduction |
| Reachability | Asset inventory, routing, build flags, configuration, auth state | Proof that the vulnerable path exists in a real deployment | Missing context | Vulnerable library exists but is not loaded or exposed |
| Exploitability | Controlled test, safe proof, crash analysis, state transition, privilege boundary | Evidence of security impact without unnecessary harm | Expert judgment | Treating every crash as critical |
| Impact scoping | Affected versions, assets, tenants, data, identities, workflows | Business and technical blast radius | Ownership gaps | No one knows which products embed the component |
| Priority assignment | Severity, exposure, KEV status, exploit maturity, asset criticality | Risk rationale that can be defended | Competing queues | CVSS-only prioritization |
| Fix design | Patch, configuration change, control, compensating mitigation | Proposed change and safety analysis | Engineering time | Quick fix creates regression |
| Deployment | Release plan, rollout schedule, rollback plan | Version evidence across environments | परिचालन जोखिम | Patch available but not deployed |
| Retest | Same reproduction path, regression suite, monitoring signal | Proof that the original condition no longer holds | Time pressure | Ticket closed after code merge, not after verification |
AI can help at every stage, but it cannot remove the need for the stages. A mature AI-assisted security program should not ask, “How many vulnerabilities can the model find?” It should ask, “How many verified risks can we safely close per week?”
That is a different metric.
False positives matter, but priority matters more
False positives are a real problem. They waste time, damage trust, and burn out maintainers. But they are not the only problem, and they may not even be the largest one.
Even if every AI-generated finding were real, a security team would still have to choose what to fix first.
A critical vulnerability in a non-exposed test system may be less urgent than a high-severity bug in a public authentication gateway. A medium-severity authorization flaw in a multi-tenant API may deserve immediate attention because it crosses tenant boundaries. A low-complexity bug with known exploitation in the wild may outrank a theoretical memory corruption issue in a service reachable only from a segmented admin network.
That is why risk-based prioritization matters.
CISA’s Known Exploited Vulnerabilities catalog exists because defenders need a way to focus on vulnerabilities known to be used by attackers. Binding Operational Directive 22-01 established a CISA-managed catalog of known exploited vulnerabilities that carry significant risk to the U.S. federal enterprise, and federal civilian executive branch agencies are required to remediate listed vulnerabilities by prescribed deadlines. (सीआईएसए)
NIST SP 800-40 Rev. 4 defines enterprise patch management as identifying, prioritizing, acquiring, installing, and verifying patches, updates, and upgrades throughout an organization. It also frames patching as preventive maintenance and recommends an enterprise strategy to simplify and operationalize patching while reducing risk. (एनआईएसटी कंप्यूटर सुरक्षा संसाधन केंद्र)
Those definitions become more important in the AI era, not less. AI vulnerability discovery increases signal volume. Good vulnerability management decides which signals become urgent action.
A practical prioritization model should include at least these factors:
| Signal | यह क्यों मायने रखती है |
|---|---|
| Confirmed exploitability | A verified exploit path is stronger evidence than a static pattern match |
| Internet exposure | Publicly reachable systems compress attacker time-to-access |
| Identity or tenant boundary impact | Authentication, authorization, and isolation flaws often carry higher business risk |
| Known exploitation | KEV or credible threat intelligence should raise priority |
| Asset criticality | A bug in a payment, identity, update, backup, or control-plane system has larger blast radius |
| Patch availability | A ready patch changes the remediation path; no patch may require segmentation or monitoring |
| Exploit maturity | Public exploit code, active scanning, or weaponization changes urgency |
| Compensating controls | WAF, segmentation, MFA, logging, and EDR can reduce but not erase risk |
| Remediation cost | A low-risk patch that can be shipped today may beat a perfect fix delayed for months |
Good triage is not just severity scoring. It is operational decision-making under constraint.
CVE-2026-5194, when AI finds a trust failure in cryptographic validation
CVE-2026-5194 is one of the most useful examples from the Project Glasswing discussion because it shows a class of bug that is easy to underestimate from the outside.
NVD describes CVE-2026-5194 as a wolfSSL issue where missing hash or digest size checks and Object Identifier checks allow smaller-than-allowed digests to be accepted when verifying ECDSA certificates, or smaller-than-appropriate digests for the relevant key type. NVD lists the weakness as CWE-295, Improper Certificate Validation, and the CNA score from wolfSSL is critical. (एनवीडी)
Anthropic said Mythos Preview constructed an exploit for a wolfSSL vulnerability that would allow an attacker to forge certificates, potentially making a fake bank or email provider website appear legitimate to an end user. Anthropic identified the now-patched vulnerability as CVE-2026-5194. (मानवजनित)
wolfSSL later wrote that Anthropic pointed Mythos at wolfSSL, the findings generated 8 CVEs, and wolfSSL 5.9.1 was released. wolfSSL also said that its own codebase is around 2 million lines of code, before counting other open-source projects and language wrappers, and that the issues Mythos found had slipped past other testing layers. (wolfSSL)
The technical lesson is not “AI can find crypto bugs, therefore everything is solved.” The lesson is that AI vulnerability discovery can surface subtle trust-decision flaws that do not look like ordinary web bugs.
Many vulnerabilities produce obvious telemetry. SQL injection may leave unusual query errors. XSS may show payload reflection. A memory corruption bug may crash. A brute-force attack may generate authentication failures. A certificate validation flaw can be quieter. The dangerous event is the software accepting trust evidence it should reject.
For defenders, the hard questions are operational:
| Question | Why it is hard |
|---|---|
| Which products embed wolfSSL? | The library may appear in firmware, appliances, IoT devices, embedded products, static builds, and vendor packages |
| Which versions are affected? | Direct package inventory may miss statically linked or vendor-modified builds |
| Which systems use affected certificate verification paths? | The vulnerable code may matter only under certain algorithm combinations and configurations |
| Can every device be patched to 5.9.1 or later? | Embedded and appliance ecosystems often have slower update paths |
| How do we verify remediation? | A version string alone may not prove that the actual linked library and runtime path are fixed |
This is exactly where AI vulnerability discovery collides with asset reality. Finding the weakness may be the fast part. Proving where it exists and eliminating it everywhere may be the slow part.
A defensive inventory workflow might start with package metadata, then move to binary inspection and vendor confirmation:
# Generate an SBOM for a container image or filesystem
syft dir:/opt/app -o cyclonedx-json > sbom.json
# Search the SBOM for wolfSSL references
jq -r '.components[]? | select((.name // "" | ascii_downcase) | contains("wolfssl")) | [.name, .version, .purl] | @tsv' sbom.json
# Look for embedded version strings in binaries, useful but not definitive
find /opt/app -type f -perm -111 -maxdepth 4 -print0 \
| xargs -0 strings 2>/dev/null \
| grep -Ei 'wolfssl|wolfcrypt|wolfssl version' \
| sort -u
# On Linux systems with package metadata
dpkg -l 2>/dev/null | grep -Ei 'wolfssl|wolfcrypt' || true
rpm -qa 2>/dev/null | grep -Ei 'wolfssl|wolfcrypt' || true
Those commands do not prove exploitability. They help answer the first question: “Where might the component exist?” A high-confidence remediation record should include the discovered component, version evidence, affected path, patch or vendor advisory, deployment status, and a retest note. Without that, a security team may know about the CVE but still not know whether its own risk changed.
Log4Shell showed the gap between knowing and fixing
Log4Shell remains one of the clearest examples of why discovery is not remediation.
NVD describes CVE-2021-44228 as an Apache Log4j2 issue where JNDI features used in configuration, log messages, and parameters did not protect against attacker-controlled LDAP and other JNDI endpoints. An attacker who could control log messages or parameters could execute arbitrary code loaded from LDAP servers when message lookup substitution was enabled. (एनवीडी)
The hard part for many organizations was not understanding that Log4Shell was bad. The hard part was finding every place Log4j existed.
It might be a direct Maven dependency. It might be a transitive dependency. It might be shaded into a JAR. It might be inside a vendor appliance. It might be in an old internal service no one owns. It might be present but not loaded. It might be present in a container image that is no longer built but still running. It might be patched in source and still unpatched in production.
That is the remediation bottleneck in its purest form. The vulnerability is public. The risk is obvious. The patch path exists. The enterprise still has to answer: where is it, who owns it, can it be patched without breaking production, and how do we prove the fix landed?
A safe defensive search for Log4j exposure can combine build metadata and filesystem inspection:
# Maven dependency tree
mvn -q dependency:tree | grep -E 'log4j-core|log4j-api' || true
# Gradle dependency view
./gradlew dependencies --configuration runtimeClasspath | grep -E 'log4j-core|log4j-api' || true
# Search packaged Java artifacts for log4j-core
find . -type f \( -name "*.jar" -o -name "*.war" -o -name "*.ear" \) -print0 \
| while IFS= read -r -d '' file; do
if unzip -l "$file" 2>/dev/null | grep -q 'org/apache/logging/log4j/core'; then
echo "Possible embedded log4j-core: $file"
fi
done
These commands do not replace vendor advisories, runtime validation, or patch testing. They illustrate the kind of evidence that must exist before a team can responsibly close a vulnerability ticket.
AI can help generate these checks. It can help interpret dependency trees. It can suggest where shaded JARs may hide. It can help write owner-ready tickets. But it cannot skip inventory.
CitrixBleed showed why slow remediation becomes active compromise
CVE-2023-4966, widely known as CitrixBleed, is another useful case because it shows how known vulnerabilities in edge infrastructure become ransomware access paths when remediation lags.
CISA’s advisory on LockBit 3.0 ransomware affiliates stated that CVE-2023-4966 is a vulnerability in Citrix NetScaler ADC and NetScaler Gateway appliances, with exploitation activity identified as early as August 2023. CISA also warned that LockBit affiliates were exploiting the flaw, labeled CitrixBleed, in ransomware activity. (सीआईएसए)
This example is not about AI discovery. It is about why the AI era makes old remediation problems more urgent.
Edge devices, VPNs, identity gateways, ADCs, and remote access appliances often sit at the boundary between the internet and internal networks. They may have complex patch processes, HA configurations, maintenance windows, and session-handling side effects. They are also high-value targets. Once exploitation starts, defenders do not merely need to install a patch. They may need to rotate sessions, inspect logs, hunt for persistence, review identity activity, and assume that compromise may have occurred before the patch.
AI vulnerability discovery and exploit development pressure this class of system. If models reduce the time required to understand and weaponize edge-device flaws, then patch windows that were already too slow become even more dangerous.
The answer is not panic. The answer is operational discipline:
| Edge-system control | यह क्यों मायने रखती है |
|---|---|
| Internet exposure inventory | You cannot patch or isolate what you cannot find |
| Vendor advisory monitoring | Edge appliances often require vendor-specific remediation steps |
| KEV-driven priority | Known exploitation should override routine backlog order |
| Session and credential rotation guidance | Some vulnerabilities expose tokens or session material that patching alone may not invalidate |
| Maintenance-window exceptions | High-risk edge flaws should not wait for ordinary monthly patch cycles |
| Post-patch validation | Version checks, config checks, and log review should confirm the control plane is actually safe |
AI makes discovery faster. It should also make defensive response faster. If only the first half accelerates, attackers benefit.
Open source is where the pressure appears first
Open-source maintainers are already experiencing the downside of cheap vulnerability report generation.
The OpenSSF Vulnerability Disclosures Working Group has an issue specifically about AI-generated low-quality vulnerability reports. It describes projects receiving high volumes of low-quality reports that appear to be generated by AI with minimal or no human review, creating a “DDoS-like situation” for maintainers. The issue also cites curl’s 2025 experience: only about 5% of bug bounty submissions were genuine vulnerabilities, while around 20% appeared to be AI-generated slop. (गिटहब)
This is the clearest example of the cost asymmetry:
| Actor | Cost to generate | Cost imposed |
|---|---|---|
| Low-effort submitter | Seconds or minutes of model time | Maintainer triage, response, reputation risk, private disclosure handling |
| Serious researcher | Hours or days of validation | Maintainer review, but with useful evidence |
| Maintainer | No choice but to inspect credible-looking reports | Lost engineering time, burnout, delayed fixes |
A bad AI-generated report is not harmless. It consumes the same scarce resource as a real report: trusted maintainer attention.
This is why AI-assisted vulnerability research needs evidence standards. A report should not be treated as credible simply because it contains technical language, stack traces, pseudocode, or a confident severity label. It should include enough evidence for a maintainer or security team to reproduce the issue and understand impact.
A minimal high-confidence vulnerability report should include:
| Evidence field | What good looks like |
|---|---|
| प्रभावित घटक | Exact project, package, version, commit, configuration, or build target |
| Entry condition | The request, file, API call, parser input, privilege level, or state required |
| Reproduction steps | Deterministic steps that work in a clean environment |
| Expected versus actual behavior | Why the behavior violates a security boundary |
| प्रभाव | What confidentiality, integrity, availability, authentication, authorization, or isolation property is affected |
| Scope limitations | Conditions where the issue does not apply |
| Suggested fix direction | Not necessarily a full patch, but enough to guide maintainers |
| Retest method | How to confirm the fix works |
The industry should normalize a simple rule: AI can help find, but humans or validated automation must prove before disclosure.
A practical evidence bundle for AI-generated findings
A strong AI vulnerability discovery workflow should create a structured evidence bundle. The goal is not bureaucracy. The goal is to make every important finding reproducible, reviewable, and retestable.
A simple JSON structure can help teams avoid vague reports:
{
"finding_id": "FIND-2026-0017",
"status": "verified",
"title": "Improper certificate validation in embedded TLS library",
"source": {
"type": "ai_assisted_review",
"model_or_tool": "internal_agent",
"human_reviewer": "security-engineer@example.com"
},
"affected_assets": [
{
"asset": "edge-gateway-prod-03",
"component": "wolfSSL",
"observed_version": "5.8.2",
"evidence": "SBOM and binary string inspection"
}
],
"reproduction": {
"environment": "staging clone, build 2026.05.18",
"steps_file": "repro/README.md",
"artifacts": [
"logs/validation-failure.log",
"screenshots/certificate-path.png"
]
},
"impact": {
"security_boundary": "TLS certificate trust",
"impact_summary": "The verifier may accept a certificate that should fail validation under specific algorithm conditions.",
"data_or_systems_at_risk": [
"device-to-control-plane TLS channel"
]
},
"priority": {
"severity": "critical",
"exposure": "internal control plane",
"known_exploitation": false,
"patch_available": true,
"recommended_due_date": "2026-05-31"
},
"remediation": {
"fix": "Upgrade wolfSSL to 5.9.1 or vendor-provided fixed build",
"owner": "platform-security",
"ticket": "SEC-18421"
},
"retest": {
"method": "Repeat certificate validation test and confirm fixed library loaded at runtime",
"status": "pending"
}
}
This structure forces the right questions. It separates model output from human-reviewed status. It distinguishes observed version from affected version. It captures environment, artifacts, impact, owner, fix, and retest.
For larger teams, the evidence bundle can be generated automatically as the AI system works. Every command, request, response, log, screenshot, and failed hypothesis should be preserved. A final report should be the compressed form of the investigation, not a detached narrative invented after the fact.
A simple risk scoring script for triage
A scoring model does not replace expert judgment. It prevents every finding from being argued from scratch.
The following Python example shows a defensible way to turn common triage inputs into a priority score. It is intentionally simple. In production, teams should tune weights to their environment, compliance requirements, and threat model.
from dataclasses import dataclass
@dataclass
class Finding:
verified: bool
internet_exposed: bool
affects_identity_or_tenant_boundary: bool
known_exploited: bool
public_exploit_available: bool
critical_asset: bool
patch_available: bool
easy_rollback: bool
compensating_controls: bool
def priority_score(f: Finding) -> int:
score = 0
# Evidence quality
score += 25 if f.verified else -20
# Exposure and blast radius
score += 20 if f.internet_exposed else 0
score += 20 if f.affects_identity_or_tenant_boundary else 0
score += 15 if f.critical_asset else 0
# Threat activity
score += 30 if f.known_exploited else 0
score += 15 if f.public_exploit_available else 0
# Remediation feasibility
score += 10 if f.patch_available else 0
score += 5 if f.easy_rollback else 0
# Risk reduction already present
score -= 10 if f.compensating_controls else 0
return max(score, 0)
def priority_label(score: int) -> str:
if score >= 80:
return "P0: emergency remediation"
if score >= 60:
return "P1: fix in the next patch window or sooner"
if score >= 40:
return "P2: schedule and track"
return "P3: monitor, harden, or backlog with rationale"
example = Finding(
verified=True,
internet_exposed=True,
affects_identity_or_tenant_boundary=True,
known_exploited=False,
public_exploit_available=True,
critical_asset=True,
patch_available=True,
easy_rollback=False,
compensating_controls=False
)
score = priority_score(example)
print(score, priority_label(score))
The useful part is not the exact math. The useful part is the discipline. A team can explain why a finding is P0, P1, P2, or P3. It can later audit whether its model overweights public exploit code, underweights identity boundaries, or ignores asset criticality. It can also prevent AI-generated severity from becoming the final decision.
The best triage systems combine model analysis, deterministic tool output, threat intelligence, asset inventory, and human approval.
What an AI-assisted triage pipeline should look like
A mature AI-assisted vulnerability workflow should behave more like a disciplined security team than a noisy scanner.
The pipeline should include at least ten stages.
First, candidate intake. Every model finding, scanner result, external report, crash, or suspicious code path enters a normalized queue. The system records where the finding came from and whether any human has reviewed it.
Second, deduplication. AI is very good at producing multiple descriptions of the same underlying issue. Findings should be clustered by component, code path, sink, CVE, asset, and reproduction condition.
Third, scope control. For pentesting and red-team workflows, the system must respect explicit authorization boundaries. Offensive automation without scope discipline is not maturity; it is risk transfer.
Fourth, evidence replay. A finding should be replayed in a controlled environment when possible. For web applications, that may mean replaying authenticated requests. For code review, that may mean running a harness. For dependency issues, that may mean confirming the vulnerable version is actually loaded.
Fifth, tool corroboration. The AI system should not be the only witness. Static analysis, dynamic tests, dependency scans, SBOM tools, logs, runtime checks, and manual inspection should support important claims.
Sixth, exploitability assessment. The system should separate “bug exists,” “security boundary is crossed,” and “attacker can achieve meaningful impact.” These are different statements.
Seventh, priority scoring. Findings should be ranked using exposure, exploit maturity, KEV status, asset criticality, patch availability, identity impact, and compensating controls.
Eighth, remediation packaging. A developer or maintainer should receive a concise, actionable ticket: affected component, reproduction, impact, suggested fix direction, tests, and rollback considerations.
Ninth, retest. The same evidence path used to prove the issue should be used to prove the fix. Retesting should be explicit, not implied by a merged pull request.
Tenth, reporting. The final record should preserve artifacts, decisions, and residual risk. This matters for audits, customer reports, compliance, and future incident response.
AI can help at every step. It can summarize evidence, generate tests, explain logs, propose fixes, and draft reports. But the pipeline must be designed so that every important security claim can be inspected.
Black-box AI pentesting will be judged by proof, not guesses
White-box AI code review and black-box AI pentesting share a problem: both can produce too many findings. But black-box pentesting has a special advantage. It can prove impact against real behavior.
A black-box test does not need full source access to show that an authorization boundary fails, an API leaks another user’s data, a workflow can be abused, an SSRF reaches an internal service, or a misconfigured object store exposes sensitive files. It can interact with the target the way an attacker would, under authorized scope, and capture the request, response, state transition, and business impact.
That makes black-box AI pentesting especially relevant in the new bottleneck. If AI vulnerability discovery produces too many possible issues, a black-box agentic workflow can help answer the question that matters: what can be proven in this environment?
A real AI pentest workflow should not stop at “the scanner found X.” It should maintain target context, preserve authentication state, map endpoints, identify roles, test object-level authorization, adapt commands based on responses, collect evidence, and stop when it has either proven impact safely or shown that the hypothesis does not hold.
Penligent describes its product as an AI-powered penetration testing tool with agentic workflows that users can control, including scope controls and human-in-the-loop operation. Its related technical page argues that a real AI pentest tool is defined by whether it can turn raw signal into attack paths, exploit validation, and defensible evidence rather than merely summarizing scanner output. (पेनलिजेंट.एआई)
That is the right category of problem. The market does not need more tools that produce alerts with confident wording. It needs workflows that connect discovery, validation, prioritization, reporting, and retesting.
Scanner, copilot, and agentic pentest workflow are not the same thing
Security teams should be careful with labels. Many products now use AI language, but they solve different problems.
| क्षमता | Traditional vulnerability scanner | LLM security copilot | Agentic AI pentest workflow |
|---|---|---|---|
| Primary input | Targets, versions, templates, signatures | User questions, code snippets, logs, tool output | Authorized scope, credentials, objectives, tools, target state |
| Strength | Known issue detection at scale | Explanation, summarization, code assistance | Adaptive testing, context preservation, evidence gathering |
| Weakness | Limited context and exploitability proof | Can hallucinate and depends heavily on user input | Requires strong controls, auditability, and safe execution boundaries |
| Best use | Asset coverage, known CVE checks, compliance sweeps | Analyst acceleration and developer assistance | Validating attack paths and producing reproducible security evidence |
| Output | Alerts and severity scores | Natural-language guidance | Evidence-backed findings, reproduction paths, reports, retest results |
| Main risk | Alert fatigue | Overconfidence in unverified answers | Unsafe autonomy or poorly bounded actions |
These tools should complement each other. A scanner can find known CVEs. A copilot can explain a stack trace or draft a patch. An agentic pentest system can test whether an issue matters in a specific environment. A mature program should use each tool where it is strongest.
The mistake is expecting any one layer to solve the whole vulnerability lifecycle.
How defenders should adapt
Security teams do not need to wait for Mythos-class models to be publicly available before adapting. The remediation bottleneck already exists.
The practical response is to build a workflow that assumes finding volume will increase.
Start with asset inventory. AI cannot prioritize risk accurately if the organization does not know what it owns, what is internet-exposed, what is business-critical, and who owns each service. Asset inventory should include applications, APIs, containers, cloud services, edge devices, third-party products, embedded libraries, and identity systems.
Then improve evidence standards. Any high-severity finding should include reproducible proof, affected versions, environment details, impact, owner, and retest method. A finding without evidence should not enter the urgent queue.
Next, separate queues. A useful triage process should distinguish confirmed vulnerabilities, high-confidence unverified findings, low-confidence AI-generated reports, known exploited vulnerabilities, and public already-disclosed issues. Treating every report as urgent burns out teams. Treating every AI-assisted report as spam misses real issues.
Use threat-informed prioritization. KEV status, public exploitation, internet exposure, identity impact, business criticality, and exploit maturity should influence priority more than raw severity alone.
Shorten patch cycles for critical paths. Edge devices, authentication systems, remote access gateways, update systems, and control planes should have emergency patch procedures that do not depend on ordinary monthly cycles.
Automate retesting. Every serious finding should have a retest plan. The best retest is often the same controlled reproduction used to verify the issue, converted into a regression check.
Measure closure quality, not just closure count. A closed ticket should answer: what changed, where was it deployed, what evidence proves it worked, and what residual risk remains?
Common mistakes in the AI vulnerability discovery era
The first mistake is treating finding count as value. A system that produces 10,000 findings may be impressive, but a customer cares about the number of real risks closed. More findings can make a program worse if triage capacity does not grow with it.
The second mistake is letting the model assign final severity. AI can suggest severity, but final priority should reflect exploitability, exposure, business context, and threat activity. Model confidence is not a risk rating.
The third mistake is relying only on CVSS. CVSS is useful for standardizing technical severity, but it does not know your asset inventory, compensating controls, customer data flows, maintenance windows, or attacker interest.
The fourth mistake is skipping reachability. A vulnerable dependency is not always reachable. A reachable vulnerable path is not always exploitable. An exploitable path is not always high impact. Each step requires proof.
The fifth mistake is sending unverified AI reports to maintainers. That shifts cost from the reporter to the maintainer and damages trust. Open-source projects are already dealing with a flood of low-quality reports. AI-assisted researchers should raise the evidence bar, not lower it.
The sixth mistake is ignoring deployment. A patch merged into source is not the same as a patch running in production. A vendor advisory is not the same as a fixed appliance. A container rebuilt in CI is not the same as a container replaced in every cluster.
The seventh mistake is failing to retest. Without retesting, a team has only changed code or configuration. It has not proven that risk is gone.
What good looks like
A mature AI-assisted security team should be able to produce a finding record that reads like this:
A model or tool identified a possible authorization bypass in a billing API. The finding was deduplicated against two similar scanner alerts. An agent replayed the workflow with two test accounts in staging and confirmed that account A could access account B’s invoice PDF by changing an object identifier. Logs, request IDs, response hashes, and screenshots were captured. The issue affects the production route /api/v2/invoices/{id}/download, but only for tenants using legacy invoice storage. The vulnerable code path is internet-exposed, crosses a tenant boundary, and affects customer financial documents. There is no public CVE because this is a first-party application flaw. The owner is the billing platform team. The recommended fix is an authorization check against tenant ownership before file retrieval. A regression test was generated. The patch was deployed to staging, then production. The same replay now returns 403, and logs confirm enforcement. The final report includes artifacts, timeline, and residual risk.
That is a security outcome. The AI did not “solve” the issue by finding it. The team solved it by converting discovery into verified remediation.
The strategic shift for security tools
The next generation of security tools will compete on conversion quality.
Can the tool convert a vague candidate into a reproducible issue?
Can it convert a scanner alert into an exploitability decision?
Can it convert a CVE headline into an environment-specific priority?
Can it convert a proof into a developer-ready fix?
Can it convert a merged patch into a retested closure?
Can it convert a one-time assessment into a continuous feedback loop?
This is where AI can be genuinely useful. Not as a magic hacker. Not as a replacement for security engineers. As an orchestration and reasoning layer that reduces the manual glue work between tools, evidence, teams, and decisions.
AI vulnerability discovery is valuable because it increases the supply of leads. AI-assisted validation is more valuable because it decides which leads deserve action. AI-assisted remediation is more valuable still because it helps shrink the window between discovery and deployed fix.
That window is where attackers live.
अक्सर पूछे जाने वाले प्रश्न
What does AI vulnerability discovery mean in practice?
- It means using AI models to assist with tasks such as code review, threat modeling, fuzz harness generation, dependency analysis, crash triage, exploitability reasoning, and report drafting.
- It does not mean every AI-generated finding is correct.
- The practical value depends on whether the workflow can reproduce issues, collect evidence, reassess severity, and support remediation.
- The strongest systems combine AI reasoning with deterministic tools, logs, tests, asset inventory, and human approval.
Does AI make traditional vulnerability scanners obsolete?
- No. Traditional scanners remain useful for known CVEs, exposed services, misconfigurations, compliance checks, and broad asset coverage.
- AI can make scanners more useful by interpreting output, correlating alerts, generating validation steps, and prioritizing findings in context.
- Scanners are weak at business logic, stateful workflows, and exploitability proof.
- AI workflows are weak when they lack scope controls, reliable evidence, or deterministic replay.
- The best architecture combines scanners, SAST, DAST, fuzzing, SBOMs, threat intelligence, and AI-assisted triage.
Why is remediation harder than discovery?
- Discovery can produce a candidate issue quickly.
- Remediation requires reproduction, reachability analysis, exploitability judgment, severity reassessment, owner assignment, patch design, regression testing, deployment, and retesting.
- Many organizations lack accurate asset inventory, especially for embedded libraries, third-party products, containers, and edge devices.
- Patches can break production systems, so engineering teams must balance urgency with reliability.
- A vulnerability is not truly closed until the fix is deployed and verified.
How should teams prioritize AI-generated findings?
- Start with evidence quality. Verified findings should outrank unverified model claims.
- Raise priority for internet-exposed systems, identity boundaries, tenant isolation, critical assets, public exploit code, and known exploitation.
- Use CISA KEV and credible threat intelligence as strong signals, but do not ignore business context.
- Do not rely on CVSS alone.
- Keep a separate queue for low-confidence AI-generated reports so they do not overwhelm urgent remediation work.
What evidence should a high-confidence vulnerability report include?
- Affected component, version, configuration, build, or asset.
- Reproduction steps that work in a clean or controlled environment.
- Request, response, input file, harness, crash, log, or screenshot artifacts.
- Clear explanation of the security boundary that is violated.
- Scope limitations and conditions required for exploitation.
- Suggested remediation direction and a retest method.
- Human reviewer or validation status when AI was used to generate the finding.
How does AI vulnerability discovery affect bug bounty and open-source disclosure?
- It lowers the cost of generating reports, which can help serious researchers work faster.
- It also increases low-quality submissions that look technical but lack proof.
- Open-source maintainers are especially exposed because they must spend scarce time triaging private security reports.
- Responsible AI-assisted reporting should include reproduction, impact, affected versions, and fix guidance before contacting maintainers.
- Programs may need stricter evidence requirements, rate limits, and triage automation.
What is the safest way to use AI in penetration testing?
- Use AI only within explicit authorization and documented scope.
- Preserve full evidence: commands, requests, responses, logs, screenshots, timestamps, and tool outputs.
- Require human approval for intrusive actions, exploitation steps, or anything that may affect availability or data integrity.
- Prefer safe proof of impact over destructive proof.
- Convert every verified issue into a retestable remediation record.
- Keep failed hypotheses, because they help reviewers understand what was tested and what was not.
How should defenders prepare for Mythos-class models?
- Assume vulnerability discovery and exploit reasoning will continue to get cheaper.
- Reduce internet-exposed attack surface, especially edge devices, identity systems, and control planes.
- Build faster emergency patch procedures for critical paths.
- Use SBOMs, asset inventory, and runtime validation to locate affected components quickly.
- Invest in triage capacity, not just scanning capacity.
- Treat verified remediation rate as a core security metric.
The scarce resource is verified remediation
AI vulnerability discovery is becoming abundant. That is good news if defenders build the systems needed to absorb it. It is bad news if organizations keep treating security as a queue of alerts that someone else will eventually clean up.
The next security advantage will not come from producing the longest vulnerability list. It will come from proving which findings are real, deciding which ones matter, fixing them safely, and verifying that the original attack path is gone.