Project Glasswing turned a model launch into a defensive warning
Anthropic did not present Project Glasswing as a routine product release. It introduced the initiative as a joint effort with Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks, and said the project exists because of capabilities it has observed in Claude Mythos Preview, an unreleased frontier model that Anthropic believes could reshape cybersecurity. Anthropic also said the model has already found thousands of high-severity vulnerabilities, including some in every major operating system and web browser, and framed Glasswing as an urgent attempt to direct those capabilities toward defense before similar capabilities spread more widely. That framing matters because it is not merely a claim about model quality. It is a claim that the operating assumptions behind software defense are changing. (アンソロピック)
Anthropic paired that announcement with a restricted access model rather than a public rollout. On the Glasswing page, the company says it does not plan to make Claude Mythos Preview generally available and that Project Glasswing participants will use it for tasks such as local vulnerability detection, black box testing of binaries, securing endpoints, and penetration testing of systems. Anthropic also committed $100 million in model usage credits for the initiative and extended access beyond the named launch partners to more than 40 additional organizations that build or maintain critical software infrastructure. Those details tell readers something important about how Anthropic itself is interpreting the risk profile of the system it built. (アンソロピック)
The most useful reaction is not breathless fascination with a frontier model. It is to ask what Glasswing implies for real security programs. If a major model lab now believes a cyber-capable model should be restricted, pointed at critical software, and wrapped in coordinated defensive work, defenders should stop treating secure design reviews, static analysis, and occasional pentest engagements as a complete answer. Those things remain valuable. They are not enough on their own when software, infrastructure, dependency graphs, and attacker capability all keep moving. Anthropic’s own messaging is effectively an argument for faster verification cycles, even if the company does not use that exact phrase. (アンソロピック)
That is the right lens for the rest of this discussion. Glasswing is best understood as a signal that AI defense is now a systems problem, not a single-control problem. Design quality still matters. Logging still matters. Patch management still matters. But when a capable system can compress the path from source review or binary analysis to plausible exploit logic, the gap between “we think we fixed it” and “we proved the attack path is dead” becomes much more dangerous. Continuous penetration testing is the discipline that lives in that gap. (cisa.gov)
What Anthropic actually disclosed about Claude Mythos Preview
Anthropic’s technical write-up is unusually detailed in some places and sharply limited in others. The strongest public evidence it offers is centered on a source-visible, agentic workflow. Anthropic says that for the bugs it discusses publicly, it launches an isolated container that runs the project under test and its source code, then invokes Claude Code with Mythos Preview and asks it to find a security vulnerability. In a typical run, the model reads code, forms hypotheses, executes the project, confirms or rejects those hypotheses, adds debug logic or uses debuggers when needed, and outputs either a no-bug judgment or a report with a proof-of-concept exploit and reproduction steps. Anthropic also says it parallelizes work by assigning agents to different files and ranks files by bug likelihood to focus effort. That is not vague marketing language. It is a concrete testing scaffold. (red.anthropic.com)
Anthropic then makes several strong claims about what that scaffold produced. The company says Mythos Preview is capable of identifying and exploiting zero-day vulnerabilities in every major operating system and every major web browser when directed to do so. It says many of the vulnerabilities it found were ten or twenty years old and cites a now-patched 27-year-old bug in OpenBSD. It also says non-experts at Anthropic with no formal security training have asked Mythos Preview to find remote code execution vulnerabilities overnight and received complete, working exploits by morning, while in other cases internal scaffolds allowed the model to turn vulnerabilities into exploits without human intervention after the initial prompt. Read literally, those are extraordinary claims. Read prudently, they are still a major warning. (red.anthropic.com)
The limits are just as important. Anthropic says fewer than 1 percent of the potential vulnerabilities it has discovered so far have been fully patched by maintainers, which is why it can only discuss a small fraction of them publicly. That means the public record is inherently incomplete. The company may be right about the broader pattern, but outside readers do not yet have broad public artifacts for most of the results. That should shape how technical readers interpret Glasswing. It is fair to take Anthropic seriously. It is not fair to pretend that every strong headline around Mythos is already independently reproduced and settled in public. (red.anthropic.com)
The public record is also more nuanced than many headlines implied. Anthropic says Mythos is “extremely capable” at reverse engineering stripped binaries into plausible source code. It then describes a workflow where it provides the reconstructed source and the original binary to the model and asks it to find vulnerabilities in the closed-source project while validating against the original binary where appropriate. That is a major capability claim, and it matters for firmware, browsers, operating systems, and other high-value compiled targets. But it is not the same thing as publicly demonstrating pure binary-only black-box research without any recovered source-like structure. Reconstructed source is still a reasoning substrate, and in vulnerability research the question of what the analyst or model can see is often a large part of the difficulty. (red.anthropic.com)
Anthropic’s own write-up also shows that its public examples are not confined to memory corruption. The company says it has found many web application logic vulnerabilities, including complete authentication bypasses, login bypasses that let unauthenticated users log in without passwords or two-factor codes, and denial-of-service issues that could remotely delete data or crash services. But it declines to discuss specifics because those vulnerabilities are not yet patched. That detail matters because it shows Anthropic is not claiming only sanitizer-friendly low-level bugs. At the same time, because the public examples are still mostly centered on source-visible systems work, defenders should resist flattening “Anthropic showed serious progress” into “the boundary between research mode and live black-box web pentesting has disappeared.” (red.anthropic.com)
The right reading, then, is neither dismissive nor credulous. Anthropic has clearly published stronger public evidence for AI-assisted vulnerability research than most labs have been willing to release. It has also been selective in what it could disclose, precisely because disclosure lags patching. That combination creates a practical asymmetry for defenders. You do not need to believe every maximal interpretation of Mythos to conclude that verification windows are shrinking, that attack-path validation is likely getting cheaper for capable actors, and that security teams should organize around retesting faster than they did before. (red.anthropic.com)
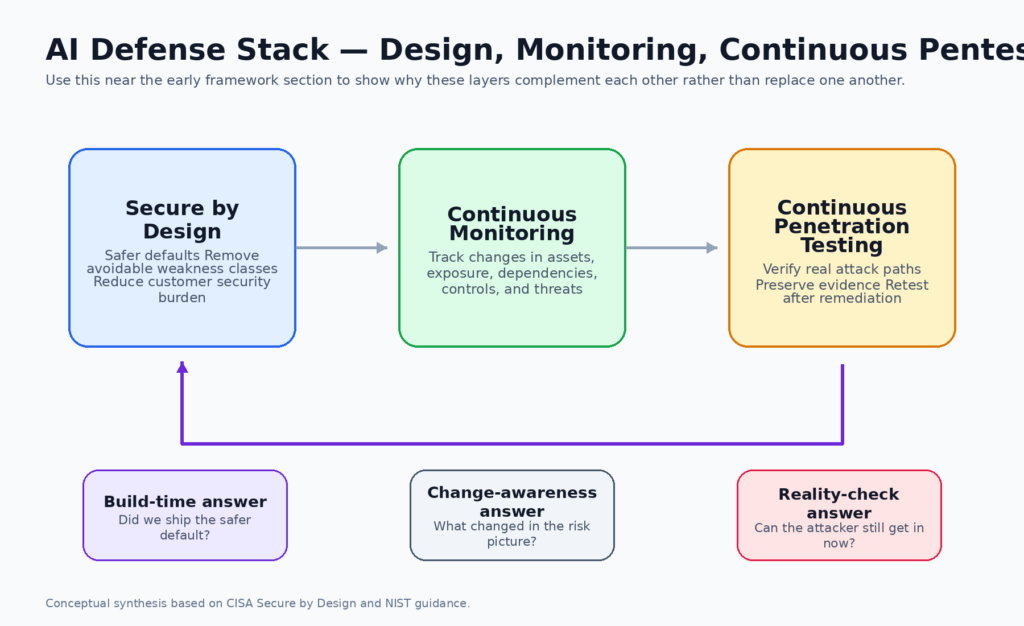
Secure by design lowers baseline risk, but it does not verify the live system

CISA’s secure-by-design guidance is one of the most important documents in modern defensive practice because it pushes responsibility back toward software manufacturers. In CISA’s framing, secure by design means shipping products that are safer by default and revamping design and development priorities so security outcomes do not depend primarily on perfect customer behavior. CISA’s principles and related guidance explicitly emphasize taking ownership of customer security outcomes, and its secure-by-default language says the most important controls should be enabled automatically rather than left as optional hardening trivia. That is an essential correction to years of product design that externalized too much security burden. (cisa.gov)
But secure by design answers a different question from penetration testing. Secure by design asks whether the safer baseline was built into the product and its default configuration. It asks whether avoidable classes of weakness were removed early, whether product choices reduce customer burden, and whether the vendor is behaving responsibly. Penetration testing asks whether a real attacker can still turn what remains into access, privilege, persistence, exfiltration, or disruption in the current environment. Those questions are related, but they are not interchangeable. A secure design principle can be perfectly sound while a live deployment is still exploitable because of integration flaws, permissions drift, transitive dependencies, incomplete patching, or a workflow that no one retested after the last change. (cisa.gov)
NIST’s continuous monitoring guidance makes the same distinction from another angle. NIST defines information security continuous monitoring as maintaining ongoing awareness of information security, vulnerabilities, and threats to support organizational risk management decisions. NIST also clarifies that “continuous” and “ongoing” do not mean nonstop action for its own sake. They mean security controls and organizational risks are assessed and analyzed at a frequency sufficient to support risk-based security decisions. That definition is useful because it dispels one of the worst misunderstandings in this area. Continuous work is not mindless repetition. It is risk-timed repetition. (tsapps.nist.gov)
That distinction leads directly to continuous penetration testing. The term should not mean incessant exploitation attempts against production. It should mean a structured, recurring, evidence-driven program of adversarial verification, tied to high-risk assets and meaningful change events, run at a cadence sufficient to keep pace with real risk. In other words, it is the offensive verification counterpart to continuous monitoring. Monitoring tells you what changed. Continuous penetration testing tells you whether the changed thing now yields a credible attack path. (tsapps.nist.gov)
NIST’s penetration-testing guidance makes this even plainer. SP 800-115 defines penetration testing as security testing in which assessors mimic real-world attacks to identify methods for circumventing the security features of an application, system, or network. It says penetration testing often involves launching real attacks on real systems and data using tools and techniques commonly used by attackers. NIST further explains that penetration testing is useful for determining how well the system tolerates real-world attack patterns, what level of sophistication an attacker needs, what countermeasures could mitigate threats, and how well defenders can detect and respond. That is exactly the kind of proof design review and scanning alone do not provide. (nvlpubs.nist.gov)
The layered relationship looks like this:
| レイヤー | Primary question | Best use | What it cannot prove by itself |
|---|---|---|---|
| Secure by design | Did we remove avoidable weaknesses and ship safer defaults | Reduce baseline risk at build time and release time | Whether the current live system is still resistant after change |
| 連続モニタリング | What changed in assets, threats, controls, dependencies, and exposure | Maintain current awareness and trigger decisions | Whether the changed condition is practically exploitable |
| Continuous penetration testing | Can an attacker turn current conditions into real access or impact | Validate exploitability, defense effectiveness, and retest fixes | Whether product design upstream is eliminating future classes of weakness |
This table is a synthesis of CISA’s secure-by-design framing, NIST’s continuous monitoring model, and NIST’s penetration-testing guidance rather than a direct quote from a single source. (cisa.gov)
Continuous monitoring and continuous penetration testing do different jobs
Security teams often collapse these categories because the words sound adjacent. That mistake becomes expensive under AI conditions. Continuous monitoring can show that a new internet-facing service appeared, a package version changed, a WAF policy drifted, a sensitive endpoint became reachable from a new network zone, or a CVE moved into active exploitation. Those are vital signals. They tell you something changed in your risk picture. They do not tell you whether an attacker can chain the exposed condition into meaningful effect against your system. (tsapps.nist.gov)
Penetration testing starts where the signal becomes a hypothesis. If monitoring tells you a new auth flow shipped, penetration testing asks whether that flow leaks privilege through alternate routes, stale session material, misapplied role checks, or business-logic shortcuts. If monitoring tells you a library changed, penetration testing asks whether the vulnerable parser is reachable in the way your application actually handles input. If monitoring tells you an externally reachable service now sits behind a different proxy, penetration testing asks whether that proxy changes request normalization, authentication handling, header trust, or tenant isolation in ways an attacker can abuse. (nvlpubs.nist.gov)
NIST’s own guidance describes a useful operational balance. SP 800-115 says organizations should consider less labor-intensive testing activities on a regular basis to maintain the required security posture, and that a well-designed program of regularly scheduled network and vulnerability scanning interspersed with periodic penetration testing can help prevent many attacks and reduce the impact of successful ones. That sentence is old, but it has aged well. It implies that detection and validation are complementary, not competing, and that a mature program uses both. What changes in the AI era is not the principle. It is the speed pressure around the validation side. (nvlpubs.nist.gov)
The same NIST publication says application tests should also be performed periodically once an application goes into production, when significant patches, updates, or other modifications are made, or when significant changes occur in the threat environment where the application operates. That is already the logic of continuous pentesting, even if the publication predates today’s AI systems by many years. It anchors the idea in change and threat movement rather than in a fixed annual ritual. Glasswing should be read as evidence that one side of the threat environment, offensive capability, may now be moving faster. (nvlpubs.nist.gov)
OWASP gives application teams the missing middle
OWASP is especially useful here because it bridges engineering reality and assessment reality. The Web Security Testing Guide describes itself as a comprehensive guide to testing the security of web applications and web services and as a framework of best practices used by penetration testers and organizations around the world. That matters because web risk is where many teams still confuse scanner coverage, secure coding checklists, and real attack-path verification. WSTG is not a product pitch and it is not a benchmark sheet. It is a reminder that application security testing has to include authentication, session management, authorization, business logic, configuration, and reporting discipline. (owasp.org)
OWASP ASVS adds another layer by turning security expectations into testable requirements. ASVS says it provides a basis for testing web application technical security controls and also gives developers a list of requirements for secure development. It also says one of its objectives is use during procurement, providing a basis for specifying application security verification requirements in contracts. That is highly relevant for buyers evaluating AI-assisted testing workflows. If a vendor says its workflow “does pentesting,” the right follow-up is not to ask for more adjectives. It is to ask which controls are actually being verified, what evidence is preserved, and how retesting is handled after remediation. (owasp.org)
In practice, OWASP’s contribution is to prevent the conversation from floating into abstraction. Secure design principles matter. Monitoring matters. But for application teams, the real work still lives in repeatable verification of controls and behaviors. That is why the phrase continuous penetration testing needs to be understood as a software delivery discipline as much as an offensive discipline. It belongs near deployment, change management, high-risk features, and fix validation, not only inside an annual external engagement. (owasp.org)
Why old bugs still matter under AI conditions
One of the most interesting parts of Anthropic’s Mythos write-up is not the browsers or the exploit chains. It is the age distribution of some of the bugs. Anthropic says many of the vulnerabilities it found were ten or twenty years old, and it specifically points to a 27-year-old OpenBSD bug. Anthropic’s description says Mythos Preview identified a vulnerability in OpenBSD’s TCP SACK handling that would allow an adversary to crash any OpenBSD host that responds over TCP. OpenBSD’s 7.8 errata page later lists a March 25, 2026 reliability fix stating that TCP packets with invalid SACK options could crash the kernel. That pairing does not prove every maximal inference people might want to draw from the story, but it does support the basic lesson: long-lived, nontrivial defects can remain latent in heavily reviewed systems for years, and better search and reasoning tools change the economics of finding them. (red.anthropic.com)
This is exactly where many defensive narratives become too comfortable. Teams often talk as if the age of a codebase and the frequency of past review make the remaining flaws less urgent. In one sense that is true, because trivial bugs tend to get removed first. In another sense it is backwards, because the remaining flaws may be difficult, obscure, and spread across paths no one has re-examined recently. Anthropic says this explicitly in its discussion of source-visible bug finding: heavily audited codebases tend to have fewer trivial bugs left, which makes the remaining bugs harder and more meaningful as a test of capability. For defenders, the implication is that “we reviewed that years ago” is losing value as a stopping argument. (red.anthropic.com)
AI does not magically create bugs that were not there. What it can do is make exhaustive or semi-exhaustive hypothesis generation, ranking, and validation cheaper across large codebases and large search spaces. Anthropic’s scaffold description is revealing for that reason. It is not an image of a model having a mystical insight. It is an image of a system repeatedly reading, ranking, executing, debugging, and filtering candidate bug reports. The change is industrial, not mystical. And industrial changes in bug-finding economics usually force industrial changes in defensive verification. (red.anthropic.com)
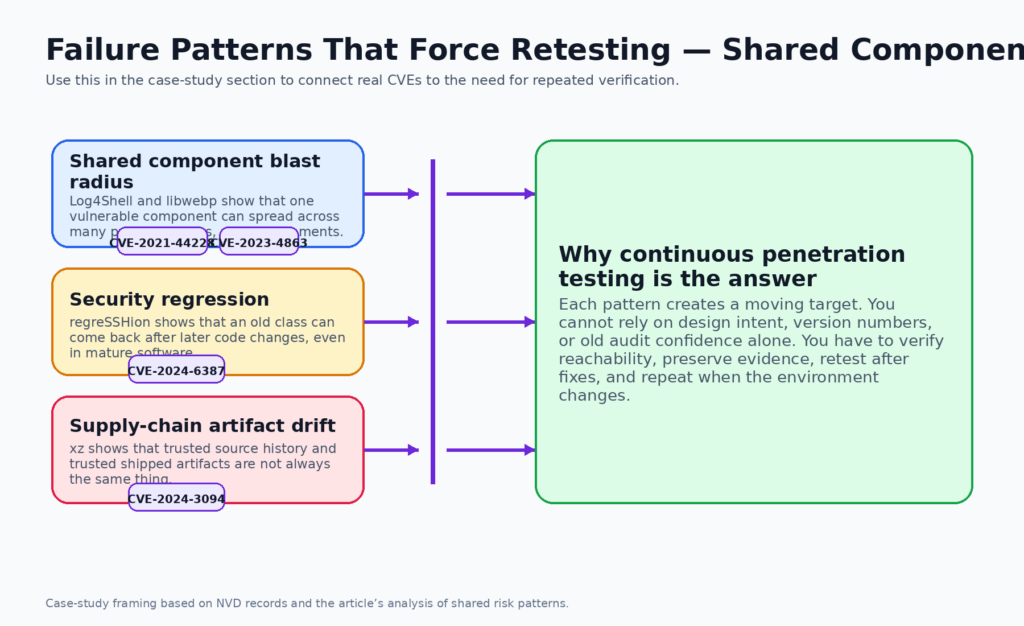
Log4Shell shows why shared components break the one-time test model
CVE-2021-44228 remains one of the clearest examples of why modern defense needs retesting after exposure changes, not just awareness after disclosure. NVD describes the flaw as affecting Log4j2 versions in the vulnerable range and explains that when JNDI lookups are enabled, an attacker who can control log messages or log message parameters can cause arbitrary code to be loaded from attacker-controlled LDAP and related endpoints. The NVD record also notes mitigations such as disabling lookups in affected versions or removing the JndiLookup class in older releases, while CISA’s advisory said Log4Shell and related Log4j vulnerabilities were being actively exploited. This was never just a patch memo. It was an environment-wide verification event. (nvd.nist.gov)
What made Log4Shell strategically important was not only severity. It was combinatorial reach. Security teams first needed to know where Log4j existed directly and transitively, then whether the vulnerable code path was reachable from attacker-controlled input, then whether their runtime, config, logging path, or network controls actually prevented exploitation in practice. That is why dependency inventories and SBOMs were necessary but not sufficient. Inventory can tell you where to look. It does not tell you whether your system’s actual behavior still yields a viable attack path. Only targeted verification can answer that. (nvd.nist.gov)
Log4Shell also exposed a human tendency that Glasswing makes riskier: teams often stop testing when they can narrate the problem. Once security staff can say “the bug is in JNDI lookups” or “we removed JndiLookup from the jar,” they feel closure. But the real question is whether the current deployment is still exploitable through the system’s live logging surfaces, fallback code, stale images, forgotten services, and post-fix regressions. Continuous penetration testing is the discipline that keeps teams from confusing a technically correct explanation with a verified security outcome. (nvd.nist.gov)
This is also why Glasswing matters to defenders who do not run operating systems or browsers. Shared components turn vulnerability response into a repeated retest problem across many business applications and internal services. If AI is improving the economics of turning candidate flaws into working exploit logic, then the pressure to validate shared-component exposure will rise not only for frontier software vendors but for ordinary engineering organizations that depend on the same libraries. Log4Shell was an early warning for that operational reality. (アンソロピック)
libwebp shows why reachability matters more than vendor patch notes
CVE-2023-4863 looks simple when written as a single sentence. NVD describes it as a heap buffer overflow in libwebp in Google Chrome prior to 116.0.5845.187 and in libwebp 1.3.2, allowing a remote attacker to perform an out-of-bounds memory write via a crafted HTML page. Google’s Chrome release notes confirm the patched browser version. The NVD entry also notes that the issue is in CISA’s Known Exploited Vulnerabilities Catalog, which is an unusually strong signal that the vulnerability moved from “serious bug” into “real operational priority.” (nvd.nist.gov)
The defensive lesson is bigger than browser patching. libwebp existed far beyond Chrome, and the NVD language itself had to evolve because the issue was not limited to a browser codebase. Once a parsing library is widely embedded, version awareness becomes only the first step. The deeper question is reachability. Does your service accept attacker-controlled images, thumbnails, embedded media, imported documents, or converted assets that flow through a vulnerable decoder? Does the vulnerable path run in a hardened sandbox, a thin container wrapper, a rich desktop context, or a server-side media pipeline with privileged storage access? Those are penetration-testing questions, not merely inventory questions. (nvd.nist.gov)
This is where continuous pentesting earns its keep. Monitoring and patch advisories can tell you the bug exists, that the vendor shipped a fix, and that exploitation is known in the wild. But if your team never validates the actual data path in your own stack, you are still trusting abstraction. A retest after patching or after swapping the decoding component is not redundant paperwork. It is the difference between knowing the library is newer and knowing the exploitable behavior is gone. (nvd.nist.gov)
regreSSHion shows how old classes come back through regression
CVE-2024-6387 is valuable because it demonstrates a different failure mode from Log4Shell and libwebp. NVD describes the issue as a security regression of CVE-2006-5051 in OpenSSH’s server, sshd. It says a race condition can lead sshd to handle some signals in an unsafe manner, and that an unauthenticated remote attacker may be able to trigger the condition by failing to authenticate within a set time period. The keyword that matters most is regression. This was not simply a new bug in a new feature. It was a return of a class that had history. (nvd.nist.gov)
OpenSSH’s 9.8 release notes sharpen the point. The project says 9.8 and 9.8p1 contain fixes for two security problems, one critical and one minor, and describes the critical issue as affecting Portable OpenSSH versions 8.5p1 through 9.7p1 inclusive. It says arbitrary code execution with root privileges may be possible, that successful exploitation was demonstrated on 32-bit Linux glibc systems with ASLR under lab conditions, and that improvement of the attacks is likely. That language is one of the reasons the issue drew so much attention. But even without focusing on exploitability details, the structural lesson is enough: a codebase that is mature, respected, and widely deployed can still reintroduce a previously addressed class of weakness. (openssh.com)
Regression risk has a nasty property that secure-by-design thinking alone cannot eliminate. A team can have the right principles, the right past fixes, and a strong engineering culture, then still drift back into exposure because code moved, assumptions shifted, or adjacent behavior changed. That is why post-change retesting matters more than defensive rhetoric. It is also why “we already audited SSH,” “we already fixed that class in the past,” or “this service is old and stable” are not satisfying risk answers. Regression vulnerability is a reminder that security is temporal. The question is not whether you were safe once. The question is whether you are safe now. (nvd.nist.gov)
This is exactly the kind of issue continuous penetration testing is built to catch. A team that ties retests to meaningful changes, to new upstream advisories, and to control-sensitive subsystems is much more likely to detect regressions before an attacker does. A team that relies on annual confidence or inherited reputation is much more likely to learn the lesson the hard way. regreSSHion is not just a CVE story. It is a calendar story. It shows what happens when the cadence of assurance drifts too far behind the cadence of code and attacker attention. (nvlpubs.nist.gov)
xz proves that source trust and shipped trust are different
CVE-2024-3094 belongs in this discussion because it is not primarily about a coding mistake. NVD describes the issue as malicious code discovered in upstream xz tarballs starting with version 5.6.0. It says the tarballs included extra build-related files and obfuscated instructions that extracted a prebuilt object file from disguised test material, which then modified functions during the liblzma build process. The result was a modified library that could be used by linked software and could intercept and modify data interactions with that library. The critical point is that the attack lived in the path between repository trust and shipped artifact trust. (nvd.nist.gov)
That difference matters far beyond xz itself. Many security programs still reason as if source review and dependency naming are enough to establish confidence. xz showed that a build artifact can diverge from repository intuition in ways that are invisible to casual review and highly meaningful at runtime. A team may have a secure design review for its own application and a reasonable SBOM for its declared dependencies, yet still deploy a compromised artifact if the packaging or build chain becomes the attack surface. That is not a hypothetical corner case anymore. It is a real category of failure. (nvd.nist.gov)
Continuous penetration testing helps here because it validates behavior at the deployed boundary, not just declared intent in the source tree. That does not mean a pentest will always detect a supply-chain compromise. It does mean a serious verification program treats the live system as a thing to test in its own right, rather than as a perfect reflection of repository history. That mindset shift is one of the deepest implications of the xz incident. You are not done when you trust the code you meant to ship. You are closer to done when you verify the software you actually shipped behaves as intended under hostile pressure. (nvd.nist.gov)
It also helps explain why Glasswing focuses not only on open-source source-visible work but on black box testing of binaries and securing foundational systems. Once a major model lab starts talking explicitly about binaries, endpoints, and penetration testing of systems, it is acknowledging the same truth xz made painfully obvious: defensive confidence has to extend past design-time reasoning and into live artifact behavior. (アンソロピック)
White-box exploit research is not the same as black-box web pentesting
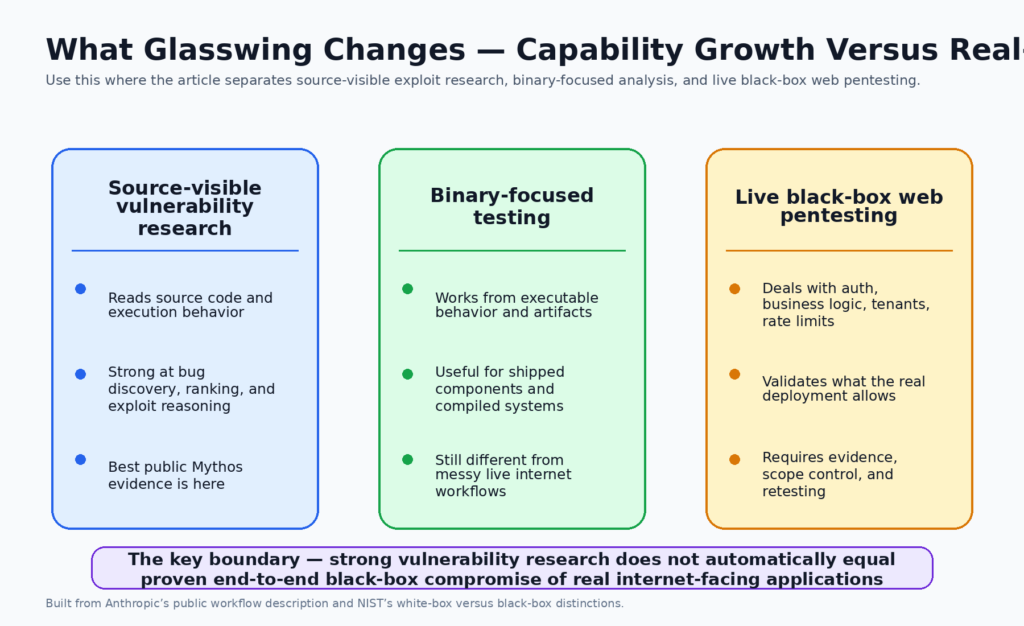
This is the distinction many people skipped as soon as the Mythos headlines hit. Anthropic’s public scaffold is clearly source-visible. It runs the project and its source code in an isolated container, lets Claude Code inspect the code, execute the target, debug behavior, and emit proof-of-concept material. That is a legitimate and powerful setup for vulnerability research. It is also not the same thing as an external tester approaching a live internet-facing application with only externally visible behavior, a small amount of contextual knowledge, limited requests, rate limits, inconsistent error messages, tenant boundaries, auth workflows, and unknown backend structure. (red.anthropic.com)
NIST’s Appendix C is very helpful here because it says application security techniques can be divided into white box techniques, which involve direct analysis of source code, and black box techniques, which are performed against the application’s binary executable without source code knowledge. NIST adds that white box methods are often more efficient and cost-effective for finding security defects in custom applications, but they cannot detect all interface defects or problems introduced during compilation, linking, or installation-time configuration. It also says black box techniques should be used primarily to assess high-risk compiled components, interactions between components, and how the application or application system handles threats in its interactions with users, other systems, and the external environment. That is an extremely useful boundary line. (nvlpubs.nist.gov)
NIST also notes a subtle point that matters even more in modern web environments: some applications, such as many web applications, do not have compiled binary executables in the sense that makes classic binary black-box language cleanly applicable. That is one reason so much public discussion becomes muddy. Binary reverse engineering and source reconstruction are real, important capabilities. But business-logic-heavy SaaS testing, identity workflows, session boundaries, alternate auth channels, multi-tenant state handling, race windows, and authorization regression are not well described by simply saying “the model can do black box work.” The task shape changes. So do the evidentiary demands. (nvlpubs.nist.gov)
Anthropic’s own material actually supports this more careful reading. It says Mythos found web application logic vulnerabilities and authentication bypasses, but because those issues are still unpatched it does not publicly document the full conditions, environments, and validation flows. That means the public record proves enough to justify defensive concern, but not enough to flatten all modes of security testing into one solved category. Readers should resist the temptation to turn “major progress” into “task categories are gone.” They are not. (red.anthropic.com)
A clean way to think about the distinction is this:
| Work mode | What the tester or model can see | What it is best at proving | Where the public Mythos evidence is strongest | What still remains harder in live environments |
|---|---|---|---|---|
| White-box vulnerability research | Source code, build context, runtime feedback | Code-path reasoning, subtle bug discovery, exploit triage | Very strong | Live deployment variance, external workflow behavior |
| Binary-focused black-box research | Executable behavior and binary artifacts, sometimes with reconstructed source | Compiled component analysis, interface behavior, exploitability of shipped artifacts | Meaningful but narrower | Source-free reproducibility across hardened, messy production conditions |
| Live black-box web pentesting | External behavior, auth flows, timing, tenant boundaries, business logic, perimeter controls | Real attack-path verification against actual deployments | Public evidence is still limited | Scope control, evidence quality, false positives, workflow coverage, retest discipline |
This table is a synthesis of Anthropic’s disclosed workflow, NIST’s white-box and black-box distinctions, and the practical boundary emphasized in Penligent’s Mythos analysis. (red.anthropic.com)
That is why the Penligent article “Claude Mythos Preview Is Not Black Box Pentesting” is a useful supplementary read rather than just a vendor opinion piece. Its core point is precise: white-box strength is not an insult, it is a job description. The article argues that reconstructed binary reasoning and source-rich exploit research are not equivalent to proving black-box web pentesting against the public internet. That distinction aligns with NIST’s own technical framing and with the gap in Anthropic’s currently public evidence. Even if one ignores the vendor angle entirely, the boundary is still technically correct. (ペンリジェント・アイ)
For defenders and buyers, this distinction should sharpen requirements rather than dampen excitement. A system that is excellent at source-visible bug finding, exploit triage, and reverse-engineering-assisted reasoning is incredibly useful. It may transform parts of software assurance. But it still does not relieve organizations of the need to test real deployments, preserve evidence from live verification, retest after fixes, and keep governance tight around scope and allowed actions. The future is not one magic category called “AI security.” It is multiple adjacent workflows that will increasingly feed each other. (red.anthropic.com)
What continuous penetration testing should actually look like
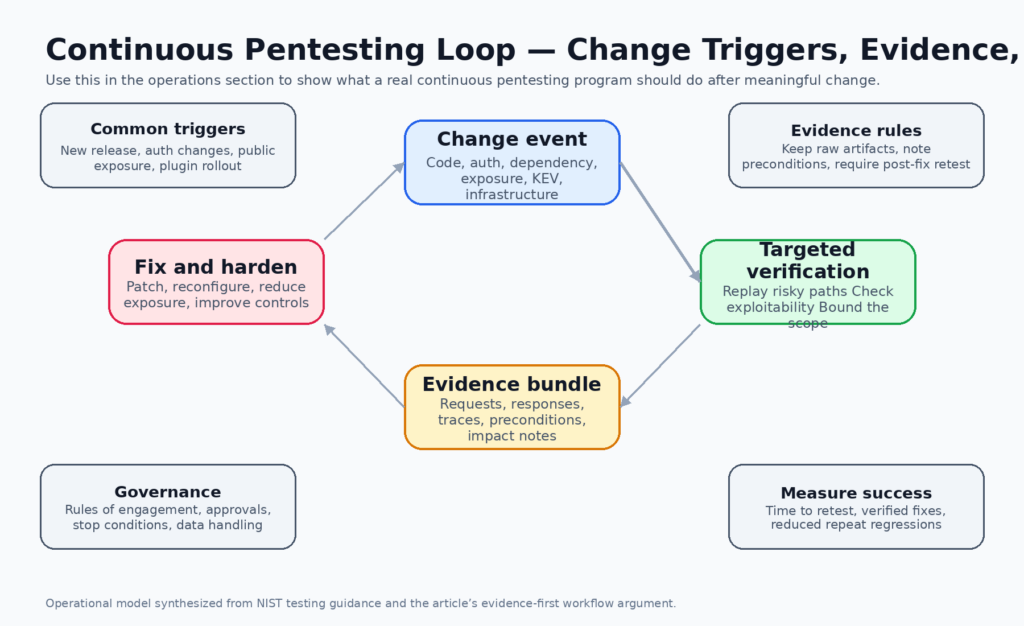
The phrase continuous penetration testing is useful only if it describes a real operating model. A serious model starts with trigger logic, not with a slogan. Significant patches, dependency updates, auth changes, new internet exposure, privilege model changes, new third-party integrations, KEV additions, routing changes, and high-value feature launches should all be able to trigger targeted adversarial verification. NIST’s application testing guidance supports this directly by saying tests should be performed periodically once an application is in production, when significant patches or other modifications are made, and when significant changes occur in the threat environment. (nvlpubs.nist.gov)
A second requirement is scoping discipline. Not every system needs the same cadence or the same style of testing. High-risk internet-facing services, identity systems, public APIs, payment or admin surfaces, remote access infrastructure, and software handling high-value user data deserve much tighter retest triggers than low-risk internal tools. SP 800-115 repeatedly emphasizes risk, planning, coordination, and the fact that target vulnerability validation techniques carry the highest operational risk of the testing categories it describes. Continuous pentesting therefore has to be selective. Doing it well does not mean doing everything all the time. It means refusing to leave the most dangerous paths unverified after meaningful change. (nvlpubs.nist.gov)
A third requirement is evidence preservation. The unit of value in a mature security program is not “the model believes there may be an issue.” It is a verified finding with preconditions, steps, impact description, raw evidence, and post-fix retest status. NIST’s publication is explicit that security testing is not only about discovering weaknesses but also about analyzing findings, developing mitigation strategies, planning reporting, and handling data. Continuous pentesting without evidence discipline produces noise. Continuous pentesting with evidence discipline produces engineering work that can be replayed, fixed, and measured. (NISTコンピュータセキュリティリソースセンター)
A fourth requirement is closure after remediation. Too many organizations still treat the discovery of a vulnerability as the end of the story and patch deployment as the end of the process. In practice, the only trustworthy endpoint is validated remediation. That can mean rerunning the same authenticated scenario, replaying the same object access pattern, verifying that an error normalization change did not reopen a side channel, or confirming that a dependency update removed the vulnerable path rather than just the package label. Continuous pentesting is valuable because it treats retest as a first-class step, not a courtesy. (nvlpubs.nist.gov)
A practical trigger matrix looks like this:
| Trigger event | What to test | Evidence that matters most | Typical owner |
|---|---|---|---|
| Dependency update for parser, image, auth, crypto, or network stack | Reachability and exploitability of the changed path | Requests, sample inputs, runtime traces, before and after behavior | AppSec with service owner |
| Auth or session logic change | Login, session fixation, privilege carryover, role separation, bypass routes | Side-by-side role output, token transitions, session cookies, replay traces | AppSec and identity team |
| New public exposure | Perimeter discovery, default controls, routing assumptions, alternate entry points | Network traces, headers, exposed endpoints, config snapshots | Platform security |
| KEV addition or active exploitation advisory | Targeted reprioritized checks on exposed assets | Proof that the vulnerable path is absent, blocked, or remediated | Security operations with app owner |
| Patch deployment for prior finding | Exact regression replay of the original path | Before and after reproduction steps and fix confirmation | Engineering owner with security reviewer |
| New plugin, connector, or third-party integration | Trust boundary, secret handling, token scope, callback flows | Request flows, scope mappings, data path evidence | Integration owner and security |
This table is a practical synthesis of NIST’s change-oriented testing guidance, KEV-style prioritization, and the recurring lessons from modern vulnerability response. (nvlpubs.nist.gov)
Evidence, retesting, and reporting are the real outputs
One of the most important but least glamorous facts in SP 800-115 is that assessment value comes from more than finding a bug. The document is organized around planning, execution, analysis, reporting, and mitigation strategy. That structure is not paperwork. It reflects a deep truth about security operations: an issue that cannot be reproduced, communicated, prioritized, and retested is not yet a useful security result. The AI era does not weaken that truth. It makes it more important, because the volume of candidate findings will rise faster than the human capacity to triage noise. (NISTコンピュータセキュリティリソースセンター)
That is where evidence-first workflows matter more than raw vulnerability claims. Anthropic’s public scaffold is notable not only because Mythos reads code and tries exploits, but because it is described as outputting bug reports with proof-of-concept material and reproduction steps, then passing severe issues through human triage. The scaffold’s closing confirmation step, where a final agent is asked whether a report is real and interesting, is effectively an internal evidence quality filter. Security teams should learn from that pattern even if they do not use Anthropic’s tooling. The goal is not just to find more. It is to keep what you find actionable. (red.anthropic.com)
This is also where a restrained Penligent mention fits naturally. Penligent’s public materials are strongest when they argue that the valuable output of AI-assisted pentesting is not chatbot commentary about vulnerabilities but replayable proof, evidence capture, retesting after fixes, and reporting that another human can verify. Its article on outsourcing pentesting with AI makes the same operational point in plainer language: AI is most useful when it absorbs the repetitive work of asset mapping, authenticated replay, hypothesis tracking, evidence capture, and retesting without taking scope control away from the organization. That is not a marketing abstraction. It is a practical description of what a serious evidence-preserving workflow should do. (ペンリジェント・アイ)
A good evidence package usually contains five things. First, it preserves the preconditions needed to trigger the behavior, including identity, headers, parameters, state, or timing assumptions. Second, it stores raw request and response material or equivalent runtime traces. Third, it explains impact in environment-specific language rather than generic severity adjectives. Fourth, it records the remediation expectation in a form the engineering owner can work from. Fifth, it includes a retest result after the fix. Those are the things that transform a candidate issue into durable security knowledge. (nvlpubs.nist.gov)
Safe automation patterns for AI-assisted validation
A useful automation pattern is to attach security regression checks to both change events and scheduled runs, while keeping the checks bounded and the artifacts auditable. The point is not to dump destructive exploit attempts into every CI run. The point is to encode the habit of retesting known high-risk paths, checking reachability of newly risky dependencies, and preserving artifacts that let humans review what happened. That is consistent with NIST’s view that organizations need repeatable technical testing processes and that reporting and data handling are integral parts of the assessment lifecycle. (NISTコンピュータセキュリティリソースセンター)
name: security-regression-verification
on:
push:
branches: [main]
schedule:
- cron: "0 3 * * *"
workflow_dispatch:
jobs:
verify-high-risk-paths:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Build security test environment
run: docker compose -f docker-compose.security.yml up -d --build
- name: Run authenticated authorization checks
run: python tests/security/run_regression.py --profile authz_core
- name: Check dependency reachability
run: python tests/security/check_dependency_reachability.py
- name: Run perimeter smoke validation
run: python tests/security/perimeter_smoke.py --target staging
- name: Collect evidence bundle
run: tar -czf security-evidence.tgz logs/ findings/ traces/ artifacts/
- name: Upload evidence
uses: actions/upload-artifact@v4
with:
name: security-evidence
path: security-evidence.tgz
The workflow above is an example, not a standard. What makes it useful is the shape: build a realistic test environment, run targeted checks against high-risk paths, store evidence, and make the result reviewable. That shape is much closer to continuous penetration testing than the older habit of running a scanner and calling the output “continuous security.” The scanner still has a place, but it is not the same job. (nvlpubs.nist.gov)
Another practical pattern is differential control testing. Many of the most serious production regressions are not exotic memory corruptions. They are authorization drift, role confusion, tenant bleed, workflow shortcuts, or changes in how object access is enforced after a deployment or integration change. A lightweight regression script that compares behavior across roles can catch a surprising amount of security decay when attached to risky changes. That pattern also maps cleanly to OWASP’s focus on application control verification. (owasp.org)
import requests
BASE_URL = "https://staging.example.internal"
ADMIN_TOKEN = "replace-with-test-admin-token"
USER_TOKEN = "replace-with-test-user-token"
def fetch_invoice(invoice_id: str, token: str) -> tuple[int, str]:
r = requests.get(
f"{BASE_URL}/api/invoices/{invoice_id}",
headers={"Authorization": f"Bearer {token}"},
timeout=10,
)
return r.status_code, r.text[:500]
invoice_id = "INV-2026-00017"
admin_status, admin_body = fetch_invoice(invoice_id, ADMIN_TOKEN)
user_status, user_body = fetch_invoice(invoice_id, USER_TOKEN)
print("admin:", admin_status)
print("user :", user_status)
if admin_status == 200 and user_status == 200 and admin_body == user_body:
raise SystemExit("Possible authorization regression detected")
print("No obvious regression detected in this check.")
This kind of check is intentionally modest. It does not claim to replace a human pentester. It demonstrates the smallest repeatable unit of continuous penetration testing: a bounded adversarial hypothesis tied to a real security control, executed after change, preserved as evidence, and rerun after fixes. Scale that habit across the most dangerous flows and you get a much more credible security program than one built around periodic narrative confidence. (nvlpubs.nist.gov)
A second restrained Penligent note belongs here. Penligent’s homepage and documentation position the platform as an AI-driven pentesting workflow rather than a static scanner, and that framing lines up with the operational need described above. The useful question for a team is not whether a platform can “talk security” fluently. It is whether it can help preserve hypotheses, scope, evidence, and retest state as software changes. If a workflow cannot do that, it is much closer to assisted commentary than to continuous verification. (ペンリジェント・アイ)
Governance, rules of engagement, and kill switches matter more as AI improves
Continuous penetration testing should never be interpreted as indefinite permission for an autonomous system to do whatever seems interesting. SP 800-115 is extremely clear that assessment plans need to spell out what systems are authorized for assessment, what activities are permitted, and what activities are prohibited. The plan should include testing approach, tools, logistics, data handling requirements, incident handling guidance, and clear instructions for what assessors should do if scope questions or actual incidents arise. In NIST’s telling, ambiguity is itself a control failure. (nvlpubs.nist.gov)
The publication goes further and explains why Rules of Engagement are needed for intrusive work. It says an ROE contains the same information as an assessment plan but also addresses testing activities that are usually prohibited by the organization. NIST specifically notes that some activities often performed during penetration testing, such as issuing attacks to compromise systems, are usually prohibited by policy, and that the ROE is what authorizes them as part of the assessment process. That is a useful reminder in the current AI moment. If organizations want AI to accelerate adversarial validation, they must get more disciplined about policy, not less. (nvlpubs.nist.gov)
A simple internal policy fragment might look like this:
targets:
include:
- https://staging.example.internal
- https://api.staging.example.internal
exclude:
- production payment endpoints
- customer data exports
- third-party managed tenant environments
allowed_actions:
- authenticated replay
- bounded input mutation
- authorization differentials
- dependency reachability checks
- passive discovery
- rate-limited perimeter validation
forbidden_actions:
- destructive state changes
- bulk data extraction
- credential stuffing
- persistence mechanisms
- privilege escalation without approval
- third-party scope expansion
approval_gates:
exploit_attempt_required: manual
production_test_required: security-lead-and-owner
high-impact-evidence-release: legal-review
evidence:
retain_requests: true
retain_responses: true
record_preconditions: true
post_fix_retest_required: true
The point of a fragment like this is not formalism for its own sake. It is to force a security team to decide what kind of speed it actually wants and what kind of risk it is willing to absorb in exchange. NIST also recommends legal advisors be involved for intrusive tests such as penetration testing, particularly when outside entities are involved or when data handling and privacy concerns may arise. In a world where AI may lower the cost of trying many things quickly, those governance choices become even more important. Speed without policy does not create a better security program. It just creates faster ambiguity. (nvlpubs.nist.gov)
NIST’s execution guidance also emphasizes coordination during the engagement. It says stakeholders should know the schedule, activities, and potential impacts, that assessments should avoid periods when systems are already being altered, and that if an incident occurs, it is recommended that activities cease until the incident is addressed and the assessors are authorized to resume. Those are not outdated bureaucratic niceties. They are the operational safeguards that let an aggressive testing program coexist with system availability and accountability. (nvlpubs.nist.gov)
Continuous penetration testing changes what buyers should ask
The rise of AI-assisted offensive workflows means technical buyers need better questions than “Does it use agents” or “Can it find zero-days.” The first useful question is visibility mode. Is the workflow primarily white-box, source-visible, binary-focused, or live black-box against deployed systems? A vendor that cannot explain that boundary is asking the buyer to accept category confusion as product value. NIST’s distinctions here remain a strong sanity check. Different task shapes require different claims, different evidence, and different governance. (nvlpubs.nist.gov)
The second question is evidence quality. Does the workflow keep raw requests, responses, runtime traces, and preconditions? Can it produce findings with reproduction steps, impact framing, and post-remediation retest status? Does it filter low-value issues before surfacing them? Anthropic’s own internal scaffold includes confirmation and triage steps before disclosure, which is revealing. Even a frontier lab does not treat raw model output as a finished security result. Buyers should not either. (red.anthropic.com)
The third question is change handling. Can the workflow be tied to significant patches, auth changes, dependency upgrades, public exposure changes, or active exploitation intelligence? NIST explicitly supports retesting after significant modifications and threat-environment changes. A system that only produces a one-time report may still be useful in a narrow consulting sense, but it is not aligned with the pace at which modern software risk actually moves. (nvlpubs.nist.gov)
The fourth question is operational safety. Does the platform support scope restrictions, prohibited action lists, approval hooks, rate control, incident stop conditions, and data handling rules? If it does not, the buyer is not evaluating a mature testing workflow. It is evaluating a tool that may generate findings while pushing governance work back onto the customer. In practice, that often means the customer either slows the tool down so much that it loses value or runs it too loosely and absorbs unnecessary risk. Neither is a good outcome. (nvlpubs.nist.gov)
The fifth question is whether the workflow produces engineering closure rather than presentation output. Security teams do not ultimately need prettier dashboards. They need verified attack-path status, fixable findings, and retestable evidence. That is why the most credible AI pentesting conversations are starting to sound less like “agent magic” and more like discussions of workflow design, evidence integrity, policy controls, and fix validation. The market is slowly rediscovering what NIST already implied years ago: penetration testing is valuable because it validates reality, not because it generates dramatic narratives. (nvlpubs.nist.gov)
Project Glasswing is the warning, not the whole answer

Project Glasswing does not prove that every organization should rush to deploy an unreleased frontier model. It does not prove that public internet black-box web pentesting has been fully solved by a single model. It does not make secure-by-design work obsolete, and it does not make humans irrelevant. What it does do is force a more serious conversation about where defensive confidence comes from. Anthropic is effectively saying that frontier models are already strong enough in cybersecurity tasks that restricted release, coordinated disclosure, and defensive partnership programs are the right deployment pattern for now. That alone should get defenders to revisit the pace of their verification loops. (アンソロピック)
The institutions already gave the defensive blueprint. CISA says software manufacturers should build and ship safer defaults and take ownership of customer security outcomes. NIST says security requires ongoing awareness of vulnerabilities and threats at a frequency sufficient to support risk-based decisions. NIST also says penetration testing uses real attack techniques to validate weaknesses, and that applications should be retested after production changes and threat-environment changes. OWASP keeps application teams honest by turning security behavior into concrete testing and verification work. Glasswing does not replace that blueprint. It raises the price of ignoring it. (cisa.gov)
That is the real takeaway. Secure design remains necessary. Monitoring remains necessary. But if defenders want to keep pace with software change, dependency risk, regression risk, supply-chain risk, and AI-assisted offensive capability, they need continuous penetration testing as a standing discipline. Not because a slogan says so. Because the current environment keeps generating new conditions to verify, and trust without repeated verification is not a serious defensive strategy anymore. (アンソロピック)
Further reading and references
- Anthropic, Project Glasswing. (アンソロピック)
- Anthropic, Assessing Claude Mythos Preview’s cybersecurity capabilities. (red.anthropic.com)
- NIST, SP 800-115 Technical Guide to Information Security Testing and Assessment. (NISTコンピュータセキュリティリソースセンター)
- NIST, SP 800-137 Information Security Continuous Monitoring. (tsapps.nist.gov)
- CISA, セキュア・バイ・デザイン and related principles. (cisa.gov)
- OWASP, Web Security Testing Guide. (owasp.org)
- OWASP, Application Security Verification Standard. (owasp.org)
- NVD、 CVE-2021-44228 Log4Shell. (nvd.nist.gov)
- CISA, Mitigating Log4Shell and Other Log4j-Related Vulnerabilities. (cisa.gov)
- NVD、 CVE-2023-4863 libwebp. (nvd.nist.gov)
- Google Chrome Releases, Stable Channel Update for Desktop. (Chrome Releases)
- NVD、 CVE-2024-6387 regreSSHion. (nvd.nist.gov)
- OpenSSH, 9.8 and 9.8p1 Release Notes. (openssh.com)
- NVD、 CVE-2024-3094 xz backdoor. (nvd.nist.gov)
- OpenBSD, 7.8 Errata and Patches. (openbsd.org)
- Penligent, クロード神話プレビューはブラックボックス・ペンテストではない. (寡黙)
- Penligent, Outsource Penetration Testing with AI Without Losing Control. (寡黙)
- Penligent, homepage and docs. (寡黙)

