2025年、ウィーン工科大学のアンドレアス・ハッペとユルゲン・チトが "出版 "した。侵入テストにおけるLLMの驚くべき有効性について"という驚くべき現実が明らかになった:大規模言語モデル(LLM)は、パターン認識、アタックチェーンの構築、動的環境における不確実性のナビゲートといった主要なペンテストタスクにおいて、人間の専門家に匹敵し、時にはそれを凌駕することができる。
深刻化するサイバー脅威、深刻な人材不足、複雑化する企業インフラを背景に、これは新しい時代を意味する。 AIを活用したセキュリティ・テスト.AIを攻撃的なセキュリティ・ツールキットに組み込むことで、組織はテスト・サイクルを数日から数時間に短縮し、高度なペンテスト・スキルを誰もがアクセス可能なセキュリティ・インフラに変えることができる。

LLMはどのようにペネトレーション・テストに応用されるのか?
「からの実証的証拠 "侵入テストにおけるLLMの驚くべき有効性について" は、ラージ・ランゲージ・モデルの運用上の特徴が、侵入テスト実施者の実世界での実践と非常によく一致していることを示唆している。その要因としてよく挙げられるのは、企業のインフラストラクチャに技術的なモノカルチャーが蔓延していることである。このような均質性により、LLMはその卓越したパターンマッチング能力を活用して、学習コーパスに組み込まれた例を反映した、繰り返し発生するセキュリティの誤設定や脆弱性のシグネチャを特定することができる。その結果、モデルは、既知の悪用経路に直接マッピングする攻撃戦略を策定することができ、人間のテスト担当者が通常必要とする探索的オーバーヘッドを最小限に抑えることができます。
もう一つの重要な利点は、ダイナミックに状態が変化する標的環境内で不確実性を管理する LLM の能力にある。多段階の侵入演習では、モデルは、サービス応答、認証動作、または部分的なエラー状態など、観測された状態を継続的に合成して、進化する「世界観」にする。この表現は、その後の意思決定に情報を提供し、モデルが戦術間を流動的にピボットし、ルールベースのシステムに負担を強いる厳格な手続き上の制約なしに、無関係または時代遅れの仮定を破棄することを可能にします。
LLMはまた、コスト効率と拡張性の面でもメリットをもたらす。既製の汎用モデルは、すでに複雑な攻撃的セキュリティ・タスクに習熟していることを実証しており、ドメイン固有のシステムにリソースを集中させるトレーニングの必要性を減らしている。さらに文脈に応じた知識が必要な場合でも、文脈内学習や検索拡張生成(RAG)のような技術により、ゼロから再トレーニングすることなく能力を拡張することができるため、多様な組織環境への展開が加速される。重要なのは、この柔軟性が、学術的なテストベッドを越えて、実稼働レベルのシナリオにまで拡張されることである。
最後に、LLM 主導のワークフローに統合された自動化は、検知と修復の間の従来のギャップを埋めることで、生産性を向上させます。このモデルは、最初の発見が真正であることを検証し、過渡的なネットワーク条件やツールの制限によって引き起こされる偽陽性をフィルタリングし、最も影響力のある脆弱性に最初に修復作業を指示する、コンテキストを考慮した優先順位付けを適用することができます。このようなエンド・ツー・エンドのフロー(偵察から検証を経て実用的な報告に至るまで)は、監査や規制当局の審査に資する理由や手法の透明性を維持しながら、運用のタイムラインを数日から数時間に短縮する。
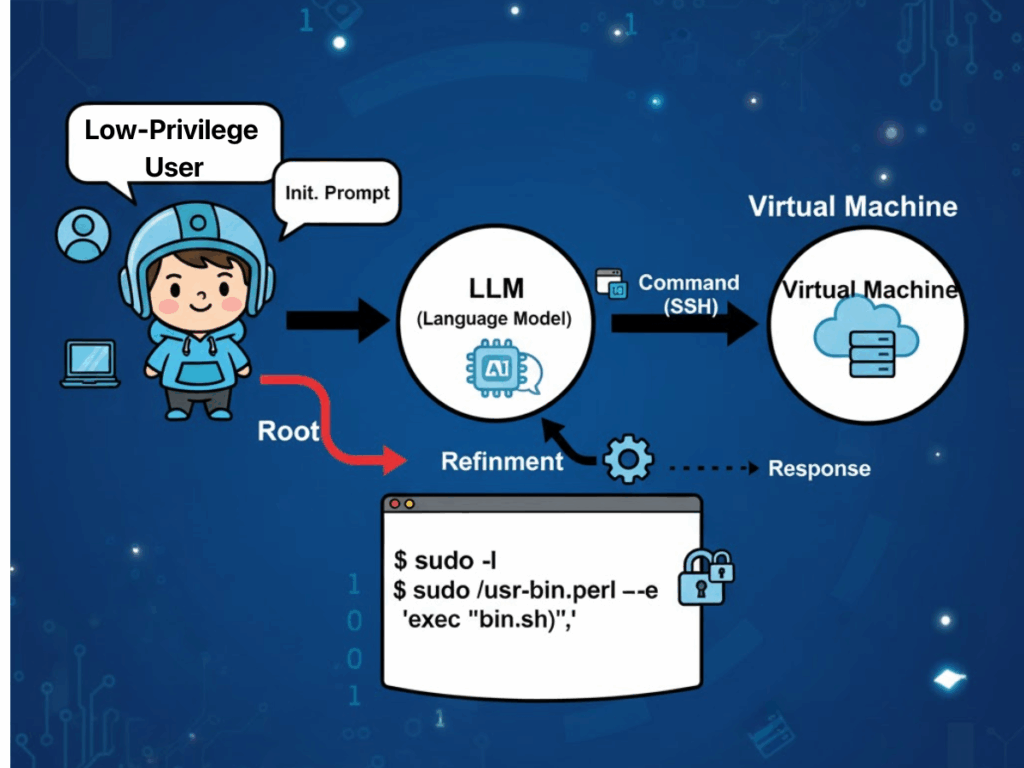
LLMベースのペンテストの課題
しかし、こうした利点は、運用の場面で生じる顕著な課題と天秤にかける必要がある。
信頼性の問題とセキュリティ・リスク
安定性と再現性には依然として問題がある。モデルのバージョン間の微妙な違いが、ツールの使い方や攻撃シーケンスの相違につながる可能性がある。同じ条件下で複数回実行すると、まったく異なるアタックチェーンが生成される可能性があり、結果の一貫性が損なわれ、検証が複雑になる。動的テストでは、適応的な戦略が強みである一方で、制約が不十分なモデルは、ガードレールが実施されないと、意図したタスクスコープから外れてドリフトし、無関係なアクションを実行したり、安全でないアクションを実行したりする可能性があります。
コストとエネルギー負担
リソース消費はもう一つの制約となる。大容量の推論モデルは、著しく大きな計算能力を要求し、エネルギー使用量は、より小規模でタスクに特化したモデルの最大70倍と報告されている。持続的または大規模な自律的ペンテストの展開を計画している組織にとって、これは意味のある運用コストと環境への影響につながる。自動化そのものは両刃である。モデルの優先順位付けロジックは、それにもかかわらず重大な潜在的リスクをもたらす優先順位の低い発見を見落としてしまうかもしれない。
プライバシーとデジタル主権
プライバシーとコンプライアンスに関する懸念は、特にクラウド推論が使用される場合、依然として深刻である。設定ファイル、独自のコードセグメント、環境の詳細などの入力データは、APIを介してサードパーティプロバイダに送信される可能性があり、国境を越えたデータ転送違反の恐れがある。多国籍企業は、LLMの統合による生産性の向上と、地域によって異なるコンプライアンス法の現実とのバランスを取る必要がある。
曖昧な説明責任
最後に、説明責任は未解決である。AI主導のテストが不注意で本番システムを混乱させたり、データ損失を引き起こしたりした場合、現在の法的状況では責任の帰属を明確にすることができず、組織は契約上、規制上、風評上のリスクにさらされることになる。
ペンリジェント:AIレッドチーム革命
ペンリジェント は、こうしたハードルの多くに特化した対応策として登場した。世界初の エージェントAIハッカー自然言語による指示を解釈し、複雑な目的を実行可能なサブタスクに分解し、200を超える業界標準のセキュリティツールの統合ライブラリから選択し、それらをインテリジェントに調整して、有効性が確認され、優先順位が付けられた脆弱性リストと修復ガイダンスを生成することにより、スタンドアロンスキャナや堅苦しい自動化スクリプトの役割を超える。
透明性はワークフローに組み込まれており、ユーザーは各推論ステップを観察し、どのツールが呼び出されたかを正確に確認し、ある結論が導き出された理由とその後に続くアクションを理解することができます。このデザインは信頼を高め、監査を容易にし、Penligentを単なるツールではなく、個人使用から企業展開までスケールアップするレッドチームの共同パートナーにします。NIST TEVVやOWASPのGenerative AI Red-Teamingガイドラインなどのフレームワークに沿ったコンプライアンスを意識したロジックを組み込むことで、自動化の可能性と規制された実践とのギャップを埋めている。
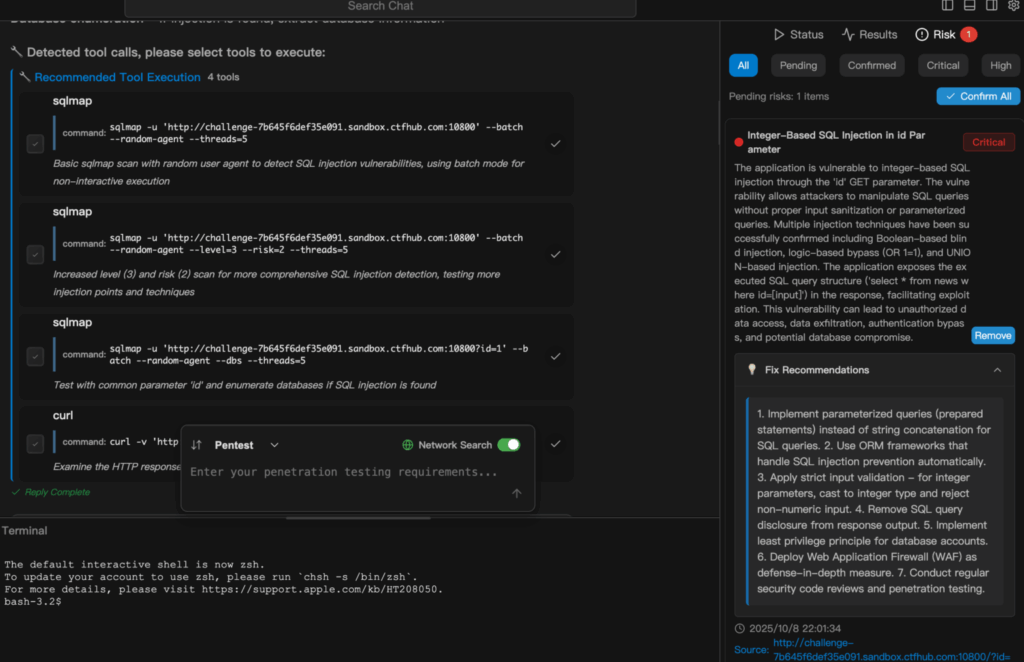
デモンストレーション例
以下の抜粋は、その概要を示している。 ペンリジェント は、単純な自然言語タスクから、完全に実行され、報告されるセキュリ ティ・テストへと移行します。以下は SQLインジェクションスキャン ペンリゲントにて。
結論
における能力の学術的検証から "侵入テストにおけるLLMの驚くべき有効性について" に具現化された運用の洗練化である。 ペンリジェントAIを活用した攻撃型セキュリティの軌跡は明らかだ。ツールは概念実証から量産可能なプラットフォームへと成熟しつつある。サイバーセキュリティの専門家、侵入テスト担当者、AIセキュリティ愛好家にとって、これは漸進的な改善というよりも、根本的なパラダイムの転換である。サイクルタイムを短縮し、参入障壁を下げ、透明性を強化し、コンプライアンスを最初から統合することによって、 ペンリジェント インテリジェント・オートメーションが、現代のビジネスが依存するシステムの防御とテストを、人間の専門家と非専門家の両方にどのように役立つかを例証している。
安定性と再現性を確保し、悪用を抑制し、プライバシーを守り、説明責任を確立する。適切な方法で実施されれば、AIを活用したペンテストは、競争上の優位性だけでなく、脅威がかつてない速さで進化する時代のセキュリティ態勢の基盤となる要素になるかもしれない。

