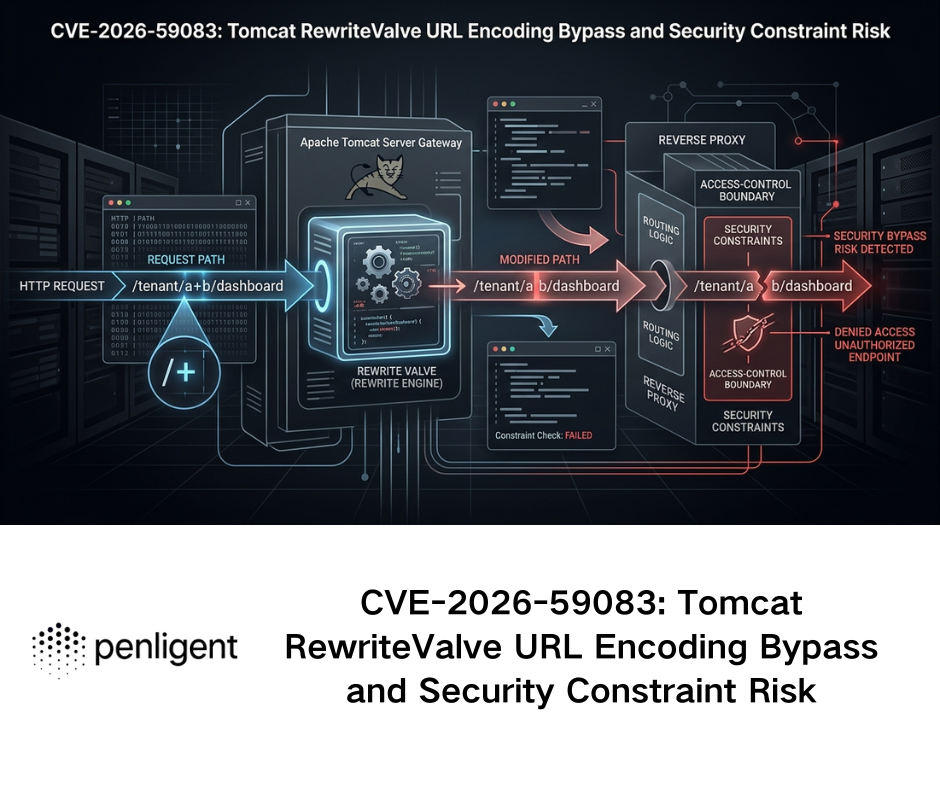
핵심 개념: 링크 분석의 의미론적 격차
최신 위협 헌팅의 맥락에서 보면 바이패스 링크 은 단순히 "숨겨진 URL"이 아닙니다. 이는 시맨틱 갭-보안 스캐너('관찰자')가 URI를 해석하는 방식과 피해자의 브라우저('실행자')가 렌더링하는 방식 간의 불일치입니다.
공격자는 이 틈새를 악용하여 보안 이메일 게이트웨이(SEG), 웹 콘텐츠 필터, 엔드포인트 탐지 및 대응(EDR) 시스템을 우회합니다. 목표는 자동화된 분석기에는 '양성 페이소스'를 표시하면서 최종 사용자에게는 '악성 페이로드'를 전달하는 것입니다.
고급 회피 방법론
1. 오픈 리디렉션을 통한 토지에서의 생활(LotL)
공격자들은 신뢰도가 높은 도메인(예: Google, Microsoft 또는 AWS)에서 '오픈 리디렉션'을 점점 더 많이 활용하고 있습니다.
- 기술: 다음과 같은 링크
https://www.google.com/url?q=https://malicious.example기본 도메인(google.com)는 전 세계적으로 허용 목록에 있습니다. - 바이패스: 필터는 신뢰할 수 있는 도메인을 확인하고 사용자의 브라우저는 피싱 사이트로 리디렉션을 실행합니다.
2. URL 클로킹 및 환경 키 설정
정교한 바이패스 링크 활용 서버 측 클로킹. 호스팅 서버는 수신 요청을 검사한 후 제공할 내용을 결정합니다.
- 봇/스캐너 탐지: 요청이 알려진 데이터 센터(AWS, Azure)에서 발생하거나 "보안 스캐너" 사용자 에이전트를 포함하는 경우 서버는 정상 "구성 중" 페이지와 함께 200 OK를 반환합니다.
- 타겟 배달: 요청이 사람의 프로필(거주지 IP, 특정 브라우저 언어, 유효한 마우스 움직임 원격 측정)과 일치하면 피싱 키트를 전달합니다.
3. 파서 차등 익스플로잇(RFC 3986 비준수)
다른 라이브러리(파이썬의 urllib, Go의 net/url, Chrome의 Blink)는 URL을 다르게 구문 분석합니다.
- CVE-2020-0696 예제: 공격자는 특정 문자 인코딩 또는 비표준 URI 스키마를 사용하여 브라우저가 다른 도메인으로 이동하는 동안 이메일 게이트웨이가 한 도메인을 '확인'하도록 만들 수 있습니다.
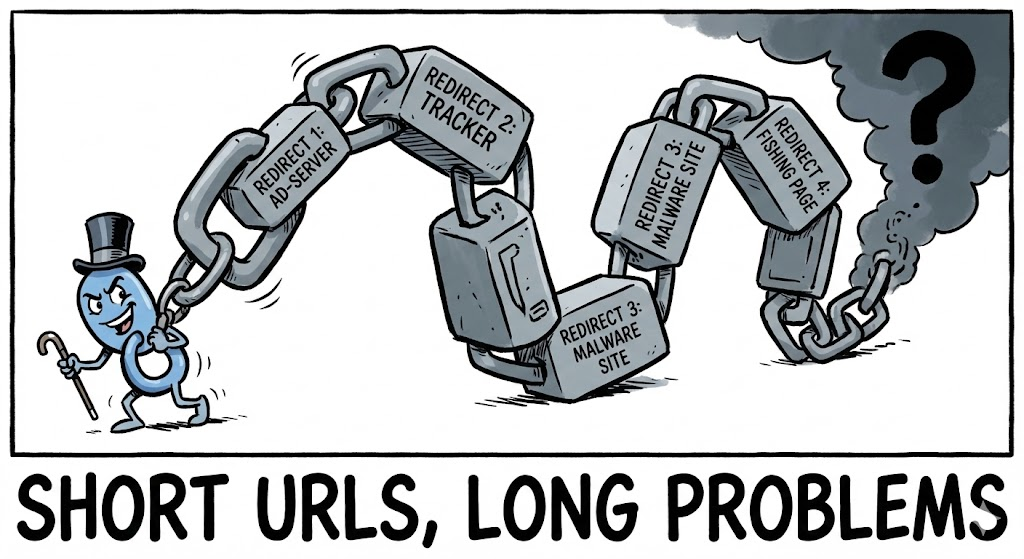
공격 및 방어: 엔지니어링 구현
예 1: 깊이 제한 스캐너 우회하기
많은 자동화된 스캐너는 리소스를 절약하기 위해 2~3개의 리디렉션만 수행합니다. 공격자는 여러 홉을 통해 링크를 '세탁'하는 방식으로 이를 악용합니다.
공격: 리디렉션 세탁소
일반 텍스트
홉 1: 신뢰할 수 있는 단축기(bit.ly) 홉 2: 손상된 워드프레스 사이트(wp-admin/redirect.php) 홉 3: 마케팅 추적 픽셀(ads.example.com) 홉 4: 최종 악성 랜딩 페이지
방어: 방어: 철저한 리디렉션 풀기(파이썬)
Python
`요청 가져오기
def unravel_link(url, max_hops=10): try: # 실제 브라우저를 모방하기 위해 사용자 정의 사용자 에이전트를 사용합니다. headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'} response = requests.get(url, headers=headers, allow_redirects=True, timeout=5)
홉_수 = len(response.history)
print(f"총 홉: {홉_수}")
for i, hop in enumerate(response.history):
print(f"Hop {i+1}: {hop.url} ({hop.status_code})")
if hop_count > 5:
반환 "경고: 고엔트로피 리디렉션 체인이 감지되었습니다(잠재적 세탁)"
응답.url 반환
예외를 e로 제외합니다:
반환 f"오류: {e}"`
예제 2: 조건부 클로킹 탐지
공격자는 다음 대상에게 다양한 콘텐츠를 제공합니다. curl (스캐너) 대 Chrome (사용자).
방어: 방어: 차등 대응 분석
Python
`def check_for_cloaking(url): # 프로필 1: 헤드리스/스캐너 r1 = requests.get(url, headers={'User-Agent': 'Security-Scanner/1.0'}) # 프로필 2: 실제 사용자 r2 = requests.get(url, headers={'User-Agent': 'Mozilla/5.0 Chrome/120.0.0.0'})
# 의미적 차이 측정(단순 길이 확인 또는 해시)
diff_ratio = abs(len(r1.text) - len(r2.text)) / max(len(r1.text), len(r2.text), 1)
if diff_ratio > 0.2: 페이지 콘텐츠의 차이 # 20%
반환 'CRITICAL: 조건부 논리(클로킹)가 감지되었습니다."
반환 "안정된 콘텐츠"`
예 3: 구문 분석기 불일치 방지(정규화)
공격자는 다음을 사용합니다. %2e%2e/ (인코딩된 점)을 사용하여 실제 액세스되는 경로에 대한 필터를 혼동할 수 있습니다.
방어: 공격적인 정규화 파이프라인
Python
`urllib.parse에서 urlparse 가져 오기, 따옴표 제거 가져 오기
def sanitize_and_canonicalize(url): # 1. Double Decode to catch nested encoding (%252e) decoded_url = unquote(unquote(url))
# 2. 경로 구문 분석 및 정규화
parsed = urlparse(decoded_url)
# os.path.normpath를 사용하여 /../ 세그먼트 해석하기
clean_path = os.path.normpath(parsed.path)
반환 f"{parsed.scheme}://{parsed.netloc}{clean_path}"
입력: https://example.com/login/..%2F..%2Fadmin
출력: https://example.com/admin`

전략적 방어 태세
| 방어 계층 | 메커니즘 | 엔지니어링 포커스 |
|---|---|---|
| 인그레스 필터링 | JA3/TLS 핑거프린팅 | 식별 클라이언트 라이브러리 (예: Python 요청)가 아닌 사용자 에이전트입니다. |
| 동적 분석 | 헤드리스 브라우저 폭발 | 샌드박스에서 링크를 실행하여 HTTP 헤더뿐만 아니라 DOM 변경 사항을 관찰하세요. |
| 로직 레이어 | 제로 트러스트 URL 서명 | 내부 바이패스 사용 사례의 경우 HMAC 서명 URL 를 사용하여 무결성을 보장합니다. |
| 사용자 계층 | 시각적 표시기 | 사용자가 클릭하기 전에 단축 URL을 '마스킹 해제'하는 브라우저 확장 프로그램을 배포하세요. |
결론 결론: 블랙리스트를 넘어서
정적 URL 블랙리스트의 시대는 끝났습니다. 공격자들이 임시, 조건부 및 다단계 바이패스 링크보안팀은 다음과 같은 방향으로 전환해야 합니다. 행동 링크 분석.
모든 URL을 통제된 환경에서 실행해야 하는 '프로그램'으로 취급하고(샌드박싱) 모든 입력을 정규화하여 '시맨틱 갭'을 좁힘으로써 조직은 사용자가 '여기를 클릭' 버튼을 보기도 전에 링크 기반 공격의 인프라를 해체할 수 있습니다.