OpenAI did not announce GPT-5.4-Cyber as a normal model launch. It announced it as part of an access model. That distinction matters more than the name of the model itself. On April 14, 2026, OpenAI said it was scaling Trusted Access for Cyber to thousands of verified individual defenders and hundreds of teams responsible for defending critical software, while also introducing GPT-5.4-Cyber, a GPT-5.4 variant fine-tuned to be cyber-permissive for defensive work. The company framed the move as preparation for more capable upcoming models and as part of a broader program built on democratized access, iterative deployment, and ecosystem resilience. (openai.com)
That makes GPT-5.4-Cyber important in a different way than a typical model release. The headline is not merely that OpenAI has a more security-capable model. The headline is that OpenAI is saying stronger cyber capability should not be deployed in the same way for every user, every environment, and every data-handling context. Some defenders will get reduced friction around dual-use safeguards on existing models. A narrower set of vetted users will be able to request a more permissive model tier. And OpenAI is being unusually explicit that visibility into the user, the environment, and the request context affects what access is possible. (openai.com)
That shift is easy to underestimate if you read the announcement as a product update. It is better understood as a security governance update with a model attached. OpenAI first introduced Trusted Access for Cyber in February 2026 as an identity and trust-based framework meant to expand access to frontier cyber capabilities while reducing misuse risk. In the same period, GPT-5.3-Codex became the first model OpenAI classified as high cybersecurity capability under its Preparedness Framework, which triggered additional safeguards such as safety training, automated monitoring, and rerouting or temporary restrictions for suspicious traffic. GPT-5.4-Cyber extends that story. It says the company now wants to lower refusal boundaries for legitimate cyber work, but only inside a more explicit trust and deployment regime. (openai.com)
For defenders, that is not a cosmetic change. It goes to the heart of what security work actually looks like in practice. Real security workflows are full of tasks that resemble malicious preparation if you only look at the text of the request. Reviewing a binary for exploitation potential, validating whether a vendor patch really closes an attack path, comparing compiled artifacts to source claims, drafting a safe proof-of-fix check, and interpreting a vulnerability advisory against your own environment are all legitimate security tasks. They are also exactly the kinds of tasks that generic safety filters can misread, because cybersecurity is a dual-use domain almost by definition. OpenAI now says that plainly in its own policy language. (openai.com)
OpenAI did not just launch GPT-5.4-Cyber
The easiest way to miss the significance of GPT-5.4-Cyber is to skip the timeline. In February 2026, OpenAI introduced Trusted Access for Cyber as a pilot. It described the program as an identity and trust-based framework designed to get enhanced cyber capabilities into the right hands, while also committing $10 million in API credits to accelerate cyber defense. The February post emphasized that frontier cyber-capable models can strengthen defense, but that restrictions designed to prevent malicious use have historically created friction for good-faith work. It also laid out the initial mechanics: individuals could verify identity through OpenAI’s cyber access flow, enterprises could request trusted access for teams, and some researchers could express interest in an even more permissive invite-only tier. (openai.com)
Two months later, the April announcement moved from pilot language to scaled deployment language. OpenAI said Trusted Access for Cyber was expanding to thousands of verified individual defenders and hundreds of teams. It also added tiers. All approved TAC customers would receive versions of existing models with reduced friction around safeguards that might trigger on dual-use cyber activity. Users willing to go further with authentication as legitimate cyber defenders could request additional tiers, including GPT-5.4-Cyber. That model was described as a GPT-5.4 variant purposely fine-tuned for additional cyber capabilities, with fewer capability restrictions and support for advanced defensive workflows including binary reverse engineering without source code. (openai.com)
That means OpenAI is now drawing at least three practical lines instead of one. There is baseline access to general models. There is trusted access to existing models with less accidental friction for legitimate security work. And there is a higher tier of more permissive, more specialized access for vetted defenders who can justify it. The structure is more important than the label. It turns “can the model answer this security question” into “who is asking, under what conditions, with what accountability, and from what kind of deployment context.” (openai.com)
The table below distills the difference between the February pilot and the April expansion as OpenAI described it in its official posts and developer documentation. (openai.com)
| 면적 | February 2026 position | April 2026 position |
|---|---|---|
| Program status | TAC introduced as a pilot | TAC expanded to thousands of individuals and hundreds of teams |
| Core framing | Identity and trust-based framework | Tiered access with broader rollout and higher-permission tiers |
| Model context | GPT-5.3-Codex launched as high cyber capability | GPT-5.4-Cyber introduced as a cyber-permissive GPT-5.4 variant |
| Defender benefit | Reduce friction for legitimate cyber work | Reduced-friction existing models plus access path to more permissive capabilities |
| Access mechanics | Identity verification for individuals, enterprise request path, invite-only interest for more permissive access | Same core mechanics, but expanded tiers and explicit request path for GPT-5.4-Cyber |
| Deployment stance | Pilot and calibration | Limited, iterative deployment for the most permissive cyber model |
The absence of public benchmark detail is also part of the story. OpenAI’s April announcement explains what GPT-5.4-Cyber is for and how it will be deployed, but it does not publish detailed public benchmark tables, calibration data, or a public matrix of evaluation results comparable to a full technical system card. That does not weaken the significance of the announcement. It changes the kind of significance it has. This is not a “look how high the benchmark climbed” post. It is a “we are willing to redraw access boundaries for legitimate cyber work, but only with stronger controls” post. (openai.com)
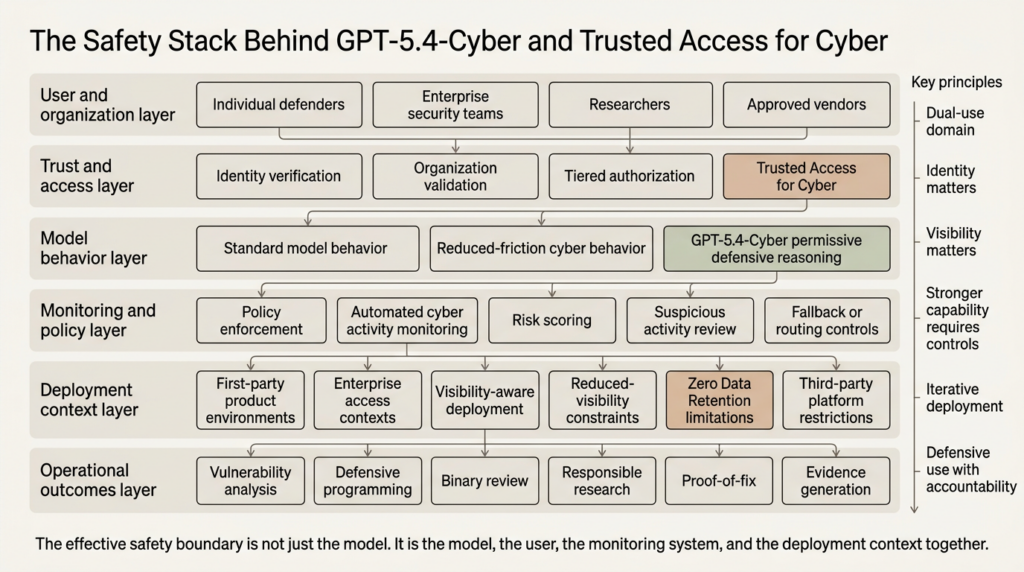
Trusted Access for Cyber is an access-control answer to a policy problem
Trusted Access for Cyber is easy to misread as a customer program. It is better understood as an access-control answer to a policy problem that generic model safeguards struggle to solve. OpenAI’s own example is simple and revealing: “find vulnerabilities in my code” can be part of responsible patching and coordinated disclosure, or it can be part of an effort to exploit a system. Restrictions intended to prevent harm have therefore created friction for good-faith work. That sentence is more than policy boilerplate. It is a direct admission that cybersecurity does not map neatly onto a clean allowed-versus-disallowed boundary when the platform only sees a textual request. (openai.com)
That ambiguity is the reason TAC exists. It lets OpenAI shift part of the decision boundary away from the prompt alone and toward user identity, organizational status, access tier, and deployment context. The question becomes not just “what is being asked,” but “who is asking, what are their trust signals, what kind of auditability exists, and how much visibility does OpenAI have into the surrounding environment.” Once you see TAC that way, it stops looking like an exception path for power users and starts looking like the core mechanism that makes stronger cyber capability deployable at all. (openai.com)
This is also why TAC matters beyond OpenAI. Security work produces many prompts that look suspicious when stripped of context. Reverse engineering a binary. Asking what a patch really changed. Asking whether a crash is likely exploitable. Drafting a lab-only validation sequence for a recently disclosed CVE. Mapping a vulnerable code path to probable detection opportunities. None of that is inherently malicious. All of it can be misread by a model safety system that only sees a cyber-shaped request and no other trust signal. TAC is OpenAI’s way of saying that policy enforcement in cybersecurity cannot live entirely inside a generic refusal layer. (openai.com)
The operational value of that becomes clearer when you look at the kinds of tasks defenders actually run every day. The table below is not a list of “offensive features.” It is a list of ordinary defensive jobs that are hard to do quickly and that generic safeguards often blur together with malicious activity. The point of TAC is to distinguish them without simply opening the floodgates. (openai.com)
| Defensive task | Why it can look suspicious to a generic safety system | Why trusted access helps |
|---|---|---|
| Reviewing code or binaries for vulnerabilities | It resembles exploit reconnaissance | Identity and context reduce accidental blocking |
| Interpreting a patch diff or vendor advisory | It resembles exploit development prep | Trusted users can do deeper analysis with fewer false refusals |
| Building a proof-of-fix check | It may resemble exploit scripting | The same action is defensive when scoped and validated |
| Drafting detection logic from exploit conditions | It requires discussing attack paths in detail | Better access reduces friction for blue-team engineering |
| Analyzing compiled software without source | It looks like reverse engineering for offensive use | Higher-tier reviewable access makes the defensive use case viable |
OpenAI is explicit that trusted access does not suspend policy. Users with trusted access still have to comply with usage policies and terms. The program is designed to reduce friction for defenders while still preventing prohibited behavior including data exfiltration, malware creation or deployment, and destructive or unauthorized testing. That combination matters. OpenAI is not claiming the cyber domain can be safely handled by better intent classification alone. It is claiming that cyber needs a different control surface, one that can preserve prohibition while being less brittle for legitimate work. (openai.com)
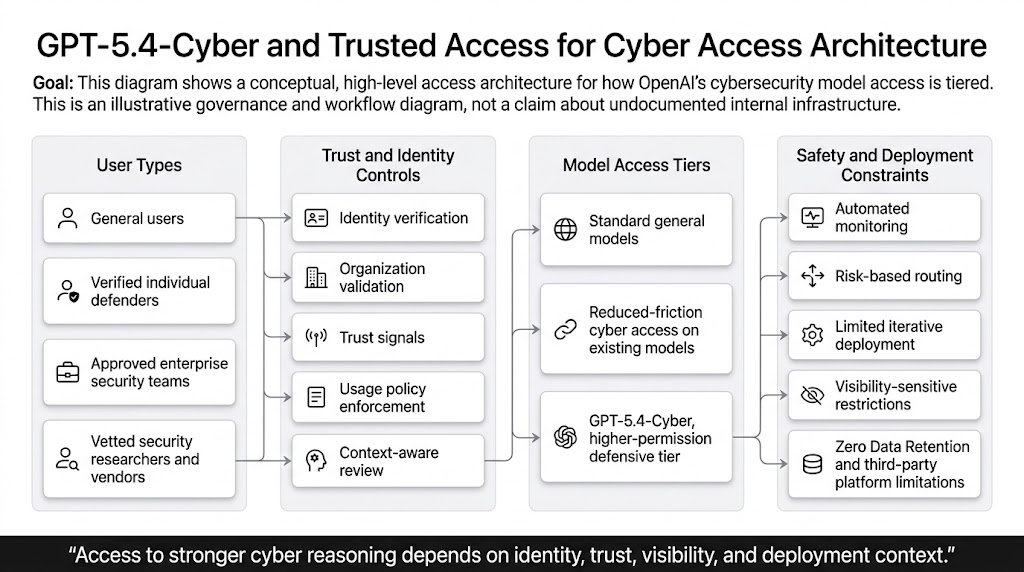
GPT-5.4-Cyber lowers the refusal boundary for legitimate cyber work
The key phrase in OpenAI’s April post is not just that GPT-5.4-Cyber is “cyber-permissive.” The more precise phrase is that it lowers the refusal boundary for legitimate cybersecurity work. That is a stronger and more useful description. It implies the value is not merely more knowledge. It is the ability to continue reasoning through tasks that generic safeguards might stop too early. In practice, that could mean fewer interruptions when analyzing exploit preconditions, fewer false refusals in responsible vulnerability research, and better support for the gray-zone tasks that sit between vendor advisory reading and destructive exploitation. (openai.com)
OpenAI also adds something more concrete: binary reverse engineering. The company says GPT-5.4-Cyber is meant to enable advanced defensive workflows that include analyzing compiled software for malware potential, vulnerabilities, and security robustness without source code. That is one of the most important lines in the entire announcement. Source-only reasoning has always left a large gap between model assistance and real security work. A great many security questions arise in closed-source contexts, in shipped binaries, in patched artifacts, in drivers, in libraries pulled from supply chains, and in software where the version in production is not the version sitting in a public repository. By naming binary reverse engineering explicitly, OpenAI is signaling that it knows where a meaningful part of real defensive work happens. (openai.com)
This is also where the model’s deployment posture matters. OpenAI says GPT-5.4-Cyber is more permissive, and because of that it will start with a limited, iterative deployment to vetted security vendors, organizations, and researchers. That is not just a safety caveat. It is a clue about how OpenAI now sees the risk profile. A more permissive cyber model is not being treated like a mainstream convenience feature. It is being treated like a capability that needs stronger surrounding controls. The company also says that permissive and cyber-capable models may come with limitations, especially around no-visibility uses such as Zero Data Retention and third-party platforms where OpenAI has less direct visibility into the user, environment, or request purpose. (openai.com)
That, in turn, changes how security teams should read the announcement. The question is not only whether GPT-5.4-Cyber is technically stronger. The question is what work becomes newly practical when the refusal boundary moves and when the platform is willing to attach that movement to verified identity and context. Security engineers already know the pain of half-finished assistance: a model that will summarize an advisory but not reason through lab-safe validation steps; a model that will explain a disassembly fragment but stop short of comparing likely exploit conditions; a model that can talk about secure coding but balk at the exact wording needed for responsible patch analysis. OpenAI is implicitly saying it wants to reduce those breaks, but only for defenders it is prepared to trust more deeply. (openai.com)
There is another subtle point here. OpenAI is not presenting GPT-5.4-Cyber as proof that it has solved cyber risk. The April announcement says the current class of safeguards is believed to be sufficient to support broad deployment of current models, and likely versions of those safeguards will be sufficient for upcoming more powerful models, but models explicitly trained and made more permissive for cybersecurity work require more restrictive deployments and appropriate controls. That is a careful sentence. It says stronger cyber alignment does not reduce the need for deployment controls. It increases it. (openai.com)
GPT-5.4-Cyber and Trusted Access for Cyber point to a new safety stack
The most valuable sentence OpenAI published on this topic may not be in the cyber post at all. In its April 2025 Preparedness Framework update, the company said that as models become more capable, safety will increasingly depend on having the right real-world safeguards in place. That sentence is the conceptual bridge between general frontier safety language and the mechanics of Trusted Access for Cyber. It is also the clearest explanation for why OpenAI’s cyber strategy now looks less like content moderation and more like deployment engineering. (openai.com)
You can already see that transition in how GPT-5.3-Codex is handled. OpenAI’s developer documentation says GPT-5.3-Codex is the first model treated as high cybersecurity capability under the Preparedness Framework. The safeguards include training the model to refuse clearly malicious requests such as stealing credentials, plus automated classifier-based monitoring that detects suspicious cyber activity and routes high-risk traffic to a less cyber-capable model, GPT-5.2. The API documentation adds that if suspicious activity exceeds thresholds, access may be temporarily limited while activity is reviewed, and that because the system is still being calibrated, legitimate security research or defensive work may occasionally be flagged. (developers.openai.com)
That is already a layered stack. Model behavior is one layer. Automated monitoring is another. Fallback routing or temporary limitation is another. Trusted access is another. Threat intelligence and enforcement pipelines add another. GPT-5.4-Cyber extends the same idea upward: if you want a more permissive model for legitimate cyber work, you do not simply tweak the model and call it done. You bind the model to stronger assumptions about who is using it, under what conditions, with how much visibility, and with what recourse if the platform sees elevated risk. (openai.com)
Zero Data Retention makes that design logic especially visible. OpenAI’s data controls documentation says Zero Data Retention excludes customer content from abuse monitoring logs and forces certain storage settings off. In other words, ZDR narrows platform visibility into the very data streams a provider would otherwise use for abuse monitoring. That is why OpenAI’s April cyber announcement specifically calls out no-visibility uses such as ZDR as a place where permissive cyber-capable models may face limitations. If the provider cannot see enough to run its safety pipeline, then trust must be established through other means or the allowed capability set has to shrink. (developers.openai.com)
This is where many public discussions of AI safety in cyber become too abstract. The practical issue is not merely whether a model “knows offensive security.” The practical issue is whether the deployment context gives the provider enough confidence to let the model complete the kinds of reasoning legitimate defenders need. That is why the combination of GPT-5.4-Cyber and TAC matters more than either one alone. It suggests that for frontier cyber models, the safety boundary is becoming a combined property of model behavior, identity assurance, monitoring, data visibility, and product environment. (openai.com)
The table below captures that shift more clearly than most public summaries do. (developers.openai.com)
| Access context | Identity signal | Platform visibility | Likely cyber friction | Practical implication |
|---|---|---|---|---|
| Standard access to general models | Low to moderate | Standard product visibility | Higher for dual-use security prompts | Useful for general analysis, limited for deep cyber workflows |
| Trusted Access for Cyber on existing models | Verified or enterprise-backed | Better alignment between user and platform context | Lower accidental friction on legitimate research | Better fit for vulnerability research, education, defensive programming |
| Highest trusted tiers including GPT-5.4-Cyber | Stronger defender authentication and vetting | Important to OpenAI’s safety posture | Lower refusal boundary, more permissive cyber reasoning | Best suited for advanced defensive workflows such as binary reverse engineering |
| No-visibility contexts such as ZDR or indirect third-party use | Varies | Reduced direct visibility | More likely to face restrictions | Stronger model access may not be available or may be constrained |
This is not just OpenAI-specific product design. It is probably a preview of how serious cyber-capable frontier models will be deployed more broadly. The old instinct was to ask whether the model could answer a sensitive question. The newer and better question is whether the model, the user, the monitoring system, and the deployment environment together create a context in which that answer can be allowed. (openai.com)
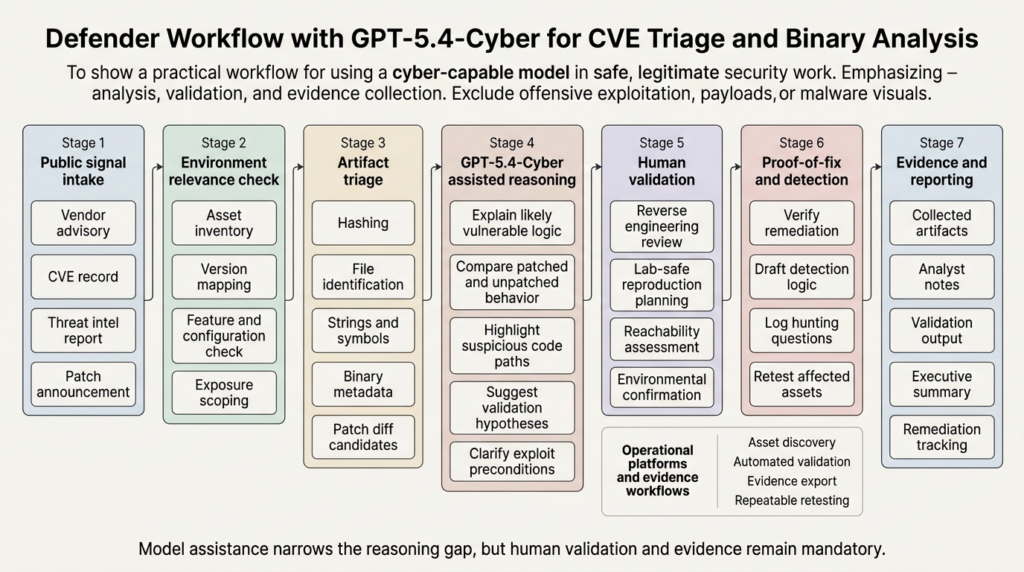
GPT-5.3-Codex shows how OpenAI now classifies high cyber capability
GPT-5.4-Cyber makes more sense when you look at what OpenAI already decided about GPT-5.3-Codex. In February 2026, OpenAI said GPT-5.3-Codex was the first model it classified as high capability for cybersecurity-related tasks under the Preparedness Framework and the first it directly trained to identify software vulnerabilities. Importantly, the company also said it did not have definitive evidence the model could automate cyberattacks end to end, but it was taking a precautionary approach anyway and deploying its most comprehensive cybersecurity safety stack to date. (openai.com)
That framing is easy to miss, but it matters. OpenAI did not say, “we proved the model can fully automate offensive operations.” It said, in effect, “we cannot rule out enough of the relevant risk, so we are activating a stronger safety stack.” That is a useful precedent for understanding GPT-5.4-Cyber. The company does not need to publicly claim full offensive automation to justify more restrictive deployment for a more permissive cyber model. It only needs enough evidence that the cyber capability frontier is moving and that safer deployment now depends on controls beyond generic model training. (openai.com)
The developers documentation around GPT-5.3-Codex also helps explain why legitimate defenders sometimes run into friction even when acting responsibly. OpenAI says automated classifiers detect suspicious cyber activity and may reroute traffic to GPT-5.2 or temporarily limit API access while activity is reviewed. It also says only a very small portion of traffic is expected to be affected and that the system is being refined. The important part is not the exact share of traffic. The important part is that OpenAI recognizes a calibration problem: the platform needs to preserve real defensive use while slowing misuse, but it cannot perfectly infer intent from every request. Trusted Access for Cyber is a structural response to that calibration problem. (developers.openai.com)
OpenAI’s language around broader ecosystem resilience also reinforces the point. In the April cyber post, it says Codex Security automatically monitors codebases, validates issues, and proposes fixes, and that since its recent launch it has contributed to over 3,000 critical and high fixed vulnerabilities. Whether or not one agrees with every implication of that framing, OpenAI is clearly moving toward a world where cyber-capable models are expected to live inside systems that monitor, validate, and help remediate, not just answer questions. That matters because GPT-5.4-Cyber’s most credible role is not as a free-floating reverse engineering oracle. Its most credible role is as a reasoning engine inside accountable defensive workflows. (openai.com)
This is also where defenders should resist a common simplification. GPT-5.4-Cyber is not the same thing as “OpenAI is going offensive.” The public material does not support that reading. OpenAI’s framing is consistently defensive: security education, defensive programming, responsible vulnerability research, binary analysis for malware potential and robustness, codebase validation, and ecosystem resilience. The reason the access regime gets stricter is not because the company is abandoning that defensive framing. It is because the same reasoning that helps defenders can too easily be repurposed by attackers if deployed without stronger controls. (openai.com)
GPT-5.4-Cyber makes binary reverse engineering a first-class defensive task
The most concrete technical signal in the April announcement is binary reverse engineering. That is a valuable choice because it anchors the conversation in the work defenders actually struggle to speed up. Source code is not the whole job. A meaningful portion of incident response, vulnerability research, malware triage, patch analysis, and supply-chain validation happens with compiled artifacts. Sometimes that is because the software is closed source. Sometimes it is because the production build contains optimizations or changes that are not obvious from the repository. Sometimes the defender needs to know whether a vendor’s “fixed” build really removed the vulnerable behavior. Sometimes the only thing available in time is a package, a library, or a suspicious executable. (openai.com)
A model that can help on compiled software without source code is useful for reasons that have nothing to do with glamour. It can shorten the path from artifact to hypothesis. It can help identify which functions or imported libraries deserve attention. It can explain what a strange branch sequence or memory-handling pattern probably does. It can help compare two disassemblies in terms that are closer to security reasoning than raw instruction listings. It can propose what additional evidence is needed before a team should decide something is a real exploit path instead of a noisy anomaly. In defensive work, those time savings are often worth more than the ability to produce a polished answer. (openai.com)
That said, binary reverse engineering is also where hype can outrun proof. A model helping you recover a plausible semantic view of a stripped binary is not the same thing as proving exploitability, proving reachability in a real deployment, or proving a vendor advisory is incomplete. Penligent’s own March 2026 discussion of binary proof makes this distinction well: recovering a stripped binary into a representation useful enough for bug hunting is real progress, but outside readers should not flatten exploitability framing, vendor advisory language, and public vulnerability descriptions into one neat sentence. That caution is exactly right here. GPT-5.4-Cyber would be most valuable if it narrows the analysis gap. It does not make evidentiary standards disappear. (penligent.ai)
The right way to use a model in binary reverse engineering is to treat it as part of a disciplined triage loop. Start with artifact identity and provenance. Record hashes. Identify the exact build, architecture, and linked libraries. Extract strings, imports, symbols if available, and basic control-flow hints. Compare old and new builds when a patch exists. Use the model to reason about what changed, what likely matters, and which hypotheses deserve manual validation. Then verify those hypotheses with your normal toolchain and lab discipline. That keeps the model in the lane where it is genuinely useful. (openai.com)
A non-destructive first-pass workflow can look like this:
#!/usr/bin/env bash
set -euo pipefail
BIN="${1:?usage: triage.sh /path/to/binary}"
echo "[*] Basic identity"
sha256sum "$BIN"
file "$BIN"
echo
echo "[*] ELF or Mach-O headers and linked libraries"
readelf -h "$BIN" 2>/dev/null || true
readelf -d "$BIN" 2>/dev/null || true
otool -L "$BIN" 2>/dev/null || true
echo
echo "[*] Exported and imported symbols"
readelf -Ws "$BIN" 2>/dev/null | head -n 120 || true
nm -D "$BIN" 2>/dev/null | head -n 120 || true
echo
echo "[*] Strings that often help with provenance and functionality"
strings -a "$BIN" | grep -Ei 'version|debug|error|http|ssl|crypto|auth|token|exec|system|shell' | head -n 120 || true
echo
echo "[*] Small disassembly slices for manual review"
objdump -d -M intel "$BIN" 2>/dev/null | head -n 200 || true
rabin2 -I "$BIN" 2>/dev/null || true
Nothing in that workflow attempts exploitation. It preserves evidence, identifies context, and produces a body of material that a human analyst and a cyber-capable model can discuss in meaningful terms. On a patched-versus-unpatched pair of artifacts, the next step is usually not “write an exploit.” It is “which code paths changed, what preconditions appear to matter, what trust boundary moved, what input handling logic got tightened, and what should we verify in our own environment.” That is exactly the kind of reasoning a model with a lower refusal boundary for legitimate cyber work should be better at supporting. (openai.com)
Trusted Access for Cyber becomes clearer when you map it to real CVEs
Public discussions of frontier cyber models often drift into abstractions about offense and defense. Real value becomes much easier to judge when you anchor the model against actual vulnerability cases. Three cases are especially useful here because they map cleanly to three defensive jobs: artifact validation, environment-specific exposure confirmation, and emergency advisory triage. Those cases are CVE-2024-3094 in XZ Utils, CVE-2024-4577 in PHP-CGI on Windows, and CVE-2024-3400 in Palo Alto Networks PAN-OS. (nvd.nist.gov)
CVE-2024-3094 is the supply-chain and artifact-analysis case. NVD says malicious code was discovered in upstream XZ tarballs beginning with 5.6.0 and explains that the build process extracted a prebuilt object file from disguised test data to modify liblzma behavior. Andres Freund’s Openwall disclosure likewise makes clear that the compromise was in the upstream repository and tarballs, discovered after odd CPU usage and valgrind errors around SSH logins on Debian sid systems. This is the kind of incident that punishes source-only thinking. You need artifact awareness, build-process suspicion, and an ability to reason about what a compiled or packaged result is actually doing. (nvd.nist.gov)
CVE-2024-4577 is the environment-sensitive validation case. NVD says the issue affects Windows-based Apache and PHP-CGI setups under certain code-page conditions, where Windows Best-Fit behavior can cause PHP-CGI to misinterpret characters as PHP options, opening the door to source disclosure or arbitrary PHP code execution. The Canadian Centre for Cyber Security later warned of mass exploitation and advised upgrading to PHP 8.1.29, 8.2.20, or 8.3.8 and later. This is exactly the kind of CVE where a team needs more than a summary. It needs environment awareness. Are we using PHP-CGI on Windows? Which code pages apply? Where are the binaries actually installed? Are we patched, and if we are patched, can we confirm the effective build and the surrounding config? (nvd.nist.gov)
CVE-2024-3400 is the emergency edge-exposure case. NVD describes it as a command injection vulnerability in the GlobalProtect feature of PAN-OS that can allow an unauthenticated attacker to execute arbitrary code with root privileges on affected firewalls under specific version and configuration conditions. Unit 42’s threat brief says the issue affected PAN-OS 10.2, 11.0, and 11.1 devices configured with GlobalProtect gateway or portal and notes tracking of related post-exploitation activity. This is the kind of case where security teams need rapid triage under pressure: which assets are exposed, which configurations actually meet the vulnerable preconditions, what logs should be hunted, how urgent is containment, and how do we distinguish hype from relevant impact on our own estate. (nvd.nist.gov)
The table below shows why these three cases are useful for evaluating GPT-5.4-Cyber style capability from a defender’s point of view. (nvd.nist.gov)
| CVE | What made it hard | Why a cyber-permissive model helps defenders | What still requires human proof |
|---|---|---|---|
| CVE-2024-3094 | Artifact-level supply-chain compromise with obfuscated build behavior | Helps connect tarball, object extraction, build logic, and binary behavior into a coherent hypothesis | Provenance validation, build reproduction, scope confirmation, incident response decisions |
| CVE-2024-4577 | Vulnerability depends on Windows, PHP-CGI mode, and code-page behavior | Helps translate advisory language into concrete asset and config checks | Exact environment confirmation, patch deployment, safe validation in lab |
| CVE-2024-3400 | Urgent edge exposure with product-specific version and feature preconditions | Helps turn advisory language into prioritization, triage steps, and hunting questions | Vendor-guided remediation, log review, containment, enterprise change control |
These are not cherry-picked because they are dramatic. They are useful because they reveal where model help is actually valuable. It is valuable where the problem is interpretive, conditional, and evidence-seeking. It is less valuable where the hard part is organizational coordination, legal scope, emergency change management, or proving exploitability beyond reasonable doubt. GPT-5.4-Cyber should be judged against that boundary, not against fantasies of one-shot autonomous offense. (openai.com)
GPT-5.4-Cyber and CVE-2024-3094 show why artifact analysis matters
The XZ incident remains one of the clearest recent examples of why binary and artifact reasoning is not an optional extra in modern defense. NVD describes the issue as malicious code in upstream tarballs starting with version 5.6.0, where a complex build process extracted a prebuilt object file from disguised test data and used it to modify functions in liblzma. Andres Freund’s disclosure explains that the path to discovery began with small, odd symptoms: SSH logins taking more CPU than expected and valgrind errors that did not make sense. He then concluded the upstream XZ repository and tarballs had been backdoored. Red Hat later summarized the event as a compromise that could have enabled silent unauthorized access to affected systems. (nvd.nist.gov)
Why does this matter for GPT-5.4-Cyber? Because the incident is the opposite of a clean source-level bug hunt. Defenders needed to reason across releases, tarballs, build artifacts, linked behavior, packaging differences, and system effects. A model that only excels at reading obvious source code changes is not enough. A model that can help map an obfuscated artifact story into a defensible hypothesis about runtime behavior is much closer to the real work. That does not mean the model should be trusted blindly. It means the model becomes useful earlier, when the team is still trying to understand what deserves urgent manual attention. (openai.com)
For defenders, the XZ lesson is not “use AI to reverse engineer everything.” The lesson is that artifact validation must sit closer to the center of security practice than many teams assume. If an incident can hide in release packaging or build-stage manipulation, then a modern defensive workflow needs ways to reason about what shipped, not just what was committed. That makes GPT-5.4-Cyber’s binary analysis positioning more credible than a generic cyber-marketing line. It is tied to a real class of defensive pain. (openai.com)
A practical, non-destructive defender workflow for this kind of case starts with inventory and provenance. Which systems have the affected version installed. Which packages came from which channels. Whether the installed library hashes match known-bad or known-good references. Whether build metadata or strings indicate a suspicious origin. Whether the library is actually loaded in processes that matter. Whether behavioral symptoms match the public descriptions closely enough to justify incident escalation. A model can help structure those questions and synthesize findings. It cannot substitute for the chain of evidence. (nvd.nist.gov)
That distinction becomes important in reporting. The wrong way to handle an XZ-like case is to let a model collapse “artifact looks suspicious,” “public write-up suggests compromise,” and “we proved active exploitability in our fleet” into one conclusion. The right way is to maintain levels of confidence and keep the model attached to the evidence available. When a cyber-capable model is used well, it helps defenders ask sharper questions sooner. That is enough to create a lot of value. (penligent.ai)
GPT-5.4-Cyber and CVE-2024-4577 show where environment context matters more than rhetoric
CVE-2024-4577 is a good test of whether a security assistant can move from public description to real operational help. NVD describes the issue precisely: in PHP 8.1 before 8.1.29, 8.2 before 8.2.20, and 8.3 before 8.3.8, when using Apache and PHP-CGI on Windows under certain code pages, Windows Best-Fit behavior can cause PHP-CGI to misinterpret characters as PHP options, potentially exposing source or enabling arbitrary PHP code execution. Later, the Canadian Centre for Cyber Security warned of mass exploitation and advised organizations to verify whether they were running vulnerable PHP on Windows and to update to the patched releases. CISA’s Known Exploited Vulnerabilities catalog also lists the issue. (nvd.nist.gov)
This is the kind of vulnerability where shallow assistance is not enough. A generic assistant can repeat the version numbers. A more useful cyber assistant needs to help answer the questions defenders actually ask. Are we using CGI mode anywhere, or only FPM and modules. Are there legacy Windows hosts with XAMPP or bundled PHP that our asset inventory misses. Are there regional deployments with relevant locale settings. Did patching happen through the standard package channel, or did someone manually replace a binary on disk. Do our web logs and process trees show anything consistent with attempted abuse. That is a very different quality bar from “summarize the advisory.” (nvd.nist.gov)
A safe first step in internal validation is boring on purpose. It should identify the effective PHP-CGI binaries, capture version information, preserve evidence, and map the surrounding web-server configuration. That can be done without reproducing the flaw on production systems. For Windows estates, even basic inventory often uncovers surprises, especially where old application bundles or vendor-maintained components still carry their own PHP runtimes. A model that can read the advisory, understand why CGI mode and Windows code-page behavior matter, and turn that into a concrete audit plan is far more useful than one that simply explains the vulnerability in prose. (nvd.nist.gov)
A minimal example of a version-audit step might look like this:
$targets = Get-ChildItem -Path C:\ -Filter php-cgi.exe -Recurse -ErrorAction SilentlyContinue
foreach ($bin in $targets) {
Write-Host "-----"
Write-Host "Path:" $bin.FullName
try {
& $bin.FullName -v
} catch {
Write-Host "Version execution failed"
}
$bin.VersionInfo | Select-Object FileVersion, ProductVersion, CompanyName
}
That script does not test exploitability. It does something more important at the start of an incident: it turns vague fleet assumptions into a list of concrete binaries and effective versions. From there, defenders can map hosts to web-server roles, check whether CGI mode is actually in use, verify locale and code-page conditions in a lab, and decide whether emergency remediation is needed. That is exactly where a cyber-capable model with a lower refusal boundary could earn its keep: connecting public advisory language to internal asset reality and to safe validation steps. (nvd.nist.gov)
There is another reason CVE-2024-4577 is a useful benchmark. It is a reminder that “known exploited” status and “theoretical vulnerability description” are not the same thing. Once a vulnerability is actively exploited, the defender’s job changes. Response time gets shorter, proof-of-fix matters more, and the cost of misreading preconditions goes up. A model that can keep those distinctions straight is more valuable than one that simply sounds smart. GPT-5.4-Cyber will be worth paying attention to if it improves that quality of reasoning, not if it merely writes more confident summaries. (CISA)
GPT-5.4-Cyber and CVE-2024-3400 show the value of fast triage under pressure
CVE-2024-3400 is the kind of vulnerability that forces security teams to think in hours, not days. NVD describes it as a command injection vulnerability caused by arbitrary file creation in the GlobalProtect feature of PAN-OS, potentially allowing unauthenticated code execution with root privileges on affected devices. Unit 42 said the issue applied to PAN-OS 10.2, 11.0, and 11.1 devices configured with GlobalProtect gateway or portal, and that Cloud NGFW, Panorama appliances, and Prisma Access were not affected. The same Unit 42 brief tracked related post-exploitation activity and documented available protections and hunting steps. CISA’s catalog also lists CVE-2024-3400 as a known exploited vulnerability. (nvd.nist.gov)
This is exactly the kind of case where defenders do not need a model to invent anything exotic. They need it to compress time. A team under pressure needs to know which devices fall within the affected version range, which ones actually have the vulnerable feature configuration, whether compensating protections are already in place, whether any telemetry suggests post-exploitation, and how to prioritize remediation if maintenance windows are tight. A capable model can help by converting a fast-moving vendor brief into a structured decision path. That is not glamorous, but in incident handling it is often the most valuable form of assistance. (Unit 42)
The defensive use case here is also a good rebuttal to a common misconception. People sometimes imagine that a more cyber-capable model becomes valuable only when it can fully automate exploitation. That misses the operational bottleneck. In cases like CVE-2024-3400, the biggest bottleneck is often understanding relevance and urgency under uncertainty. Which hosts matter. Which preconditions apply. Which facts come from the vendor, which come from third-party reports, which are already observed in the wild, and which remain hypothetical for your own deployment. A model that can reliably keep those layers separate is already highly useful. (Unit 42)
This is also where OpenAI’s deployment logic around trust and visibility starts to look practical rather than abstract. Deep triage of a known exploited edge device vulnerability requires discussing exploitation conditions, configuration state, control failures, detection opportunities, and sometimes lab-safe reproduction logic. Generic cyber safeguards can easily overreact to that class of prompt. Trusted Access for Cyber is OpenAI’s way of saying that legitimate defenders should not be forced to fight the model when dealing with exactly the issues that most urgently require careful reasoning. (openai.com)
At the same time, CVE-2024-3400 shows why human review does not go away. A model can help structure the problem, compare vendor and NVD language, draft the right questions for operations teams, and even help propose hunting priorities. It still cannot decide for the organization whether a given firewall can be taken out of service, whether a compensating control is enough for the business risk, or whether a possibly exposed edge device requires full incident response treatment. GPT-5.4-Cyber, if it is good, should accelerate those decisions. It should not pretend to replace them. (Unit 42)
GPT-5.4-Cyber still does not remove the hard parts of security work
The danger in any discussion of a more permissive cyber model is that people start to flatten all difficulty into “can the model do it.” Security work does not fail only because analysts lack reasoning throughput. It fails because evidence is incomplete, environments are messy, advisories are sometimes underspecified, organizational scope is constrained, and the difference between “interesting” and “operationally relevant” can be huge. A model that can push farther into legitimate cyber reasoning is genuinely valuable. A model that encourages teams to forget the difference between a strong hypothesis and a proven finding is dangerous. (openai.com)
Several failure modes are worth naming plainly. One is over-reading public language. NVD entries, vendor advisories, third-party write-ups, and exploit rumors are not interchangeable. Another is false certainty around binaries. A stripped binary that appears suspicious is not automatically exploitable. A patch diff that looks security-relevant may not map to the real trust boundary you care about. A third is environmental blindness. Many vulnerabilities depend on feature configuration, platform specifics, locale, build flags, or product packaging details that a model cannot infer unless the team provides them. A fourth is governance blindness. Even a highly capable defender-facing model does not authorize testing beyond scope, destructive validation, or sloppy handling of sensitive data. (nvd.nist.gov)
That is also where operational platforms become more important than chat transcripts. Once a team moves from “the model thinks this might matter” to “we need to test, retest, preserve evidence, and show proof-of-fix,” the real problem becomes workflow control. Penligent’s public materials describe an end-to-end process that starts with asset discovery and attack-surface mapping and extends through validation, exploit reproduction with evidence-chain reporting, and exportable reports. That shape is useful not because it replaces analyst judgment, but because it turns a reasoning result into a repeatable test path with artifacts that can survive review. In practice, that is exactly the gap many teams hit after the first smart answer. (penligent.ai)
The same logic applies to proof-of-fix. A one-off explanation of a CVE is helpful. A repeatable validation routine is much more valuable. Product pages that emphasize evidence export, attack-surface mapping, and one-click exploit reproduction with reporting are pointing at the operational side of the problem, not just the reasoning side. If GPT-5.4-Cyber helps teams get to the right hypothesis faster, then platforms that can run the validation loop, keep the evidence together, and support retesting after remediation become more important, not less. (penligent.ai)
This is one reason the future of AI defense will probably reward teams that think in systems rather than prompts. The scarce resource will not simply be access to a strong model. It will be access to a strong model inside a workflow that can preserve scope, record assumptions, capture artifacts, separate hypotheses from confirmed findings, and survive audit or disclosure. GPT-5.4-Cyber makes that future easier to imagine because OpenAI is now explicitly designing around deployment context, not only around model behavior. (openai.com)
Trusted Access for Cyber changes what security buyers should ask
Security buyers evaluating frontier AI for defensive work should take a lesson from OpenAI’s design rather than focusing only on the brand name of the model. The right procurement questions are not just about capability. They are about access control and evidentiary fit. Who in the organization can use the model for high-risk cyber tasks. How identity is verified. What happens when legitimate work is misclassified. Whether the deployment context supports the provider’s monitoring and safety pipeline. What restrictions apply under Zero Data Retention or indirect platform access. Whether the provider can support evidence-heavy workflows instead of only natural-language interaction. OpenAI’s own decisions strongly suggest these questions are now part of the product, not peripheral legal details. (openai.com)
That matters because a lot of the public conversation around cyber-capable models still sounds like a benchmark race. In practice, the differentiator may be trusted deployment context. A model that is technically strong but unusable for legitimate reverse engineering, responsible vulnerability research, or proof-of-fix generation because the safety stack constantly overfires is less valuable than a slightly narrower model inside a well-governed trust regime. OpenAI is signaling that it understands this tradeoff. It is willing to make more permissive cyber capability available, but only alongside stronger identity, visibility, and tiering assumptions. (openai.com)
There is a broader market implication here as well. If more providers follow the same path, the future competition in AI for cybersecurity may not revolve around who can claim the most dramatic offensive benchmark. It may revolve around who can safely make the most useful defensive reasoning available to real teams, with enough context to reduce false refusals and enough governance to reduce abuse. That is a different market from “best coding model” or “best chatbot.” It is closer to an access-regulated security product category. (openai.com)
For red teams, pentesters, and research groups, that means getting value from frontier cyber models may increasingly require proving you are the kind of user the provider wants to trust. For enterprises, it means the best deployment may not always be the most private or the most indirect one, if those choices also reduce the visibility needed to unlock higher cyber-capability tiers. For both groups, it means the old assumption that access is a commodity is probably ending. In the frontier cyber domain, access is becoming part of the security design. (openai.com)
GPT-5.4-Cyber, Trusted Access for Cyber, and the real boundary between help and proof
The most honest way to read OpenAI’s announcement is this: the company is acknowledging that better cyber assistance is not only a model problem. It is a deployment problem. GPT-5.4-Cyber exists because generic refusal behavior creates too much drag on legitimate security work. Trusted Access for Cyber exists because lowering refusal boundaries without identity, monitoring, and deployment controls would be reckless. Preparedness and developer safeguards exist because the provider expects cyber capability to keep rising and knows a pure “answer or refuse” model will not be enough. (openai.com)
That is why GPT-5.4-Cyber deserves attention from serious defenders. Not because it proves autonomous offense is solved. Not because OpenAI published a dramatic benchmark chart. It deserves attention because it puts binary reverse engineering, responsible vulnerability research, and other high-value defensive tasks inside a more realistic access model. It says, in effect, that the next stage of AI in security will not be governed only by what the model knows. It will be governed by who gets to use that knowledge, under what trust signals, with what visibility, and inside what operational workflow. (openai.com)
For defenders, that is the right question to focus on now. The most important frontier may not be raw capability. It may be the quality of the boundary between legitimate help and accountable proof. Models can narrow the reasoning gap. Trusted deployment can narrow the abuse gap. The teams that benefit most will be the ones that can connect both to a repeatable validation workflow and keep their evidentiary standards intact when the model gets smarter. (openai.com)
Reference links
- OpenAI, Trusted access for the next era of cyber defense
- OpenAI, Introducing Trusted Access for Cyber
- OpenAI Developers, Cyber Safety for Codex
- OpenAI, Our updated Preparedness Framework
- OpenAI Developers, Data controls in the OpenAI platform
- OpenAI, Introducing GPT-5.3-Codex
- NVD, CVE-2024-3094
- Openwall, backdoor in upstream xz liblzma leading to ssh server compromise
- NVD, CVE-2024-4577
- Canadian Centre for Cyber Security, Mass Exploitation of Critical PHP-CGI Vulnerability CVE-2024-4577
- Palo Alto Networks Unit 42, Operation MidnightEclipse and CVE-2024-3400
- Penligent homepage
- Overview of Penligent.ai’s Automated Penetration Testing Tool
- Penligent pricing and workflow details
- Anthropic Mythos, Strong Claims and Thin Binary Proof
