Mozilla shipped a fix for CVE-2026-6770 in Firefox 150 and Firefox ESR 140.10 on April 21, 2026. The same day, the Tor Project released Tor Browser 15.0.10, noting that it included important Firefox security updates and specifically “a fix to the cross-origin correlation issue explained here,” linking to the public Fingerprint research. In practical terms, the public disclosure described a browser privacy flaw in which affected Firefox Private Browsing sessions and affected Tor Browser sessions could expose a stable process-lifetime identifier through the ordering returned by indexedDB.databases(). (Mozilla)
That is why this bug mattered immediately, even though Mozilla’s advisory line for the CVE was short and restrained. The official entry identifies it as “Other issue in the Storage: IndexedDB component,” with moderate impact, while the overall Firefox 150 and ESR 140.10 advisory bundles were rated high because they also included memory-safety and other security fixes. The terse official wording was enough to establish the vulnerability and the patch boundary, but not enough to explain the privacy failure. The detailed explanation came from the public research write-up, which argued that internal process-scoped storage behavior was leaking through an API surface that should not have carried identity semantics in the first place. (Mozilla)
That distinction matters. There are two separate things to understand here. First, the official facts: Mozilla assigned CVE-2026-6770, fixed it in Firefox 150 and Firefox ESR 140.10, and Tor Browser 15.0.10 says it includes the corresponding Firefox-side security updates and the fix for the cross-origin correlation issue. Second, the public technical explanation: according to Fingerprint’s disclosure, the bug was rooted in how private-mode IndexedDB names were mapped and later enumerated, turning an undefined presentation order into a stable runtime identifier. Keeping those two layers separate is the only honest way to write about this case. (Mozilla)
The table below captures the high-confidence facts before getting into the deeper analysis.
| Verified point | Current status |
|---|---|
| Vulnerability ID | CVE-2026-6770, listed by Mozilla as “Other issue in the Storage: IndexedDB component,” with moderate impact. (Mozilla) |
| Firefox fix versions | Firefox 150 and Firefox ESR 140.10. (Mozilla) |
| Tor Browser status | Tor Browser 15.0.10 says it includes Firefox security updates and a fix to the cross-origin correlation issue. (blog.torproject.org) |
| Publicly described affected contexts | Firefox Private Browsing mode and Tor Browser sessions within the same running browser process. (Fingerprint) |
| API involved | IDBFactory.databases(), whose returned sequence is documented by MDN as undefined. (developer.mozilla.org) |
| Why Tor users care | Tor documents that New Identity is meant to make later activity unlinkable, and Tor Browser documents that it is engineered to reduce fingerprint uniqueness. (Support) |
Why the Firefox IndexedDB privacy vulnerability matters
The simplest way to understand this bug is to start from the promise that privacy modes are supposed to make. Mozilla’s own Firefox Help documentation says Private Browsing does not save browsing information such as history and cookies and “leaves no trace after you end the session.” Mozilla has also spent years strengthening that privacy boundary. Firefox 89 brought Total Cookie Protection into Private Browsing by default, isolating cookies per site, and Firefox 145 expanded anti-fingerprinting protections with explicit language that these defenses matter even when cookies are blocked or the user is in private browsing. (support.mozilla.org)
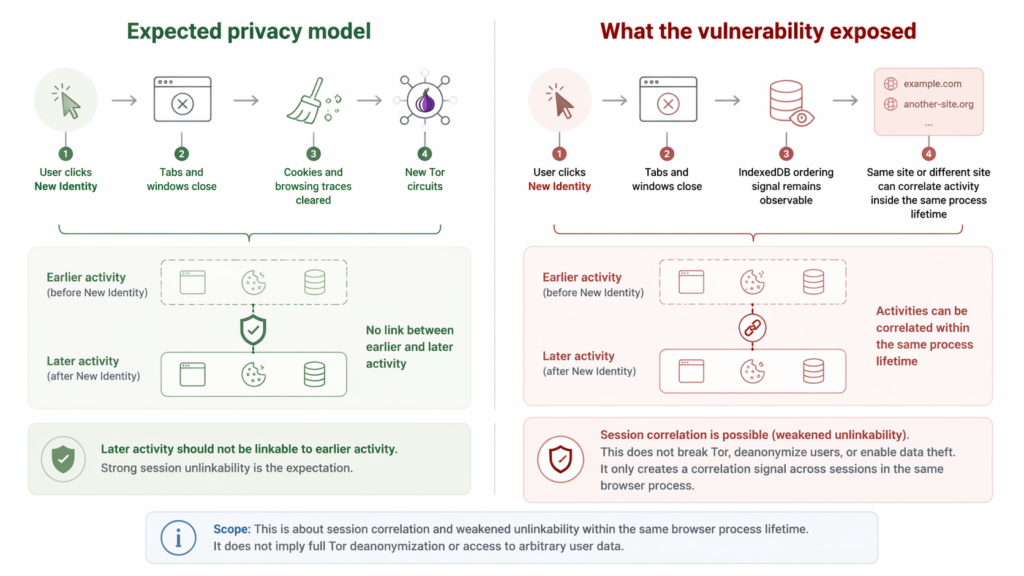
Tor Browser makes an even stronger promise about unlinkability. Tor’s support documentation says the New Identity feature is for preventing your subsequent browser activity from being linkable to what you were doing before. When a user triggers New Identity, Tor Browser says it closes open tabs and windows, clears private information such as cookies and browsing history, and uses new Tor circuits for all connections. Tor’s fingerprinting documentation says the browser is specifically engineered to minimize uniqueness across multiple metrics so users are harder to distinguish. (Support)
The public disclosure describes a problem that cut directly against those expectations. In affected Firefox Private Browsing builds, the process-lifetime identifier could persist even after the user had closed all private windows, so long as the underlying Firefox process was still alive. In affected Tor Browser builds, the identifier could survive a New Identity action during the lifetime of the same browser process. That did not mean a site could suddenly read another site’s full storage contents, and it did not mean a persistent device fingerprint survived a full browser restart. But it did mean the browser could keep leaking a stable enough signal for unrelated sites, or a revisited site, to correlate activity that the user reasonably expected to be unlinked. (Fingerprint)
That is why this case is more instructive than the advisory line suggests. Private browsing bugs are often misunderstood as being about cookie retention or browser history leftovers. This one was subtler. The leak came from the browser’s presentation of metadata. Nothing about the API name databases() suggests “identity.” Nothing about a list of database names suggests “process fingerprint.” The entire lesson is that a harmless-looking enumeration surface can become a tracking vector when it reflects internal process-scoped state in a deterministic way. (Fingerprint)
For defenders, this is the real headline. The web security community already thinks in terms of explicit storage channels such as cookies, localStorage, cache partitions, and service workers. But privacy failures do not have to arise from explicit sharing. They can arise from how the browser chooses to present an internal data structure. That difference matters because it changes what engineers need to audit. If the only question you ask is “Can one origin read another origin’s data,” you will miss bugs where the answer is “No, but one origin can infer that it is seeing the same running browser process as another origin.” (Fingerprint)
무엇 IDBFactory.databases() is supposed to do, and what it was never supposed to become
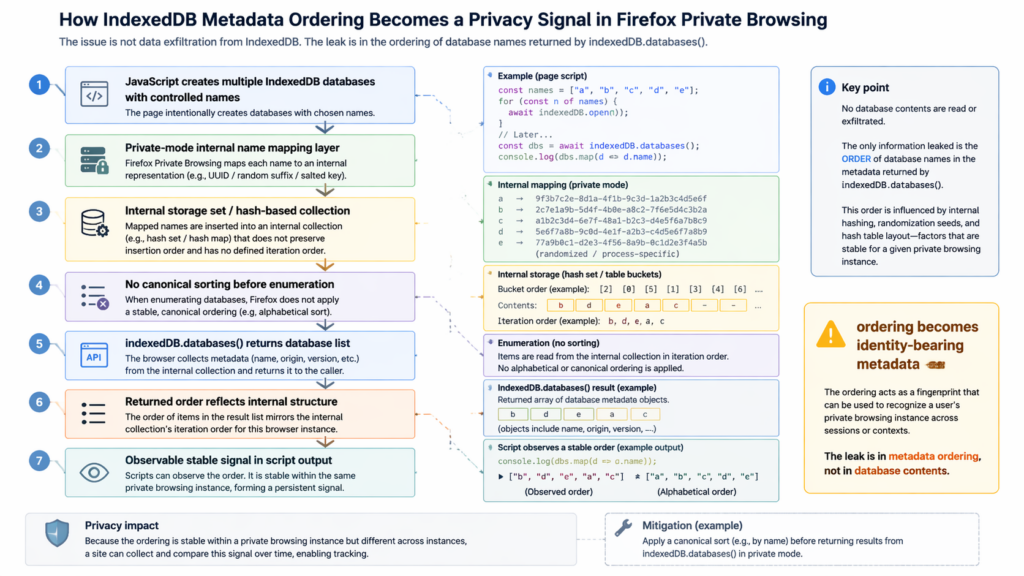
IndexedDB is a browser API for storing significant amounts of structured data on the client side. Modern web applications use it for offline support, caching, client-side state, and richer local data models than cookies were ever designed to support. The IDBFactory.databases() method returns a promise that resolves to an array describing the databases visible in the current context, including names and versions. MDN’s documentation is explicit about one detail that turns out to matter a lot here: the sequence of the returned objects is undefined. MDN also notes that the time taken to retrieve the databases and their order is undefined. (developer.mozilla.org)
That sentence on MDN is more important than it looks. In ordinary application development, “undefined order” is a warning not to build correctness around incidental enumeration order. In privacy engineering, it has a second meaning. If the sequence is undefined, then the browser should avoid letting that sequence accidentally encode sensitive internal state. A standards-compliant site should not depend on it for identity, and a privacy-preserving browser should not let it become identity-bearing by accident. That is part of what makes this case unusually clean as a postmortem lesson: the API contract itself gave Mozilla broad room to neutralize the signal without violating a developer-facing guarantee. (developer.mozilla.org)
This point also explains why the disclosure’s proposed fix direction made sense. Fingerprint argued that the cleanest mitigation would be to canonicalize the result, such as by lexicographic sorting, rather than let it reflect internal storage layout. Mozilla’s public advisory does not spell out the exact patch mechanics, so it is safer to say that this was the public research recommendation rather than the official postmortem. Still, taken together with MDN’s undefined-order note, the idea is straightforward: if developers were never promised a meaningful order, then returning a stable, neutral presentation is the obvious way to remove the leak while preserving the API’s legitimate utility. (Fingerprint)
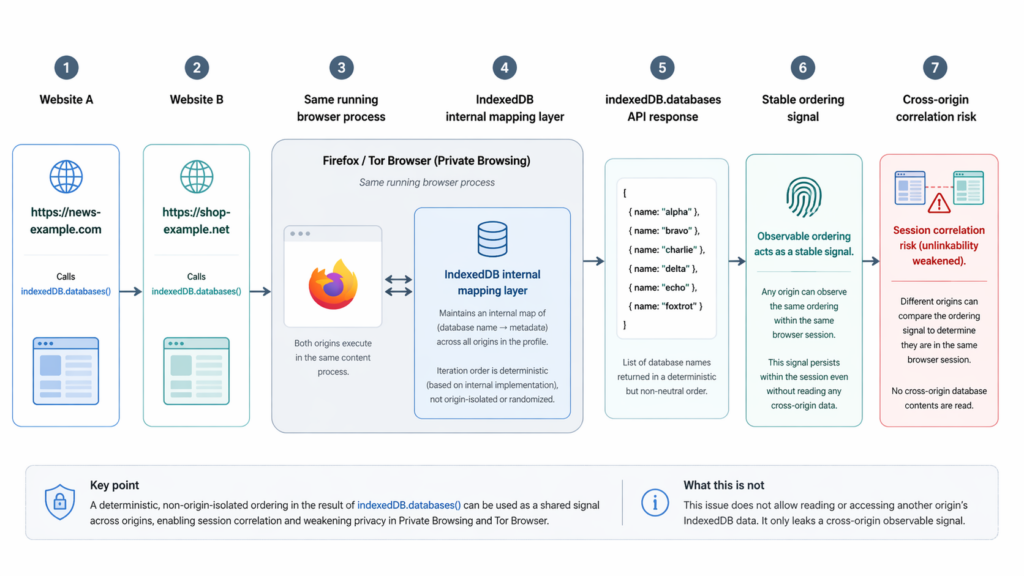
This is also where the bug becomes conceptually interesting for browser engineers. Browser APIs often expose metadata that looks harmless because it is not content. A name, a count, a timestamp, a list of handles, or the shape of an enumeration does not immediately sound like cross-site tracking material. But in privacy-sensitive contexts, metadata is often where the real trouble starts. Privacy failures frequently arise not because a browser reveals too much raw data, but because it reveals the wrong structural invariant. That is exactly what the disclosure says happened here. The problem was not “a site can read another site’s IndexedDB.” The problem was “a site can observe a structural artifact that is stable across origins because the underlying implementation state is process-scoped.” (Fingerprint)
How the public disclosure says the Firefox IndexedDB privacy vulnerability worked
The most technically detailed public description came from Fingerprint’s write-up, not from Mozilla’s advisory. According to that disclosure, the private-browsing path in Gecko’s IndexedDB implementation did not use the user-provided database names directly as on-disk identifiers. Instead, when the private-mode flag was active, the implementation mapped those names to UUID-based filename bases using a global hash table. The write-up says that mapping was keyed only by the database name string, shared across origins, persisted for the lifetime of the IndexedDB quota client, and was cleared only on a full Firefox restart. (Fingerprint)
The second half of the chain, still according to the public disclosure, is what turned that implementation choice into a privacy leak. When indexedDB.databases() was later invoked, the browser collected database base names and inserted them into an nsTHashSet. The write-up says no sorting was performed before iteration. That meant the final order exposed to JavaScript reflected the internal bucket layout of the hash structure rather than a neutral, canonical presentation. Because the UUID-like mappings were stable for the lifetime of the process, the resulting ordering was also stable for the lifetime of the process. Crucially, the disclosure argues that this state was process-scoped rather than origin-scoped. (Fingerprint)
Mozilla’s advisory does not publish that implementation story, and that matters. Good security writing should not pretend there is no difference between a vendor-confirmed CVE and a third-party root-cause analysis. But it is equally important not to throw away the research detail simply because the vendor summary is terse. In this case, the public explanation is internally coherent, aligns with the observed behavior described in the disclosure, and is consistent with the repair direction implied by the Tor release note’s “cross-origin correlation issue” language. The right way to state it is this: Mozilla officially confirmed and fixed the vulnerability, while the disclosure provides the best public explanation of how the signal emerged. (Mozilla)
Conceptually, the bug chain is elegant in the worst possible way. A user-controlled input set, namely a chosen set of database names, goes into the browser. The browser transforms those names through a process-lifetime mapping that is not scoped to the origin boundary users care about. The browser then exposes the resulting set back to JavaScript in an order that reflects internal bucket layout. No single step sounds catastrophic. Taken together, they create a process-level identity signal. That is the sort of privacy failure that slips through when engineering review focuses on direct data access but not on the semantics of metadata exposure. (Fingerprint)
From undefined order to a stable identifier
The leap from “hash set iteration order” to “usable fingerprint” deserves careful explanation because this is where non-browser specialists often get lost. If a site can control a set of database names, then it can create a list of entries and ask the browser to enumerate them. If the browser returns those entries in some neutral and canonical order, the list is boring. It carries no extra identity information. But if the returned sequence is a deterministic function of an internal process-specific mapping and hash layout, then the order itself becomes a signal. The site is not learning another origin’s data. It is learning a property of the running browser process that shows up the same way wherever the same process goes. (Fingerprint)
Fingerpint’s write-up makes the capacity argument explicit. If a site controls N database names, then the theoretical space of possible observable permutations is N!, and the theoretical entropy is log2(N!). For sixteen controlled names, the write-up estimates about forty-four bits of theoretical space. The exact reachable set of permutations may be smaller in practice because internal hash-table behavior constrains what is realizable, but the important point is not the exact number. The important point is that the signal is strong enough to distinguish many concurrent browser processes in realistic conditions. That is more than enough for cross-origin correlation during active use. (Fingerprint)
The logic here mirrors a recurring theme in browser privacy work. Signals do not need to be permanent to be harmful. A privacy-sensitive user session does not have to be linkable for weeks to be dangerous. It only has to be linkable when the user believed they had reset identity or isolated contexts. That is especially true in Tor workflows, where unlinkability within a single activity window matters as much as long-term persistence. A signal that survives until a full process restart can still materially weaken the user’s privacy model if the user believes closing windows or triggering New Identity should be enough. (Support)
There is another subtle point here that deserves emphasis. This was not a classic “supercookie” in the narrow sense of persistent cross-site storage written by one site and read by another. Mozilla’s long-running privacy work on Total Cookie Protection and supercookie protections targets explicit storage and partitioning problems. This bug sat adjacent to that work, not inside it. The leak came from the browser’s implementation details showing up in an enumeration surface. That difference matters because it explains why a browser can make real progress on state partitioning and still be vulnerable to a different class of linkability bug at the same time. (blog.mozilla.org)
Why Tor Browser felt the impact more sharply
Tor Browser users have a different threat model from ordinary Firefox users, and that changes the severity discussion even if the raw mechanics are similar. Tor’s support documentation says the browser is engineered to minimize fingerprint uniqueness by collapsing users into fewer distinguishable buckets. It also says New Identity is there to prevent later activity from being linkable to earlier activity, closing windows, clearing cookies and history, and switching to new Tor circuits. In other words, Tor’s browser UX is explicitly teaching users to think in terms of unlinkability boundaries. (Support)
The public disclosure describes this bug as weakening exactly that unlinkability boundary. Because the signal was process-lifetime rather than origin-lifetime, and because it could survive a New Identity action within the same running process, a site could continue to see the same underlying identifier after the user invoked what Tor documents as a reset action. That is why the Tor Project’s April 21 release note matters so much. It did not merely say “security updates from Firefox.” It specifically noted that Tor Browser 15.0.10 included a fix to the cross-origin correlation issue explained in the linked research. That is unusually clear wording for a release note, and it confirms that Tor considered the issue operationally relevant to its privacy model. (blog.torproject.org)
This is also a good example of why impact labels can mislead when taken out of context. Mozilla marked CVE-2026-6770 as moderate within its advisory bundle. That is a sensible vendor classification for a browser privacy flaw that did not directly hand over arbitrary cross-origin content or arbitrary code execution. But a moderate vendor label does not mean the bug is strategically minor for Tor’s user base. A flaw that would be a moderate privacy problem in one product can be a much more consequential anonymity problem in a product whose design center is active resistance to linkability and fingerprinting. Both statements can be true at once. (Mozilla)
The more general lesson is uncomfortable but important. Privacy tools are usually attacked through the places where implementation detail crosses an isolation boundary. People often imagine the most dangerous privacy failures as dramatic deanonymization exploits or obvious scripting errors. In practice, a stable runtime signal in the wrong place can be enough to chip away at the guarantees users depend on. Tor’s own documentation makes that lesson plain in reverse: its browser engineering is built around minimizing distinguishability. Any implementation detail that reintroduces distinguishability is therefore not peripheral. It strikes at the heart of the product’s security story. (Support)
What the Firefox IndexedDB privacy vulnerability did not do
Precision matters more than drama in security writing, so it is worth stating the limits of the public disclosure clearly. The disclosure does not say that one origin could directly read another origin’s IndexedDB contents. It says that unrelated websites could independently derive the same stable identifier from the ordering returned by the API and infer that they were interacting with the same running browser process. That is correlation, not direct cross-origin database exfiltration. (Fingerprint)
The disclosure also does not describe a persistent, device-level fingerprint that survived a full browser restart. In both Firefox Private Browsing and Tor Browser, the write-up says the ordering reset when the browser was fully restarted. That boundary matters. A full restart is not the same as a permanent identifier tied to hardware or profile state. Overstating this case as “Firefox had an unstoppable Tor deanonymization fingerprint” would be inaccurate. Understating it as “just a quirky order bug” would also be inaccurate. The truth is narrower and more useful: affected builds leaked a strong enough process-lifetime identity signal to weaken the unlinkability properties users expected during active use. (Fingerprint)
It is also important not to confuse this with a cookie-isolation failure. Mozilla’s Private Browsing and Total Cookie Protection work was designed to keep cookies and related storage from becoming cross-site tracking channels. The issue here bypassed that entire layer by using a different class of signal. That distinction is essential for defenders because the remediation strategy is different. You do not fix this by clearing cookies harder. You fix it by eliminating identity-bearing exposure from an enumeration API. (blog.mozilla.org)
Finally, while Fingerprint’s disclosure says the behavior was inherited by Firefox-based browsers through Gecko’s IndexedDB implementation, public confirmation is strongest where the vendor or downstream project actually said so. Mozilla officially fixed the CVE in Firefox and Firefox ESR. The Tor Project explicitly shipped the corresponding fix in Tor Browser 15.0.10 and named the issue class. For other downstream Gecko-based products, the prudent statement is that they should check whether they inherited the same behavior unless they already carried their own mitigation. That is a safer and more precise claim than asserting universal impact without downstream confirmation. (Fingerprint)
Reading CVE-2026-6770 correctly
Security teams often overestimate what a CVE record tells them and underestimate what a vendor advisory omits. CVE-2026-6770 is a good example of that gap. Mozilla’s advisory tells you the component, the reporter, the impact label, and the fixed version. The CVE mirrors and GitHub Advisory entry repeat the same basic description in similarly terse language: “Other issue in the Storage: IndexedDB component,” fixed in Firefox 150 and Firefox ESR 140.10. That is enough for vulnerability management and patching. It is not enough by itself to teach an engineer what actually went wrong. (Mozilla)
The right way to use CVE-2026-6770 is as a coordination label, not a full explanation. It tells patch management teams what to track. It lets product security teams correlate internal inventories and release cycles. It gives browser and privacy engineers a stable handle for test cases, dashboards, and follow-up analysis. But the technical meaning of the bug lives in the combination of sources: Mozilla’s fix boundary, Tor’s downstream release note, MDN’s API semantics, Firefox’s published privacy model, and Fingerprint’s public root-cause analysis. Looking at any one of those in isolation produces a thinner and less accurate understanding than looking at all of them together. (Mozilla)
There is another useful lesson here for defenders who triage browser CVEs at scale. A one-line vendor description such as “other issue” is not a reason to dismiss a finding as vague or unimportant. Browser vendors often write advisories to establish the vulnerability and the patch window without publishing a long narrative. Researchers, downstream projects, and public discussions then add the practical meaning. If your security workflow only consumes CVE titles and severity labels, you will miss the difference between a moderate inconvenience and a subtle but real privacy-boundary failure. (GitHub)
That is especially true when the affected feature sits inside a product area users already trust. Private Browsing and Tor’s New Identity are not obscure toggles. They are explicit privacy promises. A vulnerability that weakens those semantics deserves to be read in the context of that promise, not just in the context of an advisory’s terse line item. The real question is never only “what number did the vendor assign.” The real question is “what user guarantee became less reliable until the fix landed.” In this case, the answer was session unlinkability within the same running process. (support.mozilla.org)
A safe lab workflow for understanding the bug
A public write-up is easier to understand when you can turn it into a small, controlled experiment. The safest way to do that is with a local two-origin lab, using only software you own or are explicitly authorized to test. Do not point this at third-party sites. Do not browse the live web while trying to reproduce it. And do not expect patched versions to show the vulnerable behavior, because Mozilla and Tor have already shipped fixes. For lab work, you would need an intentionally vulnerable build older than Firefox 150 or Firefox ESR 140.10, or a Tor Browser build older than 15.0.10. (Mozilla)
At a high level, the public disclosure says the reproduction recipe is simple. Two different origins host the same script. Each script creates a fixed set of named databases, calls indexedDB.databases(), and prints the returned order. In an affected build, both origins observe the same permutation while the same browser process is alive. After a full browser restart, the permutation changes. That is the essence of the signal. (Fingerprint)
A minimal HTML page for a lab can look like this:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>IndexedDB Order Lab</title>
</head>
<body>
<pre id="out">running...</pre>
<script>
const names = "abcdefghijklmnop".split("");
function openDb(name) {
return new Promise((resolve, reject) => {
const req = indexedDB.open(name, 1);
req.onupgradeneeded = () => {
req.result.createObjectStore("s");
};
req.onsuccess = () => {
req.result.close();
resolve();
};
req.onerror = () => reject(req.error);
});
}
async function run() {
for (const name of names) {
await openDb(name);
}
const dbs = await indexedDB.databases();
const listed = dbs.map(x => x.name).join(",");
document.getElementById("out").textContent =
"created:\n" + names.join(",") + "\n\nlisted:\n" + listed;
}
run().catch(err => {
document.getElementById("out").textContent = String(err);
});
</script>
</body>
</html>
The easiest way to create two distinct origins locally is to serve the same page on two different ports. Different ports are different origins, so http://127.0.0.1:8000 그리고 http://127.0.0.1:8001 are enough for a local demonstration.
mkdir -p originA originB
cp index.html originA/index.html
cp index.html originB/index.html
python3 -m http.server 8000 --directory originA
python3 -m http.server 8001 --directory originB
In a deliberately vulnerable Firefox Private Browsing session, or a deliberately vulnerable Tor Browser session, the test is straightforward. Open the first origin and note the listed order. Open the second origin in the same running browser process and compare. If both origins show the same non-canonical sequence, you have reproduced the public behavior. Then fully exit the browser process, start it again, reopen one origin, and observe whether the sequence changes. That restart boundary is an important part of understanding what the bug was and was not. (Fingerprint)
One common mistake in labs like this is to test only a single origin and stop there. That proves almost nothing. The interesting behavior is not merely “the order looks odd.” The interesting behavior is “different origins see the same order during the same process lifetime.” Another common mistake is to close a private window but leave the underlying Firefox process running. The public disclosure specifically says that in affected Firefox Private Browsing builds, the identifier could persist after all private windows were closed as long as the Firefox process remained alive. In other words, “close the window” and “restart the browser” are not equivalent steps for this bug. (Fingerprint)
For Tor Browser, the lab story is slightly different because the interesting transition is not just restart versus no restart. It is New Identity versus full process restart. Tor documents New Identity as a privacy reset intended to make later activity unlinkable to what came before. The public disclosure says this signal could survive that action within the same process lifetime, which is precisely why the behavior mattered to Tor’s threat model. In a deliberately vulnerable lab, that is the state transition worth testing. Open the first origin, record the order, invoke New Identity, return to the same or another local origin, and compare. Then fully restart Tor Browser and compare again. (Support)
What defenders should test after reading this case
The most useful outcome of reading a browser privacy bug is not outrage. It is a better test plan. For browser teams, privacy engineers, and serious AppSec groups, this case suggests at least four classes of regression test. The first is enumeration neutrality: when an API returns a collection in a privacy-sensitive context, does that order encode anything about process state, insertion history, allocation behavior, or opaque handle mapping that the caller was never meant to learn. The second is context reset semantics: do privacy UI actions such as closing all private windows or triggering New Identity actually reset every user-visible signal the product implies they reset. The third is scope alignment: is any internal state unexpectedly process-scoped where the user-facing privacy boundary implies origin, site, profile, or session scoping. The fourth is downstream inheritance: if a fix lands in Gecko or another shared engine component, have downstream privacy-focused products explicitly validated that the user-facing guarantee is restored. (support.mozilla.org)
A practical audit table helps because this issue is broader than IndexedDB alone.
| Audit surface | What to ask | 중요한 이유 |
|---|---|---|
| Enumeration APIs | Does returned order reflect internal hash layout, insertion history, or process-scoped state rather than canonical presentation? | Order itself can become a tracking signal even when content access is correctly scoped. (developer.mozilla.org) |
| Privacy reset actions | After a private-session close or identity reset, does any observable browser behavior remain stable until full process restart? | Users interpret privacy UI as a semantic boundary, not merely a UI action. (support.mozilla.org) |
| Cross-origin comparisons | Can unrelated origins derive the same signal without shared storage? | Cross-origin correlation can happen without direct storage access. (Fingerprint) |
| Downstream browser products | Has the downstream product explicitly pulled the fixed engine version or documented equivalent mitigation? | Shared engine bugs often inherit into privacy-focused downstream browsers. (blog.torproject.org) |
| Developer contracts | Is the API contract already undefined or non-semantic on the attribute being leaked? | If yes, canonicalization is often lower-risk than leaving incidental behavior exposed. (developer.mozilla.org) |
For web security teams rather than browser vendors, the test program is different but still concrete. The goal is not to patch Gecko yourself. The goal is to verify privacy-sensitive behavior in the environments your users actually rely on. If your product claims privacy, anonymity, or strong session unlinkability, your QA and security plans should include browser-state validation in addition to network and storage validation. It is not enough to say “we clear cookies.” You need to ask whether any browser-observable behavior remains stable across the transitions your UI describes as resets. (support.mozilla.org)
A practical verification workflow for red teams and AppSec teams
This class of bug sits at an awkward intersection. It is too stateful for a pure static review, too UX-dependent for a simple scanner, and too subtle for a one-off manual observation to be convincing. The most reliable workflow is evidence-driven. Start with a narrow hypothesis, build a minimal two-origin harness, record exact browser version and patch state, preserve screenshots and logs of both origins, capture the transition step such as private-window close or New Identity, then retest after a full process restart. If you cannot preserve that evidence chain, your finding will be hard to explain and harder to reproduce. (penligent.ai)
That is also why this case fits naturally into an evidence-first view of modern offensive testing. Penligent’s public writing on AI pentest workflows makes a useful point here: the difference between “AI that sounds smart” and “a useful security workflow” is whether the system preserves reproducible evidence, state, and retestability. Its technical material on AI pentest tooling argues that the real value is not pleasant summarization, but the ability to carry a recognizable testing workflow from observation to proof. Its reporting article makes the same point from the documentation side, arguing that a valid deliverable needs reproducible steps and supporting evidence rather than a polished-looking chat transcript. Those are exactly the right instincts for browser privacy validation too. (penligent.ai)
A second useful parallel comes from Penligent’s browser-adjacent work on CORS testing. That article frames cross-origin security validation as something that often requires real browser context, real header observation, and bulk evidence collection rather than superficial one-shot checks. The same workflow logic applies here. A privacy-boundary failure that appears only across origins and across session transitions is not well served by a single-page manual check. It benefits from automation that can replay state transitions, compare outputs, and store artifacts. The point is not the brand name of the tool. The point is the operating model: browser-aware, state-aware, and evidence-preserving. (penligent.ai)
The table below is a good shorthand for how to structure that workflow.
| Test action | Observe | Result that should worry you |
|---|---|---|
| Create a fixed database set on origin A | Returned order from indexedDB.databases() | Non-canonical order alone is not enough; keep going |
| Repeat on origin B in same process | Compare returned order with origin A | Same unusual order across origins suggests cross-origin correlation signal |
| Close private windows without full browser exit | Reopen lab page and compare | Same order suggests process survives the apparent session end |
| Trigger Tor New Identity on a vulnerable lab build | Revisit origin and compare | Same order suggests identity reset did not clear the signal |
| Fully restart browser process | Reopen lab page and compare | Changed order supports a process-lifetime rather than persistent fingerprint model |
This framework also helps reduce overclaiming. A single matching order across origins is suspicious, but serious reporting requires repeated validation and clear version accounting. A changed order after full restart is an important boundary check. A failure to reproduce on patched Firefox 150, Firefox ESR 140.10, or Tor Browser 15.0.10 is exactly what you should expect given the official and downstream fix statements. (Mozilla)
Why browser privacy bugs like this survive normal reviews
At a glance, this bug looks like the kind of thing a code review should catch. In reality, it sits in a blind spot that many mature teams still have. Security review is very good at asking whether data crosses a forbidden boundary. Privacy review is often good at asking whether the user is exposed to a known tracking vector. Fewer teams are equally good at asking whether an implementation detail, such as enumeration order or opaque naming, unintentionally creates a new vector when combined with the user’s ability to shape inputs and compare contexts. (Fingerprint)
The problem gets worse in privacy-sensitive modes because those modes often introduce special-case code paths. Fingerprint’s public explanation explicitly ties the bug to how private-mode IndexedDB naming behaved differently from ordinary assumptions. Special-case privacy paths are necessary. They are also dangerous, because they are where implementation differences accumulate. Once that happens, engineers can end up reviewing correctness and privacy at the wrong abstraction level. Everything may look fine if you check whether names are hidden or whether disk persistence is avoided. The leak emerges only when you ask what the API returns after those implementation decisions interact. (Fingerprint)
This is also why user-facing privacy claims require cross-layer review. It is not enough for product documentation to promise that cookies are cleared or that history is not saved. Those are only parts of a privacy boundary. The real promise users hear is broader: “my later activity is not linkable to what I just did,” or at least “the browser will not preserve recognizable state after this reset action.” As soon as product copy and support docs communicate that broader promise, engineering review has to validate not only explicit storage but also the observable semantics of the browser after the reset. Mozilla and Tor’s own documentation made that promise legible, which is exactly why the bug was meaningful. (support.mozilla.org)
The larger lesson for browser privacy engineering
The most important engineering lesson from CVE-2026-6770 is not “sort your list.” It is “never let process-scoped state masquerade as harmless metadata in a privacy-sensitive context.” Sorting is only the concrete fix for this specific case. The general lesson is broader. Any API that enumerates internal objects, reports counts, returns opaque handles, or exposes fallback order can become an identity surface if the underlying state survives longer or scopes wider than the user expects. (Fingerprint)
That lesson aligns cleanly with the direction Mozilla has already been taking. Firefox’s privacy work has increasingly focused on reducing cross-site linkability, from Total Cookie Protection to newer anti-fingerprinting measures. Those efforts assume the same foundational principle: a website should learn as little as possible about the user or browser instance beyond what is needed for the task at hand. What made this bug interesting is that it violated that principle at the presentation layer, not at the storage partitioning layer. The privacy boundary was weakened not because sites gained a new permission, but because a non-semantic implementation artifact acquired semantics. (blog.mozilla.org)
For browser vendors, that implies a specific hardening strategy. Privacy reviews should include dedicated scrutiny of enumeration APIs in privacy-sensitive modes. Undefined-order APIs should be treated as especially dangerous because they give the implementation freedom that can accidentally surface state. Reset actions in privacy UIs should be tested as claims, not just features. And downstream privacy products should maintain regression suites that validate not only the engine patch level, but the actual user-facing unlinkability semantics promised in their own support docs. (developer.mozilla.org)
What defenders should do now
If you administer Firefox or Firefox ESR, the immediate action is simple: update to Firefox 150 or Firefox ESR 140.10 or later. If you use Tor Browser, update to Tor Browser 15.0.10 or later. Those are the clear, official patch boundaries reflected in Mozilla’s advisories and Tor’s release note. Anything more clever than that is secondary to getting onto a fixed build. (Mozilla)
If you are responsible for documentation or user guidance around privacy features, review how your product explains reset actions. The important distinction in this case was the difference between closing a window and fully ending the process. That difference is invisible to many users. A good privacy product should either guarantee the stronger behavior or document the boundary precisely enough that users can reason about it. Tor’s documentation is clear about what New Identity is meant to accomplish. Cases like this show why that documentation has to stay tightly coupled to regression testing. (Support)
If you build browser-adjacent features such as extensions, privacy wrappers, enterprise hardening packs, or anonymity tooling, treat enumeration and metadata surfaces as first-class review targets. Ask not only whether storage is partitioned, but whether metadata presentation can still create stable correlation signals. This advice is broader than IndexedDB. The same mental model applies to any API that surfaces internal ordering, counts, timing, or opaque names that should be semantically neutral but might not be neutral in practice. (Fingerprint)
If you run AppSec or red-team programs, add privacy-boundary regression tests to the parts of your workflow that already handle stateful browser validation. This is not only about browsers sold as privacy tools. Any product that markets private sessions, “incognito” features, temporary workspaces, unlinkable identities, or one-click reset semantics should be tested against the claim it makes. The easiest bugs to ship are often the ones that sit between implementation detail and user expectation. This case is a reminder that those are exactly the bugs defenders should get serious about. (support.mozilla.org)
추가 읽기 및 참조 링크
Official references
Mozilla advisory for Firefox 150, including CVE-2026-6770 and the Firefox fixed version boundary. (Mozilla)
Mozilla advisory for Firefox ESR 140.10, including CVE-2026-6770 in the ESR line. (Mozilla)
Tor Browser 15.0.10 release note, which explicitly says the release includes a fix to the cross-origin correlation issue. (blog.torproject.org)
Firefox Help on Private Browsing, describing the expected “leaves no trace after you end the session” behavior. (support.mozilla.org)
Tor Support on Managing Identities, documenting what New Identity is supposed to reset and why it exists. (Support)
Tor Support on fingerprinting protections, documenting Tor Browser’s goal of minimizing uniqueness across multiple metrics. (Support)
MDN documentation for IDBFactory.databases(), including the note that returned sequence is undefined. (developer.mozilla.org)
Public research and analysis
Fingerprint’s public disclosure, which provides the most detailed public explanation of the observed behavior, reproduction logic, entropy discussion, and proposed fix direction. (Fingerprint)
GitHub Advisory entry for CVE-2026-6770, useful as a compact cross-reference to the published CVE and vendor advisories. (GitHub)
Related Penligent pages
Penligent’s Firefox Nightly Wasm GC 0-day analysis, a related browser-security case study useful for readers building a broader browser risk perspective. (penligent.ai)
Penligent’s browser-adjacent CORS testing article, relevant for teams thinking about cross-origin behavior, real browser context, and repeatable validation. (penligent.ai)
Penligent’s article on what real AI pentest tooling should look like, relevant for teams automating evidence-first browser and web security validation. (penligent.ai)
Penligent’s article on how to produce an AI pentest report that survives retest, relevant for documenting stateful privacy and browser findings. (penligent.ai)
Penligent homepage, for readers who want to see the product context behind those workflow discussions. (penligent.ai)

