OX Security’s April 2026 MCP disclosure is easy to overstate and dangerous to understate. The clean version is this: the research describes a systemic command-execution risk around MCP STDIO configuration, with OX estimating 150M+ downloads, 7,000+ publicly accessible servers, and up to 200,000 vulnerable instances in total. That is not the same as proving that 200,000 internet-facing MCP servers are all directly exploitable today. The public exposure figure in the original OX write-up is 7,000+ servers; the larger number refers to vulnerable instances across the ecosystem. Getting that distinction right matters because the technical lesson is stronger than the headline. The issue is not “MCP is broken everywhere.” The issue is that agent systems are now wiring configuration, model influence, web UIs, local IDEs, package registries, and operating-system process launch into the same execution path. When that path is not governed, MCP STDIO becomes a bridge from tool configuration to command execution. (OX Security)
MCP was introduced by Anthropic as an open standard for connecting AI-powered tools to data sources, services, and workflows. The protocol’s value is obvious to anyone building agents: instead of writing custom integrations for every model-tool pair, developers can expose tools through MCP servers and connect AI applications through MCP clients. The same architecture also moves the security boundary. Once an agent can call tools, browse repositories, read tickets, modify files, start local servers, query databases, or touch cloud APIs, the interesting question is no longer just whether the model produces safe text. The question is whether untrusted influence can reach an execution primitive. (인류학)
The STDIO transport is central to this story. The MCP specification defines two standard transports: STDIO and Streamable HTTP. In STDIO mode, the client launches the MCP server as a subprocess, then sends and receives JSON-RPC messages over standard input and standard output. That design is not inherently wrong. Local developer tools have used subprocesses for decades. The risk appears when a product treats “which subprocess should I launch” as a user-editable, request-editable, model-editable, or marketplace-controlled field. At that moment, 명령 그리고 args stop being deployment configuration and become a code-execution boundary. (modelcontextprotocol.io)
MCP made tool access standard, and that changed the threat model
Before agent tooling became mainstream, many LLM security discussions focused on prompt leakage, jailbreaks, unsafe completions, and data exposure. Those risks still exist, but MCP pushes a different class of issue to the front. It standardizes a way for AI applications to reach external systems. That means a model may not only answer a question; it may trigger a workflow, invoke a function, inspect a file, fetch a webpage, open an issue, or call a tool that sits next to credentials.
In a simple MCP setup, there are three trust zones. The first is the host application, such as an IDE, desktop assistant, internal chatbot, or agent platform. The second is the MCP layer, where clients connect to servers and discover tools, resources, and prompts. The third is everything behind the MCP server: the file system, shell, database, cloud account, ticketing system, browser session, source repository, local workstation, or CI runner. Most real risk lives at the boundary between the second and third zones.
A clean local STDIO setup might look like this:
{
"mcpServers": {
"internal-docs": {
"transport": "stdio",
"command": "python",
"args": ["servers/internal_docs_server.py"]
}
}
}
That configuration is not automatically vulnerable. The command is fixed. The server path is known. The operator can review the server code, pin dependencies, run it in a constrained environment, and decide what files or APIs it can access.
The unsafe pattern looks different:
{
"transport": "stdio",
"command": "<value from user input, database config, LLM output, or HTTP request>",
"args": ["<values from the same untrusted source>"]
}
The danger is not the JSON shape. The danger is the data flow. If untrusted content reaches a process launch API, the product has created an execution path. If that product is internet-accessible, embedded in an IDE, connected to a multi-tenant service, or allowed to edit local configuration files, the execution path becomes an attack surface.
That is the key to understanding the OX disclosure. OX’s technical deep dive says the modelcontextprotocol SDK gives developers a direct configuration-to-command execution path through STDIO. Their examples show the intended use, where a fixed command starts a local server, and the unsafe use, where user_input_command 그리고 user_input_arguments are passed into STDIO server parameters. OX’s point is that downstream frameworks and products inherited the same shape because the primitive is useful, easy to expose, and easy to misuse. (OX Security)
STDIO is not the vulnerability by itself
It is tempting to summarize the problem as “STDIO executes commands.” That is too blunt. A local client must start something if it is going to communicate with a local server over standard input and output. The MCP transport documentation says exactly that: the client launches the MCP server as a subprocess, and the server then reads JSON-RPC messages from stdin and sends messages to stdout. (modelcontextprotocol.io)
The real bug class is more precise:
| Design element | Safe version | Dangerous version |
|---|---|---|
| Server launch | Fixed template reviewed by developers | Raw command submitted through UI, API, config file, or model output |
| Arguments | Schema-defined values with strict validation | Arbitrary argument array controlled by untrusted input |
| Transport choice | Server-side allowlist per connector | Client-requested transport 또는 transport_type accepted blindly |
| Approval | Full command shown before execution | Vague approval, hidden file edit, or no approval |
| Runtime | Isolated process with minimal file and network access | Same privileges as IDE, server, CI runner, or production service |
| Logging | Process launch, caller identity, config source, and output captured | Only generic “connection failed” or no audit trail |
| Recovery | Patch, retest, and regression check | One-time UI fix with backend path still reachable |
This distinction matters because defenders should not ban every STDIO MCP server by default. Some local STDIO servers are reasonable in tightly controlled developer workflows. The operational rule should be stricter: do not let untrusted influence choose the executable, the executable path, the transport type, or high-risk arguments.
The MCP security best-practices documentation makes a related point in its section on local MCP server compromise. It says local MCP servers may have direct access to the user’s system and can become attractive attack targets. It lists malicious startup commands, malicious server payloads, and insecure local servers as possible attack paths. It also recommends showing the exact command before execution, clearly identifying that the action executes code on the user’s system, requiring explicit approval, warning that MCP servers run with the same privileges as the client, and using sandboxed environments with restricted file-system and network access. (modelcontextprotocol.io)
That official guidance is useful, but the OX disclosure shows why guidance alone is not enough. In fast-moving agent products, developers often turn dangerous primitives into product features: “Add an MCP server,” “Test this connector,” “Import this tool,” “Let the agent update config,” “Install from marketplace,” “Run this local helper.” Each feature can be safe in isolation if it is designed carefully. At ecosystem scale, many will not be.
The OX disclosure in plain engineering terms
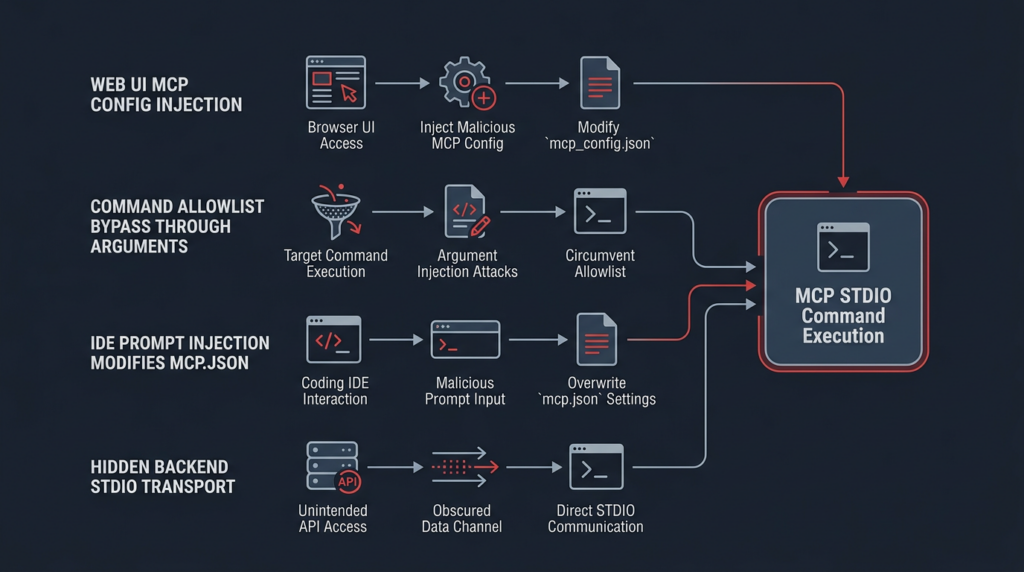
OX described one root cause and four exploit families. The root cause is the same throughout: untrusted input can influence MCP STDIO configuration, and that configuration reaches command execution. The four exploit families matter because they show how the same root pattern can surface through different products and workflows. (OX Security)
The first family is direct UI-driven command injection. A product exposes an MCP configuration screen. The attacker enters or submits a configuration with STDIO transport and attacker-controlled command fields. The application passes those values to the MCP STDIO launch path. The operating system executes the command under the privileges of the application process. OX grouped multiple AI platforms in this family, including LangFlow, GPT Researcher, LiteLLM, Agent Zero, LangBot, Fay, Bisheng, Jaaz, and Langchain-Chatchat. The exact authentication requirement differs by product, which is why defenders should not read a single exploit chain as universal. Some paths require authentication; some depend on public UI exposure; some involve open registration; some rely on management endpoints. (OX Security)
The second family is hardening bypass. Some products recognized the risk and tried to allow only certain launchers. That is better than accepting every command, but it is still fragile if the allowed launcher can execute arbitrary commands through its arguments. OX cited npm 그리고 npx style bypasses as examples of why command-name allowlists alone are insufficient when argument semantics remain unconstrained. The lesson is not “allowlists are useless.” The lesson is that allowlists must cover the executable, the path, and the allowed argument grammar. (OX Security)
The third family is prompt injection against IDEs and coding agents. In this class, the attacker does not directly submit a command through an admin UI. Instead, the attacker influences the AI assistant’s behavior through content such as a webpage, prompt, repository file, issue, README, or hidden instruction. If the assistant can modify MCP configuration and the client later trusts that configuration, prompt injection can become local code execution. OX says Windsurf received a CVE because the described chain required no further user interaction, while other IDEs and coding assistants generally required at least one user approval to modify configuration, leading some vendors to reject the finding as expected behavior rather than a vulnerability. That distinction is important. It does not mean every IDE was equally exploitable. It means the same class of risk appears wherever model-influenced file edits can reach local execution configuration. (OX Security)
The fourth family is backend transport substitution. A product’s UI may show only HTTP or SSE MCP options, giving users and reviewers the impression that STDIO is not available. But if the backend still accepts a request body that changes transport_type 또는 transport to STDIO and includes command fields, the UI has not removed the execution path. OX described DocsGPT and LettaAI-style cases where modifying network requests could trigger hidden STDIO processing. The defensive lesson is simple: never trust the UI as the policy boundary. The server must enforce the transport allowlist. (OX Security)
Why the headline became controversial
The controversy is partly technical and partly philosophical. OX says the STDIO behavior is “by design,” that Anthropic declined protocol-level changes, and that sanitization responsibility was pushed to downstream developers. OX also says it performed more than 30 responsible disclosures and produced 10+ High or Critical CVEs from the same root pattern. (OX Security)
From one perspective, a transport layer that launches a local process is doing exactly what it was designed to do. If a developer passes arbitrary user input to a process launcher, the developer misused the primitive. From another perspective, a popular agent protocol should assume that downstream developers will copy examples, wrap SDK calls, expose configuration in UIs, and ship fast. Under that assumption, a raw command execution primitive needs stronger guardrails, clearer dangerous-mode semantics, fixed templates, or manifest-only execution.
Both readings contain truth. The practical conclusion is not to wait for the argument to settle. If your system uses MCP, the safer operating assumption is that no upstream protocol-level fix will automatically save every downstream integration. You need to audit your own execution boundary.
CISA’s Secure by Design framing is useful here because it pushes software manufacturers to prioritize customer security as a core product requirement rather than treating hardening as a customer-side afterthought. That principle maps directly to MCP-enabled products. A product that lets users add an MCP server is not merely providing a convenience feature. It is exposing a privileged execution workflow and must own the safety of that workflow. (cisa.gov)
The CVEs that define the failure class
The best way to understand MCP STDIO RCE is to study concrete vulnerability records and ask what each one teaches about the boundary between configuration, model influence, and execution.
| 취약성 | 구성 요소 | What makes it relevant | Practical remediation lesson |
|---|---|---|---|
| CVE-2026-30623 | LiteLLM | Authenticated users with access to MCP server creation or preview endpoints could reach command execution through STDIO configuration, according to LiteLLM’s own security update and OX’s advisory. | Require admin-level access for dangerous paths, validate command basenames, enforce an allowlist at request parsing and runtime, and block stale DB or config entries that predate the fix. (docs.litellm.ai) |
| CVE-2026-26015 | DocsGPT | NVD describes DocsGPT versions 0.15.0 through before 0.16.0 as vulnerable to an MCP test bypass that can achieve arbitrary RCE; version 0.16.0 patched the issue. | Do server-side transport validation. Do not let request tampering activate hidden STDIO paths. (nvd.nist.gov) |
| CVE-2026-30615 | Windsurf | OX describes a prompt-injection path where attacker-controlled content could modify local MCP configuration and register a malicious STDIO server without further interaction. | Treat model-edited configuration as untrusted until reviewed. Show exact diffs and exact commands. Separate prompt handling from execution approval. (OX Security) |
| CVE-2025-49596 | MCP Inspector | GitHub and NVD describe versions below 0.14.1 as vulnerable because missing authentication between the Inspector client and proxy allowed unauthenticated requests to launch MCP commands over STDIO. | Developer tooling is still an execution surface. Bind local proxy APIs to authentication, random tokens, localhost restrictions, and patched versions. (GitHub) |
| CVE-2026-0755 | gemini-mcp-tool | ZDI and NVD describe an unauthenticated, network-reachable command injection in execAsync, scored CVSS 9.8, caused by insufficient validation before a system call. | Avoid shell-interpreting APIs for user-controlled input. Prefer argument arrays, fixed commands, strict validation, and least-privilege service accounts. (제로 데이 이니셔티브) |
| CVE-2026-25536 | MCP TypeScript SDK | GitHub and NVD describe cross-client response data leakage when a single server or transport instance is reused across multiple client connections in certain deployments. | MCP risk is broader than command execution. Session isolation and per-client transport handling are also required. (GitHub) |
| CVE-2026-33252 | MCP Go SDK | GitHub’s advisory describes cross-site tool execution for HTTP servers without authorization, where certain POST requests could reach MCP handling without a CORS preflight barrier. | HTTP transport needs Origin checks, Content-Type validation, authentication, and CSRF-aware design. (GitHub) |
LiteLLM is especially useful because its fix shows what product-level defense can look like. The LiteLLM security update says the affected paths were authenticated, not unauthenticated. It also says the fix was live in v1.83.6-nightly and first stable in v1.83.7-stable. The patch added a command allowlist for STDIO transport, Pydantic-level validation for new and updated MCP server requests, runtime re-validation for older database or config entries, and stricter role requirements for preview endpoints. That is a much stronger fix than a UI warning alone. (docs.litellm.ai)
DocsGPT illustrates a different lesson. If a UI hides STDIO but backend request handling still accepts STDIO, the attack surface remains. NVD’s record for CVE-2026-26015 says DocsGPT versions 0.15.0 to before 0.16.0 were affected and that 0.16.0 patched the issue. The remediation lesson is server-side enforcement: the accepted transport types must be validated where the request is processed, not just where the form is rendered. (nvd.nist.gov)
MCP Inspector shows that even developer-only tooling deserves production-grade local security. The advisory says versions below 0.14.1 lacked authentication between the Inspector client and proxy, allowing unauthenticated requests to launch MCP commands over STDIO. That makes the issue more than a “debug tool bug.” It demonstrates how localhost proxies, browser-accessible tools, and process launch features can combine into workstation compromise. (GitHub)
The gemini-mcp-tool case is not the same disclosure, but it belongs in the same mental model. ZDI and NVD describe CVE-2026-0755 as a command injection vulnerability in execAsync, where user-supplied input was not properly validated before a system call, allowing unauthenticated remote attackers to execute code in the service account context. That is the classic version of the same failure: untrusted input reaches a shell-capable execution sink. (제로 데이 이니셔티브)
Prompt injection becomes dangerous when it can edit execution state
Prompt injection is often discussed as if it were only a text-generation problem. That view is obsolete for tool-connected agents. OWASP’s LLM01 category describes prompt injection as manipulation of model responses through crafted inputs, including external inputs that may alter behavior. OWASP also notes that prompt injection can lead to unauthorized access, data exposure, and downstream compromise depending on the system’s agency and connected tools. (OWASP Gen AI 보안 프로젝트)
In an MCP-enabled IDE, the attacker’s goal may not be to make the model say something unsafe. The goal may be to influence a file edit, a tool selection, a configuration change, or a command launch. That is a different control problem. The model does not need to “want” to execute a malicious command. It only needs to be tricked into producing or accepting a configuration change that later reaches an execution sink.
A simplified unsafe chain looks like this:
Untrusted webpage or repo content
↓
Prompt injection influences coding assistant
↓
Assistant edits local MCP configuration
↓
MCP client trusts new STDIO server entry
↓
Client launches configured command
↓
Command runs with user or IDE privileges
A safer chain inserts review and enforcement at every transition:
Untrusted content
↓
Model output marked untrusted
↓
Config edit requires explicit diff review
↓
Server template ID must match approved registry
↓
Command and args are generated server-side
↓
Tool runs in restricted sandbox
↓
Process launch and tool output are logged
The difference between those chains is not a better system prompt. It is control architecture. Prompt injection cannot be solved reliably at the language layer alone because the model reads content that attackers can shape. The defensible pattern is to assume some malicious instruction will reach the model and then prevent that instruction from changing privileged execution state without policy enforcement.
Anthropic’s Claude Code documentation reflects part of this reality. It warns users to use third-party MCP servers at their own risk, says Anthropic has not verified the correctness or security of all servers, and calls out prompt-injection risk when MCP servers fetch untrusted content. Its security documentation also says Claude Code allows users to configure MCP servers and that Anthropic does not manage or audit those servers. (Claude)
That warning is important, but enterprise defenders need something stronger than warning text. They need a governance layer that decides which MCP servers can be installed, who can approve them, what they can access, how they are isolated, and whether tool output can influence subsequent actions.
What to audit first in a real environment
The fastest useful audit is not a Shodan search. It is an internal configuration and code-path review. Start with the places where MCP server definitions live and the places where MCP server definitions are created.
Look for local configuration files:
find "$HOME" -type f \
\( -name "mcp.json" -o -name "*mcp*.json" -o -name "*.mcp.json" \) \
2>/dev/null
For each JSON file, extract STDIO entries and inspect the command source:
jq -r '
paths as $p
| select(getpath($p) == "stdio")
| $p
' ~/.config/**/*.json 2>/dev/null
A more practical inspection command for common MCP server maps looks like this:
find "$HOME" -type f -name "*.json" 2>/dev/null \
-exec sh -c '
for file do
if jq -e ".. | objects | select(.transport? == \"stdio\" or .type? == \"stdio\" or .transport_type? == \"stdio\")" "$file" >/dev/null 2>&1; then
echo "Possible MCP STDIO config: $file"
jq ".. | objects | select(.transport? == \"stdio\" or .type? == \"stdio\" or .transport_type? == \"stdio\") | {command, args, transport, type, transport_type}" "$file" 2>/dev/null
fi
done
' sh {} +
The point is not to flag every STDIO server as malicious. The point is to build an inventory:
| Audit question | 중요한 이유 |
|---|---|
Is 명령 hardcoded by a trusted developer or editable by a user, model, API, or marketplace package | Raw command editability is the primary execution risk |
Are args constrained to a known schema | Allowed commands can still become dangerous through arguments |
| Does the server path point into a mutable workspace | Repo-controlled server paths can become code execution after checkout or pull |
| Can the model edit the config file | Prompt injection can become configuration poisoning |
| Can the app create MCP servers through an API | UI restrictions may not reflect backend behavior |
| Is the process sandboxed | Compromise impact depends on runtime privileges |
| Are secrets available in environment variables | MCP server compromise often becomes credential theft |
| Is there audit logging for process launch | Without logs, incident response becomes guesswork |
Then search the code. In Python-heavy stacks:
rg -n \
"StdioServerParameters|stdio|subprocess\.Popen|subprocess\.run|shell=True|MultiServerMCPClient" \
.
In Node and TypeScript projects:
rg -n \
"transport.*stdio|stdio.*transport|child_process|exec\(|spawn\(|mcpServers|command.*args" \
.
In YAML, JSON, and environment-driven deployments:
rg -n \
"transport_type:\s*stdio|transport:\s*stdio|MCP|mcpServers|command:|args:" \
.
Findings should be classified by data flow, not by keyword. A 명령 field in a static checked-in config may be acceptable. A 명령 field populated from an HTTP request, database row, LLM output, user profile, project file, or marketplace manifest is high risk until proven otherwise.
Safe validation patterns
The most common weak fix is to block obvious shell metacharacters. That is not enough. Shell metacharacter filters are brittle, and many bypasses do not need classic characters if the allowed executable has its own command-execution features.
A better design is template-based launch. Users choose a server type, not a command:
{
"server_id": "internal-docs",
"options": {
"index": "engineering",
"read_only": true
}
}
The backend maps that to a fixed launch template:
APPROVED_MCP_SERVERS = {
"internal-docs": {
"command": "/opt/mcp/venv/bin/python",
"args": ["/opt/mcp/servers/internal_docs.py"],
"allowed_options": {
"index": {"engineering", "support", "security"},
"read_only": {True}
}
}
}
A minimal validator should enforce the executable, path, and arguments:
from pathlib import Path
APPROVED_COMMANDS = {
"/opt/mcp/venv/bin/python": {
"allowed_scripts": {
"/opt/mcp/servers/internal_docs.py",
"/opt/mcp/servers/ticket_reader.py"
}
}
}
def validate_stdio_launch(command: str, args: list[str]) -> tuple[str, list[str]]:
resolved_command = str(Path(command).resolve())
if resolved_command not in APPROVED_COMMANDS:
raise ValueError("MCP STDIO command is not approved")
if not args:
raise ValueError("MCP STDIO server script is required")
resolved_script = str(Path(args[0]).resolve())
allowed_scripts = APPROVED_COMMANDS[resolved_command]["allowed_scripts"]
if resolved_script not in allowed_scripts:
raise ValueError("MCP STDIO server script is not approved")
for arg in args[1:]:
if arg.startswith("-c") or arg in {"--eval", "--exec"}:
raise ValueError("Dynamic code execution flags are not allowed")
return resolved_command, [resolved_script, *args[1:]]
This is still a simplified example. Production validation should be stricter and specific to each approved server. For example, a GitHub MCP server might allow a repository slug from an internal allowlist but not arbitrary URLs. A database MCP server might allow read-only query templates but not raw SQL. A browser MCP server might allow a specific domain set but not arbitrary navigation. A code-execution MCP server should run in an isolated runtime by default.
The LiteLLM patch shows a pragmatic version of this approach. It added a command allowlist, validation during request parsing, runtime re-validation, and stricter role controls around preview endpoints. That pattern acknowledges a real-world problem: configuration already stored in a database can remain dangerous after the API is patched unless runtime creation also re-checks it. (docs.litellm.ai)
Argument validation is where many fixes fail
A command allowlist is useful but incomplete. The OX Flowise and Upsonic discussion shows why: if npx 또는 npm is allowed, dangerous behavior can move from 명령 에 args. An allowlist must understand what the allowed command can do. (OX Security)
A safer policy treats each approved server as a template, not a launcher. Avoid policies like this:
{
"allowed_commands": ["python", "node", "npx", "docker"]
}
Prefer policies like this:
{
"approved_servers": {
"read-only-docs": {
"command": "/opt/mcp/venv/bin/python",
"args_exact_prefix": ["/opt/mcp/servers/docs.py"],
"options_schema": {
"workspace": ["security", "engineering"],
"mode": ["read-only"]
},
"network": false,
"filesystem": ["/srv/docs:ro"]
}
}
}
For Node-based launchers, pin the package and avoid free-form execution flags:
{
"approved_servers": {
"trusted-ticket-server": {
"command": "/usr/local/bin/node",
"args_exact": ["/opt/mcp/servers/ticket_server/dist/index.js"],
"env_allowlist": ["TICKET_API_BASE"],
"forbidden_args": ["-e", "--eval", "--require"]
}
}
}
For Docker-based launchers, do not treat “it runs in Docker” as a complete fix. Docker can reduce blast radius, but only if the container is actually constrained. A safer launch profile uses read-only filesystems, dropped capabilities, no privileged mode, no broad host mounts, and controlled egress:
docker run --rm \
--read-only \
--network none \
--cap-drop ALL \
--security-opt no-new-privileges \
--mount type=bind,src=/srv/docs,dst=/data,ro \
trusted-mcp-docs-server:1.2.3
Even then, Docker is not a substitute for command validation. It is a blast-radius reducer. If a product lets an attacker select arbitrary images, arbitrary mounts, or arbitrary Docker flags, the container becomes another command execution interface.
Detection engineering for MCP STDIO command execution
Detection should focus on three layers: configuration changes, process launch behavior, and suspicious network or file access after launch.
At the application layer, log every MCP server creation and update event with these fields:
| 필드 | Reason |
|---|---|
| actor identity | Determines whether the change was user, admin, service, or agent-driven |
| source IP and session ID | Supports investigation and correlation |
| config source | Distinguishes UI, API, import, marketplace, database migration, or model-edited file |
| transport type | Flags unexpected STDIO usage |
| command basename and resolved path | Detects dangerous or unexpected executables |
| args hash and normalized args | Allows diffing without logging secrets |
| approval event ID | Proves a real human approved high-risk execution |
| sandbox profile | Shows expected runtime restrictions |
| spawned PID and parent PID | Links configuration to endpoint telemetry |
At the endpoint layer, alert when an AI host or MCP-related process spawns shells, network utilities, scripting interpreters, archive tools, or credential-access utilities unexpectedly. A Sigma-style rule can start like this:
title: Suspicious Child Process From MCP Or AI Agent Host
id: 98d0f91a-1c1f-4f8f-9c8f-mcp-stdio-process-launch
status: experimental
description: Detects suspicious child processes spawned by common MCP or AI agent host processes.
logsource:
category: process_creation
product: linux
detection:
selection_parent:
ParentImage|contains:
- "claude"
- "cursor"
- "windsurf"
- "litellm"
- "langflow"
- "flowise"
- "mcp"
selection_child:
Image|endswith:
- "/sh"
- "/bash"
- "/zsh"
- "/curl"
- "/wget"
- "/nc"
- "/python"
- "/python3"
- "/node"
- "/npx"
- "/npm"
condition: selection_parent and selection_child
fields:
- UtcTime
- User
- Image
- CommandLine
- ParentImage
- ParentCommandLine
falsepositives:
- Approved local MCP servers launched from fixed templates
- Developer workflows that intentionally start interpreters through MCP
level: high
For Microsoft Defender-style process telemetry, a KQL query can identify suspicious parent-child relationships:
DeviceProcessEvents
| where Timestamp > ago(7d)
| where InitiatingProcessFileName has_any (
"claude", "cursor", "windsurf", "litellm", "langflow", "flowise", "mcp"
)
| where FileName in~ (
"sh", "bash", "zsh", "curl", "wget", "nc", "ncat",
"python", "python3", "node", "npx", "npm", "powershell.exe", "cmd.exe"
)
| project Timestamp, DeviceName, AccountName, InitiatingProcessFileName,
InitiatingProcessCommandLine, FileName, ProcessCommandLine, ReportId
| order by Timestamp desc
For HTTP logs, look for MCP configuration endpoints that unexpectedly include STDIO fields:
AppHttpLogs
| where TimeGenerated > ago(7d)
| where Url has_any ("mcp", "server", "connector", "tool")
| where RequestBody has_any ("\"stdio\"", "\"transport_type\"", "\"transport\"", "\"command\"", "\"args\"")
| project TimeGenerated, UserId, SourceIp, Url, StatusCode, RequestBodyHash, RequestBodyPreview
Detection should also watch for the post-execution behaviors that make MCP command injection valuable to attackers: unusual outbound HTTP from an AI service account, reads from .ssh, .env, cloud credential directories, shell history, source repositories, or token caches; unexpected archive creation; and child processes that do not match known MCP server templates.
Common mistakes that keep the bug alive
The first mistake is treating the UI as the security boundary. If the browser form hides STDIO but the API accepts STDIO, the backend is still vulnerable. The server must reject unauthorized transport types even if the frontend never renders them.
The second mistake is validating only the 명령 field. Arguments can be just as dangerous. Some launchers are designed to execute scripts, fetch packages, evaluate code, or pass command strings to other layers. A correct allowlist is semantic, not cosmetic.
The third mistake is assuming authentication makes the risk low. Authenticated RCE can still be critical when open registration exists, low-privilege users can create MCP servers, API keys are widely distributed, or a compromised user account can reach the feature. LiteLLM explicitly described CVE-2026-30623 as authenticated rather than unauthenticated, but still treated the issue seriously and patched the execution path. (docs.litellm.ai)
The fourth mistake is assuming local means safe. Local MCP servers may run with the user’s privileges. If an IDE can modify local MCP config, or if a browser can reach a local proxy, a remote attacker may still influence local execution. The MCP Inspector CVE is a concrete reminder: missing authentication in a developer proxy allowed unauthenticated requests to launch MCP commands over STDIO before version 0.14.1. (GitHub)
The fifth mistake is relying on prompt guardrails alone. Better model-side defenses reduce risk, but they do not replace execution controls. A model may refuse many malicious instructions and still sit inside an application that accepts dangerous config changes from untrusted paths.
The sixth mistake is patching the create endpoint but not the runtime loader. Old MCP server definitions may already exist in databases, config maps, project files, or user profiles. If the runtime loader still trusts those definitions, an attacker can persist a dangerous configuration before the patch and trigger it later.
A safer architecture for MCP-enabled products
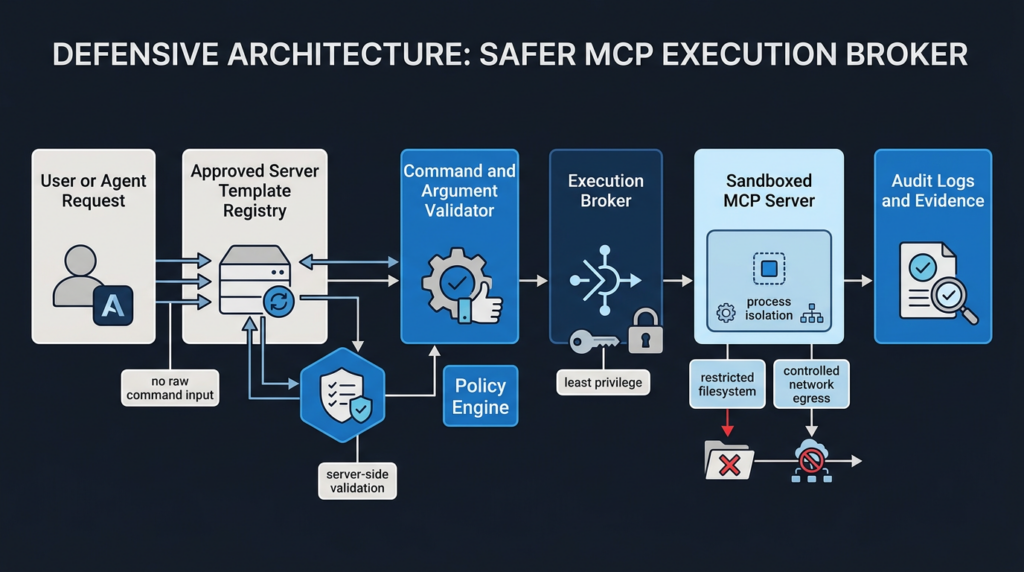
A safer MCP architecture separates user intent from process launch. Users and agents should select capabilities, not executables.
A defensible flow looks like this:
The policy engine should answer these questions before any process starts:
| Policy question | Example decision |
|---|---|
| Who requested this server | User, service account, AI agent, CI job, or imported project |
| Is this server approved for this workspace | Allow only internal registry entries |
| Is this transport allowed | STDIO allowed only for local trusted templates |
| Is the command fixed | Reject raw commands |
| Are arguments schema-valid | Reject unknown flags and free-form code |
| What secrets are available | Inject only task-specific credentials |
| What files can it read | Mount only approved paths, preferably read-only |
| Can it use the network | Deny by default, allow destination-specific egress |
| What happens on failure | Log, stop, and prevent retry loops |
| Who can approve exceptions | Require security or admin review |
A server template can be stored as code:
id: internal-docs-readonly
transport: stdio
command: /opt/mcp/venv/bin/python
args:
- /opt/mcp/servers/internal_docs.py
runtime:
user: mcp-docs
filesystem:
- source: /srv/docs
target: /data
mode: read_only
network:
mode: deny
env:
allow:
- DOCS_INDEX
approval:
required_for_install: true
required_for_each_run: false
audit:
log_process_launch: true
log_tool_calls: true
redact_env: true
The application should never accept this from an untrusted request as-is. It should load it from an internal registry or signed package source. User input should only fill narrow option fields that the template explicitly defines.
For multi-tenant hosted platforms, the execution broker should isolate tenants by runtime, filesystem, network, secrets, logs, and process identity. A compromised MCP server in one tenant should not be able to inspect another tenant’s data, reuse a shared session, read platform-wide environment variables, or connect to internal metadata endpoints. The MCP security best-practices documentation separately calls out SSRF, token passthrough, session hijacking, and scope minimization as risks, which reinforces the point that command injection is only one piece of the MCP security model. (modelcontextprotocol.io)
Continuous validation beats one-time review
MCP-heavy systems change constantly. Teams add connectors, update tool schemas, modify approval flows, install marketplace packages, change IDE policies, rotate secrets, rebuild containers, and upgrade SDKs. Every one of those changes can reopen the execution boundary.
A one-time pentest can find a dangerous path in a given state. It cannot prove that future connector changes remain safe. MCP security needs repeatable validation:
| Validation target | Example test |
|---|---|
| Config ingestion | Attempt to submit STDIO fields through every API path in an authorized test environment |
| UI and backend parity | Confirm hidden transport types are rejected server-side |
| Argument validation | Verify allowed commands cannot execute dynamic code through flags |
| Model-edited config | Confirm AI-generated edits require exact diff review and cannot silently register servers |
| Runtime isolation | Confirm MCP server cannot read unrelated files or reach blocked network destinations |
| Old config migration | Confirm pre-patch DB entries are revalidated at runtime |
| Logging | Confirm process launches and tool calls produce usable audit evidence |
| Retest | Confirm fixes stay effective after version upgrades |
This is the natural place for AI-assisted security workflows, but only when they are scoped and evidence-driven. Penligent’s public materials describe an agentic pentesting platform for security engineers, pentesters, and red teams, with support for 200+ tools, CVE-oriented testing, evidence-first results, and reproducible artifacts. In MCP environments, that kind of workflow is most useful when it is used for authorized attack-surface mapping, safe validation of connector behavior, retesting after remediation, and preserving evidence for human review rather than free-form autonomous exploitation. (펜리전트)
The important part is the evidence chain. For an MCP STDIO issue, a useful finding should show the source of untrusted influence, the configuration field it reached, the server-side validation that failed, the process that would have been launched, the privileges of that process, and the control that should block it. A screenshot of a UI field is not enough. A scanner flag is not enough. A safe, scoped, reproducible proof is what lets engineering teams fix the right boundary.
Remote HTTP MCP has its own failure modes
Do not read the OX disclosure as proof that Streamable HTTP is automatically safe. HTTP removes the local subprocess launch behavior from the client side, but it introduces its own risks: authorization mistakes, Origin validation failures, DNS rebinding, CSRF-style tool execution, session confusion, token passthrough, and exposure of local services.
The MCP transport specification explicitly warns Streamable HTTP implementers to validate the 원산지 header, bind local servers only to localhost rather than all interfaces when running locally, and implement proper authentication. It says that without these protections, attackers could use DNS rebinding to interact with local MCP servers from remote websites. (modelcontextprotocol.io)
CVE-2026-33252 in the MCP Go SDK illustrates the point. GitHub’s advisory describes cross-site tool execution for HTTP servers without authorization, where a malicious website could send certain POST requests that reached MCP message handling without a CORS preflight barrier. The fix involved validation changes, including Content-Type and origin-related protections. (GitHub)
The defensive conclusion is transport-specific, not transport-tribal:
| Transport | 주요 위험 | Required controls |
|---|---|---|
| STDIO | Local process launch can become command execution | Fixed templates, command and arg validation, explicit approval, sandboxing |
| Streamable HTTP | Remote or local HTTP endpoint can be abused | Authentication, Origin validation, Content-Type validation, CSRF defenses, session isolation |
| Local HTTP | Browser-mediated attacks and DNS rebinding | Bind to localhost, random auth token, Origin checks, no unauthenticated tool calls |
| Marketplace-installed MCP | Supply chain and tool poisoning | Signed packages, provenance, version pinning, metadata review, runtime isolation |
| IDE-managed MCP | Prompt injection into config or tool selection | Diff review, exact command display, model-output distrust, workspace trust gates |
Security teams should not ask “Which transport is safe?” They should ask “Which trust boundary does this transport move, and what enforces it?”
Incident response when MCP STDIO RCE is suspected
If you suspect MCP STDIO command execution, preserve evidence before making broad changes. The first priority is to identify the parent process, spawned child processes, configuration source, and credentials available to the runtime.
A practical response sequence:
- Capture current MCP configurations from known paths, application databases, container environment variables, and project-level settings.
- Export process creation logs for AI hosts, MCP processes, IDEs, connector services, and agent platforms.
- Identify recent MCP server create, update, test, preview, import, or marketplace install events.
- Review child processes spawned by the affected parent process during the suspicious window.
- Check whether secrets were available in environment variables, mounted files, cloud metadata, local credential stores,
.envfiles, SSH keys, or API token caches. - Review outbound network connections from the affected process and any unexpected archive or staging files.
- Disable dynamic STDIO server creation while preserving logs and configuration artifacts.
- Rotate credentials that were reachable from the compromised runtime.
- Patch affected products and revalidate old stored configurations at runtime.
- Add regression tests so the same data flow cannot be reintroduced.
For Linux hosts, process lineage can often tell the story:
ps -eo pid,ppid,user,comm,args --forest | rg -i "mcp|claude|cursor|windsurf|litellm|langflow|flowise|python|node|npx"
If auditd is enabled, review executions by parent process:
ausearch -m EXECVE --start recent | aureport -x --summary
For containerized services, inspect mounts and environment exposure:
docker inspect <container_id> \
--format '{{json .Mounts}} {{json .Config.Env}} {{json .HostConfig.NetworkMode}}' \
| jq
Avoid immediately deleting suspicious configuration files. Copy them to an evidence location, hash them, and then remove or disable the runtime path. The configuration may be the only artifact that proves how untrusted influence reached command execution.
What developers should change in code review
Every MCP-related code review should include an execution-boundary checklist. The reviewer should treat MCP server registration like they would treat dynamic plugin loading or CI runner configuration.
Review questions for Python:
Does user input reach StdioServerParameters.command?
Does user input reach StdioServerParameters.args?
Does any path use shell=True?
Does the code accept transport or transport_type from requests?
Does the code rehydrate MCP server definitions from a database?
Are old stored definitions revalidated?
Does the runtime execute under a least-privilege user?
Review questions for Node:
Does the code call child_process.exec with untrusted input?
Does it allow npx, npm, node -e, or dynamic package names?
Can project files define MCP servers without trust confirmation?
Can a model or tool response write to MCP config?
Are MCP server definitions signed, pinned, or reviewed?
Review questions for web platforms:
Can non-admin users create MCP servers?
Can open registration reach MCP configuration?
Can a request change transport type to stdio?
Are preview or test endpoints as restricted as create endpoints?
Are command and args validated both at request time and runtime?
Are failed MCP connection attempts logged with enough detail?
A strong code review should produce an explicit decision: approved fixed template, approved with sandbox restrictions, blocked until validation is added, or disallowed entirely.
The right way to talk about Anthropic’s role
It is fair to say that OX claims Anthropic treated the behavior as expected and declined to modify the protocol architecture. It is also fair to say the MCP specification and security documentation contain real warnings about local server compromise, prompt injection risk, consent, sandboxing, and HTTP transport protections. Both facts can be true. (OX Security)
A technically honest article should not reduce the issue to “Anthropic shipped a bug and refused to patch it” without qualification. The more accurate statement is that MCP STDIO includes a process-launch model; OX argues that the model creates an unsafe default when downstream products expose raw configuration; Anthropic and some maintainers appear to frame the behavior as expected or developer responsibility; multiple downstream products nevertheless produced real CVEs from the same execution pattern.
For defenders, the allocation of blame is less useful than the allocation of controls. If you own an MCP-enabled product, you own the point where configuration becomes execution. If you operate MCP-enabled infrastructure, you own the runtime privileges and logs. If you allow AI tools to edit project or user configuration, you own the approval boundary. If you install third-party MCP servers, you own the supply chain and sandbox.
실용적인 강화 체크리스트
Use this checklist as an engineering baseline:
| 제어 | Minimum acceptable state |
|---|---|
| Dynamic STDIO creation | Disabled unless explicitly required |
| Command source | Fixed server-side template only |
| Argument source | Schema-defined, validated, and command-specific |
| Transport type | Server-side allowlist, not UI-only |
| Roles | MCP server creation limited to trusted admins |
| Preview endpoints | Same or stricter authorization than create endpoints |
| Runtime loader | Revalidates stored configs before every launch |
| Existing configs | Migrated, reviewed, and invalidated if unsafe |
| Local IDE config | Exact diff and exact command shown before approval |
| Model-edited files | Treated as untrusted until reviewed |
| Marketplace servers | Signed, pinned, reviewed, and isolated |
| Filesystem | Read-only and narrow by default |
| 네트워크 | Deny by default or destination allowlist |
| 비밀 | Inject task-specific credentials only |
| Process identity | Dedicated low-privilege user |
| 로그 | Config change, approval, process launch, and tool call audit |
| 탐지 | Parent-child process rules and API request monitoring |
| Retesting | Regression tests for every fixed path |
The strongest single design rule is this: no untrusted actor should ever provide an executable command. Not a browser user. Not a low-privilege tenant. Not a project file. Not a tool response. Not an LLM. Not a marketplace package. Not a request body. Not a database row created before validation existed.
The bottom line
MCP is not doomed. STDIO is not automatically a vulnerability. Local tools are not inherently unsafe. The failure happens when a system lets untrusted influence cross into process launch without an enforcement layer.
The OX disclosure matters because it exposed the same boundary failure across multiple products, multiple workflows, and multiple CVEs. UI injection, hardening bypass, IDE prompt injection, hidden backend STDIO, unauthenticated local proxies, and classic command injection all rhyme. They are different ways of saying the same thing: agent infrastructure is privileged middleware, and privileged middleware must not confuse configuration with permission.
Security teams should stop asking only whether the model can be tricked. The better question is sharper: if the model, a user, a webpage, a package, or an API request is tricked, can that influence reach an execution boundary?
If the answer is yes, the system is not ready. Constrain the configuration. Remove raw command input. Validate at the server. Revalidate at runtime. Isolate the process. Log the evidence. Retest after every change.
참고 자료 및 추가 자료
OX Security, The Architectural Flaw at the Core of Anthropic’s MCP. (OX Security)
OX Security, MCP STDIO Command Injection, Full Vulnerability Advisory. (OX Security)
OX Security, The Mother of All AI Supply Chains, Technical Deep Dive. (OX Security)
Model Context Protocol, Transports specification. (modelcontextprotocol.io)
Model Context Protocol, Security Best Practices. (modelcontextprotocol.io)
Anthropic, Introducing the Model Context Protocol. (인류학)
Claude Code documentation, MCP and security. (Claude)
LiteLLM security update for CVE-2026-30623. (docs.litellm.ai)
NVD entry for CVE-2026-26015 in DocsGPT. (nvd.nist.gov)
GitHub and NVD entries for CVE-2025-49596 in MCP Inspector. (GitHub)
ZDI and NVD entries for CVE-2026-0755 in gemini-mcp-tool. (제로 데이 이니셔티브)
GitHub and NVD entries for CVE-2026-25536 in the MCP TypeScript SDK. (GitHub)
GitHub and CVE record coverage for CVE-2026-33252 in the MCP Go SDK. (GitHub)
OWASP GenAI Security Project, LLM01 Prompt Injection. (OWASP Gen AI 보안 프로젝트)
Penligent, Anthropic MCP Vulnerability, 7000 Servers, and the Case for Continuous Red Teaming. (펜리전트)
Penligent, Deep Analysis of gemini-mcp-tool Command Injection CVE-2026-0755. (펜리전트)
Penligent, Pentest AI Agents, Real Tool Execution Is the Line Between AI Pentesting and a Toy. (펜리전트)
Penligent homepage. (펜리전트)