GitHub now has an official tutorial called “Vibe coding with GitHub Copilot.” It describes a workflow where you can create an application “without writing any code yourself,” but it also quietly places that workflow in a narrow box: proof of concept work, early drafts, and personal-use applications. The same tutorial is explicit that experienced developers usually use Copilot differently, as a tool for problem solving and productivity rather than a mode where chat does all the work. Even in that tutorial, the workflow is not magic. It includes research, planning, building, testing, iteration, and project hardening. In other words, the mainstream version of vibe coding is already less “just trust the vibes” than its reputation suggests. (GitHub Docs)
That gap between rhetoric and reality is where the security problem starts. The danger is not that a model can write code. The danger is that teams start treating generated code, generated infrastructure changes, generated config, generated tests, and generated tool wiring as if generation itself were validation. That assumption collapses especially fast in production systems that handle authentication, authorization, customer data, money movement, or external tools. The faster the system changes, the less useful occasional review becomes, and the more valuable continuous verification becomes. (GitHub Docs)
Bram Cohen’s recent essay put the criticism in the bluntest possible way. He argued that “pure” vibe coding is mostly a myth because the machine still depends on human-created framework elements such as plan files, skills, and rules, and because AI is not good at spontaneously noticing structural mess without being shown what to look for. His deeper point was more useful than the headline: AI can be strong at cleanup and refactoring when a human first identifies the mess, explains the categories, and constrains the task. Bad software, in his framing, is not an unavoidable side effect of AI. It is a choice made by teams that stop doing the work of judgment. (Bram Cohen)
That same logic applies to security. AI-generated software does not become dangerous because a model touched it. It becomes dangerous when the surrounding engineering system stops demanding proof. If the codebase, route graph, dependency set, agent instructions, repository rules, and tool permissions are changing faster than humans can hold them in working memory, then security has to move from occasional review to continuous pentesting. Not continuous scanning alone. Not a quarterly red team ritual. Continuous pentesting: stateful, evidence-backed, repeatable validation of the attack paths that matter as the system keeps moving. (csrc.nist.gov)
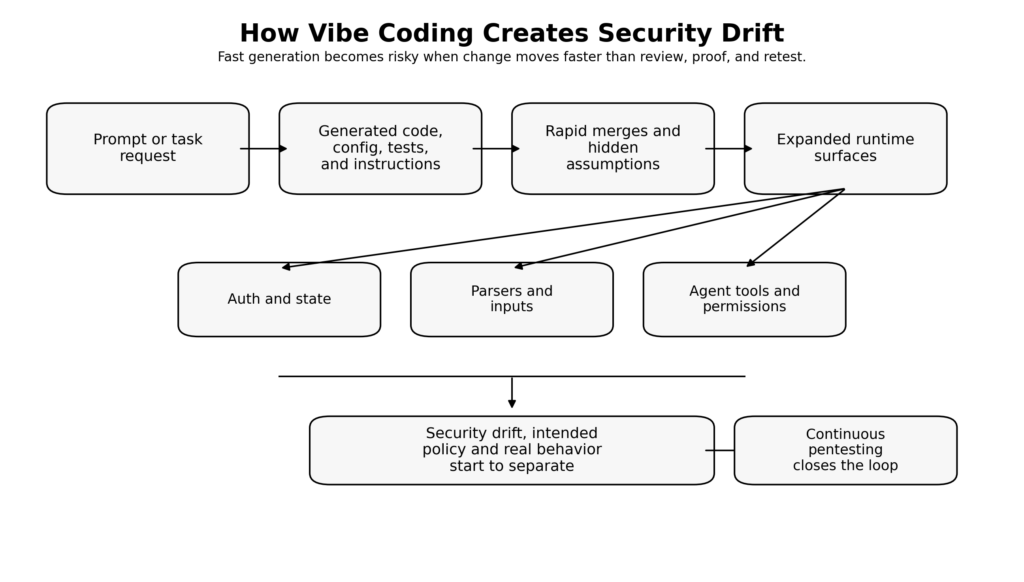
Vibe Coding Is Already a Structured Workflow, Whether Teams Admit It or Not
One of the most useful parts of Cohen’s essay is the claim that the machine “works very poorly without being given a framework.” That statement lines up with what the official vendor documentation says. Anthropic tells users to give Claude persistent context through CLAUDE.md, to keep that file concise enough to matter, to configure permissions and sandboxing, and to follow an explicit sequence of explore, plan, implement, and verify. Anthropic’s docs go even further and call verification the single highest-leverage thing you can do, warning that without tests, screenshots, or expected outputs, the model may produce something that looks right but does not actually work. (Bram Cohen)
OpenAI’s Codex best-practices documentation lands in almost exactly the same place. It recommends planning first for difficult tasks, defining how work will be verified, turning repeatable workflows into skills, and reviewing diffs against bugs, regressions, and risky patterns. Its agent-safety guidance says prompt injection is a common and dangerous risk, advises keeping tool approvals on, recommends using guardrails for user inputs, and says untrusted data should not directly drive agent behavior. It specifically recommends extracting only specific structured fields from external inputs to reduce the chance that arbitrary text flows into action-taking behavior. (OpenAI Developers)
GitHub’s Copilot documentation is just as clear. The responsible-use pages say Copilot-generated code can expose sensitive information or introduce vulnerabilities if not used carefully, and repeatedly tell users to review and test outputs thoroughly before merging. The CLI documentation says users are responsible for validating responses, warns that commands can be destructive, and describes permission controls that restrict the agent to the current directory, require approval for file changes, and require review before dangerous commands run. Its cloud-agent documentation says GitHub uses a firewall to help prevent data exfiltration and runs CodeQL, secret scanning, and dependency analysis on generated changes, which is effectively an admission that agent-generated output needs layered controls even before a human sees it. (GitHub Docs)
The important takeaway is not that Anthropic, OpenAI, and GitHub are pessimistic. It is the opposite. These are companies pushing agentic coding hardest, and their guidance still assumes planning, scoped tasks, approval boundaries, review, verification, and iteration. The “vibe” story that matters in real production use is already surrounded by structure. Security teams should notice that. If the product teams around them are talking as if AI coding means fewer controls, they are already further out on the risk curve than the tool vendors themselves recommend. (Claude)
The Security Problem Is Not Faster Code, It Is Faster Change
Traditional AppSec programs were built around a slower idea of change. Developers wrote code by hand, pull requests were relatively bounded, and the places worth reviewing were mostly obvious: code diffs, new dependencies, exposed endpoints, infrastructure configuration, and deployment artifacts. That model was never perfect, but it gave human reviewers and scheduled pentests some chance of keeping up.
Vibe coding changes the unit of change. The risky artifact is no longer just a code diff. It can also be a new agent instruction file, a changed repository rule, a broader allowlist, a connector added to an AI workflow, a browser automation permission, a one-line “temporary” shell wrapper, a new generated test that encodes the wrong assumptions, or a refactor that preserves output on the happy path while silently breaking authorization or state transitions elsewhere. Anthropic’s CLAUDE.md, OpenAI’s AGENTS.md and skills, GitHub’s custom instructions, agent settings, firewall controls, hooks, and MCP configuration are all examples of this shift. They are not code in the narrow sense, but they are part of what the system now is. (Claude)
This is why occasional review degrades so quickly in AI-heavy workflows. Point-in-time review assumes that a human can sample the important places often enough to maintain an accurate mental model. That assumption weakens when AI can generate, rework, and extend the system faster than the team can reason about all of its edges. The result is not just more bugs. It is more drift: between intended policy and implemented logic, between route assumptions and actual reachable behavior, between scoped tokens and effective capabilities, and between what a team thinks its agent can do and what its runtime actually allows. (csrc.nist.gov)
Continuous pentesting matters because it accepts that drift as normal. NIST SP 800-115 describes technical security testing as planning and conducting tests, analyzing findings, and developing mitigation strategies, while OWASP’s current Web Security Testing Guide explicitly places security testing inside development workflows and maintenance and operations. Read together, they imply something many teams still resist: if the application is changing continuously, then the testing and evidence loop has to be maintained continuously too. (csrc.nist.gov)
Classic Web Flaws Still Win in AI-Generated Apps
A common mistake in AI security conversations is to jump straight to novel agent risks and forget that most real damage still comes from old classes of defects. AI-generated software does not escape SQL injection, broken authorization, parser abuse, deserialization problems, or unsafe input handling. In many cases it makes those defects easier to ship, because generated code is often optimized for plausible completion and functional appearance, not adversarial completeness. Research on AI-generated code keeps landing in that uncomfortable middle ground. Pearce and coauthors found that roughly 40 percent of Copilot completions in security-relevant scenarios were vulnerable, and Perry and coauthors found that participants using an AI assistant wrote less secure code and were more likely to believe their code was secure. A newer large-scale analysis of public GitHub repositories found that most explicitly attributed AI-generated files were free of detectable CWE-mapped weaknesses, but still identified thousands of CWE instances across 7,703 files and 77 vulnerability types, which is a reminder that “most files are fine” and “production risk is acceptable” are not the same claim. (arXiv)
The right lesson is not that AI-generated code is always insecure. It is that security outcomes are mixed, context-sensitive, and easy to overtrust. The research and vendor documentation point in the same direction: do not argue from syntactic plausibility. Verify the behavior that matters. (arXiv)
CVE-2023-34362 in MOVEit Transfer is still one of the cleanest reminders of how old defects keep dominating outcomes. NVD describes it as a SQL injection vulnerability in the MOVEit Transfer web application that could let an unauthenticated attacker access the application database, and notes that exploitation happened in the wild through HTTP or HTTPS. This is exactly the kind of bug that AI-assisted teams can still ship if they treat generated data-access logic as “good enough” once a functional workflow appears to work in staging. The defensive lesson is straightforward: continuous pentesting has to keep testing injection conditions, not because SQLi is new, but because every fast refactor, generated wrapper, or framework migration can reintroduce it. (nvd.nist.gov)
CVE-2025-29927 in Next.js is just as relevant for a different reason. NVD says it was possible to bypass authorization checks within a Next.js application when the authorization check occurred in middleware, and notes that if immediate patching was infeasible, a temporary mitigation was to block external requests carrying the x-middleware-subrequest header. That is a perfect example of a flaw class that looks modern and framework-specific but is really about misplaced trust boundaries. When teams let models refactor routing, middleware, and auth flow glue code without continuously replaying authorization checks, they are relying on the appearance of architectural neatness instead of proof. (nvd.nist.gov)
Adobe Commerce’s CVE-2024-34102 adds another lesson. Adobe’s bulletin says the update resolved critical and important vulnerabilities, that successful exploitation could lead to arbitrary code execution, security feature bypass, and privilege escalation, and that Adobe was aware of in-the-wild exploitation of CVE-2024-34102. NVD describes that issue as an XXE vulnerability exploitable through a crafted XML document without user interaction. The relevance here is not only that parser bugs still matter. It is that systems assembled quickly through generated glue code often inherit dangerous assumptions around file handling, parser invocation, and protocol boundaries that never show up in the happy path demo. (Adobe Aide)
Citrix NetScaler’s CVE-2026-3055 shows how little time defenders get once an internet-facing validation flaw becomes visible. NVD describes it as insufficient input validation in NetScaler ADC and Gateway, leading to memory overread when configured as a SAML identity provider, gives it critical severity, and notes that it is in CISA’s Known Exploited Vulnerabilities Catalog. The reason to mention it in a vibe coding discussion is not because most teams are writing appliances. It is because the exposure pattern is the same: once trust in an input path is misplaced, public exposure compresses the time between disclosure and exploitation. Continuous pentesting exists partly to keep teams from discovering that mistake only after the internet does. (nvd.nist.gov)
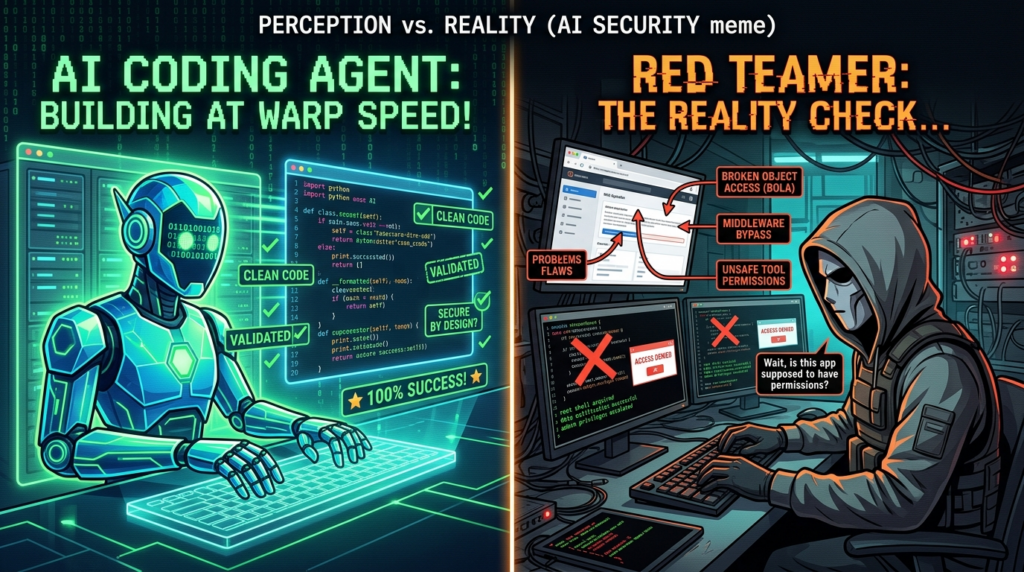
Authorization and Business Logic Are Where Vibe-Coded Systems Drift First
The bugs that hurt most in modern web apps are often not the ones easiest to detect with static patterns. OWASP’s API Security Top 10 still opens with Broken Object Level Authorization and explains why: APIs expose endpoints that handle object identifiers across a broad attack surface, and object-level authorization checks have to be considered in every function that accesses a data source using a user-supplied ID. The OWASP Web Security Testing Guide still dedicates major sections to authorization, session management, input validation, business logic testing, and API testing. That is not a historical artifact. It reflects the fact that modern applications fail at boundaries and state, not just at syntax. (OWASP)
This matters even more in AI-assisted development. Models are strong at completing obvious structural patterns. They are weaker at negative space: which role should fail here, which object should not be reachable there, which state transition should remain impossible after a refactor, which cached token should expire before a second action, which tenant boundary should survive a shortcut introduced for developer convenience. Those are exactly the places where code can look elegant and still be unsafe. The model may produce a clean middleware, a neat service class, and passing unit tests, while the actual application behavior still violates authorization intent. (Claude)
This is the point where continuous pentesting starts to look different from continuous scanning. A scanner can tell you that a route exists or that a library version is exposed. A pentest loop has to preserve state, switch identities, replay flows, compare object access across roles, watch side effects, and keep enough evidence to explain not only that a request succeeded, but why that success violated policy. The real regression asset in an AI-heavy shop is not just a unit test. It is a reusable stateful test of security intent. (csrc.nist.gov)
The simplest way to think about it is this: if a model helped you generate or rework the logic, your job is to verify the refusal path, not just the success path. Did the wrong user get a 403 every time? Did the object boundary hold after the schema changed? Did middleware assumptions still hold after a route moved? Did the agent-generated test suite actually cover state mutation, or just response formatting? Those are pentest questions, not prompt questions.
Prompt Injection Turns Coding Agents into Runtime Risk
The moment an AI system can browse, read external content, call tools, or act on behalf of a user, the security conversation expands beyond code quality. OpenAI’s prompt-injection write-up says the effective real-world versions of these attacks increasingly resemble social engineering rather than simple “ignore previous instructions” strings, and argues that defense cannot rely only on filtering inputs. The system has to be designed so the impact of manipulation is constrained even if some attacks succeed. OpenAI frames the problem as a three-actor system in which the agent acts on behalf of its employer while continuously exposed to external input that may mislead it, so limitations on capability are necessary to bound downside risk. (OpenAI)
That framing is extremely useful for continuous pentesting because it redirects attention from model cleverness to control design. The important question is no longer “Can the agent recognize a malicious string?” It becomes “What dangerous action is reachable if the agent is manipulated?” OpenAI’s agent-safety docs answer that in practical terms: keep tool approvals on, use guardrails, avoid letting untrusted data directly drive behavior, and extract only specific structured fields from external inputs where possible. That is not model worship. It is classic control-plane design translated into agent systems. (OpenAI Developers)
OWASP’s GenAI guidance uses similar language. Its prompt-injection materials describe attacks that manipulate model behavior and can lead to unauthorized actions, data leakage, or bypass of intended rules. That means a vibe-coded application with an embedded agent is not only an application-security problem. It is a runtime trust-boundary problem. Every external document, webpage, email, repository issue, or tool response is now part of the attack surface if the system allows that content to influence actions. (OWASP Gen AI 보안 프로젝트)
In practice, that changes what continuous pentesting has to test. You are not just testing routes and parameters anymore. You are testing sources and sinks. What untrusted content can reach the model? What tool calls can the model make? What data can it send outward? What approvals are required? What happens when the user, the model, and the external system all disagree about intent? Those tests belong in the same lifecycle as auth and business-logic retests, because they are now part of the same product.
The OpenAI Codex Incident Made This Concrete
The BeyondTrust Phantom Labs disclosure on OpenAI Codex is one of the clearest public examples of why agentic coding security cannot stop at source code review. BeyondTrust said it found a command injection vulnerability in OpenAI Codex’s cloud environment that exposed GitHub credential data, allowing arbitrary commands to be injected through the GitHub branch name parameter. It said the issue affected the ChatGPT website, Codex CLI, Codex SDK, and Codex IDE extension, and that the disclosed issues were remediated with OpenAI. BeyondTrust also described an automated version of the attack in which a malicious branch name could exfiltrate GitHub OAuth tokens from multiple users who interacted with the repository through Codex, and it recommended treating agent containers as strict security boundaries and minimizing token permissions and lifetimes. (BeyondTrust)
The technical details matter, but the design lesson matters more. A branch name looks like metadata. In an agentic workflow it became execution context. That is exactly the kind of boundary collapse continuous pentesting is supposed to catch. If you only review generated code, you miss the runtime chain: repository metadata flows into task creation, task creation flows into shell context, shell context has access to tokens, tokens can move laterally into GitHub. The exploit path exists across the seams between systems, not inside a single obvious code snippet. (BeyondTrust)
That incident also reinforces why “trust but review” is not enough when permissions and automation scale up. GitHub’s own Copilot CLI docs explain that autopilot mode often involves granting broad permissions so the agent can complete tasks autonomously. Anthropic’s docs warn that repeated permission prompts degrade real attention after enough approvals. OpenAI recommends keeping approvals on for tool calls. Put those together and you get the real operational problem: approval fatigue is not just a usability nuisance. It is a security failure mode. (GitHub Docs)
Continuous Pentesting Starts with a Control Plane
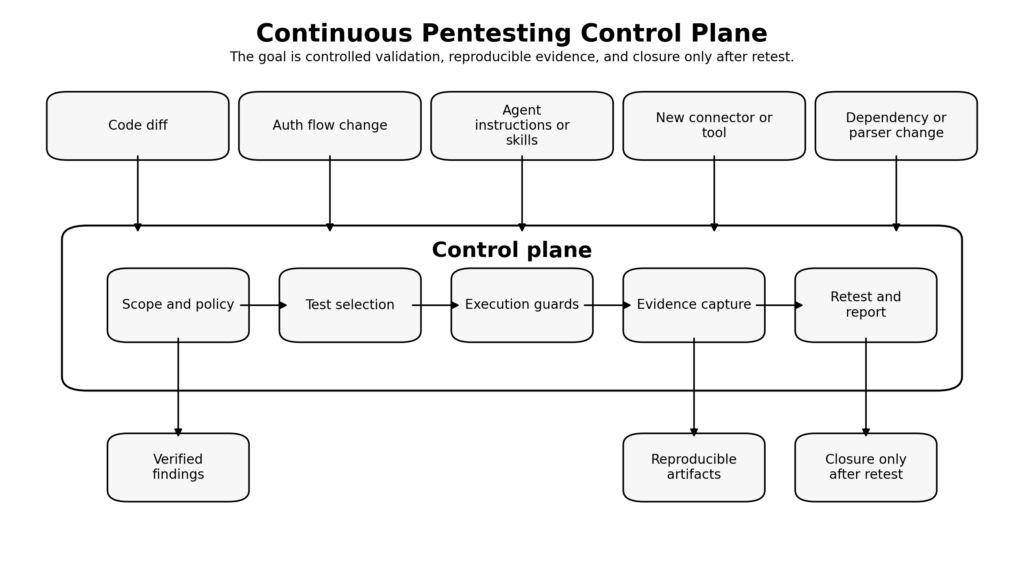
If vibe-coded software changes too quickly for occasional understanding, then the answer is not simply “run more tools.” The answer is to build or adopt a control plane for offensive validation. That control plane should define scope, identities, credential policy, allowed actions, rate limits, stop conditions, evidence requirements, approval boundaries, and retest triggers. The reason to call it a control plane is deliberate: the point is not only to find bugs, but to control how bugs are searched for, how proof is captured, and how risk is replayed after a change.
NIST SP 800-115 is useful here because it treats testing as a managed process of planning, execution, analysis, and mitigation, not as disconnected tool output. OWASP WSTG is useful because it integrates security tests into development workflows and maintenance and operations rather than leaving them as a one-off specialty exercise. The vendor docs are useful because they point to the same engineering truth from the opposite direction: agentic systems need scopes, plans, reviews, approvals, and verification. (csrc.nist.gov)
A workable control plane for continuous pentesting in AI-heavy teams usually includes five things.
First, change awareness. The system has to know what changed and why it matters. That means not only source files, but also route definitions, auth middleware, model instructions, skills, hooks, tool allowlists, and external connectors.
Second, stateful test selection. A login refactor should not trigger the same checks as a CSS tweak. Auth and object-access changes should automatically pull in role-matrix and workflow-replay tests. New parser or upload logic should pull in malicious input cases. New external tools or browser-use features should trigger prompt-injection and exfiltration scenarios.
Third, execution constraints. Tool approvals, sandboxes, bounded tokens, rate limits, egress controls, and stop conditions are not optional maturity features. They are what keep the testing system from becoming its own incident.
Fourth, artifact capture. If you cannot preserve the request, response, identity, environment, and version context that produced a finding, you do not really have a continuous pentest loop. You have a repeating rumor.
Fifth, retest discipline. A finding is not closed because a developer says it is fixed. It is closed when the same test path fails in the correct way under the updated build and the evidence store records that change. (펜리전트)
Teams that do not want to build all of that plumbing from scratch usually end up searching for a workflow layer that can preserve scope, approvals, evidence, and retest history while still supporting active offensive validation. That is the problem space Penligent’s recent technical writing is aimed at: not a chat wrapper around scanners, but an evidence-driven pentest workflow that keeps context, validates attack paths, and treats reporting as the end of a reproducible chain rather than the generation of a pretty PDF. (펜리전트)
Where Vibe Coding Fails, and What Continuous Pentesting Must Check
| Failure pattern | What changed in practice | Why code review misses it | What continuous pentesting should do | Required evidence |
|---|---|---|---|---|
| Happy-path coding | The feature works for the intended user | Reviewers see success, not refusal | Replay denied paths and negative-role cases | Request and response pairs across identities |
| Middleware trust | Auth moved into a neat shared layer | Architecture looks cleaner than behavior | Re-test protected routes with header, state, and direct object access variants | Route map plus auth-matrix results |
| Generated parser glue | XML, file, or data-transform code was assembled quickly | Parser setup looks incidental, not dangerous | Re-run malformed-input and desync cases after every parser-related change | Inputs, parser config, resulting error behavior |
| Agent tool expansion | New connector or tool approval added | The risky behavior lives in config and runtime, not code alone | Test prompt injection, data exfil paths, and approval logic | Tool-call trace, approval record, outbound destinations |
| Fast refactor drift | Business logic moved without changing UI | Unit tests still pass on normal flows | Re-run workflow state transitions and side-effect checks | Session timeline, object states before and after |
| Autopilot permissions | Agent gained broad command or file rights | The permission change may be one line or a toggle | Validate sandbox boundaries and destructive-command safeguards | Permission set, executed commands, denied operations |
| Report-first culture | AI can write polished findings fast | Teams mistake narrative quality for proof | Regenerate findings from raw artifacts and retest before closure | Artifact manifest, reproduction steps, retest result |
The table is intentionally boring. Good security control planes are boring. They turn fashionable failure modes back into ordinary engineering checks. That is exactly what vibe-coded systems need.
A CI Gate for AI-Generated Code
GitHub’s own cloud agent documentation says it uses CodeQL, secret scanning, and dependency analysis when generating code, and its responsible-use docs repeatedly say outputs must be reviewed and tested before merge. The practical lesson is not to copy GitHub’s internal implementation exactly. It is to mirror the layered posture: code quality checks, security scanning, artifact retention, and a human decision point before risky changes ship. (GitHub Docs)
Here is a simple example of what that can look like in a real repository. The structure is more important than the exact tool choices.
name: ai-change-security-gate
on:
pull_request:
branches: [main]
jobs:
classify-change:
runs-on: ubuntu-latest
outputs:
auth_or_api: ${{ steps.flags.outputs.auth_or_api }}
high_risk: ${{ steps.flags.outputs.high_risk }}
steps:
- uses: actions/checkout@v4
- id: flags
run: |
CHANGED="$(git diff --name-only origin/${{ github.base_ref }}...HEAD)"
echo "$CHANGED"
if echo "$CHANGED" | grep -E '(auth|middleware|session|api|routes|permissions|agent|prompt|mcp|connector)'; then
echo "auth_or_api=true" >> $GITHUB_OUTPUT
else
echo "auth_or_api=false" >> $GITHUB_OUTPUT
fi
if echo "$CHANGED" | grep -E '(auth|payments|admin|secrets|agent|mcp|connector)'; then
echo "high_risk=true" >> $GITHUB_OUTPUT
else
echo "high_risk=false" >> $GITHUB_OUTPUT
fi
unit-and-integration:
runs-on: ubuntu-latest
needs: classify-change
steps:
- uses: actions/checkout@v4
- run: make test
static-security:
runs-on: ubuntu-latest
needs: classify-change
steps:
- uses: actions/checkout@v4
- run: make semgrep
- run: make codeql
- run: make secret-scan
- run: make dependency-check
stateful-auth-replay:
runs-on: ubuntu-latest
needs: classify-change
if: needs.classify-change.outputs.auth_or_api == 'true'
steps:
- uses: actions/checkout@v4
- run: python tests/security/replay_auth_matrix.py
- uses: actions/upload-artifact@v4
with:
name: auth-replay-artifacts
path: artifacts/auth-replay/
staging-dast:
runs-on: ubuntu-latest
needs: [unit-and-integration, static-security]
steps:
- uses: actions/checkout@v4
- run: make deploy-staging
- run: make dast-baseline
- uses: actions/upload-artifact@v4
with:
name: dast-artifacts
path: artifacts/dast/
manual-approval:
runs-on: ubuntu-latest
needs: [staging-dast, stateful-auth-replay]
if: needs.classify-change.outputs.high_risk == 'true'
environment:
name: security-review
steps:
- run: echo "Security reviewer approves or rejects based on artifacts."
merge-gate:
runs-on: ubuntu-latest
needs: [unit-and-integration, static-security, staging-dast, manual-approval]
if: always()
steps:
- run: |
test "${{ needs.unit-and-integration.result }}" = "success"
test "${{ needs.static-security.result }}" = "success"
test "${{ needs.staging-dast.result }}" = "success"
The key design choices are diff-awareness, explicit high-risk branches, artifact upload, and a separate stateful replay path for auth- and agent-related changes. Most teams already know how to run SAST or DAST in CI. The harder discipline is deciding which kinds of changes deserve stateful retests and human review even when the normal pipeline is green. That is where AI-assisted development breaks older assumptions. A clean diff is no longer a reliable proxy for low risk. (OWASP)
Stateful Testing for Authorization and Business Logic
If OWASP’s API1 risk still says object-level authorization must be considered in every function that accesses data using a user-supplied ID, then continuous pentesting needs a cheap way to keep replaying those checks. That does not require a giant framework to start. A small role-and-object diff harness already catches classes of regressions that scanners and unit tests routinely miss. (OWASP)
Here is a minimal example.
# Authorized testing only. Point this at a staging environment you control.
import json
import requests
from pathlib import Path
BASE_URL = "https://staging.example.internal"
OBJECT_IDS = ["1001", "1002", "1003"]
TOKENS = {
"admin": "ADMIN_TOKEN_HERE",
"manager": "MANAGER_TOKEN_HERE",
"user": "USER_TOKEN_HERE",
}
def fetch(role, object_id):
r = requests.get(
f"{BASE_URL}/api/projects/{object_id}",
headers={"Authorization": f"Bearer {TOKENS[role]}"},
timeout=10,
)
try:
body = r.json()
except Exception:
body = {"raw": r.text[:500]}
return {
"role": role,
"object_id": object_id,
"status": r.status_code,
"body_keys": sorted(list(body.keys())) if isinstance(body, dict) else [],
"body": body,
}
def main():
results = []
for object_id in OBJECT_IDS:
per_object = [fetch(role, object_id) for role in TOKENS]
results.extend(per_object)
artifacts = Path("artifacts/auth-replay")
artifacts.mkdir(parents=True, exist_ok=True)
out = artifacts / "role_object_results.json"
out.write_text(json.dumps(results, indent=2))
# crude regression signal
for object_id in OBJECT_IDS:
subset = [r for r in results if r["object_id"] == object_id]
allowed = [r for r in subset if r["status"] == 200]
if len(allowed) > 1:
print(f"[!] Multiple roles accessed object {object_id}: {[x['role'] for x in allowed]}")
if __name__ == "__main__":
main()
The point of this script is not that it is sufficient. It is that it turns authorization into a replayable asset. Once you have a stable matrix of roles, objects, and expected outcomes, every auth-adjacent refactor becomes testable in the same language as the risk. That matters because vibe-coded changes often fail not in the visible UI, but in the relationship between role, object, and state. (OWASP)
The same pattern works for business logic. You can encode workflows such as “user creates invoice, manager approves, finance exports, admin archives” and keep replaying those steps after every major change. What makes this pentesting instead of generic QA is the intent: the goal is not only to ensure the workflow succeeds, but to prove that the wrong actor cannot take the same state transitions, that cross-tenant objects stay isolated, and that side effects do not leak across roles.
Evidence, Retest, and the Difference Between a Finding and a Story
Continuous pentesting fails when evidence is treated as an afterthought. A nice-looking AI-generated report is not proof. A convincing narrative is not proof. Even a successful exploit once, without preserved context, is only weak proof if the team cannot reproduce it after the next build.
That is why evidence manifests matter. A structured artifact record gives the next retest cycle something precise to consume.
{
"finding_id": "AUTH-BOLA-0042",
"scope_id": "staging-2026-04-auth",
"commit_sha": "9f3a12c",
"environment": "staging",
"test_identity": "manager-role-token",
"affected_object": "project-1002",
"request_hash": "sha256:3b3f...",
"response_hash": "sha256:8e91...",
"artifacts": {
"request": "artifacts/requests/project-1002-manager.txt",
"response": "artifacts/responses/project-1002-manager.json",
"screenshot": "artifacts/screens/project-1002-manager.png"
},
"expected_security_outcome": "403 forbidden",
"observed_outcome": "200 ok with full object body",
"reproduction_steps_version": "v3",
"status": "open",
"retest_status": "pending"
}
Once you store findings like this, “fixed” becomes a concrete state change rather than a human feeling. The next retest can replay the same request against the new build, compare the new response hash and status, and move the finding only when the expected security outcome is actually restored.
That same discipline is what separates an AI pentest report from an AI-generated document. Penligent’s recent reporting piece makes the same point from another angle: a useful AI pentest report is one that can survive retest, because the real problem is not writing a PDF but turning evidence into something another human can verify, prioritize, and act on. That standard should apply to vibe-coded systems too. If the report cannot be regenerated from artifacts and the finding cannot be rechecked after a fix, the team is managing words, not risk. (펜리전트)
From Change Event to Pentest Trigger
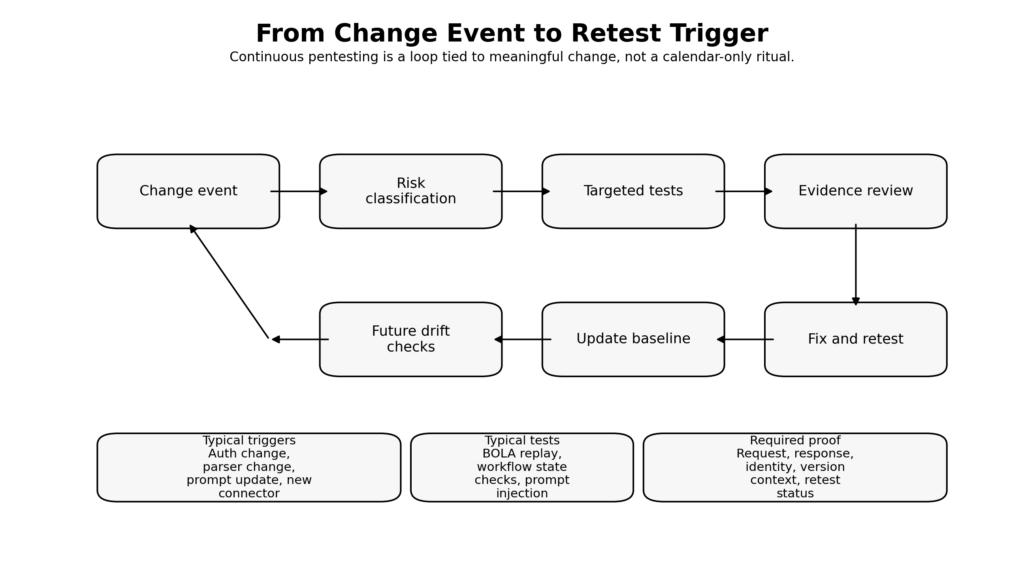
| Change event | Minimum test depth | Who should review it | What artifacts must be kept |
|---|---|---|---|
| Prompt or instruction file change | Prompt injection scenarios, golden-task regression, approval-path checks | AI platform owner and security reviewer | Old and new instructions, trace logs, approval traces |
| Auth middleware change | Role matrix replay, session tests, direct object access checks | Application security and owning engineer | Requests, responses, identity map, route map |
| New external connector or MCP tool | Tool misuse, data exfil, scope validation, least-privilege review | Platform security and infra owner | Tool manifest, token scopes, allowed destinations, approval records |
| Parser or upload pipeline change | Malformed input tests, parser abuse cases, content-type confusion checks | AppSec and service owner | Sample malicious inputs, parser config, result traces |
| New agent skill or automation | Goal-hijack tests, unintended side-effect review, rollback validation | AI workflow owner and security reviewer | Skill definition, trigger phrases, traces, blocked operations |
| Internet-facing config change | Exposure validation, route diffing, DAST baseline, auth replay | Infra, network, and AppSec | Before and after config, scan artifacts, route inventory |
| Fix for a previously exploitable issue | Targeted replay of the original exploit path plus adjacent cases | Original finder or security reviewer | Original evidence manifest, new results, closure record |
This is the operational heart of continuous pentesting. The test trigger is not “it is Friday” or “the scanner cron job fired.” It is “the system changed in a way that could alter security intent.” AI-heavy development just increases how many changes deserve that label.
Continuous Pentesting Is Not Continuous Scanning
This distinction matters enough to say plainly. Continuous scanning tells you what is exposed, outdated, or obviously misconfigured at scale. Continuous pentesting asks whether the application still resists active attempts to violate intended boundaries as it changes. NIST’s testing guidance and OWASP’s testing framework both leave room for automation, but neither reduces security testing to scheduled pattern matching. Planning, technique selection, reporting, and maintenance all remain part of the job. (csrc.nist.gov)
That difference shows up in AI-generated systems immediately. A scanner can tell you a dependency changed. It cannot tell you whether the generated refactor quietly made a manager token act like an admin token. A scanner can tell you a route exists. It cannot tell you whether prompt-injected tool output can now cause an agent to transmit secrets externally. A scanner can tell you a service is reachable. It cannot tell you whether a generated workflow step created a business-logic shortcut that lets a low-privilege user complete a high-privilege action.
This is why security buyers should be skeptical of products that describe continuous security as “always-on scanning” and stop there. The more AI is involved in building and reshaping the application, the more important state, proof, and replay become. Tools that cannot preserve context, hold auth state, validate exploitability safely, and regenerate evidence are still useful, but they are not the whole answer.
What Defenders Should Change This Quarter
The fastest useful shift most teams can make is cultural, not architectural. Treat AI-generated output as untrusted until verified. Not suspicious forever. Not forbidden. Just untrusted until it passes the same burden of proof as any other externally originated code or runtime behavior. GitHub’s docs already say this directly. Anthropic’s docs say verification is the highest-leverage move. OpenAI’s safety guidance says tool approvals and structured handling of untrusted input are necessary. The policy implication is obvious: stop pretending that “the model is smart” is a control. (GitHub Docs)
The second shift is to prioritize the boundaries AI is worst at preserving without help. Put authorization, session state, object access, parser behavior, externalized actions, and tool calls at the top of your retest queue. If a team used AI to touch those areas, do not let “tests passed” end the discussion until you know what those tests actually proved.
The third shift is to pin and version the new control surfaces. Instruction files, skills, hooks, allowlists, model-specific policies, and connector manifests should live under the same change discipline as code. Cohen’s critique of vibe coding is useful here again: the framework around the model is real work, and pretending otherwise only hides responsibility. (Bram Cohen)
The fourth shift is permission design. Do not let agents keep broad, long-lived credentials by default. GitHub’s documentation on constrained permissions and OpenAI’s guidance on approvals and structured outputs point the same way: short-lived, scoped capabilities plus explicit confirmation for risky operations. The control goal is not to make compromise impossible. It is to make compromise less useful and more visible. (GitHub Docs)
The fifth shift is evidence-first closure. Closing a finding should require replay against the updated build and preservation of the new outcome. In fast-moving AI-assisted teams, regression is not a special event. It is an expected operating condition.
What Pentesters and Bug Bounty Hunters Should Watch for
For offensive practitioners, the biggest mistake is chasing “AI bugs” in the abstract. The highest-yield targets are still concrete trust boundaries.
If the target is a conventional web app built quickly with AI assistance, start with BOLA, session confusion, negative role paths, parser edges, file handling, unsafe debug routes, and code-generated admin conveniences that were never meant to be internet-facing.
If the target embeds an agent or coding workflow, move outward. Look at instruction surfaces, imported content, connector trust, approval logic, repository metadata, branch names, command wrappers, token scope, browser-use permissions, and any place where untrusted text can influence a sensitive action.
If the target advertises “autonomous” or “agentic” development, ask what the runtime can actually do. Can it read files? Run commands? Use connectors? Reach the public internet? Call back to third parties? Write to repositories? Review PRs? Open branches? Every one of those verbs is more informative than whatever model name the vendor puts on the homepage.
The best AI-assisted research workflow is still disciplined. Penligent’s bug bounty writing makes this point well from the operator side: used badly, AI makes you test the wrong things faster and overclaim impact faster; used well, it compresses the hard middle of the work while you keep responsibility for scope, proof, and judgment. That principle generalizes beyond bug bounty into any authorized offensive workflow. (펜리전트)
What Buyers Should Ask AI Coding and AI Pentest Vendors
Security buyers evaluating AI coding or AI pentest tools should stop asking only which model is underneath. That question matters, but not enough.
Ask how the system plans before it acts. Ask how it verifies work. Ask what approvals exist for file writes, command execution, network egress, or external tool use. Ask whether untrusted content can directly influence tool calls. Ask how artifacts are stored. Ask whether findings can be replayed after fixes. Ask whether reports are generated from evidence or from narrative summaries. Ask how token scope is minimized. Ask how the product handles business-logic testing, stateful authentication, and authorization drift. Ask what happens when the tool is wrong.
Those questions are more predictive of real security value than benchmark screenshots or model-branding claims, because they measure whether the vendor has built a control plane around the model instead of treating the model as the product.

The Real Standard
The official documentation, the academic research, the public incidents, and the real CVEs all point to the same conclusion.
Vibe coding is not inherently reckless. The reckless part is shipping generated systems without a verification discipline that matches their rate of change. GitHub’s own “vibe coding” tutorial quietly assumes research, planning, testing, iteration, and hardening. Anthropic says verification is the highest-leverage move. OpenAI says prompt injection cannot be solved with filtering alone and that dangerous actions need safeguards and approvals. GitHub says AI outputs can be insecure and destructive and must be reviewed before merge. The research says AI-assisted developers can become overconfident, and public repository mining says real AI-generated code still contains meaningful vulnerability patterns. (GitHub Docs)
So the practical answer is not to romanticize “craft” against AI, and it is not to romanticize AI against security review. It is to make continuous pentesting the layer that keeps rapidly generated software honest. If the software, the agent instructions, the connectors, the permissions, and the runtime behavior are all changing continuously, then security verification has to change continuously too.
Not because the vibes are bad.
Because the system is alive.
Further Reading
Bram Cohen, The Cult Of Vibe Coding Is Insane. (Bram Cohen)
GitHub Docs, Vibe coding with GitHub Copilot. (GitHub Docs)
Anthropic, Best Practices for Claude Code. (Claude)
OpenAI Developers, Best practices for Codex. (OpenAI Developers)
OpenAI, Designing AI agents to resist prompt injection. (OpenAI)
OpenAI Developers, Safety in building agents. (OpenAI Developers)
GitHub Docs, Responsible use of GitHub Copilot CLI, Responsible use of Copilot Chat in GitHub및 Responsible use of Copilot cloud agent on GitHub.com. (GitHub Docs)
NIST SP 800-115, 정보 보안 테스트 및 평가에 대한 기술 가이드. (csrc.nist.gov)
OWASP, Web Security Testing Guide 그리고 API Security Top 10 2023. (OWASP)
NVD and vendor references for CVE-2023-34362, CVE-2024-34102, CVE-2025-29927, and CVE-2026-3055. (nvd.nist.gov)
BeyondTrust Phantom Labs, How Command Injection Vulnerability in OpenAI Codex Leads to GitHub Token Compromise. (BeyondTrust)
Penligent, AI Pentest Tool, What Real Automated Offense Looks Like in 2026. (펜리전트)
Penligent, How to Get an AI Pentest Report. (펜리전트)
Penligent, How to Use AI for Bug Bounty in 2026. (펜리전트)
Penligent, 휴먼 인더 루프 에이전트 AI 펜테스트 도구 펜리전트 - 응집력 있는 엔지니어 우선 가이드. (펜리전트)
Penligent homepage. (펜리전트)

