A sandbox is supposed to make a dangerous action boring. A coding agent can read files, run commands, install dependencies, inspect logs, and follow links, but the sandbox is the line that says: even if the agent is manipulated, the damage stays inside a defined box.
The recently disclosed Claude Code sandbox vulnerability shows what happens when that line depends on a parser, a proxy, and a hostname string that two layers interpret differently. Security researcher Aonan Guan disclosed a SOCKS5 hostname null-byte injection issue in Claude Code’s network sandbox. His analysis says Claude Code releases from v2.0.24, when the BashTool sandbox became generally available, through v2.1.89 were vulnerable to a bypass that could let code inside the sandbox connect to hosts outside the user’s configured network allowlist. The public disclosure describes the issue as live for about 5.5 months and roughly 130 versions. (Aonan Guan)
The core bug is not that Claude gave a bad answer. It is that the egress control for a tool-using AI runtime made a decision on one interpretation of a hostname, while the operating system resolved another. A hostname such as attacker.example\x00.google.com can look acceptable to a JavaScript suffix check because it ends with .google.com, while a C-style resolver such as getaddrinfo() treats the null byte as a string terminator and dials only the attacker-controlled prefix. Guan’s original write-up explains the parser differential in those terms, and the later sandbox-runtime commit explicitly mentions blocking a null-byte allowlist bypass where a SOCKS5 DOMAINNAME passed .endsWith(".allowed.com") but DNS truncated at the null byte and connected elsewhere. (Aonan Guan)
That is the technical story. The operational story is bigger. Claude Code is a coding agent, not a chat window. It can process repository content, run shell commands, work with developer tooling, and interact with external services. Anthropic’s sandbox documentation says the sandboxed Bash tool is meant to provide filesystem and network isolation for safer autonomous execution, and that network access is controlled through a proxy server running outside the sandbox. (Claude Code) If the proxy is fooled, the sandbox still appears to exist from the user’s point of view, but the outbound boundary is no longer the boundary they configured.
The most important lesson is not “never use Claude Code.” The better lesson is this: AI coding agents turn repositories, issue comments, documentation, package scripts, memory files, MCP configuration, hooks, shell commands, and network access into one execution environment. A broken network sandbox in that environment is not a small guardrail bug. It can become the path that lets indirect prompt injection turn into credential theft or source-code exfiltration.
What happened
Guan’s disclosure describes two Claude Code network sandbox failures in the same general area. The first was CVE-2025-66479, a sandbox-runtime issue where allowedDomains: [] did not correctly enforce network isolation. NVD describes that issue as a bug in sandbox-runtime before v0.0.16 where the network sandbox was not properly enforced if no allowed domains were configured, allowing sandboxed code to make network requests outside the sandbox. (NVD)
The second issue, the main subject here, is the SOCKS5 hostname null-byte injection bypass. According to the researcher, users who configured a wildcard allowlist such as *.google.com could still be bypassed by a crafted SOCKS5 DOMAINNAME containing a null byte before the allowed suffix. The policy layer saw a string ending in an allowed domain. The resolver layer saw only the prefix before the null byte. (Aonan Guan)
SecurityWeek reported the same high-level finding and summarized the researcher’s position: Claude Code’s network sandbox funnels outbound traffic through a local allowlist proxy, and the SOCKS5 null-byte issue could be chained with prompt injection to exfiltrate data. SecurityWeek also reported Anthropic’s response, which matters because it creates a timeline nuance. Guan’s write-up says the issue was fixed in Claude Code v2.1.90. Anthropic told SecurityWeek that its security team had identified and fixed the issue before Guan’s HackerOne report, that the fix was included in a public sandbox-runtime commit on March 27, and that it shipped in Claude Code 2.1.88 on March 31. (SecurityWeek)
The responsible way to write about the timeline is therefore not to pretend there is only one version number. The public researcher claim is v2.1.90. The vendor statement reported by SecurityWeek is v2.1.88. The GitHub release page for v2.1.90 lists ordinary feature and bug-fix notes and does not clearly identify a network sandbox security fix. (GitHub)
The table below separates the confirmed facts from the claims that require careful wording.
| Pergunta | What public sources support | What should not be overstated |
|---|---|---|
| What kind of bug was it? | A SOCKS5 hostname null-byte injection causing a network allowlist bypass in the Claude Code sandbox path. (Aonan Guan) | It should not be described as a model jailbreak or a flaw in all Claude products. |
| What was the impact? | Code inside the sandbox could reach hosts the user’s policy intended to block, creating a possible outbound exfiltration path. (Aonan Guan) | It does not prove every user was compromised. Impact depends on configuration, reachable files, credentials, and whether attacker-influenced code ran. |
| Which versions were affected? | Guan says v2.0.24 through v2.1.89. (Aonan Guan) | Anthropic told SecurityWeek the fix shipped in Claude Code 2.1.88, so the exact last affected version is disputed in public reporting. (SecurityWeek) |
| Is there a CVE for the SOCKS5 bypass? | Guan reported no CVE or Claude Code advisory for this bypass as of his disclosure. (Aonan Guan) | CVE-2025-66479 is related but describes the earlier sandbox-runtime allowlist enforcement bug, not this SOCKS5 null-byte issue. |
| Why does prompt injection matter? | Hidden instructions in GitHub comments, README files, or docs can influence AI agents that process them, and Guan and SecurityWeek both connect this class of attack to possible exfiltration. (SecurityWeek) | Prompt injection alone is not the same as a sandbox bypass; the risk increases when the injected instruction can drive a privileged tool path. |
How the Claude Code sandbox is supposed to work
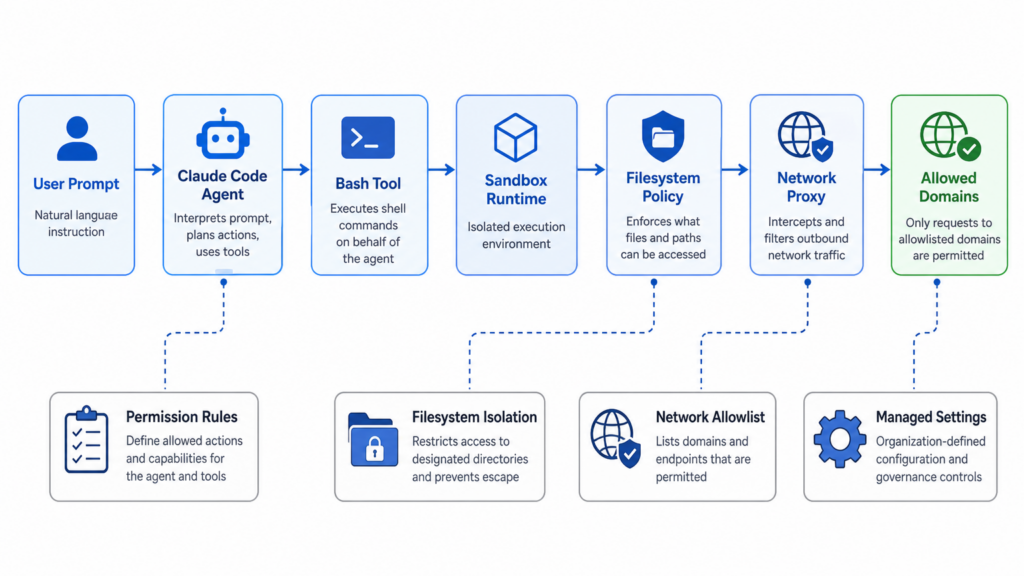
Claude Code’s sandboxed Bash tool is meant to reduce the need for constant permission prompts by constraining what Bash commands and their child processes can touch. Anthropic’s documentation says the sandbox is built into Claude Code, runs on macOS, Linux, and WSL2, uses Seatbelt on macOS and bubblewrap on Linux/WSL2, and relies on filesystem and network controls to contain Bash commands. (Claude Code)
That architecture has several layers, and the layers matter.
Permission rules decide whether a tool call is allowed before it starts. Sandboxing applies after a Bash command is running and limits what that command can access. Anthropic’s docs explicitly distinguish those layers: permission rules apply to all tools, while sandboxing provides OS-level enforcement for Bash commands and child processes. The documentation also notes that built-in file tools such as Read, Edit, and Write use the permission system directly rather than running through the Bash sandbox. (Claude Code)
For network access, the sandbox relies on a proxy outside the sandbox. The docs say network access is controlled through a proxy server running outside the sandbox, that no domains are pre-allowed by default, that approved domains can be configured with allowedDomains, and that deniedDomains can block specific domains even when a broader wildcard would otherwise permit them. The built-in proxy enforces the allowlist based on the requested hostname and does not terminate or inspect TLS traffic. (Claude Code)
That last sentence is the pressure point. If the proxy enforces policy based on the requested hostname, it must know exactly what hostname will actually be resolved and connected. Any mismatch between the string checked by the proxy and the host dialed by the operating system becomes a security boundary failure.
| Camada | What it controls | Example controls | Modo de falha |
|---|---|---|---|
| Permission rules | Whether a tool call can begin | allow, deny, ask, permission mode | A risky action may be approved or auto-approved before the user understands it. |
| Bash sandbox | What Bash commands and child processes can access | filesystem deny/allow paths, network policy | Code runs, but the containment boundary is weaker than expected. |
| Network proxy | Which hosts Bash subprocesses can reach | allowedDomains, deniedDomains, managed allowlists | A parser or canonicalization bug lets traffic reach blocked destinations. |
| Filesystem policy | Which files a subprocess can read or write | denyRead, allowRead, allowWrite | Credentials remain readable to sandboxed code. |
| Environment handling | What secrets child processes inherit | environment scrubbing, scoped shells, ephemeral credentials | Tokens leak even if files are protected. |
| Organization policy | Whether users can widen local settings | managed settings, MDM, server-managed controls | Local project config or developer convenience overrides security intent. |
The Claude Code documentation also gives a useful warning: default read behavior can still allow access to credential files such as ~/.aws/credenciais e ~/.ssh/, and users should add sensitive paths to denyRead to block them. It also notes that sandboxed Bash commands inherit the parent process environment by default, including credentials, unless environment scrubbing is configured. (Claude Code)
That means a network sandbox bypass is not isolated from filesystem and credential hygiene. If sandboxed code can read secrets and can bypass egress restrictions, the result is an exfiltration path.
The SOCKS5 null-byte bug in plain technical terms
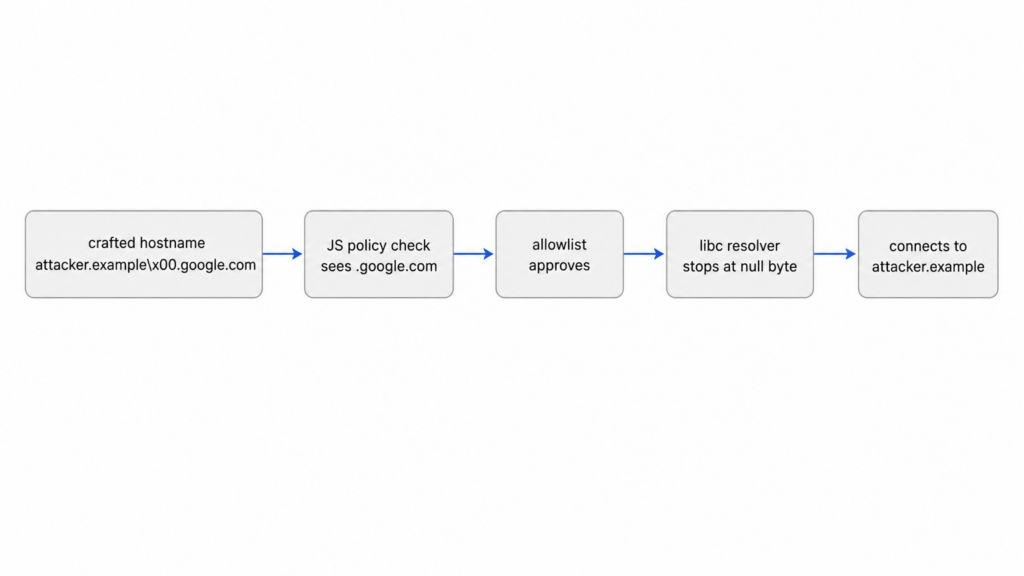
A SOCKS5 proxy can receive a CONNECT request with a domain name target. In this case, the relevant field is not a browser URL. It is a raw DOMAINNAME value passed through the SOCKS5 protocol. The vulnerable path described by Guan took that host value, treated it like a JavaScript string, and checked it against an allowlist pattern.
The simplified version looks like this:
User policy:
allowedDomains = ["*.google.com"]
Attacker-controlled SOCKS5 DOMAINNAME:
attacker.example\x00.google.com
Policy layer sees:
"attacker.example\x00.google.com".endsWith(".google.com") == true
Resolver layer sees:
"attacker.example" because \x00 terminates the C string
The same bytes cross a boundary between runtimes. JavaScript can store a null byte inside a string. C APIs traditionally treat a null byte as the end of a string. If the proxy policy check happens before canonicalization and the resolver later interprets the bytes differently, the allowlist is no longer deciding on the destination that will be dialed.
Guan’s write-up shows this exact policy-versus-resolver split, and the sandbox-runtime patch message later names the same class of bug: a SOCKS5 DOMAINNAME such as evil.com\x00.allowed.com passed a suffix allowlist check but DNS truncated at the null and connected to the blocked host. (Aonan Guan)
This is not a new kind of security bug in the abstract. Security engineers have seen parser differentials in URL parsers, reverse proxies, WAFs, SSRF filters, DNS resolvers, IDNA handling, Unicode normalization, path traversal filters, and HTTP request smuggling. The novelty is the placement: the parser differential sat inside the egress control for an AI coding agent.
A correct network boundary must do at least four things before it matches a hostname against policy:
- Reject bytes and characters that do not belong in the grammar being matched.
- Canonicalize the host into the same form the dialer will use.
- Match policy against the canonical form, not against raw input.
- Dial only the canonical host that was matched, not a later reinterpretation.
The sandbox-runtime commit that contained the fix reflects that pattern. It added validation for destHost, including a specific note about blocking the null-byte allowlist bypass, rejecting CRLF injection vectors, rejecting percent-based zone-ID bypasses, and canonicalizing host representations such as shorthand IPv4 and IPv6 forms so string comparisons agree with what getaddrinfo() will dial. (GitHub)
A safe defensive validation function is not a complete proxy implementation, but it helps show the principle. The point is not to copy this into production blindly. The point is to reject ambiguous hostnames before policy matching.
import ipaddress
import re
DNS_LABEL = re.compile(r"^[A-Za-z0-9_](?:[A-Za-z0-9_-]{0,61}[A-Za-z0-9_])?$")
def normalize_host_for_policy(raw_host: str) -> str:
"""
Defensive hostname normalization for allowlist checks.
This is intentionally strict. It rejects inputs that are common
sources of parser differentials between policy code and network
resolution code. A production proxy should pair this with a single
canonical dial path and regression tests for every rejected form.
"""
if not isinstance(raw_host, str):
raise ValueError("host must be a string")
host = raw_host.strip().lower().rstrip(".")
forbidden = ["\x00", "\r", "\n", "%", "/", "\\", "@", "#", "?"]
if any(ch in host for ch in forbidden):
raise ValueError("host contains forbidden characters")
if len(host) == 0 or len(host) > 253:
raise ValueError("invalid host length")
try:
ip = ipaddress.ip_address(host)
return ip.compressed
except ValueError:
pass
labels = host.split(".")
if any(len(label) == 0 for label in labels):
raise ValueError("empty DNS label")
if not all(DNS_LABEL.match(label) for label in labels):
raise ValueError("invalid DNS label")
return ".".join(labels)
def host_matches_allowed_domain(host: str, pattern: str) -> bool:
host = normalize_host_for_policy(host)
pattern = normalize_host_for_policy(pattern.lstrip("*.")) if pattern.startswith("*.") else normalize_host_for_policy(pattern)
if pattern == host:
return True
return host.endswith("." + pattern)
There are two important limits to this example.
First, hostname validation is not enough if the code later dials a different string from the one it validated. The policy result and the dial target must stay bound together.
Second, allowlist matching against names is only one part of egress control. If a domain resolves to internal IP space, link-local metadata addresses, loopback, or private network ranges, the proxy may still need IP-level deny rules after resolution. That matters for cloud metadata endpoints such as 169.254.169.254, which frequently appear in agent exfiltration threat models.
Why prompt injection turns this from a proxy bug into an agent security incident
A local sandbox bypass is serious, but it becomes more dangerous when the thing inside the sandbox can be steered by untrusted content. Coding agents constantly ingest content that was not written by the user: GitHub issues, PR comments, README files, documentation, dependency output, code comments, terminal logs, web pages, and MCP tool results.
That is exactly the environment where indirect prompt injection matters. OWASP describes indirect prompt injection as malicious instructions hidden in external content that an LLM processes, including code comments, documentation, commit messages, merge request descriptions, web pages, documents, and emails. OWASP also lists unauthorized data access, data exfiltration, unauthorized actions through connected tools and APIs, and persistent manipulation as key impacts of prompt injection. (cheatsheetseries.owasp.org)
OpenAI’s agent safety guidance says prompt injections happen when untrusted text or data enters an AI system and attempts to override instructions, with possible outcomes including private-data exfiltration through downstream tool calls and unintended actions. Its Codex internet-access documentation gives a concrete warning: enabling agent internet access increases risks such as prompt injection from untrusted web content, exfiltration of code or secrets, malware or vulnerable dependency downloads, and license-risk content pulls. (developers.openai.com)
NIST’s CAISI research blog uses the term agent hijacking for the same family of risk. It describes attacks where malicious instructions are inserted into data that an AI agent may ingest, with goals such as exfiltrating sensitive data or downloading and running malicious code. It also reports that a large-scale public red-teaming competition found at least one successful attack against all 13 frontier models tested across agentic scenarios. (NIST)
The Claude Code sandbox bypass fits into that broader risk model. The attacker’s prompt injection does not have to “break the model” in the science-fiction sense. It only has to influence the agent enough to run a command, execute a script, inspect a file, or follow a workflow that the environment permits. If that workflow is inside a sandbox with broken egress controls, the sandbox can become the route out.
A realistic chain looks like this:
| Estágio | Attacker-controlled input | Agent or runtime behavior | Boundary that should stop it |
|---|---|---|---|
| 1. Context injection | A GitHub issue, PR comment, README, or documentation file contains malicious task instructions. | The agent reads the content as part of normal development work. | Prompt/data separation and human review. |
| 2. Tool activation | The injected instruction steers the agent toward a Bash command, script, package operation, or helper program. | The command runs inside a sandboxed Bash subprocess. | Permission rules and sandbox policy. |
| 3. Secret access | The subprocess can read environment variables, project files, or credential paths not blocked by filesystem policy. | Tokens or internal data become available to the process. | denyRead, environment scrubbing, least privilege. |
| 4. Egress bypass | The process uses a raw SOCKS5 path with a crafted hostname. | The proxy approves a hostname that the resolver interprets differently. | Host canonicalization and proxy regression tests. |
| 5. Exfiltration | Data is sent to a host outside the intended allowlist. | Logs may not show an ordinary HTTP request. | External egress controls, EDR, DNS/proxy telemetry, token monitoring. |
This is why the phrase “network sandbox bypass” understates the risk. The bug is not only about reaching exemplo.com. It is about whether the operator can trust an AI coding agent to handle untrusted content while sitting near cloud credentials, GitHub tokens, internal services, source code, package registries, and developer machines.
What could be exposed
Guan’s disclosure says the bypass was most dangerous when paired with prompt injection. He lists examples such as environment variables, credentials in ~/.aws/ e ~/.config/gh/, GitHub tokens, model API keys, cloud metadata at 169.254.169.254, corporate intranet endpoints, and internal APIs reachable from the host. He also notes that the outbound channel is raw SOCKS5 rather than ordinary HTTP, which can reduce visibility in basic egress logs. (Aonan Guan)
That list should be read as possible exposure, not proof of compromise. The exploitability of any real environment depends on at least six conditions:
- A vulnerable Claude Code or sandbox-runtime path was present.
- The network sandbox was enabled and relied on a wildcard allowlist.
- The agent processed attacker-influenced content or ran attacker-influenced code inside the sandbox.
- The sandboxed process could read valuable data from files or environment variables.
- The host could reach interesting destinations or metadata services.
- The organization did not have external egress controls that would block or log the connection.
The second and fourth conditions are especially important. A developer machine with long-lived AWS keys in ~/.aws/credenciais, a GitHub token in ~/.config/gh/, a loaded cloud SSO session, npm credentials, PyPI tokens, Kubernetes config, and model API keys is a high-value target. A short-lived disposable workspace with no local secrets, no internal network route, strict filesystem deny rules, and an external proxy is a different risk profile.
The practical question for defenders is not “was every Claude Code user breached?” The better question is “did we ever run a vulnerable version in a credential-bearing environment where the sandbox was our main network boundary?”
| Meio ambiente | Risk level | Por que | First action |
|---|---|---|---|
| Vulnerable version, wildcard allowlist, cloud credentials on disk | Alta | The process may have had both readable secrets and a bypassable egress boundary. | Upgrade, rotate credentials, review logs, check cloud and GitHub token activity. |
Vulnerable version, wildcard allowlist, strict denyRead, scrubbed environment | Médio | The egress bypass matters, but available secrets may be limited. | Upgrade and validate that deny rules worked as intended. |
| Vulnerable version, no wildcard allowlist, external egress proxy | Médio | The exact null-byte path may be harder to trigger, but sandbox-runtime trust still needs validation. | Upgrade and run regression tests on proxy and agent logs. |
| Current version, no secrets, disposable workspace | Inferior | Blast radius is reduced even if an agent is manipulated. | Keep isolation, continue testing, avoid persistent tokens. |
Any version with bypassPermissions or unsandboxed automation in untrusted repos | Alta | The workflow may have no meaningful agent boundary. | Move to isolated environments and require explicit review. |
The version and disclosure timeline
The timeline matters because security teams often triage based on changelogs, CVEs, and advisories. This incident is a reminder that those signals can be incomplete for agent runtimes.
Guan’s disclosure says the network sandbox went generally available in Claude Code v2.0.24 on October 20, 2025, and that every release through v2.1.89 was vulnerable to the SOCKS5 null-byte issue. He says the first sandbox bypass, CVE-2025-66479, was patched in v2.0.55 on November 26, 2025, while the second issue remained present until v2.1.90. (Aonan Guan)
NVD published CVE-2025-66479 for sandbox-runtime, describing the package as a lightweight sandboxing tool for enforcing filesystem and network restrictions and stating that versions prior to v0.0.16 did not properly enforce a network sandbox when no allowed domains were configured. GitHub’s advisory for GHSA-9gqj-5w7c-vx47 gives the same patched version and rates that library issue as low severity, with a 1.8 score. (NVD)
For the new SOCKS5 issue, there is no equally clean advisory record in the public sources reviewed here. The fix appears in the sandbox-runtime commit history, where the commit message explicitly calls out the null-byte allowlist bypass and related host canonicalization hardening. SecurityWeek reports Anthropic’s position that the fix was included in a public sandbox-runtime commit on March 27 and shipped in Claude Code 2.1.88 on March 31. Guan’s disclosure says fixed in Claude Code v2.1.90 and notes that the v2.1.90 release notes did not identify a security fix. (GitHub)
| Date | Event | Notas |
|---|---|---|
| October 20, 2025 | Claude Code v2.0.24 ships sandbox mode for BashTool, according to Guan’s timeline. | Guan says the network sandbox was vulnerable from this point. (Aonan Guan) |
| November 26, 2025 | First sandbox bypass fixed, according to Guan. | Related to allowedDomains: [] behavior later tracked as CVE-2025-66479. (Aonan Guan) |
| December 2025 | CVE-2025-66479 published for sandbox-runtime. | The CVE describes improper network sandbox enforcement when no allowed domains were configured. (NVD) |
| March 27, 2026 | sandbox-runtime commit includes null-byte and related hostname security fixes. | Commit text explicitly names the null-byte allowlist bypass. (GitHub) |
| March 31, 2026 | Anthropic says fix shipped in Claude Code 2.1.88, according to SecurityWeek. | This is Anthropic’s reported position, not Guan’s version boundary. (SecurityWeek) |
| April 1, 2026 | Claude Code v2.1.90 release published. | Release notes list multiple changes but do not clearly call out the sandbox bypass. (GitHub) |
| April 3, 2026 | Guan reports the issue through HackerOne, according to SecurityWeek and his disclosure. | Anthropic reportedly closed it as duplicate of an internal finding. (SecurityWeek) |
| May 20, 2026 | Public disclosure. | The Register and SecurityWeek covered the issue. (theregister) |
For security teams, the safest action is simple: do not spend energy debating whether v2.1.88 or v2.1.90 was the exact boundary if any deployed environment is older than both. Upgrade to the latest Claude Code release, then verify the surrounding configuration and credential exposure.
Why related CVEs matter
The SOCKS5 null-byte bypass has no public CVE in the sources reviewed here, but it sits inside a broader pattern of Claude Code security issues where trust, configuration, and execution boundaries failed or were difficult to reason about.
CVE-2025-66479, empty allowlist interpreted as no network restriction
CVE-2025-66479 is the closest related sandbox issue. NVD says sandbox-runtime before v0.0.16 did not properly enforce a network sandbox if the sandbox policy did not configure any allowed domains, allowing sandboxed code to make network requests outside the sandbox. (NVD) GitHub’s advisory describes the same bug and says the patch was released in v0.0.16. (GitHub)
The relevance is not that the mechanism is identical. It is not. CVE-2025-66479 was a configuration semantics failure: the user’s intention to block network access could collapse into no network restriction. The SOCKS5 null-byte issue is a parser differential: the proxy and resolver disagreed about the destination host. But the result is similar. In both cases, a process inside the sandbox could reach hosts the user believed were blocked.
The lesson is that an allowlist is not a policy until implementation details prove it. Empty lists, wildcard suffixes, canonicalization, IP literals, DNS rebinding, metadata endpoints, and raw protocol paths all have to be tested as part of the boundary.
CVE-2025-59536, code execution before trust confirmation
CVE-2025-59536 is not a network sandbox bug, but it is highly relevant to the Claude Code threat model. NVD describes Claude Code versions before 1.0.111 as vulnerable to code injection due to a startup trust dialog implementation bug, where Claude Code could be tricked into executing code contained in a project before the user accepted the startup trust dialog. Exploitation required a user to start Claude Code in an untrusted directory. (NVD)
Check Point Research’s public analysis of Claude Code project files explains why this class of issue matters. It describes project-level .claude/settings.json as a repository-controlled configuration file and shows how features such as hooks, MCP server configuration, and environment variables can become attack surfaces when a developer opens an untrusted repository. (Pesquisa da Check Point)
That pattern matters because agent runtimes blur the old distinction between “configuration” and “execution.” A repository file is no longer passive if it can define hooks, MCP servers, permission defaults, environment variables, or startup behavior. In an AI coding agent, trust is a sequence. If project-controlled settings influence execution before trust is established, the user is already behind.
CVE-2026-21852, API key exposure before trust confirmation
CVE-2026-21852 is another Claude Code issue that helps explain the risk model. NVD says Claude Code before v2.0.65 had a project-load-flow vulnerability where an attacker-controlled repository could include a settings file that set ANTHROPIC_BASE_URL to an attacker-controlled endpoint. When the repository was opened, Claude Code could read the configuration and issue API requests before showing the trust prompt, potentially leaking the user’s API keys. (NVD)
GitHub’s advisory for GHSA-jh7p-qr78-84p7 describes the same issue, lists affected versions as < 2.0.65, and says users performing manual updates should update to the latest version. (GitHub)
The connection to the sandbox bypass is the credential story. CVE-2026-21852 shows that agent configuration can expose credentials before the user has meaningfully trusted the project. The SOCKS5 bypass shows that once code is running inside an apparently restricted environment, weak egress control can become the outbound channel. Both failures punish the same assumption: that a prompt, a settings file, or a sandbox label is enough to make an agent workflow safe.
| Issue | Failure class | Exploitation condition | Real-world risk | Fix or mitigation direction |
|---|---|---|---|---|
| SOCKS5 null-byte bypass | Parser differential at network policy boundary | Sandboxed code can send crafted SOCKS5 DOMAINNAME through a wildcard allowlist path | Exfiltration to hosts outside the intended allowlist | Reject invalid host bytes, canonicalize before policy checks, bind matched host to dial target, test raw protocol paths. |
| CVE-2025-66479 | Configuration semantics error | Network sandbox policy with no allowed domains | Network restriction may fail when user expects no network access | Correct empty allowlist semantics, test deny-by-default behavior. |
| CVE-2025-59536 | Pre-trust execution | User starts Claude Code in an untrusted directory | Project code can execute before trust confirmation | No project-controlled execution before trust, review hooks and startup paths. |
| CVE-2026-21852 | Pre-trust credential exposure | Malicious repository controls ANTHROPIC_BASE_URL in settings | API keys may be sent to attacker-controlled endpoint | Do not read dangerous project config or send API requests before trust confirmation. |
What defenders should check first
The immediate response should start with inventory, not speculation. The goal is to answer three questions:
- Did we run affected versions?
- Did we rely on the network sandbox as an egress boundary?
- Did those environments hold secrets that a sandboxed subprocess could read?
Start with version checks on developer workstations, CI runners, remote dev boxes, and any shared agent execution hosts.
claude --version
npm list -g @anthropic-ai/claude-code --depth=0 2>/dev/null
npm view @anthropic-ai/claude-code version
Those commands will not prove whether a historical vulnerable version ever ran, but they establish the current state. For managed fleets, collect installed package histories from endpoint management, shell history, npm cache metadata, device inventory, or software deployment logs.
Next, search for project and user settings that could widen the boundary:
find "$HOME" . \
-path "*/.claude/settings.json" -o \
-name ".mcp.json" -o \
-name "CLAUDE.md" \
2>/dev/null
Then look for settings that deserve review:
grep -RInE \
'bypassPermissions|dangerouslyDisableSandbox|allowUnsandboxedCommands|allowedDomains|deniedDomains|ANTHROPIC_BASE_URL|enableAllProjectMcpServers|enabledMcpjsonServers|hooks|mcpServers' \
"$HOME/.claude" . 2>/dev/null
The presence of a keyword is not proof of compromise. It is a triage signal. A legitimate team repository may use hooks or MCP servers safely. A security review should ask who controls the file, whether it is reviewed like code, whether it can run before trust, whether it inherits secrets, and whether it changes permissions or network reach.
Wildcard allowlists deserve extra attention:
grep -RInE '"allowedDomains"\s*:\s*\[|"\*\.' \
"$HOME/.claude" . 2>/dev/null
If you find broad patterns such as *.google.com, *.github.com, *.amazonaws.comou *.internal.example.com, ask what exact workflows require the wildcard and whether narrower hostnames would work. Wildcards are not automatically wrong, but they dramatically increase the value of parser-differential testing.
Credential exposure review should include the obvious files and the less obvious session material:
ls -la ~/.aws ~/.config/gh ~/.ssh ~/.kube 2>/dev/null
test -f ~/.npmrc && echo "~/.npmrc exists"
test -f ~/.pypirc && echo "~/.pypirc exists"
env | grep -Ei 'AWS_|GITHUB|GH_|ANTHROPIC|OPENAI|GEMINI|GOOGLE|AZURE|TOKEN|SECRET|KEY'
Do not paste that output into a chat tool. The point is to understand whether the runtime environment held secrets. If it did, assume the sandbox boundary was not a complete protection during the vulnerable window and rotate the most sensitive credentials first.
A safer default sandbox configuration blocks credential paths and refuses unsandboxed retries. The exact keys should be validated against the current Claude Code documentation and your deployment model, but the defensive intent is clear:
{
"sandbox": {
"enabled": true,
"failIfUnavailable": true,
"allowUnsandboxedCommands": false,
"filesystem": {
"denyRead": [
"~/.aws/",
"~/.ssh/",
"~/.config/gh/",
"~/.kube/",
"~/.npmrc",
"~/.pypirc",
"~/.docker/",
"~/.gnupg/"
],
"allowRead": [
"."
]
},
"network": {
"allowedDomains": [
"github.com",
"api.github.com"
],
"deniedDomains": [
"169.254.169.254"
]
}
}
}
Anthropic’s own docs warn that effective sandboxing requires both filesystem and network isolation, because without network isolation a compromised agent could exfiltrate sensitive files, and without filesystem isolation a compromised agent could backdoor resources to gain network access. (Claude Code) The key is to treat those controls as coupled. Network restrictions are weaker if secrets are readable. File restrictions are weaker if the agent can modify scripts, hooks, or configuration that later runs outside the sandbox.
Detection signals worth collecting
Retrospective detection is difficult because the bypass used a raw SOCKS5 path and may not show up as a normal HTTP request. Still, defenders can collect useful signals from four places: endpoint process telemetry, proxy/DNS logs, cloud audit logs, and source-control audit logs.
Endpoint telemetry should focus on child processes spawned under Claude Code or its sandbox runtime. Look for unusual network-capable tools, scripting languages, encoded commands, or subprocesses that read credential paths.
# macOS or Linux triage idea, adapt to your EDR or osquery environment
ps auxww | grep -Ei 'claude|node|python|curl|wget|nc|openssl|socat|bash|sh' | grep -v grep
For osquery-style endpoint visibility, the idea is to join process ancestry with network connections and file reads. The exact schema depends on your deployment, but the detection question is stable:
SELECT
p.pid,
p.name,
p.cmdline,
p.parent,
pp.name AS parent_name
FROM processes p
LEFT JOIN processes pp ON p.parent = pp.pid
WHERE
p.cmdline LIKE '%socks%'
OR p.cmdline LIKE '%ALL_PROXY%'
OR p.cmdline LIKE '%169.254.169.254%'
OR p.cmdline LIKE '%~/.aws%'
OR p.cmdline LIKE '%~/.config/gh%';
Proxy and DNS logs should flag malformed or ambiguous hostnames. A well-designed proxy should reject these before matching policy:
| Sinal | Por que é importante |
|---|---|
| NUL byte or escaped null sequence in host-like fields | Directly maps to the null-byte parser differential class. |
| CRLF in host fields | Can indicate proxy request injection or header confusion. |
% in hostnames or IPv6 zone identifiers | Can trigger parser disagreement in some IP and URL paths. |
IPv4 shorthand such as 127.1 or integer IPv4 forms | Can bypass simple string deny rules if not canonicalized. |
| Trailing dot variants | Can bypass naive suffix or equality checks. |
| IDNA or Unicode lookalikes | Can split policy view from resolver view if normalization is inconsistent. |
Requests to 169.254.169.254 or internal metadata hosts | Indicates attempted cloud metadata access. |
If your proxy logs raw hostnames, search for unusual bytes and encodings. Many log pipelines will drop or escape NUL bytes, so absence of evidence is not evidence of absence.
# Example for text logs where escaped sequences may be preserved
grep -RInaE '\\x00|%00|%0d|%0a|169\.254\.169\.254|metadata\.google\.internal|169\.254\.170\.2' \
/var/log/proxy /var/log/dns 2>/dev/null
Cloud audit logs can be more reliable than local proxy logs because they show credential use. Look for unusual API calls shortly after agent sessions, access from new IPs, unexpected GetCallerIdentity, token exchange events, GitHub token usage from new locations, npm publish attempts, container registry access, or secrets-manager reads.
GitHub review should include:
- New OAuth app authorizations.
- Fine-grained token creation or use.
- GitHub CLI token use from unusual hosts.
- Actions secrets access patterns.
- Suspicious repository webhooks.
- New deploy keys.
- New machine users or PATs.
- Unexpected pushes or branch changes following an agent session.
Cloud review should include:
- AWS STS calls from developer credentials.
- AWS metadata service access from dev hosts.
- GCP service account token use from unusual locations.
- Azure CLI token refresh and Graph API calls.
- Secrets Manager, Parameter Store, Key Vault, or Secret Manager reads.
- Container registry pulls or pushes.
- IAM policy changes.
- New access keys.
A simple incident response table helps keep the work concrete.
| Task | Owner | Evidence to collect | Decision point |
|---|---|---|---|
| Identify affected versions | Endpoint or IT team | Installed package versions, update logs, npm global package history | Any host older than the fixed range gets priority. |
| Review sandbox config | AppSec or platform security | .claude/settings.json, managed settings, allowedDomains, denyRead | Broad wildcard plus secrets means high risk. |
| Review secrets exposure | Cloud and DevOps | AWS/GCP/Azure/GitHub/npm/PyPI token inventory | Rotate credentials present on affected hosts. |
| Review egress | Network or SOC | Proxy logs, DNS logs, EDR network connections | Unknown outbound hosts near agent sessions require investigation. |
| Review repositories | AppSec | .mcp.json, hooks, project memory, suspicious comments | Treat untrusted repo config as execution-relevant. |
| Preserve evidence | Incident response | Disk snapshots, shell history, terminal logs, EDR timelines | Preserve before cleanup on high-risk machines. |
Hardening the agent environment
The safest response is not to wait for the next agent advisory. Agentic coding tools should be deployed like execution platforms, not like editor plugins.
Use disposable workspaces for untrusted repositories
If a repository is untrusted, do not open it with an agent on a credential-bearing laptop. Use a disposable VM, container, cloud dev environment, or remote workspace with no long-lived secrets and no route to internal networks.
This is especially important for bug bounty, malware analysis, dependency triage, open-source issue reproduction, job-candidate code review, contractor repositories, and random GitHub links. In those workflows, the repository is not just source code. It may carry agent instructions, hooks, MCP config, package scripts, hidden prompt injection payloads, and build steps.
Separate human credentials from agent credentials
A human developer account often has broad privileges because it must solve many tasks. An agent does not need all of them. Use separate short-lived tokens for agent workflows. Scope them to the repository, task, branch, and time window. Avoid giving coding agents access to persistent cloud admin credentials, default GitHub CLI tokens, or production kubeconfig files.
For cloud work, prefer:
- Short-lived role assumptions.
- Session policies that reduce permissions.
- No default credentials in the agent shell.
- Separate development accounts from production accounts.
- Explicit deny policies for metadata endpoints where possible.
- Workload identity with narrow scopes.
Treat project-level agent configuration as code
Files such as .claude/settings.json, .mcp.json, CLAUDE.md, hooks, custom commands, skills, and plugin configuration should be reviewed like code. If a repository can change how an agent runs, it can change security posture.
A useful review checklist includes:
| File or feature | Review question |
|---|---|
.claude/settings.json | Does it change permission mode, sandbox behavior, hooks, network allowlists, or environment variables? |
.mcp.json | Does it start local commands, connect to external tools, or expose credentials? |
| Hooks | Do they run automatically on session start, file edit, tool use, or task completion? |
CLAUDE.md | Does it include instructions that could override security expectations or direct data movement? |
| Skills or plugins | Do they include scripts, MCP servers, or hidden dependencies? |
| Environment variables | Can project settings override API endpoints or credential paths? |
| Permission defaults | Can repo-controlled files widen from ask/deny to auto-approve behavior? |
Keep network egress outside the agent runtime
Built-in allowlists are useful, but they should not be the only egress boundary. Put agent traffic behind controls that are not controlled by the agent process itself. A corporate proxy, local firewall policy, container network namespace, cloud egress gateway, or VM-level firewall can catch mistakes in the agent runtime.
For high-risk workflows, consider:
- No internet by default.
- Explicit domain allowlists.
- Method restrictions where supported, such as allowing GET and HEAD but blocking POST for dependency fetch tasks.
- Deny rules for metadata endpoints and private network ranges.
- Logging that captures raw CONNECT targets and rejected malformed hosts.
- Separate egress policies for package installation, source control, model APIs, and internal services.
OpenAI’s Codex internet-access documentation recommends keeping agent internet access limited, using only the domains and HTTP methods needed, and reviewing the agent’s output and work log. That advice is not Claude-specific; it is a general rule for any tool-using agent with network reach. (developers.openai.com)
Scrub subprocess environments
If a Bash subprocess inherits AWS_SECRET_ACCESS_KEY, GITHUB_TOKEN, ANTHROPIC_API_KEY, OPENAI_API_KEY, KUBECONFIG, or cloud session variables, filesystem isolation will not save you. The secret is already in memory and can be printed, posted, or used.
At minimum, run agent subprocesses with a reduced environment:
env -i \
HOME="$HOME" \
PATH="/usr/bin:/bin:/usr/sbin:/sbin" \
LANG="C.UTF-8" \
claude
That example may be too restrictive for daily use, but it shows the right direction. Enterprise deployments should define a supported wrapper that passes only what the agent needs.
Deny metadata endpoints
Cloud metadata endpoints are high-value targets. Add deny rules for at least:
169.254.169.254
169.254.170.2
metadata.google.internal
metadata.azure.internal
Do not rely only on DNS names. Deny the IP ranges at the network layer where possible. Also consider blocking link-local ranges from agent sandboxes entirely unless a specific workflow needs them.
Test raw protocol paths, not only curl
A common sandbox test is to run curl https://blocked.example and confirm it fails. That is not enough. The Claude Code bypass matters because a raw SOCKS5 path could differ from the ordinary HTTP path. Boundary tests should include the exact protocol entry points the sandbox exposes: HTTP CONNECT, SOCKS5, direct TCP, DNS, package manager traffic, Git over SSH, Git over HTTPS, npm, pip, Docker, and language-specific fetchers.
Security teams do not need to publish exploit PoCs to do this responsibly. They do need internal regression tests that assert malformed hostnames are rejected before any outbound dial occurs.
A safe regression test can target the validation layer without opening a network connection:
import pytest
BAD_HOSTS = [
"evil.example\x00.allowed.example",
"evil.example%00.allowed.example",
"evil.example\r\nhost: allowed.example",
"::ffff:127.0.0.1%allowed.example",
"2852039166",
"169.254.169.254",
]
def test_bad_hosts_rejected():
for host in BAD_HOSTS:
with pytest.raises(ValueError):
normalize_host_for_policy(host)
The production proxy still needs integration tests, but unit tests like this keep canonicalization bugs from reappearing.
How to validate an AI coding agent sandbox
A real security review of an agent sandbox should be adversarial. The question is not “does it work in the demo?” The question is “does it fail closed when an attacker controls context, filenames, config, protocol bytes, DNS responses, package scripts, and tool output?”
A practical review has eight tracks.
1. Trust sequencing
Confirm that nothing from the repository can execute, launch a server, modify settings, change permission mode, connect to MCP servers, or send API requests before the user has explicitly trusted the workspace. CVE-2025-59536 and CVE-2026-21852 both show why sequencing is not a cosmetic issue. (NVD)
2. Filesystem containment
Test reads and writes separately. A sandbox that blocks writes but allows reads of ~/.aws/credenciais can still leak secrets if network egress fails. Verify that deny rules apply to subprocesses, package scripts, child shells, symlinks, hard links, relative paths, path traversal, hidden directories, and imported scripts.
3. Environment containment
Run controlled commands that list available environment variable names, not values. Confirm that sensitive variables are absent from subprocesses by default. Then test whether hooks, MCP servers, plugin scripts, and package managers inherit a different environment.
4. Network egress
Test allowed domains, denied domains, metadata endpoints, private IP ranges, wildcard patterns, raw HTTP CONNECT, raw SOCKS5, language runtime networking, Git, npm, pip, Docker, and dependency resolvers. Include malformed hostnames, trailing dots, IDNs, IPv6 forms, percent signs, CRLF, null bytes, and numeric IPv4 variants.
5. Prompt injection to tool use
Create benign internal test repositories with issue comments, README files, docs, hidden HTML comments, and dependency output that try to instruct the agent to perform restricted actions. The goal is not to trick the model for sport. The goal is to confirm that a manipulated model still cannot cross the execution boundary.
6. Logging and evidence
Every blocked action should leave evidence. If the agent refuses a command but the proxy logs nothing, you may not have enough observability. If the proxy blocks malformed hosts but the SOC cannot search for them, detection will be weak. If a token is used from a new IP and no alert fires, exfiltration review will be slow.
7. Update and advisory monitoring
Track vendor releases, security advisories, GitHub advisories, NVD records, and public research. The Claude Code sandbox issue shows that changelogs may not clearly identify every security-relevant patch. A security program that only watches CVEs will miss some agent-runtime risk.
8. Repeatability
Manual testing once after a public incident is not enough. Agent runtimes change quickly. New features such as hooks, MCP servers, plugins, skills, memory, browser control, computer use, and background sessions add new boundary combinations. Regression tests should run on every agent runtime version you approve.
For teams that already perform authorized security testing, the same discipline used in application pentesting applies here: define scope, run controlled tests, capture commands and outputs, verify exploitability without damaging systems, and turn evidence into a report that engineering can act on. Penligent is one example of an agentic AI pentesting platform built around controlled workflows, human-in-the-loop testing, and evidence-driven outputs for authorized security validation. Its own Claude Code security research page also treats Claude Code as a trust-boundary case study rather than a simple code-scanning problem. (penligent.ai)
That matters because AI agent security testing should not stop at “the model was prompt-injected.” The evidence needs to show which boundary failed, what resource became reachable, which control should have stopped it, and which mitigation prevents the chain from repeating.
Common mistakes teams make
The Claude Code sandbox vulnerability is useful because it exposes several mistakes that are likely to repeat across other coding agents.
Mistake 1, assuming sandbox means all tools are isolated
Claude Code’s documentation is clear that sandboxing applies to Bash commands and child processes, while built-in file tools use the permission system directly. (Claude Code) Other agent platforms make similar distinctions. A sandbox may isolate shell execution without isolating browser control, file reads, MCP tool calls, memory loading, plugin behavior, or IDE integration.
The correct question is always: which action is inside which boundary?
Mistake 2, testing only the normal HTTP path
A proxy may block curl https://blocked.example and still mishandle SOCKS5, CONNECT, Git, dependency managers, or language runtime sockets. Security boundaries need negative tests for every path into the network layer.
Mistake 3, leaving real secrets in developer environments
A developer laptop is often a credential museum. Cloud keys, GitHub tokens, npm tokens, SSH keys, kubeconfig files, registry credentials, database URLs, model API keys, and SSO sessions accumulate over time. If an agent runs near all of them, every sandbox failure becomes higher impact.
Mistake 4, using broad wildcard allowlists
Wildcards are convenient. They are also parser-differential magnets. If *.example.com is allowed, the proxy must correctly handle subdomain boundaries, trailing dots, IDNA, Unicode, percent signs, null bytes, IP literals, DNS rebinding, and resolver behavior. Use exact hostnames wherever possible.
Mistake 5, treating repository configuration as harmless
Project-level agent files can define behavior. Check Point’s Claude Code research showed how repository-controlled settings could interact with hooks, MCP servers, and environment variables. (Pesquisa da Check Point) If a file can cause execution, network access, credential routing, or permission changes, it is not harmless metadata.
Mistake 6, thinking prompt injection is only a model-output problem
Prompt injection is dangerous because it can steer tools. A malicious instruction that only changes a summary is one class of issue. A malicious instruction that causes the agent to run a shell command, read a token, and send data out is a different class. The security boundary belongs around the action, not only around the text.
Mistake 7, relying only on CVEs
CVE tracking is necessary, but it is incomplete for fast-moving agent systems. The SOCKS5 null-byte bypass did not have a public CVE in the sources reviewed here, while the related CVE-2025-66479 applied to sandbox-runtime rather than Claude Code itself. (Aonan Guan) Security teams need vendor release monitoring, GitHub advisory monitoring, code-diff review for critical runtime components, and curated research tracking.
Mistake 8, logging only successful HTTP requests
If raw SOCKS5, CONNECT tunnels, DNS, or subprocess network calls are not visible, you may miss the most important path. Log rejected requests, malformed hosts, proxy validation errors, DNS queries, process ancestry, and token usage. The boundary you cannot observe is the boundary you cannot investigate.
A practical hardening checklist
Use this as a working checklist for AI coding agents, not just Claude Code.
| Controle | Good baseline | Stronger baseline |
|---|---|---|
| Version management | Keep Claude Code and sandbox-runtime updated. | Centralize approved versions and block unmanaged installs. |
| Workspace trust | Require explicit trust for new repos. | Run untrusted repos only in disposable VMs or containers. |
| Filesystem access | Deny known credential paths. | Mount only the project directory and selected cache paths. |
| Environment variables | Remove cloud and API secrets from subprocesses. | Issue short-lived task-scoped tokens only when needed. |
| Network egress | Use narrow allowlists. | Enforce egress outside the agent runtime with a proxy or firewall. |
| Metadata endpoints | Deny link-local metadata hosts. | Block link-local ranges at the namespace or VM layer. |
| MCP and hooks | Review project-defined servers and hooks. | Disallow project-controlled execution config unless signed or approved. |
| Injeção imediata | Treat external content as hostile. | Test injection-to-tool-use chains in regression suites. |
| Logging | Capture process and network telemetry. | Correlate agent sessions with proxy, DNS, cloud, and GitHub audit logs. |
| Incident response | Rotate exposed credentials after high-risk findings. | Maintain a playbook for agent-runtime containment and forensics. |
Safer patterns for agentic development
The long-term fix is not one setting. It is a shift in how development environments are designed.
Put agents in lower-trust zones
A human developer can have a full workstation. An agent should get a smaller box. The agent workspace should have a limited filesystem, limited network, limited credentials, and limited persistence. It should not share the full home directory by default.
Make untrusted content structurally separate
Prompt injection thrives when instruction and data are blended. Use structured extraction for untrusted content. A GitHub issue should become a constrained object with fields such as title, reproduction steps, expected behavior, and actual behavior. It should not become an unreviewed developer instruction with tool authority.
Require typed tool calls and explicit data-flow policy
The agent should not be able to freely decide that a secret, a file, and a network request belong together. Tool schemas should express what data can flow where. High-risk flows should require approval even if the agent is otherwise in an auto mode.
Design egress as a deny-by-default system
A coding task may need GitHub, a package registry, and a model API. It usually does not need arbitrary POST requests to random domains, cloud metadata, private network ranges, paste sites, URL shorteners, or newly registered domains. Deny by default and add narrow exceptions.
Make every privilege temporary
Agent permissions should expire. Tokens should expire. Network exceptions should expire. Workspace trust should be tied to a repository identity and revision, not just a directory path. A permanent permission granted during one debugging session often becomes tomorrow’s attack surface.
Test the control plane as much as the code plane
Traditional AppSec focuses on application code. Agent security also requires reviewing control-plane artifacts: settings, memory, prompts, hooks, skills, plugins, MCP configs, permissions, allowlists, and workflow automation. In an agentic coding environment, those files decide what code can run and what it can reach.
PERGUNTAS FREQUENTES
What was the Claude Code sandbox vulnerability?
- It was a network sandbox bypass involving SOCKS5 hostname null-byte injection.
- The issue affected the path where Claude Code’s sandbox proxy checked a requested hostname against an allowlist.
- A crafted hostname could satisfy a JavaScript suffix check while the underlying resolver connected to a different host.
- The practical risk was outbound access to destinations the user’s sandbox policy intended to block.
Was there a CVE for the SOCKS5 null-byte bypass?
- Public sources reviewed here do not show a dedicated CVE for the SOCKS5 null-byte bypass.
- The related CVE-2025-66479 covers an earlier sandbox-runtime network enforcement bug, not this specific null-byte issue.
- Guan’s disclosure says there was no Claude Code security advisory or CVE for the new bypass at the time of public disclosure.
- Security teams should track both CVE sources and public research because agent-runtime fixes may not always appear as product-level CVEs.
Which Claude Code versions were affected?
- Guan’s public write-up says Claude Code v2.0.24 through v2.1.89 were affected.
- He identifies v2.1.90 as the version where the issue was fixed.
- SecurityWeek reported Anthropic’s statement that the fix shipped earlier, in Claude Code 2.1.88 on March 31, after a sandbox-runtime commit on March 27.
- The safest operational guidance is to update to the latest version and then review historical exposure rather than relying on the disputed boundary.
Can this bug steal AWS or GitHub credentials by itself?
- Not by itself in every environment.
- The dangerous chain requires a vulnerable runtime, a useful egress bypass path, readable credentials or sensitive data, and some way for attacker-influenced code or instructions to run inside the sandbox.
- Developer machines often hold AWS credentials, GitHub CLI tokens, SSH keys, npm tokens, kubeconfig files, and model API keys, so the blast radius can be high when those conditions are met.
- Teams should rotate high-value credentials if they ran affected versions with wildcard allowlists on credential-bearing systems.
How is this different from CVE-2025-66479?
- CVE-2025-66479 was a configuration semantics issue in sandbox-runtime.
- It involved network sandbox enforcement failing when no allowed domains were configured.
- The SOCKS5 null-byte bypass was a parser differential issue, where the policy layer and resolver layer interpreted the same hostname differently.
- Both issues matter because they can let sandboxed code reach hosts the user believed were blocked.
What should security teams check first?
- Check installed and historical Claude Code versions.
- Search for wildcard
allowedDomainsentries and broad network permissions. - Review
.claude/settings.json,.mcp.json, hooks, MCP servers, permission modes, and project memory files. - Identify developer hosts that held AWS, GitHub, npm, PyPI, Kubernetes, or model API credentials.
- Review DNS, proxy, EDR, GitHub audit, and cloud audit logs around agent sessions.
- Rotate credentials where high-risk exposure is plausible.
Are network allowlists still useful for AI agents?
- Yes, but they should be treated as defense-in-depth, not the only boundary.
- Allowlists must be paired with canonicalization, IP-level deny rules, malformed-host rejection, external proxy controls, and regression tests.
- Exact host allowlists are safer than broad wildcard patterns.
- A good design assumes the model may be manipulated and still prevents the tool layer from reaching unsafe destinations.
How should teams test AI coding agent sandboxes?
- Test both normal and raw protocol paths, including HTTP CONNECT, SOCKS5, Git, npm, pip, Docker, and language runtime networking.
- Include negative tests for null bytes, CRLF, percent signs, trailing dots, IDN, IPv6 zone IDs, numeric IPv4 variants, and metadata endpoints.
- Test filesystem access and network access together, because readable secrets plus weak egress create exfiltration risk.
- Test prompt injection chains that try to move from untrusted content to tool use.
- Require logs for both blocked and allowed actions so investigations are possible.
Julgamento final
The Claude Code sandbox bypass is not just a story about one null byte. It is a story about where AI agent security actually lives.
It lives in the seam between prompt and tool call. It lives in repository configuration that looks passive but changes execution. It lives in whether a child process can read cloud credentials. It lives in whether a proxy matches the same hostname the operating system dials. It lives in whether a developer can tell, from logs and advisories, that a boundary they trusted was ever broken.
A coding agent does not need to be malicious to become dangerous. It only needs to be useful enough to act, connected enough to matter, and trusted enough that users stop checking every step. The right response is not panic. It is engineering discipline: smaller privileges, disposable workspaces, strict egress, secret isolation, prompt-injection testing, and evidence that the sandbox fails closed when the agent is wrong.

