Novo Nordisk has confirmed an IT security incident involving unauthorized access to a limited number of internal IT systems and unauthorized copying of certain non-public data, including some personal data. The company also said the incident affected a limited amount of information related to patients participating in some clinical trials, that the data was not directly linked to patients by name or other direct identifiers, and that core business operations were not impacted. (Novo Nordisk)
That is the confirmed baseline.
The larger and more explosive part of the story comes from outside the company. Reuters reported that a cyber extortion group calling itself FulcrumSec claimed it stole more than a terabyte of data from Novo Nordisk, demanded 25 million dollars, and said the data included source code, proprietary information on released and unreleased drugs, trial data, employee, doctor and patient data, processing facility information, and internal AI model information. Reuters also stated that it could not immediately verify the authenticity of the data posted by the hacking group. (Reuters)
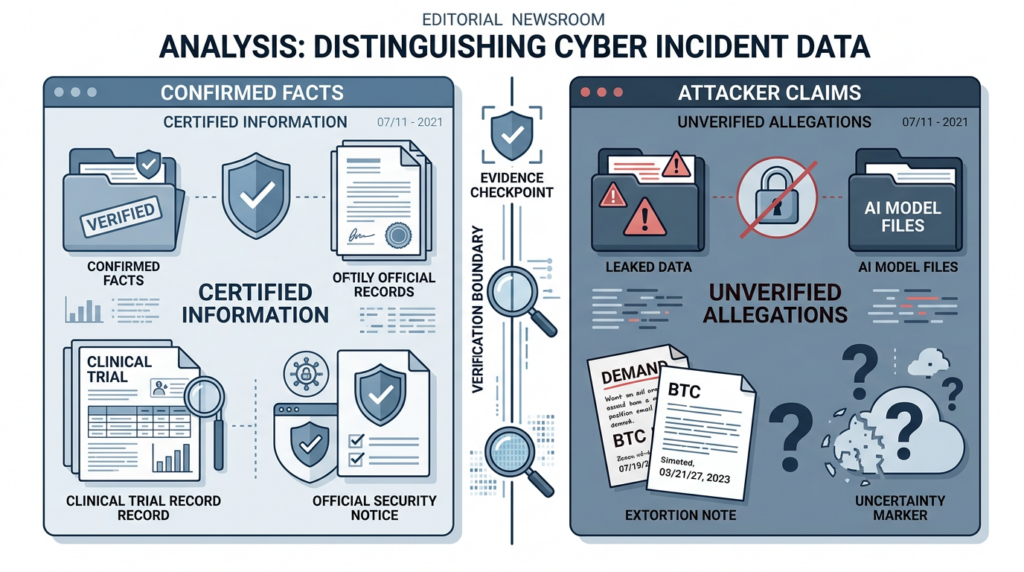
That distinction matters. A responsible security analysis of the Novo Nordisk data breach has to keep two categories separate: what Novo Nordisk has confirmed, and what the attackers claim. The confirmed incident is serious on its own because it involves clinical trial data and non-public company data. The unverified claims matter because they point to a much larger security question: what happens when a pharmaceutical breach is not only about patient records, but also about AI model assets, research pipelines, training data, model configurations, and drug-discovery infrastructure?
For defenders, the lesson is not to sensationalize “AI model theft” before the evidence supports it. The lesson is to treat the claim as a warning shot. Pharmaceutical companies, biotech firms, contract research organizations, AI labs, and healthcare technology vendors now operate environments where clinical data, scientific code, model artifacts, cloud credentials, notebooks, and high-performance computing systems can sit close together. If those boundaries are weak, a breach that starts as an IT incident can become an intellectual property, privacy, regulatory, and AI supply-chain event at the same time.
What Novo Nordisk confirmed
Novo Nordisk’s public incident update says the company identified unauthorized access to a limited number of internal IT systems. It also says the incident included unauthorized access to certain personal data stored on those systems. For clinical trial patients, the company described the affected data as a limited amount of information related to some clinical trials and said it was not directly linked to patients by name or other direct identifiers. (Novo Nordisk)
Reuters’ earlier report on June 11 matched that official framing. It reported that certain information, including patient data from some clinical trials, was copied externally without authorization from internal IT systems. Reuters also reported that potential categories of affected personal data may include patient ID, year of birth, sex, and health or immunogenicity data, and that Novo Nordisk had temporarily taken certain internal IT systems offline while working to bring them back in a controlled and safe manner. (Reuters)
The language is narrow, and security teams should respect that. The company did not publicly confirm the total number of affected individuals in the source material reviewed here. It did not publicly confirm that AI models, production facility software, unreleased drug data, or 1.3 terabytes of data were stolen. It did not publicly disclose the initial access vector, dwell time, specific systems affected, malware family, ransomware tooling, or any technical indicators of compromise.
That leaves a common but uncomfortable situation for defenders: there is enough confirmed information to require serious response, but not enough public technical detail to reconstruct the incident. The right approach is to use the case as a threat model, not as a guessed intrusion report.
Confirmed, claimed, and still unknown
| Categoria | What is currently supported | How to phrase it responsibly |
|---|---|---|
| Acesso não autorizado | Novo Nordisk confirmed unauthorized access to a limited number of internal IT systems. | Novo Nordisk confirmed an IT security incident involving limited internal systems. |
| Data copied externally | Novo Nordisk said certain non-public data, including personal data, was copied externally without authorization. | Certain non-public data was copied externally without authorization, according to Novo Nordisk. |
| Clinical trial patient data | Novo Nordisk said a limited amount of information related to patients in some clinical trials was affected and not directly linked to names or direct identifiers. | The confirmed patient-related impact concerns limited pseudonymized clinical trial data. |
| Business operations | Novo Nordisk said its core business operations were not impacted and remained up and running. | Core business operations were not impacted, according to the company. |
| FulcrumSec involvement | Reuters reported that FulcrumSec claimed responsibility. | FulcrumSec claimed responsibility, according to Reuters. |
| 1.3TB data theft | Reuters reported that FulcrumSec and DataBreaches.net described roughly 1.3TB of data, but Reuters could not immediately verify authenticity. | The attackers claimed a much larger data theft, but the full scope has not been independently verified. |
| AI model information | Reuters reported that the attackers claimed the data included internal AI model information. | Attackers claimed AI model information was included; Novo Nordisk has not publicly confirmed that detail in the reviewed sources. |
| Initial access vector | Not publicly confirmed in the reviewed sources. | Avoid stating how the attackers got in unless new evidence is available. |
The table is not a formality. It is the difference between useful incident analysis and rumor laundering. In breach reporting, attackers have incentives to exaggerate, victims have incentives to speak narrowly until investigation and legal review mature, and third parties often see only fragments. A careful article can still be strong without pretending every claim has the same evidentiary weight.
Why the Novo Nordisk data breach matters beyond patient records
Clinical trial data is not ordinary customer data. It may not include names or addresses, but it can still describe sensitive biological, medical, and behavioral attributes. Novo Nordisk said the exposed clinical trial information was not directly linked to patients by name or other direct identifiers, and that identity knowledge would require further information not exposed in the incident. (Novo Nordisk)
That is important. Pseudonymization reduces risk. It can make direct identification harder, especially if the key linking trial IDs to real identities remains protected. But pseudonymized data is not the same as meaningless data. It can still be sensitive because it describes real people, real trial participation, real health measurements, and real research contexts.
A clinical trial record can carry value in at least four ways.
First, it can reveal patient-related information. Even when direct identifiers are removed, combinations of trial type, site, demographic attributes, rare disease context, treatment timing, biomarker values, and external knowledge can sometimes create re-identification risk. The degree of risk depends on the dataset, population size, uniqueness of attributes, and whether attackers can combine the data with other sources.
Second, it can reveal research direction. Trial data may show which endpoints matter, which patient populations are being studied, what inclusion and exclusion logic was used, and where a program is scientifically strong or weak. That information can matter to competitors, short sellers, litigants, and hostile intelligence services.
Third, it can create regulatory and trust impact. Clinical research depends on patient trust, investigator confidence, institutional review processes, and regulatory credibility. A breach can force time-consuming coordination across privacy, legal, clinical operations, sponsor teams, vendors, data protection officers, regulators, investigators, and patients.
Fourth, it can expose operational seams. Even if the stolen data itself is limited, the breach can reveal where clinical systems, research systems, identity systems, cloud storage, and internal collaboration tools intersect. Attackers often value those seams because they help plan follow-on attacks.
The data classes defenders should map first
| Data class | Why attackers care | Typical storage locations | Defensive priority |
|---|---|---|---|
| Pseudonymized clinical trial data | Sensitive health context, trial participation, biomarker patterns, possible re-identification when combined with other data | Clinical data repositories, SAS/R/Python analysis environments, EDC exports, secure file shares, object storage | Alta |
| Patient identity linkage keys | Converts pseudonymized trial IDs into real identities | Restricted clinical systems, CRO-managed systems, identity mapping stores | Crítico |
| Protocols and statistical analysis plans | Reveals trial design, endpoints, success criteria, and commercial strategy | Document management systems, SharePoint, Veeva-like systems, internal drives | Alta |
| Source code and analysis scripts | Reveals data processing logic, model features, quality controls, and possible secrets | Git repositories, notebooks, CI systems, data science workspaces | Alta |
| Model weights and checkpoints | Can represent expensive research investment and encode learned behavior from proprietary data | Model registries, artifact stores, object buckets, HPC storage, notebook caches | Alta |
| Training data and feature stores | May contain proprietary data, patient-derived features, lab measurements, or sensitive research artifacts | Feature stores, lakehouses, cloud storage, data marts | Crítico |
| HPC and container images | May expose runtime dependencies, credentials, job logic, and internal network paths | Slurm clusters, Kubernetes registries, Docker registries, CI artifacts | Alta |
| API tokens and cloud secrets | Enables follow-on access and large-scale exfiltration | Notebooks, CI variables, secret managers, environment files, shell history | Crítico |
Security teams in pharma should not wait for a public breach claim before building this inventory. The inventory is the security boundary. If a team cannot quickly answer where model artifacts, clinical datasets, training jobs, credentials, and notebooks live, it cannot confidently assess exposure after an incident.
The AI model theft claim, and why it should be handled carefully
Reuters reported that FulcrumSec claimed the stolen data included internal AI model information. Reuters also reported that the group said it spent more than two months in Novo Nordisk’s networks, that it demanded 25 million dollars, and that it was exploring private sales of some data after the company refused to pay. Reuters explicitly said it could not immediately verify the authenticity of the data posted by the group. (Reuters)
That means “Novo Nordisk AI model theft” should not be written as a confirmed fact unless new evidence emerges. The accurate statement is narrower: attackers claimed internal AI model information was included in stolen data, and that claim has not been publicly confirmed by Novo Nordisk in the reviewed official update.
Even with that caveat, the claim is meaningful. AI assets in pharmaceutical environments are not just files with a .pt, .safetensors, .onnxou .pkl extension. The valuable asset may be the entire experiment context: source code, model configuration, feature engineering pipeline, training data lineage, hyperparameters, evaluation logs, container image, HPC job scripts, access tokens, and the undocumented decisions that make a model reproducible.
A stolen checkpoint can matter. A stolen training pipeline can matter more. A stolen pipeline with associated clinical features, model evaluation data, source code, and infrastructure context can matter most.
This is why defenders should avoid a narrow mental model of AI model security. Protecting AI assets is not only about preventing model extraction through an inference API. It is also about preventing attackers from walking through the research environment where models are created, tuned, evaluated, deployed, and archived.
Pharma AI infrastructure is now a breach target
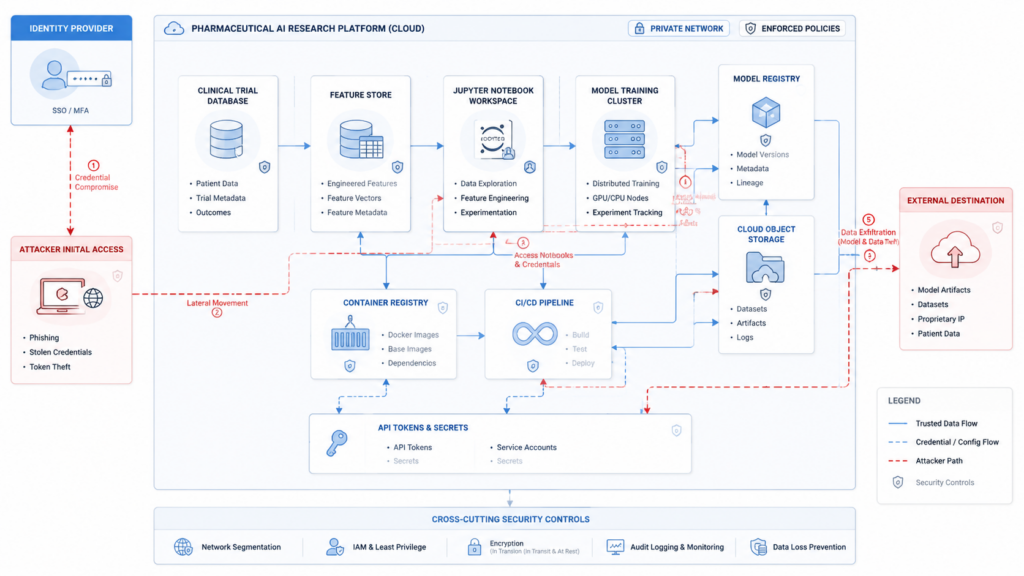
Pharmaceutical AI environments often combine characteristics that attackers like.
They contain high-value intellectual property. They process sensitive data. They depend on open-source libraries. They use cloud storage and distributed compute. They often support collaboration with universities, CROs, biotech partners, and software vendors. They rely on notebooks and experimental workflows because research work is exploratory by nature. They may run on HPC clusters, Kubernetes, managed notebook platforms, or hybrid infrastructure that evolved faster than traditional enterprise governance.
That does not mean pharma AI teams are careless. It means the environment is hard to secure because the work itself is complex. Researchers need flexibility. Data scientists need to test models. Bioinformatics teams need to move large datasets. Clinical operations teams need vendor coordination. Platform teams need to support GPU workloads and storage-heavy pipelines. Security teams need to impose controls without breaking research velocity.
The conflict is real. But attackers do not care whether the environment is hard to govern. They care whether they can get data, code, credentials, and leverage.
OWASP’s LLM security work captures several risks that apply directly to AI-heavy pharma environments, including prompt injection, training data poisoning, supply chain vulnerabilities, sensitive information disclosure, excessive agency, and model theft. OWASP describes model theft as unauthorized access to proprietary large language models that risks theft, loss of competitive advantage, and dissemination of sensitive information. (OWASP)
The OWASP list is framed around LLM applications, but the operational lesson is broader. Model theft is not isolated from supply-chain risk. Supply-chain risk is not isolated from sensitive information disclosure. Sensitive information disclosure is not isolated from overprivileged tools, plugins, data pipelines, and model registries. In real AI environments, these risks overlap.
How attackers can turn research infrastructure into a data theft path
There is no public evidence in the reviewed sources that confirms the exact intrusion path in the Novo Nordisk incident. Any technical path described below should be read as defensive threat modeling, not as a claim about what happened.
A pharma AI environment can be compromised through several realistic patterns.
An attacker may start with identity. A stolen employee credential, contractor account, VPN session, SSO token, or service account can lead to internal systems. If multifactor authentication is weak, bypassed, phished, or not applied consistently to research systems, the attacker may gain a foothold without triggering obvious malware alerts.
An attacker may start with collaboration tooling. Research partnerships often require shared datasets, shared notebooks, external repositories, file transfer portals, or vendor-managed platforms. Those collaboration edges can become difficult to monitor because external access is expected.
An attacker may start with the software supply chain. A malicious dependency, compromised package, poisoned model repository, vulnerable MLOps service, or unsafe model loader can execute code inside an environment that has access to datasets and secrets.
An attacker may start with exposed infrastructure. Jupyter notebooks, MLflow servers, Ray dashboards, object stores, Kubernetes dashboards, artifact registries, and internal APIs are all valuable if reachable from the wrong network segment or protected by weak authentication.
An attacker may start with a developer workstation. Data scientists and ML engineers often have broad access to code, credentials, datasets, and cloud tooling. A compromised workstation can be more valuable than a compromised production web server because it may hold the keys to research systems.
These paths are not unique to pharma, but pharma raises the stakes. A successful intrusion can touch patient data, regulated research records, drug-development IP, AI models, production facility context, and corporate strategy in one campaign.
Threat modeling common pharma AI breach paths
| Possible entry point | What the attacker may reach | Typical weak signal | Immediate validation step |
|---|---|---|---|
| Stolen SSO or VPN credentials | File shares, repositories, clinical documents, notebook platforms | Login from unusual geography, impossible travel, new device, odd time | Review identity logs, MFA events, device posture, and session duration |
| Overexposed notebook server | Cloud credentials, datasets, model caches, shell access | New notebooks, unusual package installs, outbound connections | Snapshot instance, collect shell history, inspect environment variables and tokens |
| Vulnerable MLOps platform | Model registry, artifacts, experiments, dataset references | Large artifact downloads, new registered models, changed tracking URI | Review MLflow or registry logs, artifact access patterns, and admin changes |
| Compromised CI runner | Source code, secrets, container registries, deployment tokens | Unexpected pipeline runs, artifact upload changes, token usage outside CI | Rotate CI secrets, compare pipeline definitions, inspect runner filesystem |
| HPC or Slurm management exposure | Training jobs, shared storage, scripts, SSH keys, logs | New jobs under unusual accounts, staging archives, compression commands | Review scheduler logs, SSH logs, shared filesystem access, and job scripts |
| Object storage misconfiguration | Clinical exports, model checkpoints, training data, backups | Bulk listing, large downloads, new access keys | Review bucket policies, access logs, object-level events, and key age |
| Malicious model or dependency | Code execution during model loading or package install | Network calls during model load, suspicious cache files, new Python modules | Freeze environment, inspect dependency tree, scan model repository metadata |
| Third-party integration | Shared trial data, research workspace, vendor-managed exports | Access through vendor IPs outside expected pattern | Validate vendor access logs, contract scope, data transfer records |
The practical goal is not to predict the exact attack. The goal is to shorten the time between “we heard a breach claim” and “we know which systems, identities, datasets, models, and secrets were actually exposed.”
Related CVEs show why AI and MLOps systems deserve first-class security review
The Novo Nordisk incident does not currently have a public CVE tied to it. But several recent vulnerabilities show why AI and MLOps environments cannot be treated as passive research tools. The relevant pattern is simple: model loading, artifact handling, and AI infrastructure can cross into code execution, data theft, or model tampering.
CVE-2026-4372, model loading as a code execution boundary
CVE-2026-4372 involved Hugging Face Transformers and a malicious model configuration path that could trigger remote code execution during model loading. Pluto Security described the issue as config injection via _attn_implementation_internal that could bypass trust_remote_code=False, with exploitation occurring through normal model loading such as from_pretrained(). (Pluto Security)
The relevance to pharma AI security is direct. Many research environments load third-party models, internal models, benchmark models, or partner-provided artifacts. Developers may believe a model load is equivalent to reading data. CVE-2026-4372 shows why that belief can be dangerous. A model repository can contain configuration and metadata that influence runtime behavior.
The practical conditions matter. An attacker generally needs the victim or an automated workflow to load a crafted model repository in a vulnerable environment. The risk rises if that environment contains cloud credentials, dataset access, Git tokens, internal network access, or mounted research storage.
The mitigation is not only “upgrade Transformers.” Upgrading is mandatory, but the deeper control is to treat external model repositories as software supply-chain inputs. Pin revisions. Allowlist approved sources. Inspect model artifacts before loading. Run external model evaluation in isolated environments without long-lived secrets. Log model identifiers, revisions, callers, dependency versions, and runtime context. Penligent’s technical write-up on CVE-2026-4372 makes the same operational point: a model load should not silently become a shell, and defenders need repeatable validation across notebooks, containers, CI runners, caches, and internal tools. (Penligente)
CVE-2024-0520, MLOps tooling can become an RCE path
CVE-2024-0520 is an MLflow vulnerability in version 8.2.1. NVD describes it as remote code execution caused by improper neutralization of special elements used in an OS command in mlflow.data.http_dataset_source.py. The vulnerable path involved loading a dataset from an HTTP source where filename handling could lead to path traversal or arbitrary file write, potentially allowing command execution and access to data and model information. NVD notes the issue is fixed in MLflow 2.9.0. (NVD)
The relevance is not that every MLflow deployment is exposed to this exact bug today. The relevance is that MLOps systems often sit near model artifacts, experiments, dataset references, metrics, notebooks, and credentials. A vulnerability in the experiment-tracking or dataset-loading layer can become a research data exposure issue.
The mitigation pattern is familiar but often underapplied in research environments. Keep MLOps services patched. Put them behind strong authentication and network controls. Avoid exposing tracking servers to broad networks. Restrict artifact storage permissions. Separate experiment metadata from sensitive raw datasets. Log artifact downloads. Treat model registry admin actions as privileged events.
CVE-2026-25874, unsafe deserialization in AI pipelines is still alive
CVE-2026-25874 affects Hugging Face LeRobot through 0.5.1. NVD describes an unsafe deserialization vulnerability in the async inference pipeline where pickle.loads() deserializes data received over unauthenticated gRPC channels without TLS in policy server and robot client components. An unauthenticated network-reachable attacker could send crafted pickle payloads through gRPC calls and achieve arbitrary code execution on the server or client. (NVD)
The relevance is broader than robotics. AI systems often exchange serialized objects across processes, services, and workers. When those objects use unsafe formats and travel over unauthenticated or weakly protected channels, the model pipeline becomes a code execution surface.
The mitigation is straightforward in principle and hard in legacy systems: do not deserialize untrusted pickle data, require authentication and TLS for inference and control channels, replace unsafe serialization with safer formats where possible, constrain network reachability, and monitor unexpected inbound calls to model-serving components.
The common thread
| Vulnerabilidade | AI security lesson | Exploitation condition | Defensive action |
|---|---|---|---|
| CVE-2026-4372 | Model loading can become remote code execution when configuration influences code paths. | Victim or workflow loads malicious model in affected Transformers environment. | Upgrade, allowlist model sources, pin revisions, isolate model loading, log model IDs and revisions. |
| CVE-2024-0520 | MLOps dataset and artifact handling can lead to code execution and data exposure. | Vulnerable MLflow version processes attacker-influenced dataset URL or headers. | Upgrade MLflow, restrict network exposure, validate dataset sources, monitor artifact access. |
| CVE-2026-25874 | AI inference pipelines can still fail on unsafe deserialization and unauthenticated channels. | Network-reachable attacker sends crafted pickle payload over affected gRPC calls. | Remove unsafe deserialization, enforce TLS and auth, segment inference services. |
| PyTorch model loading issues such as CVE-2025-32434 | “Safe mode” flags can fail if the underlying library has vulnerable loading paths. | Crafted model file or loading path reaches unsafe execution despite expected guardrail. | Patch, prefer safer formats, isolate runtime, avoid loading untrusted artifacts in privileged environments. |
The durable lesson is that AI systems are software systems. The joint guidance on deploying AI systems securely from NSA, CISA, FBI, and international partners states this directly: models are software, may have vulnerabilities or malicious code or properties, and should be validated before and during use. The guidance also recommends cryptographic methods, digital signatures, checksums, version control with access controls, secure supply-chain review, inspection of imported models in a secure development zone, continuous scans, and protection of model weights.
Detection, evidence, and validation after a pharma AI breach claim
A breach claim involving clinical trial data and AI model information requires two investigations that must meet in the middle.
The first is the classic incident response investigation: identity, endpoint, network, cloud, email, malware, lateral movement, data staging, exfiltration, persistence, and privilege escalation.
The second is the AI and research asset investigation: models, checkpoints, notebooks, training jobs, experiment logs, feature stores, model registries, clinical exports, data science workspaces, HPC shared storage, container registries, and research collaboration systems.
If those two investigations run separately, important evidence will fall through the cracks. Endpoint teams may not know what a model cache means. Data science teams may not know which logs matter for exfiltration. Legal teams may not know whether a checkpoint contains sensitive derived information. Cloud teams may see bulk object reads without knowing whether those objects are trial data, model weights, or harmless test artifacts.
A useful workflow starts with asset mapping.
Create a time-bounded exposure map
For the suspected intrusion window, identify:
- Human accounts with access to clinical trial data, research file shares, notebook platforms, model registries, HPC systems, and cloud buckets.
- Service accounts and tokens used by notebooks, training jobs, CI runners, model serving systems, and data transfer tools.
- Model artifacts created, modified, downloaded, exported, or deleted.
- Datasets accessed or copied, including clinical exports, feature stores, derived datasets, and de-identified or pseudonymized tables.
- Large archive creation events, including
.zip,.tar,.tgz,.7z, and staged folders. - Outbound transfers to unusual destinations, new cloud regions, unknown domains, personal storage services, or VPS providers.
- Source code repositories cloned or archived during the window.
- Container images pulled or pushed from research registries.
- SSH, Slurm, Kubernetes, Jupyter, MLflow, Git, object storage, and IdP logs.
The output should not be a narrative. It should be a table of assets, owners, locations, access paths, sensitivity, last access, anomalous access, evidence quality, and next action.
Search code for high-risk model and serialization patterns
The following examples are defensive search patterns for authorized environments. They do not prove compromise. They help teams find where AI artifact loading, unsafe serialization, and model intake paths exist.
# Search repositories for common model loading and unsafe deserialization patterns.
# Run only in repositories you are authorized to review.
rg -n --hidden --glob '!*.ipynb_checkpoints/*' \
'from_pretrained\(|torch\.load\(|pickle\.loads\(|pickle\.load\(|joblib\.load\(|mlflow\.pyfunc\.load_model|mlflow\.models|AutoModel|AutoTokenizer|pipeline\(' \
./repos
This search is intentionally broad. It will produce false positives. That is acceptable at the discovery stage. The next step is to classify each hit by trust boundary:
- Does the model ID or file path come from an allowlisted internal source?
- Can a user, partner, or external request influence the model path?
- Is the loaded artifact pinned to a specific revision or digest?
- Does the runtime contain secrets or sensitive datasets?
- Is model loading isolated from production networks?
- Is the dependency version patched?
- Is the action logged well enough for later investigation?
Scan local model directories for risky configuration fields
The following Python script searches model directories for configuration fields that deserve review. It does not load the model. It only parses JSON files.
#!/usr/bin/env python3
import json
import pathlib
import sys
RISKY_KEYS = {
"_attn_implementation_internal",
"_experts_implementation_internal",
"auto_map",
"architectures",
"model_type",
}
def scan_config(path: pathlib.Path) -> None:
try:
data = json.loads(path.read_text(encoding="utf-8"))
except Exception as exc:
print(f"[WARN] Could not parse {path}: {exc}")
return
hits = sorted(k for k in RISKY_KEYS if k in data)
if hits:
print(f"\n[REVIEW] {path}")
for key in hits:
value = data.get(key)
value_preview = repr(value)
if len(value_preview) > 300:
value_preview = value_preview[:300] + "..."
print(f" - {key}: {value_preview}")
def main(root: str) -> None:
root_path = pathlib.Path(root).expanduser().resolve()
for config in root_path.rglob("config.json"):
scan_config(config)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: scan_model_configs.py /path/to/model/cache/or/artifacts")
sys.exit(1)
main(sys.argv[1])
A hit is not automatically malicious. Some fields are common in legitimate model repositories. The value of the scan is that it helps investigators avoid loading unknown models just to inspect them. Static review comes first. Execution, if necessary, belongs in a disposable sandbox with no secrets and tightly controlled network egress.
Find large staged archives and possible exfiltration preparation
Attackers often stage data before exfiltration. The exact method varies, but defenders should look for sudden archive creation, compression tools used by unusual accounts, and large files appearing in temporary directories or research workspaces.
# Find recently modified large archives in shared research paths.
# Adjust paths and time windows for your environment.
find /research /shared /home -xdev -type f \
\( -name "*.zip" -o -name "*.tar" -o -name "*.tgz" -o -name "*.tar.gz" -o -name "*.7z" \) \
-size +500M -mtime -30 \
-printf "%TY-%Tm-%Td %TH:%TM %s %u %p\n" 2>/dev/null | sort
The goal is not to accuse every large archive. Data science teams legitimately create large files. The question is whether the account, location, timing, source data, and destination match expected work.
Use detection logic for unusual artifact downloads
A Sigma-style rule can help translate the idea into SIEM logic. The fields will vary by cloud provider and logging platform.
title: Unusual Bulk Download of AI or Clinical Research Artifacts
status: experimental
description: Detects unusually large download volume from model, artifact, or clinical research storage paths by a user or service account.
logsource:
category: cloud
product: object_storage
detection:
selection:
event.action:
- GetObject
- DownloadObject
- ReadObject
object.key|contains:
- "/models/"
- "/checkpoints/"
- "/mlflow-artifacts/"
- "/clinical-trials/"
- "/feature-store/"
- "/notebooks/"
timeframe: 1h
condition: selection
fields:
- user.name
- user.id
- source.ip
- object.bucket
- object.key
- object.size
- user_agent
- geo.country
- cloud.region
falsepositives:
- Approved model migration
- Scheduled backup
- Large training job reading approved data
level: high
This rule is a starting point, not a finished detection. Mature detection needs baselines: which service accounts normally read these paths, which jobs read large data, which IP ranges are expected, which buckets belong to research, and which projects are under active training.
Use Semgrep-style checks for unsafe deserialization patterns
rules:
- id: python-unsafe-pickle-load-in-ai-service
message: "Avoid pickle.load or pickle.loads on untrusted data in AI services. Use safer serialization or strict validation in isolated runtimes."
severity: WARNING
languages:
- python
patterns:
- pattern-either:
- pattern: pickle.load($X)
- pattern: pickle.loads($X)
metadata:
category: security
technology:
- python
- machine-learning
- model-serving
This rule will not solve deserialization risk by itself. It helps identify code that deserves review. The hard part is determining whether $X can be influenced by a user, a network request, a model artifact, a message queue, or a partner system.
What good incident evidence looks like
A breach involving possible pharma AI assets should preserve evidence in ways that support both technical response and legal review. Useful evidence includes:
| Evidências | Por que é importante | Erro comum |
|---|---|---|
| Identity logs | Establishes who accessed research systems and when. | Looking only at human accounts and ignoring service accounts. |
| Object storage access logs | Shows reads, listings, downloads, and unusual transfer patterns. | Logging only bucket-level events but not object-level access. |
| Model registry audit logs | Shows artifact downloads, model version changes, and registry admin actions. | Treating model registry logs as lower priority than production app logs. |
| Notebook snapshots | Captures code, environment variables, local caches, shell history, and package versions. | Rebuilding or deleting notebooks before evidence collection. |
| Container image digests | Identifies exactly what runtime was used during suspicious jobs. | Checking requisitos.txt but not the final running image. |
| HPC scheduler logs | Shows job submissions, users, commands, runtime, and output paths. | Ignoring research clusters because they are outside classic enterprise monitoring. |
| Git audit logs | Shows repository clones, token use, branch access, and unusual downloads. | Reviewing only commits and missing clone/archive events. |
| DNS and proxy logs | Helps detect staging, command-and-control, and exfiltration destinations. | Keeping too short a retention window for research networks. |
The evidence should be tied to questions the organization must answer: what was accessed, what was copied, whether the data was personal data or trade secret material, whether model artifacts were exposed, whether secrets were compromised, whether the attacker could return, and which parties must be informed.
Regulatory and privacy response cannot wait for perfect certainty
Novo Nordisk said it is in contact with relevant authorities and is informing impacted parties as appropriate. (Novo Nordisk) The company is headquartered in Denmark and operates globally, so privacy analysis may involve multiple regimes depending on affected individuals, data location, corporate entities, processors, and trial sites.
Under GDPR Article 33, a personal data breach must generally be notified to the competent supervisory authority without undue delay and, where feasible, within 72 hours after the controller becomes aware of it, unless the breach is unlikely to result in a risk to individuals’ rights and freedoms. (gdpr-info.eu)
That does not mean every breach has the same notification path, and it does not justify speculation about Novo Nordisk’s compliance. It does mean incident response must integrate legal, privacy, security, clinical operations, and communications teams early. Waiting for full forensic certainty can create regulatory risk. Acting without evidence can create inaccurate notifications. The work is to update facts as confidence improves.
For clinical trial data, response teams should answer:
- Which trial programs and geographies are affected?
- Are the affected records pseudonymized, anonymized, directly identifiable, or mixed?
- Were linkage keys exposed?
- Which data elements were copied?
- Are any special-category health data elements involved?
- Are investigators, sites, CROs, ethics boards, regulators, or patients affected?
- Does the data include adverse event information, immunogenicity data, biomarkers, genomic data, or rare disease context?
- Was the data copied by a criminal group, a nation-state actor, an insider, or an unknown party?
- Are there signs of public release, private sale, or targeted misuse?
For AI model and research assets, response teams should answer:
- Were model weights, checkpoints, training datasets, feature stores, or evaluation sets accessed?
- Were model configuration files, source code, notebooks, or experiment logs accessed?
- Were cloud credentials, Git tokens, API keys, SSH keys, or service account tokens present in the affected environment?
- Could the attacker reproduce or poison a model training pipeline?
- Could the attacker infer sensitive training data from the stolen artifacts?
- Could stolen model artifacts create safety, commercial, or regulatory concerns?
- Were any AI systems used in regulated decision-making, clinical workflows, manufacturing support, or pharmacovigilance?
These are not abstract governance questions. They drive containment, notification, credential rotation, competitive risk assessment, and legal strategy.
AI SBOMs and model lineage are becoming practical security controls
CISA’s 2026 resource on SBOM for AI describes an SBOM as an ingredients list for software and frames AI supply-chain transparency as a way to help organizations understand components and dependencies. (CISA)
That idea is moving from policy language into incident response reality. When a breach claim mentions AI models, a company should not need weeks to answer basic questions about model lineage. It should know which model versions exist, where they came from, which datasets trained them, which libraries loaded them, which containers ran them, which environments had access, which secrets were available, and which downstream systems consumed their outputs.
A useful AI SBOM or model bill of materials should include:
| Componente | Minimum useful metadata | Why it matters after a breach |
|---|---|---|
| Model artifact | Name, version, hash, format, storage path, owner, approval status | Proves which artifact was used and whether it changed. |
| Source repository | Repository URL, commit hash, branch, reviewer, build pipeline | Links model behavior to code and review history. |
| Training data | Dataset IDs, sensitivity class, lineage, retention rules, access group | Determines whether exposed model artifacts imply sensitive data exposure. |
| Dependencies | Python packages, CUDA stack, framework versions, base image digest | Supports CVE triage and reproducibility. |
| Runtime | Container image, environment variables, network policy, secret mounts | Defines blast radius if code execution occurred. |
| Evaluation data | Test sets, benchmark scripts, clinical validation context | Shows whether validation material or regulated evidence was exposed. |
| Access history | Users, service accounts, jobs, downloads, external shares | Supports breach impact analysis. |
| Signing and integrity | Hashes, signatures, attestation, approval workflow | Helps distinguish authorized artifacts from tampered ones. |
The joint AI deployment guidance recommends hashes, encrypted copies, secure vaults or HSMs, version control for code and artifacts, supply-chain review for external models and data, and inspection of imported pre-trained models in a secure development zone. Those are not paperwork exercises. They are the controls that let teams answer breach questions under pressure.
Defensive priorities for pharma and biotech teams
The following priorities are written for organizations that hold sensitive research data and operate AI or MLOps workflows. They apply whether the organization is a large pharmaceutical company, a biotech startup, a CRO, a lab automation vendor, or a healthcare AI provider.
Build a real research asset inventory
A CMDB that knows about laptops and servers is not enough. The inventory must include:
- Clinical datasets and derived feature tables.
- Model checkpoints and weights.
- Model registries and artifact stores.
- Notebooks and managed data science workspaces.
- Training and inference jobs.
- HPC clusters and shared filesystems.
- CI runners and build artifacts.
- Container registries.
- Data transfer tools.
- Collaboration portals.
- External research partner access.
- Long-lived service accounts and secrets.
Each asset should have an owner, sensitivity class, data classification, access path, retention rule, and logging status. If it does not have an owner, it is already a breach response problem waiting to happen.
Separate clinical data from experimental model work
Research teams often need clinical data, but they do not need unlimited access everywhere. Separate raw clinical data, pseudonymized datasets, derived feature stores, model training environments, and inference environments. Use controlled data release processes, narrow service accounts, and project-specific storage boundaries.
The key question is simple: if a notebook or training job is compromised, what can it read without further approval? If the answer is “most of the research lake,” the environment is not segmented enough.
Treat notebooks as privileged systems
Notebook environments are often treated like personal productivity tools. That is a mistake. A notebook can run arbitrary code, hold credentials, access datasets, fetch models, call APIs, and stage files. It deserves the controls applied to privileged workstations and production systems.
Use short-lived credentials. Disable broad instance metadata access. Restrict outbound network access. Log shell commands where appropriate. Isolate notebook projects. Prevent direct access to raw clinical data unless approved. Rebuild base images regularly. Scan packages and model caches. Keep notebooks out of flat internal networks.
Lock down model registries and artifact stores
Model registries and artifact stores can become the central vault for AI intellectual property. Treat them like source code repositories plus sensitive data stores.
Require strong authentication. Use least privilege. Separate read, write, approve, and deploy permissions. Log all downloads and model version changes. Require approvals for external model ingestion. Store hashes and signatures. Alert on bulk downloads and unusual access patterns. Keep production-approved models separate from experimental or untrusted models.
Pin model and dependency versions
Do not let production or shared evaluation environments pull arbitrary latest models or packages. Pin model revisions, package versions, container image digests, and base images. Record the exact dependency state of training and inference jobs. If a vulnerability appears in a framework such as Transformers, PyTorch, MLflow, or a model-serving stack, the organization should be able to answer where it runs.
Centralize external model intake
If every team can independently pull models from public hubs into privileged environments, policy becomes advisory. A central model intake process can enforce scanning, approval, license review, provenance checks, revision pinning, sandbox evaluation, and logging.
This does not need to block research. It can provide fast lanes for low-risk experimentation and stricter lanes for sensitive environments. The important point is that external model loading should not be invisible.
Restrict egress from research runtimes
Many data exfiltration events succeed because outbound access is too open. Training jobs, notebooks, and model evaluation containers often do not need unrestricted internet access. Use egress proxies, domain allowlists, private package mirrors, approved model mirrors, and alerting on unusual destinations.
For model evaluation sandboxes, default-deny outbound traffic is often appropriate. If a model load or dependency install unexpectedly tries to call an external server, that should be visible.
Rotate credentials after uncertain exposure
If a compromised environment contained long-lived cloud keys, Git tokens, API keys, SSH keys, database credentials, or service account tokens, assume they may be exposed until evidence says otherwise. Rotate them. Review downstream usage. Disable stale keys. Prefer short-lived, workload-bound credentials over static secrets.
Use continuous validation, not one-time cleanup
After a breach or high-profile claim, organizations often run a burst of cleanup work. That is necessary but insufficient. AI and research environments change constantly. New notebooks appear. New models are tested. New packages are installed. New collaborators are added. New buckets are created.
Continuous validation should check:
- Whether sensitive buckets are publicly exposed or broadly shared.
- Whether model registries have unusual download patterns.
- Whether vulnerable AI dependencies exist in notebooks, containers, and CI runners.
- Whether external model loads are pinned and allowlisted.
- Whether secrets appear in notebooks, repositories, or artifacts.
- Whether AI runtimes can reach the internet unnecessarily.
- Whether privileged service accounts are over-scoped.
- Whether clinical and model data are separated by project and purpose.
Authorized automated security testing can help when it produces evidence rather than noise. Penligent, for example, is positioned as an AI-powered penetration testing platform for authorized testing, and workflows of this kind are most useful when they help teams map attack surfaces, validate exposures, capture reproducible evidence, retest fixes, and turn findings into defensible reports without replacing human approval. (Penligente) In AI-heavy environments, that evidence trail matters because a vague finding such as “model storage may be exposed” is much less useful than a scoped proof showing which asset, which identity, which permission, which path, and which remediation closed the gap.
A 30-day response plan after a pharma AI breach claim
The right response depends on the facts, but a time-based structure helps teams avoid paralysis.
Primeiras 24 horas
- Confirm the source of the claim and preserve all related evidence.
- Freeze deletion policies for relevant logs, object storage access records, endpoint data, notebook environments, and cloud audit logs.
- Identify affected systems from the official incident scope and any attacker-provided samples.
- Disable or restrict suspicious accounts, sessions, tokens, and service accounts.
- Temporarily isolate affected research systems if containment requires it.
- Start a privileged access review for clinical data, research storage, model registries, and notebooks.
- Establish a single evidence register shared by security, legal, privacy, clinical operations, and AI platform owners.
- Avoid public technical claims that are not yet supported.
First 72 hours
- Build the exposure map for clinical data, model artifacts, code repositories, object stores, notebooks, HPC systems, and CI runners.
- Review identity logs, object storage access, model registry downloads, Git archive events, CI secret usage, and egress logs.
- Determine whether personal data breach notification obligations are triggered in relevant jurisdictions.
- Identify whether pseudonymized data, linkage keys, or directly identifiable data were exposed.
- Collect and preserve affected model artifacts, config files, notebook snapshots, container digests, and package inventories.
- Rotate credentials present in affected environments.
- Establish a patient, investigator, employee, vendor, and regulator communications plan based on confirmed facts.
First 7 days
- Complete high-confidence scoping of affected data categories.
- Review attacker samples for authenticity without downloading or executing unsafe content in normal environments.
- Determine whether AI model weights, training data, source code, or evaluation datasets were accessed.
- Rebuild compromised or suspect research runtimes from clean images.
- Patch vulnerable AI and MLOps dependencies across notebooks, containers, CI systems, and training platforms.
- Enforce temporary allowlists for external model downloads and artifact access.
- Review third-party access paths and suspend unnecessary collaboration links.
- Update detection rules for bulk artifact downloads, suspicious archive creation, unusual model loads, and abnormal cloud egress.
First 30 days
- Build or update the AI asset inventory and model lineage register.
- Implement model artifact signing, hashing, revision pinning, and central intake controls.
- Separate high-sensitivity clinical data from experimental model environments.
- Reduce standing privileges for notebooks, service accounts, CI runners, and training jobs.
- Deploy ongoing monitoring for model registry access, object storage downloads, notebook activity, and HPC scheduler anomalies.
- Run authorized validation exercises against research and AI infrastructure.
- Update breach playbooks to include AI assets, not only personal data and production systems.
- Conduct a post-incident review focused on evidence gaps, not blame.
The most common mistakes
Treating pseudonymized data as harmless
Pseudonymization is a risk reduction measure, not a magic eraser. It reduces direct identification risk when linkage data remains protected, but clinical context can still be sensitive. A breach response must evaluate data elements, uniqueness, trial context, geography, and possible combination with external data.
Ignoring research systems because production is up
Novo Nordisk said its core business operations remained up and running. (Novo Nordisk) That is good news for continuity, but continuity does not settle research data exposure. An organization can keep production running while still investigating serious compromise of internal research systems.
Checking source code but not artifacts
Source code review is necessary, but attackers may care more about artifacts: model checkpoints, datasets, experiment logs, container images, notebooks, and exported files. Artifact access logs deserve the same attention as Git logs.
Deleting caches before evidence collection
Model caches, notebook directories, temporary folders, and artifact stores can reveal what was loaded, when, and from where. Deleting them may remove useful evidence. Preserve first, clean later.
Assuming AI security means only prompt injection
Prompt injection is important, especially for agentic systems and LLM applications. But pharma AI security also includes model theft, training data exposure, MLOps vulnerabilities, unsafe deserialization, model registry abuse, dependency compromise, data poisoning, and overprivileged research runtimes.
Relying on security flags without version validation
A safe setting is only as good as the library version enforcing it. CVE-2026-4372 is a useful reminder: if teams rely on trust_remote_code=False, they still need patched Transformers versions, source controls, sandboxing, and logs. (Pluto Security)
Building detections with no business context
A large model download may be normal for a training job. A small download may be suspicious if it includes a linkage key or secret file. Detection logic needs asset sensitivity, project context, identity baseline, and expected workflows.
PERGUNTAS FREQUENTES
What did Novo Nordisk confirm about the data breach?
- Novo Nordisk confirmed unauthorized access to a limited number of internal IT systems.
- The company said certain non-public data, including personal data, was copied externally without authorization.
- It said a limited amount of information related to patients in some clinical trials was affected.
- It described the patient-related data as not directly linked to names or other direct identifiers.
- It said core business operations were not impacted and remained up and running. (Novo Nordisk)
Was Novo Nordisk AI model data actually stolen?
- That has not been publicly confirmed by Novo Nordisk in the reviewed official update.
- Reuters reported that FulcrumSec claimed the stolen data included internal AI model information.
- Reuters also said it could not immediately verify the authenticity of the data posted by the hacking group.
- The careful wording is: attackers claimed AI model information was stolen, but the claim remains unverified in the public sources reviewed here. (Reuters)
Why is pseudonymized clinical trial data still sensitive?
- Pseudonymized data may not directly identify a patient, but it can still describe real health, trial, biomarker, demographic, or immunogenicity information.
- Re-identification risk depends on data uniqueness, trial context, population size, external datasets, and whether linkage keys were exposed.
- Even when direct patient risk is reduced, the data may still carry research, regulatory, commercial, and trust impact.
- Defenders should classify pseudonymized clinical trial data as sensitive unless a formal privacy assessment proves otherwise.
What makes AI model theft different from a normal source code leak?
- A model artifact may encode expensive research work, training decisions, feature engineering, and learned behavior from proprietary data.
- The surrounding context can be more valuable than the model file alone: training scripts, configs, datasets, evaluation logs, dependency versions, and runtime images.
- Stolen model assets can expose trade secrets, reproduce research pipelines, reveal strategic direction, or support model tampering.
- AI model theft also overlaps with supply-chain risk because model repositories and loaders can execute code or influence runtime behavior.
Which CVEs matter for AI model and MLOps security?
- CVE-2026-4372 matters because it shows that model configuration and loading can become a remote code execution boundary in Hugging Face Transformers.
- CVE-2024-0520 matters because it shows that MLflow dataset handling could lead to RCE and access to data or model information in affected versions.
- CVE-2026-25874 matters because it shows unsafe deserialization over unauthenticated AI pipeline channels can lead to remote code execution.
- PyTorch model-loading issues such as CVE-2025-32434 matter because they reinforce that safety flags and serialization choices must be validated against patched library behavior.
- The common mitigation pattern is patching, artifact source control, sandboxed loading, least privilege, strong logging, and model supply-chain governance.
How should security teams check for exposed model artifacts?
- Inventory model registries, object buckets, notebook caches, HPC storage, CI artifacts, container registries, and local research directories.
- Review access logs for bulk downloads, unusual users, new service accounts, unfamiliar IP addresses, and large transfers.
- Search code for model loading calls such as
from_pretrained(),torch.load(),pickle.load(),mlflow.pyfunc.load_model(), and unpinned external model references. - Inspect model configuration files statically before loading models.
- Preserve evidence before clearing caches or rebuilding environments.
- Prioritize environments that had access to clinical data, cloud credentials, Git tokens, or internal networks.
What should pharma companies prioritize after a breach claim?
- Separate confirmed facts from attacker claims.
- Preserve logs and affected environments before cleanup.
- Map exposed data by sensitivity, owner, system, and access path.
- Rotate credentials available to affected systems.
- Review clinical data exposure, including pseudonymized datasets and linkage keys.
- Investigate research and AI assets, including models, notebooks, training data, and artifact stores.
- Coordinate legal, privacy, clinical operations, security, AI platform, vendor, and communications teams.
- Build a longer-term control plan for model lineage, AI SBOMs, artifact signing, and continuous validation.
Can automated pentesting help with AI infrastructure validation?
- Yes, when it is authorized, scoped, evidence-driven, and paired with human review.
- It can help find exposed services, weak access controls, vulnerable dependencies, risky API paths, and repeatable misconfigurations.
- It should not be used to run unsafe tests against production research systems without approval.
- The most useful output is not a generic severity score; it is reproducible evidence showing the affected asset, path, permission, impact, and fix.
- For AI and MLOps environments, automated validation should include notebooks, model registries, artifact stores, cloud permissions, dependency versions, and data access boundaries.
The lasting lesson
The Novo Nordisk data breach should be read with discipline. The company confirmed a limited internal IT incident involving externally copied non-public data and some clinical trial patient-related information. Attackers claimed a broader theft involving more than a terabyte of data and internal AI model information, but those broader claims have not been fully verified in the reviewed public sources. Both statements can be true at the same time: the confirmed facts are serious, and the unverified claims still point to a real defensive problem.
For pharma and biotech teams, the security boundary has moved. Patient data, clinical research, drug-development IP, source code, AI models, model registries, notebooks, training data, and cloud credentials now live inside connected research workflows. Defending only the production application or the corporate endpoint fleet is not enough.
The practical path is clear: know where the sensitive assets are, reduce standing access, separate clinical data from experimental runtimes, control model intake, patch AI and MLOps dependencies, log artifact access, preserve evidence, and validate continuously. The next pharma breach may not look exactly like this one. But it will almost certainly test the same weak points: identity, data movement, model supply chain, research infrastructure, and the gap between what an organization thinks is sensitive and what attackers already know is valuable.