CVE-2026-43503 is a Linux kernel local privilege escalation vulnerability in socket-buffer fragment handling. Public research calls the exploit variant DirtyClone. The short version is precise: this is not a standalone unauthenticated remote exploit, but it can turn low-privileged local code execution into root on affected Linux systems when the right kernel paths, namespace policy, and network capabilities line up. The NVD record describes the issue as a failure to propagate the SKBFL_SHARED_FRAG bit when Linux moves skb fragments through helpers such as __pskb_copy_fclone() e skb_shift(), leaving later code with the wrong answer to a critical question: is this packet data private, or is it backed by shared memory that must not be modified in place? (NVD)
JFrog Security Research’s DirtyClone write-up frames the bug as part of the DirtyFrag family, a set of Linux networking and page-cache corruption issues where file-backed memory can be treated as packet data and then modified by an in-place transformation path. JFrog rates the issue as a high-severity local privilege escalation and says its exploit model can bypass on-disk integrity monitoring because the affected data can live in the kernel page cache rather than as a changed file on disk. (research.jfrog.com)
The word “local” is easy to misread. A single-user laptop that never runs untrusted code has a different risk profile from a Kubernetes worker, CI runner, shared hosting node, sandbox service, GPU notebook box, browser automation host, or AI-agent tool runner that routinely executes code supplied by other users, plugins, pull requests, build scripts, or test workloads. In those environments, local code execution is not an unlikely second step. It is part of the operating model. Once untrusted code lands as a low-privileged user, a kernel local privilege escalation becomes the boundary between a contained compromise and host-level control.
| Campo | Practical meaning |
|---|---|
| CVE | CVE-2026-43503 |
| Common name | DirtyClone, used in JFrog’s public exploit analysis |
| Classe de vulnerabilidade | Linux kernel local privilege escalation through page-cache-backed memory corruption |
| Área afetada | Linux sk_buff fragment handling and fragment-transfer paths |
| Core bug | Shared-frag metadata can be lost when skb fragments are transferred |
| Key marker | SKBFL_SHARED_FRAG, checked by later code before deciding whether in-place processing is safe |
| Initial access | Local code execution as an unprivileged user, compromised service account, container workload, build job, or similar context |
| Common high-risk environments | Kubernetes nodes, CI runners, shared Linux hosts, developer build machines, sandbox services, and multi-tenant execution platforms |
| Primary fix | Install the vendor kernel update that contains the CVE-2026-43503 fix, then boot into the fixed kernel or confirm livepatch coverage |
| Unsafe shortcut | Running a public privilege-escalation PoC on production systems |
NVD shows that kernel.org’s CNA score for CVE-2026-43503 is 8.8 High with a local attack vector, low attack complexity, low privileges required, no user interaction, changed scope, and high confidentiality, integrity, and availability impact. The same NVD page also shows a Red Hat ADP score of 7.0 High with high attack complexity and unchanged scope, while NVD itself had not provided its own CVSS assessment at the time reflected in the page. That difference is important: it tells defenders not to reduce this to one number. Local kernel bugs often receive different severity interpretations depending on whether the scorer assumes user namespaces, namespaced capabilities, reachable IPsec or XFRM paths, container constraints, and distribution-specific backports. (NVD)
Ubuntu’s CVE page lists CVE-2026-43503 with a CVSS 3 score of 8.8 High while assigning Ubuntu priority Medium. Amazon Linux’s security center lists the issue as Important with CVSS v3 base score 7.0. These are not mutually exclusive facts; they are vendor-context assessments. Kernel exposure depends on the running kernel branch, enabled configuration, backported patches, namespace settings, and whether untrusted local workloads can reach the relevant networking primitives. (Ubuntu)
The bug in one sentence
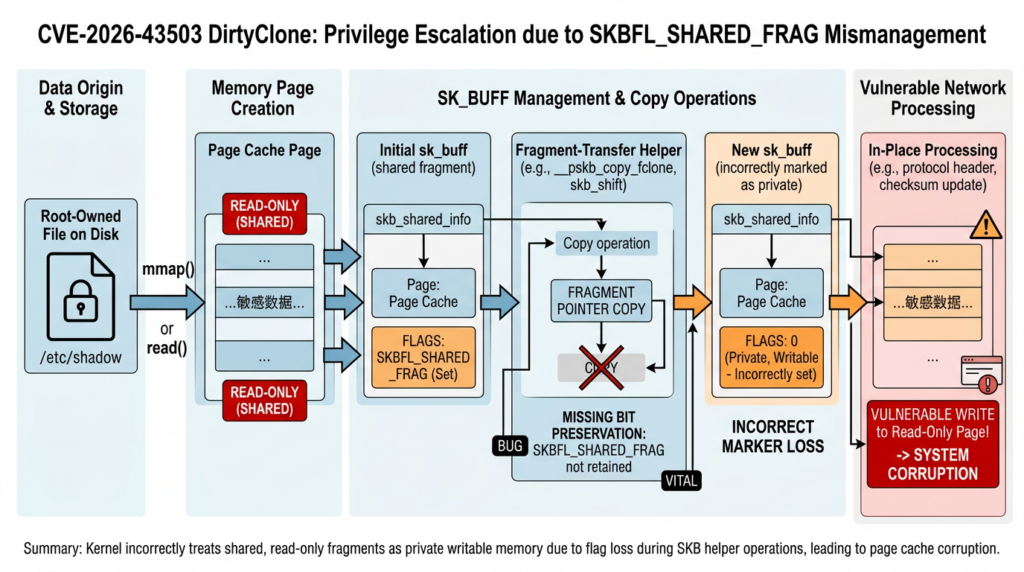
CVE-2026-43503 exists because some Linux networking paths can move references to skb fragments without carrying forward the metadata that says those fragments are shared, externally owned, or page-cache-backed; later code may then believe it is safe to decrypt, transform, or otherwise modify that memory in place.
That sentence is dense because the bug lives at the intersection of three performance-oriented kernel ideas: page cache, zero-copy data movement, and socket buffers. The page cache exists so Linux can keep file contents in memory and avoid repeated disk reads. Socket buffers, usually discussed as skb ou sk_buff, are the kernel’s packet containers. Zero-copy and splice-like paths try to move references to pages instead of copying bytes every time data crosses a subsystem boundary.
Performance-wise, that design is exactly what high-throughput systems want. Security-wise, it creates a strict bookkeeping requirement. If a network packet carries a reference to memory that is still semantically tied to a file page, every later subsystem must remember that the packet’s fragment is not ordinary private packet memory. The SKBFL_SHARED_FRAG marker is one of the ways the kernel preserves that knowledge.
The NVD description says two frag-transfer helpers, __pskb_copy_fclone() e skb_shift(), failed to propagate SKBFL_SHARED_FRAG em skb_shinfo()->flags while moving fragments from a source skb to a destination skb. It further describes related omissions in paths such as segmentation and GRO handling, where flags must be folded or propagated when fragment descriptors move between skb structures. (NVD)
The impact is not merely “a missing flag.” The flag represents memory provenance. If it disappears, later code can ask, “does this skb contain shared fragments?” and get a false answer. If the answer is false, an in-place writer may proceed without forcing a copy. In DirtyClone-style exploitation, that can become a write into a page-cache-backed representation of data that should have been treated as read-only or externally owned.
A simplified data flow looks like this:
That is why DirtyClone belongs in the same mental bucket as Dirty COW and Dirty Pipe even though the exact subsystem is different. Dirty COW, CVE-2016-5195, involved incorrect copy-on-write handling that let local users write to read-only memory mappings and gain privileges. Dirty Pipe, CVE-2022-0847, involved uninitialized pipe-buffer flags that let an unprivileged local user write to page-cache-backed pages of read-only files. CVE-2026-43503 is not the same bug, but it rhymes with the same class of mistake: the kernel temporarily loses track of what memory is allowed to be modified. (NVD)
Why cloned sk_buffs matter
sk_buff is not just a byte array. It is a packet object with metadata, head data, fragment descriptors, lists, protocol state, and references to memory owned elsewhere. Modern networking paths manipulate these objects aggressively. They split, clone, segment, coalesce, shift, linearize, and pass skb structures through protocol layers and netfilter hooks.
DirtyClone focuses on a failure during fragment transfer. If a source skb has shared fragments, a destination skb that receives those fragments must inherit the shared-frag warning. Otherwise the destination object looks safer than it is.
That matters because the kernel often distinguishes between copying data and moving descriptors. A plain copy of bytes into newly allocated private storage does not need the same marker, because the destination owns the bytes. A descriptor move is different. It may transfer a reference to the same underlying page. The NVD and Ubuntu descriptions make this distinction: copy paths that linearize data into fresh storage are different from paths that move frag descriptors and therefore must propagate shared-frag state. (Ubuntu)
The security invariant is simple:
| Operation | Safe assumption | Required marker behavior |
|---|---|---|
| Copy bytes into new private memory | Destination owns its contents | Shared-frag marker may no longer apply |
| Move a frag descriptor pointing at existing backing memory | Destination may still refer to shared or page-cache-backed data | Shared-frag marker must follow the descriptor |
| Coalesce packet fragments by attaching page-backed frags | Destination may inherit shared memory references | Marker must be merged, not dropped |
| Segment or split an skb with fragment lists | New skb objects may carry references from list members | Flags must be folded from all fragment sources |
| Decrypt or transform packet data in place | Buffer must be private and safe to write | If shared-frag marker exists, force a copy first |
The bug is subtle because the unsafe state is not visible as an obvious pointer to /usr/bin/su ou /etc/passwd. It is a chain of references and flags. By the time a later subsystem processes the skb, it may not know where the bytes came from. The whole defense depends on the metadata surviving every transfer.
What public DirtyClone exploitation proves
JFrog states that its researchers developed a privilege-escalation exploit for the CVE-2026-43503 variant they call DirtyClone. Their high-level exploitation model uses page-cache-backed memory as packet data and an in-place transformation path to modify that memory. They also identify CAP_NET_ADMIN as relevant because configuring the needed networking and IPsec environment requires network administration control. (research.jfrog.com)
The Linux capabilities manual defines CAP_NET_ADMIN as the capability used for network-related operations such as interface configuration, firewall and accounting administration, routing table modification, transparent proxy binding, type-of-service settings, clearing driver statistics, and promiscuous mode control. In other words, it is not a harmless capability. It is one of the capabilities most likely to turn a container, namespace, or build job into a meaningful kernel attack surface. (Man7)
User namespaces make this more complicated. The Linux manual page for user namespaces explains that a process can have capabilities inside a user namespace and that unprivileged processes have been able to create user namespaces since Linux 3.8, with other namespace types creatable using CAP_SYS_ADMIN in the caller’s user namespace. This is useful for sandboxing and rootless workflows, but it also means a local user may obtain powerful namespaced capabilities without being host root. (Man7)
Ubuntu’s security engineering blog explains the trade-off bluntly: unprivileged user namespaces can replace some setuid use cases and support sandboxes, but they expose kernel interfaces normally restricted to privileged processes, and they have been used as a step in multiple privilege-escalation exploit chains. Ubuntu also notes that a global sysctl-style disable can break applications, which is why selective restriction is often preferable where available. (Ubuntu)
For defenders, the lesson is not “user namespaces are always bad.” The lesson is that namespace policy is part of exploitability analysis. A Linux host with untrusted local code, permissive user namespace creation, reachable network namespace operations, and broad container capabilities has a much higher exposure profile than a tightly controlled host where local accounts cannot create the relevant namespace and networking setup.
A safe exploitation summary stops here:
local code execution
|
v
obtain or reach a network-administration context
|
v
construct skb fragments backed by file-cache memory
|
v
trigger a fragment-transfer path that loses SKBFL_SHARED_FRAG
|
v
later in-place processing writes to the backing page
|
v
privileged execution path observes modified cached bytes
|
v
root-level impact
That is enough to understand the risk without turning the explanation into a production exploit recipe.
DirtyClone is not remote RCE, but it is still high priority
CVE-2026-43503 does not mean that any internet user can send one packet to a public Linux server and become root. Public sources describe it as a local privilege escalation. The attacker needs local code execution first, or an environment that lets untrusted code run on the host. (SecurityWeek)
That limitation matters, but it should not create complacency. Many real intrusions already include local code execution before the attacker seeks kernel-level control. A vulnerable web application can drop a shell as www-data. A malicious dependency can run during a CI build. A compromised plugin can execute inside an agent runtime. A user-submitted notebook can run on a shared GPU host. A container breakout chain can start inside a low-privileged container. DirtyClone-style bugs become dangerous because they upgrade those footholds.
The riskiest systems are not always the most internet-exposed systems. They are the systems that execute other people’s code.
| Meio ambiente | Why CVE-2026-43503 matters |
|---|---|
| CI runners | Pull requests, build scripts, package installation hooks, and test jobs can run local code |
| Kubernetes workers | Containers share the host kernel, so a host kernel LPE can cross workload boundaries |
| Shared hosting nodes | Multiple customers or applications may execute code on the same kernel |
| Estações de trabalho do desenvolvedor | Project scripts, containers, dev tools, and package managers routinely execute third-party code |
| AI agent runners | Tool-using agents may execute code, clone repositories, run tests, or process untrusted artifacts |
| Browser or document sandboxes | A renderer escape or sandbox escape chain may need a kernel LPE as the next stage |
| Research labs and cyber ranges | Multi-user machines often run intentionally hostile code and should be treated as high-risk |
The same logic applies to cloud build systems. A runner that executes untrusted pull requests should not share a long-lived host kernel with secrets, signing keys, production deployment credentials, or privileged build infrastructure. Even if CVE-2026-43503 is patched, this is still the correct design principle. Kernel LPEs recur.
How CVE-2026-43503 relates to DirtyFrag and Fragnesia
DirtyClone is easier to understand if it is placed beside the recent page-cache and shared-fragment vulnerabilities that preceded it.
SecurityWeek summarized JFrog’s analysis by describing CVE-2026-43503 as a variant of DirtyFrag and Fragnesia, sharing similarities with Dirty Pipe. It notes that these defects affect Linux kernel networking stack behavior around socket buffers referencing shared page-cache memory, and that they can be weaponized through in-place cryptographic transformations in kernel subsystems. (SecurityWeek)
The Hacker News reports the same sequence as a series: Copy Fail, DirtyFrag, Fragnesia, then DirtyClone. Its account says DirtyClone followed prior fixes and found another path where a safety flag could be dropped when packets were cloned or moved. It also reports that the combined fix landed in mainline in late May 2026, while NVD lists several kernel.org patch references rather than a single universal downstream package version. (Notícias do Hacker)
| Issue | Core area | Why it is related | Exploitation condition | Main defensive lesson |
|---|---|---|---|---|
| CVE-2016-5195 Dirty COW | Linux memory management copy-on-write | Read-only mappings could be modified through incorrect COW handling | Local user needed a way to trigger the race | Copy-on-write is a security boundary, not only a performance feature |
| CVE-2022-0847 Dirty Pipe | Linux pipe buffer flags and page cache | Uninitialized pipe-buffer flags allowed writes to page-cache-backed read-only files | Local unprivileged user could manipulate pipe state | Flags that describe buffer mutability must be initialized and preserved |
| CVE-2026-43284 DirtyFrag ESP half | XFRM ESP and shared skb fragments | In-place decrypt could reach shared skb fragments | Local code plus reachable ESP-related path | In-place crypto must copy before writing shared fragments |
| CVE-2026-43500 DirtyFrag RxRPC half | RxRPC and shared fragments | Related page-cache-backed fragment handling risk | Local code plus reachable RxRPC path | Multiple protocol paths can share the same memory-provenance bug class |
| CVE-2026-46300 Fragnesia | skb coalescing and ESP-in-TCP | Shared-frag marker could be lost during coalescing | Local code plus relevant XFRM path | Partial fixes can leave bypass paths if every transfer path is not covered |
| CVE-2026-43503 DirtyClone | skb fragment-transfer helpers and cloned packets | Shared-frag metadata can be lost through helper paths such as __pskb_copy_fclone() e skb_shift() | Local code plus capability and network path conditions | Metadata must follow page references through every skb transformation |
The common thread is not one syscall, one module, or one file. The common thread is memory provenance. When file-backed memory enters a high-performance data path, every subsystem that receives a reference must know whether it is allowed to write. The bug class appears whenever the kernel keeps the reference but loses the warning label.
That is also why defenders should avoid treating DirtyClone as an isolated patch ticket. It is one member of a cluster. A host that patched the first DirtyFrag issue but missed later follow-up fixes may still be vulnerable to a bypass path. JFrog explicitly warns that systems lacking the complete chain of fixes for the DirtyFrag vulnerability family remain at risk, including systems that applied initial mitigations but missed follow-up patches for CVE-2026-46300 and CVE-2026-43503. (research.jfrog.com)
Patch status is distribution-specific
Upstream Linux patch references matter, but production patching should be driven by the distribution kernel you actually run. Enterprise and cloud distributions often backport security fixes without moving to the same upstream version number. A system can be fixed while still reporting an older-looking kernel series, and a system can have a fixed package installed while still running a vulnerable kernel because it was not rebooted.
Ubuntu’s CVE page shows release and kernel-flavor-specific statuses, including fixed versions for some Ubuntu kernel packages and “vulnerable, work in progress” or “needs evaluation” statuses for others at the time reflected in the page. That is exactly why a single version string is not enough. (Ubuntu)
Debian’s security tracker identifies the CVE and repeats the kernel description around __pskb_copy_fclone(), skb_shift()e SKBFL_SHARED_FRAG. Amazon Linux lists the issue publicly with an Important severity and a CVSS v3 base score of 7.0. SUSE’s CVE page also carries the kernel description. Vendor status pages are operational sources of truth because they map upstream fixes to supported kernels, livepatch streams, and package names. (Debian Security Tracker)
The correct patch question is not “does my kernel version look new enough?” It is:
- What kernel package is installed?
- What kernel is currently running?
- Does the distribution advisory say that package contains the CVE-2026-43503 fix?
- Has the host rebooted into that fixed kernel, or is a livepatch applied and verified?
- Are there companion DirtyFrag-family fixes missing from the same host?
- Does the host run untrusted local workloads that should be prioritized even before lower-risk machines?
The fourth question is where many patch programs fail. Kernel patching is not complete when the package manager exits. It is complete when the fixed kernel is the one executing on the host.
Safe production validation
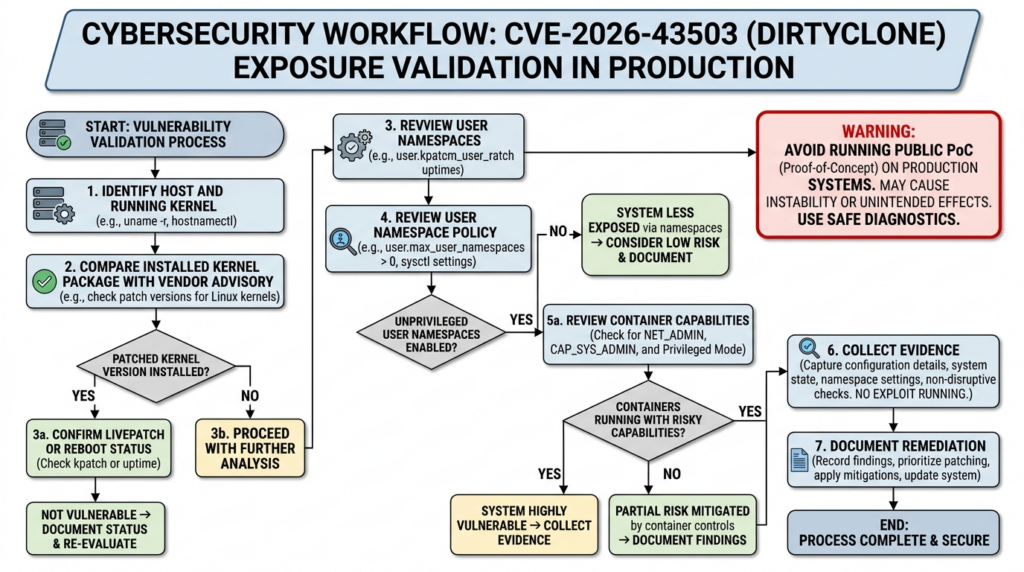
A public PoC can be useful in a lab. It is a bad production validation method. CVE-2026-43503 is a local privilege escalation primitive. A PoC designed to prove root impact may modify runtime state, disturb the page cache, crash a host, trigger security controls, or leave investigators unsure whether observed changes came from the PoC or a real attacker. Penligent’s CVE-2026-43503 verification note makes the same practical distinction: the right production outcome is not a root shell, but evidence that the running kernel is fixed, the relevant exposure is constrained, and the control state is recorded. (Penligente)
A safer process looks like this:
| Etapa | Evidence to collect | Por que é importante |
|---|---|---|
| Identify the host and kernel | Hostname, cloud instance ID, OS release, uname -r, boot time | Prevents package-state confusion |
| Check installed kernel packages | dpkg, apto, rpm, dnf, yum, zypper, vendor security tools | Shows whether a fixed package is present |
| Compare with vendor advisory | Ubuntu, Debian, Red Hat, Amazon Linux, SUSE, Oracle, distro-specific advisories | Backports differ by distribution |
| Confirm running kernel | uname -r, /proc/version, boot loader state, livepatch state | Installed fixes do not matter until active |
| Review namespace policy | kernel.unprivileged_userns_clone, AppArmor userns policy where applicable | Influences whether local users can reach namespaced capabilities |
| Review container privilege | Kubernetes security contexts, Docker flags, NET_ADMIN, privileged mode, host networking | Determines workload-to-kernel attack surface |
| Review relevant telemetry | Audit logs, process execution, namespace creation, XFRM changes, module loads | Helps detect exploit attempts or risky conditions |
| Preserve result | Ticket, report, evidence bundle, exact command output, timestamp | Enables retest and compliance review |
The following shell snippet is intentionally defensive. It does not attempt to exploit anything. It gathers the evidence most teams need before checking distribution-specific advisories.
#!/usr/bin/env bash
set -euo pipefail
echo "== Host identity =="
hostnamectl 2>/dev/null || hostname
date -u +"UTC time: %Y-%m-%dT%H:%M:%SZ"
echo
echo "== OS release =="
cat /etc/os-release 2>/dev/null || true
echo
echo "== Running kernel =="
uname -a
printf "Boot time: "
who -b 2>/dev/null || true
echo
echo "== Kernel packages, Debian or Ubuntu =="
if command -v dpkg >/dev/null 2>&1; then
dpkg -l 'linux-image*' 'linux-modules*' 2>/dev/null \
| awk '/^ii/ {print $2, $3}' \
| sort || true
echo
echo "Recent apt/dpkg changelog references:"
grep -RhiE 'CVE-2026-43503|SKBFL_SHARED_FRAG|skbuff|shared-frag|dirty.?frag' \
/usr/share/doc/linux-image*/changelog* 2>/dev/null \
| head -40 || true
fi
echo
echo "== Kernel packages, RPM-based systems =="
if command -v rpm >/dev/null 2>&1; then
rpm -qa | grep -E '^kernel|^kernel-core' | sort || true
echo
echo "Kernel changelog references:"
rpm -q --changelog kernel-core 2>/dev/null \
| grep -Ei 'CVE-2026-43503|SKBFL_SHARED_FRAG|skbuff|shared-frag|dirty.?frag' \
| head -40 || true
rpm -q --changelog kernel 2>/dev/null \
| grep -Ei 'CVE-2026-43503|SKBFL_SHARED_FRAG|skbuff|shared-frag|dirty.?frag' \
| head -40 || true
fi
echo
echo "== Namespace-related sysctls =="
for key in \
kernel.unprivileged_userns_clone \
user.max_user_namespaces \
kernel.apparmor_restrict_unprivileged_userns
do
sysctl "$key" 2>/dev/null || true
done
echo
echo "== Loaded modules with possible relevance =="
lsmod 2>/dev/null | grep -E '(^esp4|^esp6|^xfrm|^rxrpc|^af_key)' || true
echo
echo "== Reminder =="
echo "Compare this output against your distribution's CVE-2026-43503 advisory."
echo "A fixed package is not enough if the vulnerable kernel is still running."
This script should be run as a collection aid, not as a verdict engine. It cannot know whether a vendor backport contains a fix unless it is paired with the vendor’s advisory data. It cannot prove exploitability. It can reduce the usual confusion between installed package, booted kernel, and namespace policy.
For Kubernetes, check worker nodes, not only container images:
kubectl get nodes -o wide
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.nodeInfo.osImage}{"\t"}{.status.nodeInfo.kernelVersion}{"\n"}{end}'
That command answers a question container scanners often miss: what host kernel are the workloads actually sharing?
Kubernetes and container exposure
Containers do not bring their own Linux kernel. They share the host kernel. That is the first operational fact for CVE-2026-43503 triage. Rebuilding an application image with patched userland packages does not fix a vulnerable worker-node kernel. Moving a vulnerable workload to a different vulnerable node does not fix the host boundary. Patching the control plane but leaving the node pool unpatched does not close the local privilege-escalation path.
Kubernetes documentation defines a security context as the place where privilege and access control settings are configured for pods and containers, including running as privileged or unprivileged, Linux capabilities, AppArmor, seccomp, and allowPrivilegeEscalation. Kubernetes also notes that allowPrivilegeEscalation is always true when a container is privileged or has CAP_SYS_ADMIN. (Kubernetes)
For DirtyClone-style bugs, defenders should review at least these container properties:
| Property | Por que é importante |
|---|---|
privileged: true | Gives broad device and kernel-facing access and often bypasses normal containment assumptions |
NET_ADMIN | May provide access to network-administration operations relevant to XFRM, interfaces, routing, or netfilter setup |
SYS_ADMIN | Broad capability that often enables namespace, mount, and other privileged operations |
| Host network | Reduces isolation between workload networking and node networking |
| Host PID or IPC | Expands visibility and interaction with host-level process or IPC namespaces |
| Writable hostPath mounts | Can combine with other bugs for persistence or host tampering |
| Long-lived shared runners | Increase blast radius when untrusted jobs share a kernel with sensitive workloads |
| Missing seccomp or AppArmor policy | Reduces syscall and profile-based barriers |
A restrictive pod baseline is not a kernel patch, but it reduces the number of workloads that can reach dangerous paths while patching proceeds.
apiVersion: v1
kind: Pod
metadata:
name: restricted-workload-example
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
containers:
- name: app
image: example/app:stable
securityContext:
allowPrivilegeEscalation: false
privileged: false
readOnlyRootFilesystem: true
capabilities:
drop:
- ALL
volumeMounts:
- name: tmp
mountPath: /tmp
volumes:
- name: tmp
emptyDir: {}
This example is not tailored to every application. Some workloads need specific capabilities or writable paths. The value is in the default posture: drop what is not required, justify exceptions, and separate trusted infrastructure workloads from untrusted execution.
CI runners deserve special treatment. A runner that executes arbitrary pull requests should be assumed to run hostile local code. That means node rotation, ephemeral runners, strict secret isolation, no privileged mode for untrusted jobs, separate runner pools for trusted and untrusted repositories, and fast kernel patch rollout are not “nice to have” controls. They are the basic containment model.
Detection is hard because disk may stay clean
DirtyClone-style impact is uncomfortable for defenders because the most intuitive check can be misleading. If the attack modifies page-cache-backed memory without changing the file on disk, package verification and file-integrity monitoring may report clean files after the runtime state has already been abused. JFrog’s write-up says the attack can be silent, leave no kernel logs or audit traces, and bypass common on-disk integrity monitoring tools. (research.jfrog.com)
That does not mean detection is impossible. It means defenders should look for behavior around the exploit setup and post-exploitation impact, not only file hashes.
Useful detection areas include:
| Signal area | What to watch | Por que é importante |
|---|---|---|
| Namespace creation | unshare, clone, user namespace creation spikes, unexpected rootless namespace workflows | DirtyClone exploitability can depend on namespaced capabilities |
| Network administration | ip xfrm, netfilter changes, unusual loopback network setup, unexpected CAP_NET_ADMIN use | XFRM or IPsec configuration is relevant to public exploitation models |
| Kernel modules | ESP, XFRM, RxRPC, AF_KEY, or related module loads on hosts that do not normally use them | Sudden module activity may indicate path preparation |
| Privileged binary execution | Unusual su, sudo, pkexec, or setuid binary invocation after namespace activity | Page-cache overwrite impact may be realized when privileged paths execute |
| Container anomalies | Privileged pods, NET_ADMIN, host networking, new hostPath mounts | These increase local-to-host attack surface |
| Post-root behavior | New root shells, credential access, persistence attempts, lateral movement | Successful LPE is often followed by real objectives |
Audit rules can help, but they should be deployed carefully and tuned to the environment. On a production fleet, noisy rules around every namespace or networking command may overwhelm analysts. A better approach is to combine high-risk hosts, high-risk commands, and unexpected principals.
A simple starting point for Linux audit environments might track execution of common namespace and network administration tools:
# Example auditctl rules for investigation-focused monitoring.
# Test in a staging environment before broad rollout.
auditctl -a always,exit -F arch=b64 -S unshare -k namespace-change
auditctl -a always,exit -F arch=b64 -S clone -F a0&0x10000000 -k userns-clone
auditctl -w /usr/sbin/ip -p x -k network-admin-tool
auditctl -w /sbin/ip -p x -k network-admin-tool
auditctl -w /usr/sbin/iptables -p x -k netfilter-tool
auditctl -w /usr/sbin/nft -p x -k netfilter-tool
auditctl -w /usr/bin/su -p x -k privileged-binary-exec
auditctl -w /usr/bin/sudo -p x -k privileged-binary-exec
A few cautions are necessary. Path-based rules can miss alternate tool locations, static binaries, direct syscalls, or renamed utilities. clone argument filtering can vary across architectures and audit implementations. Containers may produce high volumes of namespace activity. Use these rules as investigation scaffolding, not as a complete DirtyClone detector.
For systemd-based hosts, a quick triage query after a suspicious event might look like this:
journalctl --since "24 hours ago" \
| grep -Ei 'unshare|xfrm|ipsec|iptables|nft|rxrpc|esp4|esp6|cap_net_admin|permission denied|segfault|audit'
For Kubernetes, search for risky pod settings:
kubectl get pods -A -o json \
| jq -r '
.items[]
| . as $pod
| [$pod.metadata.namespace, $pod.metadata.name,
([.spec.containers[]?.securityContext.privileged] | any),
([.spec.containers[]?.securityContext.capabilities.add[]?] | join(",")),
(.spec.hostNetwork // false),
(.spec.hostPID // false)]
| @tsv'
The goal is not to prove exploitation from one log line. The goal is to identify hosts where a vulnerable kernel and high-risk local execution conditions overlap.
Mitigation and hardening
The primary fix for CVE-2026-43503 is a vendor kernel update that includes the relevant upstream fix or backport. After installation, the host must run the fixed kernel. For most systems, that means rebooting. For livepatched systems, it means verifying that the livepatch actually covers the CVE and is active for the running kernel.
Everything else is a compensating control.
| Controle | Valor | Limitação |
|---|---|---|
| Apply fixed kernel and reboot | Removes the vulnerable code path from the running kernel | Requires maintenance window or node replacement |
| Verify livepatch | May avoid reboot for supported streams | Coverage is vendor- and kernel-specific |
| Restrict unprivileged user namespaces | Reduces access to namespaced capabilities | May break rootless containers, browsers, sandboxes, and developer tools |
Remove NET_ADMIN from containers | Reduces access to relevant network administration paths | Some networking workloads legitimately need it |
| Avoid privileged containers | Keeps workloads away from broad kernel-facing privileges | Legacy build systems may depend on privileged mode |
| Drain and replace Kubernetes nodes | Ensures workloads land on patched kernels | Requires cluster capacity and rollout planning |
| Disable unused protocol modules | Reduces reachable attack surface | Can break IPsec, VPN, RxRPC, or other legitimate functionality |
| Segregate untrusted execution | Limits blast radius from local-code workloads | Requires architecture and scheduling changes |
JFrog lists workarounds such as blocking CAP_NET_ADMIN acquisition through user namespace restrictions and blacklisting ESP and RxRPC-related modules when immediate patching is not possible. Treat that as emergency risk reduction, not a final fix. Network modules may be required for legitimate IPsec or workload functions, and namespace restrictions can break real applications. (research.jfrog.com)
A practical Linux hardening pass can start with read-only checks:
echo "== User namespace policy =="
sysctl kernel.unprivileged_userns_clone 2>/dev/null || true
sysctl user.max_user_namespaces 2>/dev/null || true
sysctl kernel.apparmor_restrict_unprivileged_userns 2>/dev/null || true
echo "== Capability-bearing files, sample paths =="
getcap -r /usr/bin /usr/sbin /bin /sbin 2>/dev/null \
| grep -Ei 'cap_net_admin|cap_sys_admin|cap_sys_module|cap_dac_override' || true
echo "== Containers with broad privilege, Docker local host =="
docker ps --format '{{.ID}} {{.Names}}' 2>/dev/null \
| while read -r id name; do
docker inspect "$id" \
--format "$name privileged={{.HostConfig.Privileged}} capadd={{.HostConfig.CapAdd}} network={{.HostConfig.NetworkMode}}" \
2>/dev/null || true
done
Be careful with fleetwide changes. Disabling unprivileged user namespaces on developer machines may break rootless Docker or browser sandboxes. Removing NET_ADMIN may break service meshes, VPN containers, packet capture tools, CNI components, or network appliances. Module blacklists may break IPsec tunnels. Good mitigation is staged: identify who needs the feature, constrain it there, remove it everywhere else, and patch the kernel.
For Kubernetes, the operational sequence is usually:
- Identify affected node pools by kernel version and advisory status.
- Create patched replacement nodes or update existing nodes using the provider’s recommended process.
- Cordon and drain vulnerable nodes.
- Verify the replacement node’s running kernel.
- Re-schedule workloads only after the node is known fixed.
- Apply admission controls to block new privileged workloads unless explicitly approved.
- Retain evidence for every node pool.
For CI infrastructure, the sequence is similar but with more emphasis on workload trust:
- Split trusted and untrusted jobs into separate runner pools.
- Patch or replace runners that execute untrusted code first.
- Remove long-lived secrets from untrusted runner environments.
- Avoid privileged Docker-in-Docker for public pull requests.
- Rotate runners frequently, ideally per job or per small batch of jobs.
- Record kernel state in job logs for high-risk build nodes.
The most common operational mistake is patching the wrong layer. Container image patching is still important, but a container image has no private kernel. CVE-2026-43503 is a host-kernel issue.
Why file-integrity tools can give false comfort
File-integrity monitoring tools are valuable. They are not a complete answer for page-cache corruption. If an exploit modifies a cached memory page and then uses that modified runtime state before it is written back to disk, a disk hash can remain clean. A reboot may clear the modified cached page while leaving no changed file for a traditional integrity scan to find.
DirtyClone should push defenders to separate three questions:
| Pergunta | Por que é importante |
|---|---|
| Did the file on disk change? | Package verification and file-integrity tools answer this well |
| Did a cached representation of file-backed memory change at runtime? | Disk hashes may not answer this |
| Did an attacker gain root and perform follow-on actions? | Incident response must focus on process history, credentials, persistence, and lateral movement |
If exploitation is suspected, do not treat “package verification passed” as proof that the host was safe. Investigate as a possible root compromise. Preserve logs, collect volatile evidence if possible, isolate the node, rotate credentials that were accessible from the host, and rebuild from known-good images if confidence is low.
A fast triage checklist:
1. Is the running kernel known vulnerable according to the distribution advisory?
2. Was untrusted local code running on the host?
3. Could that code reach user namespaces, network namespaces, CAP_NET_ADMIN, privileged container mode, or relevant modules?
4. Are there unusual namespace, xfrm, netfilter, or privileged binary execution events?
5. Did any low-privileged account suddenly spawn root-owned processes?
6. Were credentials, CI tokens, cloud instance roles, SSH keys, or signing keys available?
7. Can the host be rebuilt faster than it can be trusted?
For many production environments, the safest post-suspicion action is node replacement. Kernel LPEs damage trust in the host boundary. Even if the page-cache effect disappears after reboot, a successful attacker may have already changed credentials, installed persistence, accessed secrets, or moved laterally.
A defensible verification workflow
Security teams often struggle with Linux kernel CVEs because the evidence is scattered. Scanner output says one thing. uname -r says another. The package manager shows a fixed package installed. The node has not rebooted. A cloud advisory maps the fix to a backported kernel build that does not resemble upstream version numbers. A container scanner flags application images but does not know the node kernel. A public PoC exists, and someone wants to “just run it.”
A defensible workflow should produce an answer that another engineer can audit.
| Output | Good evidence |
|---|---|
| Exposure decision | Distribution advisory, running kernel, package version, workload trust level |
| Patch decision | Fixed package installed, reboot or livepatch verified, node replacement record |
| Compensating controls | Namespace policy, container capabilities, privileged workload exceptions |
| Detection state | Audit coverage, EDR coverage, Kubernetes admission controls, SIEM queries |
| Residual risk | Hosts still pending reboot, workloads requiring NET_ADMIN, unsupported kernels |
| Retest result | Timestamped command output and advisory comparison |
This is where AI-assisted security workflows can be useful if they stay evidence-driven. A team can use an agentic workflow to collect host facts, correlate them with advisories, separate running-kernel state from installed-package state, generate retest tasks, and preserve a report trail instead of manually copying shell output into tickets. Penligent’s main platform is positioned around AI-assisted pentesting and security validation workflows, while its CVE-2026-43503 note focuses on safe exposure verification rather than running a production root exploit. Used in this narrow way, the value is not “AI finds magic bugs”; it is turning patch verification, attack-surface review, and evidence capture into a repeatable process. (Penligente)
That process should still be conservative. A tool can organize evidence, but it cannot change the rule that the vendor kernel advisory is the source of truth for supported builds. It also cannot make an exploit PoC safe to run on a production node.
Common mistakes to avoid
| Mistake | Better approach |
|---|---|
| Treating “local” as low priority everywhere | Ask whether the host routinely runs untrusted code |
Checking only uname -r | Compare running kernel, installed package, boot state, and vendor advisory |
| Installing a fixed kernel but not rebooting | Confirm the fixed kernel is running or livepatch is active |
| Updating container images only | Patch or replace the host kernel used by container workers |
| Running a public PoC on production | Use non-destructive validation and lab reproduction |
| Assuming clean file hashes prove safety | Page-cache corruption may not persist as disk changes |
| Disabling user namespaces fleetwide without testing | Apply selective restrictions where possible and understand application impact |
Leaving NET_ADMIN in default container profiles | Grant capabilities only where explicitly required |
| Forgetting companion DirtyFrag-family fixes | Check the whole patch chain, not only one CVE |
| Mixing trusted and untrusted CI jobs on the same long-lived host | Separate runner pools and rotate untrusted runners frequently |
The biggest strategic mistake is thinking of kernel LPEs as rare edge cases. They are recurring failure modes in complex kernel subsystems. DirtyClone is interesting because a small metadata error crosses a major trust boundary. That pattern will appear again in other forms.
Practical remediation plan for different teams
A small engineering team with a few Linux servers can handle CVE-2026-43503 with a straightforward process: check distribution advisories, apply kernel updates, reboot, and confirm the running kernel. If those servers do not run untrusted local code, the emergency level may be lower, but the patch should still be scheduled promptly.
A SaaS team running Kubernetes should prioritize worker nodes that host multi-tenant workloads, CI jobs, customer code, browser automation, plugin execution, notebooks, or sandboxes. The safest pattern is usually rolling node replacement. Create fixed nodes, drain vulnerable nodes, reschedule workloads, and delete the old nodes. Then enforce pod security policies or admission controls so new workloads cannot casually request privileged mode or NET_ADMIN.
A security lab, cyber range, or exploit development environment should assume public PoCs will be attempted. These systems need isolation from production networks, no shared credentials, fast snapshot restore, and clear rules about where exploit reproduction is allowed. Lab reproduction is legitimate. Production reproduction is reckless.
A developer-platform team should review rootless container dependencies before disabling unprivileged user namespaces. Some developer workflows may break. That does not mean accepting the risk everywhere. It means applying policy by role: untrusted CI gets stricter isolation, developer laptops may get controlled exceptions, and production hosts should not expose user namespace creation unless there is a clear reason.
A regulated enterprise should preserve evidence. The difference between “we installed patches” and “we can prove every affected kernel was no longer running by a specific time” matters during incident review. Capture advisory IDs, package versions, node replacement records, reboot timestamps, and exceptions.
PERGUNTAS FREQUENTES
Is CVE-2026-43503 remotely exploitable by itself?
- Public sources describe CVE-2026-43503 as a Linux kernel local privilege escalation, not a standalone unauthenticated remote exploit.
- An attacker needs local code execution or a workload-execution context first.
- The risk is still serious on systems where local code execution is normal, including CI runners, Kubernetes nodes, shared hosts, sandbox services, and developer machines.
- A prior remote code execution bug in an application can make CVE-2026-43503 much more dangerous by providing the local foothold needed for kernel escalation.
What is DirtyClone?
- DirtyClone is the public name JFrog uses for its CVE-2026-43503 exploit analysis.
- It belongs to the DirtyFrag-related class of Linux kernel bugs involving socket buffers, shared fragments, page-cache-backed memory, and in-place processing.
- The core issue is not the name. The core issue is that Linux can lose the
SKBFL_SHARED_FRAGmarker while transferring skb fragments, causing later code to treat shared memory as safe to write. - The practical outcome can be local root privilege escalation on affected systems under the right conditions.
How is DirtyClone different from Dirty Pipe?
- Dirty Pipe, CVE-2022-0847, involved pipe-buffer flag initialization and allowed writes to page-cache-backed read-only files.
- DirtyClone, CVE-2026-43503, involves Linux networking socket-buffer fragment handling and shared-frag marker propagation.
- Both are local privilege-escalation issues connected to page-cache-backed memory, but they live in different kernel subsystems.
- The shared lesson is that metadata about memory mutability must be correct every time a kernel subsystem moves or reuses a page reference.
Are Docker and Kubernetes environments affected?
- They can be affected because containers share the host kernel.
- Rebuilding a container image does not patch the worker-node kernel.
- Risk is higher when workloads run with privileged mode,
NET_ADMIN,SYS_ADMIN, host networking, host PID, broad hostPath mounts, or permissive namespace policy. - Kubernetes teams should patch or replace worker nodes, verify the running kernel, and restrict high-risk security contexts.
How do I safely check whether a system is exposed?
- Check the running kernel with
uname -re/proc/version. - Check installed kernel packages with the host’s package manager.
- Compare package status against the distribution’s CVE-2026-43503 advisory.
- Confirm that the fixed kernel is actually running after reboot, or verify livepatch coverage.
- Review unprivileged user namespace policy,
CAP_NET_ADMIN, privileged containers, and relevant kernel modules. - Do not run a public DirtyClone PoC on production systems.
Is disabling unprivileged user namespaces enough?
- It can reduce exposure on some systems because unprivileged user namespaces can help local users reach namespaced capabilities.
- It is not a substitute for a fixed kernel.
- It can break rootless containers, browser sandboxes, developer tooling, and some application sandboxes.
- Selective restriction is usually safer than an untested fleetwide disable.
- Treat namespace restriction as a compensating control while patching and rebooting proceed.
Why can file-integrity monitoring miss DirtyClone-style impact?
- The bug class can modify page-cache-backed memory without changing the file on disk.
- A disk hash may remain clean while a cached runtime representation was modified earlier.
- A reboot may clear the corrupted cached page, but that does not prove the host was never compromised.
- If exploitation is suspected, investigate process activity, credential access, persistence, and lateral movement rather than relying only on package verification.
Should defenders run a public PoC to prove impact?
- Not on production systems.
- A PoC designed to prove root impact may alter runtime state, crash a host, trigger controls, or create confusing forensic artifacts.
- Use lab reproduction on disposable systems if exploit validation is needed.
- Production validation should focus on kernel patch state, running-kernel evidence, namespace and capability exposure, and detection coverage.
Final judgment
CVE-2026-43503 is dangerous because it turns a small metadata failure into a host-boundary problem. The kernel keeps a reference to memory whose origin still matters, but a fragment-transfer path can drop the marker that tells later code not to write in place. That is the kind of mistake that makes page-cache bugs so serious: the disk can look clean, the vulnerable operation can be local, and the result can still be root.
The practical response is not complicated, but it must be exact. Patch the kernel from the distribution’s advisory, make sure the fixed kernel is running, prioritize hosts that execute untrusted local code, reduce namespace and capability exposure, and keep evidence that the host boundary was actually restored. CVE-2026-43503 should be handled as a kernel patching task, a local-code execution risk review, and a validation-evidence problem at the same time.

