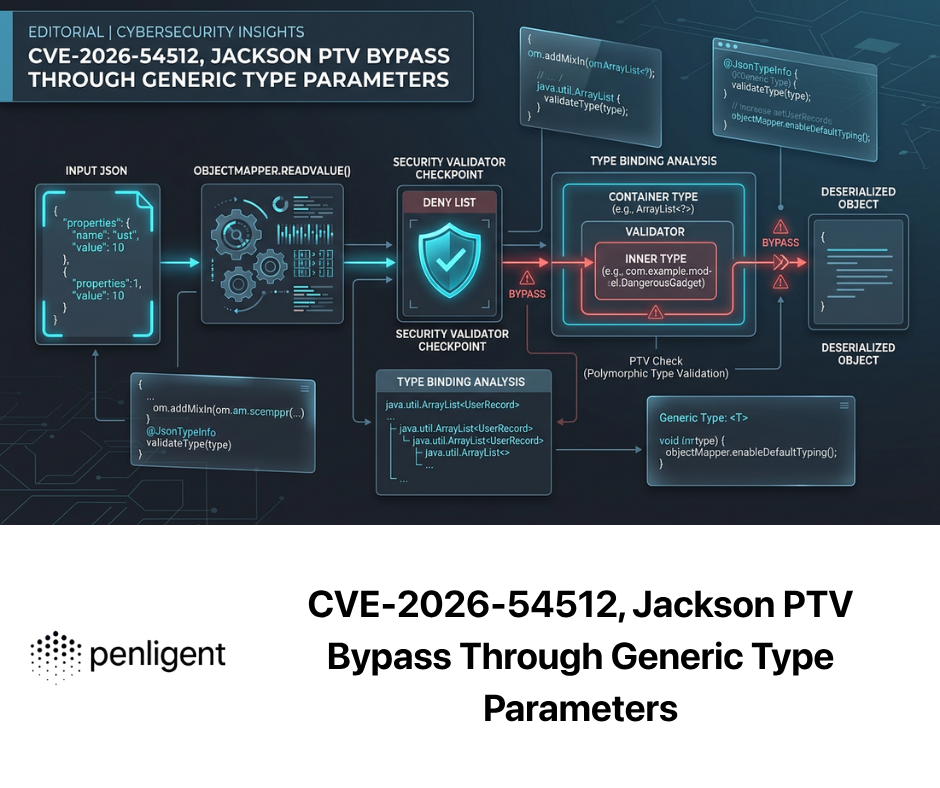
A frase "ctf ai" deixou de ser novidade e entrou nos locais onde o trabalho de segurança real acontece. Os eventos e conjuntos de dados que priorizam a IA agora testam os agentes contra injeção imediata, jailbreaks e exploração da Web; os programas governamentais estão financiando a triagem e a aplicação de patches autônomos. Se você é um engenheiro de segurança, a questão não é experimentar ou não os agentes - é como tornar seus resultados repetíveis, auditáveis e dignos de serem entregues à engenharia. As competições recentes do Hack The Box, do LLM CTF do SaTML e do AIxCC da DARPA nos dão sinais concretos sobre o que funciona e o que falha, e onde a orquestração - e não apenas modelos maiores - é mais importante. (HTB - Capture a bandeira)

O sinal atual de "ctf ai" é mais claro do que a propaganda sugere
Observe primeiro os locais que impulsionam o comportamento. O Hack The Box está sendo realizado Neurogridum CTF com IA voltado explicitamente para pesquisadores e profissionais, com cenários projetados para testar a confiabilidade do agente sob restrições realistas em vez de quebra-cabeças de brinquedo; o formato prioriza o comportamento de ponta a ponta, não apenas cargas inteligentes. Trilhas temáticas de IA também estão aparecendo nas principais reuniões de segurança e no ecossistema do AI Village; notebooks e guias passo a passo se concentram em LLMs de equipe vermelha, não apenas na solução de criptografia clássica. O resultado é um vocabulário para falhas e defesas de agentes em que as equipes podem atuar, em vez de um conjunto de "desafios divertidos". (HTB - Capture a bandeira)
O LLM CTF enquadrou a injeção de prompt como um problema mensurável: os defensores enviam grades de proteção; os atacantes tentam extrair um segredo oculto do prompt do sistema; o conjunto de dados agora inclui mais de 144 mil bate-papos adversários em 72 defesas. Essa escala é importante porque captura modos de falha e padrões de desvio que você verá novamente em assistentes e copilotos de produção. É um alvo de treinamento melhor para a injeção anti-prompt do que para a equipe vermelha ad hoc, pois os ataques e as defesas são padronizados e reproduzíveis. (Spylab CTF)
Enquanto isso, AIxCC da DARPA levou a narrativa dos laboratórios para a infraestrutura, com rodadas semifinais e finais mostrando taxas de correção automatizadas que, embora imperfeitas, provam que o caminho para a triagem e correção autônomas não é mais ficção científica. As recapitulações da mídia destacam a descoberta de vulnerabilidades reais e o desempenho de aplicação de patches, com ferramentas de código aberto dos finalistas que podem ser adotadas além do concurso. Para as organizações de segurança, a lição não é "substituir os humanos", mas "proteger automaticamente a cauda longa mais rápido do que antes" e permitir que os humanos conduzam novas cadeias. (Axios)
O que o "ctf ai" pode realmente fazer hoje
Em experimentos públicos e em artigos escritos, os agentes demonstram competência em tarefas estruturadas de nível introdutório - enumeração de diretórios, sondas de injeção de modelos, uso indevido de tokens básicos, codificações comuns - especialmente quando um planejador pode rotear para ferramentas conhecidas. Onde eles ainda vacilam: trabalho bruto de longa duração sem checkpointing, reversão complexa que exige saltos cognitivos e saída ruidosa de várias ferramentas sem correlação. Um relatório recente de profissionais constatou que os agentes se sentem confortáveis com a dificuldade do ensino médio/introdução à ciência da computação, mas são frágeis em cadeias binárias pesadas; outros benchmarks (por exemplo, conjuntos CTF da NYU, InterCode-CTF) confirmam que o desempenho depende muito da estrutura e da orquestração do conjunto de dados. A linha geral é consistente: os agentes precisam coordenação e disciplina de provas para se tornar útil além de um único quadro de CTF. (Artigos sobre InfoSec)
Se você quiser que o "ctf ai" agregue valor dentro de uma organização, ancore-o em uma linguagem de teste estabelecida. NIST SP 800-115 (testes técnicos e manuseio de evidências) e o Guia de teste de segurança na Web da OWASP (testes na Web baseados em fases) oferecem um dialeto de controle que a engenharia e a auditoria já falam. O produto final não é uma apresentação de destaque; é um cadeia de ataque reproduzível com artefatos rastreáveis, mapeados para controles reconhecidos pela sua equipe de GRC. (YesChat)
Um modelo prático de orquestração que torna o "ctf ai" crível
A peça que falta na maioria das demonstrações de agentes não são prompts geniais; é o encanamento. Trate o fluxo de trabalho como quatro camadas - intérprete de intenção, planejador, executor e evidência/relatório - para que o estado da sessão, os tokens e as restrições não vazem entre as ferramentas.
Um plano mínimo e concreto (ilustrativo)
plano:
objetivo: "HTB/PicoCTF (web fácil): descobrir administração/depuração; testar fixação de sessão/reutilização de token; capturar traços HTTP e capturas de tela; mapear para NIST/ISO/PCI."
escopo:
allowlist_hosts: ["*.hackthebox.com", "*.htb", "*.picoctf.net"]
no_destructive: true
restrições:
rate_limit_rps: 3
respect_rules: true
estágios:
- recon: { adapters: [subdomain_enum, tech_fingerprint, ffuf_enum] }
- verify: { adapters: [session_fixation, token_replay, nuclei_http, sqlmap_verify] }
- crypto: { adapters: [crypto_solver, known_cipher_patterns] }
- forensics: { adapters: [file_carver, pcap_inspector] }
- evidence (evidência): { capture: [http_traces, screenshots, token_logs] }
- report:
outputs: [exec-summary.pdf, fix-list.md, controls.json]
map_controls: ["NIST_800-115","ISO_27001","PCI_DSS"]
Isso não é pseudoacadêmico; é o que lhe permite executar novamente um plano uma semana depois e diferenciar os artefatos. Para desafios de sourcing, escolha Hackear a caixa e PicoCTF porque são bem documentados e legalmente seguros para automatizar em modo de laboratório; ambos são reconhecidos por gerentes de contratação e educadores. (HTB - Capture a bandeira)
Evidências antes de contar histórias
Uma descoberta que será corrigida pela engenharia tem três propriedades: etapas reproduzíveis, rastros analisáveis por máquina e uma narrativa de impacto com a qual alguém pode argumentar. Considere esse objeto normalizado armazenado ao lado dos artefatos:
{
"id": "PF-CTF-2025-0091",
"title": "Reutilização de token aceita em /admin/session",
"severidade": "Alta",
"repro_steps": [
"Obter token T1 (usuário A, ts=X)",
"Repetir T1 em /admin/session com cabeçalhos criados",
"Observar 200 + emissão de cookie de administrador"
],
"evidence" (evidência): {
"http_trace": "evidence/http/trace-0091.jsonl",
"screenshot": "evidence/screenshots/admin-accept.png",
"token_log": "evidence/tokens/replay-0091.json"
},
"impacto": "Ultrapassagem do limite de privilégios; possível acesso lateral aos dados",
"controles": {
"NIST_800_115": ["Teste de mecanismos de autenticação"],
"ISO_27001": ["A.9.4 Controle de acesso"],
"PCI_DSS": ["8.x Authentication & Session"]
},
"remediação": {
"priority" (prioridade): "P1",
"actions" (ações): [
"Vincular tokens ao contexto do dispositivo/sessão",
"Proteção contra reprodução baseada em nonce",
"TTL curto + invalidação no lado do servidor"
],
"verification" (verificação): "A repetição retorna 401; anexe o rastreamento atualizado"
}
}
Você pode inserir isso em um pipeline, difundi-lo entre as execuções e tratar o "concluído" como uma condição de verificação, não como uma caixa de seleção.
Resultados que importam: o que medir e por quê
Uma agenda curta domina: tempo para a primeira cadeia validada (não apenas a primeira bandeira), completude da evidência (rastros + captura de tela + ciclo de vida do token), sinal-ruído (menos correntes, porém mais fortes), repetibilidade (você pode pressionar "executar" após um patch e obter um delta) e intervenções humanas (quantas etapas ainda exigem um ser humano porque uma ferramenta não pode fornecer provas). Medir a proeza do agente somente pela contagem de soluções em quadros com curadoria é enganoso; você quer saber a rapidez com que o sinal de qualidade da cadeia chega e se uma segunda execução prova que você realmente moveu o risco.
Aqui está uma comparação compacta que esclarece os ganhos quando você adiciona orquestração ao "ctf ai":
| Dimensão | Scripting manual e notas | Agente + orquestração |
|---|---|---|
| Compartilhamento de estado (tokens, cookies) | Frágil, por operador | Central, reutilizado em todas as ferramentas |
| Captura de evidências | Capturas de tela/pcaps ad hoc | Pacote obrigatório com rótulos |
| Mapeamento de relatórios | Digitado à mão | Gerado com linguagem de controle |
| Repetição após uma correção | Propenso a erros | Plano determinístico + diffs |
| Ruído | Muitos itens "interessantes" | Menos descobertas de qualidade em cadeia |
O NIST SP 800-115 e o OWASP WSTG ajudam você a definir a barra de aceitação antes de começar; eles também são os documentos que os auditores citarão para você. (YesChat)
Estabelecimento de bases no ecossistema mais amplo para que você não se adapte demais
O Neurogrid do Hack The Box promove o realismo agêntico. O LLM CTF da SaTML publica as defesas e os chats de ataque. O AIxCC incentiva o endurecimento de bases de código em escala e já está enviando resultados de código aberto. Integre-os em seu programa: use o HTB/PicoCTF para praticar a automação segura; use os dados do SaTML para treinar defesas contra injeção imediata; use os resultados do AIxCC como prova de que você pode automatizar a triagem e a aplicação de patches em determinadas classes de bugs. O objetivo não é vencer um placar; é criar uma memória muscular que possa ser reutilizada em seu próprio patrimônio. (HTB - Capture a bandeira)
Onde o Penligent.ai se encaixa sem acenar com as mãos
Se o seu laboratório já tem ótimas ferramentas, seu gargalo é a coordenação. Penligent.ai pega uma meta em inglês simples ("enumerar administrador/depuração, testar fixação de sessão/reutilização de token, capturar evidências, mapear para NIST/ISO/PCI") e a transforma em um plano reproduzível que orquestra mais de 200 ferramentas com contexto compartilhado. Em vez de fazer malabarismos com CLIs e capturas de tela, você obtém um único pacote de evidências, uma lista de correções prontas para engenharia e um JSON mapeado por padrões que pode ser importado para qualquer rastreamento que você use. Como os planos são declarativos, você pode executá-los novamente após uma correção e enviar os artefatos de antes e depois para a liderança. É assim que o "ctf ai" deixa de ser uma demonstração interessante e se torna uma alavanca de programa.
A ênfase do produto não é um mecanismo de exploração milagroso; é controle de linguagem natural + orquestração de adaptadores + disciplina de evidências. Essa combinação tende a elevar os KPIs que importam: tempo mais rápido para a primeira cadeia validada, maior integridade das evidências e repetibilidade muito melhor. Ela também se alinha diretamente com a linguagem de controle em NIST SP 800-115 e OWASP WSTGpara que o GRC possa participar sem sobrecarga de tradução. (YesChat)
Esboço de caso: de "ctf ai" a uma vitória interna
Executar um HTB/PicoCTF plano easy-web que encontre um ponto fraco no administrador/sessão; colete os rastros e as capturas de tela automaticamente; envie uma lista de correções que vincule os tokens ao contexto do dispositivo/sessão e aplique a proteção de repetição baseada em nonce e TTLs rígidos. Após o lançamento do patch, execute novamente o mesmo plano e anexe a repetição com falha com um novo rastreamento 401 à solicitação de alteração. A liderança recebe um antes/depois de uma página; os engenheiros recebem as etapas exatas; a auditoria recebe mapeamentos de controle. Esse é um delta de risco tangível derivado de um exercício de laboratório. (HTB - Capture a bandeira)
Não envie histórias; envie correntes
A melhor coisa sobre o "ctf ai" em 2025 é que ele carrega estrutura pública suficiente - eventos, conjuntos de dados, financiamento - para ser mais do que vibrações. Use competições e laboratórios como andaimes padronizados, mas julgue seu programa pela qualidade das cadeias que você pode reproduzir e pela velocidade com que você pode verificar as correções. Quando você associa agentes à orquestração e a uma base de evidências, não obtém apenas sinalizadores; obtém artefatos que fazem o trabalho real avançar.
Links de autoridade para leitura adicional
- NIST SP 800-115 - Guia técnico para testes e avaliações de segurança da informação. Tratamento de evidências e estrutura de testes que você pode citar na auditoria. (YesChat)
- Guia de teste de segurança na Web da OWASP (WSTG) - Metodologia baseada em fases para a Web. (ELSA)
- Hackear a caixa - Laboratórios clássicos e CTF Neurogrid com IA para prática de automação jurídica. (HTB - Capture a bandeira)
- PicoCTF - Conjunto de metas de nível educacional apoiado pela Carnegie Mellon. (HTB - Capture a bandeira)
- SaTML LLM CTF - Competição de defesa/ataque de injeção imediata com conjuntos de dados liberados. (Spylab CTF)
- DARPA AIxCC - Programa apoiado pelo governo que mostra o progresso da correção autônoma e os resultados de código aberto. (Axios)