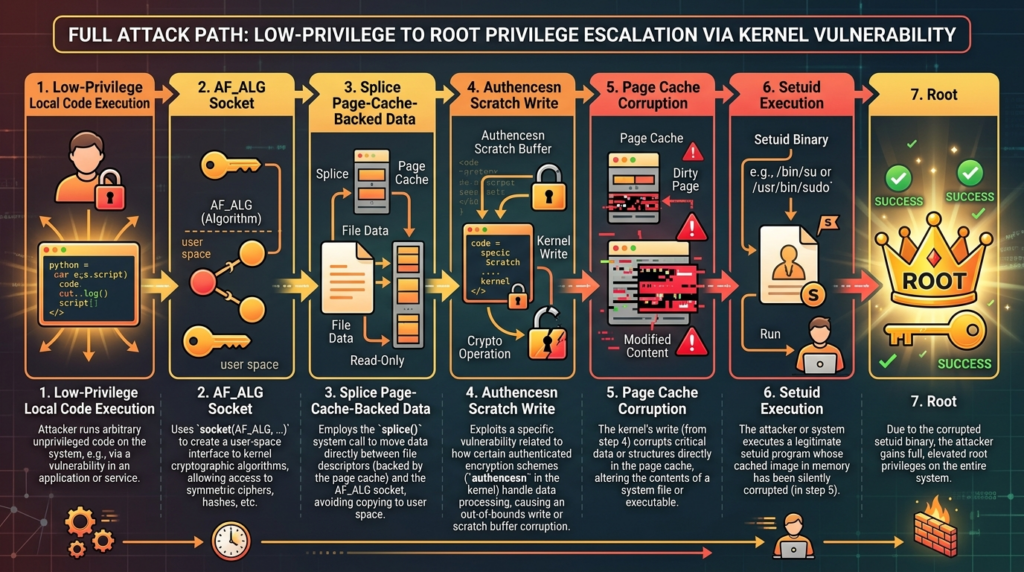
Copy Fail is CVE-2026-31431, a Linux kernel local privilege escalation flaw in the authencesn cryptographic template. The public disclosure describes a deterministic path where an unprivileged local user can combine AF_ALG, splice(), and AEAD decryption semantics to write four controlled bytes into the page cache of a readable file. In practical demonstrations, that primitive was used against a setuid-root binary to obtain root on tested mainstream Linux distributions. The bug is not a remote exploit by itself, but it becomes serious the moment an attacker already has low-privilege code execution through a shell, CI job, container workload, compromised developer dependency, weak SSH credential, web RCE, or sandbox escape chain. (Xint)
The reason Copy Fail deserves more than a quick patch note is not the size of the write. Four bytes sounds small until those bytes land in the wrong abstraction. The vulnerable path does not perform an ordinary file write. It corrupts the cached in-memory copy of a file that the kernel uses for later reads and execution. Xint’s disclosure states that the on-disk file remains unchanged and the corrupted page is not marked dirty for ordinary writeback, which means a defender relying only on disk checksums can miss the actual execution-time modification. (xint.io)
The short version for defenders is simple: patch the kernel first, then reduce exposure for workloads that do not need AF_ALG. The longer engineering lesson is more interesting. Copy Fail is a cross-subsystem invariant failure. splice() can pass page-cache-backed pages by reference. AF_ALG exposes kernel crypto operations to userspace. algif_aead added in-place operation complexity. authencesn uses destination memory as scratch space during decryption. Each piece can look reasonable on its own. The vulnerability appears when their assumptions collide.
The facts that matter first
Copy Fail is tracked as CVE-2026-31431. NVD’s description says the Linux kernel issue was resolved by changing crypto: algif_aead back to out-of-place operation, mostly reverting commit 72548b093ee3 except for associated-data copying. The CVE description states there is no benefit to in-place operation in algif_aead because the source and destination come from different mappings, and the fix removes the complexity added for in-place handling. (NVD)
The vulnerability is local. A remote attacker cannot trigger it across the network without already having a way to execute code locally on the target Linux system. That distinction matters, but it should not make teams complacent. Modern intrusions often move through stages. A low-privilege foothold on a CI runner, a developer VM, a shared build host, a container, a notebook environment, or a multi-tenant shell server is often enough to make a local kernel privilege escalation operationally useful.
The public Copy Fail page characterizes the issue as a straight-line logic flaw rather than a race-dependent exploit. It also states that the same 732-byte Python script roots Linux distributions shipped since 2017, and summarizes the chain as one logic bug in authencesn through AF_ALG e splice() into a four-byte page-cache write. (Xint)
The Xint write-up gives the most useful technical framing. It says an unprivileged local user can trigger a deterministic, controlled four-byte write into the page cache of any readable file on the system, and that a single short Python script can edit a setuid binary and obtain root on major Linux distributions shipped since 2017. It also says the primitive crosses container boundaries because the page cache is shared across the host. (xint.io)
Treat those claims carefully. The directly tested matrix in the Xint write-up lists Ubuntu 24.04 LTS, Amazon Linux 2023, RHEL 10.1, and SUSE 16 across kernel lines 6.12, 6.17, and 6.18. “Every distribution since 2017” is the researchers’ impact characterization, while the concrete evidence they published includes those named test environments and the root-cause link to the 2017 in-place optimization. (xint.io)
Why Copy Fail is different from the usual Linux LPE story
Linux local privilege escalation bugs are not rare. Some are memory corruption bugs. Some are reference-counting mistakes. Some depend on races. Some require unusual kernel configuration, fragile timing, a particular filesystem, a specific architecture, or a target-specific offset. Copy Fail stands out because the published exploit path is described as deterministic, compact, and portable across tested major distributions. (xint.io)
Xint explicitly contrasts Copy Fail with earlier high-profile Linux privilege escalation bugs. Dirty COW, CVE-2016-5195, depended on winning a race in the virtual memory copy-on-write path. Dirty Pipe, CVE-2022-0847, was version-specific and involved pipe buffer manipulation. Copy Fail, by contrast, is described as triggering without races, retries, or timing windows. (xint.io)
That does not mean every Linux system is equally exposed in practice. A laptop used by one person with no untrusted local code has a different risk profile from a multi-tenant server. A Kubernetes node running untrusted workloads has a different risk profile from a locked-down appliance. A CI runner that executes arbitrary pull requests sits near the top of the priority list because executing attacker-controlled code is part of its job.
The main operational difference is reliability. A noisy race exploit may fail, crash, or reveal itself through instability. A straight-line logic flaw is easier to reason about, easier to automate, and easier to chain after an initial foothold. If the public report is accurate for a given target kernel, the defender should assume a low-privilege local account can become root unless the kernel is patched or the vulnerable interface is blocked.
| Dimensão | Por que é importante | Copy Fail implication |
|---|---|---|
| Vetor de ataque | Determines whether exposure starts from the network or from local code execution | Local execution is required, but local code execution is common in CI, containers, dev systems, and post-exploitation chains |
| Reliability | Determines whether exploitation is noisy or repeatable | Public disclosure describes a straight-line flaw without a race window |
| Primitive size | Determines how much corruption is needed | Four controlled bytes are enough when placed into executable page-cache-backed content |
| Persistência | Determines forensic and recovery behavior | Disk content can remain unchanged while page cache is corrupted |
| Container relevance | Determines multi-tenant blast radius | Shared page cache makes containerized workloads a concern |
| Immediate mitigation | Determines whether teams can reduce risk before full patch rollout | Patch first, then consider blocking AF_ALG or disabling algif_aead where compatible |
The table should not be read as a replacement for vendor advisories. It is a prioritization model. The patch state of your actual distribution kernel is the source of truth.
The page cache is the wrong place to lose a write boundary
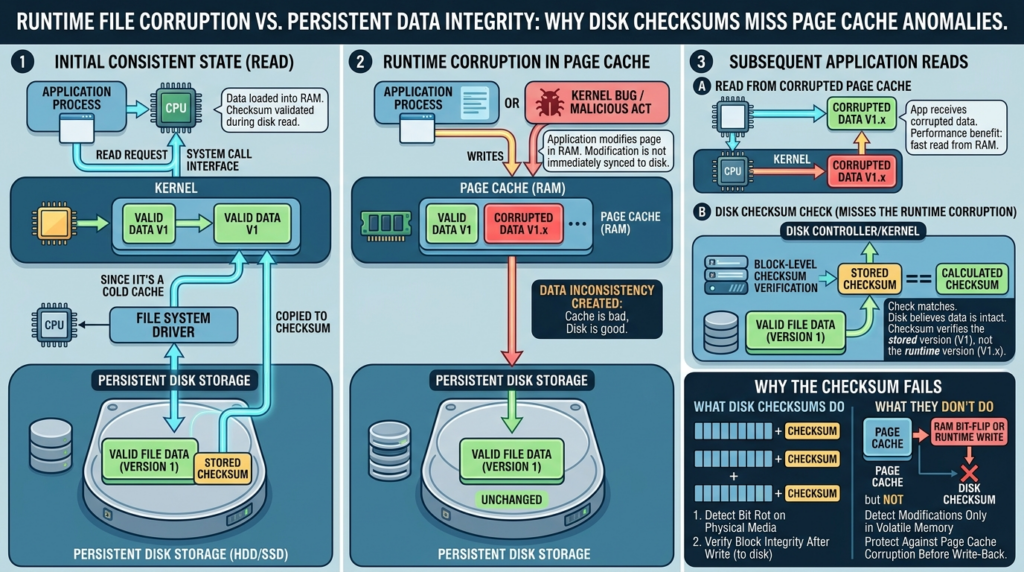
To understand Copy Fail, start with the page cache. Linux keeps file contents in memory so repeated reads, mappings, and executions do not need to go back to disk each time. When a process executes a binary, the bytes it sees can come from the cached page, not from a fresh disk read. This is normal and essential for performance.
The problem appears when a kernel path that should only read page-cache-backed data accidentally places those pages into a structure that a later crypto operation treats as writable output. At that point, the bug is no longer a normal file permission problem. The attacker did not open the target file for writing. The attacker did not call write() on the file. The disk inode may never be modified. The corrupted view can still affect what later readers and executors see while the page remains cached.
This is why simple file integrity checks are not enough. A package manager verification step that hashes the on-disk binary can say the file is clean. A traditional file monitor waiting for write events can stay quiet. The page cache, however, may contain bytes that differ from the backing file. Xint’s disclosure states that the corrupted page is not marked dirty by the kernel writeback machinery and that standard on-disk checksum comparisons miss the modification because the file on disk is unchanged. (xint.io)
A useful mental model is this:
Disk file:
/usr/bin/su contains the vendor-signed bytes
Page cache:
The kernel keeps cached pages for fast read, mmap, and execve paths
Buggy path:
A page-cache-backed page is accidentally chained into a writable crypto destination
Result:
The in-memory page can differ from the disk file without a normal file write
The danger is not that the attacker has a general-purpose file writer. The danger is that a narrow write primitive lands inside a trusted execution path.
O que splice() contributes
O splice() system call moves data between file descriptors without copying between kernel address space and user address space. The man page states that it transfers data from one file descriptor to another, with at least one of the descriptors referring to a pipe. (man7.org)
That “without copying” behavior is the performance feature that becomes relevant to this bug. Oracle’s Linux pipe and splice analysis explains that splicing from a file to a pipe allows sharing the page cache data buffer with the pipe, avoiding data copying when reading from a pipe fed by a file. It describes the file-to-pipe path as sharing page cache data through the kernel splice implementation. (Oracle Blogs)
In normal use, this is an optimization. It lets the kernel move data efficiently. In Copy Fail, it becomes a provenance problem. The data entering the crypto path can include references to page-cache-backed pages from a file. If downstream code later treats those referenced pages as part of a writable destination scatterlist, the kernel has confused “read this file-backed data” with “write output here.”
That confusion is subtle because no single API call looks obviously malicious. A user opens a readable file. A user creates a pipe. A user splices bytes. A user talks to a kernel crypto socket. The exploit lives in the composition.
O que AF_ALG contributes
AF_ALG is the userspace socket interface to the Linux kernel crypto API. Linux kernel documentation says the kernel crypto API is accessible from userspace through socket type AF_ALG, and that userspace creates a socket, binds it to a cipher, accepts an operation socket, sends input with the send() ou write() family, and receives output with read() ou recv(). The same documentation lists AEAD ciphers as one of the accessible cipher classes. (docs.kernel.org)
The interface is not inherently a vulnerability. It exists so userspace applications can use kernel crypto implementations. The kernel documentation also explicitly discusses in-place cipher operation, where the input buffer and output buffer may be one and the same. (docs.kernel.org)
Copy Fail shows why a broad userspace-to-kernel API needs strict invariants. Crypto code is full of complicated buffer semantics: associated authenticated data, plaintext, ciphertext, tags, IVs, integrity errors, scatterlists, and algorithm wrappers. When a low-privilege process can drive those paths, every assumption about source and destination memory becomes part of the kernel attack surface.
In this case, the relevant path is AEAD decryption through algif_aead, combined with the authencesn template. The vulnerable design allowed a destination scatterlist to contain page cache pages that originated from the source side of a spliced file path. That is the boundary failure.
The root cause, page-cache-backed pages in a writable scatterlist
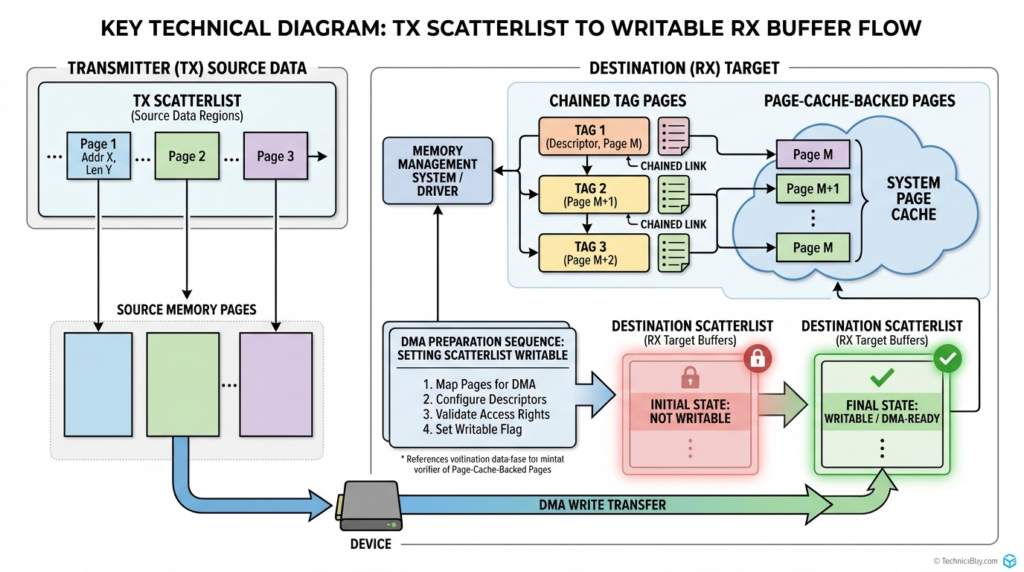
The oss-security post gives a concise root-cause summary. It says that in 2017 an optimization was added to algif_aead.c to perform AEAD operations in-place. For decryption, the code copied AAD and ciphertext from the transmit scatterlist into the receive buffer, but chained tag pages by reference using sg_chain(), then set req->src = req->dst. As a result, page cache pages from splice() were in the writable destination scatterlist. (openwall.com)
Xint’s write-up explains the same root cause in more detail. For AEAD decryption, the input layout is associated data, ciphertext, and authentication tag. The AAD and ciphertext are copied into the receive buffer, but the tag pages are not copied. The kernel retains their scatterlist entries and chains them onto the output scatterlist. The output scatterlist therefore includes normal user receive memory followed by chained tag pages that still reference the target file’s page cache. (xint.io)
A simplified diagram helps:
Input from spliced file:
TX scatterlist
[ AAD ][ Ciphertext ][ Auth tag backed by file page cache ]
algif_aead vulnerable layout:
RX buffer receives copied AAD and ciphertext
Tag pages are chained by reference
Combined destination:
[ RX buffer, writable ][ Tag pages, still file page cache ]
Then:
req->src = req->dst
The dangerous part is not merely that page cache pages are present. It is that they are present in a structure the crypto algorithm can write through. The algorithm does not need to know it is touching a file-backed page. It only sees a destination scatterlist.
The bug is also a reminder that “copy” and “reference” are not interchangeable security decisions. Copying data into a fresh buffer breaks provenance. Chaining by reference preserves provenance. In performance-sensitive code, reference chaining may look attractive. In security-sensitive kernel code, it also carries the original object’s trust boundary into the next subsystem.
The trigger, authencesn scratch space
The vulnerable scatterlist layout becomes exploitable because authencesn writes outside the intended decryption output region as part of its internal bookkeeping.
Xint explains that authencesn is an AEAD wrapper used by IPsec for Extended Sequence Number support. IPsec uses 64-bit sequence numbers split into high and low halves. For HMAC computation, authencesn rearranges those bytes and uses the caller’s destination buffer as scratch space. The disclosed code path includes a scatterwalk_map_and_copy() call that writes four bytes after assoclen + cryptlen. (xint.io)
In a safe layout, that scratch write would land in scratch space belonging to the operation. In the vulnerable layout, assoclen + cryptlen can be arranged so the scratch write lands in the chained tag pages that still reference the page cache of the target file. That turns an internal crypto rearrangement into a four-byte page-cache write primitive.
The authentication result does not save the system. An AEAD decrypt operation can ultimately fail integrity verification, but the scratch write has already happened. For defenders, this is the key lesson: security checks performed after a side effect do not undo the side effect unless the code explicitly restores the state or isolates the side effect into disposable memory.
The exploit does not require a general arbitrary write to disk. It only needs to repeat a narrow in-memory write enough times to alter an execution path. That is why the four-byte primitive matters.
Why a four-byte page-cache write can become root
A four-byte write sounds limited, but exploitability depends on placement, repeatability, and target selection.
The public exploit path targets /usr/bin/su, a setuid-root binary widely present on major Linux distributions. Xint’s write-up says the exploit constructs a sendmsg() e splice() pair for each four-byte chunk, using AAD bytes to carry the controlled value and splice offsets to position the write in the target binary’s page cache. After enough controlled chunks are placed, executing the setuid binary follows the corrupted in-memory view and yields root in the demonstrated path. (xint.io)
This article intentionally does not reproduce the exploit. For engineering purposes, the important points are enough:
Attacker has:
Low-privilege local code execution
Attacker can:
Open a readable setuid binary
Use splice to feed page-cache-backed data into AF_ALG
Trigger authencesn scratch writes into chosen page-cache offsets
System effect:
The disk binary remains unchanged
The cached executable content can be temporarily altered
A later execution of the setuid binary can follow attacker-influenced bytes
The result is local privilege escalation. The change is transient in the sense that it is tied to page cache state rather than a persistent disk modification. Transient does not mean harmless. If the attacker gets a root shell, steals secrets, modifies system configuration, loads persistence, or pivots to another host, the damage has already moved beyond the page cache.
That is why defenders should not rely on reboot as the primary fix. A reboot may clear the corrupted cache state, but it does not remove the vulnerable kernel path unless the system boots into a patched kernel.
Who should patch first
Every affected Linux system should be patched. The order matters when teams have thousands of systems and limited maintenance windows.
| Meio ambiente | Prioridade | Reason |
|---|---|---|
| Multi-tenant shell servers | Crítico | A normal local user account may become root on a shared host |
| CI runners executing untrusted code | Crítico | Pull requests, build scripts, and dependency hooks are natural local execution points |
| Kubernetes nodes with untrusted workloads | Crítico | Shared kernel and shared page cache turn local container execution into node-level concern |
| SaaS sandboxes and code execution platforms | Crítico | Running user-supplied code is the product model |
| Developer workstations used for untrusted builds | Alta | Malicious dependencies or test scripts can provide the local foothold |
| Bastion hosts and jump boxes | Alta | Low-privilege SSH compromise can become full host compromise |
| Single-tenant production servers | Medium to high | Risk depends on whether attackers can reach any local execution path |
| Single-user desktop systems | Médio | Lower multi-user risk, but malicious local code can still benefit |
The Register reported on April 30, 2026, that major Linux distributions had begun shipping patches and that Debian, Ubuntu, and SUSE had issued patches or guidance. It also noted that Red Hat’s guidance had changed toward patching promptly. (O Registro)
Distribution status can change quickly. Debian’s tracker, for example, showed some Debian releases vulnerable while forky e sid had fixed versions at the time the page was captured. (Debian Security Tracker) SUSE’s CVE page listed the overall state as pending and showed affected product rows for multiple SUSE products, while also showing scoring differences between CNA and SUSE assessments. (suse.com) CloudLinux stated on April 30, 2026, that its kernel and KernelCare teams were investigating and that a patch was on the way for CloudLinux kernels and KernelCare. (cloudlinux.zendesk.com)
The practical rule is simple: do not infer safety from the distribution name. Check the vendor tracker for your release and kernel package. Then confirm the running kernel after reboot.
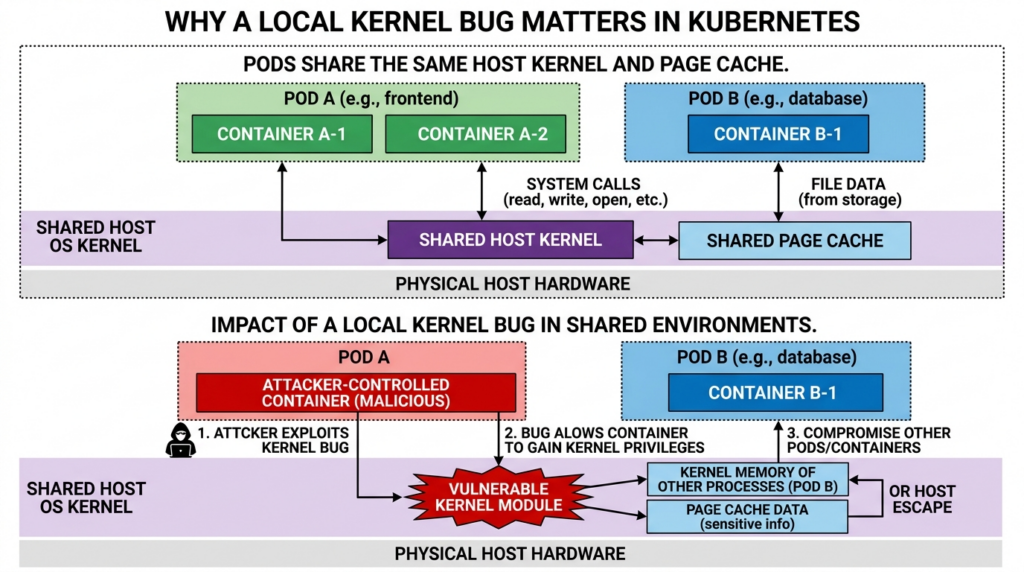
Why containers are in scope
Container isolation is not a separate kernel. Most Linux containers share the host kernel. That means a local kernel bug reachable from inside a container can become a host problem if the required interface is available and the container’s confinement policy does not block it.
Copy Fail is especially uncomfortable because the primitive involves page cache. Xint’s write-up says the same primitive crosses container boundaries because the page cache is shared across the host, and describes it as a container escape primitive and Kubernetes node compromise vector. (xint.io)
That does not mean every Kubernetes pod can exploit every node in the same way. Real exploitability depends on kernel version, module availability, seccomp policy, container runtime behavior, filesystem visibility, target binary availability, mount layout, and other hardening controls. But it does mean cluster operators should not dismiss the issue as “just local.”
Kubernetes documentation defines three relevant seccomp profile types: Unconfined, RuntimeDefaulte Localhost. It also states that privileged containers always run as Unconfined, and that a Localhost profile must exist on the node under the kubelet seccomp profile path. (Kubernetes)
For Copy Fail, that matters because a custom seccomp profile can be used to block socket(AF_ALG, ...) for workloads that do not need kernel crypto sockets. Runtime defaults may not be enough in every environment, and privileged containers bypass seccomp confinement entirely. The safer approach is to patch nodes, remove privileged containers where possible, avoid unconfined profiles, and add targeted syscall restrictions for untrusted workloads.
Why CI runners are high risk
CI runners are one of the most important environments for Copy Fail response.
A CI runner often executes code from pull requests, build scripts, package managers, test suites, postinstall hooks, and container build steps. That is exactly the kind of low-privilege local execution an LPE needs. If the runner is long-lived, shared across projects, or allowed to access signing keys, cloud credentials, package registries, deployment tokens, or internal networks, root on the runner can become a supply-chain incident.
Patch priority should be highest for runners that meet any of these conditions:
| Runner condition | Why it increases risk |
|---|---|
| Executes pull requests from forks | Attacker-controlled code may run before review |
| Runs jobs for multiple tenants or teams | Root on one job can affect other workloads |
| Keeps workspace state between jobs | Page cache and filesystem state may persist longer than expected |
| Has deployment credentials | Local root can become cloud or production access |
| Builds container images | Compromise can affect downstream artifacts |
| Runs privileged Docker or nested virtualization | Kernel attack surface and breakout impact increase |
| Uses long-lived self-hosted agents | A compromised runner may remain available for repeated attempts |
Good CI hardening is not only about this CVE. Copy Fail is another reason to prefer ephemeral runners, single-use VMs, isolated build pools, minimal credentials, short-lived tokens, strict job trust boundaries, and fast kernel patching.
Detection is hard because the visible artifact may not be the modified file
Detection for Copy Fail should start with exposure management, not IOC hunting. The primitive is small, the public PoC is compact, and variants can change quickly. Looking for one filename, one hash, or one command line will miss adapted usage.
The most reliable question is: “Is this host running a vulnerable kernel with reachable AF_ALG AEAD behavior?” That is a patch and configuration question.
Start with basic inventory:
uname -a
cat /proc/version
cat /etc/os-release
Then check whether the relevant module is loaded or available:
lsmod | grep -E '^algif_aead\b|^af_alg\b|^authenc'
modinfo algif_aead 2>/dev/null || true
grep -E 'authencesn|algif_aead|af_alg' /proc/crypto 2>/dev/null || true
A clean result does not prove the system is safe. Modules can be autoloaded. Kernel crypto algorithms may be built in. Distribution packaging varies. These checks are useful as exposure clues, not final vulnerability determinations.
Next, inventory setuid-root binaries because they are common privilege escalation targets:
find / -xdev -perm -4000 -type f -printf '%m %u %g %p\n' 2>/dev/null | sort
This command does not detect exploitation. It identifies high-value local targets that make LPE bugs more useful.
For runtime monitoring, focus on suspicious combinations rather than single events:
| Sinal | Por que é importante | Limitação |
|---|---|---|
Unusual creation of AF_ALG sockets | Copy Fail requires access to the kernel crypto socket interface | Legitimate crypto users may exist |
splice() activity tied to sensitive binaries | The primitive involves page-cache-backed file data | High-quality syscall correlation is needed |
| Execution of setuid binaries after unusual crypto socket use | Public path targets setuid execution | Attackers can choose variants |
| Root shell spawned from unexpected user context | Indicates possible successful LPE | Needs process lineage and TTY context |
| CI job opening system binaries and crypto sockets | High-risk combination in untrusted jobs | Requires runner telemetry |
| Container process using unusual kernel crypto paths | May indicate breakout attempts | Container runtime visibility varies |
Linux audit rules can help in some environments, but they are not a complete answer. For example, auditing every socket e emenda call on a busy system may be too noisy. A more realistic approach is targeted telemetry on high-risk hosts, CI runners, and sandbox nodes.
If your monitoring stack supports eBPF-based tracing, a useful defensive experiment is to alert on socket(AF_ALG, ...) by untrusted users or containers. Linux kernel documentation states that AF_ALG is socket family 38 in user space headers when not already exported, which is useful when building argument-aware filters or traces. (docs.kernel.org)
A conceptual trace policy looks like this:
Alert when:
syscall == socket
arg0 == AF_ALG
process is not an approved crypto service
user is non-root or containerized
host role is CI runner, sandbox, shared server, or Kubernetes node
Do not treat this as proof of exploitation. Treat it as a high-signal lead for investigation.
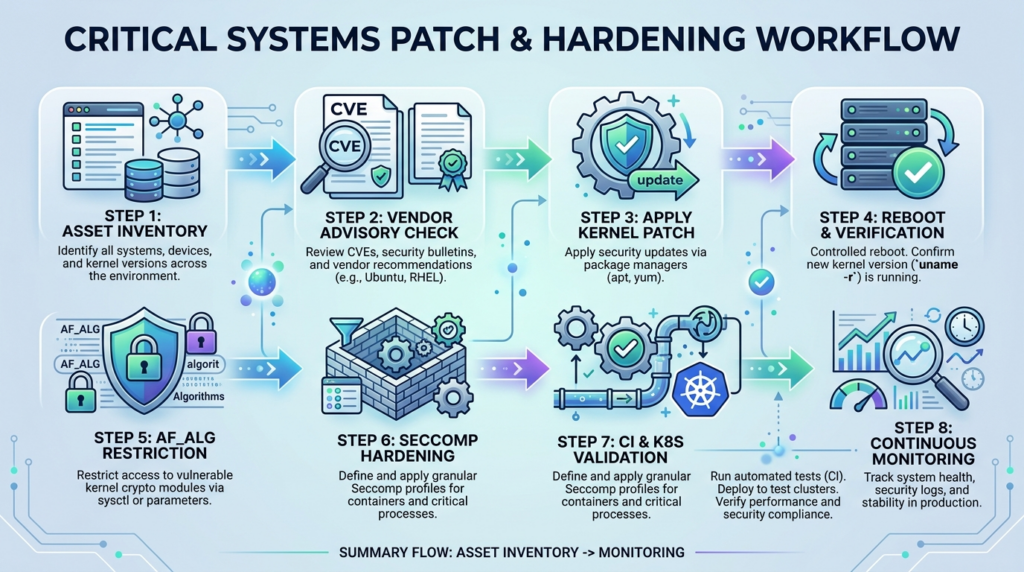
Patch and reboot, then prove the running kernel changed
The primary mitigation is to install the vendor-fixed kernel and reboot into it. The NVD and vendor descriptions point to the upstream fix reverting algif_aead to out-of-place operation. (NVD)
A common operational mistake is installing a fixed kernel package but continuing to run the old kernel. Linux systems do not stop using the running kernel just because a package update was installed. You need to reboot or live patch where supported, then confirm the active kernel.
A minimal patch verification flow:
# Before patching
uname -r
cat /etc/os-release
# Install updates using your distro package manager
# Debian or Ubuntu example
sudo apt update
sudo apt full-upgrade
# RHEL-compatible example
sudo dnf update kernel\*
# SUSE example
sudo zypper patch
# Reboot into the new kernel
sudo reboot
After reboot:
uname -r
bootctl status 2>/dev/null || true
grubby --default-kernel 2>/dev/null || true
dpkg -l 'linux-image*' 2>/dev/null | grep '^ii' || true
rpm -qa 'kernel*' 2>/dev/null | sort || true
Then compare the running kernel with your vendor’s fixed package version. For fleets, do this through configuration management or endpoint inventory, not manually one host at a time.
For cloud images and container nodes, patching the live host is only part of the job. Update golden images, node pool images, AMIs, runner base images, VM templates, and any autoscaling launch templates. Otherwise, old vulnerable kernels can reappear during scaling or replacement.
Temporary mitigation, block algif_aead where compatible
Xint’s remediation section recommends patching the kernel and, for immediate mitigation, blocking AF_ALG socket creation via seccomp or blacklisting the algif_aead module. It gives the example of writing an install rule to /etc/modprobe.d/disable-algif-aead.conf and removing the module. (xint.io)
A defensive version of that approach:
echo 'install algif_aead /bin/false' | sudo tee /etc/modprobe.d/disable-algif-aead.conf
sudo modprobe -r algif_aead 2>/dev/null || true
sudo update-initramfs -u 2>/dev/null || true
sudo dracut -f 2>/dev/null || true
Use this only after compatibility testing. Some environments may rely on kernel crypto interfaces. Some kernels may build functionality in rather than as a removable module. Some systems may require initramfs regeneration. Removing or blocking a module is a temporary risk-reduction control, not a substitute for a fixed kernel.
Also remember that module blacklisting is not always enforceable after compromise if the attacker already has root. It is useful for reducing pre-exploitation reachability, not for recovery after a suspected successful exploit.
Temporary mitigation, block socket(AF_ALG, ...) for untrusted workloads
Seccomp can reduce exposed kernel surface by filtering system calls. Linux kernel documentation describes seccomp filtering as a way for a process to specify a BPF filter over incoming system calls, using the syscall number and arguments. It also warns that seccomp is not a complete sandbox; it is a mechanism for minimizing exposed kernel surface and should be combined with other hardening techniques. (docs.kernel.org)
That distinction matters. Blocking AF_ALG is not a full container escape defense. It is a targeted mitigation for a specific reachable interface.
A minimal OCI-style seccomp deny rule for socket(AF_ALG, ...) can look like this:
{
"defaultAction": "SCMP_ACT_ALLOW",
"syscalls": [
{
"names": ["socket"],
"action": "SCMP_ACT_ERRNO",
"errnoRet": 1,
"args": [
{
"index": 0,
"value": 38,
"op": "SCMP_CMP_EQ"
}
]
}
]
}
This example uses 38 para AF_ALG, matching the Linux kernel userspace crypto documentation’s fallback macro. (docs.kernel.org) In production, do not replace your entire seccomp baseline with this small file unless you understand the consequences. Most teams should merge the deny rule into an existing hardened profile or use the container runtime’s default profile plus a targeted override.
Docker’s documentation says seccomp is available when Docker is built with seccomp and the kernel has CONFIG_SECCOMP enabled. It also says Docker’s default profile disables around 44 syscalls while preserving broad compatibility, and that you can pass a custom profile with --security-opt seccomp=/path/to/profile.json. (Docker Documentation)
Example for a test container:
docker run --rm -it \
--security-opt seccomp=/path/to/seccomp-block-af_alg.json \
debian:stable bash
Validate that legitimate workloads still work. Some cryptographic libraries may use userspace implementations and never touch AF_ALG; others may use kernel crypto through libkcapi or direct socket calls. The right policy is environment-specific.
Kubernetes mitigation with Localhost seccomp profiles
Kubernetes supports pod and container seccomp settings. The official documentation says RuntimeDefault applies the container runtime’s default profile, Unconfined applies no seccomp restrictions, and Localhost applies a profile stored on the node under the kubelet seccomp profile directory. It also states that privileged containers always run as Unconfined. (Kubernetes)
For high-risk clusters, patch nodes first. Then consider targeted AF_ALG blocking for namespaces that run untrusted code.
A pod-level example:
apiVersion: v1
kind: Pod
metadata:
name: restricted-workload
spec:
securityContext:
seccompProfile:
type: Localhost
localhostProfile: profiles/seccomp-block-af_alg.json
containers:
- name: app
image: debian:stable
command: ["sleep", "3600"]
This assumes the profile exists on every relevant node at the runtime’s expected location. If it does not exist, Kubernetes will fail container creation for a Localhost profile. That failure mode is useful because it prevents a workload from silently running without the intended profile. (Kubernetes)
For clusters, pair this with policy enforcement:
apiVersion: v1
kind: Namespace
metadata:
name: untrusted-builds
labels:
pod-security.kubernetes.io/enforce: restricted
pod-security.kubernetes.io/audit: restricted
pod-security.kubernetes.io/warn: restricted
This does not automatically block AF_ALG, but it helps prevent privileged and broadly unsafe pod configurations. Use admission control, policy engines, or platform guardrails to ensure untrusted workloads do not run privileged, unconfined, hostPID, hostPath-heavy, or root-equivalent containers.
What security teams should not trust
Copy Fail breaks several common assumptions.
Do not trust a clean file hash as proof of no exploitation. The public write-up states the on-disk file remains unchanged while the page cache can be corrupted. (xint.io) Hashing the disk file is still useful for other threats, but it does not settle this one.
Do not trust “containerized” as a security boundary by itself. Containers share the host kernel. If a kernel bug is reachable from inside the container and the container profile does not block the path, the host may be in scope.
Do not trust package installation alone. Confirm the running kernel. Confirm node pools and runners booted into the fixed kernel. Confirm old images are not redeployed.
Do not trust exploit hash detection. A 732-byte public script can be reformatted, rewritten, embedded, or reimplemented. Focus on patch state, interface exposure, and behavior.
Do not trust “local only” as a reason to defer. Local privilege escalation is often the second stage of a real intrusion. A web shell plus Copy Fail is not “local only” from the victim’s business perspective. A malicious CI job plus Copy Fail is not theoretical if your runner executes untrusted code.
Do not trust a mitigation that has not been tested. Blocking AF_ALG may be safe for many workloads, but the only defensible answer is to test your actual applications.
A practical response plan
The following plan is designed for teams that need to move quickly without losing evidence discipline.
| Etapa | Owner | Ação | Evidence to keep |
|---|---|---|---|
| 1 | Security engineering | Identify Linux hosts, containers nodes, CI runners, sandboxes, and shared servers | Asset list with kernel versions |
| 2 | Platform engineering | Check vendor advisory status for each distribution and release | Advisory references and fixed package versions |
| 3 | Infrastructure | Patch kernel packages and reboot | Change tickets, package logs, running uname -r after reboot |
| 4 | Kubernetes team | Patch and rotate node pools | Node image version, node creation time, workload migration logs |
| 5 | CI/CD team | Patch runner hosts and rebuild runner images | Runner image digest, job pool version, credential rotation notes |
| 6 | Detection engineering | Add alerts for unexpected AF_ALG socket usage on high-risk systems | SIEM rule, test event, known-good allowlist |
| 7 | App owners | Test temporary algif_aead ou AF_ALG restrictions where patching is delayed | Compatibility test results |
| 8 | Incident response | Review suspicious root transitions, setuid executions, and CI jobs during exposure window | Process lineage, audit logs, EDR events |
| 9 | Governança | Document exceptions and patch deadlines | Risk acceptance or remediation record |
A good response plan also includes negative proof. For each critical host class, record not only what was patched but how you confirmed it was running the fixed kernel after reboot.
Safe validation commands for defenders
The following commands support inventory and mitigation validation. They do not exploit the bug.
Check kernel and distribution:
uname -r
uname -a
cat /etc/os-release
Check whether the system exposes relevant crypto names:
grep -E 'authencesn|algif_aead|aead' /proc/crypto 2>/dev/null | head -50
Check loaded modules:
lsmod | grep -E 'algif_aead|af_alg|authenc|crypto'
Check whether algif_aead is available as a module:
modinfo algif_aead 2>/dev/null || echo "algif_aead module metadata not found"
Inventory setuid binaries on a single filesystem:
find / -xdev -perm -4000 -type f -printf '%p\n' 2>/dev/null | sort
Check seccomp status inside a process:
grep -E '^Seccomp:' /proc/self/status
A value of 0 means no seccomp mode for the current process, 2 means filter mode. This does not prove a profile blocks AF_ALG; it only confirms whether seccomp filtering is active for that process.
Check Docker seccomp support on a host:
grep CONFIG_SECCOMP= /boot/config-$(uname -r) 2>/dev/null || true
docker info 2>/dev/null | grep -i seccomp || true
Docker’s documentation uses the kernel config check as the basic seccomp support test and describes passing profiles with --security-opt. (Docker Documentation)
Incident response considerations
If you suspect Copy Fail exploitation, preserve volatile evidence quickly. The most important artifact may not be the disk file. If page cache tampering is involved, rebooting clears some evidence while also stopping a transient corrupted state. That creates tension between containment and forensics.
Reasonable incident response actions include:
| Evidence area | What to collect | Por que |
|---|---|---|
| Process lineage | Parent-child chains around su, shells, CI job processes, and container runtimes | Successful LPE often creates unusual root process ancestry |
| Audit logs | executar, user transitions, setuid binary execution, suspicious commands | Helps reconstruct privilege changes |
| EDR telemetry | Kernel interface use, shell spawning, file access patterns | May catch behavior before or after LPE |
| CI logs | Job scripts, dependency install hooks, runner workspace | CI is a likely local execution source |
| Container runtime logs | Pod events, container start config, seccomp profile, privileged flags | Determines whether the vulnerable interface was reachable |
| Host state | Running kernel, loaded modules, current uptime, package history | Determines exposure and remediation status |
| Credentials | Tokens available to the compromised local context | Root may allow access to secrets mounted on the host |
Do not overfit the investigation to /usr/bin/su. The public path uses it because it is widely present and setuid-root, but defenders should think in terms of privilege-bearing execution paths and local trust anchors.
The fix is conceptually simple because the bug was an invariant failure
The upstream fix reverts algif_aead to out-of-place operation. Xint’s write-up says the patch removes the 2017 in-place optimization entirely, separates source and destination scatterlists, and removes the sg_chain mechanism that linked page-cache tag pages into the writable destination scatterlist. (xint.io)
That is the right shape of fix. It does not try to make every AEAD algorithm promise never to scratch beyond a particular boundary. It removes the unsafe composition that put page-cache-backed pages into a writable destination in the first place.
The NVD description matches that framing: there is no benefit in operating in-place in algif_aead because source and destination come from different mappings, so the fix gets rid of the complexity added for in-place operation and copies associated data directly. (NVD)
This is a broader lesson for kernel and systems developers. If an optimization requires complex aliasing between data with different provenance, the performance gain must justify the security complexity. If the source is file-backed page cache and the destination is writable crypto output, the safe default should be separation.
Copy Fail and AI-assisted vulnerability research
The Copy Fail disclosure is also notable because the researchers describe the finding as AI-assisted while still rooted in human security insight. Xint says the finding began with Theori researcher Taeyang Lee studying how the Linux crypto subsystem interacts with page-cache-backed data, and that Xint Code was used to scale that research across the crypto subsystem. (xint.io)
That distinction is important. The interesting part is not “AI found a kernel bug” in isolation. The interesting part is the workflow: a researcher forms a high-quality hypothesis about a dangerous subsystem interaction, then uses automation to search a large code surface for violations of that hypothesis. Kernel vulnerabilities often hide between abstractions. An automated tool is more useful when it is guided toward invariants, provenance, and cross-subsystem assumptions than when it simply scans for generic bug patterns.
The same principle applies to authorized security validation. After a vulnerability like Copy Fail is disclosed, mature teams do not just ask whether a scanner has a CVE check. They need to map exposed hosts, confirm kernel package state, test whether compensating controls block the relevant interface, collect evidence, and produce a report that another engineer can reproduce. Penligent’s public material around Linux/Kali workflows describes installation on Kali through a Debian package path and a workflow that includes agent mode, manual mode, re-validation, TTP-backed verification, and report generation. That kind of evidence-centered workflow is most useful when it stays inside authorized scope and focuses on validation, not blind exploit execution. (penligent.ai)
Penligent also has a related write-up explaining vertical privilege escalation as the movement from a low-privilege account into a higher-privilege tier such as root or administrator, including operating-system-level flaws as one possible path. That framing is directly relevant to Copy Fail because the business risk is not “four bytes changed”; it is the transition from ordinary local execution to root control over the host. (penligent.ai)
What makes a good Copy Fail report inside an organization
A strong internal report should not stop at “CVE-2026-31431 present.” It should answer the questions an infrastructure owner needs to act on.
A good report includes:
Host identity:
hostname, instance ID, cloud account, cluster, namespace, owner
Kernel state:
running kernel, installed kernel packages, fixed vendor version, reboot status
Exposure:
AF_ALG availability, algif_aead module status, seccomp status for untrusted workloads
Risk context:
multi-tenant host, CI runner, sandbox, Kubernetes node, developer workstation, production server
Compensating controls:
module blacklist, seccomp profile, privileged container restrictions, runner isolation
Validation:
patched kernel confirmed after reboot, old vulnerable nodes drained, images rebuilt
Residual risk:
systems awaiting maintenance, unsupported releases, vendor pending states, exceptions
Evidence:
command output, timestamps, package logs, screenshots, SIEM query IDs, ticket links
This format works because it separates vulnerability identity from operational exposure. Two hosts can have the same CVE and very different urgency. A public web server with no local users but a history of web RCE exposure is different from a shared Jupyter environment where users intentionally run arbitrary code. A CI runner with production deployment tokens is different from a disposable test VM.
Common mistakes during response
One mistake is patching only production servers while ignoring CI and build infrastructure. Attackers love build systems because they often have credentials, network access, and weak isolation. Copy Fail should push CI runner patching near the top of the list.
Another mistake is patching Kubernetes worker nodes without rotating them. If the old kernel remains active, the node is still vulnerable. In managed clusters, the safest route is often to roll node pools onto a fixed image, drain old nodes, and confirm new nodes are running the expected kernel.
A third mistake is assuming RuntimeDefault seccomp always blocks the needed interface. Kubernetes documentation is clear that runtime defaults differ between container runtimes and versions. (Kubernetes) Check your actual runtime behavior.
A fourth mistake is treating exploit non-persistence as low risk. Page-cache corruption may not survive reboot, but root-level actions taken during the window can persist through other mechanisms.
A fifth mistake is waiting for a perfect detection rule before patching. Detection is useful, but patching removes the vulnerable path. For this class of bug, patch state is the primary control.
A hardened baseline after patching
After patching, use Copy Fail as a reason to improve the Linux local execution boundary.
For shared hosts:
Remove unnecessary local accounts
Use least-privilege sudo rules
Reduce setuid binaries where possible
Disable unused kernel interfaces
Apply seccomp or service sandboxing to risky daemons
Monitor unusual local privilege transitions
For containers:
Avoid privileged containers
Avoid Unconfined seccomp profiles
Use RuntimeDefault as a baseline
Use Localhost profiles for high-risk workloads
Block kernel interfaces not required by the application
Avoid broad hostPath mounts
Rotate nodes after kernel patching
For CI:
Use ephemeral runners for untrusted code
Separate trusted and untrusted job pools
Avoid long-lived credentials on runners
Use short-lived OIDC tokens where possible
Patch runner images and host kernels
Destroy runners after high-risk jobs
Preserve job logs for investigation
For developer workstations:
Patch quickly
Avoid running untrusted build scripts on the host
Use disposable VMs or containers for unknown dependencies
Keep secrets out of general shell environments
Use separate environments for research, production access, and browsing
These controls are not Copy-Fail-specific. They reduce the value of local code execution in general.
How to think about severity
The CVSS score is useful but not enough. SUSE’s page shows differences between CNA and SUSE scoring, including a 7.8 CVSS v3.1 score from the CNA and a lower SUSE assessment for some views. (suse.com) That kind of difference is normal because vendors may weigh exploitability, affected products, configuration, or environmental assumptions differently.
For prioritization, use three questions:
Can an attacker run low-privilege code here?
Can that code reach AF_ALG and the vulnerable kernel path?
Would root on this host materially expand attacker access?
If the answer to all three is yes, treat the system as high priority regardless of whether the vulnerability is “local only.”
CI runners, shared Linux hosts, Kubernetes nodes, and code execution platforms usually answer yes to all three. Single-user systems may answer yes only if the user runs untrusted code. Production servers may answer yes if they have exposed services that could lead to web RCE, local plugin execution, database UDF execution, notebook execution, or compromised service accounts.
The deeper lesson, kernel attack surface is often compositional
Copy Fail is not best understood as “crypto bug” or “splice bug” or “page cache bug.” It is a composition bug.
splice() preserves page provenance for performance. AF_ALG exposes kernel crypto operations to userspace. algif_aead tried to optimize by operating in-place. authencesn used destination memory for scratch space. The exploit path emerges when those design choices meet.
That is why cross-subsystem review matters. Many security reviews inspect code inside one subsystem. Attackers often win at the boundaries. They ask questions like:
Can a page from subsystem A enter subsystem B by reference?
Does subsystem B treat it as writable?
Does subsystem C write outside the region subsystem B expected?
Does a later subsystem consume the modified state as trusted?
Those questions are hard to answer with pattern matching alone. They require provenance tracking, invariant reasoning, and an understanding of how performance optimizations change object ownership.
Copy Fail is a useful case study because the final primitive is small but the violated assumption is large: data that came from a readable file-backed page should not become writable crypto output just because it passed through a zero-copy path.
Final remediation checklist
Use this as a practical closeout list.
1. Identify every Linux host, VM image, container node, CI runner, sandbox, and developer base image.
2. Check the vendor advisory for the exact distribution release and kernel package.
3. Install the fixed kernel package.
4. Reboot or live patch where officially supported.
5. Confirm the running kernel after reboot.
6. Remove or de-prioritize old vulnerable kernels from bootloader defaults.
7. Rebuild golden images, AMIs, VM templates, and runner images.
8. Rotate Kubernetes node pools onto fixed images.
9. Apply temporary AF_ALG or algif_aead restrictions only where compatibility testing passes.
10. Remove privileged and unconfined container configurations from untrusted workloads.
11. Add monitoring for unexpected AF_ALG socket usage on high-risk systems.
12. Review CI jobs, shared hosts, and sandbox environments for suspicious root transitions during the exposure window.
13. Document evidence and exceptions.
14. Keep tracking vendor advisories because fixed package status can change by release.
Copy Fail is dangerous because it turns a narrow kernel write into a privilege boundary failure. The fix is not mysterious: patch the kernel, reduce unnecessary kernel interface exposure, and harden the places where untrusted local code runs. The engineering lesson is sharper: performance shortcuts that preserve references across subsystem boundaries must be treated as security-sensitive design decisions.
Leitura adicional e referências
Copy Fail public disclosure page. (Xint)
Xint technical write-up on Copy Fail and CVE-2026-31431. (xint.io)
NVD record for CVE-2026-31431. (NVD)
oss-security disclosure thread for CVE-2026-31431. (openwall.com)
Linux kernel documentation for the userspace crypto API and AF_ALG. (docs.kernel.org)
Linux splice() manual page. (man7.org)
Oracle Linux analysis of pipe and splice implementation. (Oracle Blogs)
Docker documentation on seccomp profiles. (Docker Documentation)
Kubernetes documentation on seccomp profiles. (Kubernetes)
Linux kernel documentation on seccomp filtering. (docs.kernel.org)
Debian security tracker for CVE-2026-31431. (Debian Security Tracker)
SUSE CVE page for CVE-2026-31431. (suse.com)
CloudLinux advisory note on CVE-2026-31431 and KernelCare status. (cloudlinux.zendesk.com)
Penligent write-up on local Linux privilege escalation risk in Pack2TheRoot. (penligent.ai)
Penligent guide to installing Penligent in Kali Linux. (penligent.ai)
Penligent article on vertical and horizontal privilege escalation. (penligent.ai)