Casamento de escala com prova
A automação agêntica mudou a forma como exploramos as superfícies de ataque. Ela se destaca pela amplitude - reconhecimento rápido, geração de hipóteses e enumeração escalonável - mas raramente produz cadeias de exploração com grau de evidência que resistam à revisão da equipe azul ou ao escrutínio executivo. O teste manual tradicional é o oposto: ele é excelente em interpretação, julgamento contraditório e clareza narrativa, mas tem dificuldade para cobrir o perímetro extenso e em constante mudança dos aplicativos modernos e das propriedades de nuvem. O caminho prático a seguir não é "humanos versus IA", mas humano no circuito (HITL) agentes: permitir que os agentes forneçam velocidade e cobertura de superfície sob grades de proteção explícitas e que os especialistas sejam responsáveis pela validação, pelo contexto e pela responsabilidade. Na prática, um agente humano no loop ferramenta de pentest de IA Penligent A implantação se parece com isso: orquestração com base em políticas, ferramentas em nível de intençãoe relatórios com base em evidências que se destaca em auditorias e retrospectivas de incidentes.

O que a HITL realmente significa (além de um pop-up de sim/não)
Um sistema de pentesting de HITL não é uma caixa de diálogo de última hora do tipo "Tem certeza?" inserida em um fluxo de trabalho autônomo. Ele é um orquestração projetada em que intenções confidenciais - sondagem ativa, execução de exploit, gravação de arquivos, simulação de vazamento de dados ou saída - são negar por padrãoe cada aprovação traz restrições (limites de taxa, caminhos listados como permitidos, condições de parada, janelas de tempo e regras de tratamento de dados). Cada comando, parâmetro, detalhe de ambiente, saída bruta, captura de tela/papel, identidade do revisor e nota de revisão são mantidos como um cadeia de evidências forenses. Os relatórios são regenerável a partir dos primeiros princípiosSe você excluir a descrição e reconstruir a partir das evidências, deverá obter as mesmas conclusões. As conclusões são mapeadas para MITRE ATT&CK TTPs; etapas de verificação alinhadas com OWASP ASVS controles; e artefatos de processo (aprovações, registros de alterações, segregação de funções) atendem NIST SSDF. É assim que você passa do "escaneamento assistido por IA" para prática de engenharia defensável.
Arquitetura: Políticas em primeiro lugar, ferramentas abstraídas, evidências sempre
Um design sustentável se divide em três camadas:
- Camada de proteção (policy-first): Codifique os pontos de controle para intenções de alto risco como negação por padrão com aprovações estruturadas. Uma aprovação não é apenas um "sim/não"; é um contrato que especifica o que o agente pode fazer e sob quais restrições. As aprovações devem ser versionadas, atribuídas a um revisor e registradas com carimbos de data e hora, identificadores de escopo e ganchos de revogação.
- Camada de ferramentas (verbos em nível de intenção): Envolva scanners e assistentes - Nmap, ffuf, sqlmap, nuclei, APIs do Burp Suite, automação do navegador, auxiliares OSINT - por trás de verbos como
dir_bruteforce,param_fuzz,sqli_detect,xss_probe,login do rastreador. Analisar suas saídas em um tipo bem definido, registros estruturados (JSON) para que os agentes possam raciocinar de forma confiável e os relatórios possam reutilizar as evidências sem a roleta de regex. Normalize os estados de "sucesso/falha/incerto" para evitar uma lógica de cadeia frágil. - Camada de evidência (grau forense): Correlacione comandos, versões, ambiente, resultados, capturas de tela, pcaps e identidades de revisores. Considere cadeias de hash ou assinatura para proteger a integridade e permitir a procedência do relatório. As evidências devem ser consultáveis: "mostre-me todos os POCs para
T1190nesse escopo nos últimos 30 dias" deve ser uma única consulta, não uma pesquisa arqueológica.
Em resumo: A velocidade vem dos agentes, a certeza vem dos seres humanos, a defensibilidade vem das evidências.
Do sinal à prova: uma cadência de trabalho escalonável
Um fluxo de trabalho HITL robusto progride de ampla descoberta para execução limitada para relatórios defensáveis:
- Descoberta: Os agentes varrem superfícies com ações somente de leitura ou de baixo impacto. Eles geram candidatos (caminhos interessantes, parâmetros suspeitos, respostas anômalas) e agrupam sinais para reduzir a fadiga do pesquisador.
- Interceptação: As portas de aprovação interceptam intenções confidenciais. Um revisor humano adiciona restrições - taxa ≤ 5 rps, abortar em 403/429, limitar caminhos para
/api/*(por exemplo, redigir tokens de registros, não permitir a gravação fora de um diretório temporário) e anexar o contexto comercial ("este é um aplicativo de PII regulamentado; evite operações de dados em massa"). - Execução restrita: Os agentes prosseguem dentro do contrato concedidoO sistema de controle de qualidade é um sistema de controle de qualidade que captura tudo o que é necessário para reproduzir os resultados: vetores de entrada, pré-condições de ambiente, registros de data e hora e artefatos de saída.
- Regeneração de relatórios: O relatório final é explicável (vinculado ao impacto nos negócios), reproduzível (evidência → relatório), e alinhado ao padrão (ATT&CK/ASVS/SSDF). Sua equipe azul pode criar detecções a partir dele; seus desenvolvedores podem criar testes a partir dele; sua liderança pode tomar decisões de risco a partir dele.
Loop mínimo de aprovação do HITL
Abaixo está um padrão mínimo.interrupção de políticas → aprovação humana → execução restrita → persistência de evidências-que você pode incorporar em um orquestrador personalizado ou LangGraph/LangChain. Ele é intencionalmente compacto, mas completo o suficiente para ser executado e ampliado.
import json, subprocess, time, uuid, hashlib, os
from datetime import datetime
APPROVALS = {
"RUN_EXPLOIT": {"require": True, "reason": "Ação impactante"},
"SCAN_ACTIVE": {"require": True, "reason": "Pode acionar WAF/IPS"},
"WRITE_FILE": {"require": True, "reason": "Mutação do sistema de arquivos"},
"EGRESS_CALL": {"require": True, "reason": "Saída de rede externa"},
"READ_ONLY": {"require": False (falso), "reason" (motivo): "Safe intent"},
}
EVIDENCE_DIR = "./evidence" # substituir pelo armazenamento de objetos na produção
os.makedirs(EVIDENCE_DIR, exist_ok=True)
def needs_approval(intent: str) -> bool:
meta = APPROVALS.get(intent, {"require": True})
return bool(meta["require"])
def open_review_ticket(intent, cmd, context):
ticket = {
"id": str(uuid.uuid4()),
"intent": intent,
"cmd": cmd,
"context": contexto,
"status": "PENDING",
"created_at": datetime.utcnow().isoformat() + "Z",
}
# TODO: enviar para o Slack/Discord/Web UI
ticket de retorno
def await_decision(ticket, timeout=1800):
# Em produção: pesquise o armazenamento de decisões; aqui simulamos a aprovação com restrições.
start = time.time()
while time.time() - start dict:
proc = subprocess.run(cmd, capture_output=True, text=True)
return {"rc": proc.returncode, "stdout": proc.stdout, "stderr": proc.stderr}
def persist_evidence(payload: dict) -> str:
raw = json.dumps(payload, sort_keys=True).encode()
digest = hashlib.sha256(raw).hexdigest()
path = os.path.join(EVIDENCE_DIR, f"{digest}.json")
with open(path, "wb") as f:
f.write(raw)
return path
def hitl_execute(intent: str, cmd: list[str], context: dict) -> dict:
contract = None
if needs_approval(intent):
ticket = open_review_ticket(intent, cmd, context)
decision = await_decision(ticket)
se decision["status"] != "APPROVED":
return {"status": "BLOCKED", "ticket": ticket}
contract = decision["constraints"]
# Opcional: aplicar restrições localmente (por exemplo, injetar sinalizador de taxa na ferramenta)
se contract e "rate" estiverem em contract e "-rate" não estiver em cmd:
cmd += ["-rate", str(contract["rate"])]
resultado = run_tool(cmd)
evidence = {
"intent": intent,
"cmd": cmd,
"context": contexto,
"result": resultado,
"attck": "T1190", # Exploração de aplicativo voltado para o público
"asvs": "V2", # Autenticação/gerenciamento de sessão (exemplo)
"ts": datetime.utcnow().isoformat() + "Z",
"reviewer": contrato e "sec.researcher@example.com",
}
path = persist_evidence(evidence)
return {"status": "DONE", "evidence_path": path, "sha256": os.path.basename(path).split(".")[0]}
# Exemplo: descoberta ativa cautelosa com ffuf (limitada pela aprovação)
se __name__ == "__main__":
response = hitl_execute(
"SCAN_ACTIVE",
["ffuf", "-w", "wordlists/common.txt", "-u", "https://target.example/FUZZ"],
{"scope": "https://target.example", "note": "stop on 403/429"}
)
print(json.dumps(response, indent=2))
Por que isso é importante: as aprovações são contratos, as restrições são aplicável por máquinae as evidências são inviolável. Agora você pode criar uma geração de relatórios que transforma deterministicamente as evidências em uma narrativa; se a narrativa se desviar das evidências, sua criação será interrompida.exatamente o que você deseja.
Modos de operação: escolhendo o equilíbrio certo
| Dimensão | Somente para humanos | Somente IA | Agentes HITL (recomendado) |
|---|---|---|---|
| Cobertura da superfície | Médio-Baixo | Alta | Alta |
| Profundidade da validação e contexto comercial | Alta | Baixo-Médio | Alta |
| Falsos positivos/abrangência | Baixa | Médio-Alto | Baixo-Médio (governado) |
| Auditabilidade e mapeamento de padrões | Médio | Baixa | Alta |
| Cenários ideais | Provas de alto risco e de caixa cinza profunda | Descoberta de massa | Testes contínuos + POCs verificáveis |
O HITL otimiza para determinismo sob governança. Os agentes são executados rapidamente, mas dentro de trilhos; os humanos decidem o que conta como prova e como comunicar o impacto. A combinação proporciona produtividade sem perder credibilidade.
Alinhamento de padrões que reduz o atrito
Tratar os padrões como coluna vertebral de seus produtos, e não um apêndice:
- MITRE ATT&CK: mapear atividades e descobertas para TTPs concretos, de modo que as detecções e os exercícios da equipe roxa sejam as próximas etapas óbvias.
https://attack.mitre.org/ - OWASP ASVS: ancorar a verificação para controlar as famílias e preencher cada item com evidências reproduzíveis e etapas de repetição.
https://owasp.org/www-project-application-security-verification-standard/ - NIST SSDF (SP 800-218): capturar aprovações, cadeias de evidências e segregação de funções como artefatos de processo alinhados às práticas de desenvolvimento seguro.
https://csrc.nist.gov/pubs/sp/800/218/final
Com esse alinhamento, seu relatório se torna um interface bidirecionalA engenharia o utiliza para corrigir, os defensores para detectar e os auditores para verificar.
Onde Penligente Pertence ao Loop
Quando você implanta um agente humano no loop ferramenta de pentest de IA PenligentEm um ambiente de negócios, duas funções compõem consistentemente o valor:
- Guardrails como um recurso de plataforma. Os agentes orquestrados da Penligent operam dentro aprovações explícitas, listas de permissão/negação e regras de escopo/taxa. Intenções sensíveis como
RUN_EXPLOIT,WRITE_FILEouEGRESS_CALLsão acionados por interrupção e exigem contratos com revisores. Todas as linhas de comando, versões de ferramentas e saídas são normalizadas para o armazenamento de evidências, prontas para regeneração e auditoria. - Da descoberta à história defensável. Os agentes fazem uma ampla varredura e elaboram rascunhos; os pesquisadores validam POCs, vinculam a exploração a impacto nos negóciose fornecer relatórios que mapeiem de forma clara para ATT&CK/ASVS/SSDF. Essa divisão de trabalho transforma o escaneamento ad-hoc em capacidade de repetição. Se o seu ambiente exige residência estrita de dados ou testes off-line, o Penligent's local primeiro permite que você coloque em prática os recursos com segurança e os expanda à medida que a confiança aumenta.
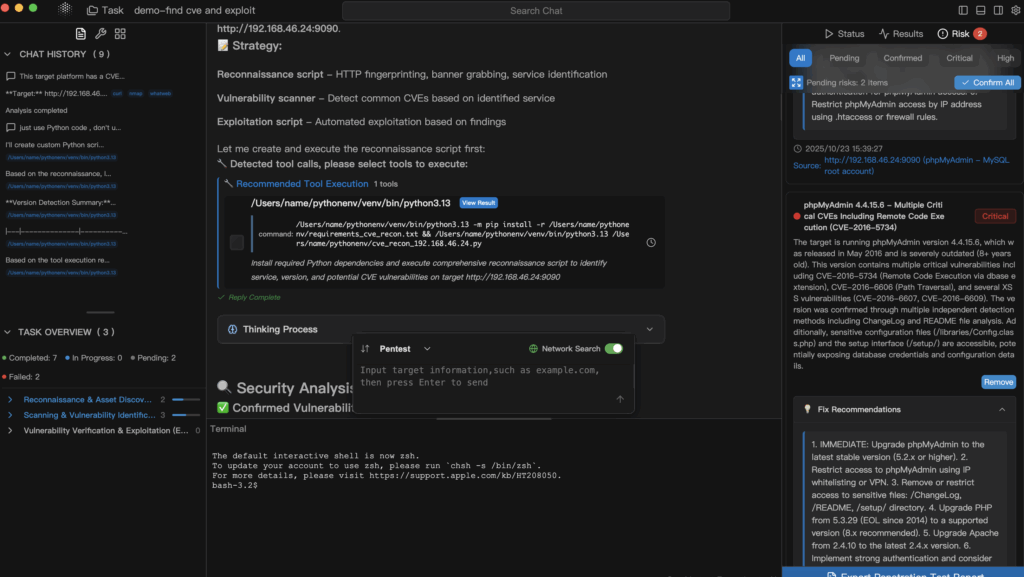
Padrões práticos e antipadrões
Faça:
- Versão tudo: prompts, imagens de ferramentas, listas de palavras e taxas. A reprodutibilidade morre sem pinos de versão.
- Proteger a automação do navegadorOs agentes precisam de introspecção de DOM, síntese de eventos, disciplina de armazenamento/cookie e interceptação de rede para evitar pontos cegos no lado do cliente.
- Dimensione corretamente as evidênciasCapture o suficiente para reproduzir e provar o impacto; criptografe em repouso; alinhe a retenção com a política; elimine segredos por padrão.
Evitar:
- Câmaras de eco de automaçãoO que é um loop de vários agentes: os loops de vários agentes podem ampliar as classificações incorretas iniciais. Os pontos de controle estratégicos de HITL quebram a cadeia e forçam a reanexação à verdade básica.
- Análise somente de RegexPreferem adaptadores estruturados com validação de esquema; alimentam os agentes com evidências normalizadas, não com registros brutos.
- "Alegações "provavelmente vulneráveisSem um POC reproduzível e um impacto mapeado, você está criando ruído, não segurança.
Lista de verificação de implementação (copiar/colar em seu runbook)
- Negar por padrão para
RUN_EXPLOIT,WRITE_FILE,EGRESS_CALL,SCAN_ACTIVEAs aprovações devem incluir escopo, taxae condições de parada. - Retorno das interfaces de ferramentas estruturado registros; os analisadores são testados em relação a registros reais e versões de ferramentas fixadas.
- As evidências são assinado ou hash-chained; os relatórios são regenerado de evidências como parte da CI para seus artefatos de segurança.
- Os resultados mapeiam para ATT&CK TTPs; citações de verificação ASVS itens; os artefatos do processo satisfazem SSDF.
- A automação do navegador abrange fluxos de autenticação, roteamento de SPA, comportamentos de CSP/CORS; a revisão de HITL é obrigatória para qualquer alteração de estado.
- Prompts, versões de ferramentas, listas de palavras e taxas são fixado e com versãoAs alterações passam pelo mesmo rigor de aprovação que o código.
Velocidade, certeza e governança
O padrão durável é simples e poderoso: Velocidade = agentes; certeza = humanos; governança = padrões + evidências. Quando esses três fecham o ciclo em um orquestrador auditável, agente humano no loop ferramenta de pentest de IA Penligent deixa de ser uma palavra da moda. Ela se torna uma capacidade repetível e defensável-Um que seus desenvolvedores possam corrigir, seus defensores possam detectar, seus auditores possam verificar e sua liderança possa confiar.
- MITRE ATT&CK - https://attack.mitre.org/
- OWASP ASVS - https://owasp.org/www-project-application-security-verification-standard/
- NIST SSDF (SP 800-218) - https://csrc.nist.gov/pubs/sp/800/218/final

