Attackers do not need a perfectly enriched vulnerability database to get started anymore. They need a codebase, a model, a narrow hypothesis, and a way to test feedback quickly. Google’s public Big Sleep work showed an AI agent finding a previously unknown exploitable SQLite issue before release, and Google now openly states that AI is likely to accelerate reconnaissance, vulnerability discovery, and exploit development. At the same time, NIST has acknowledged that the National Vulnerability Database can no longer enrich every CVE the way many teams had come to expect after CVE submissions rose 263% between 2020 and 2025 and kept climbing in early 2026. That combination is the real backdrop to NIST CVE prioritization. (projectzero.google)
That is why this moment feels less like a routine process tweak and more like asymmetric warfare. The offensive side increasingly gets help compressing the front half of the kill chain: variant hunting, exploit hypothesis generation, endpoint probing, and proof-of-concept drafting. The defensive side still has to answer slower questions that are tied to real systems: do we run the affected product, is the vulnerable feature reachable, is the exposed instance internet-facing, is a patch available, what breaks if we apply it, who owns the service, and how do we prove the risk is closed after remediation. AI is cheapening discovery faster than organizations are speeding up verification and remediation. Google Cloud and OpenAI are both already framing the next phase of cyber defense around exactly that pressure point. (Google Cloud)
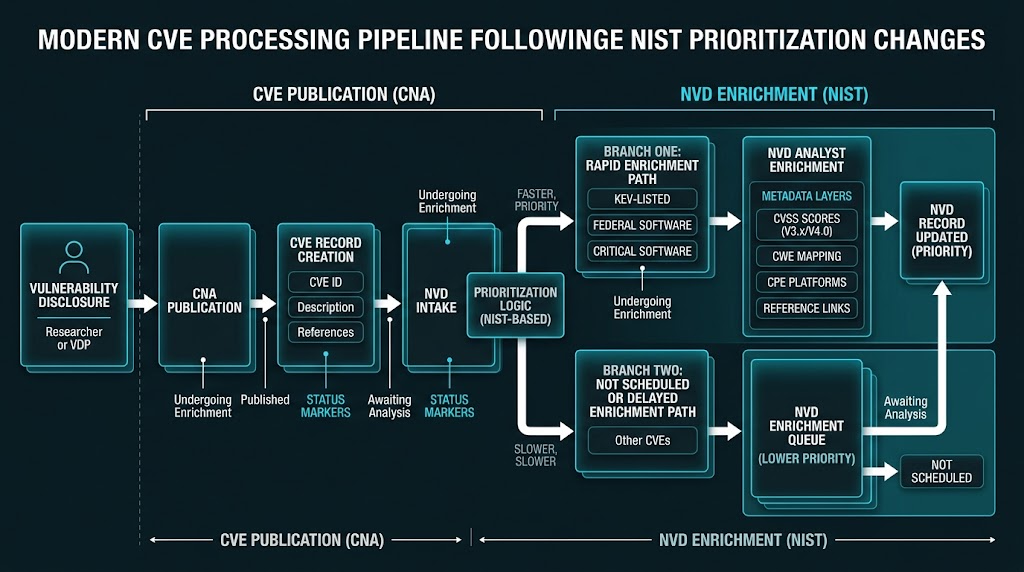
NIST’s change matters because it forces the industry to admit what many teams were already experiencing privately. Vulnerability management cannot run on the old assumption that a central public database will score, classify, and product-map everything in time for your patch cycle. NIST now says plainly that the NVD will prioritize enrichment for CVEs in CISA’s Known Exploited Vulnerabilities catalog, CVEs affecting software used by the federal government, and CVEs affecting critical software as defined under Executive Order 14028. CVEs outside those buckets still enter the NVD, but many will not get immediate enrichment, and backlogged CVEs published before March 1, 2026 are being moved to the Not Scheduled category. (NIST)
The important point is that NIST did not declare CVEs unimportant. It declared scale unmanageable under the old enrichment model. NIST says submissions in the first three months of 2026 were nearly one-third higher than the same period a year earlier, and that it enriched nearly 42,000 CVEs in 2025, more than any prior year, yet still could not keep pace. In other words, the public data layer is now signaling what frontline defenders already know: discovery volume is outrunning centralized analysis capacity. AI is one reason that gap is becoming harder to close. (NIST)
AI vulnerability discovery is creating a new asymmetry
The strongest public evidence is no longer theoretical. In November 2024, Project Zero published that Big Sleep had found an exploitable stack buffer underflow in SQLite, a widely used open-source database engine, before the issue made it into an official release. Project Zero also said it believed this was the first public example of an AI agent finding a previously unknown exploitable memory-safety issue in widely used real-world software. That does not mean AI has replaced human vulnerability researchers or purpose-built fuzzers. Project Zero was careful to say the results were still experimental, and that a target-specific fuzzer could still be at least as effective. But it does mean the old assumption that meaningful vulnerability research always requires a large human time budget is already under strain. (projectzero.google)
The detail that matters is not just that Big Sleep found a bug. It is how the research reframed the economics of variant analysis. Project Zero described a workflow in which the agent used prior bug context, repository state, and tool-assisted testing to reason toward a new issue that conventional fuzzing had not caught. Google’s own write-up explicitly said this kind of approach has defensive potential because it can find vulnerabilities before attackers get a chance to use them. That is the first half of the asymmetry: AI is making some forms of discovery, especially bounded discovery, cheaper. (projectzero.google)
Google’s later materials push the same theme forward. Its 2024 security blog on AI-powered fuzzing described more than a year and a half of work to bring AI into fuzz target generation and developer-like workflows, with the stated goal of transforming vulnerability discovery. In 2025, Google said Big Sleep had made what it believed was the first AI-assisted intervention that directly foiled exploitation in the wild. In its 2026 zero-day review and its enterprise defense guidance, Google went further and said it expected AI to accelerate reconnaissance, vulnerability discovery, and exploit development, while creating a critical window of risk as defenders race to harden software faster than attackers can weaponize new findings. (Google Online Security Blog)
OpenAI’s public materials point to the same operational pressure from another angle. OpenAI’s Trusted Access for Cyber announcement says AI is being used by attackers as well as defenders and argues that advanced coding and agentic capabilities need to shift security from episodic audits to continuous identification, validation, and fixing of issues during development. Its Codex Security launch makes the bottleneck even more explicit, arguing that agents are accelerating software development while security review becomes the critical choke point, and positioning the product around system context, prioritization, validation, and patches rather than raw bug volume. The message from both vendors is consistent: the hard part is no longer only finding candidates. It is separating real risk from noise quickly enough to matter. (OpenAI)
That distinction matters for security leaders because it changes where advantage comes from. A decade ago, a lot of advantage came from having rare specialists who could manually uncover subtle flaws or chain weak signals into exploit paths. That still matters. But now advantage increasingly comes from compressing the time between first signal and defensible action. If a model can help find a candidate vulnerability or a likely exploit path in minutes, the team that wins is the one that can confirm scope, validate exploitability, prioritize exposure, and apply or verify mitigation before the candidate becomes someone else’s intrusion path. That is not a severity problem. It is a tempo problem. (Google Cloud)
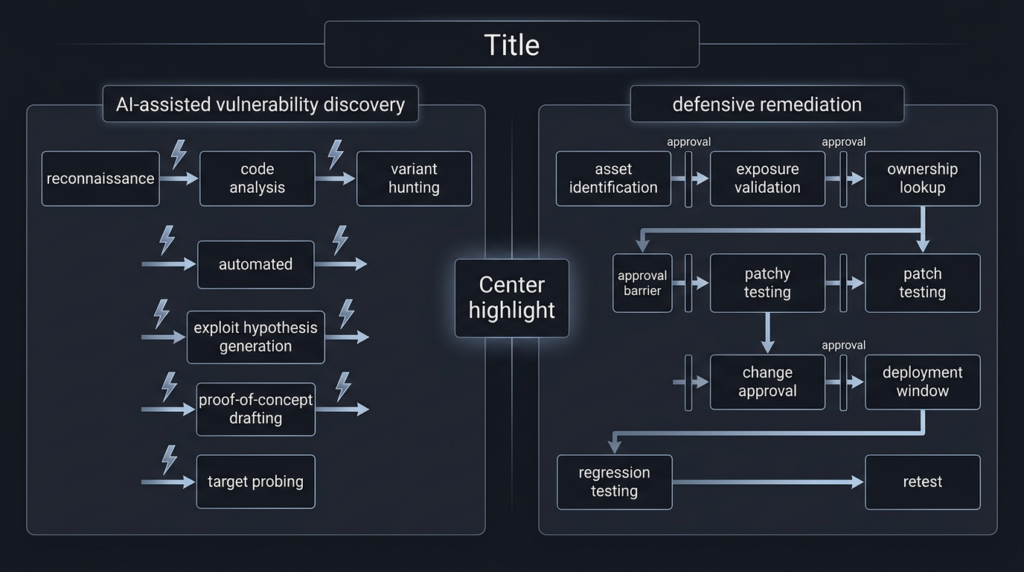
NIST CVE prioritization is a symptom, not the root cause
NIST’s April 15, 2026 update should be read as an operational admission, not just a policy announcement. NIST says that in the past the NVD aimed to analyze all CVEs and add details such as severity scores and product lists so security professionals could prioritize and mitigate vulnerabilities. Going forward, it will enrich only CVEs meeting defined criteria. That is a large change in default assumptions for the entire industry, because countless security workflows implicitly treated NVD enrichment as the normalized starting point for prioritization. (NIST)
The new criteria are straightforward. NIST will prioritize CVEs in CISA’s Known Exploited Vulnerabilities catalog, CVEs for software used within the federal government, and CVEs for critical software under Executive Order 14028. NIST’s own process page adds an important operational detail: CVEs published to the CVE List are typically available in the NVD within an hour, but enrichment time varies based on information availability and publication volume. In other words, publication and enrichment are now clearly separate phases. A CVE can be real, public, and operationally urgent before NVD has completed all the scoring and product-matching that downstream tools may be expecting. (NIST)
The new status model makes that separation visible. NVD’s vulnerability status page says “Not Scheduled” means a CVE is not currently scheduled for NVD enrichment and may have fallen outside NVD’s declared scope or not been prioritized due to resource or other concerns. Users can request enrichment, but the default assumption is no longer that every published CVE will promptly receive NVD’s full attention. That is a major shift for anyone who built dashboards, SLAs, or ticket routing rules on the assumption that missing NVD fields were temporary exceptions rather than a normal state. (nvd.nist.gov)
The numbers make the shift hard to ignore. NIST says submissions increased 263% between 2020 and 2025, and the first quarter of 2026 ran nearly one-third higher than the same period the year before. The NVD dashboard at the time of writing showed 345,254 CVE vulnerabilities in the database, and search results for the dashboard showed more than 100,000 CVEs in Not Scheduled status. The precise status count will move over time, but the scale is what matters. The queue is not a temporary inconvenience. It is now a structural feature of the ecosystem. (NIST)
NIST also changed how it treats scoring. It says it will no longer routinely provide a separate severity score when the CVE Numbering Authority already supplied one, and it will reanalyze modified CVEs only when a change materially affects enrichment data. That is rational from a workload perspective, but it pushes more responsibility back to the consumer. Security teams now have to understand what came from the CNA, what came from the NVD, what came from an Authorized Data Publisher, and what never arrived at all. The old habit of treating “NVD score present” as the beginning of seriousness is not going to survive this environment. (NIST)
CVE, NVD, CVSS, KEV, and EPSS answer different questions
The first repair most programs need is conceptual. CVE, NVD, CVSS, KEV, and EPSS are related, but they are not interchangeable. NVD’s own status page says vulnerability records in the NVD dataset are sourced from the upstream CVE List, and its process page explains that the CVE program functions as the identifier dictionary while NVD provides enrichment such as reference tags, CVSS, CWE, and CPE applicability statements for in-scope records. A CVE tells you that a specific publicly disclosed vulnerability has a stable identifier. NVD tells you more about it when and if NVD enriches it. Those are not the same service. (nvd.nist.gov)
CVSS is also routinely misused. FIRST’s CVSS v4.0 specification describes CVSS as an open framework for communicating vulnerability characteristics and severity, with Base, Threat, Environmental, and Supplemental metric groups. That is extremely useful. It gives teams a shared language for discussing intrinsic properties and contextual modifiers. But even the structure of CVSS shows why it should not be confused with patch order by itself: the Base group speaks to intrinsic qualities, the Threat group changes over time, and the Environmental group depends on the user’s environment. A CVSS score is a severity communication tool, not a universal scheduling engine. (first.org)
KEV answers a different question: has this vulnerability been exploited in the wild strongly enough for CISA to treat it as a priority remediation input. NIST’s new policy is revealing here. It explicitly puts KEV at the front of the NVD queue and says its goal is to enrich KEV-listed CVEs within one business day of receipt. That is a practical acknowledgement that exploit reality beats generic severity when time is short. A medium-scored flaw with active exploitation often deserves more urgency than a theoretically critical flaw that is hard to reach in your environment. (NIST)
EPSS answers yet another question. FIRST describes EPSS as a machine-learning model that estimates the probability that a published CVE will be exploited in the wild within the next 30 days, with daily updates, scores from 0 to 1, and ranking percentiles. EPSS is not a replacement for impact analysis, but it is exactly the kind of empirical signal that becomes more valuable when the public enrichment layer is incomplete. If you have thousands of open vulnerabilities and limited patch windows, “how likely is exploitation soon” is a different and often more useful ranking question than “how severe is the bug in abstract.” (first.org)
CISA’s SSVC work fits the same practical mindset. Its SSVC calculator describes vulnerability prioritization as a decision-tree problem rather than a single-number problem. That is closer to how experienced defenders already think under pressure. They do not ask only, “What is the score?” They ask, “Is it exploited, is the system mission-relevant, is exploitation automatable, and what would compromise actually do here?” That is why the best vulnerability programs feel less like spreadsheet sorting and more like triage. (cisa.gov)
The distinctions are easier to see side by side:
| Sinal | What it answers best | What it does not answer by itself |
|---|---|---|
| CVE | Is this a publicly tracked vulnerability with a stable identity | Whether it matters to your estate this week |
| Enriquecimento de NVD | What references, CWE, CVSS, and product mapping are publicly associated | Whether the record is complete or timely enough for your workflow |
| CVSS v4 | How severe the vulnerability is in a structured scoring framework | Whether it is currently exploited or urgent in your environment |
| KEV | Whether there is credible evidence of active exploitation | Whether you are exposed to the affected product or feature |
| EPSS | How likely near-term exploitation is across the broader ecosystem | Whether compromise would be consequential in your environment |
| Asset context | Whether your systems make the bug reachable and valuable | Whether the broader ecosystem is exploiting it yet |
| Active validation | Whether the issue is exploitable or mitigated on your actual target | Whether the same CVE is broadly abused elsewhere |
That table reflects how FIRST defines CVSS and EPSS, how CISA treats exploited vulnerabilities, and how NVD now frames enrichment scope and statuses. The takeaway is simple: good prioritization is layered, not singular. (first.org)
SharePoint showed why exploit reality beats severity
A current Microsoft example makes the point more cleanly than any abstract argument. NVD’s record for CVE-2026-32201 describes improper input validation in Microsoft Office SharePoint that allows an unauthorized attacker to perform spoofing over a network. On the same page, the CVE is shown as undergoing reanalysis, NVD’s own assessment is listed as not yet provided, and the visible CVSS 3.x base score comes from Microsoft as the CNA at 6.5 Medium. If you were relying on the traditional “wait for NVD to settle, then score the patch queue” mindset, you could easily mistake this for a normal medium-severity workflow item. (nvd.nist.gov)
But that is not what the broader signal says. The NVD record itself shows the CVE was updated by CISA for KEV, and the search result for the KEV catalog shows the vulnerability was added on April 14, 2026 with a due date of April 28, 2026. The point is not that every federal due date should become your internal due date. The point is that reality moved first. The vulnerability was already serious enough in operational terms to enter the exploited set even while NVD’s own assessment field still showed N/A. Severity communication lagged behind exploitation relevance. (nvd.nist.gov)
That single record is a compact lesson in the post-2026 vulnerability workflow. A CVE can exist. It can be public. It can have a CNA-supplied score. It can be actively relevant enough for KEV. And it can still lack a completed NVD assessment. Teams that built their pipelines around “NVD score present equals ready to prioritize” are going to underreact to exactly the sort of issue that attackers care about most. In practice, the right response is to treat exploit evidence, exposed asset context, and vendor mitigation availability as first-class inputs the moment a record exists, not after NVD finishes its part. (nvd.nist.gov)
This is why NIST’s change should not be read as “the public database is broken, so prioritization is impossible.” It should be read as “the database is no longer pretending to be your whole prioritization engine.” The SharePoint example shows that exploit reality can outrun centralized enrichment. That is uncomfortable if your program is designed around clean upstream metadata. It is manageable if your program is designed around multiple signals and quick validation. (NIST)
Langflow showed how AI-native software can collapse time to exploitation
If SharePoint is the clean “severity is not priority” example, Langflow is the cleaner “AI-native software creates fast, attractive execution surfaces” example. GitHub’s advisory for CVE-2025-3248 says that Langflow versions prior to 1.3.0 were susceptible to code injection in the /api/v1/validate/code endpoint and that a remote unauthenticated attacker could send crafted HTTP requests to execute arbitrary code. That is already a severe enough statement on its own, but the follow-on signals matter even more: CISA’s KEV catalog search results show CVE-2025-3248 as a Langflow missing authentication vulnerability with a due date of May 26, 2025. This was not merely a speculative research curiosity. It became part of the exploited, urgent set. (GitHub)
The more important lesson is architectural. AI-native developer and workflow platforms increasingly expose features that are powerful by design: user-authored code, public flows, plugin execution, interpreter nodes, model orchestration, and external connectors. Those features are part of the product value. They also create dangerous boundaries when convenience, public sharing, and code execution overlap. For classic enterprise software, a lot of severe bugs still live in stale auth checks, path traversal, unsafe deserialization, or missing validation. AI-native systems often inherit those patterns and then add direct execution surfaces on top of them. That changes the speed at which a bug can go from report to meaningful compromise. (GitHub)
The 2026 Langflow case makes the point even more strongly. GitHub’s advisory for the later issue says the POST /api/v1/build_public_tmp/{flow_id}/flow endpoint allowed building public flows without authentication. When the optional dados parameter was supplied, the endpoint used attacker-controlled flow data containing arbitrary Python code in node definitions instead of stored database flow data, and that code was passed to exec() with zero sandboxing, resulting in unauthenticated remote code execution. CISA’s KEV search result shows CVE-2026-33017 was added on March 25, 2026 with a due date of April 8, 2026. Two related lessons follow. First, execution-oriented AI systems are a fertile place for high-value bugs. Second, patching one code-execution path does not guarantee the threat class is gone if the product still embeds the same trust assumptions elsewhere. (GitHub)
This is where the old severity mindset becomes actively misleading. A security team can spend days arguing whether one AI workflow bug is a 9.1 or a 9.8 and still miss the real operational question: do we expose this thing, who can reach it, what public sharing features are turned on, what interpreter or code-generation nodes are enabled, and can we verify exploitability on our own deployment right now. The product category itself tells you the attack surface is likely to be dynamic and feature-rich. That makes fast validation more important than elegant taxonomy. (GitHub)
The broader point extends beyond Langflow. As Google Cloud argues, general-purpose AI models can already be effective at vulnerability discovery, and as AI gets integrated into more products and workflows, there is a critical window in which attackers can use those same capabilities to discover and exploit flaws before the surrounding ecosystem has adapted. AI-native applications are not uniquely insecure by fate. But they often compress the path from feature misuse to meaningful compromise because their core functions already revolve around permissions, automation, external data, and execution. That makes them ideal examples of the wider asymmetry this article started with. (Google Cloud)
Big Sleep changed the way defenders should think about time
The Big Sleep example matters for another reason. It is easy to read it as a novelty story about AI doing clever code review. That misses the operational point. Project Zero explained that the system used prior vulnerability context and real repository state to reason toward a new exploitable issue in SQLite. It also noted that traditional fuzzing had not found the issue earlier and that more than 150 CPU-hours of AFL fuzzing did not rediscover it in their experiment. Project Zero did not say AI had replaced fuzzing. It did say current models, with the right tooling, can perform vulnerability research in real software. That should change how defenders think about attacker time budgets. (projectzero.google)
What used to require a specialist spending days or weeks reading diffs, checking historical bug classes, and designing test cases may increasingly be attempted by a much larger population armed with capable models and automated tooling. Even if those attempts are noisy, the cost of trying goes down. That matters because vulnerability discovery does not need to be universally excellent to change the threat landscape. It only needs to become somewhat cheaper at the margin for the population of plausible attackers. The offense does not need perfect model autonomy. It needs a lower cost per useful lead. Google’s own threat-intelligence materials now explicitly forecast that AI will create that pressure. (projectzero.google)
Defenders should also notice what the vendor responses are telling us. Google is putting public effort into AI-assisted discovery and defense. OpenAI is putting public effort into trusted cyber access and context-aware vulnerability discovery, validation, and patching. These are not vanity launches. They are market signals that the “finding candidate issues” step and the “triaging and fixing real issues” step are being pulled apart. The first is becoming more automatable. The second is becoming the differentiator. (Google Cloud)
That is the deeper meaning of NIST’s decision. Once vulnerability discovery and publication outpace centralized enrichment, your real bottleneck moves downstream. The question becomes: can your organization turn partial external information into a confident internal decision quickly enough. If the answer is no, then the speed of AI-assisted discovery on the outside will matter more than any individual improvement to scoring vocabulary on the inside. (NIST)
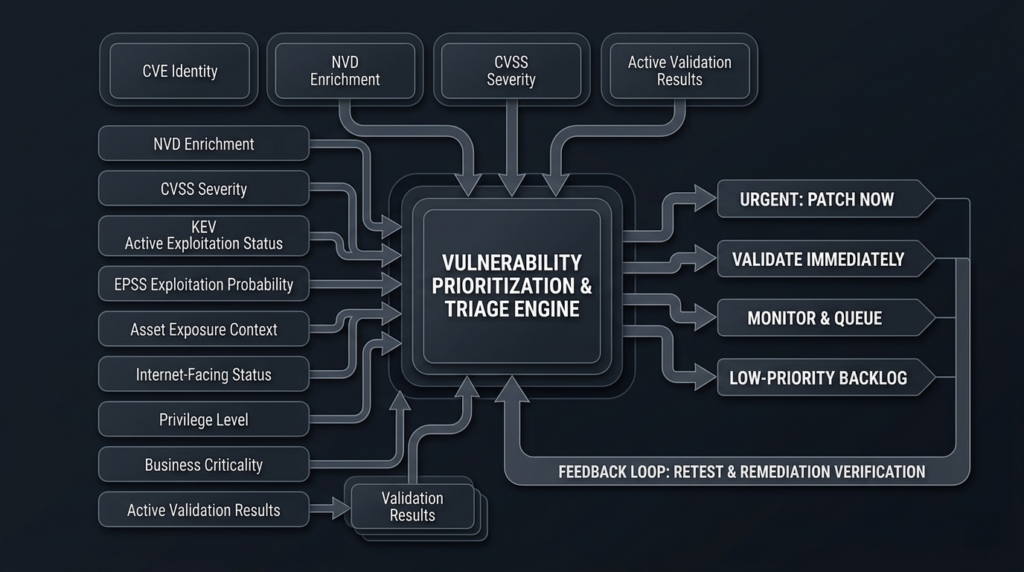
A prioritization stack that still works when NVD is incomplete
A workable 2026-era prioritization stack starts by separating identity, exploitability, exposure, consequence, and proof. Too many programs still collapse all five into one score or one ticket field. That was barely tolerable when the enrichment layer felt stable. It is not tolerable now. The better model is to ask a sequence of questions in order. Is the record real and attributable to a product or feature we care about. Is there evidence of real exploitation or high short-term exploit probability. Are we actually exposed in a reachable way. Would compromise matter on this asset. Can we validate exploitability or confirm mitigation in a controlled way. Each stage narrows uncertainty. (nvd.nist.gov)
In practice, that means using multiple sources with different jobs. The CVE record and vendor or GitHub advisory establish the vulnerability identity and basic facts. KEV tells you when a flaw has crossed into active-exploitation relevance. EPSS helps sort large pools of published CVEs by likely near-term exploitation. CVSS helps communicate severity in a standardized way. Internal asset data tells you whether the vulnerable component is internet-facing, privileged, secret-bearing, or business-critical. Active validation tells you whether the issue is actually exploitable on your target or already mitigated by architecture or controls. None of those layers can stand in for the others. (nvd.nist.gov)
The operational stack looks like this:
| Camada | Main question | Best sources |
|---|---|---|
| Identidade | What exactly is the vulnerability and affected product | CVE record, vendor advisory, GitHub advisory, CNA data |
| Exploit reality | Is it being exploited now or likely soon | KEV, EPSS, vendor incident notes, threat intel |
| Exposure | Can an attacker reach the vulnerable feature in my environment | CMDB, EASM, service inventory, config data |
| Consequência | What happens if this asset is compromised | Business criticality, privilege, secrets, blast radius |
| Proof | Is it exploitable here and is the fix effective | Controlled validation, retest, compensating control checks |
This is much closer to how SSVC-style decision thinking works, and it aligns with how NIST now separates publication from enrichment. When the upstream database is incomplete, the answer is not to give up on prioritization. The answer is to stop pretending one numeric field ever contained enough information to do the job. (cisa.gov)
A simple scoring policy can help as long as everyone agrees it is a queueing aid rather than a truth machine. For example, treat KEV as an automatic jump in queue. Use EPSS percentile to sort the next band of candidates. Add environmental weight for internet exposure, privileged placement, direct access to secrets, and business criticality. Then add a proof override: if you validate exploitability on a live or staging-equivalent target, the item jumps above the rest regardless of how pretty the public metadata looks. That will produce better patch queues than obsessing over whether a 7.5 should outrank an 8.1 in the abstract. (NIST)
Here is a deliberately simple model that captures that idea:
def priority(cve, asset):
score = 0
if cve["in_kev"]:
score += 100
score += round(cve["epss_percentile"] * 40)
if asset["internet_facing"]:
score += 30
if asset["privileged"]:
score += 20
if asset["has_sensitive_data"]:
score += 20
if asset["business_critical"]:
score += 15
if cve["vendor_patch_available"]:
score += 5
if cve["validated_on_target"]:
score = max(score, 180)
return score
That kind of model is intentionally blunt. It forces teams to surface the inputs they actually need instead of arguing endlessly over one public severity field. A mature implementation can add service ownership, maintenance windows, compensating controls, or exploit complexity. But the core lesson stays the same: prioritization improves when you add exploit signals and environment context, not when you chase more decimals in generic scoring. (first.org)
The data collection layer can also be lightweight at first. Many teams do not need a giant platform redesign to improve this quarter. They need a join. Pull CVEs from the sources you trust, map them to assets, overlay KEV and EPSS, then create a rapid validation lane for exposed or high-signal items.
curl -s "https://api.first.org/data/v1/epss?cve=CVE-2025-3248"
curl -s "https://services.nvd.nist.gov/rest/json/cves/2.0?cveId=CVE-2025-3248"
curl -s "https://www.cisa.gov/sites/default/files/csv/known_exploited_vulnerabilities.csv"
The code alone does not solve anything. The discipline of joining those feeds to your asset reality is what matters. NVD is now a piece of that answer, not the entire answer. (first.org)
Validation is now the bottleneck
This is the point where many vulnerability programs fall apart. They know how to ingest records and compute rankings, but they do not know how to answer the next question fast enough: is this exploitable here. OpenAI’s Codex Security announcement is unusually candid about this problem. It says context is essential when evaluating real security risk, that many AI security tools create triage burden through low-impact findings and false positives, and that the goal should be higher-confidence findings, validation, and actionable fixes. Even in code review, the bottleneck is shifting from raw detection to confident decision-making. The same pattern exists in infrastructure and application exposure management. (OpenAI)
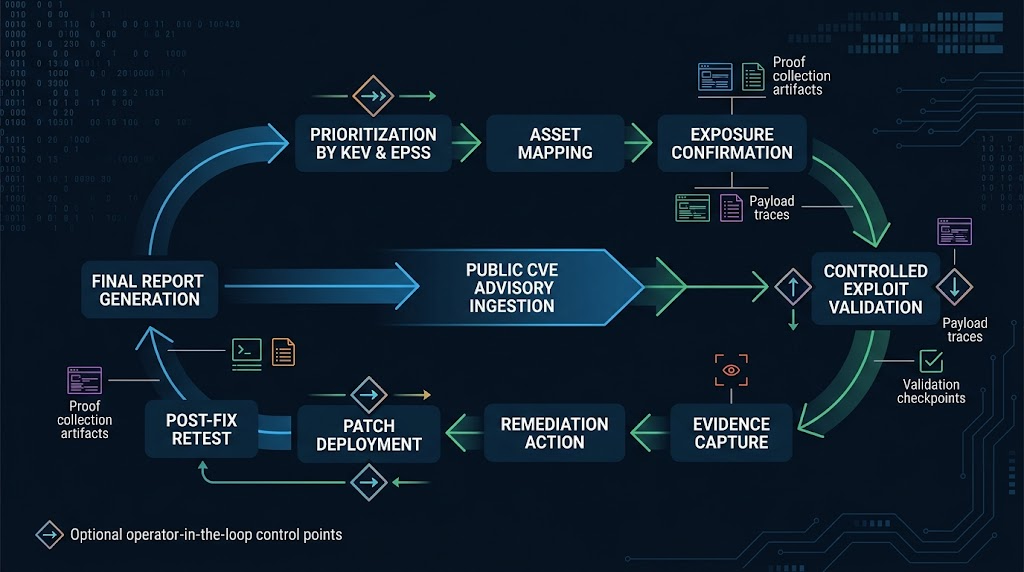
This is where controlled offensive validation becomes strategically valuable. The strongest public materials on Penligent describe a workflow where users can issue natural-language prompts, the system plans tasks, executes them, interprets outputs, and recommends next steps. Its public tool-comparison page describes the platform around CVE-focused scanning, verification, one-click PoC generation, editable reporting, Kali tool integration, and operator-controlled workflows. Whether a team chooses Penligent or another controlled validation stack, the underlying need is the same: shorten the path from “this CVE might matter” to “this service is actually affected, exploitable, and then confirmed fixed after remediation.” (penligent.ai)
That distinction is easy to miss if you have spent years buying more scanners. Scanners are good at telling you where to look. They are rarely enough to tell you which items deserve disruption, emergency change, or immediate executive escalation. Validation answers the last-mile questions that public metadata cannot. Is the vulnerable endpoint exposed through the real ingress path. Is the risky feature enabled. Does your authentication layer block the exploit path in practice. Did a WAF, reverse proxy, sandbox, or network policy already remove reachability. Did the patch really close the path, or did it only move it. Those are the questions that collapse queue size. (Google Cloud)
The irony is that AI makes this step both more urgent and more feasible. More urgent, because the external signal count rises and you cannot manually validate everything. More feasible, because operator-controlled agentic workflows can help translate advisories and public signals into repeatable probing, evidence capture, and retest logic. Penligent’s own overview describes project-based execution, result interpretation, and report generation mapped to CVE and CWE frameworks. That kind of design is useful not because it replaces prioritization, but because it gives prioritization a proof layer. In the AI era, proof is where patch queues become decisions instead of guesses. (penligent.ai)
Why patching still moves slower than discovery
Security teams sometimes talk about “faster patching” as if it were a pure discipline problem. Often it is an environment problem. Discovery is compressible because it can happen against code, advisories, diffs, and controlled targets in parallel. Remediation is slower because it touches ownership boundaries, maintenance windows, availability promises, compliance obligations, and regression risk. NIST’s own process description makes clear that enrichment itself involves mapping references, weaknesses, scores, and product applicability. Your internal remediation flow then has to add another layer that public databases can never solve: what this product means inside your environment. (nvd.nist.gov)
That is why the old phrase “just patch faster” is true but incomplete. The practical patch delay often does not come from ignorance that a CVE exists. It comes from uncertainty about whether the issue is reachable, whether the patch is safe, and whether the business can tolerate the change window. AI does not remove those constraints. In some ways it makes them more visible because it increases the number of plausible candidates that arrive before the organization is ready to validate or change production. If your internal process cannot answer “do we run this and does it matter” within hours for KEV-level or high-exposure items, you are already behind the pace the external ecosystem is moving toward. (NIST)
The best response is not panic patching of everything with a large number attached. It is faster narrowing. For exploited or high-signal vulnerabilities, aim to compress the time to four answers: affected or not, reachable or not, patched or mitigated, and retested or not. That is the real operational metric. NIST’s move away from universal enrichment makes those answers more visibly your responsibility, but they were always your responsibility in substance. What changed is that the public ecosystem no longer hides the gap for you. (nvd.nist.gov)
What security teams should change now
The first change is cultural. Stop treating “waiting for NVD” as a valid holding pattern for internet-facing or otherwise sensitive exposures. NVD still matters, but NIST now explicitly prioritizes only selected categories and allows many items to remain Not Scheduled unless they are requested or become higher priority. If a flaw touches exposed identity infrastructure, remote administration, public workflow engines, AI execution surfaces, or products in your critical path, your team needs a route to action before the enrichment layer is finished. (NIST)
The second change is data. KEV should be a required input, not a nice-to-have enrichment. EPSS should be present in every large-scale patch backlog. CVSS should still be recorded, but as one dimension rather than the entire queueing method. Service ownership and internet exposure must be queryable in the same place as vulnerability data. If your tooling cannot answer “which exposed assets run software affected by this KEV-listed CVE” without manual spreadsheet work, that is the process gap to fix first. (NIST)
The third change is workflow. Build a fast-lane for proof. That lane should include controlled validation, evidence capture, remediation verification, and re-test logic. It can be partly manual, partly scripted, partly agent-assisted. The exact product choice matters less than the design principle: the queue must narrow quickly through proof, not only through description. Public material from platforms like Penligent is useful here because it shows how CVE-focused verification, exploit generation, operator control, and editable reporting can be combined into one flow rather than split across disconnected tools. (penligent.ai)
The fourth change is language. Stop asking a single ranking question. Ask layered ones. Is it real. Is it exploited. Are we exposed. Does compromise matter. Have we validated or closed it. Teams that talk this way end up prioritizing better because they stop confusing taxonomy with urgency. That is the mindset NIST’s new model, FIRST’s EPSS language, and the current AI-driven market response are all converging on. (nvd.nist.gov)
The real meaning of NIST CVE prioritization
For security teams, the meaning is larger than one agency changing one workflow. NIST CVE prioritization is the public sign that the ecosystem has crossed a threshold. The volume of vulnerabilities and the speed of publication are now high enough that centralized enrichment cannot act like the universal front door to risk decisions. At the same time, AI is compressing the cost of vulnerability discovery, variant analysis, exploit hypothesis generation, and exploit-path exploration. Those two movements together create a structural mismatch. Offense gets faster sooner. Defense only gets safer if it learns to validate and remediate faster. (NIST)
That is why the right mental model is not “the database is worse now.” It is “the old workflow assumed more symmetry than the real world ever had.” Attackers never needed your dashboard to be complete. They needed one workable path. Defenders need to manage fleets, uptime, ownership, auditability, and proof. AI is helping both sides, but it is especially good at shrinking the discovery phase that used to consume a lot of offensive time. Unless organizations counter by shrinking the validation and remediation phase, the imbalance gets worse. (Google Cloud)
The programs that adapt will treat public vulnerability data as a layered signal system, not a finished verdict. They will use CVE for identity, NVD for enrichment when available, KEV for exploit reality, EPSS for probability, CVSS for structured severity, asset context for consequence, and active validation for proof. They will also accept that the last mile now matters more than ever: the distance between “known somewhere” and “confirmed here.” That is where patch queues become real defense. (nvd.nist.gov)
Leitura adicional
- NIST Updates NVD Operations to Address Record CVE Growth — the core announcement on the new prioritization model and backlog handling. (NIST)
- NVD Vulnerability Status — the official meanings of statuses such as Undergoing Enrichment and Not Scheduled. (nvd.nist.gov)
- CVEs and the NVD Process — the clearest official explanation of what belongs to the CVE program versus the NVD enrichment layer. (nvd.nist.gov)
- FIRST CVSS v4.0 Specification — the best reference for what CVSS does and does not measure. (first.org)
- FIRST EPSS — the official explanation of EPSS as a 30-day exploitation probability model. (first.org)
- Project Zero, From Naptime to Big Sleep — the public write-up on AI-assisted discovery of an exploitable SQLite issue. (projectzero.google)
- Google Cloud, Defending Your Enterprise When AI Models Can Find Vulnerabilities Faster Than Ever — one of the clearest public statements on the coming asymmetry. (Google Cloud)
- OpenAI, Trusted Access for the Next Era of Cyber Defense — useful for understanding how frontier-model vendors are thinking about defender acceleration and risk. (OpenAI)
- OpenAI, Codex Security — useful for understanding why validation and context are becoming the new bottleneck. (OpenAI)
- Penligent, The 2026 Ultimate Guide to AI Penetration Testing — relevant for teams exploring agentic offensive validation workflows. (penligent.ai)
- Penligent, Overview of Penligent.ai’s Automated Penetration Testing Tool — useful for understanding the platform’s public workflow around task planning, execution, and result interpretation. (penligent.ai)
- Penligent, Pentest AI Tools in 2026 — What Actually Works, What Breaks — relevant to the verification and operator-controlled workflow angle discussed above. (penligent.ai)

