Bad Epoll is not just another Linux kernel bug with a catchy name. CVE-2026-46242 is a race-condition use-after-free in the Linux kernel’s eventpoll implementation, the code behind epoll, and it matters because a low-privileged local process can turn a kernel object lifetime mistake into full system compromise on affected systems. The official vulnerability description ties the flaw to fs/eventpoll.c, specifically to how ep_remove() ve ep_remove_file() clear file->f_ep while still depending on the same struct file in a critical section. In the wrong close-vs-close interleaving, a concurrent __fput() path can skip eventpoll_release_file(), leaving the kernel to operate on objects that should no longer be trusted. The kernel.org CNA score shown by NVD is 7.8 High with local attack vector, low privileges, no user interaction, and high impact to confidentiality, integrity, and availability. (NVD)
The public research name, Bad Epoll, comes from work by Jaeyoung Chung of Seoul National University’s Computer Security Lab. The researcher describes it as a race-condition use-after-free in Linux epoll, reported and exploited as a zero-day submission to Google kernelCTF, with local privilege escalation impact on Linux desktops, servers, and Android-like targets depending on kernel lineage and patch status. The same write-up also makes an important point for defenders: this is not a remote network exploit by itself. It becomes serious when an attacker already has the ability to run untrusted code locally, inside a user account, sandbox, container, CI job, development environment, app sandbox, or other shared execution boundary. (CompSec)
That distinction is not comforting in modern infrastructure. Many real incidents begin with limited code execution: a compromised package script, a stolen developer token, a malicious CI dependency, a container escape attempt, a browser renderer foothold, a low-privileged shell, or an app sandbox bypass chain. A local kernel privilege escalation bug is often the step that turns “contained compromise” into “host compromise.” Bad Epoll sits directly in that category. It does not need to be the first bug in a chain to be the most consequential one.
What epoll does and why its lifetime rules are hard
epoll is Linux’s scalable I/O event notification facility. Instead of asking a process to poll many file descriptors one by one, the kernel keeps an epoll instance with an interest list and a ready list. A program creates the instance with epoll_create() veya epoll_create1(), adds or modifies watched file descriptors with epoll_ctl(), and waits for events with epoll_wait() or related calls. The man page describes the epoll instance as an in-kernel data structure used to monitor multiple file descriptors and return descriptors that are ready for I/O. (man7.org)
That simple API hides a dense set of kernel object relationships. An epoll instance is itself represented through a file descriptor. The file descriptors it watches refer to struct file objects. Those file objects may be sockets, pipes, eventfds, timerfds, regular files, device files, or even other epoll instances. That last case, epoll watching epoll, is a legitimate part of the API surface, but it makes object lifetime harder because one event notification object can depend on another event notification object while both can be closed concurrently by different threads.
The important point is not that epoll is unusual. The important point is that epoll is everywhere. Event loops in servers, runtimes, reverse proxies, databases, message brokers, browser components, mobile runtimes, containerized workloads, and async frameworks all rely on it. A kernel vulnerability in this area does not require a niche driver or rare hardware device. It lives in a subsystem that ordinary user-space programs can reach.
| Kernel concept | Why it matters for CVE-2026-46242 |
|---|---|
struct file | Represents an opened file description in the kernel. Bad Epoll depends on a race where code continues to rely on a file object after another path can observe changed state. |
file->f_ep | Links a file to epoll watch state. The vulnerable path clears this field before all users are safely done with the file. |
struct eventpoll | The kernel object behind an epoll instance. Epoll-on-epoll relationships make its lifetime part of the bug. |
__fput() | File release path invoked when the last reference is dropped. A concurrent __fput() can observe file->f_ep == NULL and skip cleanup that should have happened. |
| RCU and slab reuse | RCU and allocator behavior affect whether a stale pointer becomes a crash, silent corruption, or an exploitable primitive. |
ep_remove() | The removal path that the upstream fix changed by pinning the file at the beginning of the operation. |
A useful mental model is that epoll is not only an event API. It is also a graph of references between kernel objects. The bug appears when one edge in that graph is removed too early while another thread still believes the graph is valid enough to walk.
The bug in kernel terms
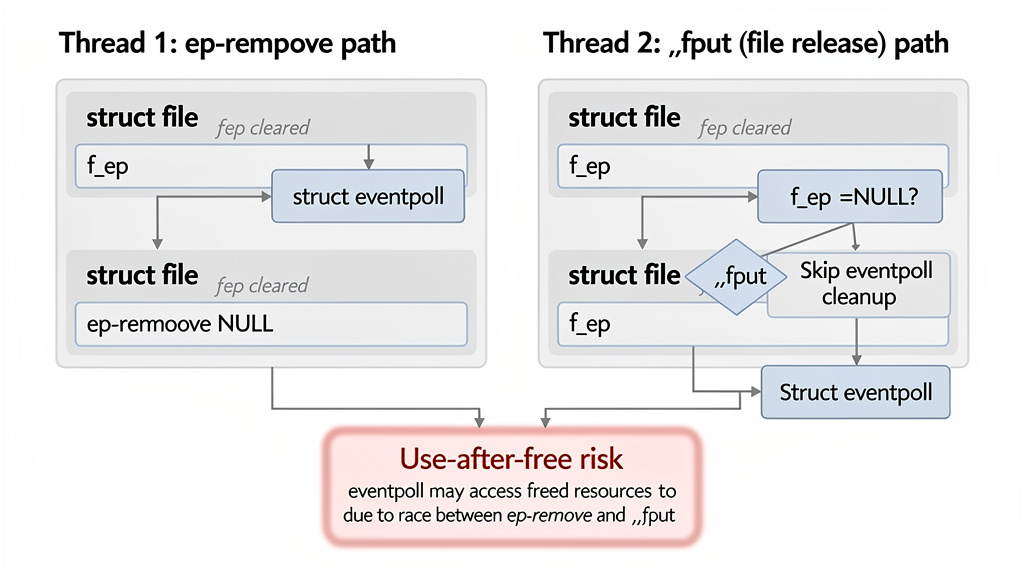
The official vulnerability description is unusually specific. It says that ep_remove() ve ep_remove_file() cleared file->f_ep under file->f_lock but kept using dosya in the following critical section. That created a window where __fput() could observe file->f_ep olarak NULL and skip eventpoll_release_file(). In an epoll-watches-epoll case, that can free the watched struct eventpoll while the removing code continues to operate on it. NVD’s record also notes that hlist_del_rcu() can scribble into a freed kmalloc-192 object and that struct file uses SLAB_TYPESAFE_BY_RCU, which changes how reuse and stale references behave. The fix pins @file ile epi_fget() at the top of ep_remove(). (NVD)
The researcher’s root cause analysis describes the vulnerable interleaving as a close-vs-close race. One thread closes an epoll file descriptor that is watching another epoll file descriptor. Another thread closes the watched epoll file descriptor. The race is not simply that memory is freed; it is that cleanup responsibility can be lost. __ep_remove() clears the link, a concurrent release path sees no epoll association, and cleanup that should release the eventpoll relationship is skipped. The result is a pair of use-after-free conditions involving struct eventpoll ve struct file. (GitHub)
A simplified defensive sketch looks like this:
/*
* Simplified model for understanding the bug.
* This is not Linux source code and not an exploit.
*/
thread_a_remove_watch() {
lock(file->f_lock);
/*
* Vulnerable idea:
* The association is cleared while later code still depends
* on file and related epoll objects being safe to use.
*/
file->f_ep = NULL;
unlock(file->f_lock);
/*
* Later cleanup still touches state reachable from the file
* and from the epoll relationship.
*/
continue_eventpoll_cleanup(file);
}
thread_b_last_close() {
/*
* Concurrent release can observe the transient NULL state.
*/
if (file->f_ep == NULL) {
/*
* Cleanup path can be skipped because the file now looks
* as if it is not attached to epoll.
*/
skip_eventpoll_release_file();
}
release_file_and_related_objects(file);
}
The upstream fix is conceptually simple: hold the right reference early enough that the object cannot disappear or be reused while removal logic still needs it. In kernel code, simple concepts often require careful placement. Pin too late and the race remains. Pin the wrong object and one UAF class may disappear while another remains. Pin without respecting lock ordering and you can introduce deadlocks. That is why object lifetime bugs in core kernel subsystems often need more than a one-line local patch.
The relationship to CVE-2026-43074 makes this even clearer. The Bad Epoll research notes that CVE-2026-43074 was a distinct eventpoll race introduced by the same 2023 commit family. That earlier fix deferred freeing struct eventpoll through an RCU grace period, but the Bad Epoll analysis argues that the struct file use-after-free remained until the separate CVE-2026-46242 fix. In other words, fixing one visible object lifetime symptom did not automatically fix the entire lifetime design problem. (NVD)
That is a common kernel security lesson. Adjacent races often share a root design pressure, but they do not always share a complete fix. When a patch changes one lifetime rule in a subsystem like eventpoll, defenders should expect follow-on analysis, backports, regression concerns, and distribution-specific status changes.
Why Bad Epoll is not a normal memory corruption bug
A plain use-after-free is already dangerous, but Bad Epoll has a more subtle shape. It is a race in a high-frequency core subsystem, not a simple deterministic call that frees an object and immediately uses it on the same thread. The exploitability depends on interleaving, object lifetime, allocator behavior, CPU scheduling, kernel configuration, target version, and available post-UAF primitives.
The public Bad Epoll exploit notes describe a high-level chain that turns a close-vs-close race into a small write primitive, then into a dangling file object, then into a more useful kernel memory interaction, and eventually into privilege escalation on tested kernelCTF targets. The researcher reported high reliability on specific tested targets, including LTS and Container-Optimized OS targets, but those measurements are target-specific and should not be read as universal reliability across every enterprise kernel, distribution backport, hardening profile, or cloud image. (GitHub)
For defenders, the key is to separate exploit research detail from risk management detail. You do not need to reproduce the exploit to prioritize the patch. You need to know whether an untrusted local process can reach the vulnerable subsystem, whether the kernel lineage includes the vulnerable code, whether your vendor has shipped a fixed package, and whether the machine is part of a boundary where local privilege escalation changes the blast radius.
| Safe to use in defensive triage | Not needed for routine remediation |
|---|---|
| CVE identifier, affected subsystem, vendor status, fixed package version, reboot status | Race timing parameters |
| Local privilege requirement and whether user namespaces are required | Object spraying strategy |
| High-level bug class and affected code path | ROP chain details |
| Whether the system runs untrusted local code | Kernel offsets and gadget selection |
| Whether a vendor backport contains the fix | Public exploit tuning for a specific target |
| Detection limits and expected logging gaps | Step-by-step exploit reproduction |
This distinction matters because many teams lose time trying to decide whether to run a public exploit. For a kernel local privilege escalation issue, running exploit code on production systems is rarely a good validation method. It can crash hosts, corrupt state, violate internal policy, or produce false confidence when it fails on a hardened target even though the code path remains vulnerable. Package status, patch commit lineage, and controlled lab reproduction are safer inputs.
Local does not mean low priority
CVE-2026-46242 requires local code execution. That should reduce panic, not priority. “Local” in a modern Linux estate includes many execution contexts that defenders do not fully trust.
A developer workstation runs package install scripts, browser-rendered content, IDE extensions, containerized tools, language servers, local AI assistants, and test binaries. A CI runner runs code from pull requests, dependency hooks, build scripts, and container images. A Kubernetes worker runs containers from multiple teams. A shared research box runs code from several users. A browser sandbox may contain attacker-controlled renderer code after a separate browser bug. An Android app sandbox is explicitly built on the assumption that a local untrusted app process should not become root.
Bad Epoll matters in all of those places because the Linux kernel is the shared enforcement boundary. When the boundary fails, higher-level isolation can collapse.
| Environment | Why CVE-2026-46242 matters | Patch priority |
|---|---|---|
| Multi-tenant CI runner | Untrusted build code may execute as a low-privileged user or inside a container. Kernel LPE can turn a job compromise into host compromise. | Çok yüksek |
| Kubernetes worker with mixed-trust workloads | Containers share the host kernel. A local kernel bug can undermine namespace and cgroup isolation. | Çok yüksek |
| Developer laptop | Dependency scripts, test code, browser content, and local tools increase local-code exposure. | Yüksek |
| Single-tenant production server | Risk depends on whether attackers can land a shell, exploit an app RCE, upload plugins, or run jobs. | Orta ila yüksek |
| Shared shell server | Any low-privileged account may become a host-level risk. | Çok yüksek |
| Android device | App sandbox escape chains may use kernel LPE as the second stage, depending on kernel version and device patch status. | High where affected |
| Air-gapped appliance | Lower exposure if no untrusted local code runs, but patching still matters for maintenance and insider risk. | Bağlama bağlı |
The public repository’s own warning is direct: the researcher lists no workaround other than patching, notes that the race window is tiny but exploitable on tested targets, and calls out Android and Chrome renderer sandbox scenarios as possible chain contexts. The same source also cautions that some older v6.1-based Android devices were not affected in the researcher’s assessment, while newer kernel lineages may be in scope. (GitHub)
Affected versions are a vendor question, not just a kernel-number question
One of the easiest mistakes with Linux kernel CVEs is to compare uname -r against an upstream version range and stop there. That is not enough. Distribution kernels are backported. Cloud kernels carry downstream patches. Android kernels may use vendor trees. Enterprise kernels may report a version that looks old while containing many newer patches, or a version that looks new while missing a specific fix.
NVD’s record for CVE-2026-46242 lists affected upstream git ranges and semver-style ranges. It also reflects the official description of the fix. However, vendor trackers show why defenders must verify against the distribution’s own advisory. Debian’s tracker, for example, shows different statuses across bullseye, bookworm, trixie, forky, and sid. SUSE’s page shows its own severity assessment and fixed openSUSE Tumbleweed package versions. Amazon Linux’s page says several Amazon Linux 2 and Amazon Linux 2023 kernel streams are not affected, while specific AL2023 kernel6.12 ve kernel6.18 streams were listed with pending fixes on its advisory page. (NVD)
| Kaynak | What it tells you | Operational reading |
|---|---|---|
| NVD and kernel.org CNA data | Official CVE description, upstream affected ranges, CWE-416 classification, CNA CVSS vector, patch references | Use it to understand the bug and upstream lineage, not as the only source for a distro decision. |
| Debian tracker | Branch-by-branch Debian package status, including fixed, vulnerable, and not-affected notes | Check the exact Debian release and installed kernel package, not only the kernel version string. |
| SUSE tracker | SUSE severity, CVSS differences, package-level status, openSUSE Tumbleweed fixed package versions | Treat vendor severity as environment-specific, especially when it differs from CNA scoring. |
| Amazon Linux advisory | Amazon Linux package status across AL2 and AL2023 kernel streams | Cloud distro kernels need cloud-vendor status, not only mainline Linux interpretation. |
| Researcher timeline | Introduced and fixed upstream commits, exploit context, tested targets | Useful for root cause and urgency, but production remediation still depends on vendor packages. |
The safest operational rule is: map every system to its vendor security tracker and kernel package version, then confirm that the fixed package is installed and booted. Installing a new kernel package without rebooting does not remove exposure from the running kernel. Live patching may help in some environments, but only if the vendor explicitly covers this CVE and the live patch is active.
Why severity scores differ
The NVD page shows the kernel.org CNA CVSS v3.1 score as 7.8 High, with local attack vector, low attack complexity, low privileges required, no user interaction, unchanged scope, and high confidentiality, integrity, and availability impact. SUSE’s page shows the same CNA/NVD 7.8 line but also lists SUSE’s own score as 5.5 Moderate with a different impact interpretation. Amazon Linux lists the issue as Important and shows a CVSS score of 7.0 with high attack complexity in its vector. (NVD)
That does not mean one source is careless. It means they are measuring different things. Upstream CNA scoring often describes the vulnerability class in a generic affected configuration. A distribution vendor may account for its kernel configuration, code lineage, default exposure, exploit reliability, package status, and support policy. A cloud provider may score based on the affected package stream and expected deployment model. A security operations team should then apply its own exposure model.
| Scoring lens | Typical focus | How to use it |
|---|---|---|
| CNA or upstream CVSS | Generic vulnerability impact and exploit prerequisites | Good starting point for severity and communications. |
| Distribution severity | Vendor kernel configuration, backports, package status, support branch policy | Best source for patch decision on that distribution. |
| Cloud image advisory | Cloud-specific kernel builds, managed images, optimized kernels | Essential for fleets using provider kernels. |
| Internal risk rating | Whether untrusted local code runs and whether a host boundary matters | Best source for remediation order across your estate. |
A CI runner that builds untrusted pull requests may deserve emergency treatment even if a vendor labels the issue Moderate. A single-purpose server with no local users and no plugin execution may still need patching, but it may rank below exposed multi-tenant systems. CVSS is a coordination language. It is not a substitute for asset context.
How to check exposure without running an exploit
A safe check begins with inventory. You want to know the running kernel, the installed kernel packages, the distribution release, and whether your vendor has shipped a fix. The following script does not trigger the bug. It gathers enough local context to start triage.
#!/usr/bin/env bash
set -euo pipefail
echo "== Operating system =="
if [ -r /etc/os-release ]; then
. /etc/os-release
printf '%s\n' "${PRETTY_NAME:-unknown}"
else
echo "unknown"
fi
echo
echo "== Running kernel =="
uname -a
echo
echo "== Kernel configuration hints =="
for f in "/boot/config-$(uname -r)" /proc/config.gz; do
if [ -r "$f" ]; then
echo "-- $f"
case "$f" in
*.gz)
zgrep -E '^CONFIG_EPOLL=|^CONFIG_KALLSYMS=|^CONFIG_SLAB_FREELIST_HARDENED=|^CONFIG_SLAB_FREELIST_RANDOM=' "$f" || true
;;
*)
grep -E '^CONFIG_EPOLL=|^CONFIG_KALLSYMS=|^CONFIG_SLAB_FREELIST_HARDENED=|^CONFIG_SLAB_FREELIST_RANDOM=' "$f" || true
;;
esac
fi
done
echo
echo "== Installed kernel package hints =="
if command -v dpkg >/dev/null 2>&1; then
dpkg -l 'linux-image*' 2>/dev/null | awk '/^ii/ {print $2, $3}'
fi
if command -v rpm >/dev/null 2>&1; then
rpm -q kernel kernel-core kernel-default kernel-devel 2>/dev/null || true
fi
The configuration lines are only hints. CONFIG_EPOLL tells you whether epoll support is present, but almost all general-purpose Linux kernels have it. Slab hardening options may affect exploitation reliability, not whether the vulnerable code exists. CONFIG_KALLSYMS and related options can affect exploit development and debugging, but they do not turn an affected kernel into a fixed kernel.
Next, query your package advisory system. These commands are examples, not universal proof.
# Debian and Ubuntu families
sudo apt update
apt list --upgradable 2>/dev/null | grep -E '^linux-(image|headers|modules)' || true
apt-cache policy "linux-image-$(uname -r)" || true
# RHEL, Fedora, Rocky, Alma, and Amazon Linux families
sudo dnf updateinfo list cves CVE-2026-46242 || true
sudo dnf updateinfo info --cve CVE-2026-46242 || true
sudo yum updateinfo info --cve CVE-2026-46242 || true
# SUSE and openSUSE families
sudo zypper lp --cve CVE-2026-46242 || true
sudo zypper patch --cve CVE-2026-46242 --dry-run || true
There are three common traps in this step.
First, a system can have a fixed kernel package installed but still be running the old vulnerable kernel. Always compare the running kernel from uname -r with the installed and booted kernel after maintenance.
Second, a scanner may flag the upstream version but miss a vendor backport. This creates false positives on enterprise kernels.
Third, a scanner may trust a package version but miss a custom kernel, container host image, embedded build, or manually installed kernel. That creates false negatives.
A strong validation workflow keeps all three data points together: upstream CVE facts, vendor package status, and live host evidence. For authorized security teams managing large estates, tools that preserve the chain from hypothesis to command output to retest evidence reduce the chance that a kernel advisory becomes a spreadsheet-only exercise. Penligent’s public site describes an evidence-first approach to authorized validation and reproducible findings, and its broader writing on AI vulnerability discovery argues that useful AI-assisted security work depends on state, tool execution, evidence, and retesting rather than model assertions alone. (Penligent)
What detection can and cannot tell you
Bad Epoll is not a web vulnerability with a stable request pattern. There is no reliable HTTP signature, no universal file path indicator, and no single log line that proves exploitation. A successful local kernel exploit may leave very little application-level evidence. A failed attempt may show up as a kernel oops, slab corruption, KASAN report, process crash, or abrupt privilege transition. In many production environments, none of those signals are collected with enough detail to reconstruct the attempt after the fact.
That does not make monitoring useless. It means monitoring should be framed as weak signal collection, not proof of absence.
Potential defensive signals include unusual local processes creating and closing many epoll file descriptors, tight loops around epoll_create1, epoll_ctlve close, suspicious use of /proc/self/fdinfo, unexpected access to kernel debugging surfaces, sudden privilege transitions, and crashes involving eventpoll or slab corruption. These are noisy. Many legitimate event-driven programs use epoll heavily. CI systems, browsers, runtimes, and server processes may generate high epoll activity under normal load.
A controlled bpftrace snippet can help responders understand local syscall patterns during an investigation, but it should not be deployed blindly as a production detection rule.
sudo bpftrace -e '
tracepoint:syscalls:sys_enter_epoll_create1
{
@epoll_create[comm] = count();
}
tracepoint:syscalls:sys_enter_epoll_ctl
{
@epoll_ctl[comm] = count();
}
tracepoint:syscalls:sys_enter_close
{
@close[comm] = count();
}
interval:s:10
{
printf("\n--- epoll and close activity by process name ---\n");
print(@epoll_create);
print(@epoll_ctl);
print(@close);
clear(@epoll_create);
clear(@epoll_ctl);
clear(@close);
}'
This shows process-name aggregates for epoll creation, epoll control operations, and close calls. It does not detect CVE-2026-46242. It does not see object lifetime corruption. It does not know whether a race was attempted. It can help an operator notice a short-lived unknown process behaving oddly on a lab system, but it can also produce misleading noise on real servers.
A more mature detection posture combines several layers:
| Signal source | Useful for | Sınırlama |
|---|---|---|
| Kernel logs | Crashes, oops messages, slab corruption, KASAN findings in debug kernels | Successful exploitation may not crash. Production kernels often lack rich diagnostics. |
| EDR or runtime telemetry | Unexpected privilege changes, suspicious child processes, post-exploitation behavior | May miss kernel-level transition and only see later actions. |
| eBPF tracing | Short-term incident triage of syscall patterns and process behavior | Noisy and potentially expensive if misused. |
| Package and reboot state | Confirming remediation coverage | Does not prove no historical exploitation occurred. |
| CI and container audit logs | Identifying which untrusted jobs ran on affected hosts | Logs may not preserve enough process-level detail. |
The best “detection” for a kernel local privilege escalation bug is often not detection at all. It is fast patching plus a serious review of systems that executed untrusted code while vulnerable. If an affected CI worker ran untrusted jobs during the exposure window, assume the host boundary may have been at risk and rotate secrets accordingly. If an affected developer workstation ran unknown binaries, review credentials and local persistence. If an affected Kubernetes node hosted mixed-trust workloads, inspect for container escape indicators and unexpected host modifications.
Mitigation and hardening that actually help
The primary mitigation for Bad Epoll is to run a fixed kernel from your vendor and reboot into it. The researcher’s public write-up says there is no workaround except patching. That aligns with the nature of the bug: epoll is too central to disable generically, and the vulnerable behavior is in kernel object lifetime logic rather than an optional network service. (GitHub)
Patching kernel vulnerabilities sounds simple until you operate real fleets. The following order is practical:
- Patch and reboot systems that run untrusted local code.
- Patch and reboot shared CI workers, build hosts, and container nodes.
- Patch developer workstations and security research machines.
- Patch externally exposed servers where an application compromise could provide a local shell.
- Patch lower-exposure single-purpose systems according to maintenance windows, while documenting why they are lower priority.
Containers are not a full mitigation. Containers share the host kernel. Namespaces, cgroups, seccomp, AppArmor, SELinux, and capability dropping all reduce attack surface and post-exploitation reach, but a kernel UAF in a reachable syscall path is precisely the kind of bug that can cross a container boundary if successfully exploited. A container may make exploitation harder. It does not make the host unaffected.
Seccomp deserves careful handling. In a narrow appliance workload, blocking epoll_create1 or restricting related syscalls might reduce exposure for a specific process. On general-purpose Linux systems, that will break many applications. Event loops and runtimes rely on epoll. A broad “block epoll” rule is not a realistic fleet-wide workaround.
A safer hardening posture is layered:
| Kontrol | Değer | Caveat |
|---|---|---|
| Vendor kernel patch and reboot | Removes known vulnerable code from the running kernel | Requires maintenance and reboot validation. |
| Reduce untrusted local code | Shrinks the number of attackers who can reach local kernel attack surface | Hard for CI, developer machines, and plugin ecosystems. |
| Strong container profiles | Reduces available syscalls, capabilities, mounts, and host reach | Does not turn a vulnerable host kernel into a safe one. |
| Separate trust zones | Keeps untrusted jobs away from sensitive hosts and secrets | Requires scheduling and infrastructure discipline. |
| Secret rotation after exposure | Limits blast radius if a host boundary was crossed | Expensive but appropriate for high-risk shared systems. |
| Kernel exploit telemetry | Helps incident response and historical review | Usually incomplete for successful LPE. |
For Android, the operational answer is also patch lineage, not panic. The researcher states that older v6.1-based Pixel 8 style kernels were not affected in their assessment, while newer v6.6+ Pixel 10 style kernels had a triggering UAF in current testing and full root exploit work was in progress at publication time. Device vendors and Android security bulletins remain the authority for shipped devices, because OEM backports and kernel branches vary. (GitHub)
The sibling bug, CVE-2026-43074
CVE-2026-43074 is the most directly relevant related CVE because it involves Linux eventpoll object lifetime too. NVD’s description says Linux addressed another eventpoll use-after-free by delaying struct eventpoll freeing through an RCU grace period. The Bad Epoll root cause analysis says the two bugs were distinct but connected by the same introducing commit family, and that the CVE-2026-43074 fix did not remove the struct file use-after-free that became CVE-2026-46242. (NVD)
That relationship matters for two reasons.
First, a system can appear to have received a nearby eventpoll fix while still needing the Bad Epoll patch. Do not assume “we patched the previous epoll race” means “we patched all epoll races.”
Second, it shows why kernel race bugs often require semantic review, not just crash reproduction. A patch that prevents one freed object from being immediately reused may reduce one symptom while preserving a stale-reference condition elsewhere. The absence of an immediate crash is not proof of correct object ownership.
For defenders, CVE-2026-43074 should be part of the same patch review conversation. If you are checking whether a kernel includes the Bad Epoll fix, also check whether the earlier eventpoll fix landed and whether your vendor delivered both in the same or different package updates.
Copy Fail and the broader Linux local privilege escalation pattern
CVE-2026-31431, often discussed as Copy Fail, is a useful contrast. It is not an epoll bug. It sits in the Linux crypto subsystem path involving algif_aead, AF_ALGve ekleme, and public analysis described how a local attacker could corrupt the page cache of readable files, including setuid binaries, to escalate privileges. Microsoft’s write-up characterized it as a Linux kernel vulnerability that can allow an unprivileged user to obtain root by corrupting the cache of readable files. NVD records the Linux kernel fix as a change in crypto: algif_aead, reverting to out-of-place operation to remove the problematic in-place complexity. (Microsoft)
Copy Fail and Bad Epoll are different bug classes, but they teach the same operational lesson: local primitives are not minor if local code execution is common in your environment. Copy Fail’s risk centers on a deterministic write primitive through a crypto and splice path. Bad Epoll’s risk centers on a timing-sensitive use-after-free in eventpoll cleanup. One looks like data corruption. The other looks like object lifetime collapse. Both can become root under the right conditions.
| CVE | Subsystem | Bug shape | Attacker position | Neden önemli |
|---|---|---|---|---|
| CVE-2026-46242, Bad Epoll | fs/eventpoll.c | Race-condition use-after-free in epoll removal and file release interaction | Local low-privileged code | Can convert a local foothold into root on affected kernels. |
| CVE-2026-43074 | fs/eventpoll.c | Related eventpoll use-after-free fixed with RCU-delayed free | Local code path reaching epoll behavior | Shows that nearby lifecycle fixes may not cover all races. |
| CVE-2026-31431, Copy Fail | Linux crypto and AF_ALG path | Page-cache corruption primitive through in-place operation complexity | Local low-privileged code | Demonstrates how non-network kernel APIs can still become root paths. |
This is why Linux kernel patching must be tied to execution trust. If all local code is trusted, a local kernel LPE is still important but may be scheduled through normal maintenance. If local code is not trusted, the same CVE becomes boundary-breaking.
Why AI found one nearby race and missed this one
Bad Epoll became part of a larger security discussion because of its relationship to AI-assisted vulnerability discovery. The public CompSec write-up says Anthropic’s Mythos found another race bug in the same epoll code but missed Bad Epoll. The researcher argues that the missed bug had a tiny race window and little runtime evidence, including the fact that it did not trigger KASAN in their testing. (CompSec)
Anthropic’s public Mythos materials describe a system aimed at vulnerability discovery and triage across complex software, including Linux kernel vulnerabilities, while also acknowledging that remote exploitation was blocked in some Linux cases by defense-in-depth after extensive scanning. That context is important: AI systems can accelerate code review and hypothesis generation, but kernel race bugs still demand dynamic reasoning, adversarial scheduling intuition, memory allocator knowledge, patch semantics, and human verification. (Anthropic Red)
The lesson is not “AI failed.” The lesson is “AI output is not a proof.” A model can point researchers toward suspicious code. It can compare commits, summarize lifetime assumptions, generate harness ideas, and suggest invariants to test. But a kernel race becomes a real vulnerability only when the hypothesis survives execution, crash analysis, patch review, exploitability assessment, and responsible disclosure.
For security teams, this matters on the defensive side as much as the research side. A vulnerability validation workflow should preserve the hypothesis, the exact kernel build, the vendor advisory, the commands run, the evidence collected, the patch applied, and the retest result. Without that chain, teams end up with screenshots, scanner output, and uncertain remediation status. With it, they can decide which systems are still exposed and which have actually booted into a fixed kernel.
Practical triage by role
Bad Epoll looks different depending on who owns the risk.
A security engineer managing Linux servers should begin with kernel inventory, vendor advisory mapping, and reboot state. The immediate question is not whether the public exploit works on a specific host. It is whether the host runs a kernel package that the vendor marks affected and whether untrusted local code can execute there.
A red teamer should treat CVE-2026-46242 as a post-foothold escalation concept, not as an initial access technique. In authorized work, the right way to handle it is to document likely exposure, validate patch status, and avoid running unstable public kernel exploit code on production unless the rules of engagement explicitly allow controlled exploitation in a test environment.
A bug bounty hunter should be careful. Many programs exclude local privilege escalation, kernel exploits, denial-of-service risk, public exploit execution, or attacks requiring a compromised account. If a bounty target includes managed Linux appliances, Android devices, CI systems, or container platforms, the scope language matters. A responsible report should focus on affected version evidence and impact path, not on dropping a root shell on production infrastructure.
A platform engineer should look at trust boundaries. If your CI runners build untrusted code, a kernel LPE is a platform isolation bug. If your Kubernetes cluster mixes tenants, a kernel LPE is a cluster boundary risk. If your developer machines hold production credentials, a local root escalation is a credential protection risk.
A compliance or security leadership team should avoid two bad extremes. One extreme is to dismiss the CVE because it is local. The other is to declare every Linux host equally critical. A defensible risk memo should rank systems by local-code exposure, kernel status, tenant mixing, secrets on host, and business function.
Safe remediation workflow
A practical remediation workflow can be written without exploit code.
# 1. Record the running kernel.
uname -r
# 2. Record the OS release.
cat /etc/os-release
# 3. Query vendor advisory tooling where available.
# Examples only; use the package manager for your distribution.
# Debian and Ubuntu families
apt-cache policy "linux-image-$(uname -r)" || true
# DNF-based systems
sudo dnf updateinfo info --cve CVE-2026-46242 || true
# SUSE and openSUSE
sudo zypper lp --cve CVE-2026-46242 || true
# 4. Apply the vendor kernel update.
# Use your normal change-control process.
# 5. Reboot into the fixed kernel.
sudo reboot
# 6. After reboot, prove the running kernel changed.
uname -r
For fleets, replace manual commands with configuration management and asset inventory. The key evidence fields are:
| Evidence field | Neden önemli |
|---|---|
| Hostname or asset ID | Links remediation to a real system. |
| Business owner | Helps prioritize downtime and reboot windows. |
| Distribution and release | Determines the correct vendor tracker. |
| Running kernel before patch | Shows exposure state. |
| Installed fixed package | Shows package remediation. |
| Running kernel after reboot | Confirms remediation is active. |
| Local-code exposure rating | Explains priority. |
| Secret or tenant exposure | Guides post-exposure review. |
| Exception owner and expiration | Prevents permanent “temporary” risk acceptance. |
If a system cannot be patched quickly, reduce local-code exposure while waiting. Pause untrusted CI jobs on affected workers. Move high-risk workloads to patched nodes. Avoid running unknown binaries on affected developer machines. Rotate secrets if an affected shared host executed untrusted code. Restrict shell access. Ensure container profiles drop unnecessary capabilities. None of this replaces the patch, but it can reduce the window of easy abuse.
Incident response when exposure may have existed
If you discover that a high-risk host was affected for days or weeks, do not limit the response to installing the patch. Ask what local code ran during the window.
For CI workers, identify jobs from untrusted contributors, forks, dependency update bots, and external build triggers. Review whether secrets were mounted, whether Docker socket access existed, and whether privileged containers were used. If the runner used long-lived credentials, rotate them.
For Kubernetes nodes, identify pods scheduled during the exposure window, especially workloads with untrusted images, broad hostPath mounts, added capabilities, or access to service account tokens with high privileges. Review node-level persistence and unexpected host file changes.
For developer workstations, review recently installed packages, browser extensions, local scripts, and test binaries. Kernel LPE is often used after another local compromise. If the host held production credentials, tokens, SSH keys, or signing material, treat the event as a credential exposure question, not just a kernel patch question.
For Android or mobile fleets, rely on vendor patch status and mobile device management telemetry. Do not assume all devices with a similar marketing name share the same kernel branch. Device kernel lineage and patch level are the facts that matter.
Common mistakes during Bad Epoll response
One common mistake is to treat “local” as “unimportant.” That may be true for a locked-down single-purpose appliance. It is not true for a CI worker, container host, shared development server, or workstation that runs code from the internet every day.
Another mistake is to trust only upstream version ranges. Enterprise vendors routinely backport fixes. A kernel that looks old may be fixed. A custom kernel that looks new may not be. Always check vendor status and patch content.
A third mistake is to install the fixed kernel but not reboot. The running kernel is the attack surface. Package state is not enough.
A fourth mistake is to run a public exploit as a vulnerability check. A failed exploit does not prove safety. A successful one may crash or damage the host. A responsible validation uses package evidence and controlled lab testing.
A fifth mistake is to overfit detection to one proof of concept. Kernel exploit techniques can change. Timing, allocator behavior, and post-UAF primitives are target-specific. Detection should focus on suspicious local behavior and post-exploitation outcomes, while remediation focuses on removing the vulnerable code.
A final mistake is to assume one nearby patch fixed the whole subsystem. CVE-2026-43074 and CVE-2026-46242 show why that assumption is risky. Similar code, similar object lifetimes, and shared commit history do not guarantee shared remediation.
SSS
Is Bad Epoll remotely exploitable by itself?
- No public authoritative source describes CVE-2026-46242 as a standalone remote network exploit.
- The vulnerability requires local code execution with low privileges.
- It becomes dangerous as a second-stage bug after an attacker gains a local foothold through a web RCE, malicious dependency, compromised CI job, browser sandbox bug, container workload, or app sandbox.
- Internet-facing servers still matter if attackers can turn an application compromise into a local process.
Does a container make CVE-2026-46242 irrelevant?
- No. Containers share the host kernel, so a reachable kernel local privilege escalation can threaten the container boundary.
- Namespaces, seccomp, AppArmor, SELinux, dropped capabilities, and read-only filesystems can reduce risk and make exploitation harder.
- These controls are not a replacement for a fixed kernel.
- Patch container hosts and Kubernetes workers before lower-risk single-tenant machines.
Which Linux systems should be patched first?
- Patch systems that run untrusted local code first: CI runners, build servers, shared shells, container hosts, developer workstations, and mixed-tenant infrastructure.
- Patch externally exposed servers next if an application bug could give attackers a local process.
- Patch lower-exposure systems through normal maintenance, but track exceptions with owners and expiration dates.
- Always reboot into the fixed kernel or confirm an active vendor live patch that specifically covers the issue.
Can epoll be disabled as a workaround?
- There is no practical general-purpose workaround that safely disables epoll across a normal Linux system.
- Many modern runtimes, servers, browsers, proxies, databases, and async frameworks depend on epoll.
- Narrow seccomp policies may reduce exposure for tightly controlled workloads, but broad epoll blocking will break applications.
- The reliable mitigation is a vendor kernel update plus reboot.
Is Android affected by Bad Epoll?
- The researcher described Android relevance and noted that affectedness depends on kernel lineage and patch status.
- Some older v6.1-based devices were described as not affected in the researcher’s assessment, while newer kernel branches may need attention.
- Device vendors and Android security bulletins are the authority for shipped device status.
- For enterprise mobile fleets, track device model, kernel version, Android patch level, and vendor update availability.
How can I verify remediation without running exploit code?
- Check the vendor advisory for your exact distribution and kernel stream.
- Confirm the fixed kernel package is installed.
- Reboot and verify the running kernel with
uname -r. - Preserve evidence: before-and-after kernel versions, package versions, advisory reference, reboot time, and affected asset list.
- Use controlled lab testing only if your organization has authorization, safe infrastructure, and clear rules of engagement.
Why do vendors rate CVE-2026-46242 differently?
- Upstream and CNA scoring describes generic vulnerability impact.
- Distribution vendors account for their kernel configuration, backports, exploitability judgment, and supported package streams.
- Cloud vendors may evaluate specific optimized kernels and managed images.
- Internal priority should depend on local-code exposure, tenant mixing, secrets on the host, and whether the fixed kernel is running.
How is Bad Epoll different from Copy Fail?
- Bad Epoll is an
eventpollrace-condition use-after-free involving kernel object lifetime and concurrent close paths. - Copy Fail, CVE-2026-31431, involved Linux crypto and AF_ALG behavior that could corrupt page cache in a local privilege escalation path.
- Bad Epoll is timing-sensitive and tied to epoll cleanup semantics.
- Copy Fail is a different primitive with a different subsystem and fix, but both show why local kernel bugs matter when untrusted code can run.
The practical call
Bad Epoll should be handled as a real kernel boundary issue, not as a headline-only panic. The right response is specific: identify affected kernel streams, follow vendor advisories, patch and reboot systems that run untrusted local code, treat shared execution environments as high priority, and avoid unsafe exploit-based validation on production machines.
The deeper lesson is about trust boundaries. Linux local privilege escalation bugs are not isolated technical curiosities anymore. They sit under CI platforms, container clusters, developer workflows, browser sandboxes, mobile app sandboxes, and cloud workloads. When the kernel is the shared boundary, a local race in epoll can become the difference between a contained compromise and root.

