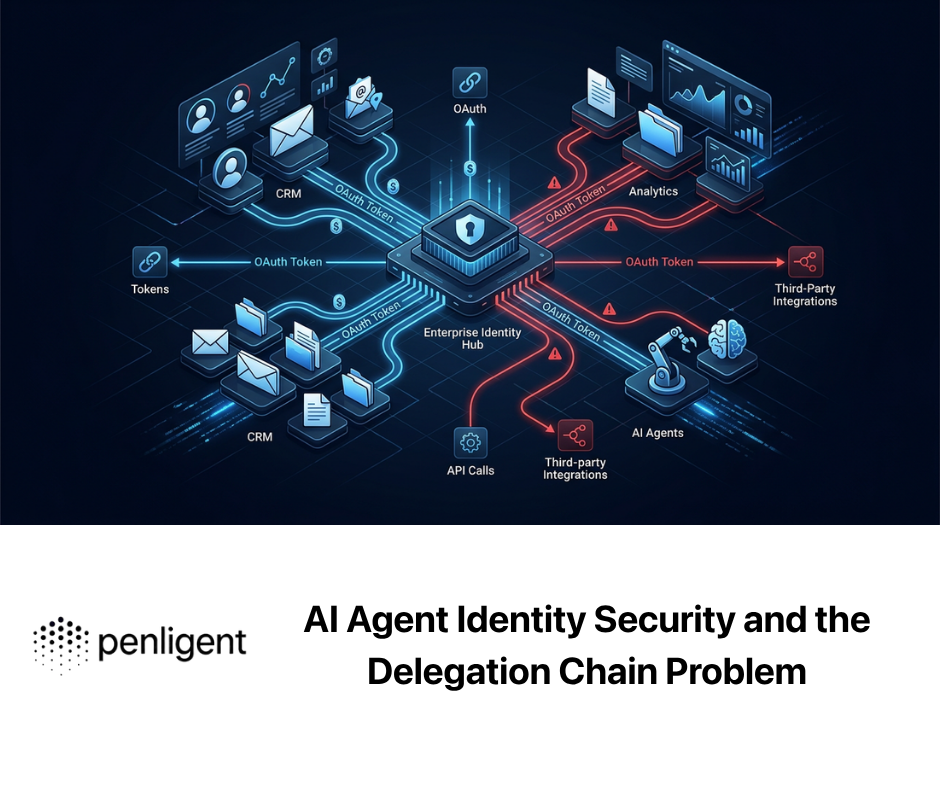
An AI agent can authenticate correctly, hold a valid token, call an approved tool, and still do something the business never intended. That is the uncomfortable part of AI agent identity security. The failure may not look like a stolen password or a perimeter breach. It may look like normal access, normal API traffic, normal tool execution, and normal logs. Only later does the team realize that the agent acted outside the task boundary, inherited the wrong authority, used a token in the wrong place, or lost the chain of accountability between the user’s original intent and the final action.
That difference changes the security model. Traditional identity systems are good at asking whether a subject is authentic, whether a session is valid, and whether a role or policy permits access to a resource. AI agents force security teams to ask a deeper question: what is this agent allowed to do right now, for this task, on behalf of which human or system, through which tools, under which policy, with what proof?
That question is now showing up across identity conferences, standards work, cloud platforms, OWASP guidance, OAuth discussions, MCP security advisories, and real CVEs. NIST launched an AI Agent Standards Initiative in February 2026 to support standards and open protocols for agents that act securely on behalf of users and interoperate across the digital landscape. (NIST) OWASP’s AI Agent Security Cheat Sheet puts the operational controls in plain language: apply least privilege to agent tools and permissions, validate external inputs, use human-in-the-loop for high-risk actions, isolate memory and context, monitor behavior, validate structured outputs, sign inter-agent communications, and classify data before agents can use it. (cheatsheetseries.owasp.org)
The practical lesson is simple but hard to implement: AI agent identity security is not just giving every agent an account. It is binding identity, ownership, intent, authorization, delegation, runtime context, and evidence into one governable chain.
Identiverse 2026 made agent identity a board-level security problem
GitGuardian’s recap of Identiverse 2026 captured the shift well. The event drew more than 3,800 identity professionals and more than 250 speakers, but the repeated theme was not another round of passwordless adoption or ordinary service account cleanup. The core issue was how enterprises should handle AI agents as they scale across ownership, delegation, least privilege, and auditability. (blog.gitguardian.com)
The useful framing from that conference is scale. A small number of internal bots can be handled by informal review. A few automation scripts can be tracked in a spreadsheet. A handful of service accounts can be mapped to applications. But AI agents do not scale like a handful of scripts. They can be created by developers, business teams, low-code platforms, copilots, support systems, data teams, and security teams. They can be short-lived or persistent. They can call tools. They can call other agents. They can run synchronously with a user in the loop or asynchronously after the user has gone offline.
That makes informal trust break down. At small scale, a team may remember who created a bot and what it does. At enterprise scale, the same organization may end up with orphaned agents, duplicated tool access, stale credentials, unknown owners, delegated permissions that no longer match the original purpose, and logs that say only that “the agent” made an API call.
The GitGuardian recap repeatedly returns to the same set of unresolved questions: who owns an agent when the employee who deployed it leaves, how should agent identity exist before production, why API keys are too blunt for delegation chains, why long-lived secrets should be eliminated rather than merely rotated, and why trust cannot be added later as an afterthought. (blog.gitguardian.com)
That matters because the AI agent is becoming a new kind of non-human actor. It is not exactly a human user. It is not exactly a service account. It is not exactly a deterministic workload. It can make model-time decisions, interpret context, choose tools, and chain actions. The identity system has to preserve accountability across that behavior.
| Boyut | Traditional service account | AI agent identity |
|---|---|---|
| Typical owner | Application team, platform team, or service owner | Named human owner plus system owner, because the agent can act with delegated intent |
| Execution pattern | Deterministic code path | Model-guided, context-sensitive, often tool-driven |
| Permission risk | Overbroad static permissions | Overbroad permissions plus task drift, prompt injection, tool misuse, and delegation chain loss |
| Credential pattern | Static secret, certificate, workload token, or cloud role | Runtime identity plus scoped, short-lived, task-bound authorization |
| Audit question | Which service called which resource | Which user or system initiated the goal, which agent acted, what tool path was used, and whether the action stayed in scope |
| Arıza modu | Stolen secret, misconfigured role, stale service account | Valid access used for an invalid action, unsafe delegation, invisible subagent, or poisoned tool context |
| Minimum viable control | Owner, least privilege, credential rotation, logging | Owner, independent agent identity, runtime attestation, scoped delegation, high-risk action gating, evidence chain |
The shift is not that old IAM has become irrelevant. The shift is that old IAM is no longer enough by itself.
The first identity question is ownership
Every production AI agent needs a named human owner. That sounds basic, but it is the control that everything else attaches to. Without an owner, the organization cannot answer who approves the agent’s tools, who reviews its permissions, who receives alerts, who responds when it behaves unexpectedly, who retires it, or who accepts the risk of its delegation paths.
Ownership should not be a decorative metadata field. It should be enforced in the agent lifecycle. An agent without an owner should not be allowed to reach production. An agent whose owner leaves the company should trigger review, reassignment, suspension, or retirement. An agent whose purpose changes should require owner approval and scope review. An agent that touches regulated data, financial operations, production systems, customer communications, or privileged infrastructure should have both a business owner and a technical owner.
A useful identity record should be concrete enough for security engineering, incident response, and audit teams. It should not be a vague catalog entry that says “customer support agent.” It should show what the agent is, who owns it, what it can do, where it runs, what tools it can call, how it authenticates, what data classes it can access, what approval gates apply, and when its authorization expires.
A minimal agent identity record might look like this:
{
"agent_id": "agent-prod-support-triage-0142",
"display_name": "Support Triage Agent",
"business_owner": "support-operations@example.com",
"technical_owner": "platform-ai@example.com",
"runtime": {
"environment": "production",
"platform": "kubernetes",
"namespace": "support-ai",
"workload_identity": "spiffe://prod.example.com/ns/support-ai/sa/support-triage-agent"
},
"model_context": {
"model_provider": "approved-provider",
"model_family": "enterprise-llm",
"agent_version": "2026.06.18",
"tool_policy_version": "support-tools-v7"
},
"allowed_tools": [
"ticket.search",
"ticket.classify",
"ticket.comment_internal",
"customer.lookup_limited"
],
"denied_tools": [
"ticket.delete",
"customer.export",
"payment.refund",
"email.send_external"
],
"delegation": {
"allowed_to_delegate": false,
"delegated_from": "support_user_session",
"requires_actor_chain": true
},
"authorization": {
"default_scopes": [
"tickets:read",
"tickets:comment_internal",
"customers:read_limited"
],
"max_token_ttl_seconds": 900,
"step_up_required_for": [
"customer:export",
"email:external",
"payment:refund"
]
},
"evidence": {
"log_stream": "agent-actions-prod",
"evidence_chain_required": true,
"retention_days": 365
},
"lifecycle": {
"created_at": "2026-06-15T10:22:00Z",
"last_reviewed_at": "2026-06-20T09:00:00Z",
"next_review_due": "2026-07-20T09:00:00Z",
"expiry": "2026-09-15T00:00:00Z"
}
}
This record does not solve the whole problem. It creates the control plane. It gives security teams something to evaluate, monitor, enforce, and revoke.
The worst production pattern is the opposite: a useful agent appears in Slack, a developer gives it a personal API key, the agent starts calling a tool server, another team copies the setup, the original developer changes roles, and nobody knows which credentials still exist. At that point, the security team is not governing AI agents. It is discovering them after the fact.
AI agent identity is not the same as human identity
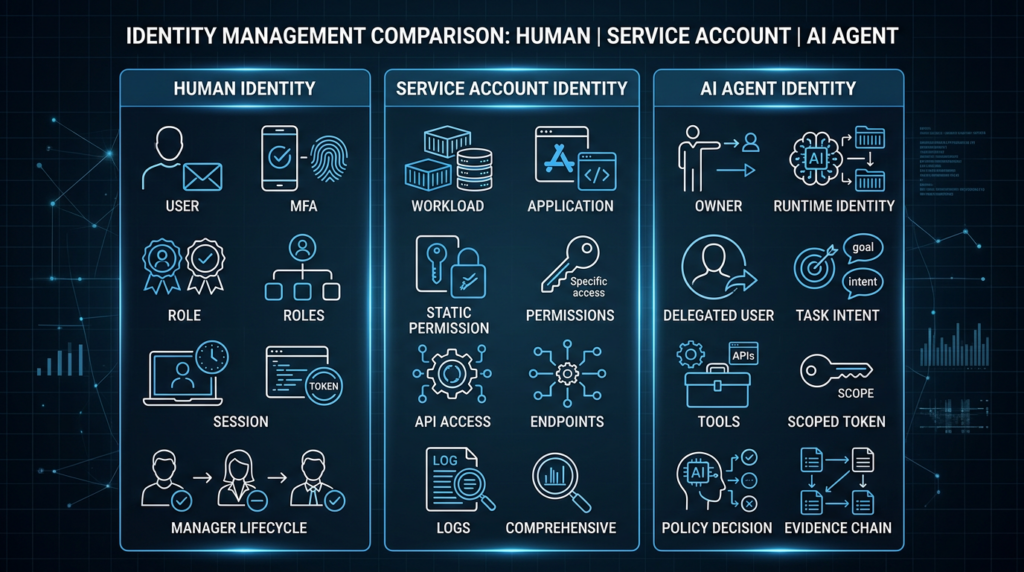
A human user has a body, an employment relationship, a legal identity, a manager, an HR lifecycle, an authentication ceremony, and a relatively stable intent model. None of that maps cleanly to an AI agent. An agent may be created from a template, modified by prompts, deployed into a container, connected to tools, delegated authority by a human, and then re-run under a scheduled workflow days later.
That is why treating an AI agent as just another user account creates confusion. Human access reviews ask whether Alice still needs access to Salesforce. Agent access reviews have to ask whether a particular agent version, running in a particular environment, with a particular tool set, should be allowed to perform a specific class of actions under a specific delegated purpose.
The same problem appears if the agent is treated as only a workload. A workload identity can prove that code is running in an expected environment. That is necessary, but it does not prove that the action is semantically appropriate. A Kubernetes service account token can show that a pod is authorized to call an API. It does not show whether the agent’s tool call was caused by a user request, a poisoned web page, a misleading document, or an over-eager planning step.
That is the core identity gap. AI agent identity security has to combine at least five layers:
| Katman | Security question | Example control |
|---|---|---|
| Agent registration | Is this a known agent with an approved owner and purpose | Agent inventory, owner approval, production gate |
| Runtime identity | Is the agent running in the expected environment | Workload identity, attestation, SPIFFE ID, cloud workload identity |
| Delegated authority | Who or what authorized this action | OAuth delegation, actor chain, transaction token, approval record |
| Task context | What task is this action supposed to serve | Intent record, task ID, policy decision, tool-level scope |
| Kanıtlar | Can the action be reconstructed after the fact | Structured logs, signed events, immutable evidence chain |
Without all five layers, logs become ambiguous. A line that says agent-prod-support-triage-0142 called customer.lookup may be true, but it is not enough. Security teams need to know whether the call was made for a real ticket, whether the user had permission to initiate it, whether the agent was allowed to use that tool for that class of customer data, whether the token was scoped to the task, and whether any downstream action expanded the original grant.
Non-human identity governance has to become more dynamic
Non-human identities are not new. Enterprises already manage service accounts, automation users, CI/CD runners, cloud workloads, Kubernetes service accounts, OAuth clients, API integrations, robotic process automation bots, and machine-to-machine credentials. The problem is that AI agents combine several of those patterns and add a reasoning layer.
A CI/CD runner executes pipeline logic. A service account authenticates an application. An OAuth client requests access on behalf of a user. A cloud workload assumes a role. An AI agent may do all of those in one workflow. It may authenticate as a workload, receive delegated user authority, call an MCP server, invoke a tool, generate code, write a file, send a message, and ask another agent to complete a subtask.
That makes identity lifecycle harder. If an ordinary service account is overprivileged, the risk is real but bounded by the code paths that use it. If an AI agent is overprivileged, the risk includes code paths, tool paths, natural-language instructions, retrieved content, model behavior, memory, and delegation.
Workload identity is still one of the strongest foundations because it removes static secrets from the agent runtime. Google Cloud’s managed workload identities bind strongly attested identities to GKE and Compute Engine workloads and explicitly include agent identities for agentic workloads. The same documentation shows SPIFFE-formatted identities for GKE workloads and agent identity workloads. (Google Cloud Documentation) SPIFFE and SPIRE provide another important model: a workload receives an identity based on registration entries and selectors, and SPIRE performs node and workload attestation before issuing the appropriate identity. (spiffe.io)
Kubernetes has also moved away from long-lived service account secrets. Its documentation recommends the TokenRequest API and token volume projection for short-lived service account tokens that expire and rotate automatically, and warns that long-lived bearer tokens stored as Secrets are not recommended, especially at scale. (Kubernetes)
The lesson for AI agents is direct. Do not put permanent API keys into agent configuration. Do not let agents inherit developer secrets from .env files. Do not use a shared service account for every agent in an environment. Do not let tool servers read broad credentials from the same runtime context unless the tools are isolated and the broker enforces policy.
A safer pattern is to let the agent prove its runtime identity, then obtain a short-lived, audience-bound, scope-limited token for the specific task.
For Kubernetes-based agents, projected service account tokens show the principle:
apiVersion: v1
kind: Pod
metadata:
name: support-triage-agent
namespace: support-ai
spec:
serviceAccountName: support-triage-agent
containers:
- name: agent
image: registry.example.com/support-triage-agent:2026.06.18
volumeMounts:
- name: agent-api-token
mountPath: /var/run/secrets/agent
readOnly: true
env:
- name: AGENT_TOKEN_FILE
value: /var/run/secrets/agent/token
volumes:
- name: agent-api-token
projected:
sources:
- serviceAccountToken:
path: token
audience: "support-api"
expirationSeconds: 900
This does not make the agent safe by itself. It does remove one dangerous default: a permanent credential sitting inside the environment. The token is short-lived, scoped to an intended audience, and rotated by the platform. From there, a credential broker or authorization service can issue even narrower tokens for downstream tools.
| Credential pattern | Why teams use it | Main risk for agents | Better direction |
|---|---|---|---|
| Static API key in environment variable | Easy setup, widely supported | Long-lived bearer authority, easy leakage, hard to bind to task intent | Replace with workload identity and runtime-issued tokens |
| Shared service account | Simple operations model | Multiple agents become indistinguishable in logs | Per-agent identity with owner and scope |
| User token passthrough | Preserves user access quickly | Downstream services cannot distinguish user action from agent action | Delegated token with actor chain and narrowed scope |
| OAuth delegated token | Better user consent model | Still too broad if reused across transactions | Short-lived, audience-bound, task-bound tokens |
| SPIFFE workload identity | Strong runtime identity | Identifies workload but not always user intent | Combine with policy decision and delegation record |
| Transaction-bound token | Captures specific action context | Requires infrastructure changes | Use for high-risk actions and cross-service chains |
API keys were not designed for delegation chains
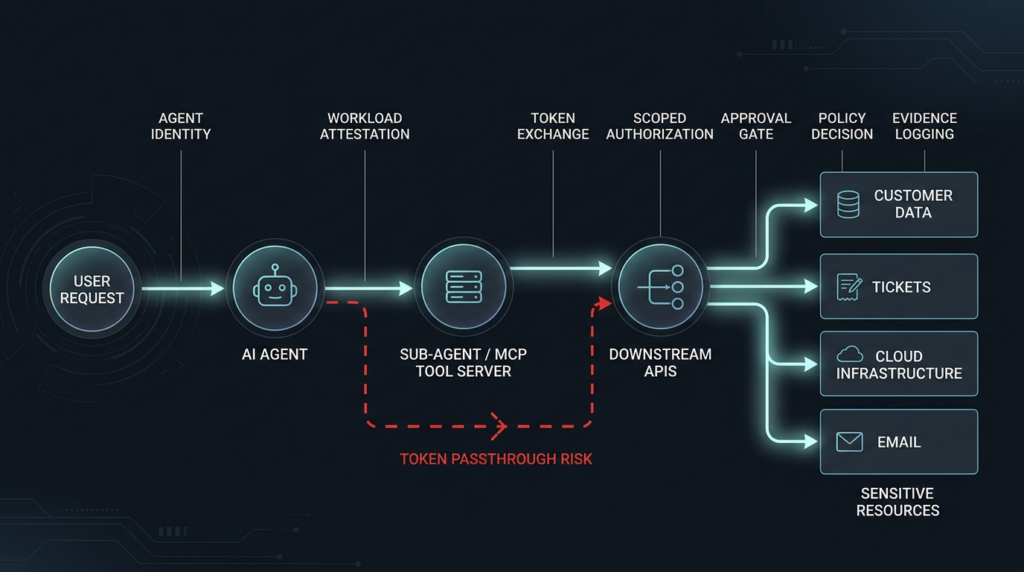
API keys work poorly for AI agent identity security because they usually compress too much authority into one string. They do not reliably express who initiated an action, which agent acted, what task was approved, which downstream service is the intended audience, which part of the scope was reduced, whether the grant can be revoked mid-workflow, or whether the action is still inside the user’s original intent.
That weakness becomes severe when agents delegate. Imagine a user asks an internal research agent to summarize open support tickets. The research agent calls a ticketing MCP server. The MCP server calls a customer database. The agent then asks a document-generation subagent to prepare a summary. The subagent calls an email tool to send a draft. If every hop uses a static key or a broad service token, the organization loses the chain. It may know that a token called an API. It may not know whether the action was properly delegated.
OAuth 2.0 Token Exchange exists because cross-domain and delegated token use cases are real. RFC 8693 defines a protocol for requesting and obtaining security tokens from OAuth authorization servers, including tokens using impersonation and delegation. (rfc-editor.org) That idea matters for agent systems because a token at one boundary is often too broad for the next boundary. A service or agent may need to exchange a received token for a new token with a narrower audience, narrower scope, or clearer delegation context.
The current IETF AI Agent Authentication and Authorization draft shows how standards work is moving toward agent-specific patterns. It describes an agent acting as an OAuth client to an authorization server, a user delegating authorization to an agent through an authorization code flow, and the agent authenticating itself directly rather than relying on static, long-lived client secrets. It also discusses transaction tokens that pass identity, authorization information, caller context, transaction context, and a unique transaction identifier through an internal call chain, producing a downscoped token bound to a specific transaction. (datatracker.ietf.org)
A simplified token exchange flow might look like this:
curl -s https://auth.example.com/oauth/token \
-u "agent-prod-support-triage-0142:${AGENT_CLIENT_ASSERTION}" \
-H "Content-Type: application/x-www-form-urlencoded" \
-d "grant_type=urn:ietf:params:oauth:grant-type:token-exchange" \
-d "subject_token=${USER_DELEGATED_TOKEN}" \
-d "subject_token_type=urn:ietf:params:oauth:token-type:access_token" \
-d "actor_token=${AGENT_WORKLOAD_TOKEN}" \
-d "actor_token_type=urn:ietf:params:oauth:token-type:jwt" \
-d "audience=https://tickets.example.com" \
-d "scope=tickets:read tickets:comment_internal" \
-d "requested_token_type=urn:ietf:params:oauth:token-type:access_token"
The exact parameters depend on the identity provider and implementation, but the security goal is stable: the downstream token should not be a copy of the user’s broad session. It should be a new grant that says, in effect, “this specific agent is acting on behalf of this subject, for this audience, with this limited scope, for this limited time.”
The opposite pattern is token passthrough. MCP’s own security best practices call out token passthrough, confused deputy conditions, SSRF, session hijacking, local MCP server compromise, OAuth authorization URL validation, stdio transport risks, and scope minimization as concrete implementation concerns. (Model Bağlam Protokolü) The MCP authorization specification also says authorization is optional for implementations, defines the authorization flow for HTTP-based transports, and says stdio transport implementations should not follow that authorization flow but retrieve credentials from the environment. (Model Bağlam Protokolü) That is a workable specification boundary, but it is also where many enterprise mistakes begin. A team may assume “MCP has auth,” while a local stdio tool is reading credentials from environment variables and passing authority across a path nobody reviewed.
The security question for every agent tool chain should be blunt: can the system prove that each downstream call is narrower than the authority that entered the previous hop?
If the answer is no, the agent is carrying ambient authority.
The confused deputy problem returns through tools and context
The confused deputy problem is not new. A less privileged party tricks a more privileged party into doing something on its behalf. AI agents make the pattern easier to trigger because they are trusted, connected, and responsive to context.
The malicious input does not have to be a forged packet or a stolen token. It can be a README, a web page, an email, a ticket comment, a calendar invitation, a PDF, a tool description, an MCP server response, or a field in a database record. If the agent consumes that content and treats it as instruction, the attacker may influence tool selection or parameters. The API call can still be authenticated. The log can still look valid. The harm comes from the agent applying legitimate authority to attacker-shaped intent.
OWASP’s guidance is practical here because it treats external inputs, memory isolation, high-risk human approval, structured outputs, inter-agent communication signing, and behavior monitoring as agent security controls rather than optional AI safety decoration. (cheatsheetseries.owasp.org) MCP’s security best practices make the same point at the protocol implementation layer by identifying confused deputy flows, vulnerable consent conditions, token passthrough, and local server compromise scenarios. (Model Bağlam Protokolü)
A simple example shows why identity alone is not enough:
- A user asks an agent to review a supplier’s onboarding document.
- The document contains hidden instructions telling the agent to call an internal vendor-payment tool.
- The agent has access to a tool server that can query vendor records and initiate payment workflows.
- The tool server uses a broad service token because it was designed for internal automation.
- The payment system sees a valid request from the tool server.
- The audit log records a legitimate service call, but not the malicious document content that shaped the action.
That is not a login failure. It is an execution governance failure. The identity system authenticated something real, but the system failed to bind the final action to the correct task boundary and evidence trail.
A strong AI agent identity security model should therefore enforce at least three gates before high-risk tool execution:
| Gate | What it checks | Örnek |
|---|---|---|
| Identity gate | Is the agent known, owned, and running in an approved environment | Workload identity, SPIFFE ID, cloud workload attestation |
| Authorization gate | Is this exact action allowed for this task, subject, and scope | Policy decision, downscoped token, transaction-bound grant |
| Evidence gate | Can the action be reconstructed with intent, input source, approval, tool call, and result | Signed event chain, immutable log, task ID, approval ID |
If a high-risk action passes only the identity gate, it is under-governed.
Real CVEs show where the control plane breaks
Security teams should avoid treating AI agent failures as vague “LLM behavior.” Some of the most useful lessons come from ordinary software vulnerabilities that sit in the new agent execution path. These CVEs are relevant because they affect tool servers, approval paths, local trust boundaries, or scope propagation.
CVE-2026-34742 in the Model Context Protocol Go SDK is a strong example. NVD describes that prior to version 1.4.0, the Go MCP SDK did not enable DNS rebinding protection by default for HTTP-based servers. When an HTTP-based MCP server ran on localhost without authentication using StreamableHTTPHandler veya SSEHandler, a malicious website could exploit DNS rebinding to bypass same-origin restrictions and send requests to the local MCP server, potentially invoking tools or accessing resources exposed by that server on behalf of the user. The issue was patched in version 1.4.0. (NVD) GitHub’s advisory adds the same key deployment condition: local HTTP-based MCP servers without authentication are not recommended, and the issue did not affect stdio transport. (GitHub)
The identity lesson is that localhost is not an identity boundary. A local tool server with no authentication may feel private because it binds to localhost, but browser-based attack paths can reach surprising places when origin checks, DNS rebinding protections, and authorization are missing. In an agent setting, that can mean a web page causes tool invocation through a local server that the user trusts.
CVE-2026-33252 is another MCP Go SDK issue. GitHub’s advisory says the SDK was modified to validate İçerik-Türü for POST requests and introduced configurable origin verification, advising users to update to v1.4.1. (GitHub) The risk pattern is easy to understand: if a browser-generated cross-site request reaches an MCP message handler without the right origin and content-type checks, an attacker may be able to trigger tool execution in deployments that lack Authorization.
The identity lesson is that request provenance matters. It is not enough for a tool server to know that a message is syntactically valid MCP traffic. It must know where the request came from, whether the request is authorized, whether the content type is expected, whether the action requires a user or agent identity, and whether the request is bound to an approved task.
CVE-2026-33579 in OpenClaw shows the danger of scope propagation errors. NVD describes that OpenClaw before 2026.3.28 contained a privilege escalation vulnerability in the /pair approve path because caller scopes were not forwarded into the core approval check. A caller with pairing privileges but without admin privileges could approve pending device requests asking for broader scopes, including admin access. NVD maps the issue to CWE-863, incorrect authorization. (NVD)
The identity lesson is that approval flows are security-critical code. If an agent platform has a pairing flow, device approval flow, tool approval flow, or subagent approval flow, the caller’s scope must travel into the final decision point. Losing scope at the approval boundary is exactly how a low-authority actor becomes a high-authority actor through a legitimate-looking workflow.
| CVE | Where the identity model failed | Exploitation condition | Defensive action |
|---|---|---|---|
| CVE-2026-34742 | Local MCP server trust and tool authority were exposed through missing DNS rebinding protection | HTTP-based MCP server on localhost without authentication in affected versions | Update to patched versions, require authentication, enforce origin protection, avoid treating localhost as a trust boundary |
| CVE-2026-33252 | Cross-site request provenance was not sufficiently validated before MCP message handling | Streamable HTTP transport accepted browser-generated cross-site requests in affected versions and unsafe deployments | Update to v1.4.1 or later, validate Origin and Content-Type, require Authorization for tool execution |
| CVE-2026-33579 | Caller scopes were not preserved into the approval decision | Caller with pairing privilege but without admin privilege could approve broader requested scopes | Upgrade to fixed version, test approval paths for scope forwarding, log requester scope and requested scope at every approval gate |
None of these examples requires science fiction. They are web security, authorization, and scope-validation failures placed inside agent infrastructure. That is why they matter.
A defensible architecture starts before the first tool call
The safest moment to govern an agent is before it can call a tool. Once the agent has a broad token and a live tool catalog, every control becomes harder. The minimum production architecture should make unsafe paths impossible or at least visible.
A workable design has six components.
First, every agent must be registered. The registry should include owner, runtime, version, purpose, allowed tools, denied tools, data classes, token policy, delegation policy, approval requirements, and expiry. Registration should happen before production, not after discovery.
Second, every agent should authenticate as itself. It should not rely on a human’s long-lived token or a shared .env secret. Workload identity, SPIFFE, cloud workload identity, or equivalent runtime-issued credentials should prove that the agent is running where it is supposed to run.
Third, every delegated action should carry actor context. If a user delegates a task to an agent, the downstream service should not see only the user or only the agent. It should be able to see that the agent is acting on behalf of a user, under a specific grant, for a specific task. Impersonation can be useful in some systems, but it is dangerous when it erases the acting party. Delegation should preserve both identities.
Fourth, every high-risk action should require step-up. Deleting records, sending external email, initiating payment, modifying access control, exporting customer data, changing production configuration, and running shell commands should not be treated like read-only lookup. They need explicit policy, risk scoring, and often human approval.
Fifth, every tool should be scoped as if it will be misused. Tool descriptions, metadata, parameters, and outputs are part of the security boundary. If an agent can call a tool, assume that untrusted context may influence that call. That means validation belongs at the tool server and resource server, not only in the prompt.
Sixth, every important action should produce evidence. A log line is not enough if it cannot reconstruct the original intent, user, agent, token exchange, policy decision, tool call, response, and final state change.
A policy engine can make this concrete. For example, an OPA/Rego policy can require approval and task scope for destructive tool calls:
package agent.authz
default allow := false
high_risk_tools := {
"ticket.delete",
"customer.export",
"payment.refund",
"email.send_external",
"iam.grant_role",
"production.deploy"
}
allow {
input.agent.registered == true
input.agent.owner != ""
input.runtime.attested == true
input.token.audience == input.tool.expected_audience
input.token.expires_in_seconds <= 900
input.task.id != ""
not high_risk_tools[input.tool.name]
input.tool.name == allowed_tool
allowed_tool := input.agent.allowed_tools[_]
}
allow {
input.agent.registered == true
input.agent.owner != ""
input.runtime.attested == true
input.token.audience == input.tool.expected_audience
input.token.expires_in_seconds <= 300
input.task.id != ""
input.approval.id != ""
input.approval.approved_by != input.agent.id
input.approval.risk_level == "high"
high_risk_tools[input.tool.name]
input.tool.name == allowed_tool
allowed_tool := input.agent.allowed_tools[_]
}
This example is intentionally simple. A production policy would include data classification, user role, business purpose, risk score, geo, device posture, anomaly signals, and resource sensitivity. The important idea is not the syntax. The important idea is that agent authorization must become a runtime decision, not a static permission assigned once and forgotten.
Evidence chains are the difference between logs and accountability
Most systems have logs. Few have evidence chains. An evidence chain is not just a record that an API call happened. It is a reconstructible path from initiating intent to final action.
For AI agent identity security, a useful evidence event should include at least:
{
"event_type": "agent_tool_call",
"event_time": "2026-06-26T02:14:08Z",
"evidence_chain_id": "evc_9f3a7c2d",
"task": {
"task_id": "task_4811",
"user_intent_summary": "Summarize open P1 support tickets for internal review",
"source_channel": "support-console",
"risk_level": "medium"
},
"subject": {
"user_id": "user_92841",
"user_role": "support_manager",
"tenant_id": "tenant_104"
},
"actor": {
"agent_id": "agent-prod-support-triage-0142",
"agent_version": "2026.06.18",
"owner": "support-operations@example.com",
"runtime_identity": "spiffe://prod.example.com/ns/support-ai/sa/support-triage-agent"
},
"delegation": {
"grant_id": "grant_7de21",
"delegated_by": "user_92841",
"scope": ["tickets:read", "tickets:comment_internal"],
"audience": "https://tickets.example.com",
"expires_at": "2026-06-26T02:29:08Z"
},
"policy": {
"policy_id": "agent-tool-policy-v12",
"decision": "allow",
"reason": "read-only ticket lookup within approved scope"
},
"tool": {
"tool_name": "ticket.search",
"tool_server": "mcp-ticket-prod",
"tool_server_version": "1.4.1",
"parameters_hash": "sha256:7b7b2f..."
},
"result": {
"status": "success",
"records_returned": 12,
"sensitive_fields_redacted": true
}
}
This kind of event lets an engineer debug a failure, an auditor validate control operation, and an incident responder reconstruct blast radius. It also lets detection rules reason about agent behavior instead of only token usage.
For example, a detection query might look for high-risk tool calls where approval is missing:
SELECT
event_time,
actor.agent_id,
actor.owner,
subject.user_id,
tool.tool_name,
task.task_id,
policy.decision
FROM agent_evidence_events
WHERE event_type = 'agent_tool_call'
AND tool.tool_name IN (
'ticket.delete',
'customer.export',
'payment.refund',
'email.send_external',
'iam.grant_role',
'production.deploy'
)
AND (
approval.id IS NULL
OR delegation.expires_at < event_time
OR policy.decision != 'allow'
)
ORDER BY event_time DESC;
Another query might look for audience confusion:
SELECT
event_time,
actor.agent_id,
tool.tool_name,
delegation.audience AS token_audience,
tool.expected_audience
FROM agent_evidence_events
WHERE event_type = 'agent_tool_call'
AND delegation.audience != tool.expected_audience;
These detections require structured evidence. If the organization logs only raw HTTP requests and model outputs, it will struggle to answer the questions that matter after an incident.
Defensive validation should test identity, not just prompts
Many AI security tests still focus too heavily on prompt behavior. Prompt injection matters, but agent risk is larger than whether the model says something unsafe. The real question is whether hostile input can cause the agent to use real authority incorrectly.
A practical AI agent identity security validation workflow should test the entire chain.
Start with inventory. List every production and pre-production agent, owner, environment, model version, tool server, external API, token source, data class, and schedule. Include agents created through low-code platforms, internal copilots, workflow automation, CI/CD, support tools, and developer environments.
Verify identity binding. Confirm that each agent has its own identity and does not reuse a human token, shared service account, long-lived API key, or unmanaged secret. Check runtime attestation where available.
Review scopes by tool. Each tool should have a declared purpose, expected audience, allowed data classes, allowed methods, denied methods, and high-risk action list. A read-only agent should not have a token that can write, delete, export, or grant access.
Trace delegation. Walk through user-to-agent, agent-to-tool, tool-to-API, and agent-to-agent paths. At each hop, verify that the original subject, acting agent, scope, task, and approval status are preserved or intentionally transformed.
Test token lifecycle. Confirm token expiry, rotation, revocation, audience restriction, replay resistance, and behavior after owner removal. A revoked grant should stop the workflow, not silently fall back to a broader credential.
Attack the approval boundary. Try lower-privilege actors requesting higher-privilege scopes. Try stale approval IDs. Try duplicated approval IDs. Try approval for one resource reused on another. Try approval for a read task used for a write action. CVE-2026-33579 is a reminder that approval paths are easy places to lose caller scope. (NVD)
Attack local tool servers. Test browser-origin requests, DNS rebinding assumptions, localhost exposure, unauthenticated endpoints, content-type validation, and Origin validation. CVE-2026-34742 and CVE-2026-33252 show that local MCP servers and Streamable HTTP transports need web security discipline, not just agent trust. (NVD)
Test confused deputy scenarios. Place hostile instructions in documents, tickets, web pages, emails, tool descriptions, MCP server responses, and database fields. The goal is not to see whether the model repeats the instruction. The goal is to see whether the instruction changes tool selection, tool parameters, data access, or downstream actions.
Validate evidence. For every high-risk test, confirm that the evidence chain records user intent, input source, agent identity, delegated grant, token exchange, policy decision, tool call, output, and final state change.
Retest after changes. Agents change when models, prompts, tools, policies, MCP servers, skills, data sources, and runtime environments change. Identity controls need regression tests just like application security controls.
For teams running authorized security testing across agentic workflows, MCP-connected tools, web applications, and APIs, the same principle applies: unverified findings should not become final risk claims. Penligent’s AI pentesting workflow is designed around black-box testing, independent sub-agent validation, headless browser verification, human-in-the-loop control, evidence capture, and editable reports for verified findings. (Penligent) That style of workflow is useful when security teams need to prove whether an agentic path can actually cross a boundary, not merely speculate that it might. Penligent also has a focused technical discussion on why AI agent security extends beyond IAM into post-authentication execution governance. (Penligent)
The important constraint is authorization. Agent security testing should be performed only against systems the team owns or has explicit permission to assess. The purpose is to validate controls, reduce false positives, and create evidence before production risk becomes incident response.
A 90-day control plan for AI agent identity security
A mature program will take longer than 90 days, but 90 days is enough to stop the worst patterns from spreading.
Days 1 to 15, find the agents and credentials
Start with discovery. Search code repositories, CI/CD variables, Kubernetes namespaces, cloud IAM roles, OAuth clients, MCP server configs, low-code automation platforms, browser extensions, internal copilots, Slack apps, support bots, and endpoint processes. Look for names like agent, assistant, copilot, mcp, tool-server, otomasyon, bot, iş akışıve ai.
The goal is not perfect classification on day one. The goal is to find running agents and the credentials they use. Any agent using a personal token, shared API key, broad service account, or long-lived secret should be flagged for review.
Days 16 to 30, require ownership and purpose
Create a production rule: no agent without an owner, purpose, environment, tool list, and expiry. Agents with unknown owners should be suspended, isolated, or moved into a review queue. New agents should be registered before they can receive production credentials.
Use the registration process to force hard questions:
| Question | Neden önemli |
|---|---|
| Who owns this agent | Alerts, approvals, access reviews, and incident response need an accountable person |
| What task does it perform | Scope cannot be evaluated without purpose |
| What tools can it call | Tool access defines the execution boundary |
| What data can it see | Data classification drives policy |
| Can it delegate | Delegation changes blast radius |
| What actions require approval | High-risk actions need stronger controls |
| When does access expire | Stale agents become invisible risk |
Days 31 to 50, remove static credentials from the highest-risk paths
Start with agents that can write, delete, export, deploy, send, approve, or grant access. Replace static secrets with runtime-issued credentials where possible. Use workload identity for the agent runtime. Use OAuth delegated flows where the agent acts on behalf of a user. Use token exchange or brokered credentials for downstream services. Reduce TTLs. Bind tokens to audiences. Stop passing broad access tokens through tool chains.
This is also the right time to remove credentials from MCP server environments unless the server is properly isolated and policy-gated. A tool server with access to a broad credential is a privileged component, not a neutral integration layer.
Days 51 to 70, enforce high-risk action gates
Define high-risk actions in business language and technical policy. Examples include:
| Action class | Örnekler | Required control |
|---|---|---|
| Data export | Export customer list, download mailbox, retrieve secrets | Step-up approval, DLP, redaction, evidence chain |
| External communication | Send email, post to Slack channel, contact customer | Human review or policy-based approval |
| Financial operation | Refund, transfer, invoice change | Strong user confirmation, transaction-bound token |
| Erişim kontrolü | Add user, grant role, approve device pairing | Separate approver, scope validation, immutable log |
| Production change | Deploy, modify firewall, restart service | Change ticket, environment policy, rollback evidence |
| Kod yürütme | Shell command, script generation, remote tool execution | Sandbox, allowlist, network egress policy, output inspection |
A confirmation button is not enough. The approval must be bound to the action, resource, scope, amount, destination, and expiry. Otherwise it becomes a reusable blessing.
Days 71 to 90, test delegation and evidence
Run adversarial tests against the agent workflows. Do not stop at prompt jailbreaks. Test whether a malicious document can change tool parameters. Test whether a lower-privilege agent can obtain a higher-privilege token. Test whether a subagent can act without preserving the original subject. Test whether a local MCP server accepts browser-origin requests. Test whether revocation stops an in-flight workflow. Test whether logs can reconstruct the full action.
The measurable goal by day 90 is not “all agent security solved.” A realistic goal is this:
- Every production agent has a named owner.
- High-risk agents no longer use static credentials.
- High-risk actions require scoped, time-limited authorization.
- Delegation chains preserve subject and actor context.
- MCP and tool servers require authentication and request validation.
- Evidence exists for important actions.
- Regression tests cover the top identity and delegation failures.
That is enough to move from unknown risk to governed risk.
Common mistakes that keep breaking agent identity
The first common mistake is treating the agent as a normal service account. That hides the fact that the agent may make model-guided decisions, consume untrusted context, choose tools, and delegate. A service account model may prove which workload called an API, but it does not prove why the action was taken or whether it stayed within intent.
The second mistake is using static API keys because they make demos easy. Static keys are fast to paste into a config file and hard to govern later. They often lack task context, actor context, audience restriction, short TTL, and revocation behavior. They also spread through logs, screenshots, developer machines, and copied examples.
The third mistake is trusting localhost. Local servers are still exposed to browser-origin risks, DNS rebinding patterns, weak local authentication, and cross-site request paths. CVE-2026-34742 is a useful reminder that localhost without authentication should not be treated as safe just because it is local. (GitHub)
The fourth mistake is letting the MCP server become a privilege laundering layer. If the MCP server holds a broad credential and the agent can trigger tools through it, the server becomes the place where user intent, agent identity, and downstream authority must be enforced. If the MCP server simply forwards calls, it may erase the most important context.
The fifth mistake is logging the wrong thing. Raw prompts, HTTP requests, or tool outputs are not enough. Security teams need structured evidence that links subject, actor, task, grant, policy, tool, and result.
The sixth mistake is treating human-in-the-loop as a UX feature instead of a security control. A human approval step should be risk-based, action-specific, scope-bound, and logged. A vague “Are you sure?” prompt does not prove that the user approved the actual downstream action.
The seventh mistake is failing to retire agents. Agent lifecycle must include owner departure, project shutdown, model replacement, tool deprecation, credential rotation, and scope expiry. Orphaned agents are not hypothetical. They are the natural result of fast adoption without lifecycle management.
The eighth mistake is assuming guardrails replace authorization. Prompt rules can reduce some unsafe behavior, but they do not replace policy enforcement at the tool server, credential broker, resource server, and approval boundary. Agents need guardrails and hard controls.
SSS
What is AI agent identity security?
- AI agent identity security is the practice of identifying, authenticating, authorizing, monitoring, and retiring AI agents as distinct non-human actors.
- It is not limited to login or API access. It must connect the agent’s identity to its owner, runtime, tools, delegated user, task context, scopes, approvals, and evidence.
- A strong model should answer: which agent acted, on whose behalf, under which grant, through which tool, for what purpose, and with what result.
How is an AI agent identity different from a service account?
- A service account usually represents a deterministic application or workload.
- An AI agent may interpret goals, choose tools, consume untrusted context, call subagents, and act asynchronously.
- A service account identity can prove which workload made a request, but it may not preserve user intent, delegated authority, task boundaries, or reasoning-influenced tool choices.
- AI agents often need both workload identity and task-bound authorization.
Why are static API keys risky for AI agents?
- Static API keys are usually long-lived bearer credentials.
- They often do not show which user delegated the action or which agent performed it.
- They are difficult to scope per task, per audience, and per transaction.
- If leaked or copied into an agent environment, they can grant the agent or an attacker broad authority for longer than the task requires.
- Runtime-issued, short-lived, scoped tokens are safer for production agent workflows.
What should be logged in an agent delegation chain?
- The initiating user or system.
- The acting agent identity and version.
- The task or intent record.
- The delegated grant, scope, audience, and expiry.
- Any token exchange or scope reduction.
- The policy decision and approval record.
- The tool server, tool name, parameters, and result.
- The downstream API action and final state change.
- Enough evidence to reconstruct the path without relying on the model’s own explanation.
How do MCP vulnerabilities relate to AI agent identity security?
- MCP connects agents to tools and data sources, so MCP servers often sit directly on the execution path.
- If an MCP server lacks authentication, origin validation, content-type checks, scope enforcement, or safe token handling, an attacker may trigger tool execution through a path that looks legitimate.
- CVE-2026-34742 and CVE-2026-33252 show how local or HTTP-based MCP implementations can expose tool execution through web-origin request problems when deployments are unsafe or unpatched. (NVD)
- MCP security should be evaluated as part of the agent’s identity and authorization chain, not as a separate integration detail.
Should every AI agent have a human owner?
- Yes, every production AI agent should have a named human owner.
- The owner is responsible for purpose, scope review, access approval, incident response, and retirement.
- High-risk agents should also have a technical owner and a business owner.
- If the owner leaves or changes roles, the agent should be reassigned, suspended, or reviewed before continuing production activity.
Is workload identity enough to secure AI agents?
- No. Workload identity is necessary but not sufficient.
- It can prove that an agent is running in an approved environment.
- It does not automatically prove that a specific action matches user intent, task scope, or downstream policy.
- It should be combined with delegated authorization, transaction-bound tokens, tool policy, high-risk action gates, and evidence logging.
How should teams test AI agent identity controls before production?
- Build an inventory of agents, tools, credentials, owners, and data access.
- Test whether each agent has a distinct identity and avoids static credentials.
- Try to force scope expansion through approval flows, pairing flows, subagents, and tool brokers.
- Test prompt injection and tool poisoning as ways to influence real tool calls, not just model output.
- Verify token expiry, revocation, audience binding, and replay resistance.
- Confirm that evidence logs can reconstruct the complete user-to-agent-to-tool-to-resource path.
Visible controls for the invisible workforce
AI agents are becoming an invisible workforce inside enterprise systems. They read, plan, call tools, transform data, write messages, change state, and delegate work. That makes identity more important, not less.
The minimum viable path is clear. Every agent needs a named owner. Every production agent needs an independent identity. Every high-risk action needs scoped, short-lived, revocable authorization. Every delegation chain needs to preserve subject and actor context. Every tool server needs authentication, validation, and least privilege. Every important action needs evidence that can be reconstructed after the fact.
The hard part is not naming the problem. The hard part is refusing the easy shortcut: a broad token, a trusted local server, a shared service account, a confirmation button, and a log line that proves only that something happened. AI agent identity security begins when the organization can prove not only that an agent acted, but that it was the right agent, acting for the right reason, with the right authority, inside the right boundary.