You can feel the split in the room: half the team is grinning because automated scans mean faster coverage; the other half is frowning because automation also makes mistakes at enterprise scale. Drop sqlmap into an AI-driven pipeline and that split becomes a chasm. You get reach and repeatability — and also the potential to run noisy or unauthorized scans with a single, casual prompt.
This isn’t a moral panic. It’s a practical tension. sqlmap is a tool: mature, blunt, and very good at surfacing injection signals. If you let a model spin up a sqlmap job and then forget about what it did, you’ll see three outcomes in practice:
Useful discoveries where an injection probe highlights a real logic flaw;
• False positives that waste analyst hours;
• And the occasional operational hiccup when a scan hits production unexpectedly.
The interesting bit is not whether tools like sqlmap are good or bad — they are — but how you stitch them into a pipeline that keeps human judgment and governance in the loop. That’s where the debate gets juicy: should we trust AI to write and run scanner commands? Or should AI be treated like a junior analyst that proposes tests, with humans giving final sign-off?
Below I sketch a balanced perspective, with a minimal, safe code module to show how automation should look (non-exploit, orchestration only), plus the practical guardrails you actually need.
A high-level orchestration
Think of this as the plumbing that should sit between your AI prompt and any scanner. It never contains exploit payloads — just intent, scope, and analysis steps.
# pseudo-orchestration: AI suggests tests, system enforces policy, analyzer triages
def request_scan(user_prompt, target_list):
intent = ai_interpret(user_prompt) # e.g., "check for SQLi risk"
scope = policy.enforce_scope(target_list, intent)
if not scope.authorized:
return "Scan not authorized for requested targets."
job = scheduler.create_job(scope, mode="non-destructive")
# scanner is invoked through a controlled runner that enforces rules
run = scanner_runner.execute(job, scanner="sqlmap-wrapper", safe_mode=True)
telemetry = collector.gather(run, include_logs=True, include_app_context=True)
findings = analyzer.correlate(telemetry, ruleset="multi-signal")
report = reporter.build(findings, prioritize=True, require_human_review=True)
return report
Notes on the pseudo-code above:
The sqlmap-wrapper is a conceptual layer that enforces non-destructive modes and rate limits;
analyzer.correlate means “don’t trust scanner output alone — cross-check with WAF logs, DB error traces, and app telemetry.”

Why the wrapper matters
Raw scanner output is a noisy wiretap. A single sqlmap run can produce dozens of “interesting” lines that are, in context, harmless.
A well-designed wrapper does three things:
Scope enforcement — only allowed targets, only authorized environments; no accidental production scans.
Safe modes & rate limits — force non-destructive options, throttle requests to avoid uptime impact.
Contextual correlation — match scanner hits to runtime signals (WAF blocks, DB errors, unusual latency) before giving something a high confidence score.
Penligent situates itself precisely in the correlation and triage layer.
It doesn’t cheerlead raw scanner output. It digests it, cross-references with telemetry, and says:
“This one is worth a ticket because it aligns with DB errors + WAF alerts.”
Or: “Probably noise — verify before escalating.”
The controversy: democratization vs weaponization
This is where opinions heat up. Automation lowers the bar for testing — that’s the democratization argument, and it’s true.
Small security teams and Dev teams can get meaningful coverage fast.
But that same ease makes accidental misuse more likely.
You can imagine a rushed Slack message that turns into a broad, noisy scan.
Or a poorly tuned model that suggests an aggressive test for a sensitive endpoint.
If you’re doing this, two questions matter:
- Who can request a scan? (auth + approval rules)
- Who signs the remediation ticket? (engineers with context, not an automated bot)
Treat AI as a productivity multiplier, not a replacement for governance.
A practical guardrail checklist (for teams that want speed and safety)
- Authorization-first: scans only after a verified approval, logged and auditable.
- Enforced non-destructive defaults: wrapper enforces read-only probes and conservative timeouts.
- Multi-signal triage: scanner output must align with at least one other signal source before auto-prioritizing.
- Human-in-loop gating: critical severity items require human sign-off before remediation or aggressive testing.
- Replayability & evidence: full, replayable logs of requests/responses, plus context (app version, DB engine, WAF rules).
- Rate & blast radius limits: per-target throttles and global concurrency caps.
- Retention & privacy rules: scans touching PII are tagged and handled under data-protection policies.
Where Penligent slots into the cycle
Penligent doesn’t replace scanners — it operationalizes their outputs.
Use Penligent to:
- Turn a natural-language test intent into a policy-checked job.
- Run sanitized scanner probes (through safe wrappers).
- Collect telemetry across app logs, WAF, DB, and network.
- Correlate signals and surface only high-confidence findings with remediation steps.
That last bit matters.
In an automated world, triage becomes the scarce skill: telling real problems from background noise.
Penligent automates triage, but keeps the human reviewer in the loop for high-impact decisions.
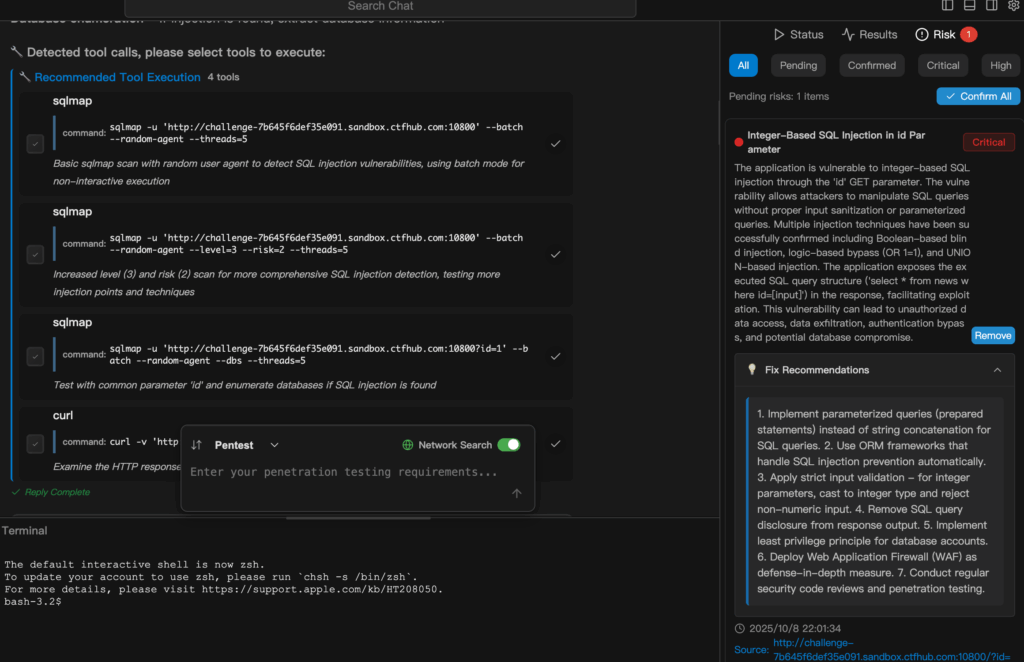
The uncomfortable truth
Automation will find more problems faster than humans alone.
That sounds great — until the people running the orgs realize it also creates more tickets, more interruptions, and more potential for accidental impact.
The real skill is designing the workflow so the signal-to-noise improves as you scale, not degrades.
If you insist on a concrete yardstick:
Automation without triage increases false-positive work in proportion to your scan volume.
Automation with triage increases real remediation throughput.
The difference is the analyzer layer.
Final note — an argument worth making
Some will say “ban AI-initiated scans” because the risks are existential.
That’s short-sighted. The point isn’t to outlaw capability; it’s to build guardrails so that capability helps defenders rather than helping attackers.
If your org can’t put policy, audit, and correlation in place, don’t flip the automation switch.
If you can, the productivity gains are real: fewer manual steps, faster hypothesis verification, and a better feedback loop between detection and fix.

